DepthAnything(1): 先跑一跑Depth Anything_depth anything离线怎么跑-CSDN博客
目录
1. 写在前面
DepthAnything是一种能在任何情况下处理任何图像的简单却又强大的深度估计模型。
2. 安装推理组件
针对有GPU加持的场景,以NVIDIA显卡为例,首先需要安装GPU驱动。
然后再安装CUDA、cuDNN和ONNX Runtime,一般情况下,在有显卡的系统中,我们选择GPU版本。
进入如下链接,可以查看CUDA、cuDNN、ONNX Runtime库的版本对应关系。
如下所示,ONNX Runtime与CUDA、cuDNN的版本需要匹配,否则可能出现我发调用GPU进行推理。
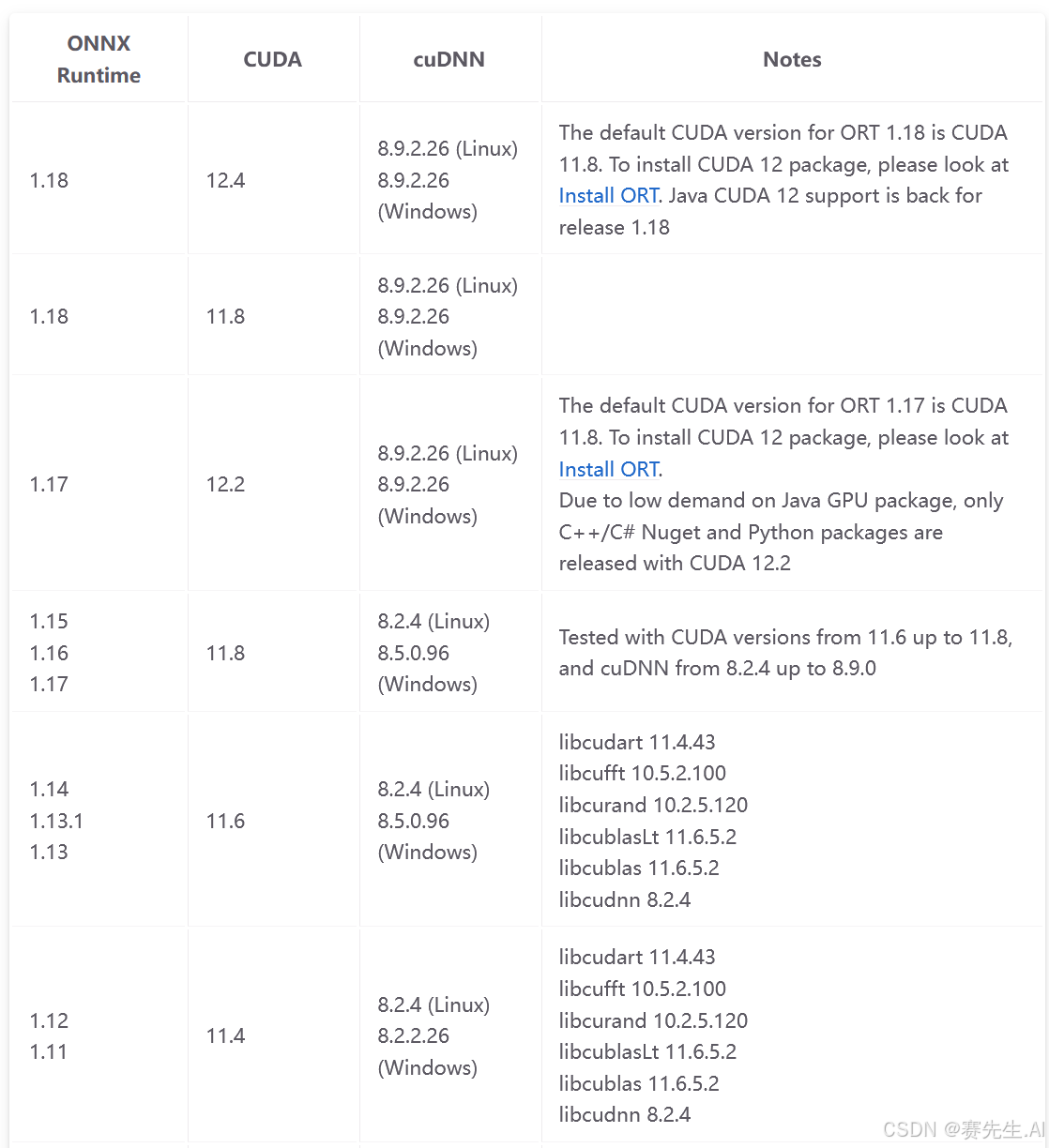
针对没有GPU的场景,我们使用CPU进行推理。可直接下载相应平台的onnx-runtime库。
3. 生成ONNX
使用DepthAnything训练工程下的export_onnx.py文件导出ONNX模型。
注意,导出的时候,需要注意分辨率,DepthAnything到处分辨率必须是14的整数倍。
另外,如果导出分辨率过小,可能会导致识别的深度图失效,因此一般建议导出时,分辨率选择518*518。
导出onnx模型参考代码如下。
import argparse
import torch
from onnx import load_model, save_model
from onnxruntime.tools.symbolic_shape_infer import SymbolicShapeInference
from depth_anything.dpt import DPT_DINOv2
def parse_args() -> argparse.Namespace:
parser = argparse.ArgumentParser()
parser.add_argument(
"--model",
type=str,
choices=["s", "b", "l"],
required=True,
help="Model size variant. Available options: 's', 'b', 'l'.",
)
parser.add_argument(
"--output",
type=str,
default=None,
required=False,
help="Path to save the ONNX model.",
)
return parser.parse_args()
def export_onnx(model: str, input: str, output: str = None):
# Handle args
if output is None:
output = f"weights/depth_anything_vit{model}14_ori.onnx"
# Device for tracing (use whichever has enough free memory)
device = torch.device("cpu")
# Sample image for tracing (dimensions don't matter)
image = torch.rand(1, 3, 518, 518).to(device) # [SAI-KEY] 必须是14的倍数
# Load model params
if model == "s":
depth_anything = DPT_DINOv2(
encoder="vits", features=64, out_channels=[48, 96, 192, 384]
)
elif model == "b":
depth_anything = DPT_DINOv2(
encoder="vitb", features=128, out_channels=[96, 192, 384, 768]
)
else: # model == "l"
depth_anything = DPT_DINOv2(
encoder="vitl", features=256, out_channels=[256, 512, 1024, 1024]
)
weights = torch.load(input)
depth_anything.to(device).load_state_dict(weights)
depth_anything.eval()
