C++ txt文档转存
迭代器分类
分配器allocator
容器对元素要求
哈希函数
以下Cpp重点
第十四章 C++中的代码重用
法一,类成员是另一个对象的类—包含、组合、层次化。例如在自己写的类中包含vector之类的
法二,使用私有或保护继承
用以实现has-a关系,新的类包含另一个类的对象
法三,第十章 函数模板,本章,类模板
使用通用术语定义类,然后使用模板创建针对特定类型顶一个的特殊类。
14.1包含对象成员的类
valarray类由头文件valarray支持。处理数值。支持诸如数组中的一系列操作-----是一个模板类 。std::valarray 是表示并操作值数组的类。它支持对元素逐个进行数学运算,并且支持多种形式的广义下标运算符、切片及间接访问。
初始化方法类似vector
valarray< type_name> value_name( number/array/… , array_size);
valarray< int> v5 = {22,32}; //c++11初始化列表
方法:
operator; 访问各个元素
size();元素个数
sum() 总和
max(); /min()
e.g.
class Student
{
private:
string name; //string类
valarray< double> scores; //valarray 类
}
student类的成员函数可以使用string类的公共接口访问其内部值,但是student类外部不可以这么做。只能通过student类的公有接口访问string类的值。student类获得了其成员对象的实现,没有继承接口。
使用公有继承,类可以继承接口,可能还有实现(基类的纯虚函数提供接口,但不提供实现)。获得接口时is-a关系的组成部分。使用组合,类可以获得实现,但不获得接口。不继承接口时has-a关系的组成部分
对于has-a不继承接口是个好事,例如,string类将+运算符重载为将两个字符串连接起来。但是对于两个student类对象串接起来没意义。
另一方面,被包含的类的接口部分对于新类来说可能是有意义的,例如,可能希望使用string类接口中的
operator<()方法将student对象按姓名排序,可以定义student::operator<()成员函数,在内部使用string::operator<()。
explicit Student(int n) : name("Nully"), scores(n) {}
一个参数调用的构造函数,可以用作从参数类型->类类型的隐式转换函数。通常会导致问题(没有按照你设计的来),加上explict,关掉隐式转换,按需手动转换P538
1.初始化被包含的对象
成员初始化列表
Queue::Queue(int qs) : qsize(qs) {…}
使用数据成员qsize的名称,初始化它
hasDMA::hasDMA(const hasDMA & hs) : baseDMA(hs) {…}
使用类名称baseDMA调用特定的基类构造函数,初始化派生类的基类部分
Student(const char * str, const double * pd, int n) : name(str), scores(pd, n) {}
对于成员对象,构造函数使用成员名(私有数据名称)
对于继承的对象,构造函数在成员初始化列表中使用类名调用特定的基类构造函数
初始化列表中的每一项都调用与之匹配的构造函数,即name(str)嗲用构造函数string(const char *)
scores(pd, n)调用构造函数Array Db(const double *, int)
此时的成员对象的背后是一个类。当不使用成员初始化列表,C++将使用成员对下个所属类的默认构造函数
初始化顺序
当初始化列表包含多个项目,初始化顺序为他们被声明的顺序,而不是他们在初始化列表中的顺序。一般来说顺序不太重要,但是当一个成员的值是另外一个成员的一部分的时候,很重要
2.使用被包含对象的接口
被包含对象的接口不是公有的,但是可以在类方法中使用它。
double Student::Average() const
{
if (scores.size() > 0)
return scores.sum() / scores.size();
else
return 0;
}
Student调用自己定义的average,在其内部,使用了valarray的方法size(),sum()。
当类方法没有提供时,可以自行提供私有辅助方法
14.2 私有继承
另一种实现has-a关系的途径。
此时,基类的公有成员和包含成员都将成为派生类的私有成员。基类方法也不会成为派生对象公有接口的一部分,但是可以在派生类成员函数中使用他们。
公有继承,基类的的公有方 将成为派生类的公有方法,派生类将继承基类的接口,–is-a关系的一部分
私有继承,基类的公有方法->派生类的私有方法—派生类自己的方法可以调用来实现对父类的操作,但派生类的对象不能直接调用父类方法,派生类不继承基类接口–不完全继承-has-a关系的一部分
例如String类->Student类
包含,将具体的对象作为一个命名的成员对象添加到类中
私有继承,将对象作为一个未被命名的继承对象添加到类中—子对象,表示通过继承或包含添加的对象
获得实现,不提供接口
14.2.1 示例
private默认值,省略也导致私有继承
class Student : private std::string, private std::valarray< double>
{
}
此student类从多个类继承而来,多重继承(multiple inheritance)。公有多重继承将导致很多问题。
1.初始化
包含,它的构造函数 使用对象名
Student (const char * str, const double * pd, int n) : name(str), scores(pd, n) {}
私有继承,使用类名
Student (const char * str, const double * pd, int n) :
std::string(str), ArrayDb(pd, n) {} // ArrayDb <–std::valarray< double>
2.访问基类方法
使用私有继承,只能在派生类的方法面里面使用基类方法。有时候希望能用到公有的,
则可以在公有函数中使用继承过来的基类方法
包含的方法:
double Student::Average() const
{
if (scores.size() > 0)
return scores.sum() / scores.size();
else
return 0;
}
私有继承使得能够使用类名称和作用域解析运算符来调用基类方法
double Student::Average() const
{
if (ArrayDb :: size() > 0)
return ArrayDb.sum() / ArrayDb.size();
else
return 0;
}
当然,如果你想使用派生类对象直接调用私有继承来的基类方法,在public部分使用
using base :: func(); //14.2.4
这样在main中可就可以deried :: fun();
3.访问基类对象
使用作用域解析运算符可以访问基类的方法,如果使用基类本身,如Student类的包含版本实现了Name()方法,返回string对象成员name,私有继承时,string对象没有名称,无法返回name。
此时,强制类型转换
因为student是string类派生而来,因此可以通过强制类型转换,将Student类转换为string类对象,结果就成了继承而来的string对象。 this指向用来调用方法的对象, *this为用来调用方法的对象。
const string & Student::Name() const
{
return (const string &) *this;
}
返回一个引用,指向用于调用该方法的student对象中继承而来的string对象
翻译:
student由string类私有继承而来,因此它要访问string对象的私有成员,只能先将自己强制类型转换为string类型的公有继承对象
4.访问基类的友元函数
用类名显式地限定函数名不合适,友元函数不属于类,可以通过显式的转换为基类来调用它
ostream & operator<<(ostream & os, const Student & stu)
{
os <<(const String &) stu;
}
cout << plato;
plato是一个student对象,则上面代码可用。stu将是指向plato的引用,os指向cout的引用
引用stu不会自动转换为string引用,是因为在不进行显示类型转换的情况下,不能将指向派生类的引用或指针赋给基类引用或指针
在本例,即使公有继承,不强制转换也不行。会变成这样os <<stu;不停的与友元函数匹配,导致递归
另外,student例子是多重继承,编译器无法确定应转换成哪个基类。
14.2.2 使用包含还是继承
包含还是私有继承???
大多数倾向于包含!!!,
首先,容易理解,类声明中包含表示被包含类的显式命名对象,代码可以通过名称引用这些对象。 而私有继承是关系更抽象
其次,继承会引起很多问题,尤其从多个基类继承。
另外,包含能够包含多个同类的对象,如三个string对象,继承只能使用一个这样的秀昂,对象呢没名称,那一区分
私有继承提供的特性比包含多
如果类包含了保护乘员(可以是数据,也可以是函数)。则这样的成员在派生类中是可用的,在继承层级结构之外不可用。原因:如果使用组合将这样的类包含在另一个类中,则后者将不是派生类,而是位于继承层次结构之外,因此不能访问保护乘员,(多重包含组合) 但可以通过继承得到的是派生类,可以访问保护成员
另外,需要重新定义虚函数时候,只能使用私有继承,派生类可以重定义虚函数,但是包含类不能。私有继承重定义的函数将只能在类中使用,而不是公有的。
tip:通常,应该使用包含建立has-a关系,如果需要访问原有类的保护乘员,或重定义虚函数,则私有继承
14.2.3 保护继承
私有继承的变体,关键字:protected
class Student : protected std::string, protected std::valarray
{…}
保护继承,基类的公有成员和保护成员将成为派生类的保护成员,和私有继承一样,基类的接口在派生类中也可以使用,但是继承层次结构之外的不可用。
使用私有继承,派生出的第三代(基-派1-派2)类将不能使用基类的接口,因为基类的公有方法在派生类中变成私有方法
使用保护继承。基类的公有方法在第二代将变成受保护的,因此第三地派生类仍然可以使用他们
P550 表14.1
14.2.4使用using重新定义访问权限
使用保护派生或私有派生,要让基类的方法在派生类外可用,
法一,定义一个使用该基类方法的派生类方法,如希望Student类能使用valarray的sum()方法
double Student::sum() const //公有的派生类方法
{
return std::valarray::sum(); //使用私有继承的方法
}
法二,将函数调用包装在另一个函数调用中,即用using声明(像名称空间那样)
class Studen : private std::string, private std::valarray< double>
{
public:
using std::valarray< double>::min;
using std::valarray< double>::max;
}
上述using声明使得valarray<double>::min 可用,就好似他们是student的公有方法一样
cout << ada[i].max();
using声明只是用成员名,没有圆括号!! 函数特征标是返回类型。 using只适用于继承,不适用于包含
e.g. 为使student类可以使用valarray的operator方法,只需在student类声明的公有部分报下一下
using std::valarray< double>::operator[]
14.3 多重继承
MI描述的是有多个直接基类的类。公有MI表示的也是is-a关系。
class SingingWater : public Water, public Singer {…}
每一个基类都需要public,不然,编译器默认是私有派生
会碰到的主要问题:从两个基类继承而来的同名方法,从多个相关基类那里继承同一个类的多个实例。
慎用!!!
14.3.1 同一基类被继承多次
e.g.
worker
| |
| |
singer waiter
| |
| |
singingwaiter
singingwaiter ed;
worker * pw = &ed; //二义性
通常,应该使用类型转换来制定对象
worker * pw1 = (waiter *) &ed; //the worker is waiter
P556
但是,即使这样,其中一份worker基类部分也是多余的,不需要的
在此,用到了虚基类。
1.虚基类
虚基类使得从多个类(具有相同的基类)派生出的对象只继承一个基类对象。 又是virtual
virtual 与public顺序没关系
class singer : virtual public worker {…}
class waiter : public virtual worker {…}
class singingwaiter : public singer, public waiter {…}
现在,singingwaiter对象只包含worker对象的一个副本。本质上来说,singer和waiter对象共享一个
worker对象,也因此,可以使用多态。
小问题解答:
1.虚函数和虚基类之间并不存在明显的联系,但是不能增加新关键字了。
2.为啥还使用将基类声明为虚的方式?第一,某些情况下,可能需要基类的多个拷贝;第二个,将基类作为虚的要求程序完成额外的计算,为不需要的工具付出代价是不应当的。第三,有缺点
----这啥垃圾问题,重难点
3.为了使得虚基类能工作,C++需要调整。另外,虚基类还可能需要修改已有的代码。如增加virtual关键字
2.新的构造函数规则
对于非虚基类,唯一可以出现在初始化列表中的构造函数是即时基类构造函数。但这些构造函数可能需要将信息传递给其基类。
e.g.
class A
{
int a;
public:
A(int n = 0) : a(n) {}
};
class B:public A
{
int b;
public:
B(int m = 0, int n = 0):A(n), b(m) {}
};
class C : public B
{
int c;
public:
C(int q = 0, int m = 0, int n = 0) : B(m,n), c(q) } {}
};
如果 worker是虚基类,以上自动传递信息给各自基类将失效。C++在基类是虚的时候,禁止信息通过中间类自动传递给基类。
singingwaiter(const worker & wk, int p = 0, int v = singer::other):
waiter(wk,p), singer(wk,v) {} //failed
因此,这种wk被通过两条路径传递,行不通,这种情况下使用worker的默认构造函数
不然,只能显式调用所需的基类构造函数。
singingwaiter(const worker & wk, int p = 0, int v = singer::other):
worker(wk), waiter(wk,p),singer(wk,v) {}
waiter 和singer中wk基类部分数据不会被传递,只能通过worker被传递
上述代码将显式调用worker(const worker &).对于虚基类,必须,对于非虚基类,非法
如果类有间接虚基类,除非只使用虚基类的默认构造函数,否则必须显式调用该虚基类的某个构造函数
14.3.2继承了多个同名方法
对于单继承,如果没有重新定义方法,则将使用最近祖先中的定义,而在多重继承中,每个直接祖先都有一个show()函数,因此二义性。
可以使用作用域解析运算符来表明意图:
singingwaiter newhire(“aaa”, 2,2,soprano);
newhire singer::show(); //使用singer version
更好的方法是在singingwaiter中重新定义show,并指出使用哪个show
对于单继承来说,让派生方法调用基类的方法是可以的。还可以无线套娃。但是对于多重继承无效
如worker->waiter->singer ,单例继承ok,多重继承中,singer将忽略waiter组件
同样
void singingwaiter::show()
{
singer::show();
}
无效
补救措施:
void singingwaiter::show()
{
singer::show();
waiter::show();
}
但是这样会重复显示worker最终基类的内容多次
解决措施:模块化方式,而不是递增方式。
公有worker部分单独显示,个性化部分合并在一起显示,最后在singingwaiter:show()中组合
void worker::Data() const //protected 公共部分
{
cout <<…;
}
void waiter::Data() const //protected单独部分
{
cout <<…;
}
void singer::Data() const //protected单独部分
{
cout <<…;
}
void singingwaiter:Data() ocnst //protected单独部分
[
singer::Data();
waiter::Data();
}
void singingwaiter:Show() const //public最终合并
{
worker::Data();
Data();
}
MMP,不就是相当于把公有的基类单独下是剩余的各自单独显示嘛
这种方式,对象仍然可以沿用show()方法,
但是Data()方法只能在类内部使用,作为协助公有接口的辅助函数。然而,Data()方法成为私有的将组织waiter中的代码使用worker::Data(),这正是保护访问类的用武之地。
如果Data()方法是保护的,则只能在继承层次结构中的类使用它,其他地方不能使用
另外一种方法:将所有的数据组件都设置为保护的,而不是私有的。不过保护方法(而不是保护数据)将可以更严格地控制对数据的访问。
P560
有关MI的一些问题
1.混合使用虚基类和非虚基类
通过多种途径继承了一个基类的派生类。如果基类是虚基类,派生类将 包含 基类的一个子对象。
如果基类不是虚基类,派生类将包含多个子对象。
混合使用的话,虚基类的子对象,和非虚基类的多个子对象……
那个SB会这么用
2.虚基类和支配
使用虚基类不一定会导致二义性。如果某个名称优先于其他所有名称,则使用它时,不用限定符,也无所谓
优先级:派生类中的名称优先于直接或间接祖先类中的相同名称。
虚二义性规则与访问规则无关 只要在派生链中存在同名,但是你没有限定是谁,则会存在二义性P567
14.4类模板
通常情况,类定义放在一个头文件中,方法定义放在一个源代码文件中,使用类对象的代码会通过#include 来包含对应头文件,通过链接器访问这些代码。
模板不是。编译器需要通过模板为实例化类型生成实际的方法代码,因此需同时访问类定义和方法定义。解决办法:
1.方法定义和类定义直接放在同一个头文件中。也可以将模板方法定义放在另一个头文件,然后在类定义中包含这个头文件
2.方法定义在一个源代码文件中,然后在模板定义头文件中包含方法实现的源文件。
template… 下方包含实现文件
#include “haha.cpp”
这种方法不能把haha.cpp文件添加到项目中,且这个方法实现文件可以随便命名如haha.inl
除了对象类型不同之外,代码相同。可以使用泛型–独立于类型。然后再将具体的类型作为参数传递给这个类。这样就可以使用通用的代码生成存储不同类型的类
14.4.1 定义类模板
和模板函数一样,模板类开头如下:
template <class Type>
template--定义一个模板
<>--参数列表
class--变量的类型名
Type--变量的名称,不一定必须是一个类,知识说Type是一个通用的类型说明符。
新版C++:
template < typename Type>
typename: 表示模板参数是一个类型的占位符,
可以使用自己的泛型名代替Type,其命名规则与其他标志符相同。被调用时,Type将被具体的类型值(如int)取代。
使用模板成员函数替换原有类的类方法,每个函数头都将以相同的模板声打头:
template < class Type>
同样应使用泛型名Type替换typedef的标志符,还需将Stack::改为Stack< Type>::
e.g.
bool stack::push(const Item & item){}
----->>>>>
template < typename Type>
bool stack< Type>::push(const Type & itme) {}
如果在类声明中定义了方法(内联定义),则可以省略模板前缀和类限定符。
模板,不是具体的定义。他们是C++编译指令,说明如何生成类和成员函数定义,
具体实现—实例化或者具体化
不能将模板成员函数放在独立的实现文件中。模板必须与特定的模板实例化请求一起编译使用。 因此,模板信息放在一个头文件中。
限制模板实例化:
头文件提供类模板,没有方法定义 末尾也不包含方法定义源码文件
这里在项目添加真正的.cpp文件,包含方法定义(包含模板头文件)并在该.cpp文件末尾使用如template class Grid< int>; 类似的语句,这就对int类型显示实例化,并禁止其他类型实例化
14.4.2使用模板类
通过模板生成具体可用的类——实例化,具体类型替换泛型名
e.g.
Stack< int> kernels; //int Stack
Stack< string> colonels; //object Stack
使用的算法必须与类型一致,如stack类假设可以将一个项目赋给另一个项目。这种假设对于基本类型,结构和类来说是成立的(除非将赋值运算符设置为私有),但是对于数组是不成立的。
泛型标志符–例如这里的Type–被称为:类型参数,类似于变量,但只能将类型赋给他们。
必须显式地提供所需类型,与常规的函数模板不同,函数模板可以根据参数类型确定要生成哪种函数
14.4.3 模板类-指针栈
可以将内置类型或类对象用作类模板stack< type>的类型(stack< int>),指针也可以,如指针栈,但是要修改代码
2.正确的使用指针栈
让调用程序提供一个指针数组,每个指针指向不同的字符串。这样的指针栈,实际上还相当于是指针数组。负责管理指针,而不是创建指针。
bool pop(Type & item);
template <class Type>
bool Stack<Type>::pop(Type & item)
{
if (top > 0)
{
item = items[--top];
return true;
}
else
return false;
}
Stack & operator=(const Stack & st);
template <class Type>
Stack<Type> & Stack<Type>::operator=(const Stack<Type> & st)
{
if (this == &st)
return *this;
delete [] items;
stacksize = st.stacksize;
top = st.top;
items = new Type [stacksize];
for (int i = 0; i < top; i++)
items[i] = st.items[i];
return *this;
}
原型将赋值运算符函数的返回类型声明为stack引用,是stack的缩写,只能在类中这么使用。
即可以在模板声明或模板函数定义内使用stack(而不是stack),在类外面,即指定返回类型或使用作用域解析运算符时,必须完整的使用stack
初始化一组字符串常量,P577 类型可以为const char*
析构函数对于保存了指针的栈来说,只是山粗了构造函数中new出来的数组,对于指向的字符串无影响
14.4.4数组模板示例和非类型参数
模板常用作容器类,因为类型参数的概念适合将相同从存储方案应用于不同的类型。
允许指定数组大小的简单数组模板,14.3法一中的构造函数接收数组大小的参数。另外就是使用模板参数来提供常规数组的大小。C++ array模板就是这么干
template <class T, int n>
关键字class指出T为类型参数,int 指出n的类型为int—指定特殊的类型而不是用作泛型名,称为非类型或表达式参数
表达式参数可以是整型,枚举,引用或指针。因此,double m是不合法的,但double * pm是合法
模板的非类型形参也就是内置类型形参
非类型形参在模板定义的内部是常量值,也就是说非类型形参在模板的内部是常量。模板代码不能修改非类型参数的值,也不能使用参数的地址,因此n++ &n无效。实例化时,表达式参数的值必须是常量表达式。类模板类型形参不存在实参推演的问题,必须明确指定,且必须有
对比:1
与法一使用构造函数方法相比,当前方法使用表达式参数方法是用到了为自动变量维护的内存栈,速度块,尤其小型数组
构造函数用的是new和delete管理的堆内存
表达式参数方法的主要缺点是,不同大小的数组将生成自己的模板,也就是一下是俩个独立的类声明:
ArrayTP<double, 12> egg;
ArrayTP<double, 13> dcounts;
但是,
Stack egg[12];
Stack dunker[13];
只生成了一个类声明,并将数组大小信息传递给类的构造函数
对比:2
另一个却别是,构造函数方法更通用,因为数组大小是作为类成员,而不是硬编码存储在定义中的,这样可以将一种大小的数组赋给另一种大小的数组,也可以创建允许数组大小可变的类。表达式参数的大小是写死的。 可以返回类型T,也可以返回类对象Sack
https://www.runoob.com/w3cnote/c-templates-detail.html
1、类模板的格式为:
template<class 形参名,class 形参名,…>
class 类名
{ … };
4、在类模板外部定义成员函数的方法为:
template<模板形参列表> 函数返回类型 类名<模板形参名>::函数名(参数列表){函数体},
template<class T1,class T2> void A<T1,T2>::h(){}。
14.4.5 模板的多功能性
**模板类可以用作基类,也可以用作组件类,还可以用作其他模板的类型参数。**如,可以使用数组模板实现栈模板,也可以使用数组模板来构造数组–数组元素是基于栈模板的栈。
e.g.
