关联分析
关联分析(association analysis):在大规模数据集只中寻找数据之间有意义的关系——关联规则的无监督机器学习的算法。假设你是一家超市的数据分析师,你想要了解顾客的购物习惯。你有一个包含所有交易数据的数据库,每一笔交易都记录了顾客购买的商品。
- 关联规则是你在分析中发现的规律或者模式。比如,你可能会发现“如果顾客购买了牛奶,那么他们也很可能购买面包”这样一个规则。这个规则说明了牛奶和面包之间存在一种关联性;
- 关联分析则是你用来发现这些规则的过程。在这个过程中,你会使用像 Apriori 这样的算法来分析数据库中的交易数据。关联分析的目的是找出数据库中的项目之间隐藏的关联性。
关联分析的关系可以概括为:
- 关联分析是方法:关联分析是一种数据分析的方法,它用来挖掘大量数据中的关联性;
- 关联规则是结果:关联规则是关联分析发现的结果,它描述了数据中不同项目之间的有趣关系。
关联分析就是寻找数据中不同变量之间的意外联系,这些联系可能在没有明确逻辑关系的情况下出现。通过发现这些关联,我们可以更好地理解数据,预测未来的趋势,或者优化业务策略。
关联分析的应用领域:
- 零售业:零售商使用关联分析来确定哪些商品经常一起被购买,以便在商店中调整商品的位置或者进行捆绑销售。例如,尿布和啤酒的关联在超市中被发现后,超市就将这两种商品放在了靠近的货架上。
- 营销和广告:通过分析消费者的购买习惯和偏好,营销人员可以设计更有效的广告策略,比如针对特定人群的定制广告。
- 金融领域:银行和金融机构使用关联分析来发现欺诈行为,比如信用卡欺诈。通过分析交易式,可以识别出异常行为并采取预防措施。
- 医疗健康:在医疗领域,关联分析可以帮助医生发现疾病和特定生活习惯之间的联系,或者药物之间可能的相互作用。
- 电信行业:电信公司使用关联分析来分析用户的使用模式,比如通话、短信和数据使用,以便提供个性化的服务计划。
- 库存管理:通过分析销售数据,企业可以更有效地管理库存,确定哪些商品需要更多的库存,哪些商品可能需要减少库存。
- 推荐系统:在线购物平台和流媒体服务使用关联分析来创建推荐系统,向用户推荐他们可能会感兴趣的商品或内容。
- 供应链管理:分析供应链中的数据,企业可以优化物流,减少成本,提高效率。
- 安全监控:在安全领域,关联分析可以用来识别可能的威胁或异常行为,比如在监控视频中识别可疑活动。
- 教育:在教育领域,关联分析可以帮助教育工作者了解学生的学习习惯和成绩之间的关系,以便提供个性化的教学支持。
关联分析涉及概念:
- 项:每条交易中的每个物品都可以称为一个项,如牛奶,面包等。
- 项集(ltemset):指一组项的集合。在超市的例子中,项集可以是“尿布”和“啤酒”或者其他单独的商品。
- 频繁项集:指那些在数据集中出现频率超过用户定义的最小支持度的项集。
- 关联规则(Association Rule):关联规则是指在一个数据集中发现的频繁项集之间的关系。在超市的例子中,我们可以得到一条关联规则:“如果顾客购买了尿布,那么顾客很可能也会购买啤酒”。
- 事务:指一组项目或物品的集合,这些项目或物品在一次交易、事件或行为中同时出现。事务通常用于描述消费者购买商品、数据库中的记录或者其他任何一组相关的项目。例如,在超市的销售数据中,每一行数据可以代表一个事务,其中每一列代表一个商品。如果一个顾客在一次购物中购买了牛奶、面包和鸡蛋,那么这就可以被视为一个事务,其中包含三个项(牛奶、面包、鸡蛋)。
1.指标作用及选择
| 指标 | 定义 | 判断关联的作用 |
|---|---|---|
| 支持度(Support) | 项集出现的频率(如 {X,Y} 在所有事务中的占比) | 衡量规则的普遍性,过滤罕见项集。 |
| 置信度(Confidence) | 规则 X → Y 的可信度(在 X 出现时 Y 出现的概率) | 衡量规则的可靠性,但可能受 Y 本身高频影响。 |
| 提升度(Lift) | 规则的有效性(X 和 Y 的关联强度是否强于随机) | 核心指标:>1 表示正相关,=1 独立,<1 负相关。 |
| 杠杆率(Leverage) | 规则的实际支持度与期望支持度的差异(正值表示显著关联) | 衡量规则的实际价值,对高频项敏感。 |
| 确信度(Conviction) | 衡量规则的预测错误程度(值越大,规则越可靠) | 补充指标,高值表示规则不易出错。 |
(1)指标介绍
-
支持度(Support)
- 定义:项集在所有事务中出现的频率。如果我们在所有的购物篮中查看,发现尿布和啤酒一起出现在 80% 的购物篮中,那么我们就说尿布和啤酒的支持度是 80% 。支持度越高,说明这两个物品一起购买的概率越大。
