前言
并发数据结构的设计意图是让多线程并发访问。只要满足以下条件,我们就认为这是一个线程安全的数据结构:
多线程执行的操作无论异同,每个线程所见的数据结构都是自洽的;
数据不会丢失或破坏,恶性条件竞争不会出现。
并发设计的意义在于提供更高的并发成都,让各线程有更多机会按并发方式访问数据结构。
互斥使多个的访问互相排斥:在一个互斥上,每次只能让一个线程获取锁。互斥保护数据结构的方式明令禁止真正的并发访问。即以上称作串行化:每个线程轮流访问受互斥保护的数据,它们只能先后串行依次访问,而非并发访问。
所以,我们思考一下,如何制作支持真正的并发访问。这时候我们需要理解一点:锁保护的范围越小,需要的串行化操作少,并发成度就越高。
一、设计并发数据结构的指引
– 确保访问安全,实现真正的并发访问。–
数据结构的使用者应该受到什么样的条件限制?
如果有线程能通过特定的函数访问数据结构,那么哪些函数可以安全的跨线程调用?
首先,构造函数和析构函数都需要排他性方式执行。数据结构的使用者须自行保证这一点:在析构函数完成以前和析构函数开始之后,访问不会发生。
如果数据结构支持赋值、内部数据互换或拷贝构造等操作,且数据结构还具备多个处理函数,那么即便其中绝大部分函数可由多线程安全地并发调用,但是身为数据结构的设计者,我们依然有责任决断:这些函数与其他操作一起并发调用是否安全,以及这些函数是否要求使用者保证以排他方式访问。
第二个要考虑的方面则是实现真正的并发访问。我们无法就此给出太多建议,然而身为数据结构的设计者,我们需要思考下列问题。
■能否限制锁的作用域,从而让操作的某些部分在锁保护以外执行?
■数据结构内部的不同部分能否采用不同的互斥?
■是否所有操作都需要相同程度的保护?
■能否通过简单的改动,提高数据结构的并发程度,为并发操作增加机会,而不影响操作语义?
这些问题全部都归结为一个核心问题:我们如何才可以只保留最必要的串行操作,将串行操作减少至最低程度,并且最大限度地实现真正的并发访问?若线程仅仅读取数据结构,就容许它们并发访问,而改动数据结构的线程则必须以排他方式访问。这种模式并不罕见,利用构造对象即可实现(如std::shared mutex)。类似地,我们很快会看到另一种颇为常见的情形:某些数据结构支持其并发访问,能让多个线程执行不同的操作,然而对于同一项操作,只允许多个线程按串行化方式执行。
利用互斥和锁保护的数据结构具有代表意义,是最简单的、线程安全的数据结构。
之前已经分析过,这种方式其实存在问题,但它相对简单,能确保每次只有一个线程
访问数据结构。我们循序渐进,逐步深入线程安全的数据结构的设计。
二、基于锁的并发数据结构
设计基于锁的并发数据结构的奥义就是,要确保先锁定合适的互斥,再访问数据
并尽可能缩短持锁时间。即使仅凭一个互斥来保护整个数据结构,其难度也不容忽视。
我们已经分析过,需要保证不得访问在互斥锁保护范围以外的数据,且成员函
数接口上不得存在固有的条件竞争。若针对数据结构中的各部分分别采用独立互斥,这
两个问题就会互相混杂而恶化。另外,假使并发数据结构上的操作需要锁住多个互斥,
则可能会引发死锁。所以,相比只用一个互斥的数据结构,如果我们考虑采用多个互斥
就需要更加谨慎。
1.单线程队列的简单实现
上一篇文章我们其实尽保护了一项数据 – data_queue,也只用到了一个互斥。为了采用惊喜粒度的操作,我们需要深入队列的实现为不同的数据单独使用互斥。
单向链表可以充当队列的最简单的数据结构,有一个 “头指针 head” – 指向头节点,每个节点再依次指向后继节点。队列弹出数据的方法是更改 head指针:将指向的目标改为其后继节点,并返回原来的第一项数据。
