前言
趁着《苹果书》新书发布之际,
看准 开源项目 - 跟李宏毅学深度学习(入门),
库库学~

🍎
系列文章导航
【深度学习详解】Task1 机器学习基础-线性模型 Datawhale X 李宏毅苹果书 AI夏令营
【深度学习详解】Task2 分段线性模型-引入深度学习 Datawhale X 李宏毅苹果书 AI夏令营
【深度学习详解】Task3 实践方法论-分类任务实践 Datawhale X 李宏毅苹果书 AI夏令营
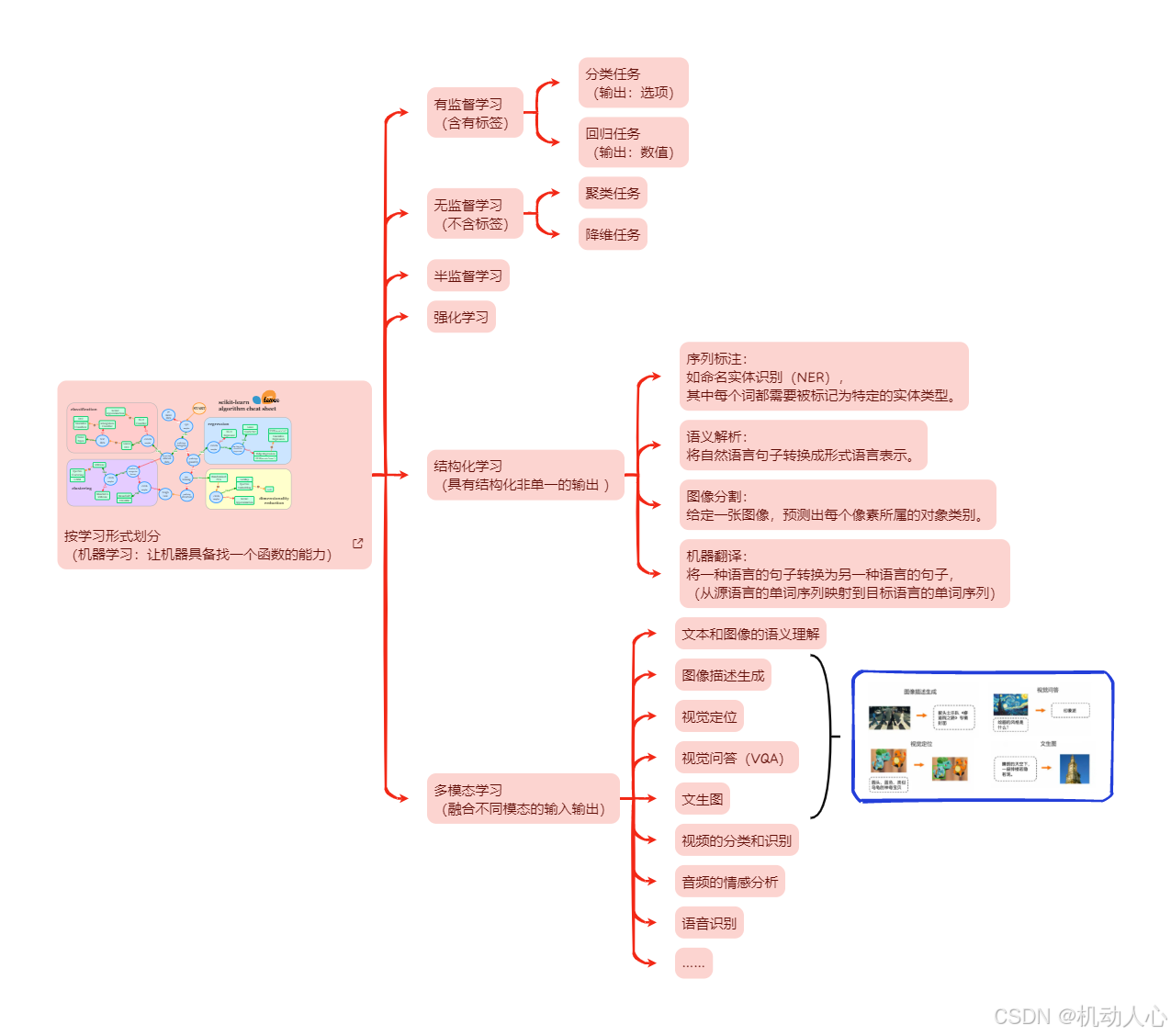
机器学习基础
按学习形式划分
鼠标右键 -> 在新标签页中打开图像

Python 编程实现
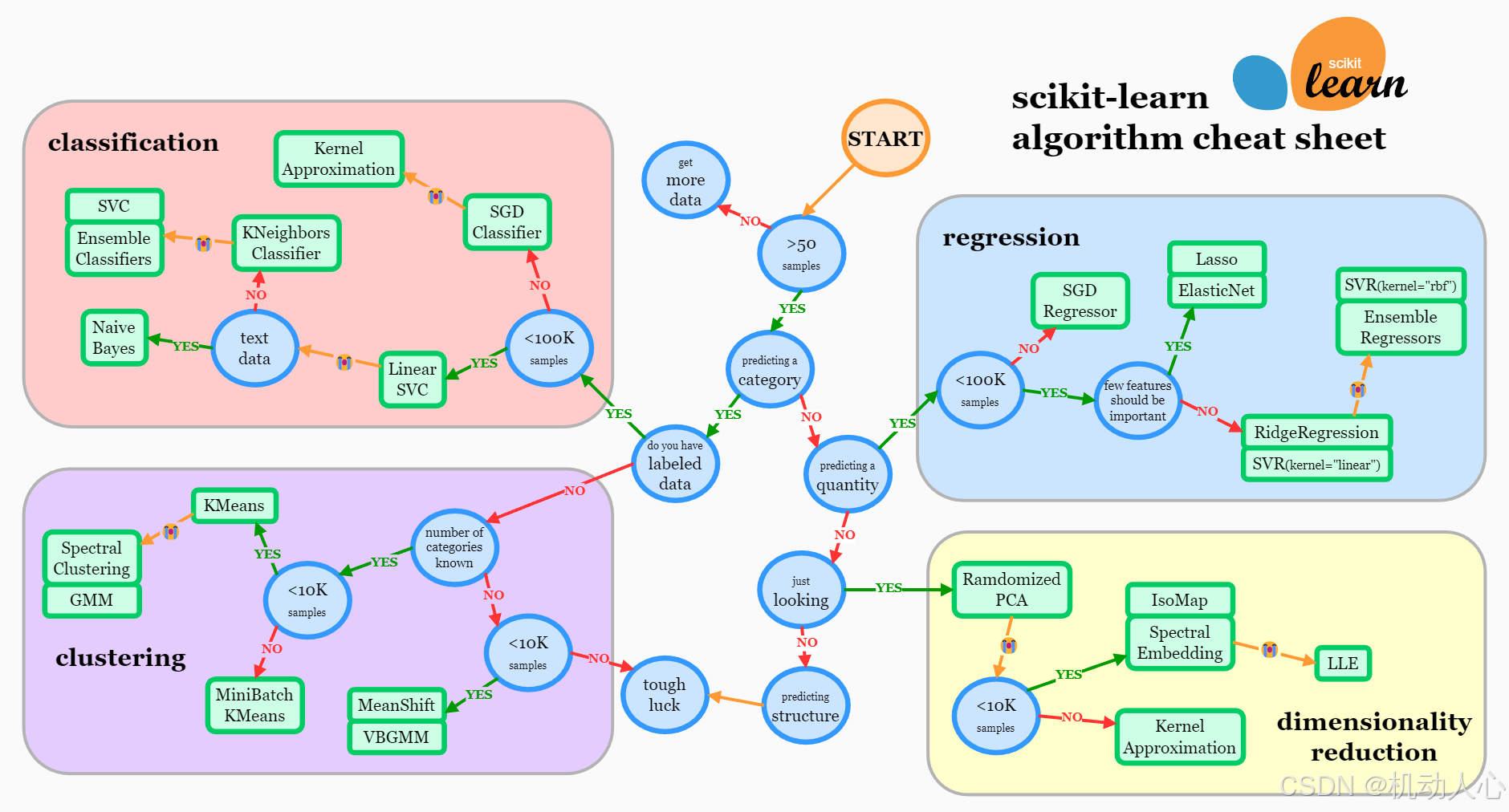
https://scikit-learn.org/stable/machine_learning_map.html
准备
访问 Graphviz 的官方网站 (https://www.graphviz.org/download/) 下载并安装 Graphviz。
安装过程中,确保选择“Add application directory to your system path”选项
导入数据并处理数据
import numpy as np
import pandas as pd
# 鸢尾花数据集,红酒数据集,乳腺癌数据集,糖尿病数据集
from sklearn.datasets import load_iris,load_wine,load_breast_cancer,load_diabetes
