一、运行前准备
code:
paper:
https://arxiv.org/pdf/2107.08430.pdf
torch2trt:
https://github.com/NVIDIA-AI-IOT/torch2trt/releases
在使用命令行进行操作的时候需要在tools/demo.py和tools/train.py中加上
import sys,os
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(BASE_DIR)此处 需要更改yolox_s.pth,模型下载地址:yolox_s.pth
建立weights文件夹将下载的yolox_s.pth放到weights文件夹下
python tools/demo.py video -n yolox-s -c weights/yolox_s.pth --path 0 --conf 0.25 --nms 0.45 --tsize 640 --save_result --device gpu(缺少什么包直接安装)
demo测试结果

二、训练注意事项:
1.准备VOC数据集
1.将VOC数据放到datasets文件夹下(如果是自己标注的数据改成VOC格式就可以了)
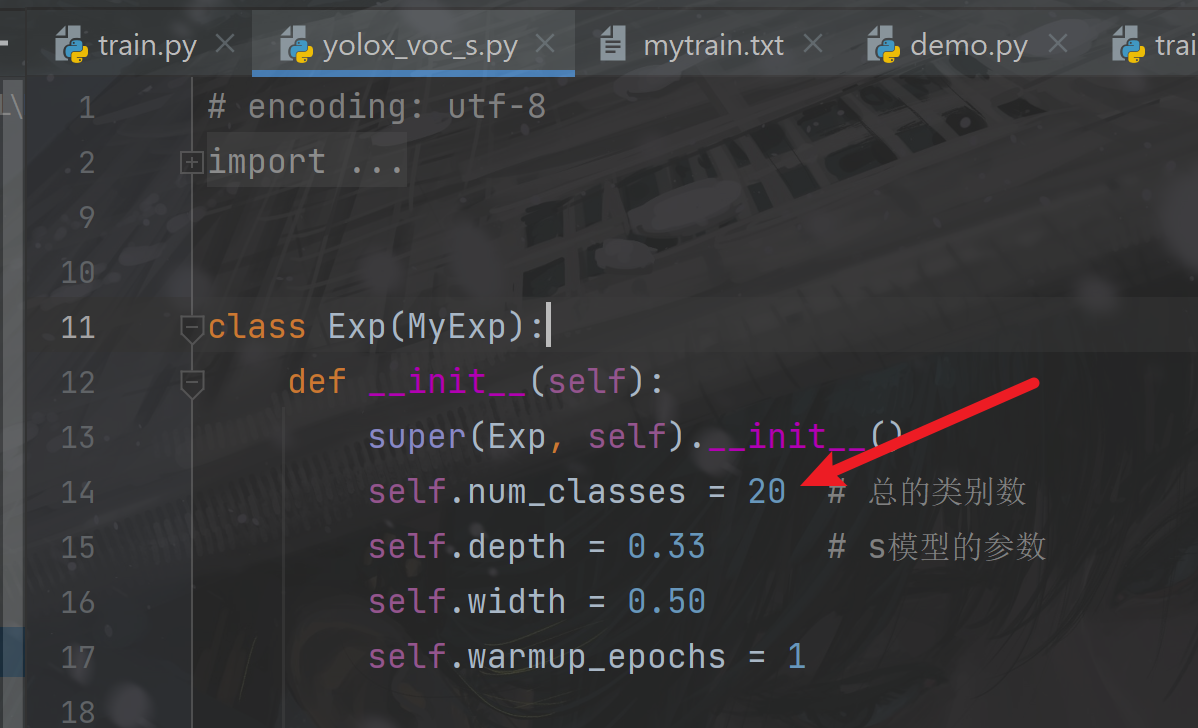
2.调整训练的类别数
VOC数据的默认类别是20个,如果是自己的数据集,则调整exps/example/yolox_voc/yolox_voc_s.py下的类别数
