(三)SQL 多表查询篇
多表查询
1.多表关系
项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种:
- 一对多(多对一)(One-to-Many):一个表中的记录可以与另一个表中的多个记录相关联;
- 多对多(Many-to-Many):一个表中的记录可以与另一个表中的多个记录相关联,反之亦然;
- 一对一(One-to-One):这意味着一个表中的记录与另一个表中的记录直接对应。
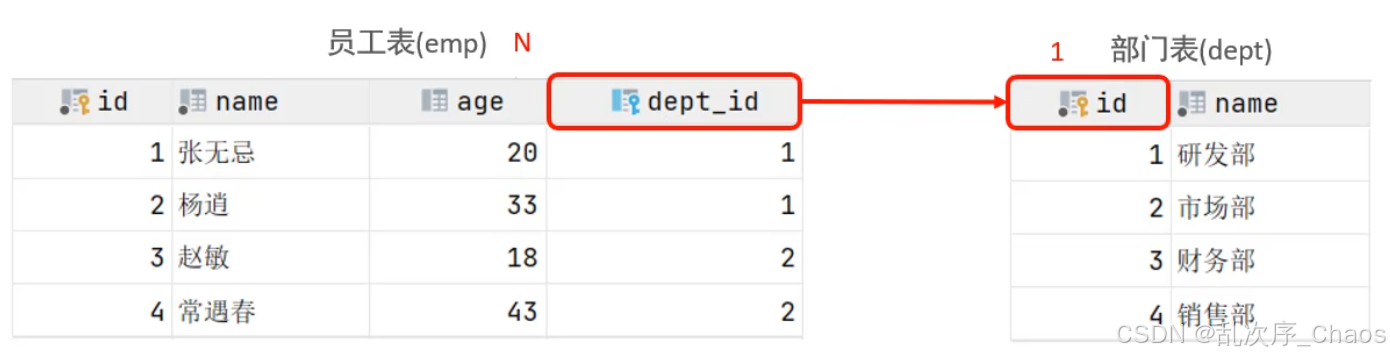
(1)一对多(多对一)
案例:部门与员工
关系:一个部门对应多个员工,一个员工对应一个部门
实现:在多的一方建立外键,指向一的一方的主键
示例:
## 创建班级表用于存储班级信息
CREATE TABLE Classes (
ClassID INT PRIMARY KEY, -- 班级ID,作为主键,确保每条记录的唯一性
ClassName VARCHAR(50), -- 班级名称,使用VARCHAR类型最大长度为50字符
-- 其他班级相关字段... -- 可以在此处添加更多与班级相关的字段,例如年级、班主任ID等
);
## 创建学生表用于存储学生信息
CREATE TABLE Students (
StudentID INT PRIMARY KEY, -- 学生ID,作为主键,确保每条记录的唯一性
StudentName VARCHAR(50), -- 学生姓名,使用VARCHAR类型最大长度为50字符
ClassID INT, -- 班级ID,用于关联到Classes表中的班级
FOREIGN KEY (ClassID) REFERENCES Classes(ClassID) -- 定义外键,将ClassID与Classes表中的ClassID关联起来
-- 其他学生相关字段... -- 可以在此处添加更多与学生相关的字段,例如年龄、性别等
);
Classes 表和 Students 表之间存在一对多关系。一个班级可以有多个学生,但每个学生只属于一个班级。这通过在 Students 表中添加一个外键 ClassID 来实现,该外键引用 Classes 表的 ClassID 主键。通过这种方式,确保每个学生都与一个班级相关联,但每个班级可以有多个学生。
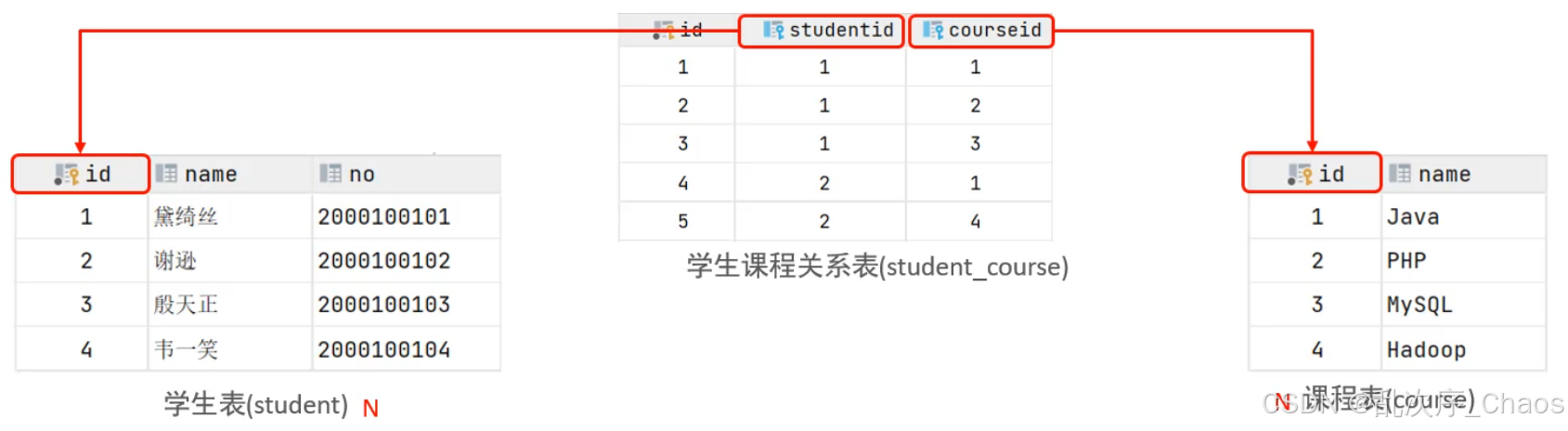
(2)多对多
案例:学生与课程
关系:一个学生可以选多门课程,一门课程也可以供多个学生选修
实现:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
示例:
## 创建学生表用于存储学生信息
CREATE TABLE Students (
StudentID INT PRIMARY KEY, -- 学生ID,作为主键,确保每条记录的唯一性
StudentName VARCHAR(50), -- 学生姓名,使用VARCHAR类型最大长度为50字符
-- 其他学生相关字段... -- 可以在此处添加更多与学生相关的字段,例如班级ID、年龄、性别等
);
## 创建课程表用于存储课程信息
CREATE TABLE Courses (
CourseID INT PRIMARY KEY, -- 课程ID,作为主键,确保每条记录的唯一性
CourseName VARCHAR(50), -- 课程名称,使用VARCHAR类型最大长度为50字符
-- 其他课程相关字段... -- 可以在此处添加更多与课程相关的字段,例如授课教师、学分、上课时间等
);
## 创建学生选课表,这是一个典型的“多对多”关系表,也称为“关联表”或“联接表”
CREATE TABLE StudentCourses (
StudentID INT, -- 学生ID,与Students表中的StudentID相对应