继承
template < typebname T>
class Array
{
privat:
T entry;
};
template < typebname Type>
class GrowArray : public Array< Type> {…};
包含
tmeplate < tmeplate Tp>
class Stack
{
Array< Tp> ar; //使用Array<> 作为元素
}
Array<Stack< int>> asi; //an Array of stacks of int C++11
1.递归使用模板–套娃
ArrayTP< ArrayTP<int,5>, 10> twodee;
teodee是一个包含了10个元素的数组,其中每个元素都是一个包含5个int元素的数组。等价于int twodee[ 10] [5];
参数顺序正好与二维数组相反。
2.使用多个类型参数
如希望类可以保存多种值
tmeplate <class T1, class T2>
class Pair
{
private:
T1 a;
T2 b;
…
}
3.默认类型模板参数
可以为类型参数提供默认值。没有提供T2的值,则编译器默认使用int
template <class T1, class T2 = int> class Tp {…}
template<class T1,class T2=int>
class CeilDemo
{
public:
int ceil(T1,T2);
};
类模板类型参数可以这么干,但是函数模板参数不能这么干。然而,可以为非类型参数提供默认值,类模板和函数模板都可以
14.4.6 模板的具体化
类模板与函数模板类似,因为可以有隐式实例化,显式实例化和显式具体化。统称具体化。
模板以泛型的方式描述类。据具体化用具体的类型生成类声明。
1.隐式实例化
声明一个或多个对象,指出所需类型。编译器使用通用模板提供的处方生成具体的的定义
Array<int, 100> stuff; //隐式实例化,Array<class Type, int n>
编译器在需要对象之前,不会生成类的隐式实例化:
Array<int, 100> * pt; //指针,无需对象,没有实例化
pt = new Array<double, 30>; //现在需要对象了,此时需要编译器生成类定义,并根据定义创建要给对象,实例化
pt(1,2)这个过程就是一个隐式实例化的过程,它实例化生成了一个T为int的函数。
因此我们得知,隐式实例化实际上就是使用模板时,模板根据传入的实参类型实例化一个函数的过程。
2.显式实例化
当使用template,并指出所需类型来声明类时,编译器将生成类声明的显式实例化。声明必须位于模板定义所在的名称空间中,如:
定义了Array<>模板后后写了如下语句,
template class Array<string, 100>; //生成类了 类模板 Array<string, int n>
这种情况下,虽然没有创建或提及类对象,编译器也将生成类声明,包括方法定义。和隐式实例化一样,也嫁给你根据通用模板生成具体化。
对,你猜的没错,实际上就是我们显式地写明了是何种类型
3.显式具体化
所谓具体化,是指我对此函数做出的具体的定义。注意:具体化需要给出函数的具体实现。通过以下例子将说明。
**针对特殊情况,更改具体的实现,而不是使用泛型定义的模板得到的方法。**也就是进一步在显式实例化的基础上,自己给出具体代码定义,而不是让编译器帮你补全。
当具体化模板和通用模板都和实例化请求匹配时,具体化更优先
注意:
对于给定的函数名,可以有非模板函数、模板函数和显示具体化模板函数以及他们的重载版本。
显示具体化的原型和定义应以template<>打头,并通过名称支出类型
具体化优先于常规模板,而非模板函数优先于具体化和常规模板
4.部分具体化
即,部分限制模板的通用性。例如,部分具体化可以给类型参数之一指定具体的类型
//general template
template <class T1, class T2> class Pair {…}
//specialization with T2 set to int
template < class T1> class Pair<T1, int> {…} //这是一个模板T1不确定的模板,类Pair使用T1,int传入
< class T1>是没有被具体化的类型参数
当T1也指定类型 ,<>内为空, tmeplate <> class Pair<int, int) {…} 成了显式具体化
在有多种选择的情况下,编译器偏向于具体化程度最高的。
也可以通过指针提供特殊版本来部分具体化现有的模板
14.4.7成员模板
模板套模板
模板可用于结构,类或模板类的成员
模板嵌套
template< typename T>
{
template< typename V> //嵌套模板类成员
{
}
template< typename U> U fun(U u, T t) {…}; //模板方法
}
14.4.8 模板用作参数
模板套模板,融入
模板可以包含类型参数,非类型参数和模板作为参数,用于实现STL
template <template < typename T> class Thing>
class Crab
{
private:
Thing< int> s1;
Thing< double> s2;
};
template < typename T> class Thing-------模板参数,template < typename T> class是类型 ,Thing 是参数
Crab< King>legs
King 是一个模板类,其声明与模板参数Thing的声明匹配:template< typename T> class King {…}
模板参数Thing将被替换为声明Crab对象时,被用作模板参数的模板类型
King 替换Thing
可以混合使用模板参数和常规参数
template <template < typename T> class Thing, typename U, typename V>
class Crab
{
private:
Thing< U> s1;
Thing< V> s2;
}
Crab<Stack, int, double> nebula
14.4.9模板类和友元
模板类声明也可以有友元,分三类
1.非模板友元
2.约束模板友元,即友元的类型取决于被实例化的类型
3.非约束模板友元,即友元的所有具体化都是类的每一个具体化的友元
1.模板类和非模板友元函数
模板类中将一个馋鬼函数声明为友元
template< class T>
class HasFriend
{
public:
friend void counts();
};
上述声明使得counts()函数成为模板所有实例化的友元,
counts()不是通过对象调用的,因为它是友元,不是成员函数,也没有对象参数,访问HasFriend对象的方式:
可以访问全局对象,可以使用全局指针访问非全局对象,可以创建自己的对象,可以访问独立于对象的模板类的静态数组成员
为了向友元函数传递对象,只能特定的具体化,如HasFriend
template < class T>
class HasFriend
{
friend void reprot(HasFriend< T> &); //约束模板元
}
如果report本身并不是模板函数,而只是使用一个模板用作参数,意味着必须为要使用的友元定义显式具体化而不是跟随传入的T
void report(HasFriend< short> &) {…} 成为了HasFriend类的友元
2.模板类的约束模板友元函数
类模板参数和友元函数的参数一样
友元函数本生成为模板,使得类的每一个具体化都获得与友元匹配的具体化
首先,在类定义的前面声明每个模板函数
template < typename T> void counts();
template < typename T> void reprot(T &);
然后,在函数中再次将模板声明为友元,这些语句根据模板参数的类型声明具体化
template < typename TT>
class HasFriendT
{
//counts()没有参数,无法推断类型,只能使用模板参数语法< TT>指明具体化,TT是HasFriendT类的参数类型
friend void counts< TT>();
// <>指出这是模板具体化,对于repot,<>可以为空,因为可以从函数参数推断出如下模板类型参数
HasFriendTT< TT>,
然而,也可使用
reprot<HasFriendT< TT> > (HasFriendT< TT> &)
friend void reprot<>( HasFriendT)< TT> & );
}
e,g,
HasFriendT< int> squack;
生成如下定义
class HasFriendT< int>
{
friend void coutns< int >();
friend void report<>(HasFriendT< int> &);
}
此时友元也成了模板
最后,为友元提供模板定义。每种类型多有自己的友元函数
3.模板类的非约束模板友元函数
约束模板友元函数是在类声明外面声明的模板的具体化。int类具体化获得int函数具体化
通过在类内部声明模板,可以创建非约束友元函数。对于非约束友元,友元模板类型参数与模板类类型参数都是不同的
template < typename T>
class ManyFriend
{
template <typename C, typename D> friend void show2( C &, D &):
};
函数调用show2(hfi1, hfi2),与下面的具体化匹配
//友元函数模板
void show2 <ManyFriend< int> &, ManyFriend< int> &> (ManyFriend< int> & c, ManyFriendM< int> & d);
因为它是所有ManyFriend具体化的友元,所以能够访问所有具体化对象中数据成员。
//函数模板
template <class 形参名,class 形参名,......> 返回类型 函数名(参数列表)
{
函数体
}
14.4.10 模板别名C++11
typedef std::array<double,12> arrd;
arrd a;
C++11新功能,使用模板提供一系列别名
template< typename T>
using arrtype = std::array<T,12> //using 模板别名 = 引用细节;
//arrtype被定义为一个模板别名
arrtype< double> days; // days is type std::array<double, 12>
总之,arrtype< T> 表示类型std::array<T, 12>
C++11允许将语法using = 用于非模板。 用于非模板时,与常规typedef 等价
typedef const char * pc1 < => using pc1 = const char *
第十八章 新增 可变参数模板
第十五章 友元、异常和其他
友元类 及方法
嵌套类
引发异常、Try块和catch块
异常类
运行阶段类型识别RTTI
dynamic_cast typeid
static_cast, const_const, reiterpret_cast
15.1 友元
友元类的所有方法都可以访问原始类的私有成员和保护成员。
可以将特定的成员函数指定为另一个类的友元,只能有类内部定义,外部不可强加。
尽管友元被授予从外部访问类的私有部分的权限。
15.1.1友元类 A->B
例子,remote类可以改变tv类的状态,但与tv无物理上的交集,因此可以成为tv类的友元
friend class Remote;使得Remote成为友元
友元可以位于公有,私有或保护部分,所在位置无关紧要。但是由于Remote提到了Tv类的具体方法,所以编译器必须了解Tv类后,才能处理Remote类。最简单的方法是首先定义Tv类。当然也可以使用前向声明
P603
线声明tv类,其中remote声明为友元类,再给出remote类,remote的方法均使用了tv中的接口或成员
class Tv { friend class Remote}
class Remote { … }
隐式表示——在类中直接定义
显式表示——类外定义时声明
https://blog.csdn.net/WHEgqing/article/details/100089649
友元关系在类之间不能传递,即类 A 是类 B 的友元,类 B 是类 C 的友元,并不能导出类 A 是类 C 的友元。“咱俩是朋友,所以你的朋友就是我的朋友”这句话在 C++ 的友元关系上 不成立。
15.1.2友元成员函数
让特定的类成员成为另一个类的友元,但是各种声明的顺序很重要
不能把其他类的私有成员函数声明为友元。
将全局函数声明为友元的写法如下:
friend 返回值类型 函数名(参数表);
将其他类的成员函数声明为友元的写法如下:
friend 返回值类型 其他类的类名::成员函数名(参数表);
class Tv
{
friend void Remote:: set_chan(Tv & t, int c);
}
要使编译器能处理这条,必须知道Remote的定义,使用前向声明
class Tv; //前向声明,不给实现
class Remote { … };
class Tv { … };
书中例子remote::set_chan()在Tv中充当友元函数,所以,remote必须在Tv前先定义,但是,Remote提到了Tv对象,Tv又需要放在remote前面,避免这种循环依赖的方法.使用前向声明 forward declaration:
在remote定义的前面插入:class Tv
class Tv; //forward declaration
class Remote; //用到了Tv对象
class Tv {…}; //用到了remote中的方法
不能这么干 ,Tv类对象处于被调用的局面,只能在后。
Remote用到了Tv类中的数据,在Tv中充当友元
class Remote;
class Tv {…};
calss Remote {…};
因为在编译器在Tv类的声明中看到Remote的一个方法被声明在Tv类的友元之前,应该先看到Remote类的声明和set_chan–这个会从当友元函数的声明
前一种,只是用到了对象,因此可以先告诉remote,下面会有这么个对象
另外,remote中包含内联代码调用了Tv类的方法,所以编译器此时必须已经看到Tv类的声明,这样才能知道Tv类有哪些方法。但是已经在后面了,解决方法是,使Remote声明中只包含方法声明,并将实际的定义放在Tv类之后,顺序如下:
class Tv; //forward declaration
class Remote; //用到了Tv对象,用到了一个Tv的一个方法的方法—只有声明
class Tv {…}; //用到了remote中的方法
//放置remote方法的定义
通过在方法定义中使用inline关键字,仍然可以时期成为内联方法
#include < iostream>
using namespace std;
class B; //前向声明
class A{
private:
int a;
public:
A() { a = 1; }
void print( B & b );
};
class B{
private:
int b;
public:
B() { b = 6; }
void print() { cout << b << endl; }
friend void A::print( B & b ); //友元成员函数
};
/* 被定义为友元成员函数的函数必须在类外(另一个使用该函数的类后面)定义 */
void A::print( B & b ) {
cout << "b = " << b.b << endl;
}
int main() {
A a;
B b;
a.print( b );
return 0;
}
/*
输出结果: b = 6
*/
需要注意的是:
(1)类的前向声明。由于在A中的print函数需要使用B,如果不进行B的前向声明,编译器就不知道B是一个类,会报错。
(2)类的排列顺序。在类B中会用到A的方法print(),因此需要先定义A,再定义B。
(3)友元成员函数的定义位置。友元成员函数不能使用内联代码,类中只能有函数声明。函数定义需要放到类之后,在类外进行定义,而且必须放到另一个类定义的后面。(对上面代码来说,若将A::print()的定义放在类B定义之前——示例位置1处,也会报错,提示类B未完成)
对于友元的位置在何处生明,可以简单记为friend在哪,哪个就可以被外面直接访问。(friend在类A,A就可以被其他特定位置访问
内联函数链接性是内部的,意味着函数定义必须放在使用函数的文件中。放于头文件,因此在使用函数的文件中包含头文件可确保将定义放在正确的位置。
也可以将定义放在实现文件中,但必须删除inline,这样函数的链接性将是外部的
另外Tv类中提到了Remote是个友元类,不需要前向声明,友元语句本省已经指出Remote是一个类。
15.1.3 其他友元关系
互相成为友元 A< - > B,对于使用Remote对象的Tv方法,其原型可在Remote类声明之前声明,但必须在Remote类声明之后定义,以便编译器有足够的的信息来编译该功能
e.g.
class Tv
{
friend class Remote;
public:
void buzz(Remote &r); //可以先声明,但是必须后定义
};
class Remote
{
friend class Tv;
public:
void Bool volup(Tv & t) { t.volup(); } //可直接定义
};
inline void Tv::buzz(Remote & r)//如果不希望内联, 可在其他文件定义,不带inline
{
…
};
由于Remote声明位于Tv声明的后面,所以可在类声明中定义Remote::volup(),但Tv::buzz()必须在Tv声明的外部定义,使其位于Remote声明的后面。
15.1.4 共同的友元
函数 需要访问连个类的私有数据。可以将函数用作两个类的友元。
如prober 和analyzer ,
class Analyzer; //forward declartion
class Prober
{
friend void sync(Analyzer & a, const Probe & p); //sync a to p
friend void sync(Probe & a, const Analyzer & p); //sync a to p
};
class Analyzer
{
friend void sync(Analyzer & a, const Probe & p); //sync a to p
friend void sync(Probe & a, const Analyzer & p); //sync a to p
};
//define the friend functions
inline void sync(Analyzer & a, const Probe & p) {…}
inline void sync(Probe & a, const Analyzer & p) {…}
前向声明使编译器看到Probe类声明重点友元声明时,知道Analyzer是一个类型。
15.2 嵌套类
在另一个类中声明的类–嵌套类。它通过提供new type class scope来避免名称混乱.嵌套类所在的类,它的成员函数可以创建和使用嵌套类的对象。仅当声明位于公有部分,才能在包含类的外面使用嵌套类,而且必须使用 :: 才能使用
对类进行嵌套与包含并不同,包含意味着将具体的类对象用作另一个类的成员。对类进行嵌套并不创建类成员,而是一种类型的定义,该类型仅在包含嵌套类声明的类中有效。
对类进行嵌套是为了帮助实现另一个类,类定义套娃类定义
e.g.
class Queue
{
class Node
{
public:
Item item;
Node * next;
Node(const Item & i) :item(i),next(0) {}
};
};
在Queue中定义了一个Node类
调用方式:
Queue::Node::Node(const Item & i) : item(i), next(0) {}
15.2.1 嵌套类和访问权限
嵌套类的声明位置决定了嵌套类的作用域。即它决定了程序的哪些部分可以创建这种类的对象。其次和其他类一样,嵌套类的公有,私有,保护部分控制了对类成员的访问。
在哪些地方可以使用嵌套类以及如何使用,取决于作用域和访问控制。
1.作用域
如果在另一个类的私有部分,则只有后者知道它,
类的默认访问控制权限是私有的。上述Queue成员可以使用Node对象和指向Node对象的指针,不能使用里面的数据,但是程序其他部分不知道Node这个类。从Queue派生出来的类,Node也是不可见的,因为派生类不能直接访问基类的私有部
如果在另一个类的保护部分声明,则它对于后者来说是可见的,可以使用里面的数据。但是对于外部世界是不可见的。派生类将知道这个嵌套类,并可以直接创建和使用这种类型的对象
如果声明再公有部分,则全世界都能看到他,但是嵌套类的作用域是包含它的类,外部世界使用需要类限定符
嵌套结构和枚举的作用域与此相同,公有枚举提供程序员的类常数P613
2.访问控制
15.2.2 模板中的嵌套
程序15.5
上述Queue成员可以使用Node对象和指向Node对象的指针
15.3 异常
15.3.1调用abort()
位于cstdlib头文件中。向标准错误流–cerr使用的错误流发送 abonormal program termination,然后终止程序,返回一个随实现而异的值。告诉操作系统或父进程,处理失败。
abort()是否刷新文件缓冲区取决于实现。exit(),也可以刷新缓冲区,但不显示消息。
用法:处理错误函数部分中加入abort(),
15.3.2 返回错误码
更灵活的是使用函数返回值来指出具体的问题,单独参数专门干这个,引用或者指针,全局变量也ok
15.3.3 异常机制
C++异常是对程序运行过程中发生的异常情况的响应,提供了将控制权从程序的一个部分传递到另一个部分的途径,对异常的处理包括三个部分:
1.引发异常–程序出现问题 throw语句实际上是跳转,并终止throw之后的语句,命令程序跳转到另一条语句,throw关键字表示引发异常,紧随其后的值(例如字符串或对象)指出了异常的特征。
2.使用处理程序捕获异常 exception handler。异常处理程序位于要处理问题的程序中,catch关键字表示捕获异常,
处理程序以关键字catch开头,随后是位于括号中的类型声明,指出了异常处理程序要相应的异常类型;然后是一个花括号内的代码块,指出要采取的措施。catch和异常类型用作标签,指出当程序引发异常,跳转到此处执行。异常处理程序也叫catch块。
3.使用try块 try块标识其中特定的异常可能激活的代码块,后面跟着一个或多个catch块。try关键字。后面花括号内的代码块表明需要注意这些代码引发的异常。
e.g.
try{...} 其中的语句可能导致异常,发生异常,后面的catch会处理
如:
try{
{
...
throw "..."; //此处为异常类型,可以是字符串或类或者其他C++类型,通常为类
}
}
catch(const char *s) //开始处理异常
{
std::cout << s << std::endl;
std::cout << "Enter a new ...";
continue;
}
catch(...)
{
...
break; //跳出执行块外,如果是exit(EXIT_FAIL_URE),则程序立即结束
}
#include <iostream>
#include <exception>
#include <vector>
using namespace std;
int main()
{
vector<int> v {1,2,3 } ;
try{
if (v.at(0) < v.at(2))
throw "haha";
}catch(const char* e)
{
cout << " error------" << e << endl;
}
return 0;
}
/*
执行结果: error------haha
*/
执行thorw语句类似与执行返回语句,它将终止函数执行;导致程序沿着函数调用序列后退,直到找到包含try块的函数。然后将控制权返回给包含try块的函数,并在该函数中寻找引发的异常类型匹配的异常处理程序
执行完try块后,如果没有依法异常,跳过后续的catch块
如果没有对应的catch块,默认情况下,最终会调用abort()函数
15.3.4 将对象用作异常类型 –const 引用最好 const exception &
通常,引发异常的函数将传递一个对象,这样可以使用不同的异常类型来区分函数在不同情况下引发的异常。另外,对昂可以携带信息,方便确定异常原因,和catch采取什么措施。 P623
catch块与传递的对象约定好怎样传递异常信息 可以是int值, 字符串 当然,最好是对象
例子中返回void ,函数中直接cout异常信息,则catch中可直接使用函数显示异常信息,如果用const char*返回,则可以cout
double func() noexcept; //不抛出异常
int*ptr = new(nothrow) int[max]; //分配失败返回nullptr,而不是异常
15.3.6 栈解退
函数栈,每次返回上一个函数,层层返回 知道最初调用的函数
栈解退 如果try块没有直接调用引发异常的函数,而是调用了对 引发异常的函数 进行调用的函数(异常函数上一层- try-error编程try-funa-funb-error,套娃),则程序流程将从引发异常的函数 直接 跳转到包含try块和处理程序的函数,而不是一层一层返回(return)—栈解退(unwinding the stack)。栈内容也会一层一层释放。随后控制权交给块尾巴上的异常处理程序,而不是调用函数或函数调用后的第一条语句
重新引发的异常将由下一个捕获这种异常的try—catch块组合进行处理。没找到,程序就会异常终止。
重新抛出异常
catch (bad_hmean & bg) // start of catch block
{
bg.mesg();
std::cout << “Caught in means()\n”;
throw; // rethrows the same exception
}
这是主动返回已有的异常到上一层代码块中,寻找可以处理的catch块,否则在没有找到处理块的情况下,也只能被动的返回到上一层,因为没找到嘛
嵌套异常
处理第一个异常到时候出发第二个异常]
class MyException : public std::exception; //
{
public:
virtual const char* what() const noexcept override
{
return mMessage.C_str();
}
private;
string mMessage;
}
void func()
{
try { throw runtime_error("...") ;} erro_a 1st
catch( runtime_error& e) { throw_with_nested (MyException("...") );} arro_b 2nd
}
throw_with_nedted函数调用自动将 a异常包含在b异常内
try 先处理b, 然后用dynamic_cast 访问嵌套的b,如果b中没包含异常,则为空指针,如果包含了嵌套的异常a,则调用nested_exception的rethrow_nested()方法,这样再次抛出嵌套异常,在紧接着的另一个try/catch块中捕获
try {
func();
}
catch( cosnt MyException& e)
{
cout << e.what() << endl;
const auto* pNested = dynamic_cast<const nested_exception*>(&e);
if( pNested)
{
try {
pNested->rethrow_nested();
}
catch( const runtime_error& e)
{
cout << e.what() << endl;
}
}
}
可能经常需要dynamic_cast
因此可以改为
try{
rethow_if_nested(e);
}catch(const runtime_error& e)
15.3.7 其他异常特性
throw 语句将控制权向上返回到第一个这样的函数:包含能够捕获相应异常的try-catch组合所在的代码块。普通函数中的return将控制权返回到该函数函数顶
另外,出现异常,编译器总会创建一个临时拷贝。
动态异常说明 (C++17 前,C++17弃用)
class problem {...} ...
void super() throw (problem)
{
...
if(oh_no)
{
problem oops; //construct object
throw oops; //throw it
...
}
}
...
try{
super();
}
catch(problem &p)
{
...