torch.onnx.export(
depth_anything,
image,
output,
input_names=["image"], # 列表,如果有多个输入,应按照顺序,依次
output_names=["depth"],
opset_version=12,
)
save_model(
SymbolicShapeInference.infer_shapes(load_model(output), auto_merge=True),
output,
)
if __name__ == "__main__":
export_onnx("l", "/2T/001_AI/8001_DepthAnything/003_Models/checkpoints/depth_anything_vitl14.pth", "/2T/001_AI/8001_DepthAnything/003_Models/checkpoints/depth_anything_vitl14.onnx")4. 准备ONNXRuntime库
登录链接https://github.com/microsoft/onnxruntime/releases下载相应的ONNX Runtime推理库。如下所示,可选择linux、windows、osx系统下的库,以及选择x86或aarch64架构的库。需要说明的是,aarch64目前仅支持CPU版本。
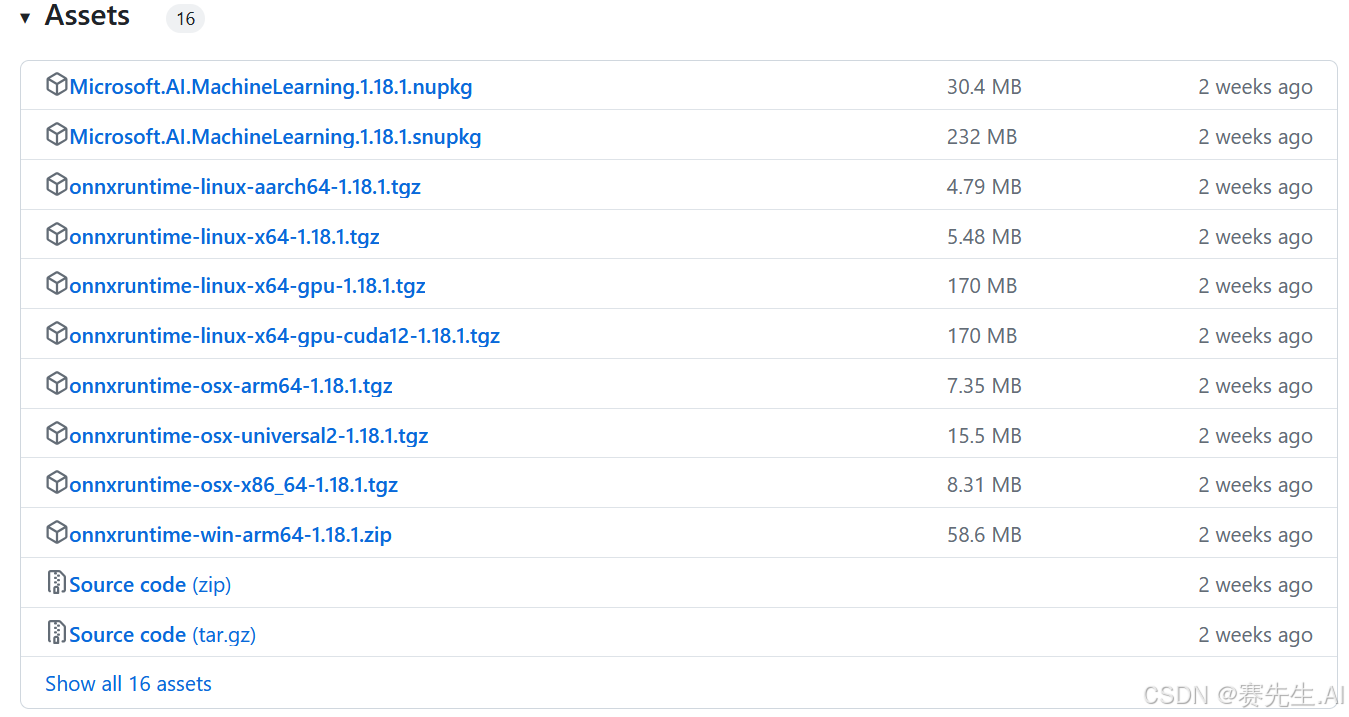
不同系统的库,引入方式也不同。
例如,下载onnxruntime-linux-aarch64-1.18.1.tgz库,解压后可以将其中lib文件夹下的libonnxruntime.so和libonnxruntime.so.1.18.1复制到/usr/lib路径下。
include头文件可移动可不移动,也可重命名后,加入到工程中。如果需要添加到工程中,需要注意Makefile中的包含项。
如果是下载的windows平台的库,一般是include文件和dll链接库,按照不同IDE的引入方式来就可以。
5. API介绍
本小节简单介绍几个API,具体使用可以参照后续小节的例程加以探索和理解。
(1)Ort::Env(ORT_LOGGING_LEVEL_WARNING, "depthAnything_mono");
ORT_LOGGING_LEVEL_VERBOSE:最详细的日志信息,包括所有信息。
ORT_LOGGING_LEVEL_INFO:一般的信息,例如模型加载和推理进度。
ORT_LOGGING_LEVEL_WARNING:警告级别的日志,例如潜在的问题或性能下降,仅输出警告日志。
ORT_LOGGING_LEVEL_ERROR:错误级别的日志,例如无法恢复的错误。
ORT_LOGGING_LEVEL_FATAL:致命错误,通常是程序无法继续执行的错误。
(2)OrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 0); ///< 相当于指定执行后端,如果不指定,则默认使用CPU
参数1:
参数2:设备号
(3)GetInputCount()和GetOutputCount()
获得输入和输出的数量。
(4)GetInputTypeInfo(i)
获取第i个输入的信息。
(5)GetShape()
获取输入或输出的shape信息。
6. 例程
以下例程以DepthAnything利用ONNXRuntime与OpenCV实现对一张图片的深度估计、并将结果存储到本地。
#include <assert.h>
#include <vector>
#include <ctime>
#include <iostream>
#include <chrono>
#include <onnxruntime_cxx_api.h>
#include <opencv2/core.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/videoio.hpp>
using namespace cv;
using namespace std;
int input_width = 518;
int input_height = 518;
class DepthAnything
{
public:
DepthAnything(std::string onnx_model_path);