CourseID INT, -- 课程ID,与Courses表中的CourseID相对应
FOREIGN KEY (StudentID) REFERENCES Students(StudentID), -- 定义外键,将StudentID与Students表中的StudentID关联起来
FOREIGN KEY (CourseID) REFERENCES Courses(CourseID) -- 定义外键,将CourseID与Courses表中的CourseID关联起来
-- 注意:通常还需要一个主键来唯一标识每条记录,可以是单独的一列(如自增ID),也可以是这两列的组合
);
Students表和 Courses 表之间存在多对多关系。一个学生可以选择多门课程,而一门课程也可以有多个学生选择。这种关系通过一个关联表 StudentCourses 来实现,该表记录了哪些学生选择了哪些课程。在这个关联表中,StudentID 和 CourseID 都是外键,分别引用 Students 表和 Courses 表的主键。通过这种方式,确保每个学生和课程之间的多对多关系得以实现。
(3)一对一
案例:用户与用户详情
关系:一对一关系,多用于单表拆分,将一张表的基础字段放在一张表中,其他详情字段放在另一张表中,以提升操作效率
实现:在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)
示例:
![[多表关系:一对一.png]](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9kaXJlY3QvMjJiZTk1MWVmMzQyNDQ4OWJjNmJkNGRmNTFmZmUwZTcucG5n)
## 创建用户表用于存储用户基本信息
CREATE TABLE Users (
UserID INT PRIMARY KEY, -- 用户ID,作为主键,确保每条记录的唯一性
Username VARCHAR(50), -- 用户名,使用VARCHAR类型最大长度为50字符
-- 其他用户相关字段... -- 可以在此处添加更多与用户相关的字段,例如密码、电子邮件、注册日期等
);
## 创建身份证信息表用于存储用户的身份证相关信息
CREATE TABLE IDInfo (
IDInfoID INT PRIMARY KEY, -- 身份证信息ID,作为主键,确保每条记录的唯一性
UserID INT, -- 用户ID,关联到Users表中的UserID,表明该身份证信息属于哪个用户
IDNumber VARCHAR(18), -- 身份证号码,使用VARCHAR类型最大长度为18字符(适应中国大陆身份证号码)
-- 其他身份证信息相关字段... -- 可以在此处添加更多与身份证信息相关的字段,例如发证机关、有效期等
FOREIGN KEY (UserID) REFERENCES Users(UserID) -- 定义外键,将UserID与Users表中的UserID关联起来,建立用户与身份证信息的关系
);
- ①
Users表和IDInfo表之间是一对一的关系,因为每个人都有一个唯一的身份证号; - ②
UserID是Users表的主键,而在IDInfo表中,UserID是外键,它引用了Users表中的UserID。这意味着每个记录在IDInfo表中都必须有一个与之对应的UserID在Users表中; - ③ 如果某个用户没有身份证信息,则可以在
Users表中创建记录,但在IDInfo表中不创建记录。或者反过来,如果某人的身份证信息是保密的或未收集,则可以在IDInfo表中创建记录,但在Users表中不创建记录。但两者之间不能同时没有记录,因为它们之间是一对一的关系。
2.多表查询分类
合并查询(笛卡尔积,会展示所有组合结果):