# 回归重要指标
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error
# 分类重要指标
from sklearn.metrics import accuracy_score, confusion_matrix, f1_score, precision_recall_curve, roc_auc_score
#训练集训练集分类器
from sklearn.model_selection import train_test_split
import graphviz #画文字版决策树的模块
import pydotplus #画图片版决策树的模块
from IPython.display import Image #画图片版决策树的模块
iris = load_iris()
print(iris.data) # 数据I
print(iris.target_names) # 标签名
print(iris.target) # 标签值
print(iris.feature_names) # 特证名(列名)
iris_dataframe = pd.concat([pd.DataFrame(iris.data),pd.DataFrame(iris.target)],axis=1)
print(iris_dataframe)
Xtrain, Xtest, Ytrain,Ytest = train_test_split(iris.data,iris.target,test_size=0.3)

随后选择对应接口创建模型,
输入数据通过 fit 方法进行训练,
然后进行 predict 并评估指标即可。
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis # 导入LDA模型
from sklearn.svm import SVC # 导入SVM模型(支持向量机)从中调用SVC模型 (支持向量机分类)
from sklearn.linear_model import LogisticRegression,LinearRegression
from sklearn.neighbors import KNeighborsRegressor,KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeRegressor,DecisionTreeClassifier
from sklearn.ensemble import RandomForestRegressor,RandomForestClassifier
from sklearn.ensemble import ExtraTreesRegressor,ExtraTreesClassifier
from sklearn.ensemble import AdaBoostRegressor,AdaBoostClassifier
from sklearn.ensemble import GradientBoostingRegressor,GradientBoostingClassifier
clf = RandomForestClassifier()
clf.fit(Xtrain, Ytrain)
Ypredict=clf.predict(Xtest)
print(r2_score(Ytest,Ypredict))
