SQL 查询语法
SQL 通用语法:
-
① SQL 语句可以单行或多行书写,以分号结尾;
-
② SQL 语句可以使用 空格/缩进 来增强语句的可读性;
-
③ MySQL 数据库的 SQL 语句不区分大小写,关键字建议使用大写;
-
④ 注释:
- 单行注释:
--注释内容或#注释内容(MySQL特有) - 多行注释:
/*注释内容 */
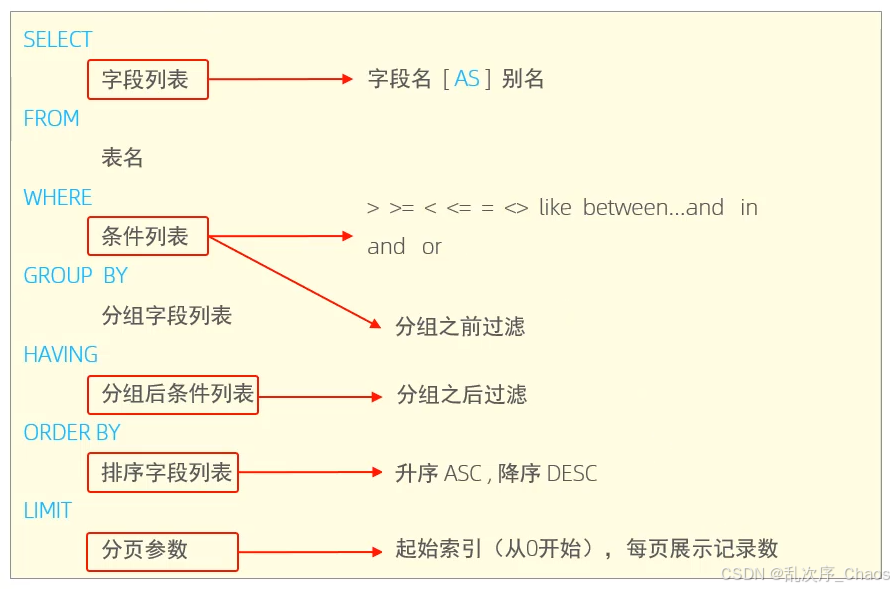
语法:
- 单行注释:

SELECT
字段列表
FROM
表名字段
WHERE
条件列表
GROUP BY
分组字段列表
HAVING
分组后的条件列表
ORDER BY
排序字段列表
LIMIT
分页参数
-- SQL运行原理
-- from--where--group by--having--select--order by--limit
-- 执行from语句从数据库中调取复制一份表格
-- 执行where语句在复制的表格中筛选出符合条件的数据行
-- 执行group by语句依据指定字段对筛选后的数据分区,将依据的字段去重分组,相当于Excel建立了一个数据透视表,添加了行标签
-- 执行having语句筛选满足条件的分组
-- 执行select语句,提取最后要显示的字段
-- 执行order by语句对筛选后的数据进行排序
-- 执行limit语句对排序后的数据限制显示的行
示例:
-- 查询年龄大于15的员工姓名、年龄,并根据年龄进行升序排序。
select name , age from emp where age > 15 order by age asc;
-- 在查询时,我们给 emp 表起一个别名 e,然后在 select 及 where 中使用该别名。
select e.name , e.age from emp e where e.age > 15 order by age asc;
-- 执行上述SQL语句后,我们看到依然可以正常的查询到结果,此时就说明: from 先执行, 然后 where 和 select 执行。那 where 和 select 到底哪个先执行呢?
