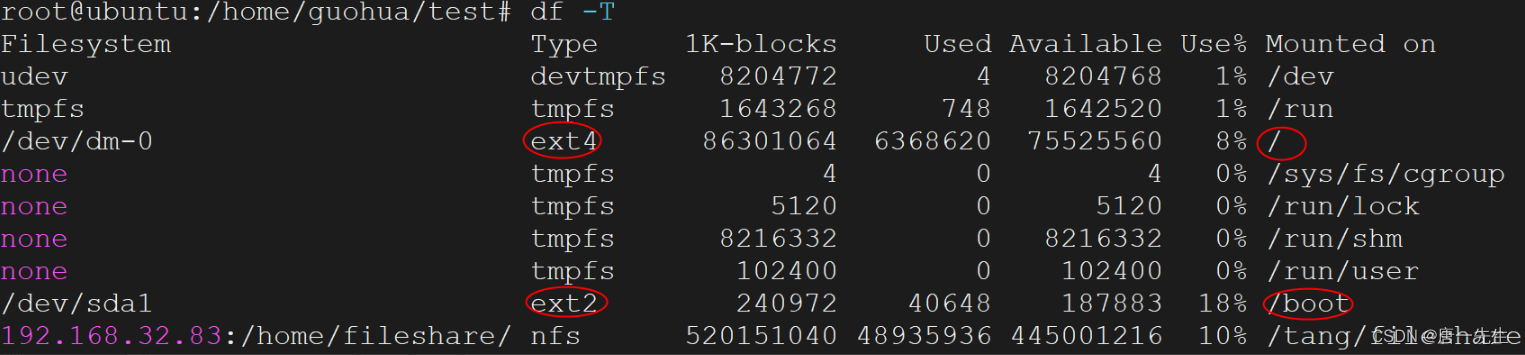
Linux内核支持十多种不同类型的文件系统
典型的 Linux 文件系统由 bootfs 和 rootfs 两部分组成,bootfs(boot file system) 主要包含 bootloader 和 kernel,bootloader 主要是引导加载 kernel,当 kernel 被加载到内存中后 bootfs 就被 umount 了。 rootfs (root file system) 包含的就是典型 Linux 系统中的 /dev,/proc,/bin,/etc 等标准目录和文件。
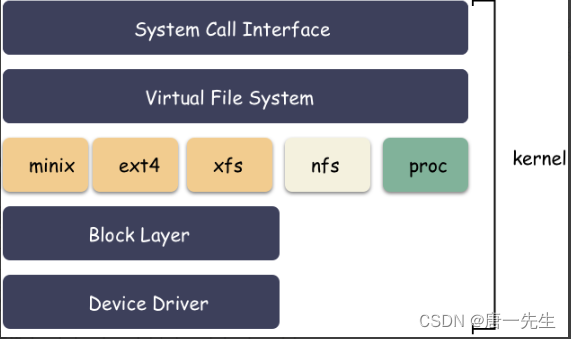
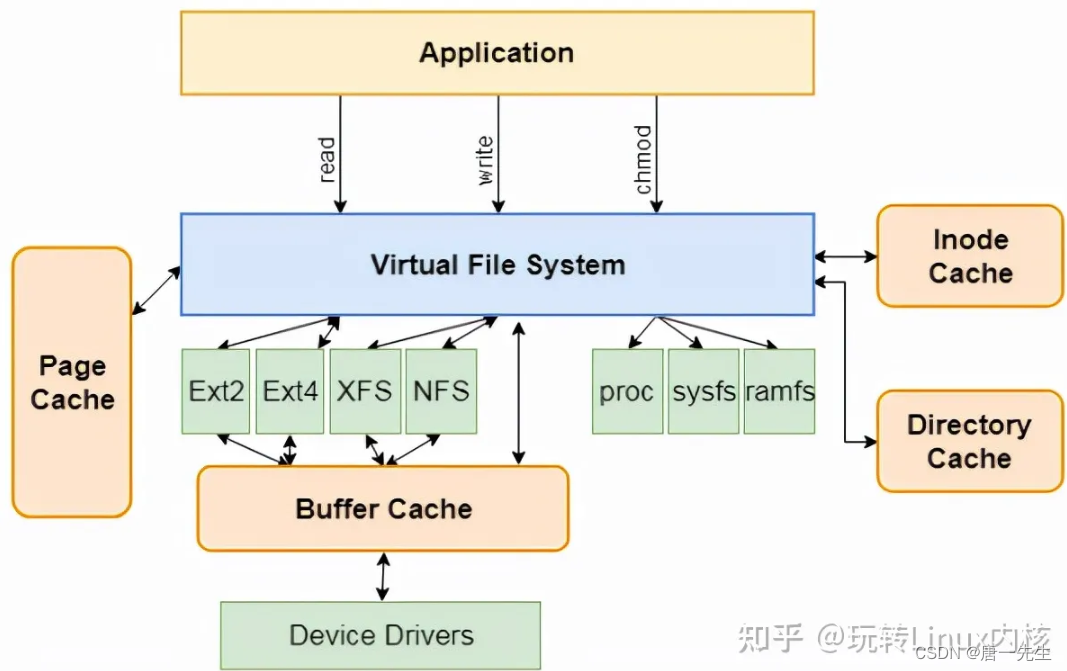
VFS,虚拟文件系统(Virtual File System,简称VFS)是Linux内核的子系统之一,它为用户程序提供文件和文件系统操作的统一接口,屏蔽不同文件系统的差异和操作细节。借助VFS可以直接使用open()、read()、write()这样的系统调用操作文件,而无须考虑具体的文件系统和实际的存储介质。
"一切皆文件"是Linux的基本哲学之一,不仅是普通的文件,包括目录、字符设备、块设备、套接字等,都可以以文件的方式被对待。实现这一行为的基础,正是Linux的虚拟文件系统VFS机制。
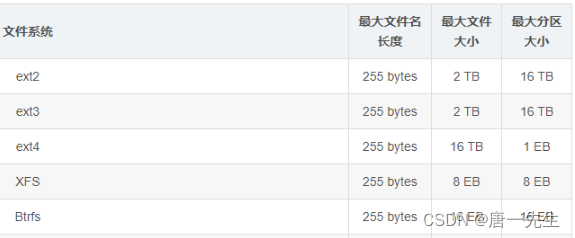
ext,专门为Linux设计的第一代文件系统,后面升级ext2,ext3(增加了文件系统日志记录功能,称为日志式文件系统),ext4(在Ext3中加入了新的高级功能)。
swap,用于Linux的交换分区的文件系统。在Linux中,使用整个交换分区来提供虚拟内存,其分区大小一般应是系统物理内存的2倍,在安装Linux操作系统时,就应创建交换分区,它是Linux正常运行所必需的,其类型必须是swap,交换分区由操作系统自行管理。
