软件设计之MySQL(7)
此篇应在JavaSE之后进行学习:
路线图推荐:
【Java学习路线-极速版】【Java架构师技术图谱】
Navicat可以在软件管家下载
``
使用navicat连接mysql数据库创建数据库、表、转储sql文件,导入sql数据
MySQL数据库入门到大牛,mysql安装到优化,百科全书级,全网天花板
资料可以去尚硅谷官网免费领取
学习内容:
- 视图概述
- 存储过程概述
- 存储函数
- 存储过程和函数的比较
- 存储过程使用的优缺点
1、视图概述
1、视图是一种
虚拟表,本身是不具有数据的,占用很少的内存空间,它是 SQL 中的一个重要概念。
2、视图建立在已有表的基础上, 视图赖以建立的这些表称为基表
3、视图的创建和删除只影响视图本身,不影响对应的基表。但是当对视图中的数据进行增加、删除和修改操作时,数据表中的数据会相应地发生变化,反之亦然
4、向视图提供数据内容的语句为SELECT,可以将视图理解为存储起来的SELECT语句

创建视图
准备工作
#准备工作
CREATE DATABASE dbtest;
USE dbtest;
CREATE TABLE emps
AS
SELECT *
FROM atguigudb.`employees`;
CREATE TABLE depts
AS
SELECT *
FROM atguigudb.`departments`;
针对单表情况
#针对于单表
#情况1:视图中的字段在基表中有对应字段
CREATE VIEW vu_emp1
AS
SELECT employee_id,last_name,salary
FROM emps;
#确定视图字段名的方式1:
CREATE VIEW vu_emp2
AS
#查询语句中字段的别名会作为字段的名称出现
SELECT employee_id emp_id,last_name lname,salary
FROM emps
WHERE salary > 8000;
#确定视图字段名的方式2:
CREATE VIEW vu_emp3(emp_id,NAME,monthly_sal)#括号内的字段别名个数与SELECT字段个数相同
AS
SELECT employee_id emp_id,last_name lname,salary
FROM emps
WHERE salary > 8000;
#情况2:视图中的字段在基表中可能没对应字段
CREATE VIEW vu_emp_sal
AS
SELECT department_id,AVG(salary) avg_sal
FROM emps
WHERE department_id IS NOT NULL
GROUP BY department_id;
针对多表情况
#针对于多表
CREATE VIEW vu_emp_dept
AS
SELECT e.employee_id,e.department_id,d.department_name
FROM emps e JOIN depts d
ON e.`department_id` = d.`department_id`
#利用视图对数据进行格式化
CREATE VIEW vu_emp_dept1
AS
SELECT CONCAT(e.last_name,'(',d.department_name,')')
FROM emps e JOIN depts d
ON e.`department_id` = d.`department_id`;
基于视图创建视图
CREATE VIEW vu_emp4
AS
SELECT employee_id,last_name
FROM vu_emp1;
查看视图
#语法1:查看数据库的表对象、视图对象
SHOW TABLES;
#语法2:查看视图的结构
DESC / DESCRIBE 视图名称;
#语法3:查看视图的属性信息
# 查看视图信息(显示数据表的存储引擎、版本、数据行数和数据大小等)
SHOW TABLE STATUS LIKE '视图名称'\G
#语法4:查看视图的详细定义信息
SHOW CREATE VIEW 视图名称;
更新视图中的数据
不能更新的视图情况:
1、在定义视图的时候指定了“ALGORITHM = TEMPTABLE”,视图将不支持INSERT和DELETE操作;
2、视图中不包含基表中所有被定义为非空又未指定默认值的列,视图将不支持INSERT操作;
3、在定义视图的SELECT语句中使用了JOIN联合查询,视图将不支持INSERT和DELETE操作;
4、在定义视图的SELECT语句后的字段列表中使用了数学表达式或子查询,视图将不支持INSERT,也不支持UPDATE使用了数学表达式、子查询的字段值;
在定义视图的SELECT语句后的字段列表中使用DISTINCT 、 聚合函数 、 GROUP BY 、 HAVING 、UNION等,视图将不支持INSERT、UPDATE、DELETE;
5、在定义视图的SELECT语句中包含了子查询,而子查询中引用了FROM后面的表,视图将不支持INSERT、UPDATE、DELETE;
6、视图定义基于一个不可更新视图;
7、常量视图。
#一般情况下,可以更新视图数据的情况
SELECT employee_id,last_name,salary
FROM emps;
#更新视图的数据,会导致基表中的数据修改
UPDATE vu_emp1
SET salary = 20000
WHERE employee_id = 101;
#更新表中的数据,也会导致视图中的数据修改
UPDATE emps
SET salary = 10000
WHERE employee_id = 101;
修改视图
#方式1
CREATE OR REPLACE VIEW vu_emp1
AS
SELECT employee_id,last_name,salary,email
FROM emps
WHERE salary > 7000;
#方式2
ALTER VIEW vu_emp1
AS
SELECT employee_id,last_name,salary,email,hire_date
FROM emps
删除视图
基于视图a、b创建了新的视图c,如果将视图a或者视图b删除,会导致视图c的查询失败。这样的视图c需要手动删除或修改,否则影响使用
SHOW TABLES;
DROP VIEW vu_emp4;
DROP VIEW IF EXISTS vu_emp2,vu_emp3;
2、存储过程概述
1、含义:存储过程是一组经过 预先编译 的 SQL 语句的封装。
2、执行过程:存储过程预先存储在 MySQL 服务器上,需要执行的时候,客户端只需要向服务器端发出调用存储过程的命令,服务器端就可以把预先存储好的这一系列 SQL 语句全部执行。
语法结构
IN :当前参数为输入参数,也就是表示入参;存储过程只是读取这个参数的值。如果没有定义参数种类, 默认就是 IN ,表示输入参数。
OUT :当前参数为输出参数,也就是表示出参;执行完成之后,调用这个存储过程的客户端或者应用程序就可以读取这个参数返回的值了。
INOUT :当前参数既可以为输入参数,也可以为输出参数。
characteristics表示创建存储过程时指定的对存储过程的约束条件(不细讲)
DELIMITER设置新的结束标记,因为MySQL默认的语句结束符号为分号‘;’。为了避免与存储过程中SQL语句结束符相冲突,需要使用DELIMITER改变存储过程的结束符
注意: navicat执行存储过程的时候,会默认就自动设置delimiter 为其他符号,不需要额外修改!!
CREATE PROCEDURE 存储过程名(IN|OUT|INOUT 参数名 参数类型,...)
[characteristics ...]
BEGIN
存储过程体
END
创建与调用存储过程
#这是在Navicat中运行的,所以这里没设置结束标记
# 创建存储过程
#类型1:无参
CREATE PROCEDURE select_all_data()
BEGIN
SELECT *
FROM employees;
END
#调用1:
CALL select_all_data();
#类型2:带OUT
CREATE PROCEDURE show_min_salary(OUT ms DOUBLE)
BEGIN
SELECT MIN(salary) INTO ms
FROM employees;
END
#调用2:
CALL show_min_salary(@ms);
#查看变量值
SELECT @ms;
#类型3:带IN
CREATE PROCEDURE show_someone_salary(IN empname VARCHAR(20))
BEGIN
SELECT salary
FROM employees
WHERE last_name = empname;
END
#调用3:
CALL show_someone_salary('Abel');
#类型4:带IN和OUT
CREATE PROCEDURE show_someone_salary2(IN empname VARCHAR(20),OUT empsalary DOUBLE)
BEGIN
SELECT salary INTO empsalary
FROM employees
WHERE last_name = empname;
END
#调用4:
CALL show_someone_salary2('Abel',@empsalary);
SELECT @empsalary;
#类型5:带INOUT
CREATE PROCEDURE show_mgr_name(INOUT empname VARCHAR(25))
BEGIN
SELECT last_name INTO empname
FROM employees
WHERE employee_id = (
SELECT manager_id
FROM employees
WHERE last_name = empname
);
END
#调用5:
SET @empname := 'Abel';
CALL show_mgr_name(@empname);
SELECT @empname;
3、存储函数
语法结构
1、
参数列表:指定参数为IN、OUT或INOUT只对PROCEDURE是合法的,FUNCTION中总是默认为IN参数。
2、RETURNS type 语句表示函数返回数据的类型;RETURNS子句只能对FUNCTION做指定,对函数而言这是强制的。它用来指定函数的返回类型,而且函数体必须包含一个RETURN value语句。
3、characteristic 创建函数时指定的对函数的约束。取值与创建存储过程时相同,这里不再赘述
4、函数体也可以用BEGIN…END来表示SQL代码的开始和结束。如果函数体只有一条语句,也可以省略BEGIN…END
CREATE FUNCTION 函数名(参数名 参数类型,...)
RETURNS 返回值类型
[characteristics ...]
BEGIN
函数体 #函数体中肯定有 RETURN 语句
END
注意点1

