温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
PySpark+大模型 Bilibili弹幕情感分析
摘要
随着互联网的发展,视频弹幕网站如Bilibili(简称B站)已成为年轻人特别是二次元文化爱好者的聚集地。弹幕作为B站独特的用户互动方式,不仅提升了观看的互动性,还反映了观众的即时情感和态度。本文旨在开发一个基于PySpark和大模型(如BERT)的Bilibili弹幕情感分析系统,通过先进的自然语言处理(NLP)技术和大规模数据处理框架,实现对弹幕数据的情感分类和情感趋势的可视化展示。该系统将帮助内容创作者和平台运营者更好地理解观众反馈,优化内容策略和用户体验。
引言
弹幕起源于日本,现已在中国广泛应用于各大视频分享平台。B站以其独特的弹幕评论功能和丰富的视频内容深受用户喜爱。弹幕数据作为用户实时反馈的重要来源,包含了丰富的情感信息和用户偏好。然而,传统的情感分析方法在处理这类海量、实时的文本数据时面临诸多挑战。PySpark作为一个强大的分布式数据处理框架,结合大模型(如BERT)的自然语言处理能力,能够实现对弹幕数据的高效处理和实时分析。
研究背景与意义
弹幕数据的特点
- 数据量大:B站的弹幕数据具有海量特点,需要高效的数据处理框架。
- 实时性强:弹幕数据是实时生成的,需要实时分析。
- 语言表达丰富多样:弹幕中的语言表达具有多样性,包含丰富的情感信息。
情感分析的重要性
- 提升数据分析能力:通过实时情感分析,帮助内容创作者和平台运营者更好地理解观众反馈。