std::vector<float> predict(std::vector<float>& input_data, int batch_size = 1, int index = 0);
cv::Mat predict(cv::Mat& input_tensor, int batch_size = 1, int index = 0);
private:
Ort::Env env;
Ort::Session session;
Ort::AllocatorWithDefaultOptions allocator;
std::vector<const char*>input_node_names = {"image"}; ///< 生成onnx时的输入节点名
std::vector<const char*>output_node_names = {"depth"}; ///< 生成onnx时的输出节点名
std::vector<int64_t> input_node_dims;
std::vector<int64_t> output_node_dims;
};
DepthAnything::DepthAnything(std::string onnx_model_path) :session(nullptr), env(nullptr)
{
/** 初始化ORT环境. */
this->env = Ort::Env(ORT_LOGGING_LEVEL_WARNING, "DepthAnything_ORT");
/** 初始化ORT会话选项. */
Ort::SessionOptions session_options;
// session_options.SetInterOpNumThreads(1);
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_BASIC); ///< ORT_ENABLE_ALL
/** 初始化ORT会话. */
this->session = Ort::Session(env, onnx_model_path.data(), session_options);
/** 输入输出节点数量. */
size_t num_input_nodes = session.GetInputCount();
size_t num_output_nodes = session.GetOutputCount();
for (int i = 0; i < num_input_nodes; i++){
Ort::TypeInfo type_info = session.GetInputTypeInfo(i);
auto tensor_info = type_info.GetTensorTypeAndShapeInfo();
ONNXTensorElementDataType type = tensor_info.GetElementType();
this->input_node_dims = tensor_info.GetShape();
for(int i=0; i<this->input_node_dims.size(); i++){
printf("shape[%d]: %d\n", i, this->input_node_dims[i]);
}
}
for (int i = 0; i < num_output_nodes; i++){
Ort::TypeInfo type_info = session.GetOutputTypeInfo(i);
auto tensor_info = type_info.GetTensorTypeAndShapeInfo();
ONNXTensorElementDataType type = tensor_info.GetElementType();
this->output_node_dims = tensor_info.GetShape();
}
}
std::vector<float> DepthAnything::predict(std::vector<float>& input_tensor_values, int batch_size, int index)
{
this->input_node_dims[0] = batch_size;
this->output_node_dims[0] = batch_size;
float* floatarr = nullptr;
std::vector<const char*>output_node_names;