-- 此时,此时我们可以给 select 后面的字段起别名,然后在 where 中使用这个别名,然后看看是否可以执行成功。
select e.name ename , e.age eage from emp e where eage > 15 order by age asc;
-- 执行上述SQL报错了
-- 由此我们可以得出结论: from 先执行,然后执行 where , 再执行select
-- 接下来,我们再执行如下SQL语句,查看执行效果:
select e.name ename , e.age eage from emp e where e.age > 15 order by eage asc;
-- 结果执行成功。那么也就验证了: order by 是在select 语句之后执行的。
-- 综上所述,我们可以看到DQL语句的执行顺序为: from → where → group by → having → select → order by → limit
1.基础查询
查询多个字段:
SELECT 字段1, 字段2, 字段3, ... FROM 表名;
SELECT * FROM 表名;
- ①在
select后指定要查询的字段名称,多个字段名之间用英文逗号,隔开,最后一个字段名后不需要加逗号; - ②
select和from关键字后不要忘记添加空格; - ③查询结果的字段顺序,按照
select后的字段名顺序显示; - ④SQL语句不区分大小写,
select和SELECT完全相同,但是实际场景中没空大小写切换,部分数据库管理工具会对select、from这类关键字做标色高亮处理,所以这里推荐选择全部小写; - ⑤一段标准的査询语句的最后应当添加英文分号
;向数据库声明这一段査询语句已结束; - ⑥查询单列,在select后指定要查询的那一个字段名称即可,例如
select name from world; - ⑦
select和"*"通配符联用返回查询表中所有的列,返回的所有列的显示顺序按照定义表时的顺序显示。
设置别名:
SELECT 字段1 [ AS 别名1 ], 字段2 [ AS 别名2 ], 字段3 [ AS 别名3 ], ... FROM 表名;
SELECT 字段1 [ 别名1 ], 字段2 [ 别名2 ], 字段3 [ 别名3 ], ... FROM 表名;
- ①
select核心语句中,在字段名后加as别名,可以给字段名在最后显示前赋予别名; - ②注意
as前后加空格; - ③这个别名不会修改该字段在数据库表中的原名,仅影响最后的显示;
- ④
as可以省略,写成字段1 [ 别名1 ],注意字段和别名之间有空格,别名和下一个字段之间为","。
去除重复记录:
SELECT DISTINCT 字段列表 FROM 表名;
- ①在
select核心语句中加distinct关键字,可以对最后显示的数据去重; - ②在
select distinct后加多个字段时,是对重复的行数据进行去重; - ③将
distinct放在第二个字段时,出现了语法错误,因为显示多个字段时distinct无法对单一字段去重,只能对这几个字段组成的行中重复的行数据去重,所以distinct本质是加在select后,而不是字段前。
转义:
SELECT * FROM 表名 WHERE name LIKE '/_张三' ESCAPE '/'
/之后的_不作为通配符
计算字段:
SELECT 字段1, 字段2, 字段2/字段1, ... FROM 表名;
- ①在
select的核心语句中,可以对数据库表中有的字段进行计算形成新的字段; - ②字段计算得到的每行数据仅涉及当前行,不会行与行之间交叉计算;
- ③加减乘除等数学运算都可以进行,当然,字段值必须是数值才可以;
- ④此外,也可以使用函数对字段进行处理,后续有专门的部分讲解函数。
示例:
-- 查询指定字段 name, workno, age返回
select name, workno, age from emp;
-- 查询所有字段返回
select id, workno, name, gender, age, idcard, workaddress, entrydate from emp;
select * from emp;
-- 查询所有员工的workaddress,别名为'工作地址'
select workaddress as '工作地址' from emp;
select workaddress '工作地址' from emp;
-- 查询公司员工的上班地址
select distinct workaddress from emp;
select workaddress as '工作地址' from emp group by workaddress;
2.条件查询
语法:
SELECT 字段列表 FROM 表名 WHERE 条件列表;
条件:
| 比较运算符 | 功能 |
|---|---|
> | 大于 |
>= | 大于等于 |
< | 小于 |
<= | 小于等于 |
= | 等于 |
<> 或 != | 不等于 |
BETWEEN ... AND ... | 在某个范围内(含最小、最大值) |
IN (...) | 在 in 之后的列表中的值,多选一 |
NOT IN (...) | 查找值不匹配值列表中的任意一个 |
LIKE 占位符 | 模糊匹配( _ 匹配单个字符,% 匹配任意个字符) |
IS NULL | 是 NULL |
IS NOT NULL | 不为 NULL |
| 逻辑运算符 | 功能 |
|---|---|
AND 或 && | 并且(多个条件同时成立) |
OR 或 || | 或者(多个条件任意一个成立) |
NOT 或 ! | 非,不是 |
示例:
-- 年龄等于30
select * from employee where age = 30;
-- 找寻字段值够于某个值时使用等于号"=",这里的值是一个数字,而文本需要用英文单引号(”)包裹
-- 年龄小于30
select * from employee where age < 30;
-- 小于等于30
select * from employee where age <= 30;
-- 没有身份证
select * from employee where idcard is null or idcard = '';
-- 年龄在20到30之间
select * from employee where age >= 20 and age <= 30;
-- 1.and的逻辑是同时满足,or的逻辑是满足其中一个条件即可
-- 2.and的运行优先级高于or,因此先运行and条件再运行or条件