select * from employee, dept;
笛卡尔积:两个集合 A 集合和 B 集合的所有组合情况(在多表查询时,需要消除无效的笛卡尔积)
![[笛卡尔积.png]](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9kaXJlY3QvMmIyMWE2M2M2OTZlNGY4ZmJlMzMyOWJkYmQxYmU2OTYucG5n)
消除无效笛卡尔积:
select * from employee, dept where employee.dept = dept.id;
![[消除无效笛卡尔积.png]](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9kaXJlY3QvMTcwM2FlMGQwMjdkNDQ0NDlhMmQzZDRkYmY2ODM3OTYucG5n)
(1)内连接查询
内连接查询的是 A、B 两张表交集的 C 部分
隐式内连接(使用逗号 , 分隔表名,并在 WHERE 子句中指定连接条件):
SELECT 字段列表 FROM 表1, 表2 WHERE 条件 ...;
![[表连接.png]](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9kaXJlY3QvZmQxYjI4MWUzZGRmNDRlOWFkN2IyZTJiYjdlYzhkMTgucG5n)
显式内连接(使用 INNER JOIN 关键字明确指出连接操作,并在 ON 子句中指定连接条件):
SELECT 字段列表 FROM 表1 [ INNER ] JOIN 表2 ON 连接条件 ...;
隐式内连接和显式内连接都是在 SQL 中实现内连接的方式,它们的主要区别在于语法格式和可读性、性能方面:
- 可读性:
- 隐式内连接:由于连接条件与
WHERE子句中的其他过滤条件混合在一起,对于复杂查询或多个表的连接,可读性较差,不易于理解和维护。 - 显式内连接:通过明确的
JOIN关键字和ON子句分离连接条件和过滤条件,使得查询语句结构更清晰,可读性更好。
- 隐式内连接:由于连接条件与
- 性能:
- 隐式内连接:在执行时,数据库系统首先会做笛卡尔积(即两个表的所有行组合),然后再根据
WHERE子句中的条件进行筛选,这在大数据量下可能会导致性能问题。 - 显式内连接:数据库系统通常能够更有效地处理显式内连接,因为它可以直接根据
ON子句中的连接条件进行匹配,避免了不必要的笛卡尔积操作。在大数据量下,显式内连接通常会有更好的性能。
- 隐式内连接:在执行时,数据库系统首先会做笛卡尔积(即两个表的所有行组合),然后再根据
因此,虽然两种内连接都能达到相同的数据查询结果,但显式内连接在可读性和性能上通常更优。现代的 SQL 编程实践中,更推荐使用显式内连接,因为它的语法更标准、清晰,且在处理大数据时更高效。
示例:
## 查询员工姓名,及关联的部门的名称
-- 隐式
SELECT e.name AS employee_name, -- 选择并重命名employee表中的name字段为employee_name
d.name AS department_name -- 选择并重命名dept表中的name字段为department_name
FROM employee AS e, -- 将employee表别名为e
dept AS d -- 将dept表别名为d
WHERE e.dept = d.id; -- 条件:通过员工的dept字段与部门的id字段匹配,关联两个表
-- 显式
SELECT
e.name AS employee_name, -- 员工姓名,来自employee表,并别名为e
d.name AS department_name -- 部门名称,来自dept表,并别名为d
FROM