- 公式: S u p p o r t ( X ) = 包含项集 X 的事务数 总事务数 Support(X)=\frac{包含项集 X 的事务数} {总事务数} Support(X)=总事务数包含项集X的事务数
- 作用:衡量项集的普遍性,用于生成频繁项集;
- 最小支持度(Minimum Support):最小支持度是用户定义的一个阈值,用来决定一个项集是否足够频繁。如果我们设置的最小支持度是 50%,那么只有当尿布和啤酒一起出现在至少 50% 的购物篮中时,我们才认为这个组合是频繁的。
-
置信度(Confidence)
- 定义:在包含前件
X的事务中,同时包含后件Y的条件概率;例如在购买了尿布(前件)的顾客中,有多少比例同时也购买了啤酒(后件)。如果购买了尿布的顾客中有 80% 同时也购买了啤酒,那么尿布导致啤酒的置信度就是 80%。置信度越高,说明购买前件的顾客购买后件的概率越大。 - 公式: C o n f i d e n c e ( X → Y ) = S u p p o r t ( X ∪ Y ) S u p p o r t ( X ) Confidence(X→Y)=\frac{Support(X∪Y)}{Support(X)} Confidence(X→Y)=Support(X)Support(X∪Y)
- 作用:衡量规则的可靠性;
- 最小置信度(Minimum Confidence):最小置信度是用户定义的一个阈值,用来决定一条关联规则是否足够可信。如果我们设置的最小置信度是 60%,那么只有当尿布导致啤酒的置信度至少是 60% 时,我们才会认为这个关联规则是可信的。
- 定义:在包含前件
-
提升度(Lift)
- 定义:规则的有效性,衡量
X和Y的独立性。它表示两个项集共同出现的概率与名自独立出现概率的乘积的比值。商品A出现,对商品B的出现概率提升的程度; - 公式: L i f t ( X → Y ) = S u p p o r t ( X ∪ Y ) S u p p o r t ( X ) × S u p p o r t ( Y ) Lift(X→Y)=\frac{Support(X∪Y)}{Support(X)×Support(Y)} Lift(X→Y)=Support(X)×Support(Y)Support(X∪Y)
- 作用:衡量规则的强度;
- 解释:
- Lift > 1:
X和Y正相关,代表有提升。 - Lift = 1:
X和Y独立,代表没有提升,也没有下降。 - Lift < 1:
X和Y负相关,代表下降。
- Lift > 1:
- 定义:规则的有效性,衡量
-
杠杆率(Leverage)
- 定义:规则的实际支持度与期望支持度的差异。
- 公式: L e v e r a g e ( X → Y ) = S u p p o r t ( X ∪ Y ) − S u p p o r t ( X ) × S u p p o r t ( Y ) Leverage(X→Y)=Support(X∪Y)−Support(X)×Support(Y) Leverage(X→Y)=Support(X∪Y)−Support(X)×Support(Y)
- 作用:衡量规则的显著性。
-
确信度(Conviction)
- 定义:衡量规则预测错误的程度。
- 公式: C o n v i c t i o n ( X → Y ) = 1 − S u p p o r t ( Y ) 1 − C o n f i d e n c e ( X → Y ) Conviction(X→Y)=\frac{1−Support(Y)}{1−Confidence(X→Y)} Conviction(X→Y)=1−Confidence(X→Y)1−Support(Y)
- 解释:值越大,规则越可靠。
(2)关联判断
-
初步筛选:支持度
- 条件:支持度 ≥ 最小支持度阈值(如 0.1);
- 目的:排除偶然出现的低频项集,确保规则具有实际应用价值;
- 注意:支持度过低可能导致规则不普适,但过高可能仅反映常识性关联。
-
可靠性验证:置信度
- 条件:置信度 ≥ 最小置信度阈值(如 0.5);
- 目的:确保规则在发生时具有较高的准确性;
- 陷阱:若后件(B)本身支持度极高(如 0.9),即使置信度高(如 0.8),规则
A → B也可能是无效的(需结合提升度)。
-
独立性检验:提升度
- 条件:提升度 > 1;
- 目的:确认规则的有效性,排除因项本身高频导致的虚假关联;
- 解释:
- 若提升度 = 1:A 和 B 独立,规则无效;
- 若提升度 > 1:A 和 B 正相关,规则有意义;