-- 3.会有需要先运行or再运行and的条件需求,此时使用括号()来标记优先运行的部分,同时在and和or联用时最好使用括号来标记优先运行的部分便于阅读代码,也避免条件逻辑出错
-- 有身份证
select * from employee where idcard;
select * from employee where idcard is not null;
-- 不等于
select * from employee where age != 30;
-- 年龄在20到30之间
select * from employee where age between 20 and 30;
-- 不包括30
select * from employee where (age between 20 and 30) and (age != 30);
-- 下面语句不报错,但查不到任何信息
select * from employee where age between 30 and 20;
-- 1.between and 主要用于选取介于两个值之间的数据,这些值主要是数值和日期
-- 2.between and 包含了这两个值
-- 3.and前必须写两个数值中较小的那个,后必须写较大的那个,不然会出现无法显示数据的情况
-- 4.between and的逻辑是and,适用于包含边界的范围判断,使用between and时如果想要去掉某个边界可以使用英文符号(!=)来去除
-- 性别为女且年龄小于30
select * from employee where age < 30 and gender = '女';
-- 年龄等于25或30或35
select * from employee where age = 25 or age = 30 or age = 35;
select * from employee where age in (25, 30, 35);
-- 1.in会筛选出字段值中所有与括号内数据相等的行
-- 2.在这题中in筛选的是名为employee的这列字段中值等于25或30或35的行
-- 3.由上面可知in多条件的逻辑是or,满足其中一个条件即可,适用于对同一个字段的值进行多条件等值判断的情况
| 通配符 | 描述 |
|---|---|
% | 表示任何字符出现任意次数 |
_ | 表示任何字符出现一次 |
| 示例: |
-- 姓名为两个字
select * from employee where name like '__';
-- 身份证最后为X
select * from employee where idcard like '%X';
-- 模糊查询
-- 1.通配符用来匹配值的一部分,跟在like后面进行数据过滤,常用的通配符有"%"和 "_","%"用来匹配多个字符可以是零个、一个、多个字符,"_"仅能用来匹配单个字符
-- 2.like后的字符和通配符的组合表达式需要用英文单引号(””)包裹
3.聚合查询(聚合函数)
将一列数据作为一个整体,进行纵向计算,常见聚合函数:
| 函数 | 功能 |
|---|---|
count | 统计数量 |
max | 最大值 |
min | 最小值 |
avg | 平均值 |
sum | 求和 |
语法:
SELECT 聚合函数(字段列表) FROM 表名;
示例:
select count(*), count(字段名) from world
-- 1.对比count(*)和count(字段名)
-- count(字段名)计算指定字段下的总行数,但是计算时将忽略空值的行
-- count(*)计算表中的总行数,不管某列是否有数值或者为空值
-- 因此,count(*)适用于计算表格行数,count(字段名)计算字段中非空的行数
-- 2.sum、avg、max、min函数必须指定字段进行聚合运算,无法使用(*)通配符,同时这些指定字段名的聚合函数都会忽略空值行,以avg函数为例,已知gdp字段有3个空值,总195行,因此avg(gdp)等同于sum(gdp)/192
-- 3.在不使用group by子句时使用聚合函数,select字句中只能写聚合函数或者包含了聚合函数的算式,否则会报错
-- 报错翻译:如果没有GROUP BY子句,在没有GROUP列的情况下混合字段和聚合函数(MIN()、MAX()、COUNT()..)是非法的
-- 聚合函数类似于在excel中的数据透视表中只计算聚合值(求和项、计数项等),此时不能直接放一个原表的字段,数据透视表完全不支持
4.分组查询
语法:
SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUP BY 分组字段名 [ HAVING 分组后的过滤条件 ];
示例:
-- 对大洲进行分组
select continent from world group by contitent
select distinct contitent from world
-- 1.发现答案等同于对continent使用distinct去重后的答案,因此group by子句有数据去重的功能
-- 2.虽然都可以对数据去重,但是distinct和groupby的逻辑完全不同,distinct仅是返回不同的行,group by本质是先对指定的字段中相同的值分为一个区(字段值相同的放在一起,不会对字段进行删除),然后再对字段去重分组(将字段一样的去除掉)
-- 计算每个大洲的国家数量
select continent, count(name) from world group by continent
-- ①依据continent字段相同值分区;②将continent去重分组;③同时将分区内的多行数据聚合计算成一行数据,如:count计算每个分区内name个数
select yr, subject, count(winner) from nobel
where yr between 2013 and 2015
group by yr, subject
order by yr desc,subject,count(winner) desc
-- ①依据yr分区,从原表中筛选出2013到2015年的数据;②在yr的分区里,依据subject分区;③依据yr和subject去重分组;④在分区里聚合计算;⑤对yr降序排序、subject升序排序、获奖人数降序排序
-- 1.group by子句中有多字段时,依据写的字段顺序依次对数据分区,因此group by 字段名1,字段名2与group by 字段名2,字段名1不一样
-- 2.便用group by子句时,select只能使用聚合函数和group by引用过的字段,否则会报错
-- 根据性别分组,统计男性和女性数量(只显示分组数量,不显示哪个是男哪个是女)