}
p指向oops的副本而不是它本身。执行完super后,oops将消失。
同样语法格式的
noexcept
noexcept 运算符进行编译时检查,如果表达式不会抛出任何异常则返回 true。
它可用于函数模板的 noexcept 说明符中,以声明函数将对某些类型抛出异常,但不对其他类型抛出。
语法
noexcept( 表达式 )
返回 bool 类型的纯右值。
解释
如果 表达式 求值为 true,那么声明函数不会抛出任何异常。
代码中使用引用。引用另一个重要特征:基类引用可以执行派生类对象。假设有,一组通过继承关联起来的异常类型,则在异常规范中只需列出一个基类引用,它将与任何派生类对象匹配。
如果有一个异常类继承层次结构,应这样排列catch块:将捕获位于层次结构最下面的异常的catch语句放在最前面,将捕获基类异常的catch 语句放在最后面。throw 1 ,2 ,3。 catch 3, 2, 1 。如果catch为1,2,3 则1将捕获全部1,2,3的异常。(因为是基类引用)
在不知道异常类型的情况下,这样catch (…) {//statements}放在最后 可以捕获任何异常 类似于switch 中的default
15.3.8 exception类—STL
C++异常为设计容错程序提供语言级支持
exception头文件定义了该类,C++可以把它用作其他异常类的基类
其中,有个**what()**虚拟成员函数,返回一个字符串,其特征随实现而异。派生成其他的时候要重定义
std::exception在标头 <exception> 定义
class exception;提 供一致的接口,以通过 throw 表达式处理错误。标准库所生成的所有异常都继承自 std::exception。
#include < exception>
class bad_mean : public std::exception
{
public:
const char* what() { return "...";} //自定义了要抛出的不良信息
}
或者使用基类处理程序捕获他们
try{
其中方法包含了 throw exception(); 语句
}
catch(std::exception &e)
{
cout << e.what() << endl; //输出上述自定义的不良信息
}
基于exception的异常类型
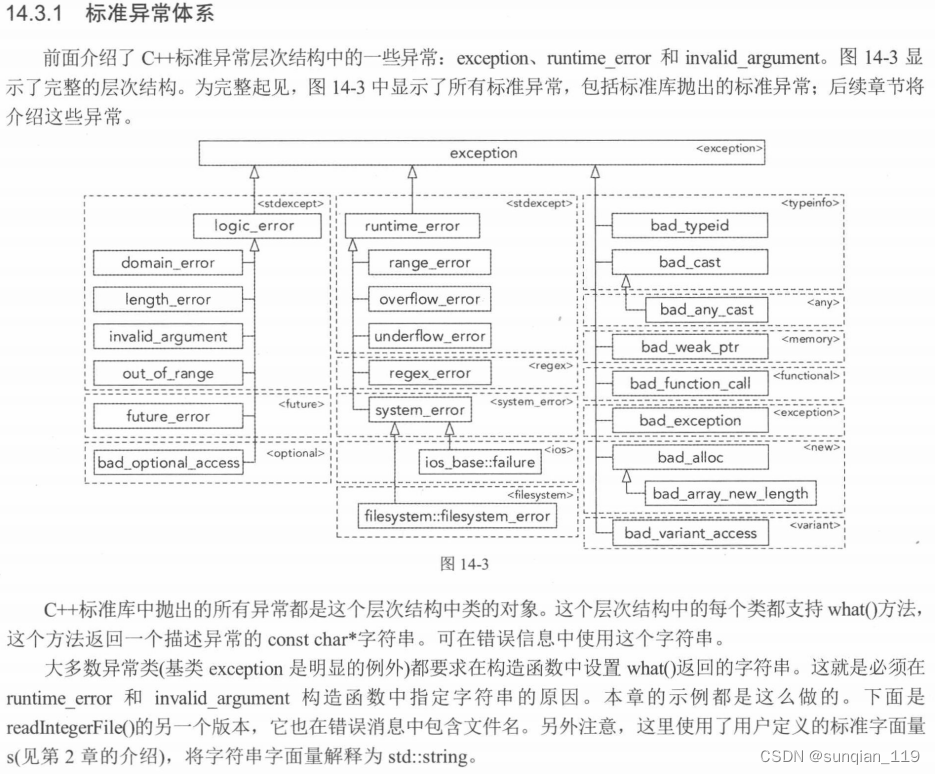
stdexcept异常类定义在<stdexcept>,继承自<exception> ,包含 logic_error 和runtime_error等类,然后从中继续派生出各种错误类型如logic_error派生出invalid_argument
class logic_error : public exception
{
public:
logic_error( const std::string& what_arg );
}
double() { throw invalid_argument ("haha"); }
catch(cosnt invalid_argument& e) {...} //这个来处理
runtime_error同样的操作。
当然,如果只抛出一种标准错误,还可以使用catch(const exception & e)
构造函数接受一个string对象作为参数,该参数提供了方法what()以C-风格字符串方式(cosnt char *)返回异常描述(由异常的构造函数提供)
new分配内存,不像抛出异常可以
pb = new(std::nothrow) Big[10000]; // nothrow定义在<new>中
15.3.9 异常、类和继承 P638
15.3.10 未处理异常
1.在带有异常规范的函数中引发,则必须与规范列表中的某种异常匹配
在继承层次结构中,类类型与这个类及其派生类的对象匹配,否则成为unexpected exception
默认情况下,程序异常终止,C++17摒弃
2.异常不是在函数中引发,或者函数没有异常规范,则必须捕获他,如果没有捕获,则称为
uncaught exception,默认情况下,程序终止。
未捕获异常不会导致程序立即终止,首先调用terminate(),默认情况下terminate()调用abort()函数。因此,可以修改terminate调用的函数来修改他之后的行为
任何情况下, std::terminate 调用当前安装的 std::terminate_handler 。默认的 std::terminate_handler 调用 std::abort 。
std::terminate_handler 是函数指针类型(指向不接收参数且返回 void 的函数)
这些函数为 std::set_terminate 安装,为 std::get_terminate 查询,并为 std::terminate 调用。
多次使用std::set_terminate,则terminate调用最后一次set_terminate调用设置的函数
修改terminate调用函数:
首先
#include < exception>
using namespace std;
然后:
void myQuit()
{
cout << “aaa”;
exit(5);
}
最后,在程序开头–main后第一句
set_terminate( myQuit)
这样没有捕获的异常,调用terminate(),后者调用myquit()
e.g.
#include <iostream>
#include <cstdlib>
#include <exception>
int main()
{
std::set_terminate(
[]()
{
std::cout << "Unhandled exception" << std::endl;
std::abort();
}
);
throw 1;
}
/*
Unhandled exception
*/
get_terminate()
#include <exception>
#include <iostream>
void my_terminate()
{
std::cout << "Terminate program" << std::endl;
std::exit(1);
}
int main()
{
std::terminate_handler current_handler = std::get_terminate();
if(current_handler = std::get_terminate()) //判断是否为默认的处理函数
{
std::set_terminate(my_terminate);
}
throw std::runtime_error("an error occuurred");
std::set_terminate(std::terminate);//继续使用默认的处理函数
system("pause");
return 0;
}
15.3.11 有关异常的注意事项 内存释放问题-第十六章-智能指针
func; FILE; LINE; 预处理符号,会被制定名称替换
编写自己的异常类
需要继exception来自定义。通过重载what函数,以返回异常信息。
class Myexception : public exception
{
public:
Myexception(string s)
{
error = s;
}
virtual const char* whar() const noexcept override
{
return error.c_str();
}
string error;
}
try
{
thorw Myexception;
}catch(cosnt Myexception& e) {
cout << e.what() << endl;
}
15.4 RTTI
运行阶段类型识别–Runtime Type Identification
旨在为程序运行阶段确定对象的类型提供一种标准方式。因为不同库可能互不兼容,无法互相识别。RTTI语言标准为此而生。
15.4.1 RTTI用途
例如,从基类派生了许多其他类,其中都有各自私有的方法,要确定哪个类对象赋给了指针,就需要识别类类型了
15.4.2 RTTI工作原理
C++有三个支持RTTI的元素
dynamic_cast运算符将使用一个指向基类的指针来生成一个指向派生类的指针,否则返回0–空指针
typeid返回一个指出对象类型的值
type_info结构存储了有关特定类型的信息
RTTI只能用于包含虚函数的类层次结构–基类-派生-派生,只有这种才能将派生类的地址赋给基类指针
1.dynamic_cast运算符 – 最常用的RTTI组件
不能回答指针指向的是哪类对象,但能回答,是否可以安全地将对象的地址赋给特定类型的指针
只有指针类型与对象类型(或对象的直接或间接基类的类型)相同的类型转换才安全,如a类赋给a类 或者派生类赋给基类指针
指向的对象(*pt)的类型为Type或者是从Type直接或间接派生而来的类型,则下面的表达式将指针pt转换为Type 类型的指针:
**Type *p = dynamic_cast<Type *>(pt)**否则,结果为0,即空指针。
RTTI可能默认关闭,嘚自己开
dynamic_cast也可用于引用:没有与空指针对应的引用值,因此无法使用。特殊的引用值来指示失败。当请求不正确时,dymamic_cast 将引发类型为 bad_cast 的异常,这种异常是从 exception 类派生而来的,它是在头文件 typeinfo中定义的。因此,可以像下面这样使用该运算符,其中rg是对Grand对象的引用。
#inlcude <typeinfo>
try{
Super & rs = dymamic_cast<Superb &>(rg);
}
catch(bad_cast &) {
}
2.typeid运算符和type_info类
typeid运算符能够确定两个对象是否为同种类型,类似sizeof,接受参数:类名,结果为对象的表达式
返回一个对type_info对象的引用,type_info是头文件typeinfo(C–typeinfo.h)中的类
type_info类重载了==和!=运算符
如typeid(Class A) == typeid(*ptr)
ptr指向A的话 则返回bool值true,ptr为空引发bad_type异常 。从exception类派生,位于typeinfo中
type_info类的实现随厂商而已,但都包含一个name()成员,用于返回一个随实现而已的字符串:通常是类的名称。
cout << typeid(*p).name() //显式p指针指向的对象所属的类定义的字符串
RTTI受人诟病
15.5 类型转换运算符
C语言中的 只是基于机器数上的转换–重新解读二进制位,可能无意义。
C++中添加四种类型转换运算符,加以限制
dymamic_cast A是B的可访问基类,不然传递值为空指针,使得类层次结构中进行向上转换(由于is-a,安全),而不允许其他转换 派生类指针转换为基类。
const_cast,只改变值为const或volatile,语法同上
const_cast< type-name> (expression)
除了const或volatile特征(有或者无)可以不同,type_name和expression的类型必须相同–也就是仅改变cosnt或volatile,其余不能改
e.g.
High bar;
const High * pbar = &bar;
High *pb = const_cast<High *>(pbar); //ok。 删除了const标签
const Low * pl = const_cast<const Low *> (pbar);//ng 试图从const high *->const low*
有些值多数时候常量,有时候必须可以修改,因此,声明为const,需要修改,const_cast
static_const 语法同上,仅当type_name可被隐式转换为expression所属的类型或expression可被隐式转换为type_name所属的类型时,才合法
如 A 时B的基类,则从A到B,从B到A都合法,其余违法
A *pa = static_cast<A *> (&B_obj);//向上转换
B *pa = static_cast<B *> (&A_obj);//向下转换, 从基类指针到派生类指针,在不进行显示类型转换,无法进行,但由于无需进行类型转换,便可以进行另一个方向的类型转换,因此向下转换合法。
同理,无需类型转换,枚举也可以被转换为整型,同样可以将基本数据类型之间转换。
reinterpret_cast 用于天生危险的类型转换,它不允许删除const。简化对依赖实现的跟踪。
语法同上,适用于依赖实现的底层技术,不可移植 不支持所有的类型转换,
可以将指针类型转换为足以存储指针的整形,不能将指针转换为更小的整形或浮点型。不能将函数指针转换为数据指针,反之亦然
第十六章 string类和STL
16.1 string类
string实际上时模板具体化basic_string的一个typedef,同时省略内存管理相关的参数
size_type是一个依赖于实现的整形 定义于string头文件
string类将string::npos 定义为字符串的最大长度 通常为unsigned int 的最大值
NBTS:null-terminated string 表示以空字符结束的字符串–传统的C字符串
P656 string初始化方式
C++新增的构造函数
string(string && str)类似于复制构造函数,导致新创建的string为str的副本,与复制构造函数不同的是,不能保证将str视为const。----移动构造函数,move constructor,
string(initializer_list< char>il)将初始化列表语法用于string类,
string aa = {‘f’, ‘f’}; 合法
string bb {‘f’,‘f’}; 合法
P659 string类输入
C-风格
cin>>info; //读一个单词
cin.getline(str, 100, ‘a’); //读取一行,100字符,读到a停止 忽略\n
cin.get(str, 100); 读一行,将\n留在队列中
string对象
cin>>
getline(cin, str, ‘f’); //读到 f停止
getline 忽略\n get则保留 ‘f’限定读取到的字符十个可选参数
区别:
string版本的getline()自动调整目标string对象的大小,使之刚好能够存储输入的字符
c风格的字符串的函数是istream类的方法,而string版本是独立的函数
对c风格字符串输入,cin是调用对象,而对于string对象的输入,cin是函数参数
自动调整输入大小的限制:
1.string对象最大允许长度的限制,string::npos制定,通常为max unsigned int值,大文件ng
2.程序可使用的内存。
string版本的getline从输入中读取字符,转存到string中,直到:
1.文件结尾,输入流的eofbit将被设置,方法fail()和eof()都将返回true
2.遇到分节字符(默认\n), 将分解字符从输入流中删除,并且不存储它
3.读取的字符数达到最大允许值,将设置failbit,fail()将单独返回true
输入流对象是一个统计系统,用于跟踪流的错误状态。
在这个系统中,检测到文件尾后将设置 eofbit寄存器,检测到输入错误时将设置failbit 寄存器,出现无法识别的故障(如硬盘故障)时将设置badbit寄存器,一切顺利时将设置goodbit 寄存器。第17章将更深入地讨论这一点。
string版本的opcrator>>()函数不断读取,直到遇到空白字符并将其留在输入队列中,而不是不断读取,直到遇到分界字符并将其丢弃。空白字符指的是空格、换行符和制表符,是任何将其作为参数来调用 isspace()时,该函数返回ture 的字符。
P662 find重载 返回索引 正向查找
rfind--参数最后一次竖线的位置
find_first_of 参数首次出现的位置
find_last_of 参数最后一次出现的位置
find_first_not_of,在字符串中查找第一个不包含在参数中的字符,
e.g.
string str("abcdf");
int a = str.find_first_not_of("abc", 0); //0可省略
//a = 3
find_last_not_of,在原字符串中最后一个与指定字符串(或字符)中的任一字符都不匹配的字符,返回它的位置
e.g.
string str("abcdf");
int a = str.find_last_not_of("hf");
npos变量是string类的静态成员,值是string 对象能存储的最大字符数。由于索引从0开始,所以它比最大的索引值大1,因此可以使用它来表示没有查找到字符或字符串。
自动调整大小
新增字符,可能占用了其他人的地方,可能需要分配新内存块,并将原有内容复制过去。实践中,C++实现分配一个比实际需求大的内存块,但还不够,则,程序将分配一个原来两倍的内存块。
capacity()返回当前分配的大小,reserve()请求的最小长度的内存块
fout.open(filename.c_str());
open要求使用C风格字符串作为参数,c_str返回一个指向C风格字符串的指针,
该字符串内容与用于调用c_str方法的string对象相同,因此可以打开一个名称存储在string对象中的文件
16.1.5字符串种类
string库基于一个模板类:
template<class chatT, class traits = char _traits< chatT>, class Allocator = allocator< charT> >
basic_string {…};
有多个具体化,都有typedef名称
typedef basic_string< char> string;
还有wchar_t, char16_t, char32_t
Template parameters
CharT - character type
Traits - traits class specifying the operations on the character type
Allocator - Allocator type used to allocate internal storage ,use new and delete
以上两个有预定义的模板
16.2智能指针模板类
让然可以使用 * 或-> 对智能指针解引用
行为类似于指针的类对象 auto_ptr C++17弃用 ,默认使用unique_ptr,分享使用shared_ptr
函数终止,内部生成的指针占据的栈内存将被释放,但是new出来的内存堆只能delete释放,不然一直被占用
16.2.1 使用只能指针 < memory>
三个智能指针模板–auto_ptr, unique_prt, shared_ptr都定义了类似指针的对象,可以将new获得的地址赋给这种对象,无论直接或间接。当只能指针过期时,其析构函数将使用delete释放内存。
auto_ptr模板中的构造函数 //C++17 弃
Template< class X> class auto_ptr {
public:
expolicit auto_ptr(Type * p) throw(); //显式构造函数 指针作为参数
};
auto_ptr< double> pd (new double> 其他两种语法相同
auto ptr = make_unique< Simple>(); //C++14, 若simple的构造函数需要参数,放在make_unique调用的圆括号中。
auto arr = make_unique<int[]>(10); int数组,10个大小
C++17后推荐make_unique
unique_ptr:
**get()方法返回被管理对象的普通指针:
void fun(Simple simple); //指向simple的指针
auto mysimpleptr = make_unique< Simple>();
fun(mysimpleptr.get() );
reset() 改成另一个指针
mysimpleptr.reset(); //释放资源并指向nullptr
在reset之后mysimpleptr那块地址已经被unique_ptr释放了,无法再继续使用
release()
断开unique_ptr与底层指针(最开始接触的指针)的链接。返回底层指针,然后将智能指针置为nullptr。资源仍在,获得底层指针的话仍然可以访问,
Simple simple = mysimpleptr.release();//智能指针release置为空,并返回底层指针
//使用获得指向资源的simple指针,此处为释放获得的simple指针
delete simple;
simple = nullptr;
std::move
使用移动语义将一个unique_otr移到另一个, 原本的设置为nullptr,
class Foo
{
unique_ptr< int> mData;
func(unique_ptr< int> data) : mData(move(data)) {}
}
Foo f( move(mysmartptr) );
int类型的unique_ptr无法指向double的
std::unique_ptr< int> foo (new int(10));
std::unique_ptr< int> bar (new int(20));
foo.swap(bar)
智能指针对象的操作有些类似常规指针,如解除引用 *pd, 访问结构成员 pd->data, 将他赋给指向相同类型的常规指针, 将它赋给另一个同类型的智能指针对象。
默认情况下,unique_ptr使用标准的nrew和delete,也可自定义
int * malloc_int(int value)
{
int *p = (int*)malloc(dizeof(int));
*p = value;
return p;
}
unique_ptr<int, decltype(free)*> myptr(malloc_int(42), free);
malloc_int() 分配内存,使用标准的free释放内存。不建议这样用,但是可以用来管理其他非内存资源,如文件,网络套接字。decltype(free)用于返回free()类型,模板参数用函数指针的类型,因此加了个 *
shared_ptr
不应创建两个指向同一个对象的shared_ptr,应该建立副本:
auto ptr = make_shared< Simple<(); //Simple对象的shared_ptr
shared_ptr< Simple> ptr2(ptr1); //ptr2 用ptr1 来创建副本
使用make_shared()创建,也可直接创建
由于引用技术,reset仅在最后销毁或重、重置,不支持release,可以使用**use_cout()**来查看共享统一资源的 shared_ptr实例数量。可以自定义分配和释放内存,但是不必将自定义deleter的类型定义为模板类型参数
shared_ptr< int > myptr(malloc_int(4), free);
强制转换shared_ptr的函数 const_pointer_cast()等四个 15.5章节
shared_ptr支持别名,允许一个shared_ptr与另一个shared_ptr共享一个指针(拥有的指针),但指向不同的对象(存储的指针),如指向一个对象的成员,同事拥有该对象本身
class Foo
{
Foo(int value) : mData(value) {}
int mData;
}
auto foo = make_shared< Foo> (42);
auto ptr = shard_ptr< int>(foo, &foo->mData);
仅当两个shared_ptr(foo 和ptr )都销毁,Foo对象才能销毁。
//template< class Y >
shared_ptr( const shared_ptr& r, element_type* ptr ) noexcept; 构造函数原型
拥有的指针用于计数,对其解引用或get,返回存储的指针
存储的指针用于大多数具体操作
weak_ptr
可包含由shared_ptr管理的资源,不直接处理shared_ptr管理的资源,但可以用来判断资源是否被关联的shard_ptr释放。
weak_ptr使用shard_ptr或者另一个weak_ptr作为参数,
为了访问weak_ptr保存的指针,需要将weak_ptr转换为shared_ptr
lock方法,返回一个shard_ptr,如果释放了关联的shared_ptr,则返回的shared_ptr为nullptr
创建新的shared_ptr实例,将weak_ptrzuowei shared_ptr
注意:
string vaction(“afhfhf”);
shared_ptr< string> pvac(&vaction>); //ng
pvac过期,delete将会作用于非堆内存,这是错误的
16.2.2 智能指针的注意事项
指向同一个内存两次的智能指针将会释放它两次,这不行,解决方法:
1.定义赋值运算符,执行深复制。这样两个指针将指向不同的对象,其中的一个对象是另一个对象的副本
2.建立所有权(ownership)概念,对于特定的对象,只能有一个智能指针可拥有它,这样只有拥有对象的智能指针的构造函数会删除该对象。然后,让赋值操作转让所有权。这就是用于auto_ptr和unique ptr 的策略,但unique_ptr 的策略更严格。
3.创建智能更高的指针,跟踪引用特定对象的智能指针数。称为引用计数(reference coumi)例如,赋值时,计数将加1,而指针过期时,计数将减1。仅当最后一个指针过期时,才调用delete。这是shared_ptr 采用的策略。
16.2.3 unique_ptr 相对于auto_ptr的好处
当一个函数返回一个临时unique_ptr指针,然后p接管临时指针的对象, 这是可以的,因为函数内的指针之后会被立即销毁,根本没有时间被其他函数访问
总之,将unique_ptr赋给另一个时,可以是临时右值,但是unique_ptr不能存在一段时间
unique_ptr 有new 和he delete[]版本
16.2.4 智能指针选择
程序使用多个指向同个对象的指针----shared_ptr
如,一个指针数组,并使用辅助指针来标识特定的元素
两个对象都包含指向第三个对象的指针
STL容器包含指针。STL算法支持赋值和赋值操作,用到了shared_ptr,不能使用unque_ptr和auto_ptr
不需要多个指向同一个对象的指针,使用unique_ptr。 new分配内存,并返回指向该内存的指针,将返回类型声明为unique_ptr也ok
shared_ptr 包含一个显示构造函数,将右值unique_ptr转换为shared_ptr,shared_ptr接管unique_ptr的对象
16.3 STL /《C++高级编程》 第16章
标准库概述
字符串:< string> < string_view>–字符串只读视图,替换const string&,切没有额外开销,不复制字符串。(章节2)支持Unicode和本地化 < locale>(章节19)
正则表达式:< regex>提供,简化文本的模式匹配(章节19)
I/O流:(章节13)
智能指针:< memory>(章节7) 普通的指针在free后分配的内run仍然可用,因此需要指向nullptr
异常:< exceptioin> (章节14)
数学工具:
时间工具:< chrono>(章节20) < ctime>
随机数: < random>(章节20)
初始化列表:< initializer_list> 便于编写参数可变的函数 func(initializer_list< int> t)
pair & tuple:< utility> 定义了pair 用于存储两种不同类型的元素–存储异构元素。< tuple>中tuple是pair的泛化,没有固定大小的序列,元组的元素可以是异构。tuple实例化的元素数目和类型在编译时固定不便(章节20)
optional,variant,any:< optional>存储制定类型的值,要么什么都不存储,可用于函数的参数或返回类型。 < variant>存储单个值(属于一组给定类型中的一种类型)或什么都不存储。< any>存储单个值,任意类型(章节20)
函数对象:实现函数调用运算符的类称为函数对象。可用作某些标准库算法的谓词。< functional>(章节18)
文件系统:< filesystem> 位于std::filesystem。允许编写可用于文件系统的可移植代码,使用它确定是目录还是文件,迭代目录内容,曹总路径,以及检索有关文件的信息。(章节20)
多线程:单线程< thread>中的thread。< atomic>的原子性,提供对一段数据的原子访问,避免多个线程读写同一个数据段。< conditioin_variable> 和< mutex> 提供了线程同步机制。如果只需要计算某个数据(可能在不同线程上),得到结果,且可以处理相应异常,< future>中的async和future比thread容易(章节23)
典型特质:< type_traits> 提供编译期间的类型信息,编写高级模板用到(章节22)
标准整数类型:< cstdint> 如int8_t跨病态需要(章节30)
容器:vector–对标数组。list–双向链表。forward_list前向列表。deque双端队列,array–c风格数组替代品。以上为顺序容器。
queue–FIFO队列。priority_queue优先队列。先按优先级,同级没顺序,每次操作需要重新排优先级。stack–栈。以上容器适配器adapter,狗仔在某种熟悉怒容器上的简单接口
set&multiset定义于 < set>中。保存元素的集合,类比数学概念,但是是按照一定顺序保存,而不是混乱的。每个元素唯一。当需要保证元素顺序,且插入删除操作数目和朝招操作数目接近,且都需要优化性能,使用set。不希望重复,也可用。向重复用multiset
map&multimap定义于< map>是一个关联数组。可用作数组。其中的索引可以是任意类型,**保存键/值对。按照顺序保存元素,按照键排序。**提供operator[]操作。multimap允许重复键。
set与map称为关联容器,存储了键和值。set的键本身就是值。会对元素排序。
hash,无序关联容器。上述set map的无序(unordered_)版本(C++标准定的,第三方可能用hash_map等来定义。插入删除和查找能以平均常量时间完成,最坏也是线性时间。查找比map或set块很多,数据量越大越明显。(章节17)
bitset定义于< bitset>中操作位
《C++高级编程4th》P350
算法:使用中介–迭代器来简介操作容器。(begin非const,cbegin-const,rbegin–反向,crbegin)(章节17,18)< algorithm> P352 https://zh.cppreference.com/w/cpp/algorithm
标准库缺什么:
多线程同时访问,不保准线程安全,没有提供任何泛型的树结构或图结构。只能自己实现或找其他库
STL提供了一组表示容器、迭代器、函数对象和算法的模板。
容器,一个与数组类似的单元,可以存储若干值。存储的类型必须相同
迭代器能够用来遍历容器的对象,与能够遍历数组的指针类似,是广义指针
函数对象是类似函数的对象,可以是类对象或函数指针(包括函数名,函数名称被用作指针)
STL 可以构造各种容器(包括数组,队列和链表),执行各种操作(查找,排序,随机排列)
STL 不是面向对象的编程,而是一种不同的编程模式---泛型编程 generic programming
16.3.1 模板类 vector
vector类提供了与第14章介绍的valaray和ArayTP 以及第4章介绍的aray类似的操作,即可以创建 vector对象,将一个vector对象赋给另一个对象,使用[]运算符来访问vector元素。
要使类成为通用的,应将它设计为模板类,STL正是这样做的———在头文件vector中定义了一个vector模板
int n;
vector<int> aa{n};
for( int i = 0; i < n; i++)
cout << aa[i] << end;
分配器,与string类似,各种STL容器模板都接收一个可选的模板参数,用来制定使用那种分配器对象来管理内存,vector 模板:
template<class T, class Allocator = std::allocator< T>>
class vector {…};
省略的话,默认使用allocator< T>,它可以使用new和delete
STL容器的基本方法
size–元素数目
swap–交换内容
begin–返回一个指向容器第一个元素的迭代器
end–返回表示超过容器尾的迭代器
迭代器:广义指针。它可以是指针,也可以是一个可对象执行类似指针的操作–如解除引用和递增–的对象
这样,STL能够为不同的容器类提供统一的接口。迭代器的类型是iterator的typedef 作用域为整个类
如,为vector的double类型规范声明一个迭代器
vector< double>::iterator pd;
vector< double> scores;
可以有以下操作:
pd = scores.begin(); //指向第一个元素
*pd = 22.3; //解除pd引用,并赋值给第一个元素
++pd; //指向下一个元素
自动类型推断C++11
vector< double>::iterator pd = scores.begin();
可以简化为:
auto pd = scores.begin();
超过结尾 past_the_end,指向容器最后一个元素 后面的那个元素
end()成员函数标识超过结尾的位置
vector特有的方法
push_back() 将元素放到vector尾巴
vector< double> scores;
double temp;
while(cin >> temp && temp >=0)
scores.push_back(temp);
erase() 删除制定区间的元素,接收两个迭代器参数 第一个区间起始,第二是区间个终止的后一个位置
(1)
iterator erase( iterator pos );(until C++11)
iterator erase( const_iterator pos );(since C++11)(until C++20)
constexpr iterator erase( const_iterator pos );(since C++20)
(2)
iterator erase( iterator first, iterator last );(until C++11)
iterator erase( const_iterator first, const_iterator last );(since C++11)(until C++20)
constexpr iterator erase( const_iterator first, const_iterator last );(since C++20)
Erases the specified elements from the container.