# 其中,决策树、随机森林等具有树形结构的基学习器可以把树形结构打印出来并保存为PDF或png文件
from sklearn import tree
clf = clf.estimators_[0]
tree_data = tree.export_graphviz(
clf
,feature_names =iris.feature_names
,class_names = iris.target_names#也可以自己起名
,filled = True #填充颜色
,rounded = True #决策树边框圆形/方形
)
graph1 = graphviz.Source(tree_data.replace('helvetica','Microsoft YaHei UI'), encoding='utf-8')
graph1.render('./iris_tree')
详见学习笔记
【数学建模导论】Task04 机器学习
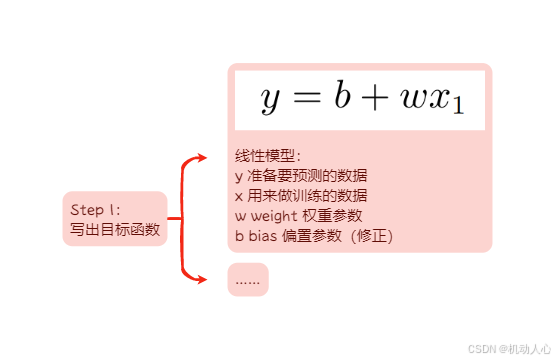
线性模型 - 机器学习的三个步骤
Step 1:写出目标函数
鼠标右键 -> 在新标签页中打开图像
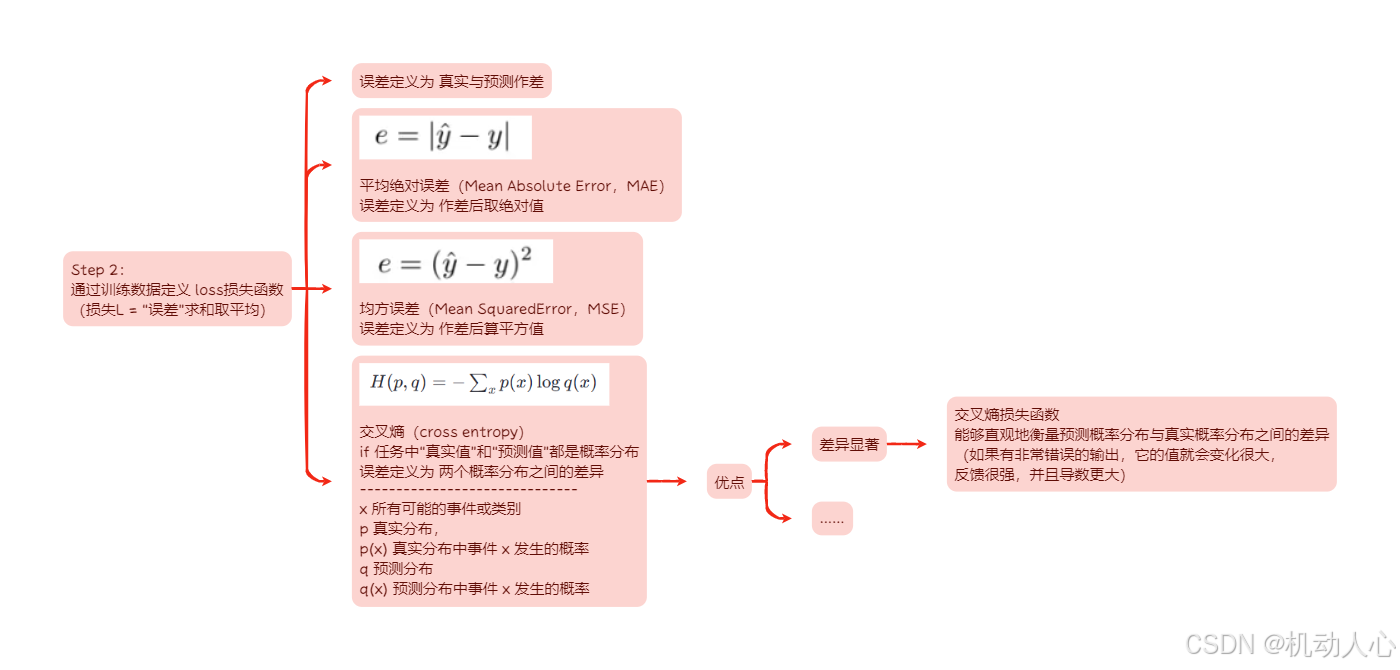
Step 2:定义 loss损失函数
鼠标右键 -> 在新标签页中打开图像
Step 3:确定 权重参数偏置参数
鼠标右键 -> 在新标签页中打开图像
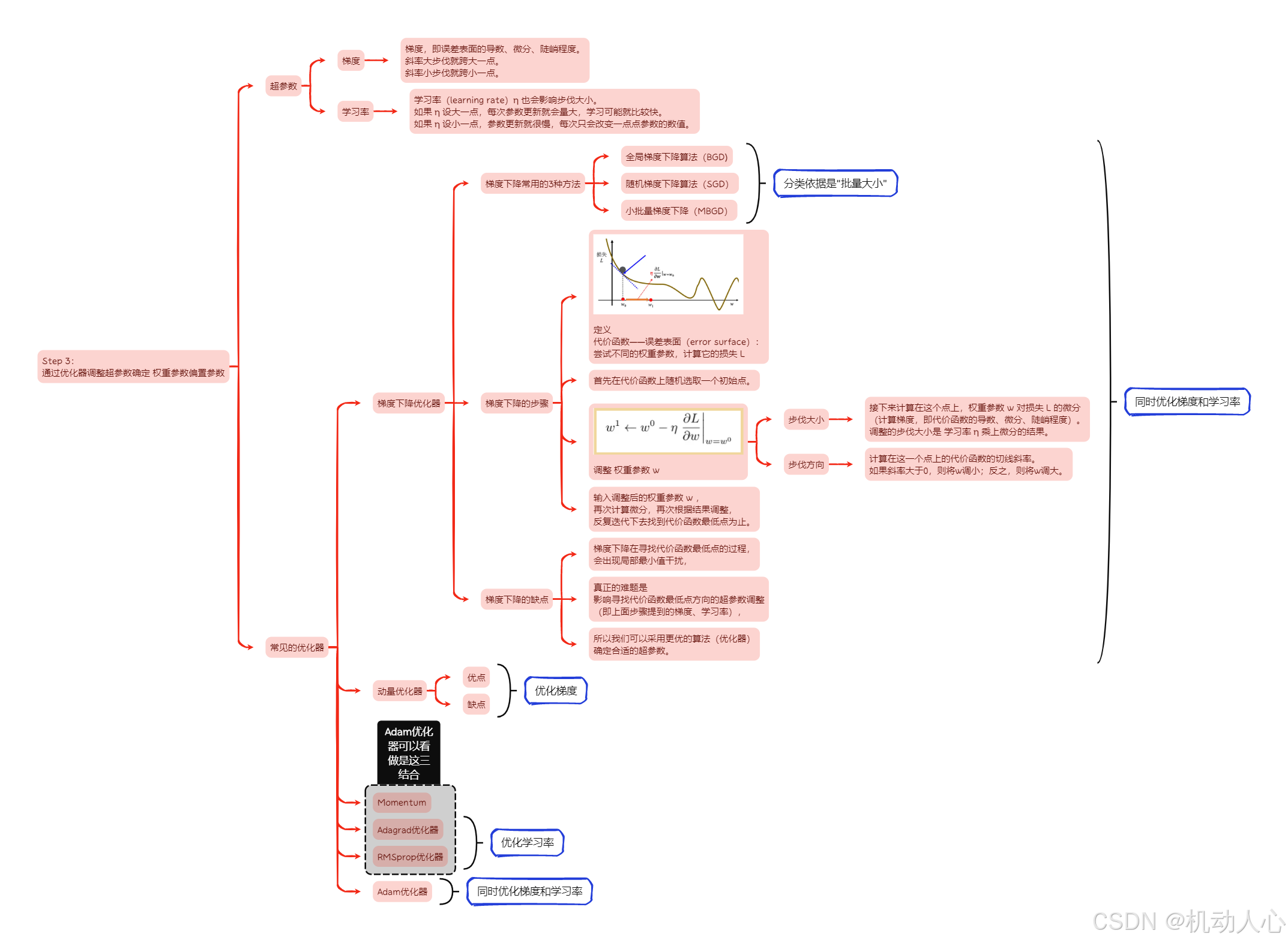
定义代价函数
- 代价函数——误差表面(error surface):
尝试不同的权重参数,计算它的损失 L