vfat,Linux对DOS,Windows系统下的FAT(包括fat16和Fat32)文件系统的一个统称,具有和Windows系列文件系统和Linux文件系统兼容的特性。因此VFAT可以作为Windows和Linux交换文件的分区。
reiserFS,Linux环境下最稳定的日志文件系统之一,使用快速的平衡二叉树(binary tree)算法来查找磁盘上的自由空间和已有的文件。有先进的日志(Journaling/logging)功能机制,保证了在每个实际数据修改之前,相应的日志已经写入硬盘。
XFS,是一个全64-bit的文件系统,它可以支持上百万T字节的存储空间。对特大文件及小尺寸文件的支持都表现出众,支持特大数量的目录。
NFS,网络磁盘文件系统。
anon_inodefs :匿名文件系统,整个文件系统只有一个 inode ,这个 inode 是文件系统初始化的时候创建好的。之后,所有需要一个匿名 inode 的句柄都直接跟这个 inode 关联即可。
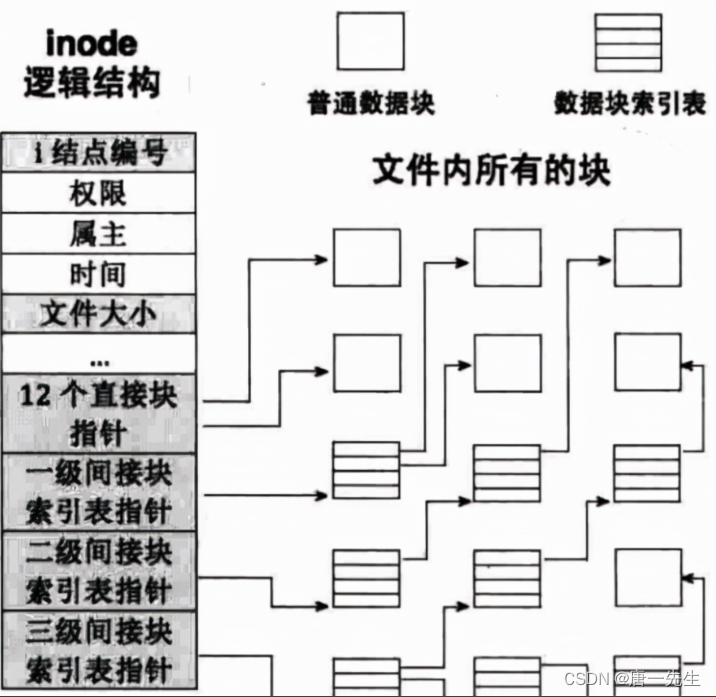
eventpollfs
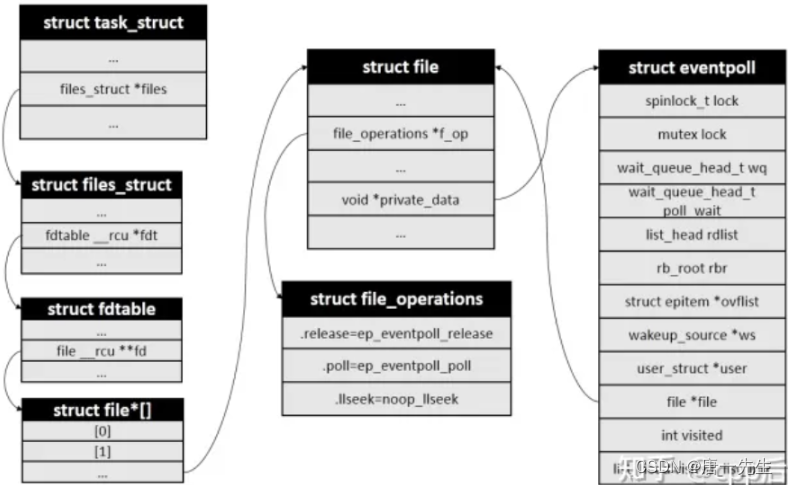
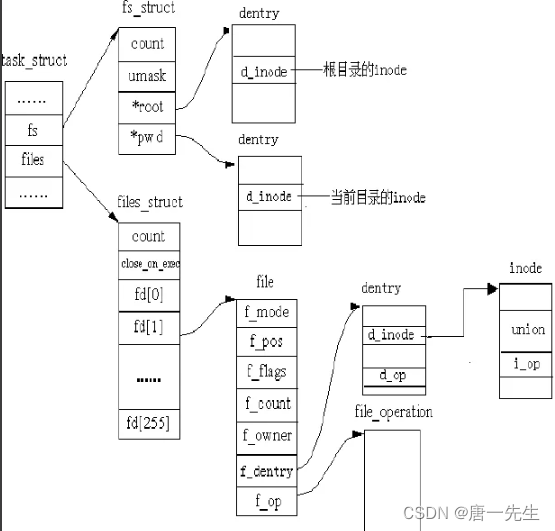
打开文件表
进程描述符 task_struct中包含着该进程的打开文件表。
struct files_struct {
// 读相关字段
atomic_t count;
bool resize_in_progress;
wait_queue_head_t resize_wait;
// 打开的文件管理结构
struct fdtable __rcu *fdt;
struct fdtable fdtab; //动态数组,数组边界是用字段描述的。
// 写相关字段
unsigned int next_fd;
unsigned long close_on_exec_init[1];
unsigned long open_fds_init[1];
unsigned long full_fds_bits_init[1];