- 提供决策支持:为视频平台提供数据支持,帮助其及时发现和应对潜在的舆情危机。
- 推动技术应用:探索Python在弹幕数据分析中的应用,为相关领域的技术应用提供示范和参考。
系统设计
系统架构
本系统基于PySpark和大模型(如BERT)的Bilibili弹幕情感分析系统,主要包括以下几个模块:
- 数据抓取与处理:设计并实现弹幕数据的实时抓取和预处理模块,获取和整理用户生成的弹幕内容。
- 情感分析:通过自然语言处理技术和情感分析模型,对弹幕数据进行情感分类和情绪分析。
- 结果展示与应用:使用Flask构建Web应用,展示弹幕情感分析结果,包括情感趋势图、实时情感分布等功能。
技术路线
- 数据抓取:利用Python的爬虫库(如Scrapy、requests)和弹幕协议(如WebSocket)从B站实时抓取弹幕数据。
- 数据预处理:在PySpark环境下进行数据清洗和处理,包括去除无效数据、去重、处理缺失值以及文本规范化(如去除特殊字符、统一格式等)。
- 文本处理:使用PySpark的文本处理功能对弹幕进行分词、去除停用词、词性标注等操作。
- 情感分析模型:应用大模型(如BERT)对弹幕进行情感评分和分类,分析观众的情感倾向(如正面、负面、中性)。
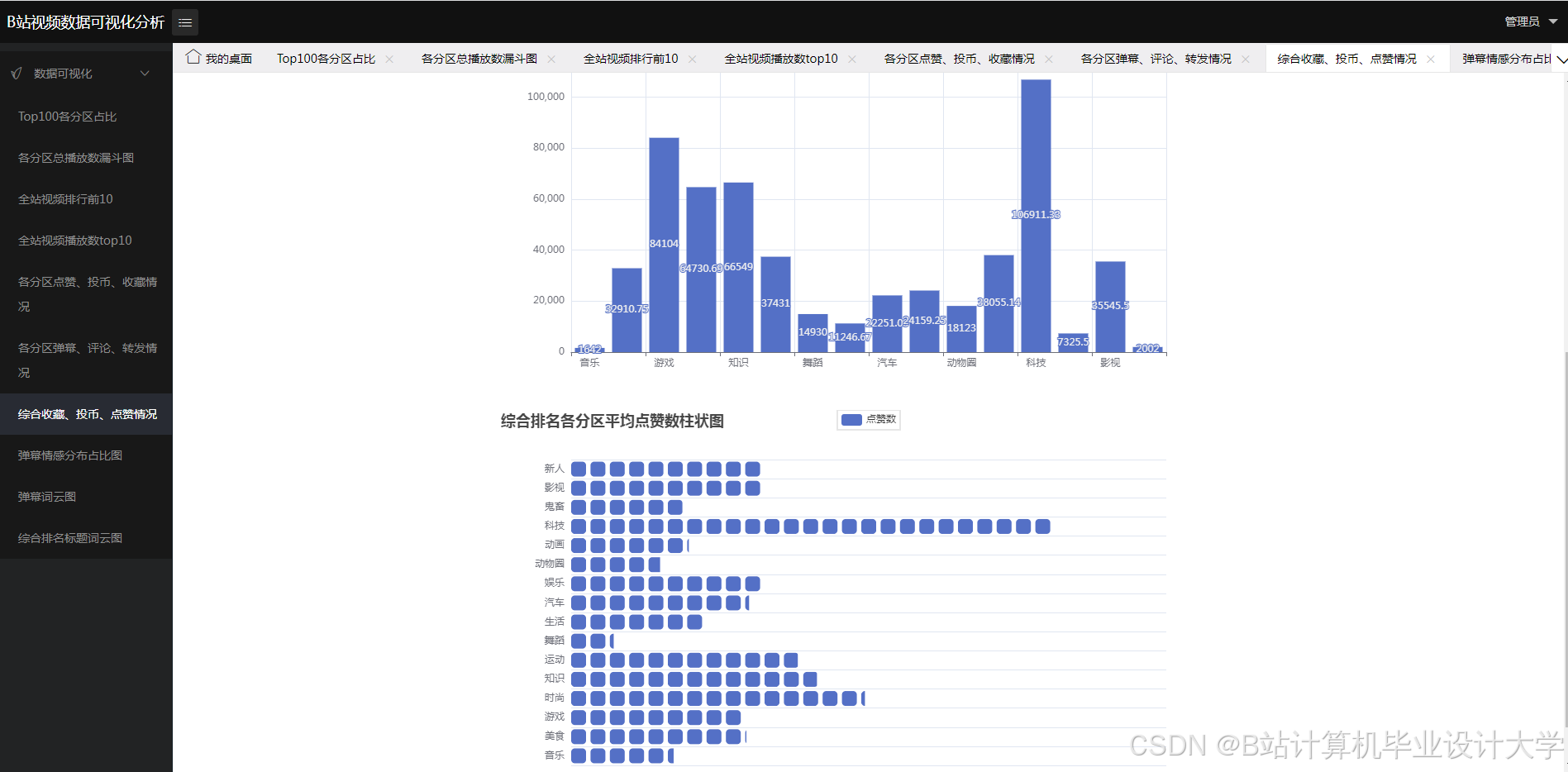
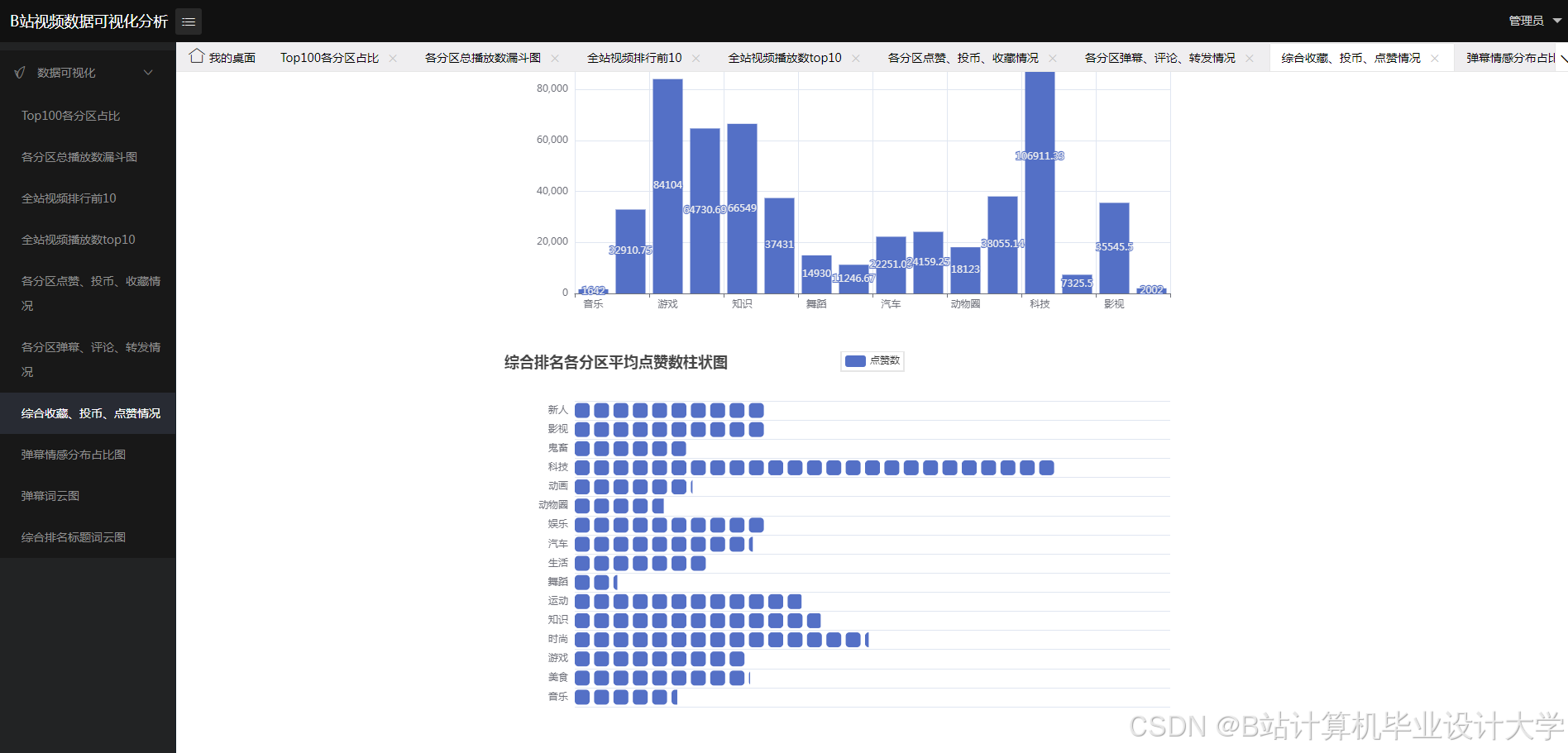