选取初始点
- 首先在代价函数上随机选取一个初始点。
调整 权重参数 w
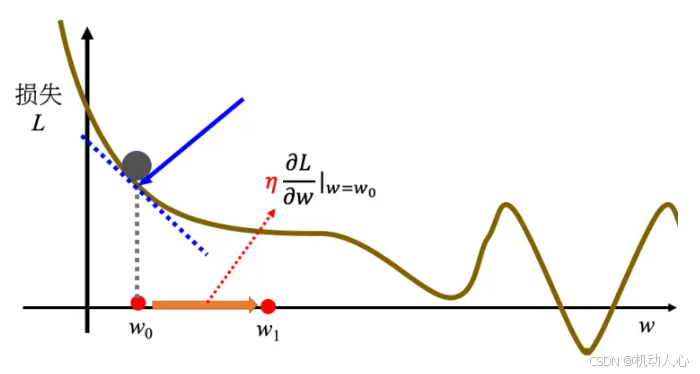
步伐大小:
接下来计算在这个点上,权重参数 w 对损失 L 的微分
(计算梯度,即代价函数的导数、微分、陡峭程度)。
调整的步伐大小是 学习率 η 乘上微分的结果。步伐方向
计算在这一个点上的代价函数的切线斜率。
如果斜率大于0,则将w调小;反之,则将w调大。
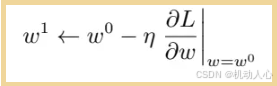
反复迭代计算
- 输入调整后的权重参数 w ,
再次计算微分,再次根据结果调整,
反复迭代下去找到代价函数最低点为止。
Read more
-
李宏毅深度学习教程 LeeDL-Tutorial(苹果书)
https://github.com/datawhalechina/leedl-tutorial
李宏毅《机器学习/深度学习》2021课程(视频教程 24 h 46 min)
https://www.bilibili.com/video/BV1JA411c7VT/ -
数学建模导论 intro-mathmodel 第9章 机器学习与统计模型
https://datawhalechina.github.io/intro-mathmodel/#/
对应学习笔记
【数学建模导论】Task04 机器学习 -
数学建模导论 intro-mathmodel 第10章:多模数据与智能模型
https://datawhalechina.github.io/intro-mathmodel/#/
对应学习笔记
【数学建模导论】Task05 多模数据与智能模型