(三)K 邻近算法
K 近邻算法(KNN,K-Nearest Neighbors)是一种简单且直观的监督学习方法,可用于分类和回归任务。它的工作原理是基于距离度量来找到与待预测样本最接近的K个训练样本,并根据这些“邻居”的信息来进行预测。KNN 的特点:
- 非参数化方法:KNN 不假设数据服从任何特定的概率分布形式,因此适用于多种不同类型的数据集;
- 懒惰学习:KNN 在训练阶段不做太多工作,只是简单地存储训练样本;所有的计算都在预测时进行;
- 易于理解和实现:算法逻辑直接,容易上手。
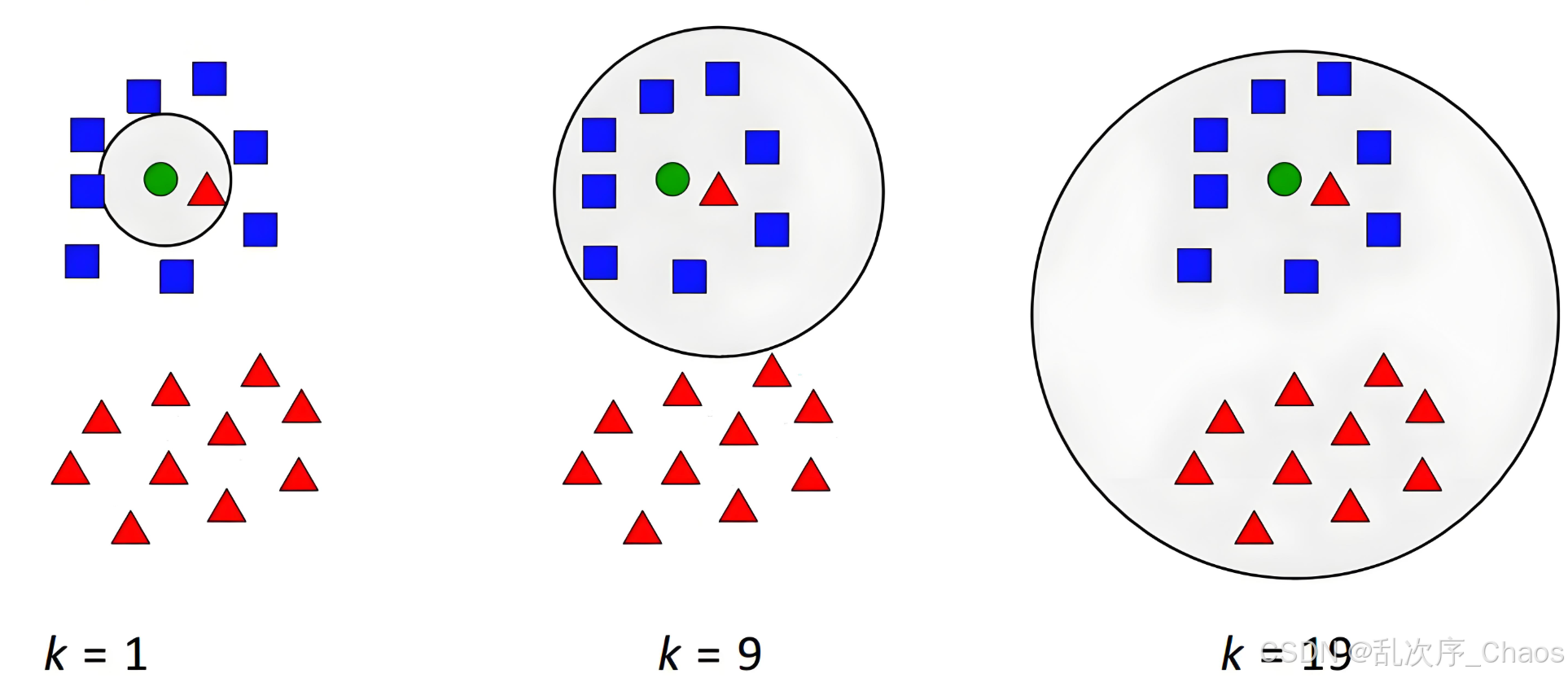
1.算法步骤
-
数据准备
- 目标:确保数据格式正确,划分为训练集和测试集;
- 关键步骤:
- 标准化:若特征量纲差异大,需标准化(如 Z-score)以避免距离计算偏差;
- 划分数据集:通常按比例(如 8:2)随机分割,避免过拟合。
-
计算距离
- 目标:量化测试样本与训练样本的相似性。
- 常用距离公式:
- 欧氏距离(默认): d = ∑ i = 1 n ( x i − y i ) 2 d=\sqrt{\sum_{i=1}^{n}(x_i-y_i)^2} d=i=1∑n(xi−yi)2
- 曼哈顿距离: d = ∑ i = 1 n ∣ x i − y i ∣ d=\sum_{i=1}^{n}\lvert x_i-y_i \lvert d=i=1∑n∣xi−yi∣
- 实现:对每个测试样本,计算与所有训练样本的距离。
-
排序与选择
- 目标:找到距离最近的 K 个样本;
- 操作:
- 对距离数组升序排序;
- 提取前 K 个样本的索引和标签。
-
投票决策
- 目标:根据 K 个最近邻的标签确定预测类别;
- 规则:多数表决(出现平票时可随机选择或加权投票)。
-
输出结果
- 返回测试样本的预测标签。
2. MATLAB 实现
某电商平台希望根据客户的 历史行为数据 将其分为 高价值、中价值、低价值 三类,以便差异化运营。数据特征包括:
- 最近购买天数(Recency)
- 过去一年购买次数(Frequency)
- 过去一年消费总额(Monetary)
- 平均浏览时长(分钟)
目标变量:客户价值标签( 0=低价值,1=中价值,2=高价值 )
%% K 邻近算法根据历史行为数据判断客户价值
clc; clear; close all;
%% 1. 生成模拟电商数据(修正标签逻辑)
rng(42);
num_customers = 1000;
% 生成特征数据(三类客户)
Recency = [abs(randn(300,1)*30 + 10); % 高价值客户(标签2)
abs(randn(400,1)*60 + 50); % 中价值客户(标签1)