struct file * fd_array[NR_OPEN_DEFAULT]; //静态数组,随着 files_struct 结构体分配出来的,在 64 位系统上,静态数组大小为 64,在文件打开不多的情况下使用。fd 就是 这个指针数组的索引,通过 fd 能够找到对应文件的 struct file 结构体。
};
j于性能和资源的权衡 ,大部分进程只会打开少量的文件,所以静态数组就够了,这样就不用另外分配内存。如果超过了静态数组的阈值,那么就动态扩展。同 inode 的直接索引,一级索引的优化思路类似。
struct fdtable {
unsigned int max_fds; //指明数组边界
struct file __rcu **fd; /* current fd array */ 打开文件返回的fd 就是 这个指针数组的索引,通过 fd 能够找到对应文件的 struct file 结构体。
};
struct file* fd_array 和 struct file**fd,二级指针,就是一个一级指针数组,即一个数组中保存着这个进程打开的每一个文件指针,通过每一个文件的索引fd找到这个文件指针就能找到这个文件的相关信息。fd索引值是进程内的,每个进程自己分配自己的文件表对应有自己的fd值,但指向的struct file属于系统级的,多个不同的进程可以共享访问。
文件描述符fd (File descriptor 的缩写)
Linux中一个进程启动时,都会打开3个文件:标准输入、标准输出和标准出错处理。这三个文件分别对应文件描述符0、1、2。
fd是以进程为单位的,每个进程有一个最大的fd数目,可以使用ulimit设置。
fd的系统最大值在/proc/sys/fs/file-max中。
打开文件时系统检查所有进程的fd总数,进程检查进程自己的fd总数。
0,1,2 这三个 fd 值已经被赋予特殊含义,分别是标准输入( STDIN_FILENO ),标准输出( STDOUT_FILENO ),标准错误( STDERR_FILENO )。
struct file {...
