我的新站 https://swy20190.github.io
P1
设A的端口为
α
\alpha
α,B的端口为
β
\beta
β.
a) 源端口号
α
\alpha
α,目的端口号23
b) 源端口号
β
\beta
β,目的端口号23
c) 源端口号23,目的端口号
α
\alpha
α
d) 源端口号23,目的端口号
β
\beta
β
e) 有可能相同
f) 不可能相同
P2
源端口号80,目的端口号7532(C),26145(C),26145(A)
源IP为B,目的IP为A或C。
P3
01010011
01100110
01110100
00101110
取反,11010001
采用反码方案,不必依赖系统是大端还是小端
差错检验方法:将收到的数据与检验和相加,所得的结果如果有任一位为0,即为出错。
1比特的差错不可能检测不出,2比特的差错可能检测不出。
P4
a) 00111110
b) 10111111
c) 01011101,01100100
P5
不能,显然
P6
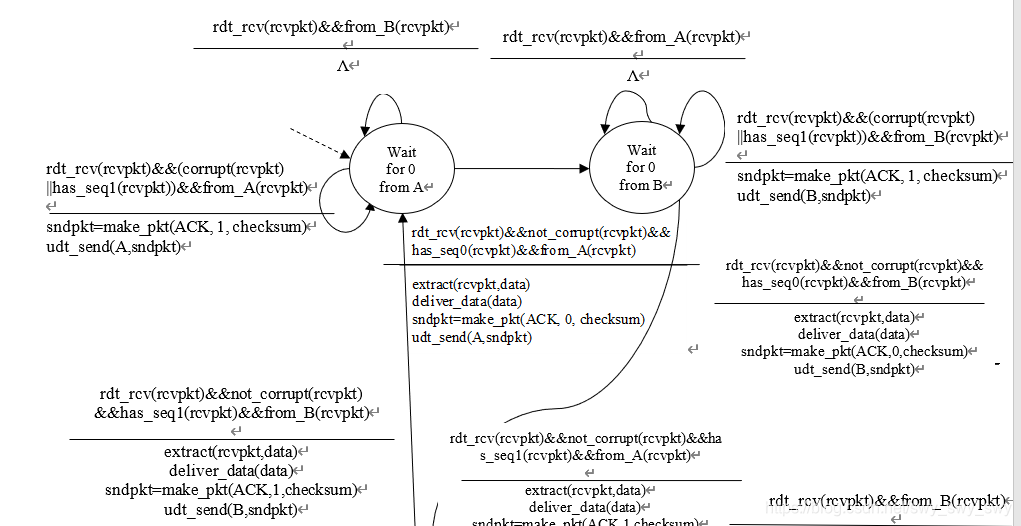
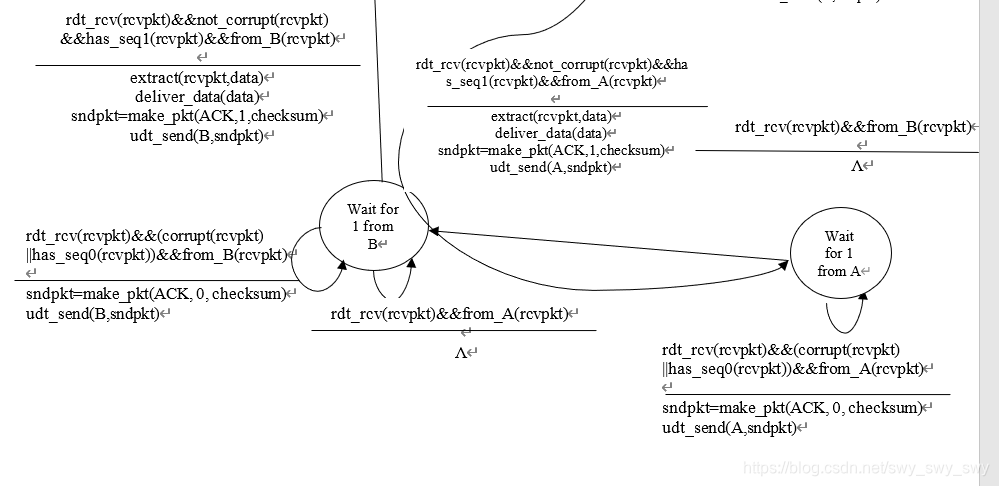
假如发送端重发了依次0或1,则陷入死锁:接收端一直在等待正确的包,但发送端一直在重复发送错误的包。
P7
因为是停等协议,只要在当前位置重传即可,不需要表明序号(也就是数据在字节流中的起始位置)
P8
略
P9
略