3.调整代码
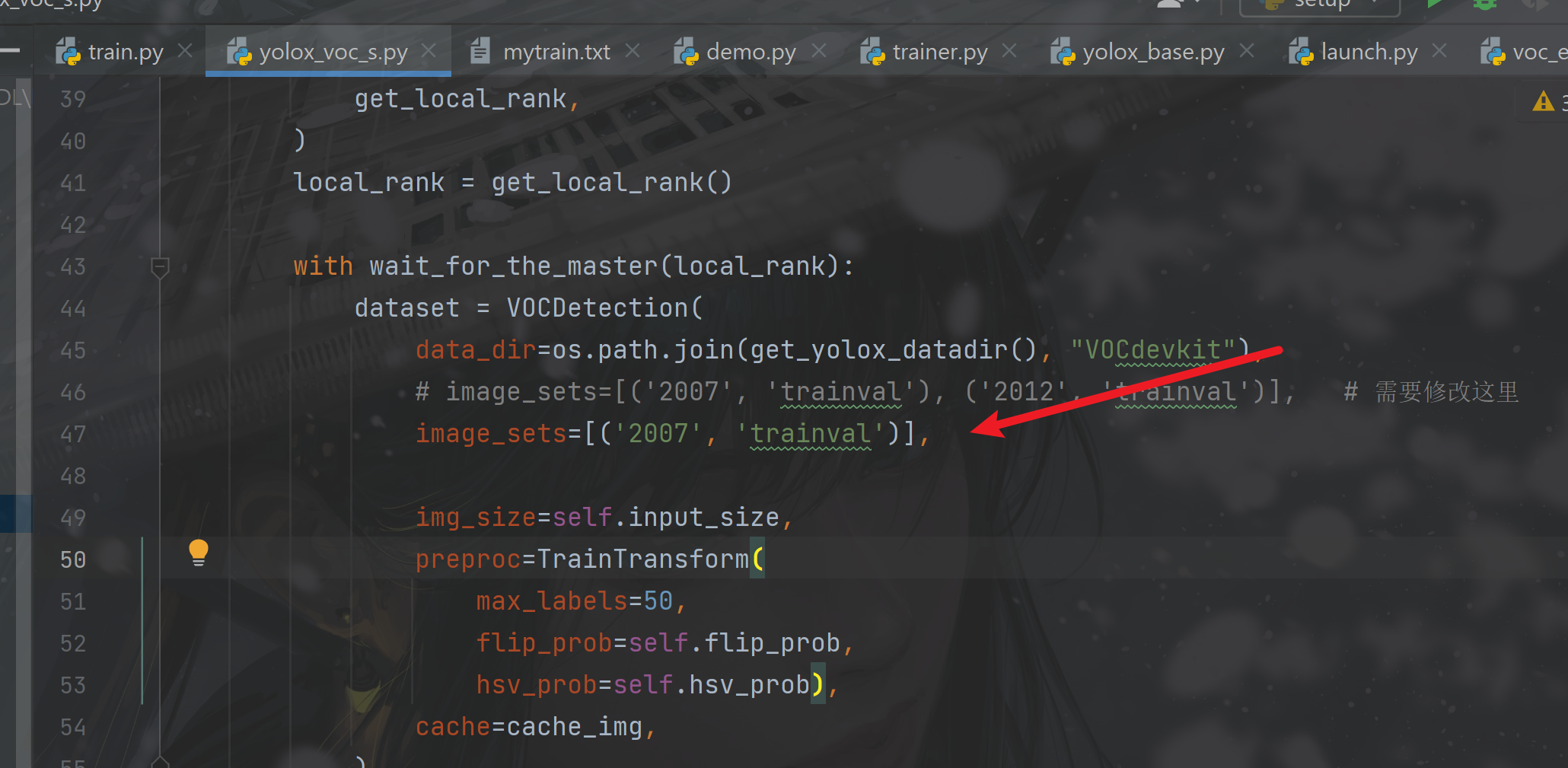
(1)更改exps/example/yolox_voc/yolox_voc_s.py下的image_sets
删除2012的目录,改为图中47行
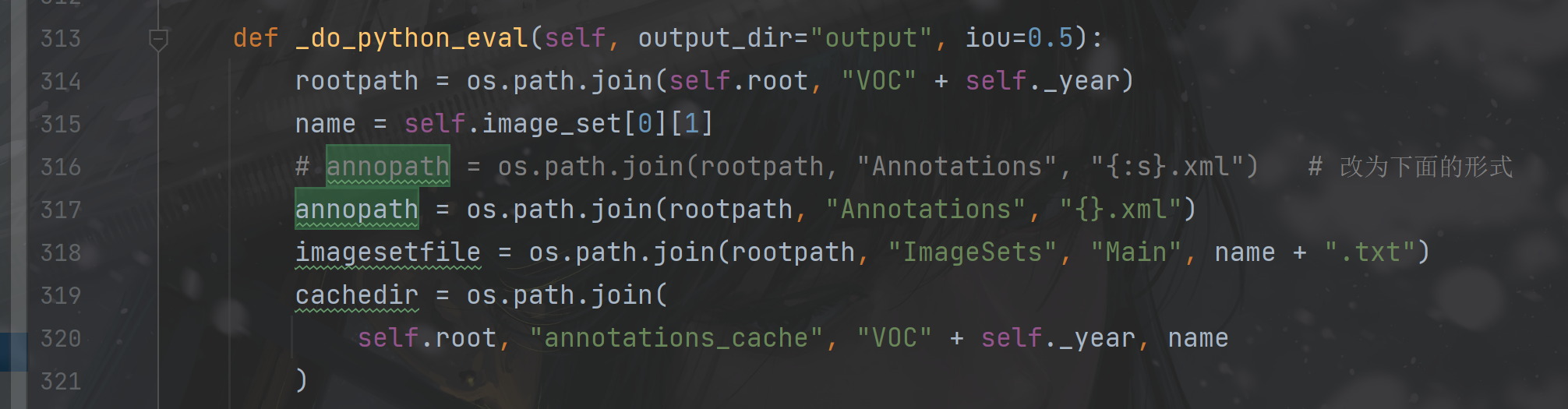
(2)更改yolox/data/datasets/voc.py的do_python_eval
更改为317行的格式
4.训练指令
从零开始训练:
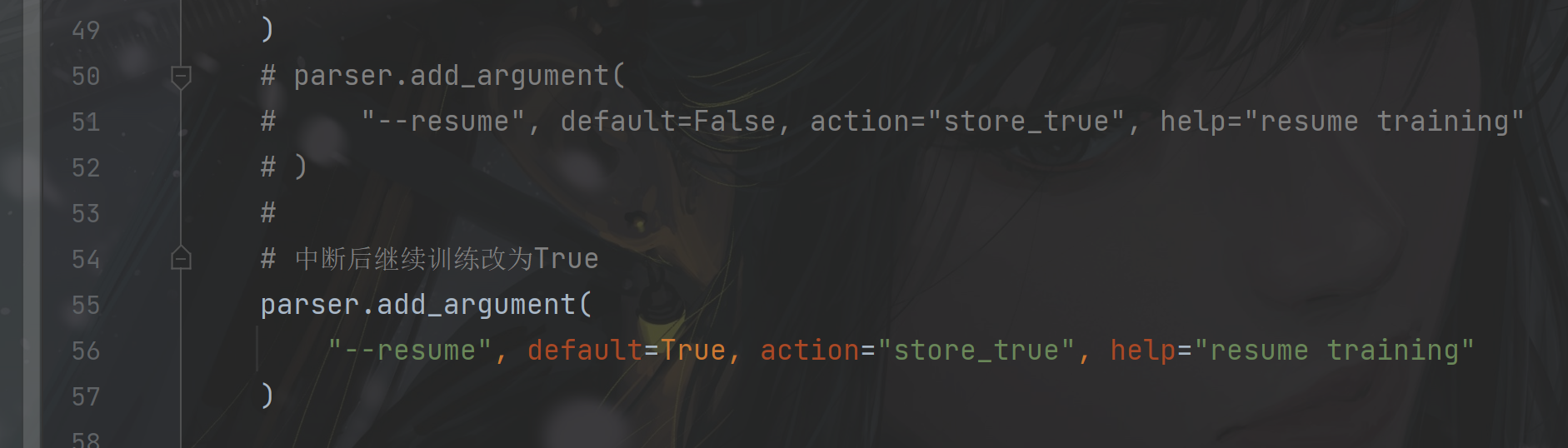