- 情感趋势分析:统计和分析不同时间段、视频内容或事件下的情感变化趋势,生成情感趋势图和情感分布图。
- Web应用开发:使用Flask开发Web应用,设计用户交互界面和数据展示模块,实现实时弹幕展示和情感分析结果的可视化展示。
- 数据可视化:利用数据可视化库(如Matplotlib、Plotly)展示分析结果。
系统实现
数据抓取
通过Python的爬虫库(如Scrapy、requests)和B站的API接口获取弹幕数据。弹幕数据的文档链接构成为https://comment.bilibili.com/cid.xml,其中cid为视频的唯一标识符。
数据预处理
在PySpark环境下进行数据清洗和预处理,包括去除无效数据、去重、处理缺失值以及文本规范化。例如,去除特殊字符、统一格式等。
文本处理
使用PySpark的文本处理功能对弹幕进行分词、去除停用词、词性标注等操作。可以使用Python的自然语言处理库(如NLTK、spaCy)进行文本处理。
情感分析模型
应用大模型(如BERT)对弹幕进行情感评分和分类。BERT是一种基于Transformer的预训练语言表示模型,能够捕捉文本中的复杂语义关系,提高情感分析的准确性。
情感趋势分析
统计和分析不同时间段、视频内容或事件下的情感变化趋势,生成情感趋势图和情感分布图。通过PySpark的分布式计算能力,实现对大规模弹幕数据的实时情感趋势分析。
Web应用开发
使用Flask开发Web应用,设计用户交互界面和数据展示模块。实现实时弹幕展示和情感分析结果的可视化展示,包括情感趋势图、情感分布图等。