- 若提升度 < 1:A 和 B 负相关(可能需反向规则
A → ¬B)。
-
显著性补充:杠杆率
- 条件:杠杆率 > 0;
- 目的:进一步验证规则的显著性,避免微小差异导致的误判;
- 注意:杠杆率对高频项敏感(如
{牛奶}和{面包}可能杠杆率高,但提升度可能接近 1)。
-
稳定性验证:确信度
- 条件:确信度 ≥ 1(理想值越大越好)。
- 目的:衡量规则的抗干扰能力,值越大表示规则越稳定。
- 公式特性:
- 若置信度 = 1,确信度为无穷大(完美规则)。
- 若置信度 < 支持度(Y),确信度 < 1(规则不可靠)。
啤酒与尿布:
沃尔玛的“啤酒与尿布”是营销界经典的案例,该案例是正式刊登在1998年的《哈佛商业评论》上面的,这应该算是目前发现的最权威报道,20世纪90年代的美国沃尔玛超市中,沃尔玛的超市管理人员分析销售数据时发现了一个令人难于理解的现象:在某些特定的情况下,“啤酒”与“尿布”两件看上去毫无关系的商品会经常出现在同一个购物篮中,这种独特的销售现象引起了管理人员的注意,经过后续调查发现,这种现象出现在年轻的父亲身上。
在美国有婴儿的家庭中,一般是母亲在家中照看婴儿,年轻的父亲前去超市购买尿布父亲在购买尿布的同时,往往会顺便为自己购买啤酒,这样就会出现啤酒与尿布这两件看上去不相干的商品经常会出现在同一个购物篮的现象。假设规则
尿布 → 啤酒的指标如下:
- 支持度 = 0.3
- 置信度 = 0.75
- 提升度 = 1.5
- 杠杆率 = 0.1
- 确信度 = 2.0
分析:
- 支持度 0.3:满足常见阈值(如 0.1),规则具有一定普遍性;
- 置信度 0.75:较高,说明购买尿布时大概率会买啤酒;
- 提升度 1.5 > 1:确认尿布和啤酒存在正相关,非随机现象;
- 杠杆率 0.1 > 0:实际关联显著强于期望;
- 确信度 2.0 > 1:规则预测错误率低,稳定性好。
结论:该规则为有效关联,可用于实际推荐。
(3)局限性及应对
| 指标 | 局限性 | 应对策略 |
|---|---|---|
| 支持度(Support) | 可能忽略低频率但有价值的规则(如奢侈品组合)。 | 根据业务场景调整阈值,长尾场景适当降低支持度。 |
| 置信度(Confidence) | 受后件高频影响(如 A → 热门商品 置信度高但无意义)。 | 必须结合提升度验证。 |
| 提升度(Lift) | 对低频项敏感(提升度高但支持度极低)。 | 综合支持度筛选,避免过低的规则。 |
| 杠杆率(Leverage) | 对高频项敏感(如常见商品组合杠杆率高但提升度低)。 | 优先使用提升度,杠杆率作为补充。 |
| 确信度(Conviction) | 对置信度接近 1 的规则过于敏感(可能导致无穷大值)。 | 结合业务解释,避免过度依赖。 |
2.算法步骤
-
数据准备
- 数据格式:事务数据需转换为“项集”形式,每条事务包含一组项(如购物篮中的商品);
- 预处理:去除噪声、标准化项的名称,确保数据为布尔型(存在/不存在)。
-
生成频繁项集
- 核心目标:找到支持度(Support)≥ 最小阈值的所有项集;
- 常用算法:
- Apriori:通过逐层搜索和剪枝(利用“频繁项集的子集必频繁”的性质);
- FP-Growth:构建频繁模式树(FP-Tree),避免生成大量候选项集。
-
生成关联规则
- 规则形式:
X → Y(X为前件,Y为后件); - 关键指标:
- 支持度(Support):项集
X ∪ Y出现的频率; - 置信度(Confidence):在
X出现时Y也出现的概率,即Support(X∪Y)/Support(X); - 提升度(Lift):规则的有效性,
Lift = Confidence / Support(Y)(>1表示正相关); - 杠杆率(Leverage):衡量规则的显著性;
- 确信度(Conviction):衡量规则预测错误的程度;
- 支持度(Support):项集
- 生成方法:从频繁项集中提取所有可能的规则,并筛选满足最小置信度和提升度的规则。
- 规则形式:
-
规则评估与筛选
- 根据业务需求,选择高置信度、高提升度的规则,避免冗余和无关规则。
-
应用与解释
- 将规则应用于实际场景(如商品推荐、交叉销售)。
3.MATLAB 实现

%% 关联分析完整案例(自定义Apriori算法)
clc; clear;
%% 准备事务数据(示例数据)
% 定义10个事务,每个事务包含购买的商品
transactions = {
{'牛奶', '面包', '尿布'}, % 事务1
{'可乐', '面包', '啤酒', '鸡蛋'}, % 事务2