python tools/train.py -f exps/example/yolox_voc/yolox_voc_s.py -d 1 -b 24 --fp16中断后继续训练:
将tools/train.py中的训练参数--resume默认值改为True或者在命令行中加入--resume True
参数保存在YOLOX_outputs文件夹下:
三、测试注意事项:
1.更改代码
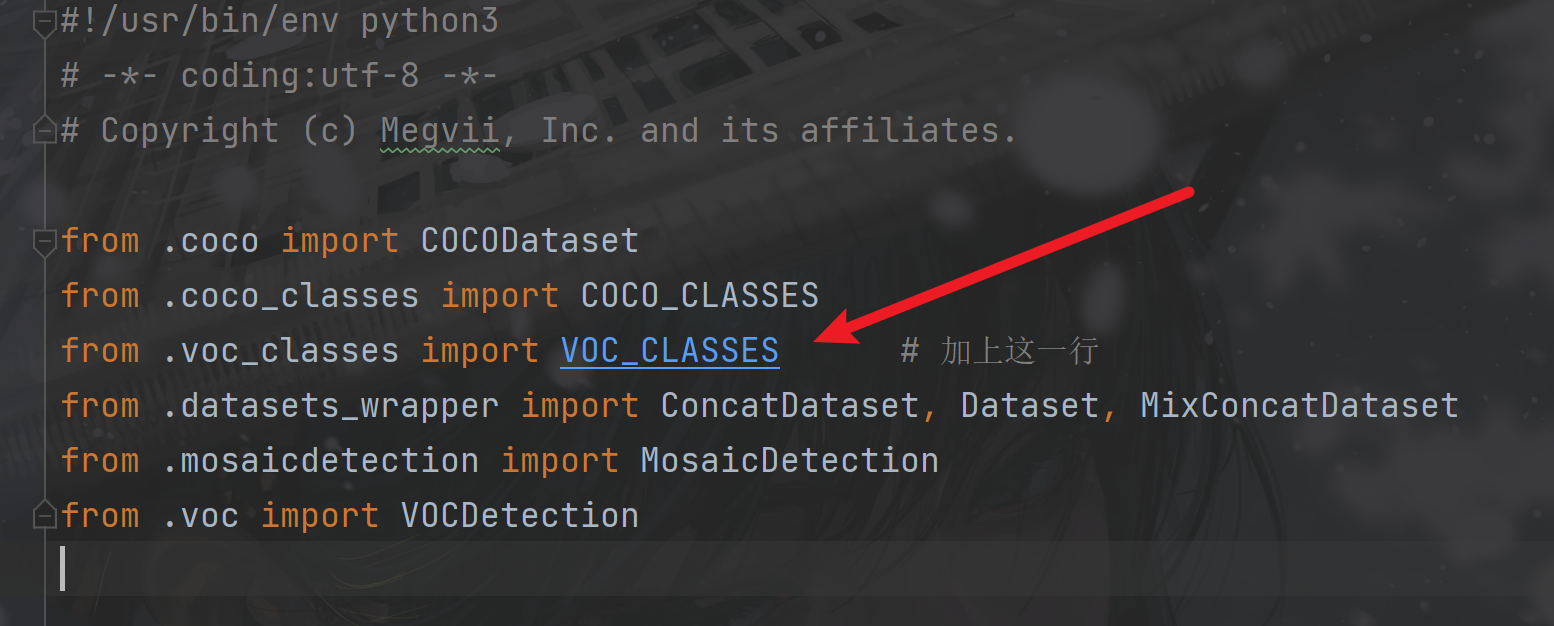
(1)更改:yolox/data/datasets/__init__.py
加上from .voc_classes import VOC_CLASSES
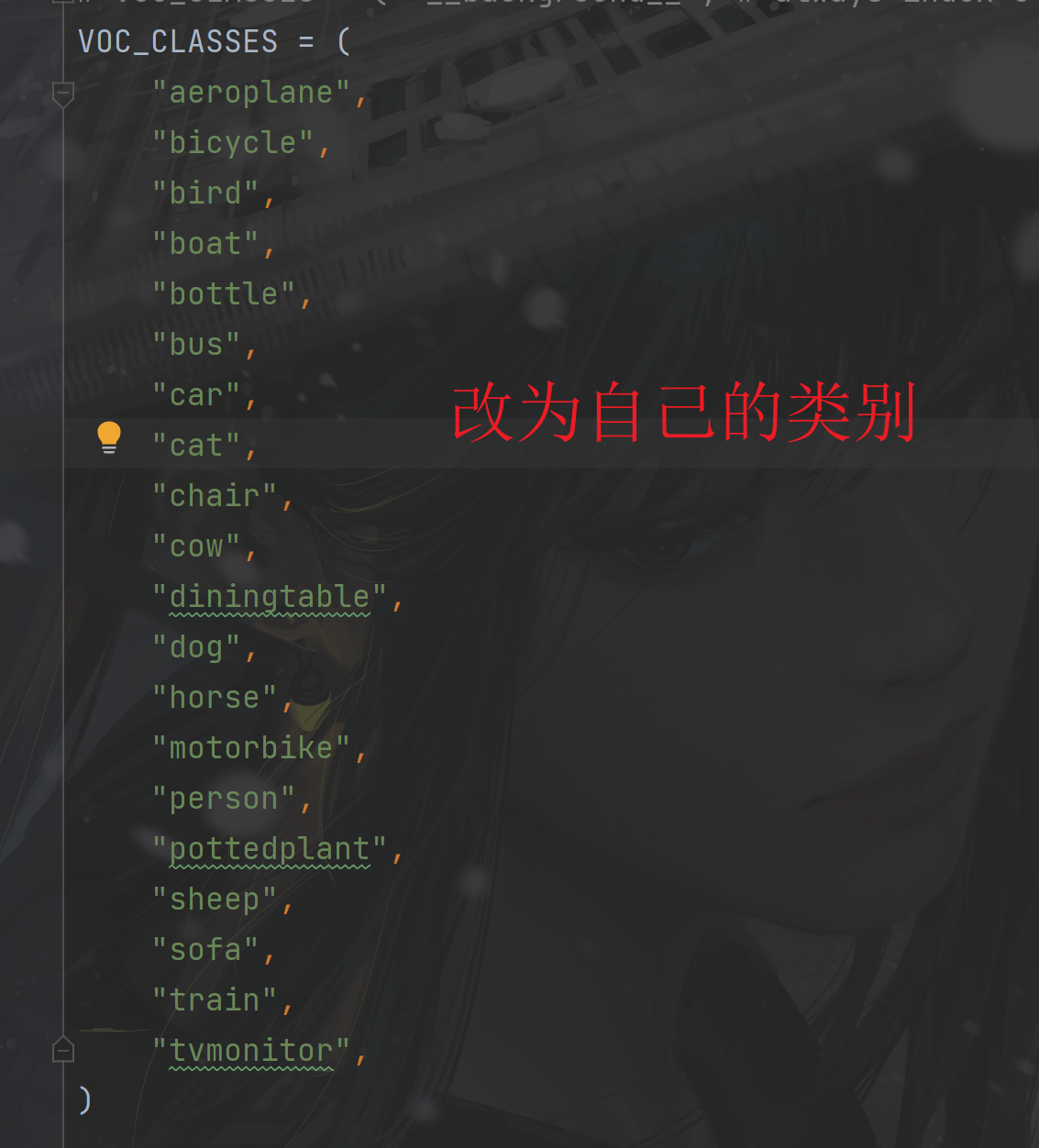