数据可视化
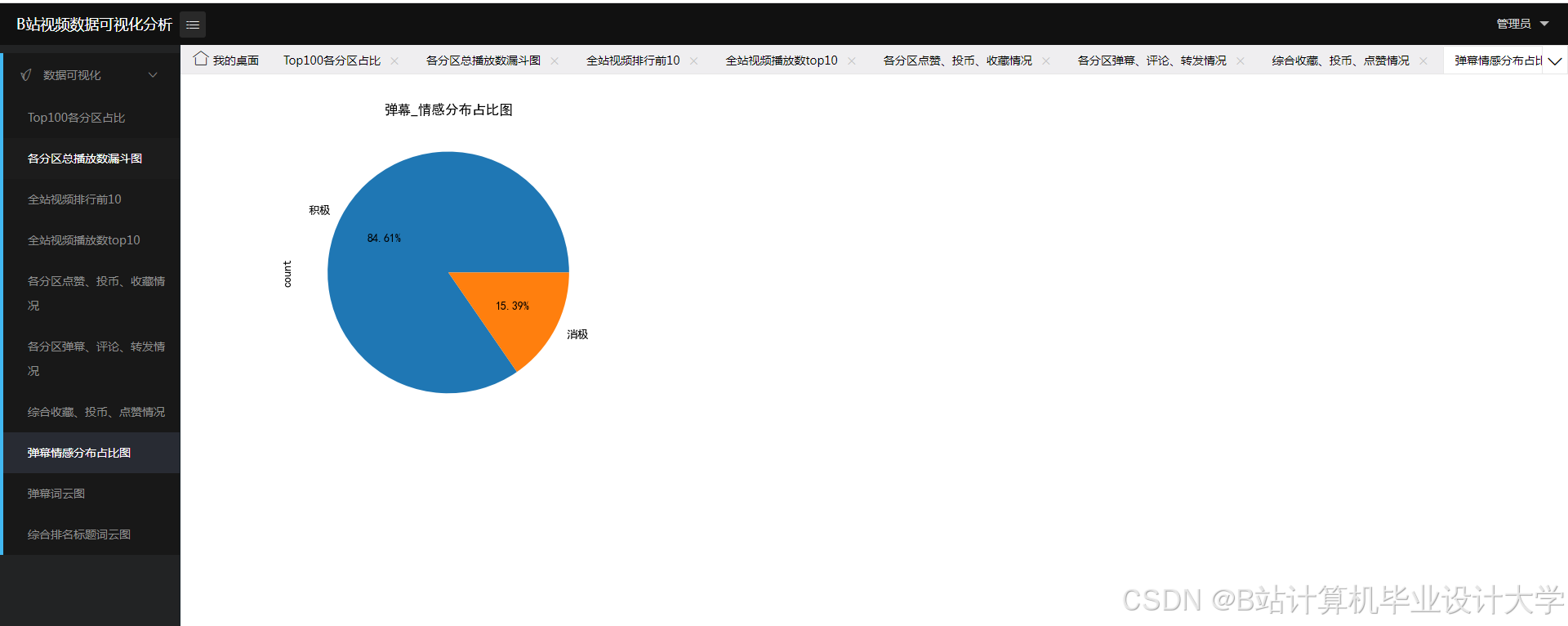
利用数据可视化库(如Matplotlib、Plotly)展示分析结果。通过数据可视化,可以更直观地了解观众的情感倾向和情感变化趋势。
实验结果与分析
情感分析结果
通过大模型(如BERT)对弹幕进行情感分析,得到每个弹幕的情感倾向(正面、负面、中性)和情感评分。根据情感评分,可以绘制情感分布图和情感趋势图。
系统性能评估
通过实际的B站弹幕数据案例,评估系统的性能和应用效果。分析系统在实际应用中的价值,包括数据处理效率、情感分析准确性、用户交互体验等方面。
结论与展望
本文开发了一个基于PySpark和大模型的Bilibili弹幕情感分析系统,实现了对弹幕数据的实时情感分析和可视化展示。该系统能够帮助内容创作者和平台运营者更好地理解观众反馈,优化内容策略和用户体验。未来,可以进一步优化系统性能,提高情感分析的准确性,并探索更多应用场景。
参考文献
- Aggarwal, C. C., & Zhai, C. (2012). Mining Text Data. Springer.
- Bird, S., Klein, E., & Loper, E. (2009). Natural Language Processing with Python. O'Reilly Media.