abs(randn(300,1)*100 + 80)]; % 低价值客户(标签0)
Frequency = [abs(randn(300,1)*3 + 12);
abs(randn(400,1)*5 + 8);
abs(randn(300,1)*7 + 3)];
Monetary = [abs(randn(300,1)*0.3 + 2.5);
abs(randn(400,1)*0.5 + 1.5);
abs(randn(300,1)*0.8 + 0.5)];
BrowsingTime = [abs(randn(300,1)*5 + 20);
abs(randn(400,1)*8 + 15);
abs(randn(300,1)*10 + 5)];
% 合并特征并添加标签(三分类)
X = [Recency, Frequency, Monetary, BrowsingTime];
y = [2*ones(300,1); % 高价值(标签2)
ones(400,1); % 中价值(标签1)
zeros(300,1)]; % 低价值(标签0)
% 打乱数据顺序
shuffle_idx = randperm(num_customers);
X = X(shuffle_idx, :);
y = y(shuffle_idx);
%% 2. 数据标准化(强制标准化)
X_scaled = zscore(X);
%% 3. 划分训练集与测试集(80%训练,20%测试)
train_ratio = 0.8;
train_size = floor(train_ratio * num_customers);
X_train = X_scaled(1:train_size, :);
y_train = y(1:train_size);
X_test = X_scaled(train_size+1:end, :);
y_test = y(train_size+1:end);
%% 4. 手动实现KNN算法
K = 15; % 近邻数
distance_metric = 'euclidean'; % 距离度量
y_pred = zeros(size(y_test));
for i = 1:size(X_test,1)
% 计算距离(与所有训练样本)
if strcmp(distance_metric, 'euclidean')
distances = sqrt(sum((X_train - X_test(i,:)).^2, 2));
elseif strcmp(distance_metric, 'manhattan')
distances = sum(abs(X_train - X_test(i,:)), 2);
end
% 按距离排序并选择前K个