struct path f_path; // 标识文件名
struct inode *f_inode; // 非常重要的一个字段,inode 这个是 vfs 的 inode 类型,是基于具体文件系统之上的抽象封装。为什么会有这一层封装呢?其实很容里理解,就是解耦。如果让 struct file 直接和 struct ext4_inode 这样的文件系统对接,那么会导致 struct file 的处理逻辑非常复杂,因为每对接一个具体的文件系统,就要考虑一种实现。所以操作系统必须把底下文件系统屏蔽掉,对外提供统一的 inode 概念,对下定义好接口进行回调注册。这样让 inode 的概念得以统一,Unix 一切皆文件的基础就来源于此。
const struct file_operations *f_op; // 这个字段非常重要,偏移,对,就是当前文件偏移。f_pos 在 open 的时候会设置成默认值,seek 的时候可以更改,从而影响到 write/read 的位置
...
}
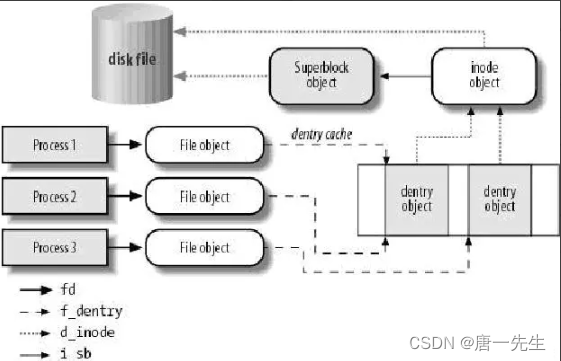
多个进程可使用一个 struct file
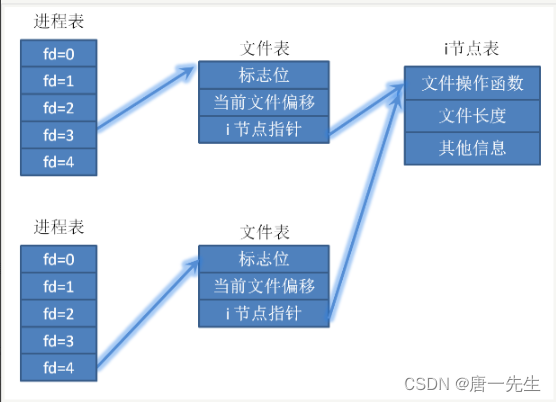
1. 子进程。fork()时继承的父进程的fd,实质是重新复制了一份struct file,所以文件指针偏移量都是保持着父进程原来的值。
2. dup和dup2复制fd。实质是用一个新的fd指向原有的struct file*,同时给原有的struct file*引用计数加1。
从姿势上来讲,用户 open 文件得到一个非负数句柄 fd,之后针对该文件的 IO 操作都是基于这个 fd ;
文件描述符 fd 本质上来讲就是数组索引,fd 等于 5 ,那对应数组的第 5 个元素而已,该数组是进程打开的所有文件的数组,数组元素类型为 struct file;
结构体 task_struct 对应一个抽象的进程,files_struct 是这个进程管理该进程打开的文件数组管理器。fd 则对应了这个数组的编号,每一个打开的文件用 file 结构体表示,内含当前偏移等信息;
file 结构体可以为进程间共享,属于系统级资源,同一个文件可能对应多个 file 结构体,file 内部有个 inode 指针,指向文件系统的 inode;
inode 是文件系统级别的概念,只由文件系统管理维护,不因进程改变( file 是进程出发创建的,进程 open 同一个文件会导致多个 file ,指向同一个 inode )
inode
一个文件对应一个inode,存储文件类型,权限,文件大小,创建、修改、访问时间。
struct inode {