注意点2

创建与调用存储函数
SET GLOBAL log_bin_trust_function_creators = 1;
#类型1
CREATE FUNCTION email_by_name()
RETURNS VARCHAR(25)
BEGIN
RETURN(SELECT email FROM employees WHERE last_name = 'Abel');
END
#调用
SELECT email_by_name();
#类型2
CREATE FUNCTION email_by_id(emp_id INT)
RETURNS VARCHAR(25)
BEGIN
RETURN(SELECT email FROM employees WHERE employee_id = emp_id);
END
#调用
SELECT email_by_id(101);
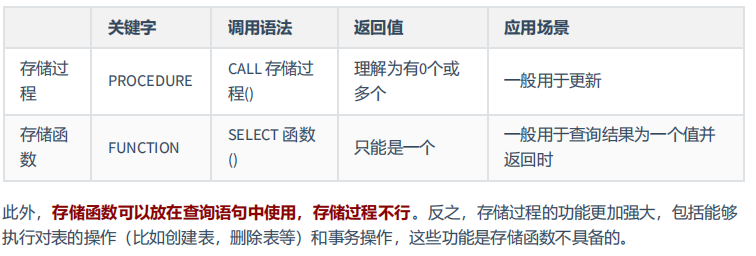
4、存储过程和函数的比较
存储过程和函数的查看
#1. 使用SHOW CREATE语句查看存储过程和函数的创建信息
SHOW CREATE {PROCEDURE | FUNCTION} 存储过程名或函数名
#2. 使用SHOW STATUS语句查看存储过程和函数的状态信息
SHOW {PROCEDURE | FUNCTION} STATUS [LIKE 'pattern']
#3. 从information_schema.Routines表中查看存储过程和函数的信息
SELECT * FROM information_schema.Routines
WHERE ROUTINE_NAME='存储过程或函数的名' [AND ROUTINE_TYPE = {'PROCEDURE|FUNCTION'}];
存储过程和函数的修改
修改存储过程或函数,不影响存储过程或函数功能,只是修改相关特性。使用ALTER语句实现。
ALTER {PROCEDURE | FUNCTION} 存储过程或函数的名 [characteristic ...]
存储过程和函数的删除
DROP {PROCEDURE | FUNCTION} [IF EXISTS] 存储过程或函数的名

