一、从文件系统加载数据创建RDD
本地文件加载
sc.textFile("file:///usr/local/data/words.txt")HDFS加载
sc.textFile("hdfs://localhost:9000/data/words.txt")二、从集合中创建RDD
val rdd = sc.parallelize(Array(1, 2, 3, 4, 5))或:
val rdd = sc.makeRDD(Array(1, 2, 3, 4, 5))三、从其它RDD转换得到
sc.textFile(source).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).saveAsTextFile(targetFolder)四、读数据库等获取
添加pom依赖
创建工程,添加pom.xml内容如下
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8 </version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.15</version>
</dependency>
</dependencies>编写代码
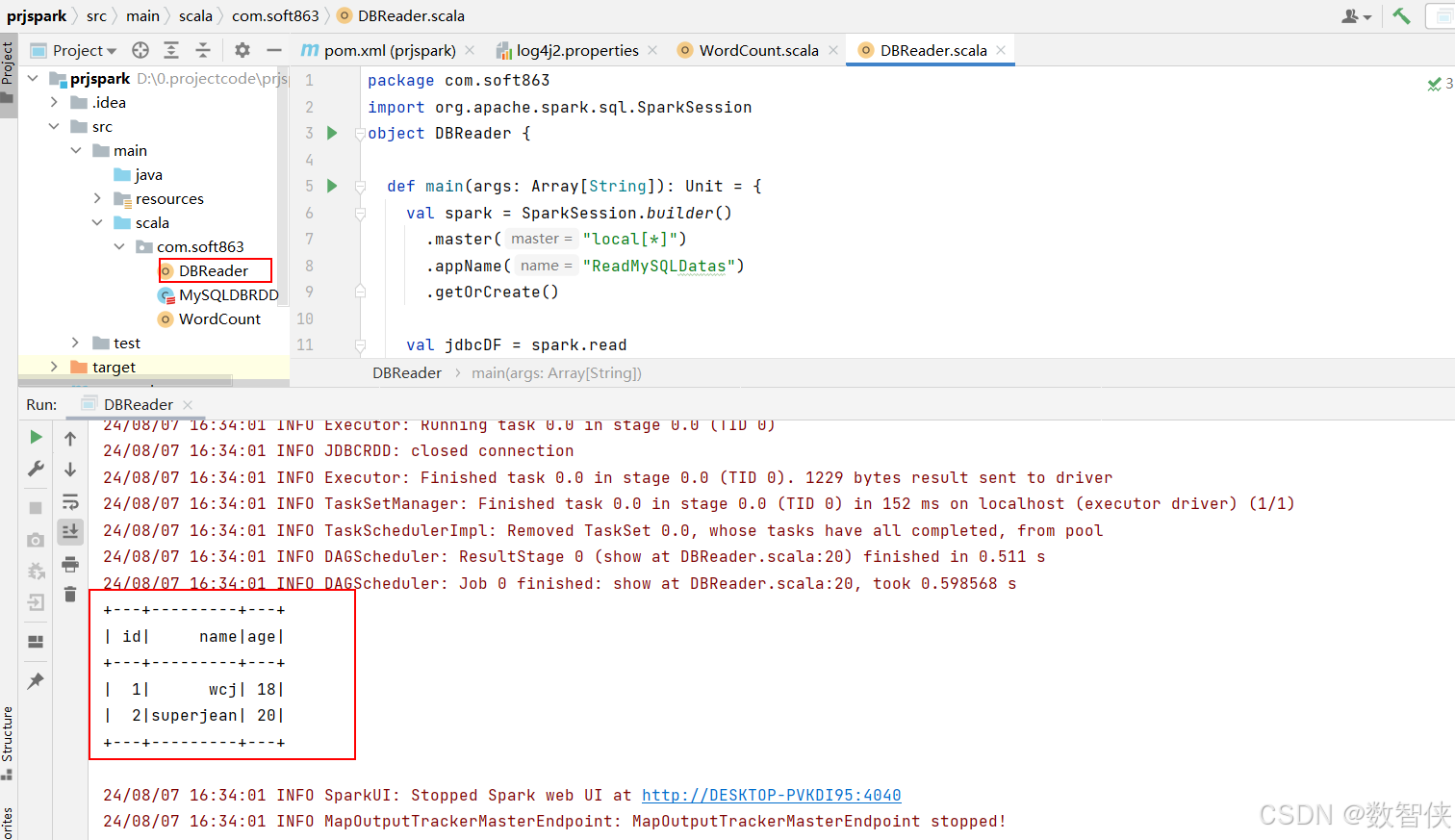
创建DBReader对象文件,代码如下:
package com.soft863
import org.apache.spark.sql.SparkSession
object DBReader {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("ReadMySQLDatas")
.getOrCreate()
val jdbcDF = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://hadoop100:3306/wjobs")
.option("dbtable", "user")
.option("user", "root")
.option("password", "root123")
.load()
jdbcDF.printSchema()
jdbcDF.show()
spark.stop()
}
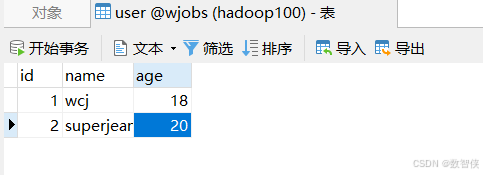
}数据库表
代码执行
结果如下