1) Removes the element at pos.
2) Removes the elements in the range [first, last).
Invalidates iterators and references at or after the point of the erase, including the end() iterator.
The iterator pos must be valid and dereferenceable. Thus the end() iterator (which is valid, but is not dereferenceable) cannot be used as a value for pos.
The iterator first does not need to be dereferenceable if first==last: erasing an empty range is a no-op.
Return value
Iterator following the last removed element.
If pos refers to the last element, then the end() iterator is returned.
If last==end() prior to removal, then the updated end() iterator is returned.
If [first, last) is an empty range, then last is returned.
insert(),接收三个迭代器参数,依次,插入的位置,第二三个迭代器定义了被插入的区间–通常是另一个容器对象的一部分
old_v.insert(old_v.begin(), new_v.begin() + 1, new_v.end() );
将new 除了第一个元素之外的所有元素 插入到old的第一个元素 前面
16.3.3 vector的其他操作
STL 定义了非成员 non-member函数来执行如搜索,排序。随机排序之类的操作,–定义一次,适用所有
e.g.
for_each(): 三个参数,前两个是定义容器中区间的迭代器,最后一个是指向函数的指针(更普遍,是一个函数对象)。将被指向的函数应用于容器区间中的各个元素,被指向的函数不能修改容器元素的值
因此可以替代for循环—避免显式使用迭代器变量
for(pr = books.begin(); pr !=books.end(); pr++)
showreview(*pr);
替换为:
for_each(books.begin(), books.end(), showreview);
Random_shuffle(),两个特定区间的迭代器参数,并随机排列区间内的元素–要求容器允许随机访问
sort(),也要求容器支持随机访问,
版本一,接收两个定义区间的迭代器参数,使用为存储在容器中的类型元素特别定义的 < 运算符,来操作区间内的元素,排序时,使用内置的 < 运算符 对值进行比较
如,下面升序排序
vector< int> coolstuff;
sort(coolstuff.begin(), coolstuff.end() );
如果容器元素是用户定义的对象,则必须自己提供能够处理对象类型的operator<(函数)
版本二, 为对象进行排序,需要三个参数,第三个是指向要使用的函数的指针–返回值使用bool值表示顺序是否正确
sort(begin,end,func) ;//func 排序函数
全排序 total ordering: a<b 和a>b都不成立,则a = b
完整弱排序 strict weaking ordering, 上述情况不一定,可能相同,也可能只是某方面相同(因为是对象)
16.3.4 基于范围的for循环 C++11
double prices[5] = {1.1, 1.2, 1.3, 1.4, 1.5};
for(double x : prices)
cout << x << endl;
声明了与容器相同的变量,并指出了容器的名称
因此 for_each(books.begin(), book.end(), show);
转换,for(auto x : books) show;
for_each 不可改变容器内容, 基于范围的for循环可以,诀窍是指定一个引用参数
for (auto & x : books) func–改变内容的函数
16.4 泛型编程
STL 是一种泛型编程。
面向对象编程关注的是编程的数据方面,泛型编程关注的是算法。
共同点是为了抽象和代码复用
16.4.1 为何使用迭代器
模板使得算法独立于存储的数据类型,迭代器使得算法独立于使用的容器
模板提供了存储在容器中的数据类型的通用表示,因此还需要遍历容器中的值的通用表示,迭代器就来了
list< double>::iteraotr pr;
按功能强弱,定义了多种级别的迭代器
C++ 将operator++ 作为前缀, operator++(int)作为后缀版本--其中参数永远不会使用,所以无名称
iterator & operator++()
{
pt = pt->p_next;
return *this;
}
iterator operator++(int)
{
iterator tmp = * this;
pt = pt->p_next;
return tmp;
}
STL: 基于算法需求,设计基本迭代器的特征和容器特征
首先,每个容器类定义了相应的迭代器类型,对于某个类,迭代器可能是指针,也可能是对象,迭代器提供所需的操作,如*和++。
其次,每个容器类都有一个超尾标记,当迭代器增加到超尾容器的最后一个值后,这个值将被赋给迭代器。每个容器类都有begin()和end()方法,都有++操作
作为编程风格,最好避免直接使用迭代器,尽可能使用STL函数来处理细节
16.4.2迭代器类型/《C++高级编程4th–C17》
http://t.csdn.cn/yY4zd
http://t.csdn.cn/2CqTD
《c++高级编程》p362
STL定义了5种:输入/输出迭代器,正向/双向迭代器,随机访问迭代器
都可以执行解除引操作,进行比较。如果两个迭代器相同,则对他们解除引用后得到的值相同
流的迭代器,容器的迭代器
1.输入迭代器
可被程序用来读取容器中的信息对输入迭代器解除引用将使得程序能读取容器中的所有值,不一定可被修改。 基于输入迭代器的算法 不能保证第二次遍历时,之前的顺序不变,之前的数据可被解除一次,因此不依赖前一次遍历的迭代器值,也不依赖本次遍历中前面的迭代器值。 输入迭代器 可以递增,不能倒退
2.输出迭代器 支持 前缀和后缀
将信息从程序输出给容器。解除引用,为了让程序修改容器的值,而不是读取。
单通行,只读算法–输入迭代器;只写算法–输出迭代器
3.正向迭代器 forward iterators 支持 前缀和后缀
只使用++运算符遍历容器,与上两个类似。每次向前move forward 一个元素
不同的是,总是按照相同的顺序遍历,递增后的正向迭代器,仍然可以对前面的迭代器值解除引用,并可以得到相同的值,多次通行成为可能
4.双向迭代器 具有正向迭代器的所有特性,同时 支持 前缀和后缀 递减运算符
5.随机访问迭代器-等同于普通指针
具有双向迭代器的所有特性,同时支持随机访问的操作和对元素排序的关系运算符
每个支持迭代器的容器都有成员iterator,reverse_iterator,以及其const_(只读)版本。根据容器类型起到以上五种中特定的功能。 如vector中iterator为随机访问迭代器,list中iterator为双向迭代器。每个容器也提供begin end及其const,reverse版本
16.4.3迭代器层次结构
正向包含输入输出 双向包含正向, 随机包含双向
目的,使用要求最低的迭代器,适用于容器的最大区间
16.4.4 概念、改进和模型 --略过
假设要将信息复制都显示器上,如果有一个表示输出流的迭代器,则可以使用copy()。STL为这种迭代器提供了ostteam_iterator模板。用STL的话来说,该模板是输出迭代器概念的一个模型,它也是一个适配器adapteor–一个类或者函数,可以将一些其他接口转换为STL使用的接口。可以通过包含头文件iterator,并使用下面的声明来创建这种迭代器
#include < iterator>
ostream_iterator<int, char> out_iter(cout, " ");
out_iter迭代器现在是一个接口,可以使用cout来显示信息
第一个模板参数指出被发送给输出流的数据类型。第二个模板参数指出了输出流使用的字符类型(char或者wchar_t)。构造函数的第一个参数(这里是cout)指出了要使用的输出流,也可以是用于文件输出的流,最后一个字符串参数是在发送给输出的流的每个数据项后显示的分隔符。
*out_iter++ = 15; //works like cout << 15 << " ";
这意味着将 15 和由空格组成的字符串发送到cout 管理的输出流中,并为下一个输出操作做好了准备。可以将copy()用于迭代器,如下所示:
copy(dice.begin(), dice.end(),out_iter);//copy vector to output stream
也可以直接使用迭代器
cout(dice.begin(), dice.end(), ostream_iterator<int, char>(cout , " " ) );
// <int, char>中 char可以省略, int 为要输出的内容类型
copy(istream_iterator<int, char>(cin), istream_iterator<int, char>(), dice,begin() );
第一个参数指出要读取的数据类型,第二个–输入流要使用的字符类型, 构造函数的参数cin指出由cin管理输入流。
若省略构造函数参数,如cin 用于表示因某种原因输入失败而停止输入的输入流尾巴 上述代码表示从输入流中读取,直到文件结尾、类型不匹配或出现其他问题为止。
Class template std::ostream_iterator
template< class T, class CharT = char, class Traits = std::char_traits<CharT>>
class ostream_iterator; (since C++17)
ostream_iterator( ostream_type& stream, const CharT* delim ); (1)
ostream_iterator( ostream_type& stream ); (2)
1) 以 stream 为关联流并以 delim 为分隔符构造迭代器。
2) 以 stream 为关联流并以空指针为分隔符构造迭代器。
参数
stream - 此迭代器所访问的输出流
delim - 在每次输出后插入流的空终止字符串
#include <iostream>
#include <iterator>
#include <algorithm>
#include <numeric>
int main()
{
std::ostream_iterator<char> oo {std::cout};
std::ostream_iterator<int> i1 {std::cout, ", "};
std::fill_n(i1, 5, -1);
*oo++ = '\n';
std::ostream_iterator<double> i2 {std::cout, "; "};
*i2++ = 3.14;
*i2++ = 2.71;
*oo++ = '\n';
std::common_iterator<std::counted_iterator<std::ostream_iterator<float>>,
std::default_sentinel_t>
first { std::counted_iterator{std::ostream_iterator<float>{std::cout," ~ "}, 5} },
last { std::default_sentinel };
std::iota(first, last, 2.2);
*oo++ = '\n';
}
其他迭代器
reserve_iterator, back_insert_iterator, front_insert_iterator, insert_iterator
反转
反向打印。vector类有rbegin()的成员函数和rend()的成员函数,前者返回一个指向超尾的反向迭代器,后者返回一个指向第一个元素的反向迭代器。,因为对迭代器执行递增操作将导致它被递减,所以可以使用下面的语句来反向显示内容:
copy(dice.rbegin(), dice.rend(), out_iter);//display in reverse order
copy(casts, casts + 10, dice,begin() );
上述copy方法,将内容从dice容器初始位置开始覆盖内容
back_insert_iterator, front_insert_iterator, insert_iterator 三个插入迭代器,不会覆盖已有。并使用自动内存分配来确保新信息存储
insert_iterator将元素插入到insert_iterator构造函数参数制定的位置 前面
back_insert_iterator 只允许尾部快速插入--一种时间固定的算法,vector满足 针对性强,块
front_insert_iterator 值允许起始位置时间固定插入,vector不行,queue满足
这些迭代器将容器类型作为模板参数,实际容器标识作为构造函数参数,名为dice的vector<int> 容器创建一个back_insert_iterator:
template< class Container > class back_insert_iterator; //模板
back_insert_iterator< vector<int> > back_iter(dice);
//ostream_iteraotr<int, char> out_iter(cout, " "); 类比
//front_insert_iterator类似
#include <iostream>
#include <iterator>
#include <algorithm>
#include <vector>
int main()
{
std::vector<int> v;
std::generate_n(
std::back_insert_iterator<std::vector<int>>(v), // C++17: std::back_insert_iterator(v)
10, [n=0]() mutable { return ++n; } // or use std::back_inserter helper
);
for (int n : v)
std::cout << n << ' ';
std::cout << '\n';
}
声明容器类型的原因:迭代器必须使用合适的容器方法
insert_iterator< vector > insert_iterator(dice,dice.begin() ); //dice是个vector名
16.4.5 容器种类《c++高级编程》C17.2+
容器是存储其他对象的对象,被存储的对象必须是同一种类别,可以OOP对象,也可以是内置类型值
标准容器库对元素使用值语义,在输入元素时保存元素的一份副本,通过赋值运算符给元素赋值,通过析构函数销毁元素。因此要保证他们可以复制的。请求容器中的元素,会返回所存副本的引用。
引用语义。可存储元素的指针(最好智能指针)而不是元素本身。当容器复制指针时,结果仍然指向同一元素。
或者容器中存储reference_wrapper。可用std::ref()或std::cref()创建reference_wrapper。使引用变得可复制。《c++高级编程》p361 < functional>
补充插入reference_wrapper-< functional>
容器存储引用
std::reference_wrapper 是一个包装类,它可以在需要按引用传递对象时用作替代。
在标头 <functional> 定义
template< class T > class reference_wrapper;
std::reference_wrapper 是包装引用于可复制、可赋值对象的类模板。它常用作将引用存储入无法正常保有引用的标准容器(类似 std::vector )的机制。
特别是, std::reference_wrapper 是围绕到类型 T 的对象引用或函数引用的可复制构造 (CopyConstructible) 且可复制赋值 (CopyAssignable) 的包装器。 std::reference_wrapper 的实例是对象(它们可被复制或存储于容器),但它们能隐式转换成 T& ,故能以之为以引用接收底层类型的函数的参数。
若存储的引用可调用 (Callable) ,则可以相同参数调用 std::reference_wrapper 。
辅助函数 std::ref 与 std::cref 常用于生成 std::reference_wrapper 对象。
//得到存储的引用
constexpr T& get() const noexcept;
#include <iostream>
#include <functional>
void modify(int& x) {
x = x * 2;
}
int main() {
int a = 5;
std::reference_wrapper<int> ref_a(a);
modify(ref_a.get());
std::cout << "a: " << a << std::endl; // 输出: a: 10
}
operator() ( ArgTypes&&... args ) const
参数
args - 传递给被调用函数的参数
返回值
被调用函数的返回值。
#include <functional>
#include <iostream>
void f1()
{
std::cout << "调用了到函数的引用\n";
}
void f2(int n)
{
std::cout << "以 " << n << " 作为实参调用了绑定表达式\n";
}
int main()
{
std::reference_wrapper<void()> ref1 = std::ref(f1);
ref1();
auto b = std::bind(f2, std::placeholders::_1);
auto ref2 = std::ref(b);
ref2(7);
auto c = []{std::cout << "调用了 lambda 函数\n"; };
auto ref3 = std::ref(c);
ref3();
}
/*
输出
调用了到函数的引用
以 7 作为实参调用了绑定表达式
调用了 lambda 函数
*/
vector 默认0初始化
保存在连续空间中,数组的一种表示,自动内存管理,随机访问,反转容器
除非其他类型更好,不然默认这个好用
for_each(dice.begin(). dice.end(). show); //display in roder
for_each(dice.rbegin(), dice.rend(). show);//dispaly in reserved order
//rbegin..返回的迭代器都是类级类型 reserve_iterator,这样的迭代器递增,将导致反向遍历可反转容器
#include <iostream>
#include <vector>
#include <algorithm>
#include <iterator>
using namespace std;
int main()
{
// vector<int> ina{ {10, 155}};
// vector<int> inb{10,160};
// vector<int> in;
vector<int> in(10,100);
vector<int> it(10,160);
vector<int>::iterator b =in.begin();
vector<int>::iterator e = end(in);
for_each(b, e, [](int j) {cout << j << " ";});
cout << endl;
//in.assign(5,50); //删除所有,重新分配5个50
it.swap(in);
e.base(); //emm,竟然能过
for_each(in.cbegin(), in.cend(), [](int j) {cout << j << " ";});
cout << endl;
for(auto iter = begin(it); iter != it.end(); ++iter)
{
cout << *iter << " ";
}
cout << endl;
cout << it.size() << " " << in.size() << endl;
system("pause");
return 0;
}
/*
输出:
100 100 100 100 100 100 100 100 100 100
160 160 160 160 160 160 160 160 160 160
100 100 100 100 100 100 100 100 100 100
10 10
*/
}
| at() | 执行边界检查,可能抛出out_of_range异常。指定访问的元素.等同于operator[]运算符(返回引用) |
| front/back | 返回第一个和最后一个元素的引用 |
| push_back() | 添加元素,并为新元素分配空间,动态增长 |
| pop_back() | 尾部删除元素,不会返回已删除的 |
| assign() | assign(5, 100)删除所有元素,并添加5个100 / assign( {1,2,3,4,5}) |
| swap() | a.swap(b) a和b交换元素 |
| insert() | 指定位置前插入 |
| erase() | 删除任意位置元素。一个迭代器的元素,两个迭代器范围的元素 |
| clear() | 删除所有元素 remove-erase-idiom |
| emplace | 在指定位置(迭代器指出)分配空间,添加元素,之后元素后移。返回指向被安置的元素的迭代器 |
| emplace_back | 在末尾假如元素,返回插入元素的引用 |
| size | 已有元素个数 |
| capacity | 容量 |
每个支持迭代器的容器都有成员iterator,reverse_iterator,以及其const_(只读)版本。根据容器类型起到以上五种中特定的功能。 如vector中iterator为随机访问迭代器,list中iterator为双向迭代器。每个容器也提供begin end及其const,reverse版本
从迭代器中或取指针:
int* p = &v[5] //取数组地址
int* p = v.data() //返回指向作为元素存储工作的底层数组的指针 如vector(其成员函数)等顺序容器,可以对标数组的
int *p = v.begin().base()//reverse_iterator 提供 base()方法 返回指针
智能指针,用get方法
vector中元素为对象,迭代器使用->调用对象方法或访问对象成员
迭代器全部失效。解决办法:P372
1.插入删除导致的,将erase或insert函数返回的新迭代器替换原有
2.容器的begin end重新获取起始位置
3. 使用容器的size(已保存的)或capacity(可以保存的)检查迭代器是否失效,失效的话重新分配内存或调整容量。
当vector扩容时。他会整体复制到新内存。因此一开始申请时,他会分配更多的内存待命
reserve预先确定分配能保存制定数目足够的空间。或者构造函数中resize, assign指定大小的容器
vector< bool>特化来按位保存bool数组。可以用flip()方法反转位,特化后事项是一个名为reference的类。operator[] at()方法访问,返回reference对象,它实际是boo值的代理,不可以取地址---------慢 ,不建议, bitset代替
#include <iostream>
#include <exception>
#include <vector>
using namespace std;
int main()
{
vector<int> v {1,2,3 } ;
/*
vector<string> v {5, "haha"};
vector<int> v (5, 55);
*/
try{
cout <<v.at(55) << endl;
throw;
}catch(const exception& e)
{
cout << " error------" << e.what() << endl;
}
vector<int> w (50,100);
//尽量iter++.更快
//auto iter = w.begin(w);
vector<int>::iterator iter = w.begin(); //begin(w) 也行
*++iter = 5; //可能存在隐患,因为可能迭代器指向end()
cout << *iter << endl;
cout << *--iter << endl;
cout << w.at(5) << endl;
return 0;
}
/*
执行结果:
error------vector::_M_range_check: __n (which is 55) >= this->size() (which is 3)
5
100
100
*/
移动语义。将一个内存移交给另一个对象管理, 避免大规模复制。P371
将方法内定义的变量或对象返回并传值给方法外,不支持移动语义就会调用复制赋值运算符,移动语义可以提升性能。如push_back(T& val) 复制则push_back(T&& val)的移动赋值方法将鼻尖调用复制函数。
v.push_back(w)或者v.push_back( move(w) ) 都可以触发。移动后w状态不确定,可以使用clear返回确定状态,这样可以再次使用w
deque --< deque>中 双端队列 double_ended queue 支持随机访问 用的少
list 双链表
支持++ --来遍历
void splice(iterator pos, list<T, Alloc> x)
insert将原始区间的副本插入到目标地址,
splice 将原始区间移动到目标地址,之后x为空,全部并到pos指向的位置,之后指向one的迭代器仍然有效,当splice()将它重新定位到调用splice的对象后,迭代器仍然指向相同的元素
unique()只能将相邻的相同值压缩为单值,
非成员sort不能用于list
forward_list 单链表 只需要正向迭代器
queue FIFO
templata< class T, class Container = deque< T> > class queue;
T是queue中数据类型,conatiner是底层容器
是一个适配类,让底层类(默的deque)展示典型的队列接口,不允许随机访问,不允许遍历
priority_queue–< queue>
template< class T, class Container = vector< T> ,class Comare = less< T> >;
T指定数据类型,container制定底层容器,vector,deque。支持随机访问
less是个类模板,operator< 比较。 还有>
支持的操作同queue。最大元素被移动到队首。内部区别在于,默认的底层类时vector,可以修改用于确定哪个元素放到队首的比较方式,方法是提供一个可选的构造函数参数
priority_queue< int> pg1; //默认版本
priority_queue< int> pg2(gerater< int>);//使用geater< int> 排序
stack--< stack>
template<class T, class Container = deque< T> > class stack;
底层容器是vector,list或deque
与queue类似。也是一个适配器类,底层类默认vector, 提供了典型的栈接口
array 长度是固定的,没有调整大小的操作
16.4.4 关联容器 – associative container
将值与键关联。使用键来查找值,如值可以是一对信息的结构,但其中一个作为标识–键
快速访问元素,允许插入,但是不能制定插入位置–关联容器有用于确定放置位置的算法。
数据结构通常是树
4种关联容器:Set, multiset, map, multimap,前两个在< set> 后一个在< map>中
最简单的是set 值类型与键相同,键唯一,集合中不会有多个相同的键。值就是键
multiset类似set,可能多个值对应一个键。如值和键的类型为int, multiset对象包含的内容可以是1、2、2、3、5、7、7
map中,值和键类型不同,键唯一,一个键对应一个值,multimap与map类似,一个键对应多个值
pair < utility>
将两个不同类型值组个,first,second访问 ==, 比较两成员数据
pair< string, int> mypair(“hello”, 5);
pair<string, int> myotherpair;
myotherpair.first = “hello”;
myother.second = 5;
pair<string, int> mythirdpair(myotherpair); //复制构造函数
pair<int ,double> apair = make_pair(5,10.10); //智能指针?