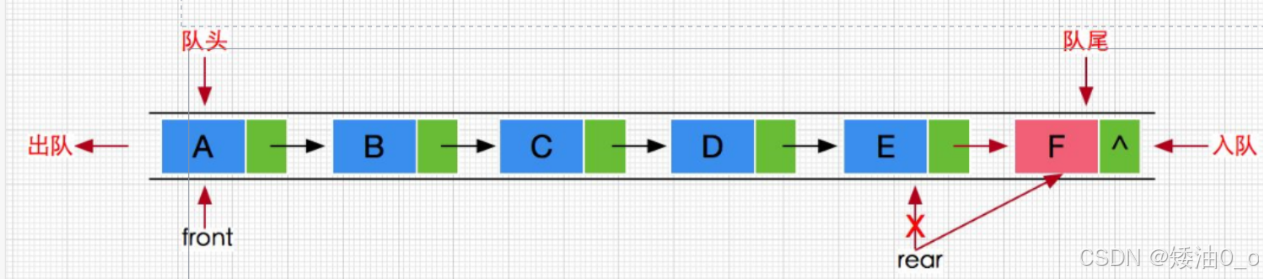
新数据从队列末端加入 – 队列另外维护一个 “尾指针 tail”,指向尾节点。如果有新的节点加入,则将为节点的 next 指针指向新节点,并更新 tail 节点,令其指向新节点。如果队列为空,则将 head 和 tail 指针都设置为nullptr。
代码如下(示例):
template<typename T>
class queue
{
private:
struct node
{
T data;
std::unique_ptr<node> next;
node(T data):
data(std::move(data))
{}
};
std::unique_ptr<node> head;①
node*tail;②
public:
queue():tail(nullptr)
{}
queue(const queue& other)=delete;
queue& operator=(const queue& other)=delete;
std::shared_ptr<T> try_pop()
{
if (!head)
{
return std::shared_ptr<T>();
}
std::shared_ptr<T>const res(
std::make_shared<T>(std::move(head->data)));
std::unique_ptr<node> const old_head=std::move (head);
head=std::move(old_head->next);③
if(!head)
[
tail=nullptr;
}
return res;
}
void push(T new_value)
{
std::unique_ptr<node> p(new node(std::move(new_value)));
node*const new_tail=p.get();
if(tail)
{
tail->next=std::move(p);
}
else
{
head=std::move(p);⑤
}
tail=new_tail;⑥
}
};
首先,请注意代码清单采用 std::unique ptr管控节点,通过其自身特性
保,当我们不再需要某个节点时,它和所包含的数据即被自动删除。从队列的头节点开始一直到队列末端,相邻节点之间都按前后顺序关系。末端节点已划给前方节点的std:uniquept指针所有,但我们仍须对它进行直接操控,所以通过一个原生指针(提及的“tail指针”)指向它。
虽然这种实现在单线程模式下工作不错,但是如果我们换成多线程模式,并试图
合精细粒度的锁,其中几个细节就会引发问题。假设队列含有两项数据–head指
①和 tail 指针②,原则上我们可以使用两个互斥分别保护 head 指针和 tail 指针,但问
题随之而来。
最明显的问题是,push(可以同时改动head 指针⑤和 tail 指针⑥,所以该函数载
要将两个互斥都锁住。尽管这并不合适,但同时锁住两个互斥的做法还算可行,问题不大
。严重的问题在于,push()和try_pop()有可能并发访问同一节点的next指针:
更新 tai->next④,而try_pop()则读取 head->next。如果队列仅含有一项数据
head,那么head-next和tail->next两个指针的目标节点重合,而它需要被保护。
假设我们没有该取头节点和尾节点的内部数据,无法辨别是否是一个节点、
就会在同时执行push()和try_pop()的过程中,无意中锁定同一互斥,我们要如何破局?