employee AS e -- 使用employee表,并将其临时命名为e
INNER JOIN -- 使用内连接来关联employee表和dept表
dept AS d ON e.dept = d.id; -- 连接条件:通过员工表中的dept字段与部门表中的id字段相匹配进行关联
(2)外连接查询
左外连接:
查询左表所有数据,以及两张表交集部分数据( A + C 部分)
SELECT 字段列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON 条件 ...;
相当于查询表1的所有数据,包含表1和表2交集部分数据
![[表连接.png]](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9kaXJlY3QvMmExZmRlYTExMWNiNGU1YWJlMzJjYTA3ZGFhNzJmMWEucG5n)
右外连接:
查询右表所有数据,以及两张表交集部分数据( B + C 部分)
SELECT 字段列表 FROM 表1 RIGHT [ OUTER ] JOIN 表2 ON 条件 ...;
示例:
-- 左外连接
## 查询所有员工及其可能所属的部门名称
SELECT
e.*, -- 选择employee表中的所有字段
d.name AS department_name -- 部门名称,来自dept表,并别名为department_name
FROM
employee AS e -- 使用employee表,并将其临时命名为e
LEFT OUTER JOIN -- 使用左外连接来关联employee表和dept表
dept AS d ON e.dept = d.id; -- 连接条件:通过员工表中的dept字段与部门表中的id字段相匹配进行关联
-- 右外连接
## 查询所有部门及其关联的员工信息(如果存在)
SELECT
d.name AS department_name, -- 部门名称,来自dept表,并别名为department_name
e.* -- 员工的所有字段,来自employee表
FROM
employee AS e -- 使用employee表,并将其临时命名为e
RIGHT OUTER JOIN -- 使用右外连接来关联employee表和dept表
dept AS d ON e.dept = d.id; -- 连接条件:通过员工表中的dept字段与部门表中的id字段相匹配进行关联
(3)自连接查询
自连接查询是一种特殊的 SQL 查询技术,它用于在同一个表中连接相同的表,通常是为了比较表中的不同行。这种查询方式允许你根据表中的某些关联字段来关联表的自身,从而获取具有特定关系的数据。当前表与自身的连接查询,自连接必须使用表别名。
语法:
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 ...;
自连接查询,可以是内连接查询,也可以是外连接查询。
示例:
-- 查询员工及其所属领导的名字
select a.name, b.name from employee a, employee b where a.manager = b.id;
-- 没有领导的也查询出来
select a.name, b.name from employee a left join employee b on a.manager = b.id;
3.联合查询 union, union all
联合查询(Union Query)是 SQL 中用于垂直合并多个查询结果集的操作。它将多个 SELECT 语句的结果合并成一个结果集,类似于“上下堆叠”数据。与 JOIN(横向合并列)不同,联合查询是纵向合并行。
语法:
SELECT 字段列表 FROM 表A ... UNION [ALL] SELECT 字段列表 FROM 表B ...