if (index != -1){
output_node_names = { this->output_node_names[index] };
}else{
output_node_names = this->output_node_names;
}
this->input_node_dims[0] = batch_size;
auto input_tensor_size = input_tensor_values.size();
/** 创建Tensor对象. */
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault); ///< 创建CPU内存信息
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(memory_info, input_tensor_values.data(), input_tensor_size, input_node_dims.data(), 4); ///< 创建输入张量
/** 执行推理. */
auto output_tensors = session.Run(Ort::RunOptions{ nullptr }, input_node_names.data(), &input_tensor, 1, output_node_names.data(), 1);
assert(output_tensors.size() == 1 && output_tensors.front().IsTensor());
floatarr = output_tensors[0].GetTensorMutableData<float>(); ///< 获取输出张量
int64_t output_tensor_size = 1;
for (auto& it : this->output_node_dims){
output_tensor_size *= it;
}
std::vector<float>results(output_tensor_size);
for (unsigned i = 0; i < output_tensor_size; i++){
results[i] = floatarr[i];
}
return results;
}
cv::Mat DepthAnything::predict(cv::Mat& input_tensor, int batch_size, int index)
{
int input_tensor_size = input_tensor.cols * input_tensor.rows * 3;
std::size_t counter = 0;
std::vector<float>input_data(input_tensor_size);
std::vector<float>output_data;
/** 转换RGB Planar, 归一化. */
for (unsigned k = 0; k < 3; k++){
for (unsigned i = 0; i < input_tensor.rows; i++){
for (unsigned j = 0; j < input_tensor.cols; j++){
input_data[counter++] = static_cast<float>(input_tensor.at<cv::Vec3b>(i, j)[k]) / 255.0;
}
}
}
/** 推理. */
output_data = this->predict(input_data);
/** 后处理. */
cv::Mat output_tensor(output_data);
output_tensor =output_tensor.reshape(1, {input_width, input_height});
double minVal, maxVal;
cv::minMaxLoc(output_tensor, &minVal, &maxVal); ///< 获取最大值、最小值.
output_tensor.convertTo(output_tensor, CV_32F); ///< 转换数据类型,float32类型.
if (minVal != maxVal) {
output_tensor = (output_tensor - minVal) / (maxVal - minVal);