(2)如果是自定义的类别需要更改yolox/data/datasets/voc_classes.py的类别名称
(3)更改demo.py
- 加上
from yolox.data.datasets import VOC_CLASSES
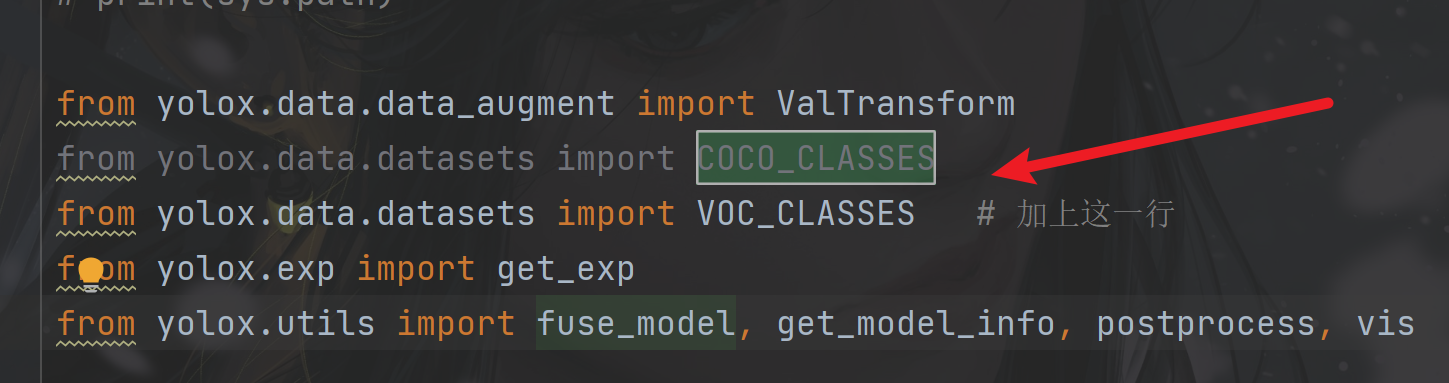
将main函数中的cls_names改为VOC的数据类别
cls_names = VOC_CLASSES,

2.测试指令:
(1)测试图片
python tools/mydemo.py image -f exps/example/yolox_voc/yolox_voc_s.py -c