umode_t i_mode; // 文件相关的基本信息(权限,模式,uid,gid等)
unsigned short i_opflags;
kuid_t i_uid;
kgid_t i_gid;
unsigned int i_flags;
const struct inode_operations *i_op; // 回调函数
struct super_block *i_sb;
struct address_space *i_mapping;
loff_t i_size; // 文件大小,atime,ctime,mtime等
struct timespec64 i_atime;
struct timespec64 i_mtime;
struct timespec64 i_ctime;
const struct file_operations *i_fop; // 回调函数
struct address_space i_data;
void *i_private; /* fs or device private pointer 指向后端具体文件系统的特殊数据*/
};inode 是vfs的文件地址(相当于基类),具体的文件系统(子类)扩展 inode, 然后通过地址偏移强转来实现相互转换。
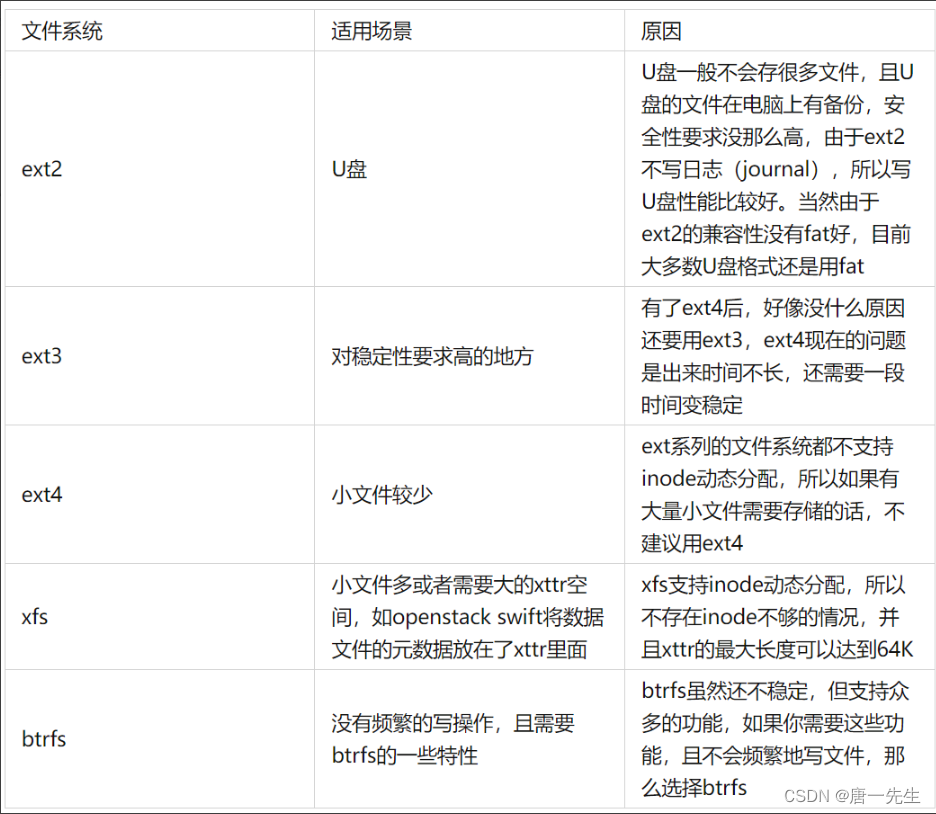
索引表的索引结构称为inode,是"index node"的简称,用来索引,跟踪一个文件的所有块。inode是文件索引结构组织形式的具体体现,一个文件就必须对应一个inode。
inode表(inode Table)由一个块组中的所有inode组成。一个文件除了数据需要存储之外,一些描述信息也需要存储,如文件类型,权限,文件大小,创建、修改、访问时间等,这些信息存在inode中而不是数据块中。
inode表占多少个块在格式化时就要写入块组描述符中。 在Ext2/Ext3文件系统中,每个文件在磁盘上的位置都由文件系统block group中的一个Inode指针进行索引,Inode将会把具体的位置指向一些真正记录文件数据的block块,需要注意的是这些block可能和Inode同属于一个block group也可能分属于不同的block group。我们把文件系统上这些真实记录文件数据的block称为Data blocks
文件操作
一般C库函数写文件时是全缓冲,而显示器是行缓冲。
printf fprintf 是库函数, 是对系统调用的“封装”,在系统调用的“上层”,有缓存。
write() 是系统函数,没有缓冲区,fwrite()是C标准库函数有缓冲区。