}
output_tensor *= 255.0;
output_tensor.convertTo(output_tensor, CV_8UC1); ///< 转单通道(灰度图).
cv::applyColorMap(output_tensor, output_tensor, cv::COLORMAP_HOT); ///< 伪彩映射.
return output_tensor;
}
std::chrono::time_point<std::chrono::high_resolution_clock> tic;
std::chrono::time_point<std::chrono::high_resolution_clock> toc;
std::chrono::milliseconds elapsed;
int main(int argc, char* argv[])
{
std::string model_path = "/zqpe/8001_DepthAnything_OnnxRuntime/out/bin/depth_anything_vits14.onnx";
std::string image_path = "/zqpe/8001_DepthAnything_OnnxRuntime/out/bin/204995.jpg";
printf("Construct depth anything inference engine.\n");
tic = std::chrono::high_resolution_clock::now();
DepthAnything model(model_path);
toc = std::chrono::high_resolution_clock::now();
elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(toc - tic);
printf("Construct depth anything inference engine, takes %ld ms\n", elapsed.count());
printf("Prepare sample.\n");
tic = std::chrono::high_resolution_clock::now();
cv::Mat image = cv::imread(image_path);
auto ori_h = image.cols;
auto ori_w = image.rows;
// cv::imshow("image", image);
cv::cvtColor(image, image, cv::COLOR_BGR2RGB);
cv::resize(image, image, {input_width, input_height}, 0.0, 0.0, cv::INTER_CUBIC);
toc = std::chrono::high_resolution_clock::now();
elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(toc - tic);
printf("Prepare sample, takes %ld ms\n", elapsed.count());
cv::Mat result;
// while(1){
printf("Do inference.\n");
tic = std::chrono::high_resolution_clock::now();
result = model.predict(image);
toc = std::chrono::high_resolution_clock::now();
elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(toc - tic);
printf("Do inference, takes %ld ms\n", elapsed.count());
// }
cv::resize(result, result, {ori_h, ori_w}, 0.0, 0.0, cv::INTER_CUBIC);
printf("Save result.\n");
int pos = image_path.rfind(".");
image_path.insert(pos, "_depth");
cv::imwrite(image_path, result);
}