{'牛奶', '尿布', '啤酒', '可乐'}, % 事务3
{'面包', '牛奶', '尿布', '啤酒'}, % 事务4
{'面包', '牛奶', '尿布', '可乐'}, % 事务5
{'牛奶', '面包', '黄油'}, % 事务6
{'面包', '黄油'}, % 事务7
{'牛奶', '面包'}, % 事务8
{'牛奶', '面包', '黄油'}, % 事务9
{'面包', '黄油'} % 事务10
};
%% 数据预处理:转换为二进制矩阵
% 获取所有唯一商品项并按字母排序(保证后续操作一致性)
items = unique([transactions{:}]);
items = sort(items); % 按字母排序
numItems = length(items); % 商品总数
numTransactions = length(transactions); % 事务总数
% 创建二进制矩阵(行: 事务, 列: 商品)
binaryData = false(numTransactions, numItems);
for i = 1:numTransactions
% 使用ismember获取商品存在性(按排序后的items顺序)
binaryData(i, :) = ismember(items, transactions{i});
end
% 显示二进制矩阵
disp('二进制矩阵:');
disp(array2table(binaryData, 'VariableNames', items));
%% 自定义Apriori算法生成频繁项集
minSupport = 0.4; % 最小支持度阈值(40%的事务包含项集)
% 生成频繁项集和支持度
[freqItemsets, support] = apriori(binaryData, minSupport, items);
% 显示频繁项集
disp('频繁项集:');
for k = 1:length(freqItemsets)
if ~isempty(freqItemsets{k})
disp(['频繁', num2str(k), '-项集:']);
for i = 1:length(freqItemsets{k})
disp(items(freqItemsets{k}{i}));
end
end
end
%% 生成关联规则
minConfidence = 0.6; % 最小置信度阈值(60%的规则可信度)
rules = generateRules(freqItemsets, support, minConfidence, items);
% 显示所有关联规则
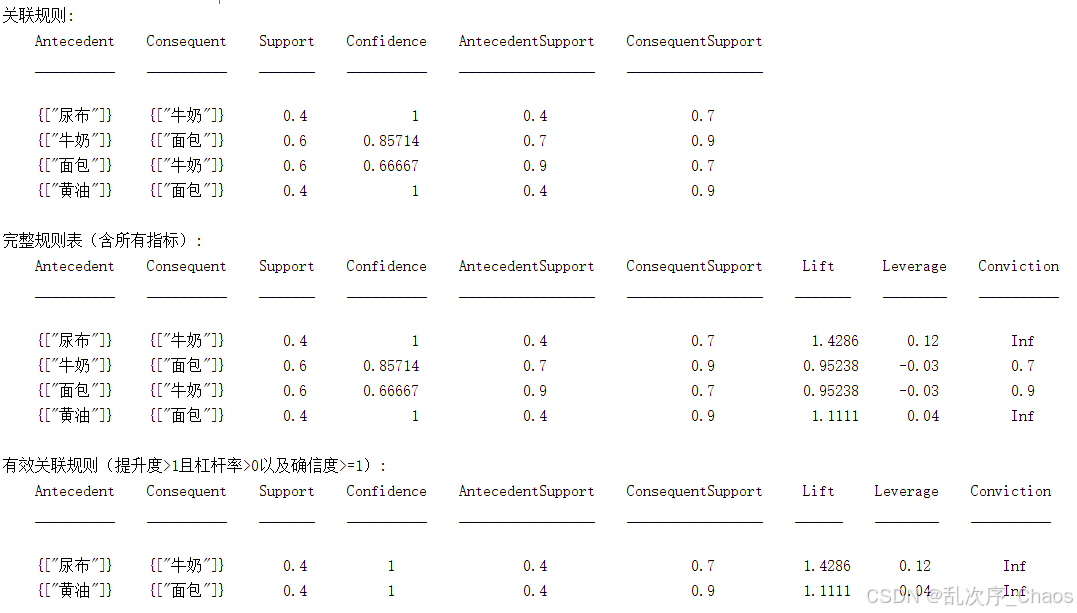
disp('关联规则:');
disp(rules);
%% 计算附加指标:提升度、杠杆率、确信度
if ~isempty(rules)
% 提取规则指标
antecedentSupport = rules.AntecedentSupport;
consequentSupport = rules.ConsequentSupport;
ruleSupport = rules.Support;
confidence = rules.Confidence;
% 计算提升度 Lift = Confidence / Support(Y)
lift = confidence ./ consequentSupport;
% 计算杠杆率 Leverage = Support(X∪Y) - Support(X)*Support(Y)
leverage = ruleSupport - (antecedentSupport .* consequentSupport);
% 计算确信度 Conviction = (1 - Support(Y)) / (1 - Confidence)
conviction = (1 - consequentSupport) ./ (1 - confidence);
conviction(confidence == 1) = Inf; % 处理除零情况
% 将指标添加到规则表中
rules.Lift = lift;
rules.Leverage = leverage;
rules.Conviction = conviction;
% 显示完整规则表
disp('完整规则表(含所有指标):');
disp(rules);
else
disp('未生成有效关联规则');
end
%% 筛选有效规则(提升度 > 1 且杠杆率 > 0 以及确信度 >= 1)
if ~isempty(rules)