int dup2(int oldfd,int newfd);// dup2函数复制描述符表表项oldfd到描述符表表项newfd,覆盖描述符表表项newfd以前的内容,若newfd已经打开,dup2会在复制oldfd之前关闭newfd。
文件存储
磁盘空间划分元数据区和数据区,元数据去主要存贮文件的一些属性,比如说大小,块信息,这些信息被存贮在inode当中,而数据以datablock 为存贮单元,主要是存放了文件的数据。
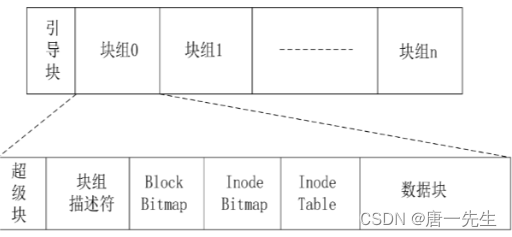
因为磁盘上的数据要和内存交互,而内存通常是以4KB为单位的,所以从逻辑上,把磁盘按照4KB,称为一个块 block,将若干个块儿组成一个块组group。
存储结构
顺序文件结构、链式文件系统,类似于vector和list的存储方式。
索引式文件系统,这是顺序文件结构和链式文件系统的折中。索引表是顺序的,方便随机访问,数据块是链表的,方便分散存储。
组
块的管理节点,相当于块之上更大的索引结构,描述整个分区的文件系统信息,如inode/block的大小、总量、使用量、剩余量,以及文件系统的格式与相关信息。超级块在每个块组的开头都有一份拷贝(第一个块组必须有,后面的块组可以没有)。
Block Group:ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成。
超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。
GDT(Group Descriptor Table):块组描述符,描述块组属性信息。
块位图(Block Bitmap):Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用。
inode位图(inode Bitmap):每个bit表示一个inode是否空闲可用,记录block group中Inode区域的使用情况,Ext文件系统中一个block group中可以有16384个Inode,代表着这个Ext文件系统中一个block group最多可以描述16384个文件。
节点表(inode Table): 存放文件属性 如 文件大小,所有者,最近修改时间等。
数据区(Data blocks):存放文件数据。
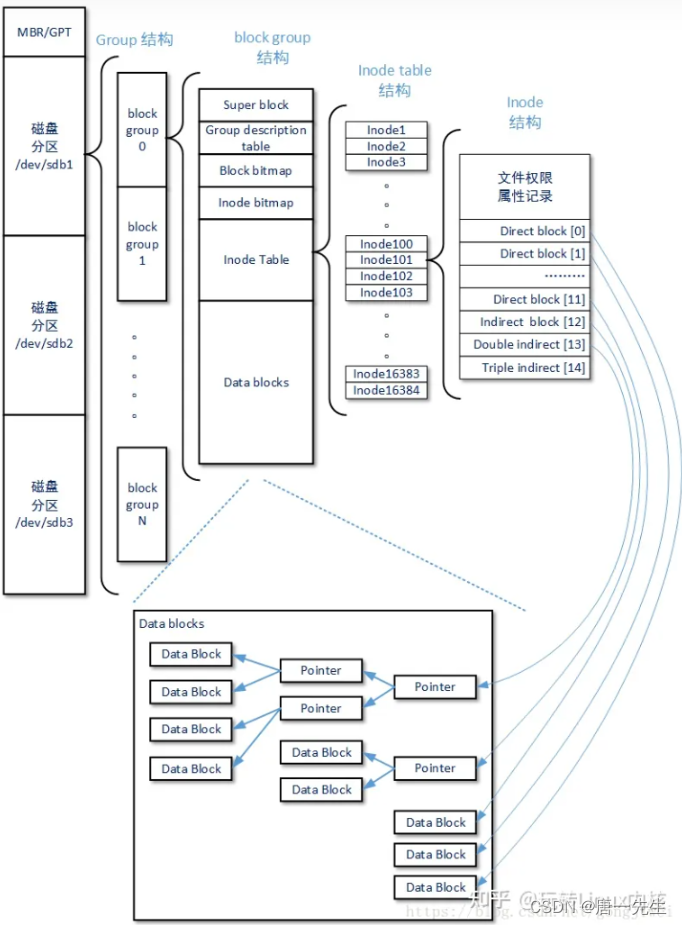
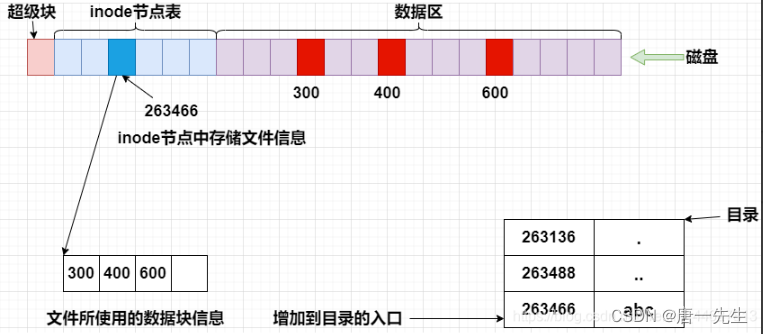
1、存储文件:内核先找到一个空闲的inode节点(这里是263466)。内核记录文件信息。
2、存储数据:该文件需要存储到三个磁盘块,内核找到三个空闲块:300、400、600。将内核缓存区的数据依次复制到磁盘块。