P10
在发送方加入start_timer以及timeout事件,注意timer要大于RTT
P11
前一种情况,可以正常工作,因为sndpkt在之前状态转移的过程中已经生成;
后一种情况,在第一个数据包损坏后,ACK是一个错误的值,发送方会认为ACK错误,从而重复发送当前的包,进入死锁。
P12
仅有一个比特差错时,正常工作;定时器过早超时,会导致重发的包从1累计到n,n趋于无穷时,第n个分组将被发送无穷次。
P13
draw your horse
P14
偶尔发送数据,NAK不如ACK,因为此时接收方判断丢失是依据数据包的上下文,也就是说,当丢失的包的下一个包被接收时,才会发现丢包,所以可能很长时间才发现丢包。
大量数据,使用NAK更好,可以减小数据流量
P15
N
L
/
R
R
T
T
+
N
L
/
R
\frac{NL/R}{RTT+NL/R}
RTT+NL/RNL/R=90%
解得N=278
P16
能增加信道利用率;会有大量问题,比如,若连续丢2个包则根本不会被检测到。
P17
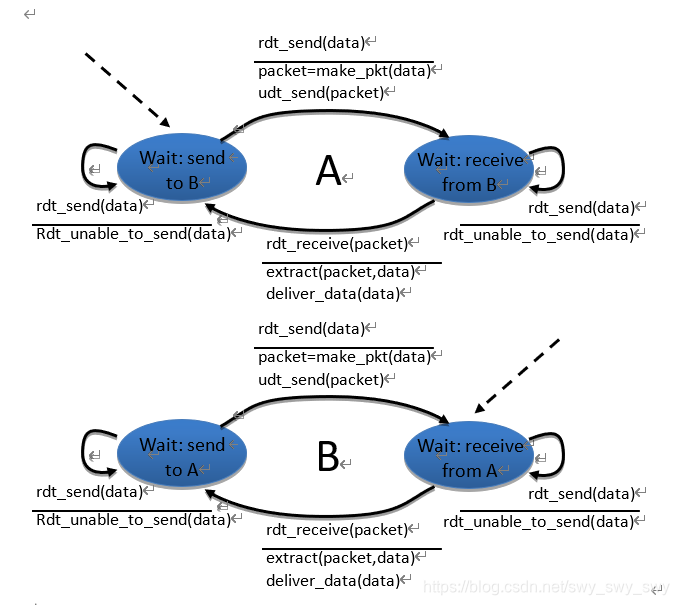
P18
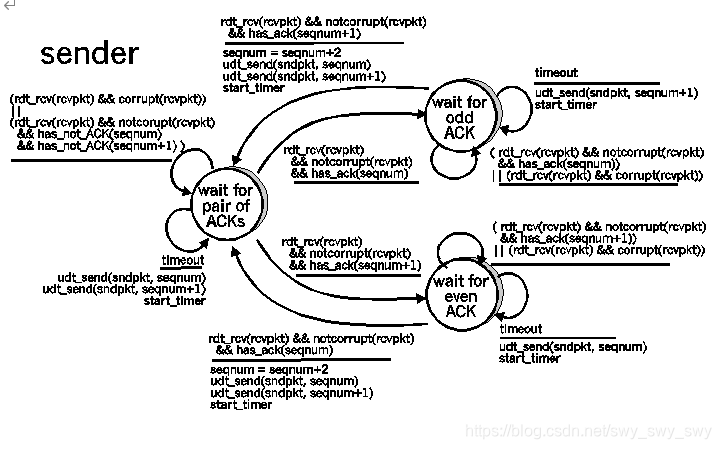
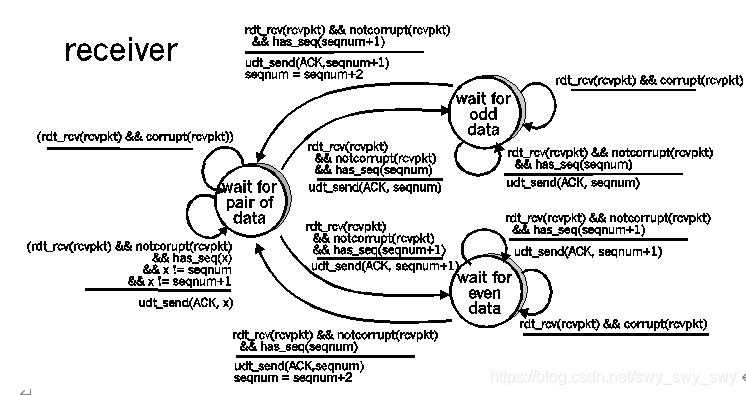
P19
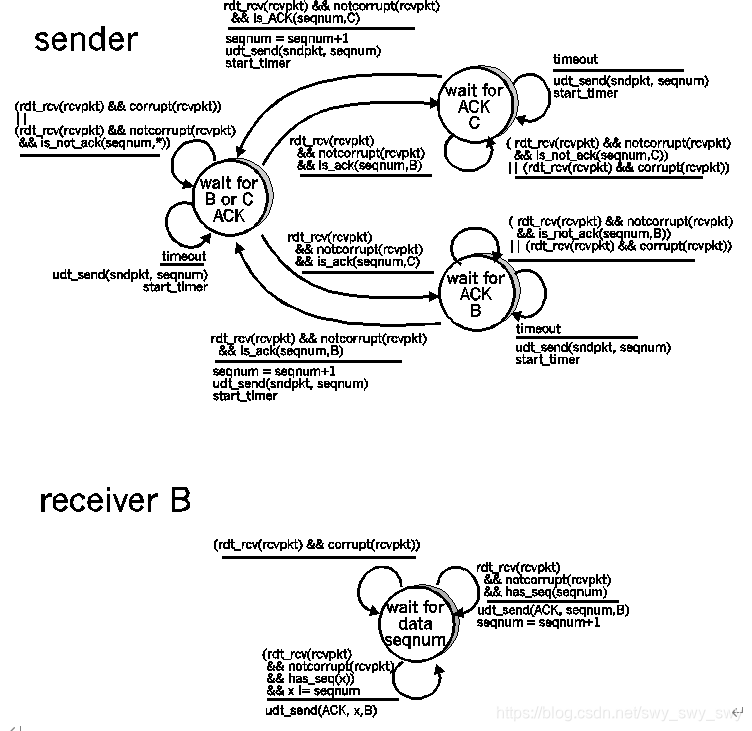
P20
发送端同教材图3.15