auto asecondpair = make_pair(5, 10.10); //从参数推断
auto asecondpair = pair(5, 10.10);//C++17引入的构造函数模板参数推导
结构化绑定C++17引入,将pair分解为单独变量
auto< a, b> = mypair; //可以单独使用a, b
set 集合
与map非常类似,接口与map几乎完全相同。set没有operaor[],insert_or_assign,try_emplace()。但set保存的不是键值对,值本身就是键。
如果希望信息没有显式的键,且希望进行排序(不包含重复)一边进行快速插入,查找,删除。可以考虑set。不能修改set中元素的键/值,因为会破坏顺序
是关联集合,可翻转,可排序,键唯一。与vector和list类似
set< string> A;// a set of string objects
第二个模板参数可选,用于指示用来对键进行排序的对比函数或对象,默认情况下使用less< > :set<string, less< string> > A; //老式隐式
(1)
template< class InputIt >
set( InputIt first, InputIt last, const Allocator& alloc) : set(first, last, Compare(), alloc) {}
范围构造函数。构造拥有范围 [first, last) 内容的容器
(2)
set( std::initializer_list< value_type> init, const Allocator& alloc ) : set(init, Compare(), alloc) {}
initializer_list 构造函数。构造拥有 initializer_list init 内容的容器
(3)
复制构造函数。以 other 内容的副本构造容器。
set( const set& other );
移动构造函数。用移动语义构造拥有 other 内容的容器
set( set&& other );
参数
alloc - 用于此容器所有内存分配的分配器
comp - 用于所有关键比较的比较函数对象
first, last - 复制元素的来源范围
other - 将用作初始化容器元素所用源的另一容器
init - 初始化容器元素所用的 initializer_list
类型要求
-InputIt 必须符合老式输入迭代器 (LegacyInputIterator) 的要求。
-Compare 必须符合比较 (Compare) 的要求。
-Allocator 必须符合分配器 (Allocator) 的要求。
map
需要根据键保存和获取数据时,需要按特定顺序保存元素时,使用。
template<
class Key,
class T,
class Compare = std::less< Key>,
class Allocator = std::allocator<std::pair<const Key, T>> > class map;
map<int, Data> dataMap;
map<int, int> ={ {1,2},{2,3}} //统一初始化
插入元素:
insert() 自动判定位置,只需要提供键和值即可。键值对必须是pair对象或者initializer_list,返回类型是迭代器和布尔值组成的pair,这个干原因:如果键已存在,insert不会改写元素值,bool值反应是否成功。迭代器引用的是map中待制定键的元素(根据是否插入成功,它可能是新值或者旧值)
插入 value
std::pair<iterator, bool> insert( const value_type& value );
插入 value 到尽可能接近正好在 pos 之前的位置
template< class P >
iterator insert( const_iterator pos, P&& value );
iterator insert( const_iterator pos, value_type&& value );
按范围插入。
template< class InputIt >
void insert( InputIt first, InputIt last );
void insert( std::initializer_list< value_type> ilist );
map<int , Data> datamap;
auto ret = dataMap.insert( {1, Data(4) } ); //使用初始化列表
这里可以用ret.second (因为是pair)来判断是否成功了
auto ret = dataMap.insert( make_pair(1, Data(4) ) ); //使用pair对象
if语句初始化器,同事插入并检查
if(auto result = dataMap.insert((1, Data(4) )); result.second) {
//success}
else{ //fail }
组合结构化绑定
if( auto [ iter, success] = dataMap.insert( {1, Data(4) } ); success)
//…
insert_or_assign()
template < class M>
std::pair<iterator, bool> insert_or_assign(key_type&& k, M&& obj);
k - 用于查找和若找不到则插入的键
hint - 指向将插入新元素到其前的位置的迭代器
obj - 要插入或赋值的值
若插入发生则 bool 组分为 true ,若赋值发生则 bool 组分为 false 。迭代器组分指向插入或更新的元素。
若给定键元素已经存在,则会替换旧值,而insert不会这么干、
ret = dataMap.insert_or_assign(1, Data(7) );
if(ret.second) { …}
operator[]
键值分别指定,总是成功:给定键没有元素值,就创建。已存在,就替换新值
map<int , Data> datamap
dataMap[1] = Data(4);
dataMap[1] = Data(6); //6 替换4
emplace
template< class… Args >
std::pair<iterator,bool> emplace( Args&&… args );
若容器中无拥有该关键的元素,则插入以给定的 args 原位构造的新元素到容器。
返回由指向被插入元素,或若不发生插入则为既存元素的迭代器,和指代插入是否发生的 bool (若发生插入则为 true ,否则为 false )。
emplace_hint//以上俩与vector中通,若已存在,则不会改现有
template <class… Args>
iterator emplace_hint( const_iterator hint, Args&&… args );
hint - 指向将插入新元素到其前的位置的迭代器
插入元素到尽可能靠近正好在 hint 之前的位置。原位构造元素,即不进行复制或移动操作。
try_emplace()//键不存在,则原始位置插入,如果已经有,则啥都不做
template <class… Args>
pair<iterator, bool> try_emplace(key_type&& k, Args&&… args);
template <class… Args>
iterator try_emplace(const_iterator hint, const key_type& k, Args&&… args);
map迭代器,引用的是键值对,second来访问值
for(auto iter = cbegin(dataMap); iter != cend(dataMap); ++iter) {
cout << iter->second.getValue() << endl; }
#include <iostream>
#include <utility>
int main()
{
auto p = std::make_pair(1, 3.14);
std::cout << '(' << std::get<0>(p) << ", " << std::get<1>(p) << ")\n";
std::cout << '(' << std::get<int>(p) << ", " << std::get<double>(p) << ")\n";
}
/*
(1, 3.14)
(1, 3.14)
*/
#include <iostream>
#include <iterator>
#include <map>
#include <utility>
#include <string>
using namespace std;
int main()
{
map<int, string> v;
v.insert(make_pair(5,"hello world"s));
v.emplace(make_pair(5, "haha"s));
auto ret = v.begin();
//++ret;
//auto ret = v.insert_or_assign(1,"hello world"s);
cout << ret->second << endl;
v.insert_or_assign(5,"china");
ret = v.begin();
cout << ret->second << endl;
cout <<v[5] << endl;
map<string, string> w ={{"enen", "aa"}};
auto iter = w.begin();
cout << w.begin()->second << endl;
return 0;
}
查找元素
非const情况, operator[] 查找,好处在于返回可以直接使用和修改的元素引用,不用考虑从pair对象获取值。 只能操作键为int的
find()
template< class K > iterator find( const K& x );
参数
key - 要搜索的元素键值
x - 能通透地与键比较的任何类型值
返回值
指向键等于 key 的元素的迭代器。若找不到这种元素,则返回尾后(见 end() )迭代器。
auto iter = map.find(1); // 1 键值
若只想知道是否有给定键的元素,count(),返回给定键元素个数。map因为键唯一,所以返回值不是0就是1. map.count(1)
删除元素
iterator erase( iterator pos );(1)
iterator erase( const_iterator pos );(2)
iterator erase( const_iterator first, const_iterator last );(3)
size_type erase( const Key& key );(4)
从容器移除指定的元素。
1,2) 移除位于 pos 的元素。
3) 移除范围 [first; last) 中的元素,它必须是 *this 中的合法范围。
4) 移除键等价于 key 的元素(如果存在一个)。
迭代器 pos 必须合法且可解引用。从而 end() 迭代器(合法,但不可解引用)不能用作 pos 所用的值。
参数
pos - 指向要移除的元素的迭代器
first, last - 要移除的元素范围
key - 要移除的元素键值
返回值
1-3) 后随最后被移除的元素的迭代器。
4) 被移除的元素个数。
节点句柄
所有有序和无序的关联容器都被称为基于节点的数据结构。C++17 STL中以句柄的形式,提供节点的直接访问。确切类型不知,每个容器都有node_type的类型别名,它指定容器节点句柄的类型。只能移动,是节点中存储元素的所有者。提供对键和值的读写。
使用**extract()**提取节点句柄,使用insert()插入节点句柄。可以江数据从一个关联容器传递给另一个关联容器,而不发生复制或移动。甚至可以从map到multimap,set到multiset
map<int, Data> dataMap2;
auto extractNode = dataMap.extract(1);
dataMap2.insert(std::move(extractedNode) );
merge.试图合并两个关联容器,无法移动的留在源容器中。
map src
map dst
dst.merge(src)
map<int, string> m{{1, "mango"}, {2, "papaya"}, {3, "guava"}};
auto nh = m.extract(2);
nh.key() = 4;
m.insert(move(nh));
// m == {{1, "mango"}, {3, "guava"}, {4, "papaya"}}
成员类型
成员类型 定义
key_type(仅限 map 容器) 在节点存储的关键
mapped_type(仅限 map 容器) 在节点存储的元素的被映射部分
value_type(仅限 set 容器) 在节点存储的元素
allocator_type 销毁元素时使用的分配器
操作:
/* 节点把柄 /& operator=(/ 节点把柄 */&& nh); //从 nh 获得容器元素的所有权;
参数
nh - 同类型的节点把柄(不必属于相同容器)
返回
*this
nh.empty() 在节点把柄为空时返回 true,否则返回 false。
nh.key();//仅map。返回到此节点把柄管理的容器元素对象中的 value_type 子对象的 key_type 成员的非 const 引用。在节点把柄为空时行为未定义。–key
nh.mapped(); //仅map返回到此节点把柄管理的容器元素对象中的 value_type 子对象的 mapped_type 成员的引用。在节点把柄为空时行为未定义。–value
nh.value();//仅set 返回到此节点把柄管理的容器元素对象中的 value_type 子对象的引用。在节点把柄为空时行为未定义。
multimap
支持统一初始化
std::multimap< std::string, std::string> aa;
可反转,经过排序的关联容器,键和值类型不同,一个键可以于多个值关联
multimap<int, string> codes; // 键类型:int,存储的值类型:string
第三个模板参数可选,指出用于对键进行排序的比较函数或对象。默认情况下为模板less< >,将键类型作为参数
不提供operator[]和at(),不支持insert_or_assign(),不支持try_emplace()
插入操作总会成功,因此添加单个元素的insert返回iterator而不是pair
查找
count(), 接收键作为参数,并返回具有该键的元素个数
lower_bound,upper_bound将键作为参数,返回给定键的第一个后最后一个的后一个元素对应的iterator
equal_rnge将键作为参数,返回两个迭代器,表示区间与该键匹配。返回值封装在pair对象中,这里的pair的两个参数都是迭代器。分别对应lower_bound,和upper_bound返回的iterator
#include <iostream>
#include <iterator>
#include <map>
#include <utility>
#include <string>
using namespace std;
int main()
{
map<int, string> v;
v.insert(make_pair(5,"hello world"s));
v.emplace(make_pair(5, "haha"s));
auto ret = v.begin();
//++ret;
//auto ret = v.insert_or_assign(1,"hello world"s);
cout << ret->second << endl;
v.insert_or_assign(5,"china");
ret = v.begin();
cout << ret->second << endl;
cout <<v[5] << endl;
map<string, string> w ={{"enen", "aa"}};
auto iter = w.begin();
cout << w.begin()->second << endl;
iter = w.find("enen");
cout << iter->second << " " << w.count("nen") << endl;
auto nh = w.extract("enen");
nh.mapped() = "oo";
nh.key() = "hahah";
w.insert(std::move(nh));
auto nhh = w.extract("een");
cout << nhh.empty() << endl;
cout << w.begin()->second << endl;
multimap<std::string, std::string> x {
{"a","aa"s},{"a","aaa"s},{"a","aaaa"s},
{"b","bb"s},
{"c","ccc"s},{"b","bbb"s}
};
x.insert(std::make_pair("d", "ddddd"));
auto [s, e] = x.equal_range("a");
for(auto iter = s; iter != e; ++iter)
cout << iter->second << endl;
system("pause");
return 0;
}
/*
hello world
china
china
aa
aa 0
1
oo
aa
aaa
aaaa
*/
e.g.
pair<multimap<ketype, string>::iterator, multimap<kekytype, string>::iterator> range
= codes.equal_range(718);//打印codes对象中区号718的所有城市
std::multimap<keytype, std::string>::iterator it;
for( it = range.first; it != range.second; ++it)
ocut << (*it).second << endl;
或
auto range = codes.equal_range(718);
for( it = range.first; it != range.second; ++it)
ocut << (*it).second << endl;
关联容器--自动有序
16.4.5 无序关联容器/哈希表
与关联容器一样,无序关联容器也将值与键关联起来,并用键查找值。底层的差别:关联容器基于树结构,无序关联容器基于哈希表–旨在提高添加和删除元素的速度以及提高查找的效率
有四种:unordered_set, unordered_multiset, unordered_map, unordered_multimap
哈希表的实现通常使用某种形式的数组,数组中的每个元素称为桶,每个桶有特定的数值索引。哈希函数将键转换为哈希值,再转换为桶索引,与整个键关联的值再桶中存储。
哈希函数结果不一定唯一,可能会冲突,二重哈希,线性链(虽然没指定,但整个常用)-----数据结构。
使用线性链,桶不直接包含与键关联的数据值,而是包含一个指向链表的指针,链表包含特定桶中的所有数据值。
C++提供了部分类型的哈希函数,也可以自己写。
其他容器
bitset
set, reset, flip改变单个位的值, operator[] 访问单个位
运算符:& | ^ ~ << >> 组合
16.5 函数对象 < functional>
《C++高级编程》-Chapter 18
很多STL算法都使用函数对象–函数符functor,函数符是可以以函数方式与 () 结合使用的任意对象。
重载了operator()运算符的类对象–定义了函数operator() ()的类
算数函数对象 包括 函数名, 指向函数的指针 。
plus, minus,multiplies,divides,modulus.(还有取反)对实际运算符的包装
template< class T >struct plus;
plus< int> myPlus;
int res = myPlus(14, 5);
更好的用处是可以将函数对象以回调形式传递给函数。(回调,函数作为参数传递给另一个函数)
double mult = fun(cbegin(nums), cend(nums), plus< int>() );
//plus< int>(), 创建一个新的plus仿函数对象,并通过int实例化.
确保容器能够被对应的运算符操作
透明运算符仿函数,即省略int, 直接plus<>()- —建议使用
比较函数对象
euqal_to, not_equal_to, less, genter, less, less_equal, gereater_equal,
有的容器模板有compare参数,如
template<
class T,
class Container = std::vector< T>,
class Compare = std::less< typename Container::value_type> //默认less
>
class priority_queue;
priority_queue< int> qu;
改为greater
priority_queue<int, vector< int>, greater<>> qu;
逻辑函数对象
logical_not, logical_and, logical_or
按位函数对象
bit_not, bit_and, bit_or
函数对象适配器
绑定器:将函数的参数绑定至特定的值 < functional> std::bind()
bind( F&& f, Args&&... args );
参数
f - 可调用 (Callable) 对象(函数对象、指向函数指针、到函数引用、指向成员函数指针或指向数据成员指针)
args - 要绑定的参数列表,未绑定参数会被命名空间 std::placeholders 的占位符 _1, _2, _3... 替换
返回值
某个未指定类型 T 的函数对象 g
将str绑定固定值myString,结果保存在f1中,使用auto是因为bind()返回类型未指定,取决于实现。没有绑定固定值的参数标记为_1, _2, _3等。这些都存在于std::placehoders名称空间中。在f1定义中 ,_1指定了调用func()时,f1()的第一个参数出现的位置。
void func(int num, sring_view str);
string mySting = "haha";
auto f1 = bind(func, placehoders::_1, myString);
f1(16); //func(16, "haha");
bind可用于调整参数顺序
auto f2 = bind(func, placehoders::_2, placehoders::_1);
f2("Test", 32); // f2的第一个参数在func第二的位置,f2的第二个参数出现在func第一的位置
//func(32, "Test");
< functional> 中有std::ref 和cref,用于绑定引用和const引用
void ff(...); //随便什么功能
int index = 0;
auto incr = bind(ff, ref(index) );
incr; //这样可以改变index值,传递了引用,而不是index副本嘛
这样 index 本身会继续递增, 如果bind直接调用index,就不会,因为bind使用了index的一个副本
结合重载函数overloaded,一个版本接收int,一个接收float。这是需要绑定接收浮点数参数的重载函数的参数:
void overloaded(int num) {};
void overloaded(float f) {};
//void(*)(float)是一个函数指针,它指向一个以float为参数并返回空(void)的函数
auto f4 = bind( ( void(*)(float) )overloaded, placehoders::_1);
// * 表示绑定参数的位置,指定绑定这两个函数中的哪一个
auto f4 = bind( static_cast<void(*)(float)>(overloaded), placehoders::_1);
取反器 not_fn
对作为参数传入的每个调用结果取反。用到这种的场景,考虑下lambda表达式
调用成员函数 mem_fn()
函数模板 std::mem_fn 生成指向成员指针的包装对象,它可以存储、复制及调用指向成员指针。到对象的引用和指针(含智能指针)可在调用 std::mem_fn 时使用。
mem_fn(&string::empty)); // 生成string中empty的函数对象
auto it = find_if(begin(strings), end(strings), mem_fn(&string::empty));
其实这种的lambda更好
auto it = find_if(begin(strings), end(strings), [](const string* str) {return str.empty();});
std::invoke() --C++17
< functional>中
invoke<fun," a"); //调用函数fun,赋予值a
fun部分可以是函数,可以是lambda表达式,也可以是实例化的函数。本身没啥用,但是在模板代码中可以用来调用任意对象。
函数对象示例:
class myIsDigit
{
public:
//重载了函数调用运算符operator()
bool operator()(char c) const {return ::isdigit(c) != 0;}; //不修改对象,使用const
};
bool isNumber(string_view str)
{
auto endIter = end(str);
auto it = find_if(begin(str), endIter, not_fn(myIsDigit() ) );
return (it ==endIter);
}
C++11之后,函数作用域内局部定义的类可以作用域模板参数,如上述代码。将myIsDigit类放到isNunber函数中去。
一般建议lambda,除非完成复杂的任务才使用函数对象
16.6 算法
《C++高级编程》-Chapter 18
算法函数,它们都使用模板来提供泛型。其次,通过迭代器间接操控容器。
通常用迭代器左闭右开区间
谓词- 函数名?
bool func()
auto if = find_if(iter-a;ite-b, func); //每个元素调用谓词,直到谓词返回true,find_if返回迭代器
上述表达式用到func()函数的指针
find_if(iter-a;ite-b, num); //元素匹配,返回迭代器
16.6.1 算法组
STL将算法库分成4组:
< algorithm>
非修改式序列操作–对区间中的每个元素操作,不修改容器内容
修改式序列操作–修改内容,也可以修改值的排列顺序
排序和相关操作–排序函数和其他各种函数
< numeric>
通用数字运算–包括区间的内容累计、计算两种容器的内部乘积。计算小计、计算相邻对象差的函数
通常都是数组的操作特性,vector最合适
16.6.2 算法的通用特征
结果防止在原始数据位置–sort()就地算法–in place algorithm
异地放置–复制算法–copying algorithm–相对于原地输出,需要给出结果防止的位置
有两个版本的 复刻版本的名称以_copy结尾,返回迭代器,并指向复制的最后一个值的后面一个位置
根据函数应用于容器元素得到的结果来执行操作–以_if结尾。如果将函数用于旧值,返回值为true,则
replace_if()将旧值替换为新的值。谓词是返回bool值的一元函数
重难点,谓词或迭代器参数输入类型不对,编译器不会检查,知识会在编译时候报大量错误
chapter18.2
18.2 std::function
定义于**< functinal>**中,用于创建指向函数、函数对象或lambda表达式的类型。可以指向任何可调用的对象—多态函数包装器,当做函数指针使用,或者用作实现回调的函数的参
数–真正用到的地方。 用于封装,以便在函数模板中使用
std::function< R(ArgTypes…) >;// R–函数返回值的类型,ArgTypes是一个以逗号分隔的函数参数类型的列表。
void func(int num, const string& str) {}.