validRules = rules(rules.Lift > 1 & rules.Leverage > 0 & rules.Conviction >= 1, :);
disp('有效关联规则(提升度>1且杠杆率>0以及确信度>=1):');
disp(validRules);
else
disp('无有效规则可筛选');
end
%% ================== 自定义函数 ==================
%% 自定义Apriori算法函数
function [freqItemsets, support] = apriori(binaryData, minSupport, items)
numTransactions = size(binaryData, 1);
numItems = size(binaryData, 2);
% 初始化频繁项集存储结构
freqItemsets = {}; % 元胞数组,每层存储不同长度的项集
support = []; % 支持度列表
% ---------------------------
% 生成频繁1-项集
% ---------------------------
k = 1;
freqItemsets{k} = {}; % 初始化
for i = 1:numItems
itemSupport = sum(binaryData(:, i)) / numTransactions;
if itemSupport >= minSupport
freqItemsets{k}{end+1} = [i]; % 存储商品索引
support = [support, itemSupport];
end
end
% ---------------------------
% 生成频繁k-项集(k >= 2)
% ---------------------------
k = 2;
while true
% 生成候选项集
candidates = generateCandidates(freqItemsets{k-1}, k);
if isempty(candidates), break; end
% 计算候选项集支持度
validCandidates = {};
candidateSupport = [];
for i = 1:length(candidates)
candidate = candidates{i};
% 检查所有k-1子集是否频繁(Apriori剪枝)
allSubsetsFrequent = true;
subsets = nchoosek(candidate, k-1); % 生成所有k-1子集
for s = 1:size(subsets, 1)
subset = subsets(s, :);
% 检查子集是否在上一层的频繁项集中
isFrequent = any(cellfun(@(x) isequal(x, subset), freqItemsets{k-1}));
if ~isFrequent
allSubsetsFrequent = false;
break;
end
end
% 若通过剪枝,计算支持度
if allSubsetsFrequent
sup = sum(all(binaryData(:, candidate), 2)) / numTransactions;
if sup >= minSupport
validCandidates{end+1} = candidate;
candidateSupport = [candidateSupport, sup];
end
end
end
% 存储结果
if ~isempty(validCandidates)
freqItemsets{k} = validCandidates;
support = [support, candidateSupport];
k = k + 1;
else
break;
end
end
end
%% 生成候选项集函数
function candidates = generateCandidates(prevFreqItemsets, k)
candidates = {};
numItemsets = length(prevFreqItemsets);
% 仅当k>1时执行合并操作
if k > 1
for i = 1:numItemsets
for j = i+1:numItemsets
% 合并两个项集(确保有序)
itemset1 = sort(prevFreqItemsets{i});
itemset2 = sort(prevFreqItemsets{j});