YOLOX_outputs/yolox_voc_s/best_ckpt.pth --path assets/dog.jpg --conf 0.25 --nms 0.45 --tsize 640 --save_result --device gpu测试结果:

(2)测试摄像头(yolox-s)(不即时展示):
python tools/demo.py webcam -n yolox-s -c weights/yolox_s.pth --conf 0.25 --nms 0.45 --tsize 640 --save_result --device gpu边展示写入需要修改下代码:
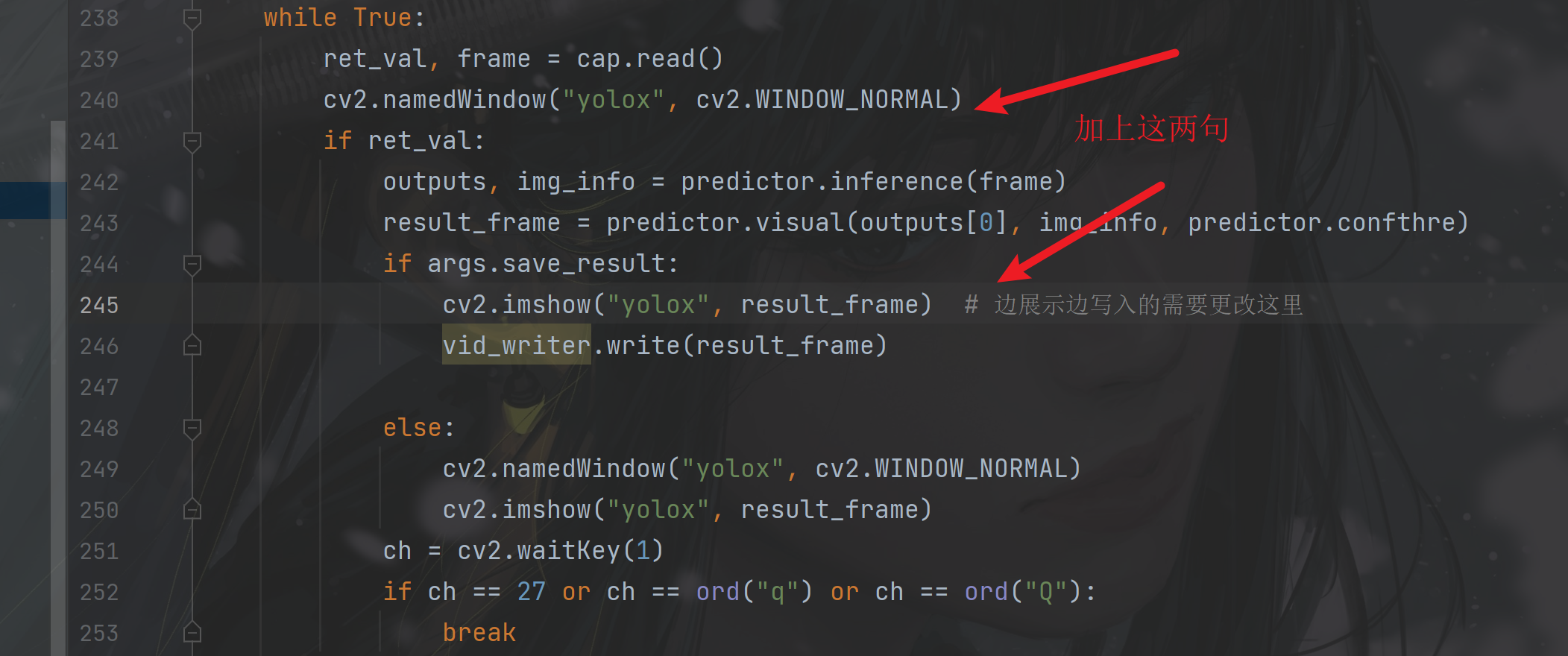