function< void( int, const string&) > f1 = func; //std::function
也可以让编译器自己猜: auto f1 = func;// 推断类型为函数指针void (*f1)(int, const string&),不是function
上述实现了一个函数指针f1, 指向func,这样func或f1都可以调用func();
void f(const vector< int> vec, function<void(int)> f) //实际上还是替代函数指针
{
for(quto & i : vec) {
f(i);
}
}
std::function<void(int)> f=[ ] (int x) {…}; //指代一个lambda表达式,后续将f代替表达式传递给其他函数作为参数。
涉及到内存分配和虚函数调用等开销,避免在性能铭感场景下使用,切代码可读性会降低。
第十七章 输入、输出和文件
streambuf类为缓冲区提供了内存,并提供了用于填充缓冲区、访问缓冲区内容、刷新缓冲区和管、理缓冲区内存的类方法
ios_base类表示流的一般特征,如是否可读取、是二进制流还是文本流等
ios类基于ios_base,其中包括了一个指向streambuf对象的指针成员
ostream 类是从ios类派生而来的,提供了输出方法
istream类也是从ios类派生而来的,提供了输入方法
iostream类是基于istream 和ostream 类的,因此继承了输入方法和输出方
重新定义I/O
为成为国际语言,C++必须能够处理16位的国际字符集或更宽的字符类型,在传统的8位char(“窄”)类型的基础上添加了wchar_t(“宽”)字符类型, C++11 添加了char16_t和char32_t。
c++的iosteam将自动创建8个流对象,4个用于窄字符流,4个用于宽字符流
cin,cout,cerr / wcin, wcout, wcerr err–无缓冲
clog/wclog也对应标准错误流–有缓冲
cout凭借streambuf对象的帮助,管理流中的字节流
始终可以用flush()方法刷新缓冲区,强制要求缓冲的流将其当前所有缓冲数据发送到目的地
流的三个公共的来源和目的地,控制台,文件,字符串。
C语言提供的:
文件:fprintf(), fwrite(), fputs(); fscanf(), fread(), fgets()
字符串:sprintf(), sprintf_s(), sscanf()
17.1.3 重定向
输入重定向 > 和输出重定向<
17.2 使用cout进行输出
17.2.1 重载的<<运算符
C++与C一样,<<运算符的默认含义是按位左移运算符。ostream重新定义了<<运算符,重载为输出,叫做插入运算符,插入运算符被重载,使之能够识别C++中所有基本类型
1.输出和指针
C++用指向字符串存储位置的指针来表示字符串,指针形式可以是char数组名,显示的char指针或用引号括起的字符串
使用字符串中的终止空字符确定结尾
ostream为以下指针类型定义了插入运算符
const signed char*
const unsigned char*
const char*
void*
对于非字符串,C++将其对应于void*,要获得字符串地址,必须强制转换为其他类型
char * s = “aa”;
cout << &aa;
cout << (void*) aa;
//均打印字符串地址
2.拼接输出
插入运算符的返回类型是ostream &: ostream & operator<< (type);
运算符的返回值为调用运算符的对象, cout<<“”, 返回cout对象
这样可以连续输出
3.其他ostream方法
put()和write(),前者显示显示单个字符,后者显示字符串
put可以接收数值型参数, 系统将自动将其转换为对应int的对应的ascll码
cout.put(‘a’);
write显示整个字符串
basic_ostream<CharT,Traits> & write( const char_type* s, std::streamsize count );
outputs the characters from successive locations in the character array whose first element is pointed to by s. Characters are inserted into the output sequence until one of the following occurs:
1)exactly count characters are inserted
2)inserting into the output sequence fails (in which case setstate(badbit) is called
Parameters
s - pointer to the character string to write
count - number of characters to write
Return value
*this
cout调用write() ,将调用char具体化, 返回ostream &
std::cout.write(c, 4).write(“!\n”, 2); //c–string
write()并不会在遇到空字符时自动停止,只打印制定数目的字符,即使超出了字符串的边界。
wtire()也可用于数值数据,可以将数值的地址强制转换为char*,然后传递给该方法
long vla = 560031841;
cout.write( (char *) & val, sizeof(long));
这不会将数字转换为相应的字符,而是传输内存中存储的位表示,输出设备将每个字节作为ascll进行结识,因此vla将被显示未4个字符的组合–可能会乱码
17.2.3 刷新输出缓冲区 ios_base
cout填满缓冲区,然后刷新缓冲区并将内容发出,清空缓冲区。
换行符也可手动刷新缓冲区
C++会在输入即将发生时刷新缓冲区,输出字符串没有换行符–这将导致cout立即显示消息,不然,程序将等待输入,不显示
如果实现不能在希望的时刻刷新输出,可以使用两个控制符中的一个来强行刷新,flush()刷新缓冲区,endl刷新缓冲区的同时插入一个换行符
控制符也是函数,如可以这样flush(cout) 直接刷新cout缓冲区
ostream 对<<进行了重载,使得下述表达式将被替换为函数调用flush(cout)
cout << flush;
cout.flush();
**cout.good()**方法可以判断流当前是否处于正常状态
**cout.bad()**方法提供流不可用等信息,为true,意味着致命错误(导致bug)。
**cout.fail()*方法在最近一次操作失败返回true,但下一次啥样子不知道。等价!cout,将cout转换为bool类型
文件结尾处good和fail都会返回false,关系:good() == ( !fail() && !eof() )
可以要求流在异常是抛出信息,catch块抓住ios_base::failure异常,然后对其调用**what()方法,获取错误描述信息,调用code()**方法获取错误代码。这些都取决于库实现。cout.clear()重置流的错误状态
try{
cout << "haha" << endl;
}catch(const ios_base::failure& e){
cerr << e.what() << endl;
cerr << e.code() << endl;
}
17.2.4 用cout格式化输出/输出操作算子
ostream插入运算符将值转换为文本格式。在默认情况下,格式化值的方式如下
1.对于char值,如果它代表的是可打印字符,则将被作为一个字符显示在宽度为一个字符的字段中
2.对于数值整型,将以十进制方式显示在一个刚好容纳该数字及负号(如果有的话)的字段中
3.字符串被显示在宽度等于该字符串长度的字段中。
4.浮点数的默认行为有变化。下面详细说明了老式实现和新实现之间的区别:
新式:浮点类型被显示为6位,末尾的0不显示(显示数字位数与数字被存储时精度没有任何关系)。数字以定点表示法显示还是以科学计数法表示(参见第3章),取决于它的值。当指数大于等于6或小于等于-5时,将使用科学计数法表示。另外,字段宽度恰好容纳数字和负号(如果有的话)。默认的行为对应于带%g 说明符的标准C库函数 fprint。
老式:浮点类型显示为带6位小数,末尾的0不显示(注意,显示的数字位数与数字被存储时的精度没有任何关系)。数字以定点表示法显示还是以科学计数法表示(参见第3章),取决于它的 值。另外,字段宽度恰好容纳数字和负号(如果有的话)。
因为每个值的显示宽度都等于它的长度,因此必须显式地在值之间提供空格:否则,相邻的值不会被分开。
ios_base类存储了描述格式状态信息,通过其成员函数,可以控制字段宽度和小数位数。
可以将方法用于他的ostream子类
如将cout对象的计数系统格式设为十六进制:hex(cout)–>通常cout<<hex 之后将以十六进制打印,直到重新设置了格式状态
控制符不是成员函数,不必通过对象调用
2.调整字段宽度
方法原型
width成员设置:
int width(); —返回字段宽度的当前设置,
int width(int i);–将字段宽度设置为i个空格,并返回以前的字段宽度值
这个方法只影响将显示的下一个项目,然后字段宽度将恢复默认值
cout<<“#”;
cout.width(12);
cout << 12;
结果: # 12; //默认右对齐
C++永远不会截断数,字段不够,自动增加
用来填充的空格被承能、称为 填充字符
3.填充字符
默认情况下,cout用空格填充字段中未被使用的部分,下述方法可以改变填充字符,这个时一直有效,直到改变它
cout.fill( ‘*’ );
4.设置浮点数精度
默认指的是总位数,在定点模式和科学模式下,指的是小数点后面的位置,C++默认精度 6位,末尾0不显示, precison()成员函数可以定义其他精度值
cout.precison(2); 精度为2,两位数字 ,一直有效直到重置
以上,包含< iostream>即可
以下在ios_base类中,需要using std::ios_base
同时在std空间中
5.打印末尾的0和小数点
ios_base提供了setf()函数,如
cout.setf(ios_base::showpoint); 显示末尾小数点
默认的浮点格式,还可以将末尾0显示出来,即默认情况(精度6位)下 cout将把2.0 显示为2.000 000
6.再谈setf()
setf方法控制小数点被显示时的其他几种格式选项,ios_base类有一个受保护的数据成员,其中的各位(标记)分别控制着格式化的各个方面。打开一个标记称为设置标记(或位),并意味着相应的位被设置为1。hex,dec,oct控制计数系统的3个标志位,setf()函数提供了另一种调整标记位的途径。
C++对十六进制和八进制视为无符号的
使用这些常量 需要作用域解析符 ios_base::xxx
std::ios_base::setf 方法原型
cppreference-< ios>-setf
fmtflags setf( fmtflags flags );(1)
fmtflags setf( fmtflags flags, fmtflags mask ); (2)
//第二个参数指出要清除第一个参数中的哪些位,用第一个参数指出要设置哪位
设置格式化标志以指定设置。
- 设置 flags 所标识的格式化标志。等效地进行下列操作: fl = fl | flags ,其中 fl 定义内部格式化标志的状态。
- 清除 mask 下的格式化标志,并设置被清除的标志为 flags 所指定者。mask有adjustfield,floatfield,basefield
参数
flags, mask - 新格式化设定。 mask 定义哪些标志可以改变, flags 定义要改变的标志中该设置那些(其他将被清除)。两个参数都能为下列常量的组合:
返回值
调用函数前的格式化标志。如果打算以后恢复原始设置,可以保存。类型类fmtflags的数字
以下操作算子, 有部分在ios中,可以直接cout << showpoint, 或者cout.showpoint;
有部分重复的在ios_base类中,这时可以用setf
| dec | 为整数输入/输出使用十进制底:见 std::dec |
| oct | 为整数输入/输出使用八进制底:见 std::oct |
| hex | 为整数输入/输出使用十六进制底:见 std::hex |
| left | 左校正(添加填充字符到右):见 std::left |
| right | 右校正(添加填充字符到左):见 std::right |
| internal | 内部校正(添加填充字符到内部选定点):见 std::internal |
| scientific | 用科学记数法生成浮点类型,或在与 fixed 组合时用十六进制记法: |
| fixed | 用定点记法生成浮点类型,或在与 scientific 组合时用十六进制记法:见 std::fixed |
| boolalpha | 输入和输出bool值(true/false) |
| noboolalpha | 输入和输出bool值(1/0) //cout <<std::noboolalpha方式使用在< ios>内,不在ios_base类中 |
| showbase | 生成为整数输出指示数字基底的前缀,货币输入/输出中要求现金指示器: |
| showpoint | 显示末尾小数点 |
| noshowpoint | 不显示小数点/cout <<std::noshowpoint方式使用在< ios>内,不在ios_base类中 |
| showpos | 为非负数值输出生成 + 字符 |
| skipws | 在具体输入操作前跳过前导空白符:见 std::skipws |
| unitbuf | 在每次输出操作后冲入输出:见 std::unitbuf |
| uppercase | 在具体输出的输出操作中以大写等价替换小写字符 |
| basefield | dec oct hex 适用于掩码运算//第二个参数 |
| floatfield | scientific fixed。适用于掩码运算//第二个参数 |
| adjustfield | left right internal。适用于掩码运算 //第二个参数 |
本书P748
cout左对齐
ios_base::fmflags old = cout.setf(ios::left, ios::adjustfield);
恢复以前
cout.setf(old, ios::adjustfield);
void unsetf( fmtflags flags );
Unsets the formatting flags identified by flags.
flags为1 将对应恢复
没有专门指示浮点数默认显示模式的标记。系统的工作原理如下
仅当只有定点位被设置时使用定点表示法;仅当只有科学位被设置时使用科学表示法
对于其他组合,如没有位被设置或两位都被设置时,将使用默认模式。
因此,启用默认模式的方法之一如下:
cout.setf(0,ios_base::floatfield);//go to default mode
第二个参数关闭这两位,而第一个参数不设置任何位。
简捷方式是,使用ios:floatfield 来调用函数 unsetf
cout.unsetf (ios_base::floatfield);//go to default mode
如果已知cout 处于定点状态,则可以使用参数 ios_base:fxed 调用函数unsetf()来切换到默认模式
然而,无论cout的当前状态如何,使用参数 ios_basc:foatfield 调用函数unsetf都将切换到默认模式,因此这是一种更好的选择。
定点表示法意味着使用格式123.4来表示浮点值,而不管数字的长度如何,
科学表示法则意味着使用格式1.23e04,而不考虑数字的长度。
如果您熟悉c语言中 printf()的说明符,则可能知,
默认的c++模式对应于%g说明符,定点表示法对应于%f说明符,而科学表示法对应于%e说明符。
在C++标准中,定点表示法和科学表示法都有下面两个特征:
精度指的是小数位数,而不是总位数; 显示末尾的0。
7.标准控制符
使用setf()不是进行格式化的、对用户最为友好的方法,C++提供了多个控制符,能够调用setf,并自动提供正确的参数。前面已经介绍过 dec、hex 和 oct,这些控制符工作方式都与hex 相似。例如,下面的语句打开左对齐和定点选项:
cout <<left << fixed;
8.头文件iomanip
iostream 设置格式值不太方便,iomanip 方便一点。最常用的setprecision(),setfill(), setw(),分别设置精度、填充字符和字段宽度
setprecison()接受一个指定精度的整型参数,
cout << setprecision(n) or cin >> setprecision(n) //cout.precison(2)
setfill()接受一个指定填充字符的char参数
cout << setfill© //cout.fill( ‘*’ )
setw()接受一个指定字段宽度的整数参数
// cout.width(12);
cout << setw(n) or cin >> setw(n)
put_money 向流中写入格式化货币值
put_time 向流中写入格式化时间值put_time
time_t t_t{ time(nullptr) }; // Get current system time.
tm* t{ localtime(&t_t) }; // Convert to local time.
cout << "This should be the current date and time formatted according to your location: "
<< put_time(t, "%c") << endl;
quoted 把给定的字符串封装在引号中,并转义嵌入的引号
cout << "This should be: \"Quoted string with \\\"embedded quotes\\\".\": "
<< quoted("Quoted string with \"embedded quotes\".") << endl;
/*output:
This should be: "Quoted string with \"embedded quotes\".": "Quoted string with \"embedded quotes\"."
*/
以上对后续内容有效(目前也就cout.width() 对后续无效,setw也是)
cout<< fixed << right; //显示结尾的0
17.3 使用cin进行输入
cin对象将标准输入表示为字节流,之后根据变量类型进行类型转换
通过重载 抽取运算符>> 适配基本类型,指针类型
istream & operator>>(int &);
参数和返回值都是引用,处理参数本身而不是副本 返回调用对象(此处cin)的引用
可以使用hex, oct, dec控制符于cin一起使用,来制定将证书输入解释为对应格式,如 cin >> hex
针对字符指针,抽取运算符将读取输入中的下一个单词,放置在制定的地址,并加上一个空值字符,使之成为一个字符串
17.3.1 cin>>如何检查输入
跳过空白(空格,换行符,制表符),直到非空白符,对于单字符模式(参数类型为char,unsigned char,signed char)也是如此。
单字符模式,>>读取该字符放到指定位置,
其他模式,读取指定类型的数据,从空字符开始直到第一个类型不匹配为止的全部内容
不符合的字符将被留在字符中,等待下次读
输入可能完全不满足需求,则返回0–false 可以用来判断输入是否满足需求
int input
while( cin >> input);
17.3.2 流状态
cin/cout对象包含一个描述流状态(stream state)的数据成员(从ios_base继承),被定义为iostate类型–iostate是一种bitmask类型。由eofbit,badbit或bailbit 组成
每个元素都是一位,可以为1(设置)或0–(清除)。
cin到达文件末尾,设置eofbit; 未能读到预期字符时 或 I/O失败,设置failbit;在一些无法诊断的失败破坏流,设置badbit。 三个都是0一切顺利
goodbit 另一种全0表示法
以上定义于ios_base类中(位于< ios>中) basic_ios继承自ios_base,提供状态函数
其中方法:
good() 如果流可用(所有位都被清楚),返回true
eof()/bad() 对应位被设置,返回true
fail() badbit或者failbit被设置,返回true
rdstate() 返回流状态
exceptions() 返回一个位掩码,指出哪些标记导致异常
流可以直接调用,如cin.good()
1.设置状态
**clear()**把状态设置成它的参数,没有传入参数,则默认为0,这将清除全部三个状态位
clear(eofbit)将设置eofbit为1,其余全部清除
**setstate()**方法只影响其参数中已经设置的部分,setstate(eofbit)只设置eofbit,其余不变
clear--重新打开输入 setstate主要是为了提供一个修改状态的途径
2.I/O 和异常
输入函数设置了eofbit,默认情况下不会导致异常,但可以使用**exceptions()**方法来控制异常如何被处理。
std::ios_base::iostate exceptions() const;(1)
void exceptions( std::ios_base::iostate except );(2)
获取和设置流的异常掩码。异常掩码确定在哪些错误状态出现时抛出 failure 类型异常。如果在调用的流具有异常掩码覆盖的错误状态,则出发异常。
- 返回异常掩码。指出哪些标记引发异常
- 设置异常掩码为 except 。它指出哪些状态导致clear()引发异常。如此时的except为eofbit,如果eofbit被设置,则clear将引发异常
参数
except - 异常掩码
返回值 - 当前异常掩码。
- (无)
ios_base::failure异常类是从std::exceptions类派生而来,因此包含一个what()方法。
重载的exceptions(iostate)可以用try-catch块来控制异常发生时的行为, cin.exceptions(badbit),将导致异常被传递,期待try-catch块处理
位预算OR,可以指定多为, cin.exceptions(badbit | eofbit);将导致异常
这就是如何在接受输入时使用异常
3.流状态的影响
设置流状态位将导致流对后面的输入输出关闭,直到位被清除
while( cin >> input)
{
sum+= input;
};
//脱出循环时候eofbit= 1 是可能的
if(cinleof() )
cout << “…”
cin >> input; //无法输入,此之前加上cin.clear() 重置流状态
此时,导致程序终止的不匹配循环输入仍留在输入队列中,可以一直读取字符,直到遇到空白,isspace()函数是一个cctype函数,它在参数是空白字符时返回true,
另外一种方法是,丢弃行中剩余的部分, continue
如果循环遇到文件尾巴或硬件故障,则处理错误输入的代码将毫无意义,可以使用fail()来检测假设是否成立。fail()在failbit或eofbit被设置时返回true
17.3.3 其他istream类方法
get(char&)和get(void)提供不跳过空白的单字符输入
get(char *, int, char)和getline(char *, int, char)在默认情况下读取整行而不是一个单词
这两被称为非格式化输入函数,只读取字符输入,不会跳过空白,也不会数据转换
1.单字符输入
istream
使用char参数或没有参数时,get()方法读取下一个输入字符,即使是空格,制表符或换行符,
getchar(char & ch)将输入字符赋给参数,
get(void)将输入字符转换为整型(通常为int),并将其返回
(1)get(char &)
cin会跳过空格
返回一个指向用于调用它的istream对象的应用,因此可以拼接后续抽取
cin.get(c1.get(c2); >> c3
到达文件结尾,无论真结尾还是模拟的,都不会给其参数赋值,同时调用setstate(failbit), 导致cin.get(ch)的返回值为false
(2)get(void)
读取空白,但使用返回值来讲输入传递给程序,所以ch = cin.get()
返回值类型不是对象,不能对它应用成员运算符,因此cin.get().get() 将报错
到达结尾,cin.get(void)将返回EOF,可以用来判断
while( (ch = cin.get()) !=EOF) // EOF可能无法使用char类型 EOF一般为 -1–头文件定义的
2.采用哪种单字符输入形式
对比cin.get(ch)与ch = cin.get()
传输字符方法:前者赋给参数ch。后者返回值给ch
函数的案回执:前者指向istream对象的引用,后者返回int型字符编码
到达文件结尾:前者转换为false,后者EOF。
希望跳过空白, >>
get() 会处理非空白字符,如\n,
希望程序检查每个字符, get()
get(char &)更好,get(void)于C中的getchar()类似,意味着可以通过包含iostream而不是stdio.h,并用cin.get()替换所有getchar(),用cout.put(ch)替换putchar(ch),将C转换成C++
3.字符串输入,getline(),get() ignore()
getline()成员函数和get()的字符串读取版本 都去读字符串,函数特征标相同
istream & get(char *, int, char)
istream & get(char *, int)
第一个参数用于防止输入字符串的内存单元地址,第二个参数比要读取的最大字符数大1,用于存储’\0’。第三个参数指定用作分解符的字符,只有两个参数的版本将换行符用作分解符。上述函数都在读取到最大数目或遇到换行符为止。因此,定义的数组小了,C++也会自己给他增长。
get()和getline()区别,get()将换行符留在输入流中,这样接下来的输入操作首先看到的是换行符,而getline()抽取并丢弃掉输入流中的换行符。getline没有读取到字符(如直接换行)或者超过了最大字符,设置failbit,get没有读取到字符时设置failbit
第三个参数指定了分界符,遇到它,输入立即停止。get()将分界字符留在队列,getline不保留
对于getline,在< string>中有个版本,接收一个流引用,一个字符串引用和一个可选的分隔符作为参数,这个版本的优点是不需要制定缓存区的大小。
std::getling(cin, myString); //myString是个string对象
**ignore()**接受两个参数,一个数字,指定要读取并忽略的最大字符数,另一个是字符,用它做输入分界符,读取到该字符,忽略,且之后的字符正常读取,不再忽略。两个参数满足一个,之后都会正常读取。
原型的两个参数默认值分别为1 和EOF,返回类型为istrem &;
istream & ignore(int = 1, int = EOF);
默认参数值EOF将导致ignore()读取到指定书目的字符或读取到文件结尾,之后全部丢弃
该函数也可以拼接输入。没读取一次丢弃掉当前行多余未读,直接下一行
4.意外字符输入
get(char*, int) 和getline()遇到文件结尾将设置eofbit,遇到流被破坏,将设置badbit,另外两种特殊情况是无输入,以及输入到达或超过函数调用指定的最大字符数
上述两种方法,如果不能抽取字符,空字符将把空字符放置到输入字符串中,并使用setstat()设置failbit。不能抽取的原因可能是输入立刻到达了文件尾巴, get(char *, int)还可能时输入了一个空行
空行不会导致getline()设置failbit,这是因为它仍将抽取换行符,虽然又扔了。如果希望getline()遇到空行立即停止,这样:
char temp[8];
while( cin.getline( temp, 8) && temp[0] != ‘\0’)
效果等同于
while(cin.get( temp, 8))
空行终止
大于指定数目,则设置failbit,包含30个或更多字符的输入行将被终止
get(char *,int)先测试字符数,然后测试是否为文件尾巴以及下一个字符是否为换行符。如果读取到了最大数目,则不会设置failbit标记。因此可以知道是不是读取了过去字符。可以用peek()查看下一个字符,如果是换行符,则说明get()读取了整行,如果不是,则说明到达一行的结尾停止的,这种办法getline()不能用,因为它丢弃掉了换行符
17.3.4 其他istream方法
read()读取指定数目的字节,并存储在指定位置,
char gross[144];
cin.read( gross, 144);
它不会在输入后加上空值字符,因此不能将输入转换为字符串,常常与ostream_write()结合使用,来完成文件输入和输出,返回istream &, 因此可以拼接
// cin.read().read()
**peek()**返回输入中的下一个字符,但不抽取输入流中的字符,可以用来查看是否到一行结尾.瞄一眼下一个字符。
gcount()返回最后一个非格式化抽取方法读取的字符数,这意味着由get(),getline(),ignore(),read()方法读取的,不是由抽取运算符>>去读的,抽取运算符对输入进行格式化,使之与特定的数据类型匹配,如cin.get(myarray,80) 想知道读取了多少字符, strlen可以, 比cin.grount()计算读取了输入流中多少个字符快
putback()函数将一个字符插入到字符串中,被插入的字符将是下一条输入语句读取的第一个字符,接收一个char参数–要插队的字符,返回istream &,可以拼接。使用peek()的效果相当于先用get()读取一个字符,然后使用pushback将字符放回到输入流中,然而,pushback()允许将字符放到不是刚才要读取的位置。cin.putback(‘e’), e将放入到流待读取
unget()
流回退一个位置,将读入的前一个字符放回流中,调用fail()查看unget()是否成功。
cin.unget()
17.4 文件输入和输出
重定向来自操作系统
写入文件,要创建ofstream对象,使用ostream方法,如<<或write()。
读取文件,要创建ifstream对象,使用istream方法,如>>或get().