if isequal(itemset1(1:end-1), itemset2(1:end-1))
newCandidate = unique([itemset1, itemset2(end)]);
if length(newCandidate) == k
candidates{end+1} = sort(newCandidate);
end
end
end
end
% 去重
candidates = unique(cellfun(@mat2str, candidates, 'UniformOutput', false));
candidates = cellfun(@str2num, candidates, 'UniformOutput', false);
end
end
%% 生成关联规则函数
function rules = generateRules(freqItemsets, support, minConfidence, items)
rules = table();
if isempty(freqItemsets) || length(freqItemsets) < 2
return;
end
ruleIdx = 1;
% 遍历所有频繁项集(k >= 2)
for k = 2:length(freqItemsets)
if isempty(freqItemsets{k}), continue; end
for i = 1:length(freqItemsets{k})
itemset = freqItemsets{k}{i};
itemsetSupport = support(findCellIndex(freqItemsets, itemset)); % 查找支持度
% 生成所有可能的规则(X -> Y)
allAntecedents = nchoosek(itemset, k-1);
for a = 1:size(allAntecedents, 1)
antecedent = sort(allAntecedents(a, :));
consequent = sort(setdiff(itemset, antecedent));
% 查找antecedent的支持度
antecedentSupport = support(findCellIndex(freqItemsets, antecedent));
% 计算置信度
confidence = itemsetSupport / antecedentSupport;
% 筛选满足置信度的规则
if confidence >= minConfidence
rules.Antecedent{ruleIdx} = string(join(items(antecedent),','));
rules.Consequent{ruleIdx} = string(join(items(consequent),','));
rules.Support(ruleIdx) = itemsetSupport;
rules.Confidence(ruleIdx) = confidence;
rules.AntecedentSupport(ruleIdx) = antecedentSupport;
rules.ConsequentSupport(ruleIdx) = support(findCellIndex(freqItemsets, consequent));
ruleIdx = ruleIdx + 1;
end
end
end
end
end
%% 辅助函数:查找项集在freqItemsets中的索引
function idx = findCellIndex(freqItemsets, target)
target = sort(target);
for k = 1:length(freqItemsets)
if ~isempty(freqItemsets{k})
for i = 1:length(freqItemsets{k})
if isequal(sort(freqItemsets{k}{i}), target)
idx = i + sum(cellfun(@length, freqItemsets(1:k-1)));
return;
end
end
end
end
idx = 0; % 未找到
end
参考资料
[1] 通俗易懂讲算法-关联规则 哔哩哔哩 bilibili
[2] Python学习笔记关联规则(关联分析)python 关联分析-CSDN博客
[3] 【Oracle 公益课堂】OAC 购物篮分析_哔哩哔哩_bilibili