3、记录分配情况:文件内容按顺序300,500,800存放。内核在inode上的磁盘分布区记录了上述块列表。
4、添加文件名到目录:新的文件名abc。linux如何在当前的目录中记录这个文件?内核将入口(263466,abc)添加到目录文件。文件名和inode之间的对应关系将文件名和文件的内容及属性连接起来。
机器启动加载
主引导区 MBR(Master Boot Recorder),MBR 在一块硬盘的第 0 轨上,这也是计算机启动之后要去使用硬盘时必须读取的第一个区域。记录了硬盘里所有分区的信息即磁盘分区表,以及启动时可以写入引导程序的位置。
三个部分组成(512个字节):
引导程序占用其中的前446字节(偏移0~1BDH)
随后的64字节(偏移1BEH~1FDH)为DPT(Disk Partition Table,硬盘分区表)
最后的两个字节“55 AA”(偏移1FEH~1FFH)是结束标志。
机器启动,指向ROM(read-only memory)芯片程序BIOS(Basic Input/Output System),BIOS 程序启动,硬件自检。
硬件自检完成后,BIOS按照"启动顺序",把控制权转交给排在第一位的储存设备(BIOS需要有一个外部储存设备的排序,排在前面的设备就是优先转交控制权的设备。这种排序叫做"启动顺序”(Boot Sequence),Windows上需要U盘启动的需要把U盘放在第1个)。
计算机读取该设备的第一个扇区,也就是读取最前面的512个字节。如果这512个字节的最后两个字节是0x55和0xAA,表明这是MBR(告诉计算机到硬盘的哪一个位置去找操作系统),可以用于启动;如果不是,表明设备不能用于启动,控制权于是被转交给"启动顺序"中的下一个设备。
读取"主引导记录"前面446字节的机器码找到操作系统所在的硬盘位置,运行事先安装的"启动管理器"(Linux环境中,目前最流行的启动管理器是Grub),由用户选择启动哪一个操作系统。
载入操作系统的内核到内存。 以Linux系统为例,先载入/boot目录下面的kernel ,运行第一个程序 /sbin/init 产生init进程(第一个进程,pid=1,其他进程都是它的后代),init线程加载系统的各个模块。
C语言的多态
基类定义统一的数据结构和操作函数;
基类持有void*指针作为访问子类资源的统一入口,每个子类自己定义自己的结构,创建实例,赋值给基类的void*private_data,如epoll 定义struct eventpoll子类,socket定义struct socket 子类,。。。;
子类持有基类指针,通过基类指针调用基类函数;
子类初始化时把操作函数通过基类指针访问塞给基类函数指针;
对外统一通过基类接口访问;