< fstream>定义了fstream类用于同步文件I/O,都从< iostream>中的类派生出来的
17.4.1 简单的文件I/O
写入文件步骤:
1.创建一个ofstream对象来管理输出流
2.将该对象与特定的文件关联起来
3.以使用cout的方式使用该对象,输出的被写进文件
包含fstream头文件,多数情况,该头文件自动包含iostream文件。
1.ofstream fout; //创建一个ofstream对象,任意有效的C++名称,fout可以,dida也行
2. fout.open(“name.txt”); //将fout对象与具体文件连接
或:
ofstream.fout(“jar,txt”);
3.类比cout。fout << "haha;
由于ostream是ofstream的基类,因此可以使用所有ostream方法
ofstream使用被缓冲的输出因此程序创建fout这样的ofstream对象时,将为输出缓冲区分配空间。每个ofstream对象都有自己的空间。这种方式,在没有关联的文件时候,自己会创建一个新文件,已存在则打开清空,再输入。
以默认模式打开文件进行输出将自动把文件的长度截断为零,这相当于删除已有的内容,填充新的内容,即覆写 。
读取文件步骤:
1.创建一个ifstream对象关联输入流
2.将该对象与特定的文件关联起来
3.以使用cin的方式使用该对象
1.与写出声明对象类似
ifstream fin;
fin.open(“jamjar.txt”);
或
ifstream fin(“jamjar.txt”);
2.l类似cin一样使用fin
char ch;
fin >> ch; //从txt中读取一个字符
char buf[12];
fin >> buf; //从文件中读取一个单词
fin.getline(buf, 80); //从文件中读取一行
string line;
getline(fin, line); //读取一个文件传送给一个string对象
当输入和输出流对象过期(如程序终止)时,到文件的链接将自动关闭。close()方法可以显示关闭到文件的链接。
fout.close();
fin.close();
这并不会删除流,而只是断开流到文件的链接。流管理装置仍然被保留,如fin对象与它管理的输入缓冲区仍然存在
string对象提取出C风格字符串 stringname.c_str
ofstream fout(filename.c_str() )
17.4.2 流状态检查和is_ioen()
C++文件流类从ios_base类继承了一个流状态成员,如果一切顺利,已到达文件尾巴,I/O操作失败等。
如果一切顺利,则流状态为零,no news is good news。其他状态都是通过特定位设置为1来记录的。
文件流类还继承了ios_base类中报告流状态的方法,可以通过检查流状态来判断最后一个流操作是否成功
试图打开不存在的文件,将设置failbit位
fin.open(aoff);
if (fin.fail())
{…};
ifstream对象和istream对象一样,被放在需要bool类型的地方时,将被转换为bool值
因此,可以这么判断
if(fin)
{…}
bool is_open() const; //(since C++11)
Checks if the file stream has an associated file.
true if the file stream has an associated file, false otherwise.
if(fin.is_ioen() ) 之前的方法无法检测不合适的文件模式打开文件 这个可以
{…}
17.4.3 打开多个文件
两个文件排序,并合并成第三个文件,这样每个文件都需要对应的流
一个流也可以依次关联多个文件
fin.close() 断开连接
fin.clear() 重置fin状态
17.4.4 命令行处理技术–黑框框中使用
C++ 中有一种让在命令行环境中运行的程序能够访问命令行参数的机制
int main(int argc, char *argv[]);
argc–命令行中参数个数,argv[]–指针数组,其中的指针指向命令行参数,
argv[0]是一个指针,指向存储第一个命令行参数的字符串的第一个字符,以此类推
17.4.5 文件模式–描述文件如何被使用
P774
ios_base::
| 常量 | 含义 |
|---|---|
| in | 打开文件,从开头开始读取 |
| out | 打开文件,从开头写入,覆盖已有 |
| ate | 打开文件,并移动到文件尾 |
| app | 追加到文件尾写入 |
| trunc | 如果文件存在,则截短/删除已有数据 |
| binary | 以二进制模式操作(相当于文本文件) |
app追加模式,结尾可写,其余部分只读
ifstream和ofstream构造函数可以接收两个参数,构造函数原型为第二个参数(文件模式参数)提供了默认值
ifstream::open默认 in,
ofstream默认out | trunc , 位运算符将两个位值合并成一个可用于设置两个位的值
fstream不提供默认值,因此必须显式提供文件模式
trunc 意味着 打开已有的文件,,以接收程序输出时将被短,以前的内容将被删除。可能会将不希望删除的内容删除,可以这样解决
ofstream fout9(“sf”,ios_base:out | ios_base::app); 可以保留文件内容,并在文件尾添加重要信息
C++文件打开模式与C模式 P775
文本模式or二进制模式 //需要时再看
除非指定ios_base::binary标识,默认文件流以文本模式打开。
二进制模式下,要求把流处理的字节写入文件,读取时,将完全按照文件中的形式返回字节。
文本模式下,会执行一些隐式转换,写入或者读取每一行都会以\n结束
文本格式:将所有内容,如数字,存储为文本,
二进制格式:存储值的金算计内部01表示。
对于字符,二进制表示与文本表示一样,即字符的ASCII码的二进制表示
对于数字,二进制表示与文本表示有差别,二进制表示是计算机内部01表示,转换成文本是ascii码对应的二进制
文本格式便于读取,可以方便的计算机间传送
二进制格式,对于数字精确,因为它的值是计算机硬件的表示,不会有转换误差和舍入误差,速度更快
但是,不同的解读方法可能无法读取到同样的值
将p1内容以文本格式保存
ofstream fout("plantes.dat", ios_base::out | ios_base::app);
fout << p1.name << " " << p1.population << p1.g << "\n";
数量多的话,麻烦
以二进制格式存储相同的信息
ofstream fout("plantes.dat", ios_base::out | ios_base::app | ios_base::binary);
fout.write( (char *) &p1, sizeof p1);
这样使用计算机内部数据表示,将数据保存为一个整体,不能将该文件作为文本读取,但与文本对比,信息的保存更紧凑精确
二进制文件和文本文件
使用二进制文件模式,程序将数据从内存传输给文件(反之亦然)时,将不会发生任何隐藏的转换
而默认的文本模式并非如此,
要使用二进制格式存储,可以使用write函数,将内存中制定数目的字节复制到文件中,可以逐字节复制,也可成段复制文本,而不进行任何转换。唯一不方便的是,必须将地址强制转换为char的指针
读取二进制文件
ifstream fout("plantes.dat", ios_base::out | ios_base::app | ios_base::binary);
fin.read((char *) &p1, sizeof p1);
有些系统只有一种文件类型,因此可以将二进制操作(如read write)用于标准文件格式。如果,实现认为ios_base::binary为非法常量,删除就行
如果不支持fixed和right控制符,则可以使用cout.setf(ios_base::fixed.ios_base::floatfield)和
fout.setf(ios_base::right、ios_base::adjustfield),另外,也可能必须使用ios替换ios_base。
使用string对象而不是字符数组来表示planet结构的name成员不可行,因为string本省实际上并没有包含字符串,二十包含了一个指向其中存储了字符串的内存单元的指针,将结构复制到文件中时,复制的是字符串的存储地址
17.4.6随机存取
seek() 移动
文件中移动的方式,fstream类为此继承了两种方法,seekg()(g–get 输入流)和seekp()(p–put 输出流)前者将输入指针移动到指定的文件位置,后者将输出指针移动到指定位置,因为缓冲区的缘故,实际上指针指向的是缓冲区中的位置,而不是实际的文件。
两个版本,
接收一个参数:绝对位置(从文件开始处算起),定位到这个绝对位置// 第一个字节编号0
接收一个变异量+一个位置:定位到距离给定位置一定偏移量(类型:std::streamoff)的位置(类型:std::streampos),字节计数。
basic_istream& seekg( pos_type pos ); //oStream.seekp()
basic_istream& seekg( off_type off, std::ios_base::seekdir dir); //inStream.seekg()
预定义的位置
常量 解释(ios_base)
beg 流的开始
end 流的结尾
cur 流位置指示器的当前位置
e.g.
fin.seekg(30, ios_base::beg);// 30 bytes beyond the beginning
fin.seekg(-1, ios_base::cur);//back up one byte
fin.seekg(0, ios_base::endl);//go to the end of the file
fout.seekp(0); //go to the begin of the file
Return value
*this
Exceptions
failure if an error occurred (the error state flag is not goodbit) and exceptions() is set to throw for that state.
If an internal operation throws an exception, it is caught and badbit is set. If exceptions() is set for badbit, the exception is rethrown.
ios_base <----- base_ios<charT, Traits> <----- base_istream<charT, Traits>
tell() 查询
如果要检查指针的当前位置,对于输入流, tellg(),对于输出流tellp(),以字节为单位,从文件头开始计算
pos_type tellg(); //istream.tellg()
Returns input position indicator of the current associated streambuf object.
Return value
The current position of the get pointer on success, pos_type(-1) on failure
pos_type tellp();
Returns the output position indicator of the current associated streambuf object.
Return value
current output position indicator on success, pos_type(-1) if a failure occurs.
e.g.: std:streampos curPos = inStream.tellg();
if(finout.eof())
finout.clear(), //clear eof flag
else
{
cerr << “Error”;
exit(EXIT_FAILURE);
}
上述代码重置eofbit,这样可以再次访问文件
将流链接tie()
输入流与输出流链接,输入流请求数据,输出流也自动刷新。互相依赖的文件流会用到。
输出流链接到输入流,对输入流调用tie(),并传入出书流地址,解除传入nullptr
ifstream inFile("input.txt"); //must exist
ofstream outFile("output.txt");
inFile.tie(&outFile);//输出流连接至输入流
//向输出流放一点字符,这是不会刷新缓冲区,因为没有std::endl
outFile << "Hello There!";//outFile还没有被刷新
//当从inFile读取时,这将出发onFile上的刷新
string nextToken;
inFile >> nextToken;/outFile //已经被刷新
每次写入一个文件,发送给另一个文件的缓存数据就会被刷新,这样两个文件可以保持同步,cin -cout
双向I/O
前提是数据大小固定。双向流逝iostream的自雷,支持<< 和>>。fstream类提供
使用不同的指针保存读和写的位置,切换时,需要定位到正确的位置
第十八章 探讨C++新标准
C++11
移动语义和右值引用
Lambda表达式
包装器模板function
可变参数模板
P796
18.8.2 统一的初始化
C++11 提供了模板类 initializer_list,可将其用作构造函数的参数,此时,初始化列表语法只能用于该构造函数,列表中的元素必须是同一种类型或可转换为同一种类型
vector<int> a1(10) 10个元素
vector<int> a2[10] a2 初始化为10
vector<int> a3{4,6,1} 三个元素 4,6,1
#include <initializer_list>
double sum(std::initializer_list<double> i1);
int main()
{
double total = sum({2.5, 3.1});
...
}
double sum(std::initializer_list i1)
{
double tot = 0;
for(auto p = i1.begin(); p !=i1.end(), p++) //begin, end 指针
tot += *p;
return tot;
}
18.1.3 声明
2.decltype
将变量的类型声明为表达式指定的类型,
decltype(x) y; //让变量y的类型与x表达式 类型相同
常用于定义模板
3.返回类型后置
再函数名和参数列表后面指定返回类型
double f1(double, int); // traditional syntax
auto f2(double ,int) ->double;// new syntax, return type is double
搭配decltype指定模板函数返回类型
4.模板别名:using=
typedef std::vector<std::string>""iterator itType;
C++11
using itType = std::vector<std::string>::iterator
新语法可以用于模板部分具体化 typedef不能
template<typename T> using arr12 = std::array<T, 12>
因此:
std::array<double,12> a1; 可以简化为 arr12<double> a1;
5.nullptr
18.1.5 异常规范方面的修改
void f1(int) throw(bad_dog); //throw type bad_dog exception
void f2(int) throw(); //dosen’t throw an exception
指出函数不会引发异常--noexcept
void fun() noexcept;//doesn't throw an exceptioin
18.1.6 作用域内枚举
同一作用域内枚举成员不能同名
传统枚举,类型检查低级
enum old {yes, no, maybe};
新枚举, 要求显示下你的那个,以免发生名称冲突,引用特定枚举时,new1::never 这样的限定
enum class new1 {…}
enum struct new2 {…}
18.1.7 对类的修改
1.显式转换运算符
自动转换可能存在问题,C++引入关键字explicit,以禁止单参数构造函数导致的自动转换
class Flebe
{
Flebe(int); // 自动转换
explicit Fleb(double); // requires explicit use
}
Flebe a, b;
a = 5, //隐式转换,调用Flebe(int)
b = 0.5;//不允许
b = Flebe(0.5); //显式调用转换
C++11拓展了explicit,使得可对转换函数做类似的处理
class Flebe
{
operator int() const; // 自动转换
explicit operator double() const; // requires explicit use
}
Flebe a, b;
int n = a; //隐式转换
double x = b; //不允许
x = double(b); //显式调用转换
2.类成员初始化
C++11中,可以在类定义中初始化成员了
class Session
{
int mem1 = 10;
double mem2 {123.123};
short mem3;
public:
Sesson() {};
Session(short s) :mem3(s) {};
Session(int n, double d, short s) : mem1(n), mem2(d), mem3(s) {}
}
可以使用等号或大括号初始化,但不能使用圆括号版本的初始化,其结果与给前两个构造函数提供成员初始化列表,并制定mem1,mem2的值相同
Session() : mem(10), mem2(123,32) {}
Session(short s) : mem1(10), mem2(23,12), mem3(s) {}
通过内部初始化,可避免在构造函数中编写重复的代码
18.1.8 模板和STL方面的修改
前面提到过了模板别名和适用于STL的智能指针
1.基于范围的for循环
对于内置数组以及包含方法begin() 和end()的类和STL容器,基于范围for循环简化工作
double proces[5] = {...};
for(double x : prices)
std::cout << x << std::endl;
更安全的方式
double proces[5] = {...};
for(auto x : prices)
std::cout << x << std::endl;
需要修改
std::vector<int> v(4);
for (auto & x: v)
x = std::rand();
2.新的STL容器
C++11新增STL容器forward_list、unordered_map unordered_multimap unordered_set unordered_multiset
forward_list 单向链表,只能沿一个方向遍历,剩余集中哈希表实现
C++11还新增了array,可制定元素类型和个数 std::array<int, 360> ar;
3.新的STL方法
cbegin() cend() 返回一个迭代器指向容器的第一个元素和最后一个元素的后面,并将元素视为const
4.valarray升级
C++11 添加的begin()和end(),都可以接收valarray作为参数,并返回迭代器,这样基于范围的STL算法可以用于valarray第十六章
6.尖括号
std::vector<std::list<int>> vl; //ok in C++11
18.1.9 右值引用
在 C++ 或者 C 语言中,一个表达式(可以是字面量、变量、对象、函数的返回值等)根据其使用场景不同,分为左值表达式和右值表达式。确切的说 C++ 中左值和右值的概念是从 C 语言继承过来的。
值得一提的是,左值的英文简写为“lvalue”,右值的英文简写为“rvalue”。lvalue 是“loactor value”的缩写,可意为存储在内存中、有明确存储地址(可寻址)的数据,而 rvalue 译为 “read value”,指的是那些可以提供数据值的数据(不一定可以寻址,例如存储于寄存器中的数据)(只出现在等号右边)。
通常情况下,判断某个表达式是左值还是右值,最常用的有以下 2 种方法。
1) 可位于赋值号(=)左侧的表达式就是左值;反之,只能位于赋值号右侧的表达式就是右值
2) 有名称的、可以获取到存储地址的表达式即为左值;反之则是右值。
左值是可以放在赋值号左边可以被赋值的值;左值必须要在内存中有实体;
右值当在赋值号右边取出值赋给其他变量的值;右值可以在内存也可以在CPU寄存器。
一个对象被用作右值时,使用的是它的内容(值),被当作左值时,使用的是它的地址。
反之,字面量 5、10,它们既没有名称,也无法获取其存储地址(字面量通常存储在寄存器中,或者和代码存储在一起),因此 5、10 都是右值。
左值引用
左值引用就是我们平常使用的“引用”。引用是为对象起的别名,必须被初始化,与变量绑定到一起,且将一直绑定在一起。
我们通过 & 来获得左值引用,
type &引用名 = 左值表达式;
可以把引用绑定到一个左值上,而不能绑定到要求转换的表达式、字面常量或是返回右值的表达式。举个例子:
int i = 42;
int &r = i; //正确,左值引用
int &r1 = i * 42; //错误, i*42是一个右值
const int &r2 = i * 42; //正确,可以将一个const的引用绑定到一个右值上
左值引用通常也不能绑定到右值,但常量左值引用是个“万能”的引用类型。它可以接受非常量左值、常量左值、右值对其进行初始化。不过常量左值所引用的右值在它的“余生”中只能是只读的。相对地,非常量左值只能接受非常量左值对其进行初始化。
int &a = 2; # 左值引用绑定到右值,编译失败 非常量引用必须左值
int b = 2; # 非常量左值
const int &c = b; # 常量左值引用绑定到非常量左值,编译通过
const int d = 2; # 常量左值
const int &e = c; # 常量左值引用绑定到常量左值,编译通过
const int &b =2; # 常量左值引用绑定到右值,编程通
右值值引用通常不能绑定到任何的左值,要想绑定一个左值到右值引用,通常需要std::move()将左值强制转换为右值,例如:
int a;
int &&r1 = c; # 编译失败
int &&r2 = std::move(a); # 编译通过
右值引用
右值引用是C++11中引入的新特性 , 它实现了转移语义和精确传递。
它的主要目的有两个方面:
消除两个对象交互时不必要的对象拷贝,节省运算存储资源,提高效率。
能够更简洁明确地定义泛型函数。
右值引用就是必须绑定到右值的引用,他有着与左值引用完全相反的绑定特性,我们通过 && 来获得右值引用。
右值引用的基本语法type &&引用名 = 右值表达式;
右值有一个重要的性质——只能绑定到一个将要销毁的对象上。举个例子:
int &&rr = i; //错误,i是一个变量,变量都是左值
int &&rr1 = i 42; //正确,i42是一个右值
右值引用和左值引用的区别
左值可以寻址,而右值不可以。
左值可以被赋值,右值不可以被赋值,可以用来给左值赋值。
左值可变,**右值不可变**(仅对基础类型适用,用户自定义类型右值引用可以通过成员函数改变)。
C++ 新增右值引用--第八章 &&表示,右值引用可关联到右值。即可出现再赋值表达式右边,但不能对其应用地址运算符的值。
int && r1 = 13;
int && r2 = x + y; //关联刀x+y的结果,即使之后x + y 修改了 r2 也不变
double && r3 = std::sqrt(2,0);
右值关联到右值引用导致该右值被存储到特定的位置,且可以获取该位置的地址。也即是说&13不成立,但是&r1是可以的,通过将数据与特定的地址关联,可以通过右值引用访问该数据
18.2 移动语义和右值引用
数据保留在原来位置,但是将所有权移交–移动语义。这样避免了移动原始数据,而只修改了记录。
感觉就像,新指针指向了旧指针的内存,然后旧指针被删除了
要实现移动语义,旧必须让编译器知道什么时候要复制,什么时候不需要,就是为了解决复制构造函数带来的不必要的临时操作。右值引用用上了。作为函数参数,右值引用不能为const
noexcept--应当加上
由于移动操作时“拦截窃取操作”,通常不会抛出异常。当编写一个不抛出异常的库函数时,应该通知标准库,使之不要做一些额外的操作。
在vector重新分配空间并执行原有对象从老空间到新空间的拷贝时,vector此时并不会默认调用移动构造函数而是拷贝构造函数,这是因为如果重新分配过程使用了移动构造函数,且在移动了部分而不是全部元素后抛出一个异常就会产生问题——旧空间的移动源元素已经改变了,而新空间中为构造的元素可能尚不存在,在此情况下,vector将不能满足自身保持不变的要求。另一方面,如果vector调用的是拷贝构造函数,它很容易得可以保持旧元素不变且释放新分配的(但还未成功构造的)内存并返回。vector原有的元素仍然存在。因此,如果我们希望vector在重新分配空间时执行的是移动操作而不是拷贝,我们通过将移动构造函数标记为noexcept来做到这一点。
复制构造函数:
Useless::Useless(const Useless & f) : n(f, n)
{
++ct; //number of objects
pc = new char[n]; //pc: pointer to data
for(int i = 0, i < n, i++)
pc[i] = f.pc[i];
}
执行深度复制
Useless two = one;//引用f将指向one
移动构造函数:
Useless::Useless(Useless && f) : n(f,.n) noexcept
//f.n number ofelements
{
++ct;
pc = f.pc; //steal address
f.pc = nullptr;// 将旧对象指向空指针方便delete[]
f.n = 0;
}
将pc指向现有的数据,以获取这些数据的所有权,pc与f.pc指向相同的数据,后续f.pc = nullptr 方便了delete[], delete 空指针完全没问题-----窃取 pilfering
修改了f对象, 因此不能const
Useless four(one + three); // 调用operator+(),,右值引用f将关联到operator()返回的临时对象temp,并调用移动构造函数
g++4.5 以后的c++11,自动优化,并忽视代码中的移动构造函数
18.2.3移动构造函数解析
要让移动语义发生,需要两个步骤,首先,右值引用让编译器知道合适可以使用移动语义
Useless two = one;// matches Useless::Useless(const Useless &)
Useless four (one+three);//matches Useless::Useless(Useless &&)
one是左值,与左值引用匹配,而one+three是右值,与右值引用匹配。因此,右值引用让编译器使用移动构造函数来初始化four
实现移动语义的第二步,编写移动构造函数,并提供所需的行为
g++编译器可以自动消除额外的复制工作,但是通过右值引用,程序员可指出何时使用移动语义
18.2.4 赋值运算符 --移动语义
Useless & Useless::operator=(const Useless & f) //copy assigment
{
if(this = &f)
return *this;
delete [] pc;
n = f.n;
pc = new char[n];
for(int i = 0; i < n; i++)
pc[i] = f.pc[i];
return *this;
}
Useless & Useless::operator=(Useless && f) noexcept//move assigment
{
if(this = &f)
return *this;
delete [] pc;
n = f.n;
pc = f.pc;
f.n = 0;
f.pc = nullptr;
return *this;
}
18.2.5 强制移动
移动构造函数和移动赋值运算符使用右值。但是如果想把左值用得像右值一样,如从对象数组中挑选一个并舍弃其他,默认左值引用,但是右值的话方便。
可以使用static_cast<>将对象的类型强制转换为Useless &&, 但C++11 提供了一种更简单的方式:
在头文件utility中声明有函数:std:move()。
int && rr3 = std::move(rr1); //ok
move告诉编译器,我们希望将左值rr1用得像右值一样,
e.g.
