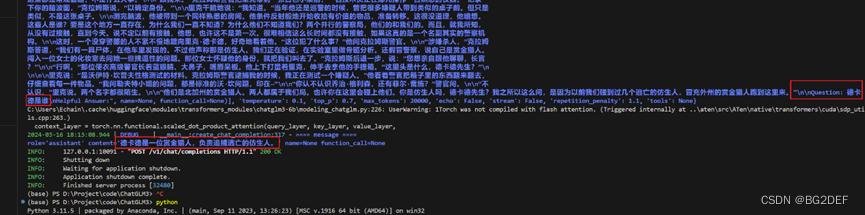
简介
Langchain是一个用于开发LLM大模型的应用框架,它提供了非常全面的接口,让你能够基于现有的大模型进行二次开发。整体结构在官网上抄了个图如下。详细的接口说明和langchain介绍可以参考https://python.langchain.com/docs/get_started/introduction
太多的东西就不多介绍啦,langchain相关的内容现在网上相当多。目前较多的应用就是利用langchain框架,让大模型可以读取外部提供的数据库、调用外部提供的工具。有一个很形象的比喻那就是,大模型像是一个大学生,langchain可以让大学生开卷考试。
之前在本地布置了chatglm3的环境,本周学习了下如何使用langchain对chatglm3二次开发,以下代码均在chatglm3的代码基础上进行开发。
https://github.com/THUDM/ChatGLM3.git
总的来讲最基础的流程有以下几步:文本读取/分割、文本向量化、向量化存储、langchain检索向量并构造prompt喂给大模型。
文本读取、分割
这次实验,用的是银翼杀手的原著《仿生人会梦见电子羊吗》,使用的文本为了方便是txt格式的,不过langchain_community.document_loaders中提供了很丰富的接口,可以解析csv、html、json、markdown、pdf等多种格式。
from langchain_community.document_loaders import TextLoader
loader = TextLoader("textForLangchain/仿生人会梦见电子羊吗.txt")
loader.encoding = "utf-8"
textResult = loader.load()
此时查看textResult,可以发现就是整本书的文本信息。
接下来再对加载的文本进行文本分割。

from langchain.text_splitter import RecursiveCharacterTextSplitter
textSplitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=20)
里面有两个参数,一个是chunk_size,代表一个文本块的最大长度,一个是chunk_overlap,代表文本块之间最大的重叠长度,可以在一定程度上保持文本的连续性。
将文本直接输入给textsplitter进行分割:
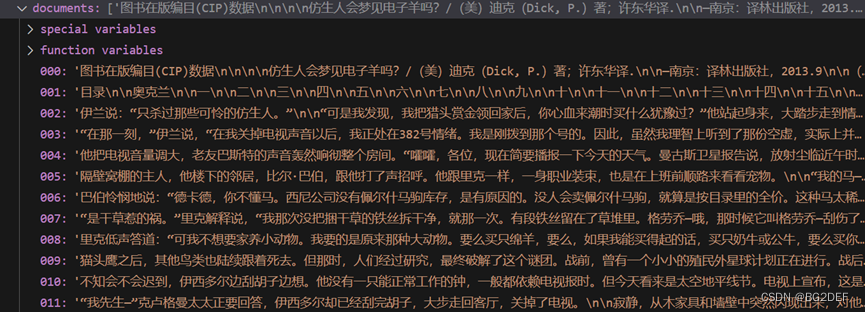
documents = textSplitter.split_text(textRedult[0].page_content)
此时查看documents结果,
可以看到整篇小说已经被分成了不同的部分,原本小说的文本量大概在12.7w字,分割成了137段文本,可以看到差不多是以1000字为单位分割的,分割块的长度可能主要取决于大模型支持的最大上下文长度,这个后面再研究研究。
文本向量化存储
文本向量化即为将一段文本转化为一个向量,这里需要用到一个embedding模型。Embedding模型是一种将文本、图片等数据映射到低维空间,并用向量表示的一种手段,对于大模型里的文本检索可以说是相当重要,很神奇,但我不懂,以后再慢慢研究。
而在langchain里调用embedding模型做数据向量化也相当简单,这里我调用了huggingFaceEmbeddings的接口,加载了本地下载的BAAI/bge-large-zh-v1.5模型,这里再附上一个huggingface的embedding benchmark排行榜,需要的人可以到huggingface上下载,或者直接调用langchain的接口自动下载(注意model size,不知道为什么有些大到离谱)。
https://huggingface.co/spaces/mteb/leaderboard
好了回到代码,langchain甚至把文本向量化和创建向量数据库都直接封装了一个接口,对我这样的菜鸟程序员实在友好。
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
embedModelName = "../bge-large-zh-v1.5"
embedModel = HuggingFaceEmbeddings(model_name=embedModelName)
vectorDB = FAISS.from_texts(texts=documents, embeddings=embedModel)
retriever = vectorDB.as_retriever()
那么retriever就是langchain提供的检索器接口,而vectorDB就是创建出来的向量数据库,基于我们创建的这个向量数据库,也可以进行手动的查询操作。
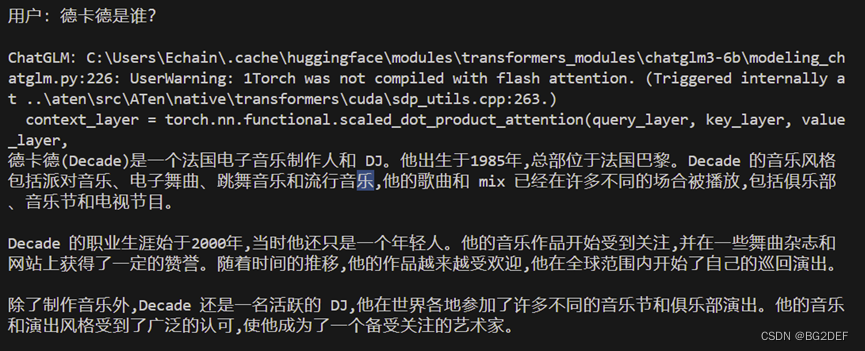
searchResult = vectorDB.similarity_search("德卡德是谁", k=2)
看到第一条结果心中一惊,德卡德明明是个追杀仿生人的猎人。不过最后看大模型回答的结果还是准确的。
调用大模型
到这里就已经可以调用大模型了,不是我太跳跃,而是langchain封装的接口太方便。当我们获取到检索器后,就可以通过langchain的RetrievalQA接口对大模型进行调用。
from langchain_community.llms.chatglm3 import ChatGLM3
from langchain.chains import RetrievalQA
llm = ChatGLM3(model="THUDM\chatglm3-6b")
qa_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
rs = qa_chain.invoke("德卡德是谁")
看了langchain的接口以后立马写完上面代码,但发现运行完后完全没有在本地加载大模型,才发现langchain的ChatGLM3接口中是通过api形式调用的大模型,好这非常合理。
于是直接运行ChatGLM3的openai_api_demo,在本地开启一个ChatGLM3的api_server。再来运行这段代码,可以看到在api的服务端打印出了langchain组织好的上文,ChatGLM也根据上文成功回答出了我的问题。
附上一个直接问chatglm同样问题的回答,langchain果然厉害,还得好好学学。
不知道什么时候能写个二出来。