2.通过分离而实现并发
我们可以预先设立一个不含数据的虚位节点(dummy node),从而确保至少存在一个节点,以区别头尾两个节点的访问。
如果队列为空,head 和 tail 两个指针都不再是 nullptr,而是同时指向虚位节点。这很不错,因为孔队列的try_pop() 不会访问head->next。
初始化时 head 与 tail 相同

我们向队列添加数据,则head 和 tail 指针会分别指向不同的节点,在 head->next 和 tail->next 上不会出现竞争。但缺点是,为了容纳虚位节点,我们需要通过指针间接存储数据,额外增加了一个访问层级。
代码如下(示例):
template<typename T>
class queue
{
private:
struct node
{
std::shared_ptr<T> data;①
std::unique_ptr<node> next;
};
std::unique_ptr<node> head;
node* tail;
public:
queue():
head(new node),tail(head.get())②
{}
queue(const queue& other)=delete;
queue& operator=(const queue& other)=delete;
std::shared ptr<T> try_pop()
{
if(head.get()==tail)③
{
return std::shared_ptr<T>();
}
std::shared ptr<T>const res(head->data);④
std::unique ptr<node> old_head=std::move(head);
head=std::move(old_head->next);⑤
return res;
}
void push(T new_value)
{
std::shared_ptr<T> new_data(
std::make_shared<T>(std::move(new_value)));⑦
std::unique_ptr<node> p(new node);⑧
tail->data=new_data;⑨
node* const new_tail=p.get();
tail->next=std::move(p);
tail=new_tail;
}
);
try_pop的改动相当小。首先,由于引人了虚位节点,head 指针不再取值nullptr
因此我们不再判别它是否为nullptr,而改为比较指针 head 和 tail 是否重叠③。因为head
指针的类型是std:unique_ptr,所以我们调用 head.get来进行比较运算。其次
节点现已改为通过指针存储数据①,所以在弹出操作中,我们直接获取指针④,而不再
构建T类型的实例。最大的变化是push,我们必须先在堆数据段上创建T类型的新实
例,通过std::shared_ptr管控其归属权⑦(请注意我们采用了std::make_shared,以避
免因引用计数而出现重复内存分配)。新创建的节点即为虚位节点,故无须向构造函数
提供new_value 值⑧。为了代替原来的增加数据的行为,我们将前面的共享指针⑦存入
原来的虚位节点⑨,则该节点的数据变为新近创建的new_value副本。最后,我们在队
列的构造函数中创建虚位节点②。
总结
行文至此,大家会问,这些改动带来了什么好处?它们对队列的线程安全有何帮助吗?
回答是 – push 只访问tail指针而不再触及head指针,这就是一个好处。虽然 try_pop
既访问 head 指针又访问 tail 指针,但 tail指针只用于函数中最开始的比较运算,所以只
需短暂持锁。最大的好处来自虚位节点,它存在的意义是:try_pop和push不再同时
操作相同的节点,所以我们不再需要由一个互斥统领全局。那就是,指针head 和tail
可以各用一互斥保护。但是,具体应该在哪一处加锁呢?
我们的目标是最大程度实现真正的并发功能,让尽可能多的操作有机会并发进行,
所以希望持锁时长最短。push不难处理。tail指针的全部访问都需要对互斥加锁,即新
节点一旦创建完成,我们就马上锁住互斥⑧,在将数据赋予当前的尾节点之前⑨,也要
锁住互斥。该锁需要一直持有,等到函数结束才释放。
try_pop的处理则不太简单。首先,我们需要为head 指针锁住互斥并一直持锁,等
到它使用完成才解锁。互斥会被多个线程争抢,这将决定哪个线程弹出数据,故我们在
最开始就要锁定互斥。一旦 head 指针的改动完成⑤,互斥即可解锁,结果的返回操作
无须互斥保护。
余下的只有tail指针的访问,它需要在对应的互斥上加锁。因为我们只需在 try_pop
内部访问tail指针一次,所以在临近读取指针之前再对互斥加锁。最好将加锁和访问包
装成同一个函数。实际上,因为仅有try_pop成员函数中的部分语句需锁住head_mutex
所以将它们包装成一个函数会显得更清晰。
emmm,要知代码如何写,请见下文分解…