注意事项:
- ①合并规则:
- 多个
SELECT的列数必须相同。 - 对应列的数据类型需兼容(如数值与数值、文本与文本)。
- 列名以第一个
SELECT的列名为准。
- 多个
- ②去重与保留重复:
UNION:自动去重,合并后删除重复行。UNION ALL:保留所有行(包括重复行),性能更高。
示例:
## 合并两年的用户数据,并去除重复的记录
SELECT user_id, name FROM user_2022 -- 从2022年的用户数据表中选择user_id和name字段
UNION -- 使用UNION操作符合并两个SELECT语句的结果集,并自动去除重复的记录
SELECT user_id, name FROM user_2023; -- 从2023年的用户数据表中选择user_id和name字段
## 合并两年的用户数据,并保留所有记录,包括重复项
SELECT user_id, name FROM user_2022 -- 从2022年的用户数据表中选择user_id和name字段
UNION ALL -- 使用UNION ALL操作符合并两个SELECT语句的结果集,不会去除重复的记录
SELECT user_id, name FROM user_2023; -- 从2023年的用户数据表中选择user_id和name字段
4.子查询
子查询(Subquery)是嵌套在另一个 SQL 查询内部的查询。它像一个“查询中的查询”,用于为外层查询提供临时数据源或过滤条件。SQL 语句中嵌套 SELECT 语句,又称嵌套查询。 子查询可以出现在 SELECT、FROM、WHERE、HAVING 甚至 INSERT / UPDATE / DELETE 语句中。 子查询的核心作用:
- ①数据过滤:在
WHERE或HAVING中动态生成条件; - ②派生数据:在
FROM中生成临时表供外层查询使用; - ③计算字段:在
SELECT中动态生成列值。
语法:
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2);
根据子查询结果可以分为:
- 标量子查询(子查询结果为单个值)
- 列子查询(子查询结果为一列)
- 行子查询(子查询结果为一行)
- 表子查询(子查询结果为多行多列)
(1)标量子查询
子查询返回的结果是单个值(数字、字符串、日期等)。
常用操作符:- , < > , > , >= , < , <=
示例:
## 查询名为“销售部”的部门ID
SELECT id
FROM dept
WHERE name = '销售部' -- 筛选出名称为“销售部”的部门记录
; -- 从dept表中选择id字段,条件是name字段等于'销售部'
## 查询属于编号为 4 的部门(例如销售部)的所有员工信息
SELECT *
FROM employee
WHERE dept = 4 -- 筛选条件:dept字段等于4,假设4是目标部门的ID,例如销售部
; -- 从employee表中选择所有字段,条件是dept字段等于4
## 合并(子查询)
-- 查询属于销售部的所有员工信息
SELECT * FROM employee
WHERE dept = (
-- 子查询:获取名为“销售部”的部门ID
SELECT id
FROM dept
WHERE name = '销售部' -- 筛选出名称为“销售部”的部门
) -- 子查询的结果作为外部查询中dept字段的比较值
; -- 主查询:从employee表中选择所有字段,条件是dept字段等于子查询返回的部门ID(即销售部的ID)
## 查询入职日期晚于员工'xxx'的所有员工信息
SELECT *
FROM employee
WHERE entrydate > (
-- 子查询:获取名为'xxx'的员工的入职日期
SELECT entrydate
FROM employee
WHERE name = 'xxx' -- 筛选出名称为'xxx'的员工记录
) -- 子查询的结果作为外部查询中entrydate字段的比较值
; -- 主查询:从employee表中选择所有字段,条件是entrydate字段大于子查询返回的入职日期
(2)列子查询
返回的结果是一列多行。
常用操作符:
| 操作符 | 描述 |
|---|---|
IN | 在指定的集合范围内,多选一 |
NOT IN | 不在指定的集合范围内 |
ANY | 子查询返回列表中,有任意一个满足即可 |
