以太坊作为一个去中心化的系统,其底层个体相互间的通信显然非常重要,所有数据的同步,各个个体状态的更新,都依赖于整个网络中每个个体相互间的通信机制。以太坊的网络通信基于peer-to-peer(p2p)通信协议,又根据自身传输数据类型(区块,交易,哈希值等),网络节点业务相关性等需求,在各方面做了特别设计。
由于以太坊中p2p通信相关代码量较大,打算分为上下两篇文章来加以详解:上篇主要介绍管理p2p通信的核心类ProtocolManager内部主要流程,以及通信相关协议族的设计;下篇主要介绍ProtocolManager的两个成员Fetcher和Downloader,这里是上篇。
1. 一般意义上的p2p网络
在开始介绍以太坊的p2p通信机制之前,不妨先来看看一般意义上的p2p网络通信的一些特征,以下部分内容摘自peer-to-peer_wiki
peer-to-peer(p2p)首先是一种网络拓扑类型,与之对比最显著的就是client/server(C/S)架构。从TCP/IP协议族分层的角度来说,p2p网络中实际的数据交换,依然是网络层用IP协议,传输层用TCP协议;而p2p协议--如果可称之为协议的话,应算作应用层再往上,类似于逻辑拓扑层,毕竟著名的应用层协议之一FTP,就属于非常典型的一种C/S架构类型。
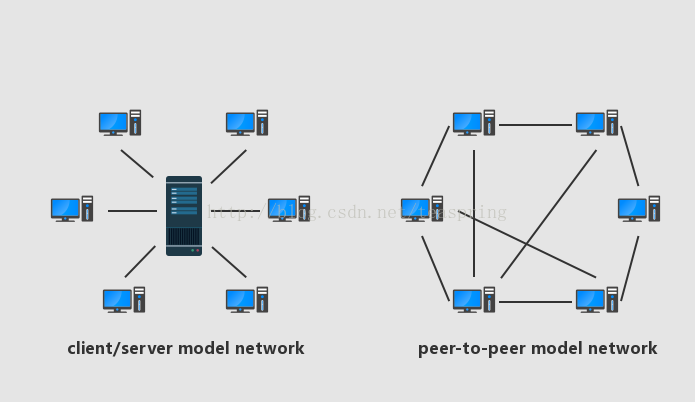
上图是C/S架构和p2p架构的一个简单示意图,原图来自wiki。左图中C/S架构被描绘成星型拓扑,这当然仅仅是特例,大家可能在工作中遇到各种各样拓扑形状的C/S架构,而其核心特征是不变的:C/S 网络中的个体地位和功能是不平等的,client个体主要消耗资源,发起请求,server个体主要提供资源并处理请求,这使得C/S架构天然是中心化的。
相比之下,p2p架构中最重要的特点在于:其网络中的个体在地位和功能上是平等的,虽然每个个体可能处理不同的请求,实际提供的资源在具体量化后可能有差异,但它们都能同时既消耗资源又提供资源。如果把整个所处网络中的资源--此处的资源包括但不限于运算能力、存储空间、网络带宽等,视为一个总量,那么p2p网络中的资源分布,是分散于各个个体中的(也许不一定均匀分布)。所以,p2p网络架构天然是去中心化的、分布式的。
注意上图右侧p2p网络中,并非每个个体与网络中其他同类均有通信。这其实也是p2p网络的一个很重要的特点:一个个体只需要与相邻的一部分同类有通信即可,每个个体可与多少相邻个体、哪些个体有通信,是可以加以设计的,
无结构化的和有结构化的p2p网络
根据p2p网络中节点相互之间如何联系,可以将p2p网络简单区分为无结构化的(unstructured),和结构化的(structured)两大类。
无结构化的
这种p2p网络即最普通的,不对结构作特别设计的实现方案。优点是结构简单易于组建,网络局部区域内个体可任意分布,反正此时网络结构对此也没有限制;特别是在应对大量新个体加入网络和旧个体离开网络(“churn”)时它的表现非常稳定。缺点在于在该网络中查找数据的效率太低,因为没有预知信息,所以往往需要将查询请求发遍整个网络(至少大多数个体),这会占用很大一部分网络资源,并大大拖慢网络中其他业务运行。
结构化的
这种p2p网络中的个体分布经过精心设计,主要目的是为了提高查询数据的效率,降低查询数据带来的资源消耗。提高查询效率的基本手段是对数据建立索引,结构化p2p网络最普遍的实现方案中使用了分布式哈希表(Distributed Hash Table,DHT),它会对每项数据(value)分配一个key以组成(key,value)键值对,同时网络中每个个体的分布--这里的分布主要指相互通信关系-根据key键进行关联和扩展。这样,当要查找某项数据时,只要跟据其key键就能不断的缩小查找区域,大大减少资源消耗。
尽管如此,这样的p2p网络缺点也很明显:由于每个个体需要存有数量不少的相邻个体列表,