[~, sorted_idx] = sort(distances);
k_nearest_indices = sorted_idx(1:K);
% 投票决策(多数表决)
k_labels = y_train(k_nearest_indices);
[unique_labels, ~, label_counts] = unique(k_labels);
[max_count, max_idx] = max(histcounts(label_counts, length(unique_labels)));
y_pred(i) = unique_labels(max_idx);
end
%% 5. 模型评估
% 计算准确率
accuracy = sum(y_pred == y_test) / numel(y_test);
fprintf('模型准确率: %.2f%%\n', accuracy * 100);
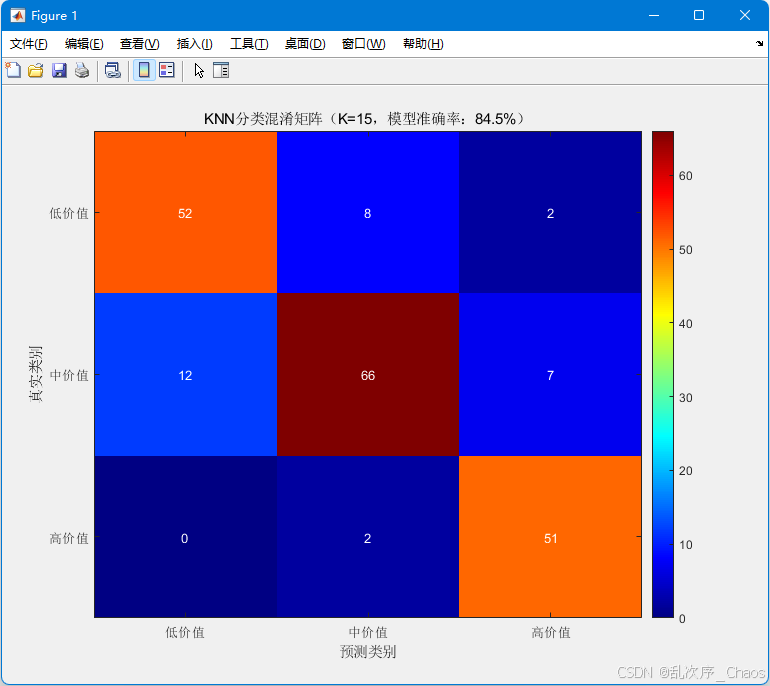
% 绘制混淆矩阵
classes = unique(y);
conf_mat = zeros(length(classes));
for i = 1:length(classes)
for j = 1:length(classes)
conf_mat(i,j) = sum(y_test == classes(i) & y_pred == classes(j));
end
end
% 可视化混淆矩阵
figure;
imagesc(conf_mat);
colormap(jet);
colorbar;
xticks(1:length(classes));
yticks(1:length(classes));
xticklabels({'低价值','中价值','高价值'});
yticklabels({'低价值','中价值','高价值'});
xlabel('预测类别');
ylabel('真实类别');
title(['KNN分类混淆矩阵(K=',num2str(K),',模型准确率:',num2str(accuracy * 100),'%)']);
% 添加数值标签
for i = 1:length(classes)
for j = 1:length(classes)
text(j, i, num2str(conf_mat(i,j)),...
'HorizontalAlignment', 'center',...
'Color', 'white');
end
end
参考资料
[1][5分钟学算法] #01 k近邻法_哔哩哔哩_bilibili
[2]【小萌五分钟】机器学习 | K近邻算法 KNN_哔哩哔哩_bilibili
[3]KNN简介_哔哩哔哩_bilibili