SOME | 与 ANY 等同,使用 SOME 的地方都可以使用 ANY |
ALL | 子查询返回列表的所有值都必须满足 |
示例:
## 查询销售部和市场部的所有员工信息
SELECT *
FROM employee
WHERE dept IN (
-- 子查询:获取名为“销售部”或“市场部”的部门ID
SELECT id
FROM dept
WHERE name = '销售部' OR name = '市场部' -- 筛选出名称为“销售部”或“市场部”的部门记录
) -- 子查询的结果作为外部查询中dept字段的比较值列表
; -- 主查询:从employee表中选择所有字段,条件是dept字段在子查询返回的部门ID列表中
## 查询比财务部所有员工工资都高的员工信息
SELECT *
FROM employee
WHERE salary > ALL (
-- 子查询:获取财务部所有员工的工资
SELECT salary
FROM employee
WHERE dept = (
-- 子查询:获取名为“财务部”的部门ID
SELECT id
FROM dept
WHERE name = '财务部' -- 筛选出名称为“财务部”的部门记录
) -- 子查询的结果作为外部查询中dept字段的比较值
) -- 子查询的结果集作为外部查询salary字段的比较集合
; -- 主查询:从employee表中选择所有字段,条件是salary字段大于财务部所有员工的工资
## 查询比研发部任意一人工资高的员工信息
SELECT *
FROM employee
WHERE salary > ANY (
-- 子查询:获取研发部所有员工的工资
SELECT salary
FROM employee
WHERE dept = (
-- 子查询:获取名为“研发部”的部门ID
SELECT id
FROM dept
WHERE name = '研发部' -- 筛选出名称为“研发部”的部门记录
) -- 子查询的结果作为外部查询中dept字段的比较值
) -- 子查询的结果集作为外部查询salary字段的比较集合
; -- 主查询:从employee表中选择所有字段,条件是salary字段大于研发部任意一名员工的工资
(3)行子查询
返回的结果是一行多列。
常用操作符: = , < , >, IN , NOT IN
示例:
## 查询与名为'xxx'的员工薪资及直属领导相同的员工信息
SELECT *
FROM employee
WHERE (salary, manager) = (
-- 子查询:获取名为'xxx'的员工的薪资和直属领导信息
SELECT salary, manager
FROM employee
WHERE name = 'xxx' -- 筛选出名称为'xxx'的员工记录
) -- 子查询的结果作为外部查询中(salary, manager)元组的比较值
; -- 主查询:从employee表中选择所有字段,条件是(salary, manager)元组等于子查询返回的元组
(4)表子查询
返回的结果是多行多列的临时表。
常用操作符:IN
示例:
## 查询与名为'xxx1'或'xxx2'的员工职位和薪资相同的员工信息
SELECT *
FROM employee
WHERE (job, salary) IN (
-- 子查询:获取名为'xxx1'或'xxx2'的员工的职位和薪资
SELECT job, salary
FROM employee
WHERE name = 'xxx1' OR name = 'xxx2' -- 筛选出名称为'xxx1'或'xxx2'的员工记录
) -- 子查询的结果作为外部查询中(job, salary)元组的比较集合
; -- 主查询:从employee表中选择所有字段,条件是(job, salary)元组在子查询返回的元组集合中
## 查询入职日期是2006-01-01之后的员工,及其部门信息
SELECT e.*, d.*
FROM (
-- 子查询:筛选出所有入职日期在2006-01-01之后的员工
SELECT *
FROM employee
WHERE entrydate > '2006-01-01' -- 筛选条件:entrydate字段值大于'2006-01-01'
) AS e -- 将子查询的结果命名为e
LEFT JOIN dept AS d ON e.dept = d.id -- 左连接:将员工表(e)与部门表(d)基于部门ID进行关联
; -- 主查询:选择员工表(e)和部门表(d)中的所有字段