select count(*) from employee group by gender;
-- 根据性别分组,统计男性和女性数量
select gender, count(*) from employee group by gender;
-- 根据性别分组,统计男性和女性的平均年龄
select gender, avg(age) from employee group by gender;
where 和 having 的区别:
- 执行时机不同:
where是分组之前进行过滤,不满足where条件不参与分组;having是分组后对结果进行过滤。 - 判断条件不同:
where不能对聚合函数进行判断,而having可以。
示例:
-- 查询总人口数量至少为1亿的大洲
select continent, sum(population) from world
group by continent having sum(population) >= 100000000
-- 1.只有使用了group by子句后才会使用having子句,having子句不能脱离group by子句单独使用,因为having子句本质上是对group by分组的筛选
-- 2.having子句中只能使用聚合函数和group by作为分组依据的字段
-- 3.having的表达式和where的表达式基本相同,但是having的表达式中可以使用聚合函数,where的表达式中不可以,因为where是对原表的行数据筛选,having是对group by分组后的数据筛选
-- 4.建议对行数据进行筛选时使用where子句,对含有聚合函数的筛选表达式使用having子句
select continent, avg(gdp)
from world
where (gdp > 20000000000 and population > 60000000) or (gdp < 8000000000 and capital like '%a%a%a%')
group by continent
having sum(population >= 300000000)
order by count(country) desc
limit 1
-- 年龄小于45,并根据工作地址分组
select workaddress, count(*) from employee where age < 45 group by workaddress;
-- 年龄小于45,并根据工作地址分组,获取员工数量大于等于3的工作地址
select workaddress, count(*) address_count from employee where age < 45 group by workaddress having address_count >= 3;
注意事项:
- 执行顺序:
where> 聚合函数 >having - 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
having表达式限定分组聚合后的查询行必须满足的条件,having核心子句是可选项,使用该子句是为了对group by分组后的数据进行筛选
5.排序查询
语法:
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1, 字段2 排序方式2;
排序方式:
ASC:升序(默认)DESC:降序
示例:
-- 根据年龄升序排序
SELECT * FROM employee ORDER BY age ASC;
SELECT * FROM employee ORDER BY age;
-- 两字段排序,根据年龄升序排序,入职时间降序排序(如果年龄相同那么就按这个)
SELECT * FROM employee ORDER BY age ASC, entrydate DESC;
-- 1.order by关键字后可以加多个字段,按照写的字段顺序,依次作为排序依据,该题中就是先按照age排序,再按照entrydate排序,即在对age排序后,age字段中有相同值的行,这些行再根据entrydate排序,如果没有相同的值,则不再依据entrydate字段排序
-- 2.数值由大到小排序叫降序(desc),由小到大为升序(asc),字母由Z到A为降序,由A到z为升序
-- 3.不指定排序方式时默认为asc升序,因此asc可以省略
-- 4.order by子句每个字段都需要指定排序方式,排序方式desc和asc(或者不写)只对其紧邻的前面的一个字段生效
-- 5.order by可以指定不在select子句中的字段作为排序依据
-- 查询1984年所有获奖者的姓名和奖项科目。结果将诺贝尔化学奖和物理学奖排在最后,然后按照科目排序,再按照获奖者姓名排序
select winner, subject
from nobel
where yr = 1984
order by subject in ('chemistry','physics'),subject, winner
注意事项:
- 如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序。
6.分页查询
语法:
SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询记录数;
示例:
-- 查询第一页数据,展示10条
SELECT * FROM employee LIMIT 0, 10;
-- 查询第二页
SELECT * FROM employee LIMIT 10, 10;
-- 1.limit n中n代表参数行数,只有n时从第一行开始显示前n行
-- 2.limit x,n中x代表位置偏移量,数据表中第一行的位置偏移量为0,第二行位置偏移量为1,以此类推,因此limit 0,n等价于limit n
-- 3.limit x,n返回第x+1行开始的n行,取到第x+n行(可以通过“从x行后开始,取n行,取到x+n行”来记忆,例如limit7,2意为从第7行后开始(第7行后为第8行),取2行,取到第9行)
-- 4.limit子句不同于其他核心子句也可以在其他类型的数据库中便用,limit仅能在MySQL数据库中使用
-- 5.limit子句写在整段查询语句的最后一行
注意事项:
- 起始索引从 0 开始, 起始索引 = ( 查询页码 − 1 ) ∗ 每页显示记录数 起始索引 = (查询页码 - 1) * 每页显示记录数 起始索引=(查询页码−1)∗每页显示记录数;
- 分页查询是数据库的方言,不同数据库有不同实现,MySQL 是
LIMIT; - 如果查询的是第一页数据,起始索引可以省略,直接简写
LIMIT 10。