- Chen, J., & Li, X. (2020). "Real-time Big Data Processing with Apache Spark: Challenges and Opportunities." Journal of Cloud Computing, 9(1), 1-20.
- Flask Documentation. (2024). Retrieved from Welcome to Flask — Flask Documentation (3.0.x)
- Gonzalez, R. C., Woods, R. E., & Eddins, S. L. (2017). Digital Image Processing Using MATLAB. CRC Press.
- Liu, B. (2015). Sentiment Analysis: Mining Opinions, Sentiments, and Emotions. Cambridge University Press.
- Zhang, L., & Zhao, J. (2018). "Sentiment Analysis of Online Comments: A Comparative Study of Traditional and Deep Learning Methods." Journal of Computer Science and Technology, 33(3), 463-477.
- B站弹幕协议文档. (2024). Retrieved from https://github.com/clangcn/bilibili-danmaku
- Apache Spark Documentation. (2024). Retrieved from Overview - Spark 3.5.3 Documentation
本文详细阐述了基于PySpark和大模型的Bilibili弹幕情感分析系统的研究背景、系统设计、系统实现、实验结果与分析以及结论与展望,旨在通过先进的数据处理和自然语言处理技术,实现对弹幕数据的高效分析和实时展示,为相关领域提供有价值的参考和实践经验。
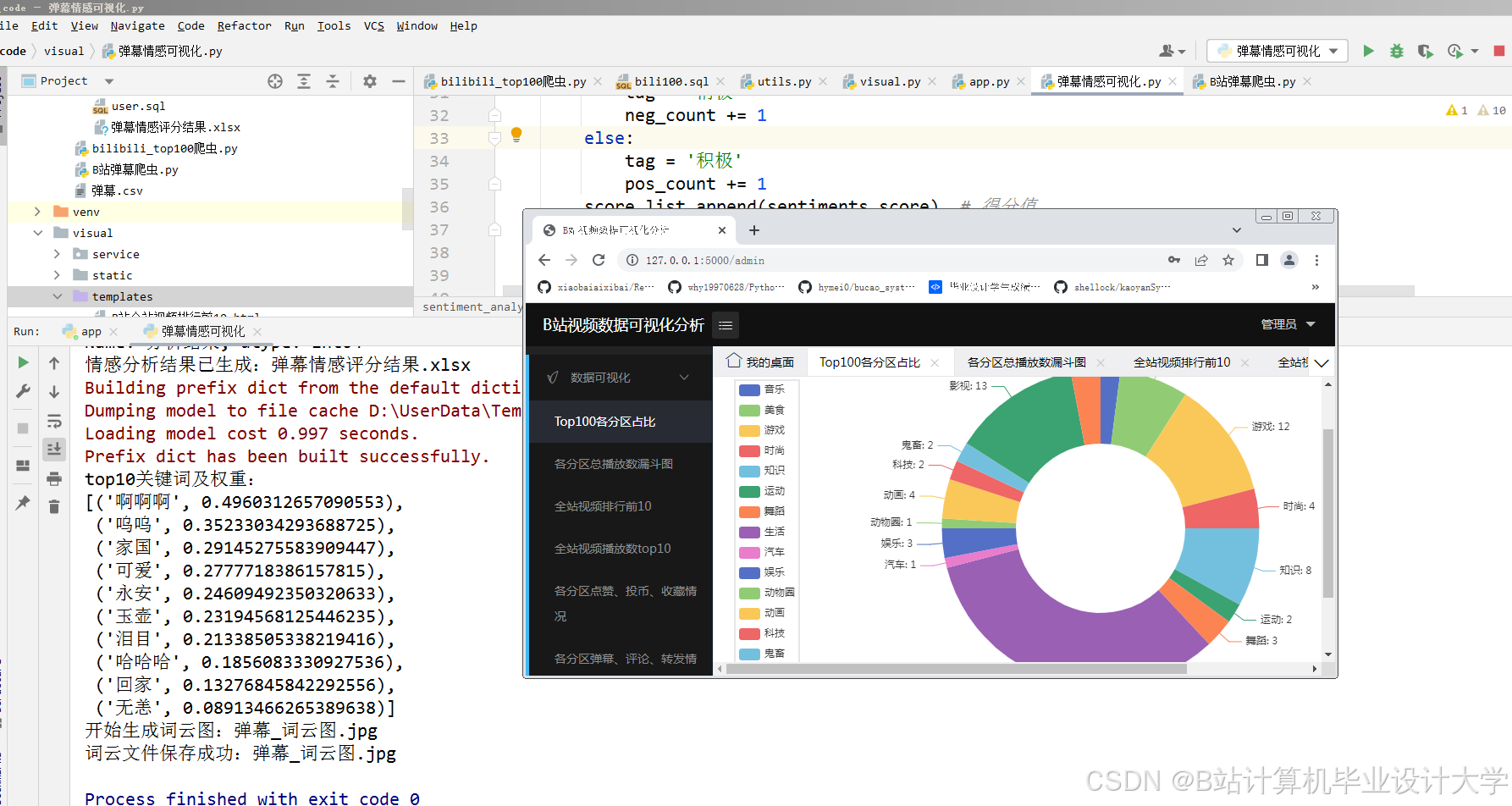

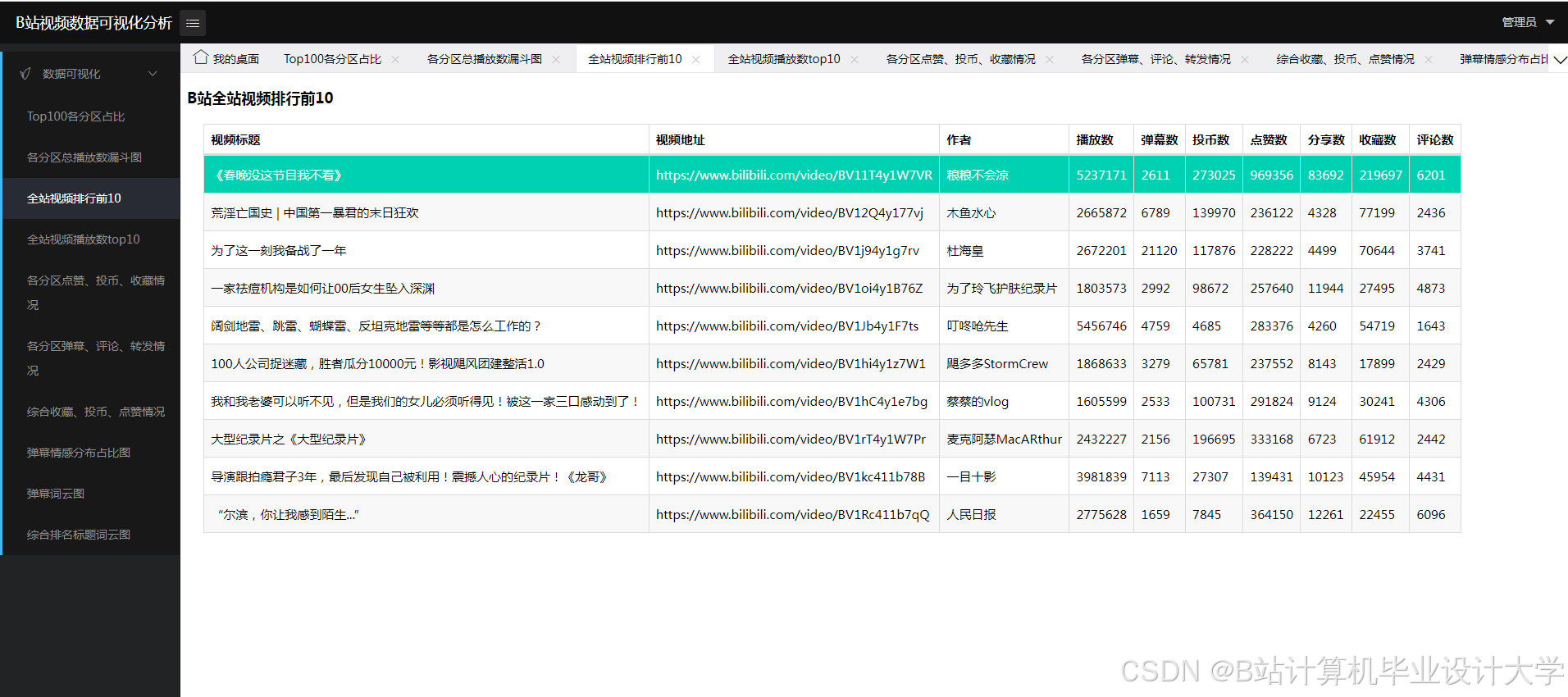
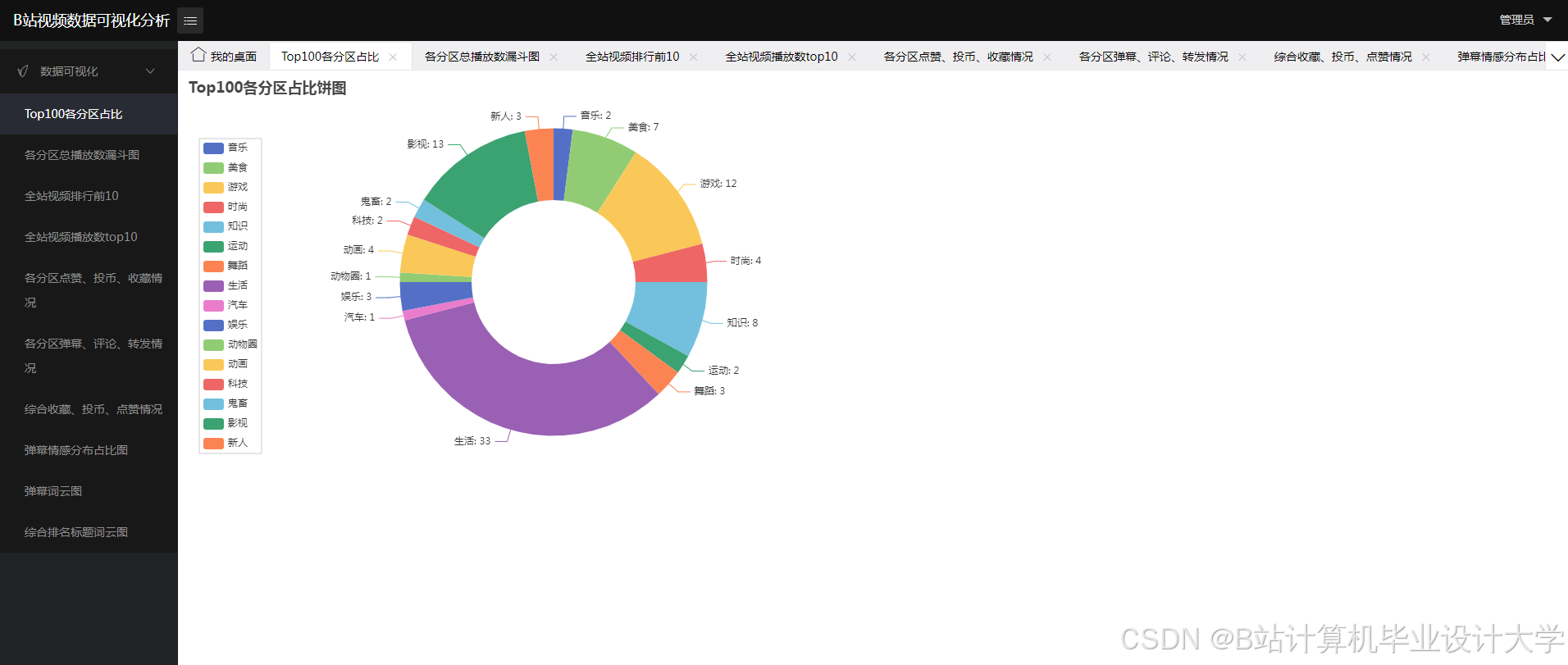
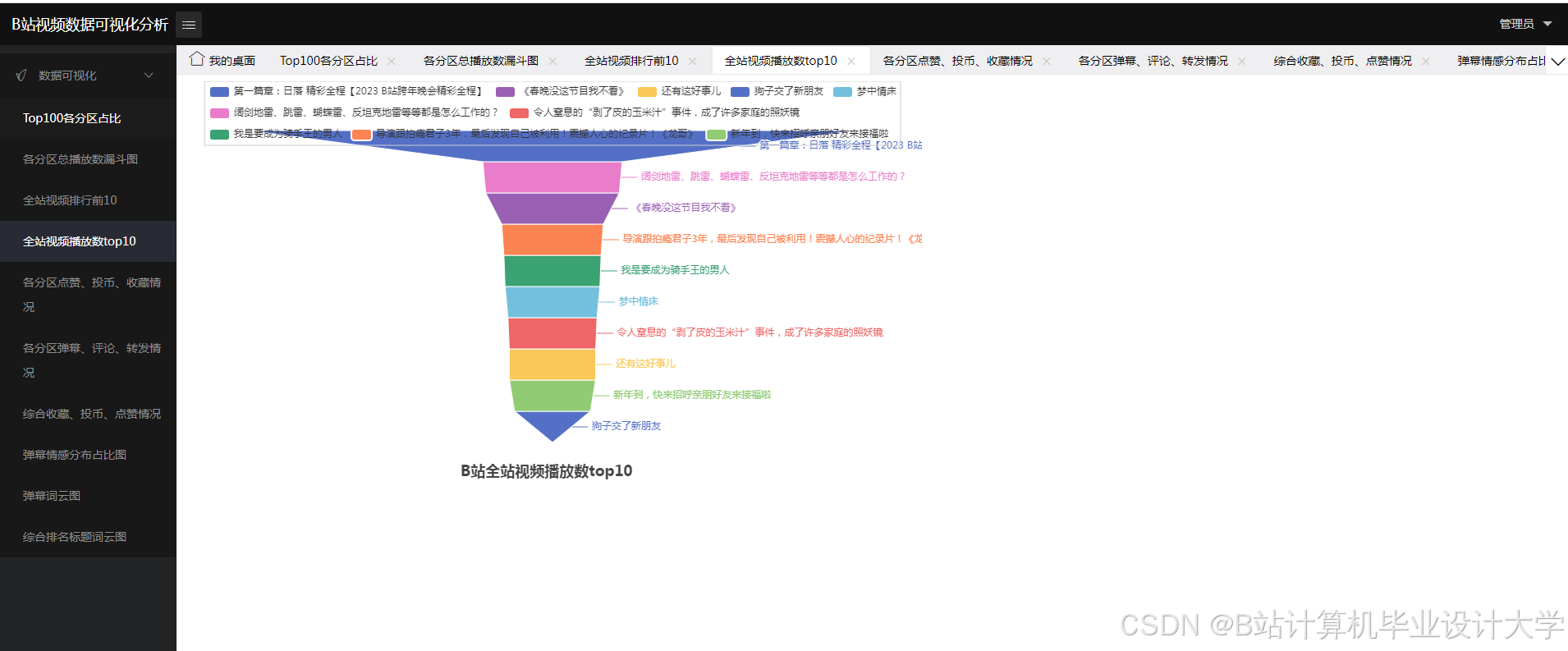
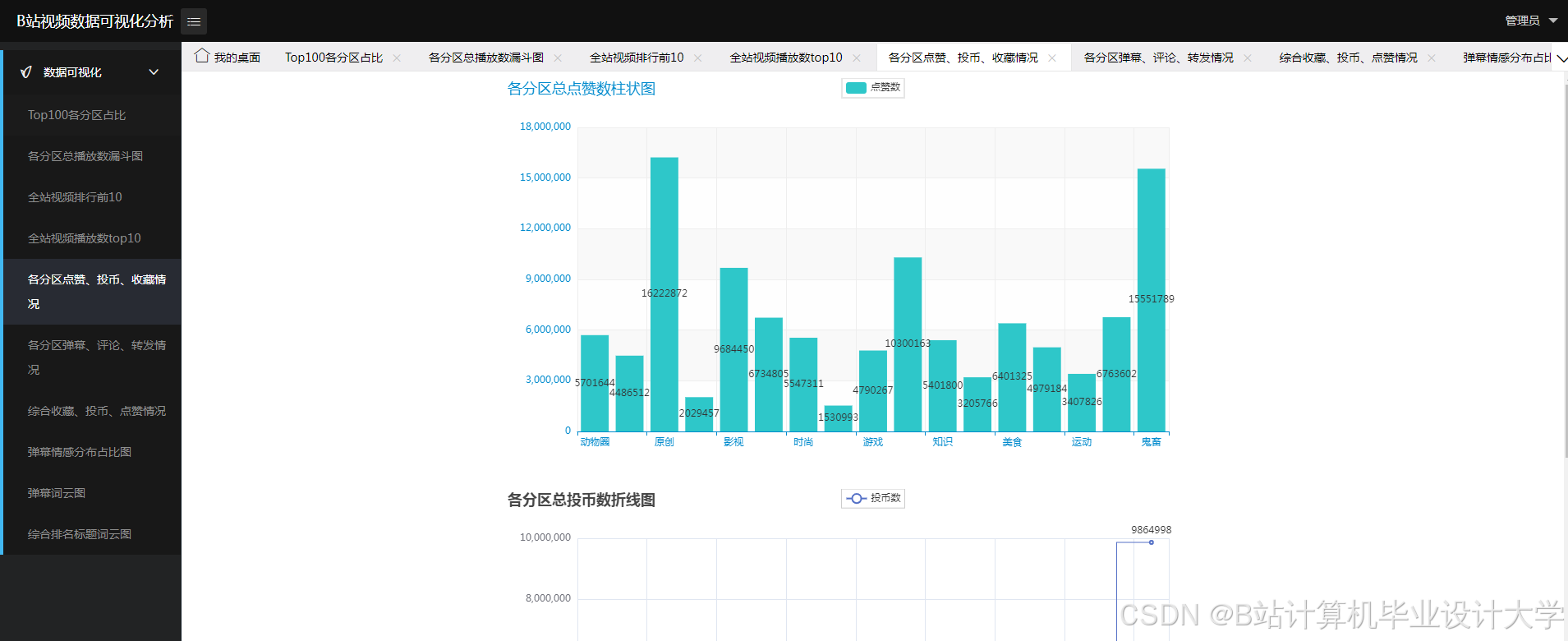
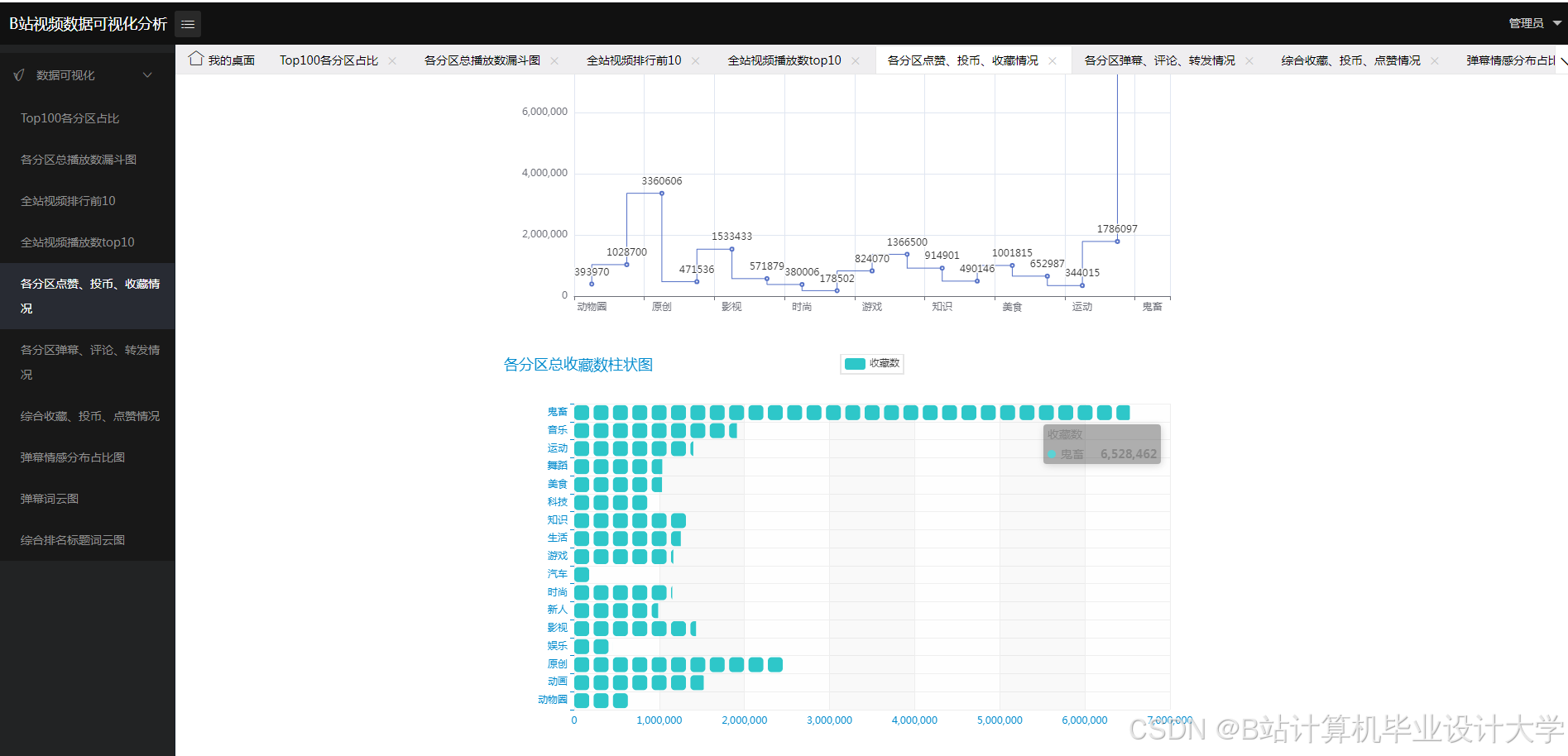
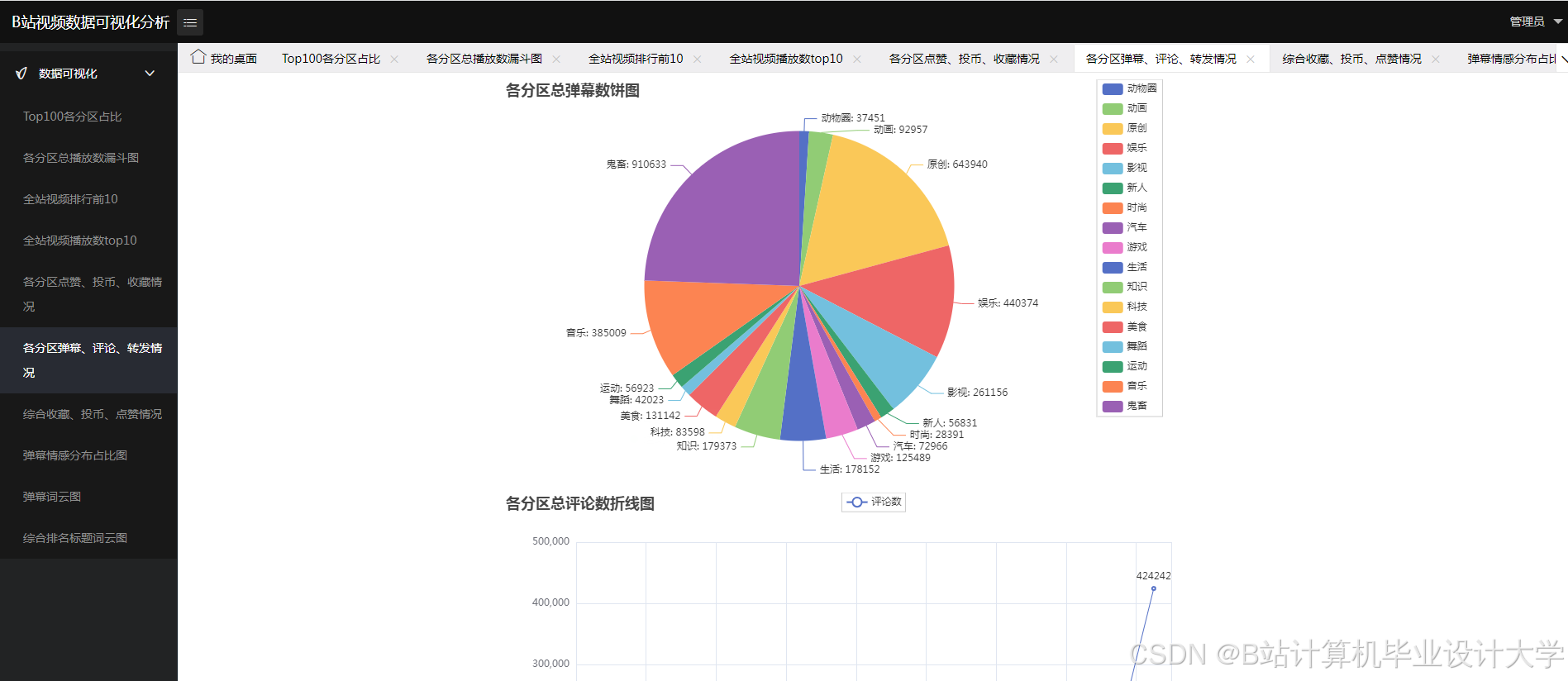
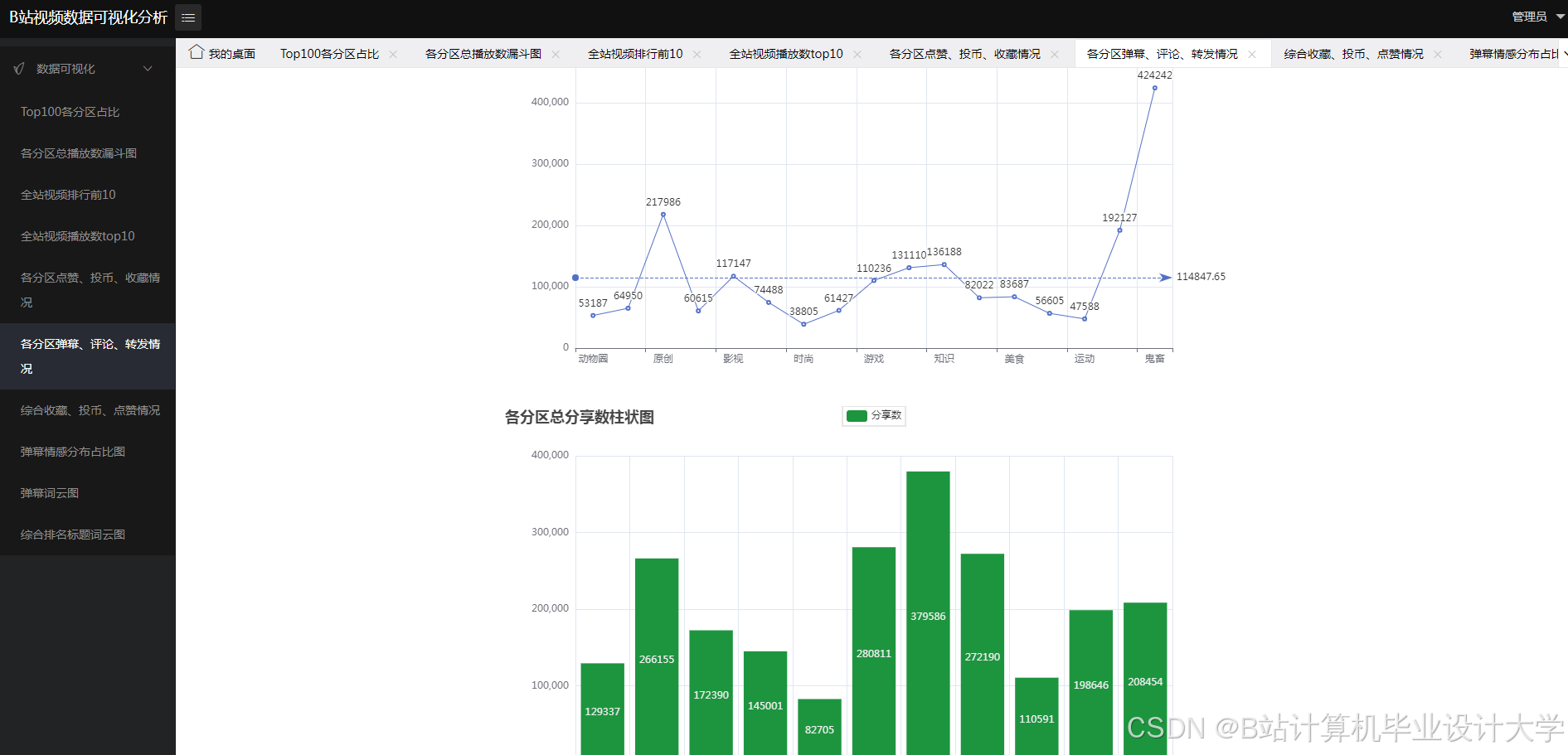
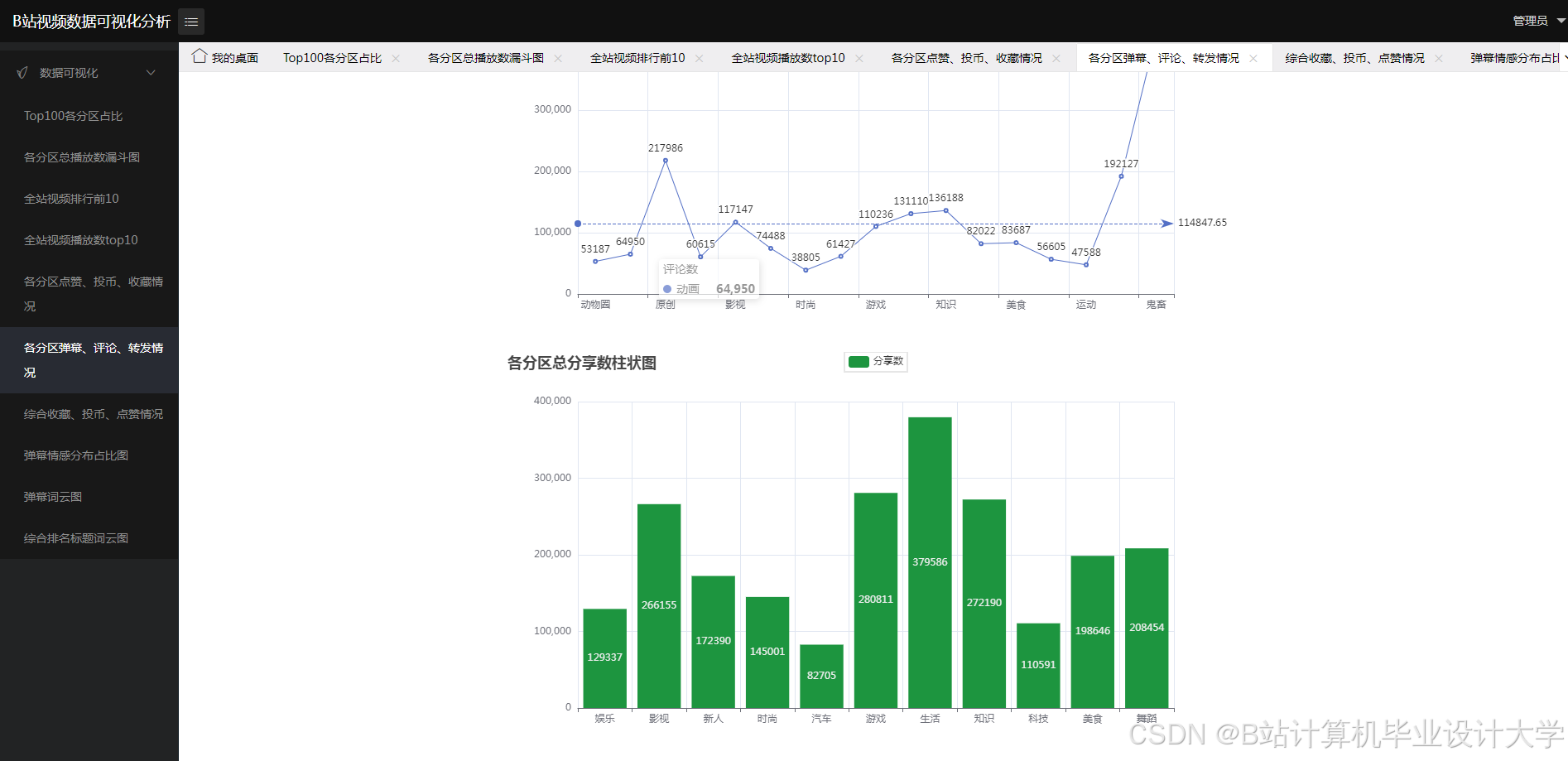
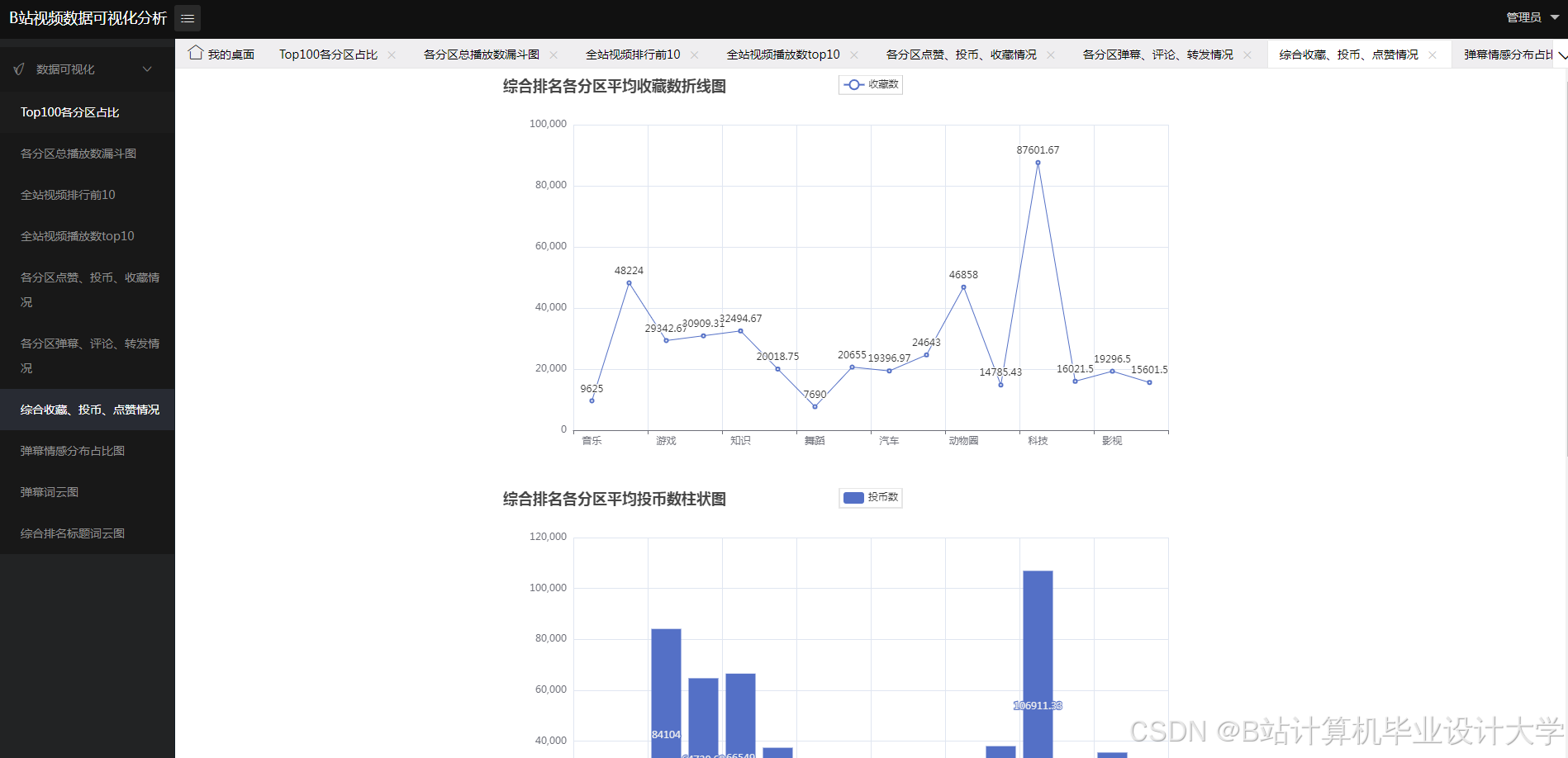