只显示实时测试结果:
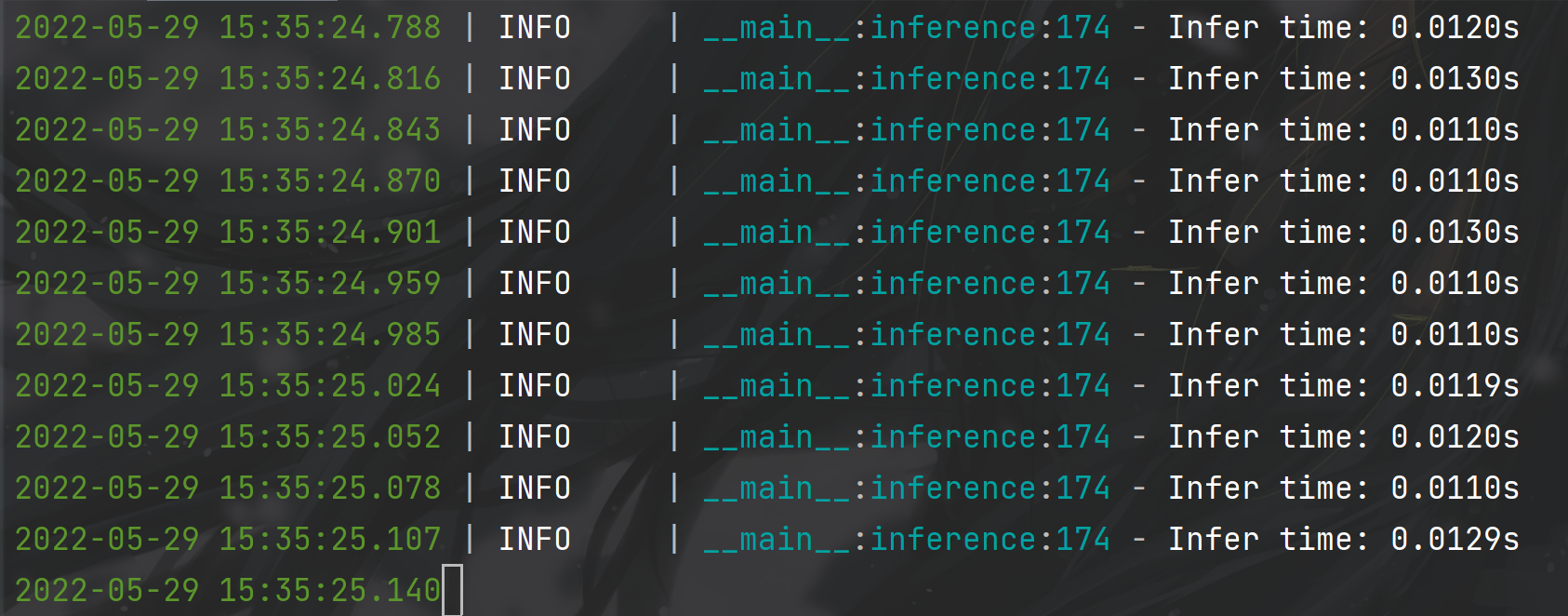
python tools/demo.py webcam -n yolox-s -c weights/yolox_s.pth --conf 0.25 --nms 0.45 --tsize 640 --device gpu测试速度如下:
参考:
YOLOX/README.md at main · Megvii-BaseDetection/YOLOX · GitHub
https://github.com/Megvii-BaseDetection/YOLOX/blob/main/docs/train_custom_data.md