在人脸识别领域,常常有两个词容易被混淆,人脸验证和人脸识别。人脸验证是输入一个人的照片和名字(或者ID),验证这个人是否和名字相符。人脸识别是输入一个人的照片,识别这个人是否是数据库中存在的人。人脸验证问题是1:1问题,而人脸识别是1:K问题,假设K=100,也就是数据库有100个人,那么人脸识别就需要一一和数据库的照片进行相似度对比,即人脸识别的错误率是人脸验证的100倍。因此我们可以通过训练一个准确度很高的人脸验证系统,然后将其运用到人脸识别上,就能起到不错的效果。
要解决人脸验证问题,首先要解决One-Shot学习。
1.One-Shot学习
假设数据库只有4张照片,编号1是需要验证的照片,她和左列第二个人是同一个人,识别系统应该能认出来,但是编号2这个人不存在数据库中,系统应该识别不出来,那通常情况下,数据库中只保存一个人的一张照片,而不是多张,经验告诉我们,用一张照片作为训练集,训练的网络表现很差(欠拟合),如何用一个人的一张照片就可以训练出健壮的网络就是One-Shot学习的目的。

有一个好办法就是学习Similarity函数,定义函数d(),函数的两个参数是两张照片,计算两张照片之间的差异值,如果小于阈值就认为相似,也就是同一个人,如果大于阈值就认为不相似,也就是不是同一个人。通过让网络学习这个函数,输出差异值来判断是否是同一个人。

我们需要让新图片或需要识别的图片,依次和数据库的图片做对比,从而确定某个人是不是已经存在数据库中的人。这样做还有一个好处,在训练好的网络结构下,即使数据库新增某个人的照片,我们的识别系统依然可以正常工作。
2.Siamese 网络
要想实现相似度函数的学习,就需要用到Siamese网络网络:

这是一个普通的卷积神经网络,包含卷积层、池化层和全连接层等模块,一张图片输入进去,最后经过全连接层得到向量,假设向量是128长度,我们可以把这个向量看成提炼了特征的编码向量(前提一定是这个向量足够优秀,也就是能代表这个图片),记为f(x),x是输入样本。

这里我们需要对比两张照片,那就需要将两张照片输入相同的卷积神经网络(参数一样),得到两个照片的编码向量,然后计算相似度函数:
即计算编码之差的范数。而Siamese网络架构就是对于两个不同的输入,运行相同的卷积神经网络,然后比较它们。
我们前面提到,编码向量需要足够优秀,能代表这个图片。换句话说,我们需要训练同一个卷积网络,让网络输出的向量具有这样的特征:相似的照片(同一个人)他们的相似度d()尽可能小,编码向量的距离尽可能接近;不相似照片(不是同一个人)他们的相似度d()尽可能大,编码向量的距离尽可能远离。这样的编码向量才是优秀的。
了解了网络的输出和架构,那么应该如何定义损失函数来达到我们上述的目的?
3.Triplet 损失

Triplet 损失即三元组损失,需要我们提供一组图片,这组图片有三张,一张称为Anchor(用于作为其他图片的对比模版),一张称为Positive(这张和Anchor是同一个人,因此相似,用Positive代替),第三张称为Negative(这张和Anchor不是同一个人,因此不相似,用Negative代替),后面取首字母代替照片类别,即A、P、N。
现在用这三张照片构成两组对比,(A,P)和(A,N),我们希望d(A,P)值很小,因为他们是同一个人,而d(A,N)值很大,因为他们不是同一个人。因此有如下公式:
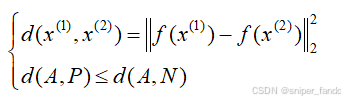
这个公式说明我们希望P与A更相似,N与A更不相似。但是如果网络训练的全是0编码向量,也满足关系式,此时没有意义。因此做如下改动:
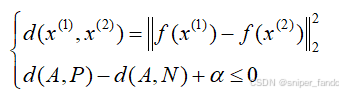
通过添加a(正数),来确保不会出现d(A,P)=d(A,N),从而也就避免了输出无意义的编码向量问题,同时也能确保输出更有区分度的编码向量。比如:d(A,P)=0.50,d(A,N)=0.51,这样虽然满足没有改动的关系式,但是区分度不高,明显他们都是比较相似的。通过添加a=0.2,此时编码向量的相似度就不满足关系式,从而网络会继续训练,得到更好的编码向量。
注意,我们需要把a作为超参数进行调试,一般不小于0.2。
有了上述分析,就可以给出损失函数:
如果出现d(A,P)-d(A,N)+a<=0,那么就说明满足关系式,我们可以认为此时识别正确了(已经能区分相似和不相似),因此损失值取max,输出为0。如果d(A,P)-d(A,N)+a>0,此时损失值就取该值,说明还有优化空间,继续梯度下降等优化算法减少损失,直到满足关系式。
整个网络的代价函数应该是训练集中这些单个三元组损失的总和。假如有一个10000个图片的训练集,里面是1000个不同的人的照片,我们要做的就是取这10000个图片,然后生成多个三元组,然后训练学习算法,对这种代价函数用梯度下降。
注意:1.三元组至少需要同一个人的两张不同照片以上,如果每一个人只有一张照片,那就无法组成三元组,也无法训练。2.选择三元组时,如果随机选择A、P和N,满足A和P是同一个人,A和N是不同人,那么就很容易满足关系式,网络也就无法学习到有用的信息。因此需要选择难以学习的三元组,即d(A,P)≈d(A,N),这样算法会尽力学习使d(A,P)更小,d(A,N)更大,从而学习到有用的信息。
4.人脸验证与二分类
除了使用Triplet 损失来学习网络的参数,还有一种方法也可以学习参数,主要思路就是将网络改造成二分类网络,我们来一起看看:
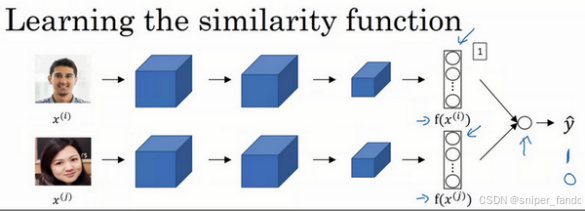
还是采用Siamese网络架构,输入两张照片,然后把输出的编码向量输入到logistics回归单元,如果是相同的人,输出1,否则输出0,从而转化为二分类问题。下面给出逻辑回归单元的细节:
假设编码向量为128长度,上述公式把每个元素看成一个单元,通过取编码向量差的绝对值和权重w、偏差b线性组合,并经过激活函数比如sigmoid函数,得到二分类的输出。其中对于编码向量差的绝对值还可以替换成卡方相似度:
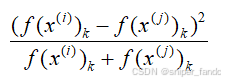
注意:
细节1:Siamese网络架构决定上下两个卷积网络的参数相同。
细节2:假设第一张图片是数据库存在的图片,第二张图片是新图片,那么不需要每次都计算第一张图片的编码向量,这样会浪费计算资源。可以将存在数据库的图片预计算编码向量并存储,需要时直接读取编码向量即可。