核心算法代码分享如下:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.utils import to_categorical
# 假设我们有一个CSV文件包含流量数据
# 数据格式:时间戳, 源IP, 目标IP, 源端口, 目标端口, 协议, 数据包长度, 数据包数量, 标签(0表示正常,1表示恶意)
data_path = 'traffic_data.csv'
# 读取数据
df = pd.read_csv(data_path)
# 特征选择(排除时间戳和IP地址)
features = ['source_port', 'destination_port', 'protocol', 'packet_length', 'packet_count']
X = df[features].values
y = df['label'].values
# 数据预处理
# 将协议从文本转换为数值(假设协议只有TCP, UDP, ICMP三种)
protocol_mapping = {'TCP': 0, 'UDP': 1, 'ICMP': 2}
X[:, 2] = [protocol_mapping[protocol] for protocol in df['protocol'].values]
# 数据标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 将标签转换为one-hot编码
y = to_categorical(y)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建模型
model = Sequential()
model.add(Dense(64, input_dim=X_train.shape[1], activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(y_train.shape[1], activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=50, batch_size=32, validation_split=0.2)
# 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print(f'Test Accuracy: {accuracy:.4f}')
# 使用模型进行预测(示例)
sample_data = np.array([[1234, 80, 0, 500, 10]]) # 示例数据(需先经过同样的预处理)
sample_data = scaler.transform(sample_data)
prediction = model.predict(sample_data)
predicted_class = np.argmax(prediction)
print(f'Predicted Class: {predicted_class} (0: Normal, 1: Malicious)')