#include <i ostream>
#include < utility>
using namespace std;
int main()
{
int x = 1;
int y = 2;
int && r = x + y;
x = y = 5;
cout << r << " ";
int rr1 = 2;
int && rr3 = move(rr1);
++rr1;
cout << rr3 << " ";
int z = rr1 * 5;
cout << z << endl;
return 0;
}
输出:3 3 15
18.3 新的类功能
18.3.1 特殊的成员函数
原有四个——默认构造函数,复制构造函数,复制赋值运算符和析构函数,的基础上,C++11新增了:
移动构造函数,移动赋值运算符。这些成员函数是编译器在各种情况下自动提供的
没有提供任何参数的情况下,将调用默认构造函数,如果你没给任何构造函数,编译器自己提供一个默认的默认构造函数。
对于使用内置类型的成员,默认的默认构造函数将不对其进行初始化,对于属于类对象的成员,将调用其默认构造函数
如果没有提供赋值构造函数,代码又需要他,编译器将提供一个默认的赋值构造函数,同样的情况,编译器也会提供一个默认的移动构造函数
假定类名Classname:
Classname::Classname(const Classname &); //编译器给 默认复制构造函数
Classname::Classname(Classname &&); //编译器给 默认移动构造函数
同样 赋值运算符
Classname & Classname::operator(cosnt Classname &); //copy
Classname & CLassname::operator(Classname &&); //move
最后,没有定义析构函数,编译器也会给一个
class a
{
public:
int s;
};
int main()
{
a o;
o.s = 1;
cout << o.s << endl;
return 0;
}
输出:1
如果你提供了以上函数,编译器就不会多此一举
默认的移动构造函数和移动赋值运算符 工作方式和复制版本类似
18.3.2 默认的方法和禁用的方法
如果非要使用编译器提供的默认函数 加上default显示声明出来
class a
{
public:
a() = default; //使用编译器提供的默认构造函数
delete 用于禁止编译器使用特定方法
a & operator=(const a &) = delete; //禁止使用复制运算符
default只能用于6个特殊成员函数,毕竟编译器也只能提供这六个,delete可以用于任何成员函数
delete可以用来禁止特定的转换
class类中有函数
void func(double)
class sc;
sc.func(5);
将会把5 变成5.0参与运算
当有 void func(int) = delete;上述方法产生编译错误
18.3.3 委托构造函数
**多个构造函数可能包含相同的代码。也就是说有些构造函数可能需要包含其他构造函数已有的代码。但是为使得编码简单,C++11允许在一个构造函数的定义中使用另一个构造函数。即:委托。因为构造函数暂时将创建对象的工作委托给另一个构造函数。委托使用成员初始化列表语法的变种
e.g.
class Notes
{
int k;
double x;
std::string st;
public:
Notes();
Notes(int);
Notes(int ,double);
Notes(int, double, std::string);
};
Notes::Notes(int kk, double xx, std::string stt) : k(kk), x(xx), st(stt) {/ do stuff/}
Notes::Notes(int kk) : Notes(kk, 0.01, “Ah”) {/do other stuff/}
构造函数Notes(int),先 使用了第一个构造函数初始化数据成员并执行函数体,之后才执行自己的函数体
18.3.4 继承构造函数
为进一步简化编码工作, C++11 提供了一种让派生类能够继承基类构造函数的机制。默认构造函数,复制构造函数和移动构造函数除外。
也不会使用与派生类的构造函数的特征表匹配的构造函数
e.g.
class BS
{
int q;
double w;
public:
BS() : q(0), w(0) {}
BS(int k) : q(k), w(100) {}
BS(double x) : q(-1), w(x) {}
BS(int k, double x) : q(k), w(x) {}
void show() const { std::cout << q << w;}
};
class DR : public BS
{
short j;
public:
using BS:BS //将BS的构造函数继承了过来
DR() : j(-100) {} //DR 需要他自己的构造函数,默认构造函数不继承
DR(double x) : BS(2X), j(int(x)) {}
DR(int i) : j(-2), BS(i, 0.5i) {} //委托构造函数
void show() const (std::cout <<j; BS.show();}
};
int main()
{
DR o1; //use DR()
DR o2(18.81);// use DR(double) insted of BS(double)
DR o3(10, 1.8); // use BS(int, double)
}
继承来的基类构造函数只能初始化基类成员,派生类自有的成员,使用成员初始化列表语法
18.3.5 管理虚方法:override 和final
虚方法对实现多态类层次结构很重要,让基类引用或指针能够根据指向的队形类型调用相应的方法。虚方法陷阱:基类中声明的虚方法在派生类中重写将覆盖旧版本,特征表不匹配将 隐藏而不是覆盖旧版本
C++11 中,使用虚方法说明符overrid指出要覆盖的一个虚函数,将其放在参数列表后面,如果声明与基类方法不匹配,编译器将报错
如果想禁止派生类覆盖特定的虚方法,参数列表后加上final。加上后,你讲无法在派生类中重新定义该虚函数
18.4 Lambda函数/Lambda表达式
18.3—《C++高级编程》
18.4.1 比较函数指针、函数符(函数对象)和Lambda函数
补充知识
【C++】回调函数与仿函数
https://blog.csdn.net/weixin_43723269/article/details/121595303
回调函数就是一个被作为参数传递的函数。在C语言中,回调函数只能使用函数指针实现,在C++、Python等更现代的编程语言中还可以使用仿函数或匿名函数。
而这个约束我们希望不将他写死
C-函数指针
bool (*compare)(int, int);//函数指针定义
compare=compareUp;//compareup 定义好的函数
void bubbleSort(vector<int>& arr, bool (*compare)(int&, int&))//将函数指针作为排序函数的参数,它接收一个函数的地址
{
for (int i = 0; i < arr.size(); i++)
{
for (int j = i + 1; j < arr.size(); j++)
{
if (compare(arr[i], arr[j]))
{
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
}
}
}
lambda表达式(匿名函数)
另外,在我们不想声明定义一个过于简单的函数时,可以使用lambda表达式(匿名函数),匿名函数也可以传入函数指针中使用:
void test02()
{
//使用匿名函数作为函数指针
vector<int>b = { 9,3,5,23,12,34,16,8,20 };
cout << "从小到大排序(匿名函数)" << endl;
bubbleSort(b, [](int& v1, int& v2) { return v1 > v2 ? true : false; });
printVectorInt(b);
}
仿函数 --函数符--类对象
仿函数(Functor)又称为函数对象(Function Object)是一个能行使函数功能的类
顾名思义,仿函数即仿照的函数,表示它功能与函数类似但并不是真正的函数,仿函数又叫函数对象。在C++中它通过重载函数调用运算符即()运算符
谓词
是一个可调用的表达式,其返回结果是一个能用作条件的值,标准库算法所使用的的谓词分两类:
一元谓词--unary predicate,意味着只接受单一参数
二元谓词--binary predicate,接受两个参数
接受谓词参数的算法对输入序列中的元素调用谓词,因此元素类型必须能转换谓词的参数类型
返回bool类型的仿函数称为谓词
如果operator()接受一个参数,那么叫做一元谓词
如果operator()接受两个参数,那么叫做二元谓词
//定义排序规则的仿函数类--从小到大
在仿函数的类中,通常不需要定义构造函数和析构函数,这将由系统帮我们自动完成。值得一提的是,我们最好将重载operator()的函数定义为常函数,这表明我们并不会改变传入的参数,避免一些麻烦。
class compareUp
{
public:
bool operator()(const int& val1, const int& val2) const {//定义为常函数
if (val1>val2)
{
return true;
}
return false;
}
};
总结
使用回调函数(函数指针实现)与使用仿函数优缺点比较
1.当需要回调的功能函数比较简单时,通常声明为内联函数,这时函数调用将被展开,此时与仿函数性能差别不大;但是使用函数指针实现的回调函数它终究是函数,如果我们需要保留某些状态,这时函数无法实现,因为在函数调用结束后,内部数据都被释放了。而仿函数可以做到这一点,例如我们需要实现记录某一个回调逻辑在程序运行中被调用了多少次,这在普通函数内只能通过一些外部的静态变量来实现;而在仿函数中,我们可以通过给类添加属性,来记录一些状态,而不是使用外部的变量。
2.当需要回调的功能函数比较复杂时,此时回调函数作为一个函数指针传入,其代码亦无法展开。而仿函数则不同。虽然功能函数本身复杂不能展开,但是对仿函数的调用是编译器编译期间就可以确定并进行inline展开的。因此在这种情形下,仿函数比之于回调函数,有着更好的性能。
Lambda表达式------重要
原文链接:https://blog.csdn.net/YGG12022/article/details/124043116
C++11的一大亮点就是引入了Lambda表达式。利用Lambda表达式,可以方便的定义和创建匿名函数。
声明Lambda表达式
Lambda表达式完整的声明格式如下:
[capture list] (params list) mutable /cosntexpr exception/attributes/->return type { function body }
各项具体含义如下:
capture list:捕获外部变量列表,可在表达式中使用
params list:形参列表
mutable指示符:允许 函数体 修改复制捕获的对象,以及调用它们的非 const 成员函数
constexpr:用此,可在编译时计算。若满足constexpr,及时没有这个标记,也会隐式使用
exception:异常设定 如noexcept
attribute:《C++高级编程-chapter11》
return type:返回类型
function body:函数体
举例:
double pi = 3.14;
auto lambda = [lambda = "pi = ", pi] (int a, int b) mutable
->int { cout << lambda <<": " << pi <<" a+b=: " << a+b << endl;
pi+=1;
cout << pi << endl;
return a+b;
};
int a = lambda(1, 2);
cout << a << endl;
/*输出结果:
pi = : 3.14 a+b=: 3
4.14
3
*/
此外,我们还可以省略其中的某些成分来声明“不完整”的Lambda表达式,常见的有以下几种:
[capture list] (params list) -> return type {function body} //声明了const类型的表达式,这种类型的表达式不能修改捕获列表中的
[capture list] (params list) {function body}
//省略了返回值类型,但编译器可以根据以下规则推断出Lambda表达式的返回类型:
(1):如果function body中存在return语句,则该Lambda表达式的返回类型由return语句的返回类型确定;
(2):如果function body中没有return语句,则返回值为void类型。
[capture list] {function body} //格式3中省略了参数列表,类似普通函数中的无参函数。最简单的lambda表达式
当以 auto 为形参类型或显式提供模板形参列表 (C++20 起)时,该 lambda 是泛型 lambda。
auto func = [] (auto i) { …}
捕获外部变量
Lambda表达式可以使用其可见范围内的外部变量,但必须明确声明(明确声明哪些外部变量可以被该Lambda表达式使用)。Lambda表达式通过在最前面的方括号[]来明确指明其内部可以访问的外部变量,这一过程也称过Lambda表达式“捕获”了外部变量。
int main()
{
int a = 123;
auto f = [a] { cout << a << endl; };
f(); // 输出:123
//或通过“函数体”后面的‘()’传入参数
auto x = [](int a){cout << a << endl;}(123);
}
C++11中的Lambda表达式捕获外部变量主要有以下形式:
[变量名, …] 默认以值得形式捕获指定的多个外部变量(用逗号分隔),如果引用捕获,需要显示声明(使用&说明符)
*[=] 以值的形式捕获所有外部变量 都隐式地以传值方式加以引用。
[&] 以引用形式捕获所有外部变量 都隐式地以引用方式加以引用
[=, &x] 变量x显式的以引用形式捕获,其余变量以传值形式捕获
[&, x] 变量x显式的以值传递形式捕获,其余变量以引用形式捕获
[] 不捕获任何外部变量
[this] 当前对象的简单的以引用捕获
[this] 当前对象的简单的以复制捕获,lambda执行时对象消失,仍可执行
对于[=]或[&]的形式,lambda 表达式可以直接使用 this 指针。但是,对于[]的形式,如果要使用 this 指针,必须显式传入:
[[ this] ]() { this->someFunc(); }();
建议指定要捕捉的变量,减少开销
1、值捕获
值捕获和参数传递中的值传递类似,被捕获的变量的值在Lambda表达式创建时通过值拷贝的方式传入,因此随后对该变量的修改不会影响影响Lambda表达式中的值。
int main()
{
int a = 123;
auto f = [a] { cout << a << endl; };
a = 321;
f(); // 输出:123
}
这里需要注意的是,如果以传值方式捕获外部变量,则在Lambda表达式函数体中不能修改该外部变量的值。
[data] () muteable {…}; // muteable前必须加(),这样允许 函数体 修改复制捕获的对象的副本
没用到的不会捕捉
2、引用捕获
没用到的不会捕捉
使用引用捕获一个外部变量,只需要在捕获列表变量前面加上一个引用说明符&。如下:
int main()
{
int a = 123;
auto f = [&a] { cout << a << endl; };
a = 321;
f(); // 输出:321
}
从示例中可以看出,引用捕获的变量使用的实际上就是该引用所绑定的对象,lambda表达式可直接在其内部作用域内修改捕获的引用对象。确保lambda执行时,引用有效
3、隐式捕获
上面的值捕获和引用捕获都需要我们在捕获列表中显示列出Lambda表达式中使用的外部变量。除此之外,我们还可以让编译器根据函数体中的代码来推断需要捕获哪些变量,这种方式称之为隐式捕获。隐式捕获有两种方式,分别是[=]和[&]。[=]表示以值捕获的方式捕获外部变量,[&]表示以引用捕获的方式捕获外部变量。
int main()
{
int a = 123;
auto f = [=] { cout << a << endl; }; // 值捕获
f(); // 输出:123
}
int main()
{
int a = 123;
auto f = [&] { cout << a << endl; }; // 引用捕获
a = 321;
f(); // 输出:321
}
4、混合方式
上面的例子,要么是值捕获,要么是引用捕获,Lambda表达式还支持混合的方式捕获外部变量,这种方式主要是以上几种捕获方式的组合使用。
怎样修改捕获的变量
int main()
{
int a = 123;
auto f = amutable { cout << ++a; }; // 不会报错
cout << a << endl; // 输出:123
f(); // 输出:124
}
5、捕捉表达式
double pi = 123.321;
auto lambda = [capture = " pi = ", pi] {std::cout << capture << pi;};
用捕捉初始化器初始化的非引用捕捉变量,如capture,是通过复制构建的。可用于任何类型的表达式初始化,std::move(),可用于不能复制,只能移动的对象,如unique_ptr(只能通过move,将所有权转交)
auto ptr = make_unique< double> (3.12);
auto my = [p = move(ptr)] {};
捕捉变量允许使用所在作用域内相同的名称
auto ptr = make_unique…
auto lam = [myptr =move(myptr)] { cout << *myptr;} ; //捕捉的myptr与表达式内的同名
返回lambda表达式
function<int(void)> fun(int x)
{
return [x] { return 2 * x;};
}
//function<int(void)> --返回一个匿名函数,返回值int,不接受参数,只管输出捕获x的二倍
//可用auto代替
function<int(void)> fn = fun(15);
cout << fn() << endl;
//定义了个匿名函数fn, 用fun(15) 赋值
必须按值捕获,不能捕获引用。即上述函数汇总改为[&x] 不行
Lambda表达式的参数
Lambda表达式的参数和普通函数的参数类似,还有一些限制:
参数列表中不能有默认参数,因此lambda调用的实参数目永远与形参相等
不支持可变参数
所有参数必须有参数名
18.4.2 为何使用lambda
将相关的代码放在一起,lambda是理想的选择,因为其定义和使用在同一个地方进行
重复使用的lambda表达式,可以制定一个名称
auto mod3 = [](int x) { return x % 3 == 0;} //mod3 成为了lambda表达式的名称,科重复用
count1 = std:count_if(n1.begin(), n1.end(), mod3);
可以向常规函数一样使用有名称的lambda
bool result = mod3(z); // result is true if z % 3 == 0
18.5 包装器
包装器wrapper,也叫适配器adpater。这些对象用于给其他编程接口提供一致或更适合的接口
bind 第十六章// https://blog.csdn.net/dongkun152/article/details/123992292
men_fun 能够将成员函数作为常规函数进行传递
reference_wrapper 能够创建行为像引用但可被复制的对象
function 能够以统一的方式处理多种类似于函数的形式
参数绑定--bind()--<functional>
接受一个可调用对象,生成一个新的可调用对象来适应原对象的参数列表
auto newCallable = bind(callable, arg_list);
newCallable 本身是一个可调用对象, arg_list是一个都好分隔的参数列表,对应给定的callable参数
即,我们调用newcallable,它会接着调用callable,并传递arg_list中的参数
arg_list中的参数可包含形如 _n的数字,用来表示占位符,表示newcallable中的参数,占据了传递给newcallable的参数的位置,数值n表示生成的可调用对象总参数的位置: _1 newcallable的第一个参数, _2 第二个。。。
e.g.
使用bind生成一个调用check_size的对象,
/*check6是一个可调用对象,接受一个string类型的参数,
并使用此string和值6调用check_size
*/
auto check6 = bind(check_size, _1, 6);
只有一个占位符_1,表示check6只接受一个参数,并且因为出现在参数列表第一个位置,因此check6的这个参数对应check_size中的第一个参数,是一个const string& 的参数
翻译过来就是:调用check6必须传递给他一个string类型的参数,check6拿着它调用check_size
string s = "hello";
bool b1 = check6(s); // check(s)调用check_size(s,6)
因此可以将以下lambda表达式替换掉
auto wc = find_if(words.begin(), words.end(), [sz](const string &a));
-->
auto wc = find_if(words.begin(), words.end(), bind(check_size, _1, sz));
此bind调用生成一个可调用对象,将check_size 的第二个参数绑定到sz。当find_if 对words的``string`调用这个对象时,这些对象会调用check_size,将给定的··string··和··sz··传递给他
名字_n都定义在一个名为placeholders的命名空间中,它本身又定义在std中
using namespace std::placeholders
#include <iostream>
#include <functional>
using namespace std;
using namespace std::placeholders;
void func(int a, int b, int c)
{
cout << (a -b -c) << endl;
}
int main(int argc, char *argv[])
{
auto fn1 = bind(func, _1, 2, 3);
auto fn2 = bind(func, 2, _1, 3);
fn1(10);
fn2(10);
return 0;
}
/*
输出:
5
-11
*/
18.5.1 包装器function及模板的低效性–P825
answer= ef(q)
ef可以是函数名,函数指针,函数对象或有名称的lambda表达式,导致模板效率低,正常情况下,每种可调用类型都会实例化模板一次
调用特征标:由返回类型及参数类型决定
function模板定义在<functional>中,从调用特征标的角度定义一个对象,用于包装调用特征标相同的函数指针 函数对象 或lambda
std::function<double(char, int)> fdci;
然后可以将满足要求的可调用类型付给它
P825 例子中 可以使用function<double(double)> 创建六个包装器,用于六个函数,仿函数和lambda
这样对use_f()六次调用中, 访问相同的(functioin<double(double))—只实例化一次
function<double(double)> ef3 = Fq(10.0);
use_f(y, ef3);
优化
不用声明六个function<double(double)>
typedef function<double(double)> fdd; //简化
cout << use_f(y, fdd(dub)) << endl; // 创建并初始化指向dub函数的对象P 826
18.6 可变参数模板
创建参数数量可变的函数模板和模板类
要点:
模板参数包 函数参数包 展开参数包 递归
18.6.1 模板和函数参数包
C++11提供了一个用省略号表示的元运算符 meta-operator, 用来声明表示模板参数包的标志符
模板参数包基本上是一个类型列表。同时,能够用来声明表示函数参数包的标志符,它是一个值列表
template<typename...Args> //Args is a template parameter pack
void show_list(Args...args){} //args is a function parameter pack
// type is Args
Args可以匹配任意数量的类型
show_list('s',80,“haha”,4.5);
18.6.2 展开参数包
可将省略号放在函数参数包右边,将参数包展开
template<typename...Args> //Args is a template parameter pack
void show_list(Args...args) //args is a function parameter pack
{
// passes unpacked args to show_list1()...为了访问某一个参数
show_list(args...);
} // 导致无限递归
/*
在函数模板 show_list1 的实现中,递归调用了自身。
当传入参数时,该函数会继续调用自身,并且参数没有发生变化,
因此会无限循环调用自身,导致无限递归的问题。
*/
18.6.3 在可变参数模板函数中使用递归
上述代码提供了思路:将函数参数包展开,对列表中的第一项进行处理,剩余的传递给递归调用,交给下一层处理,直到列表为空。
template<typename T, typename...Args>
void show_lis3(T value, Args...args)
{
std::cout << value << ", ";
show_list3(args...);
}
可以显示T value 并将剩余的args 向下传递
对于大量值,替换为
show_list3(const Args&…args); 将每个函数参数引用const &
// variadic2.cpp
#include <iostream>
#include <string>
// definition for 0 parameters
void show_list() {}
// definition for 1 parameter
template<typename T>
void show_list(const T& value)
{
std::cout << value << '\n';
}
// definition for 2 or more parameters
template<typename T, typename... Args>
void show_list(const T& value, const Args&... args)
{
std::cout << value << ", ";
show_list(args...);
}
int main()
{
int n = 14;
double x = 2.71828;
std::string mr = "Mr. String objects!";
show_list(n, x);
show_list(x*x, '!', 7, mr);
return 0;
}
18.7 C++11 新增的其他功能
18.7.1 并行编程
C++定义了一个支持线程化执行的内存模型,添加了关键字thread_local,和相关库
thread_local 将变量声明为静态存储,其持续性与特定线程相关:即定义这种变量的线程过期时,变量过期
库支持由原子操作(auto operation)库和线程支持库组成
< atomic>, 线程支持库提供了thread mutex condition_variable future
18.7.2 新增的库
< regex> 正则表达式
18.8 语言变化
18.8.3 使用Boost库
18.9 接下来的任务
OOP方法的基本活动之一是发明能够表示正在模拟的情形–问题域的类,逐步迭代
常用技术:
用例分析/use-case analysis,
开发小组列出常见的使用方式和最终系统将用于的场景:找出元素、操作、职责。
以确定可能要是用的类和类特性
CRC 卡:
Class/Responsibilities/Collaborators
卡片是一种分析场景的简单方法,开发小组为每个类创建索引卡片,卡片上列出类名,类职责(如表示的数据和执行的操作),类的写作者(如必须与之交互的其他类)。然后,小组使用CRC卡片提供的接口模拟场景,这可能提出新的类。转换责任等
更大规模上,是用于整个项目的系统方法。最新的建模语言,Unified Modeling Language, UML--软件工程
用于表示编程项目的分析和设计语言。
重要的类库
附录
alignof --等用到的
noexcept–指出函数不会引发异常,也可用作运算符,判断操作数/表达式是佛能引发异常,如果引发了返回false,否则返回true
int halt(int) noexcept; //true
F string P870
G STL
H Reference