hadoop生态 怎么 安装 apache-Flume-1.8.0
Flume 1.8.0 是 Apache Flume 的一个版本,Flume 是一个分布式、可靠且可用的服务,用于高效地收集、聚合和传输大量日志数据到 Hadoop 存储。Flume 主要用于大数据生态系统中,尤其是与 Apache Hadoop 结合使用,来处理大规模的流数据。
主要常见的应用场景:
日志收集: Flume 常被用来收集应用程序日志、服务器日志等,并将其传输到 Hadoop 存储系统中进行进一步分析。
实时数据流: 它还可以用于实时流数据的处理和分析,广泛应用于日志分析、监控系统等场景。
总的来说,Flume 1.8.0 是一个高效的、可靠的数据传输系统,特别适用于处理大规模的流数据,并且与 Hadoop 生态中的其他工具(如 HDFS、HBase)无缝集成。
Flume安装部署
安装apache-flume-1.8.0
第一步
下载好 apache-flume-1.8.0-bin.tar.gz
第二步 解压
tar -zxvf apache-flume-1.8.0-bin.tar.gz
第三步 修改 权限
chmod 777 apache-flume-1.8.0-bin
进⼊apache-flume-1.8.0-bin的⽬录
第四步 重命名flume-env.sh.template ⽂件
mv flume-env.sh.template flume-env.sh
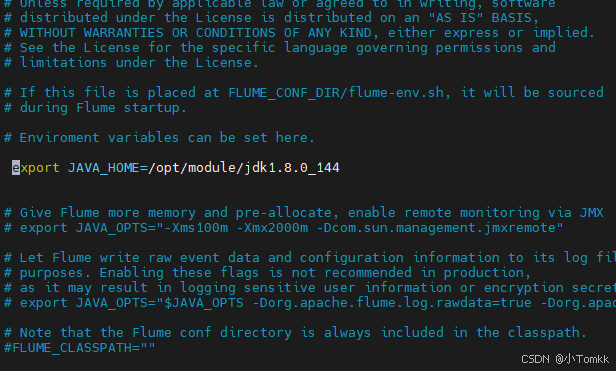
第五步 配置 flume-env.sh

vi flume-env.sh
第六步
升级替换 guava jar包
cp /opt/module/hadoop-3.3.0/share/hadoop/hdfs/lib/guava-27.0-jre.jar /opt/m
odule/apache-flume-1.8.0-bin/lib/
示例 1
1、先在flume的conf⽬录下新建⼀个⽂件
vim netcat-logger.conf
将下面的 数据 copy 到 netcat-logger.conf
# 定义这个agent中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置source组件:r1
a1.sources.r1.type = netcat
a1.sources.r1.spoolDir = /home/hadoop/logs
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 描述和配置sink组件:k1
a1.sinks.k1.type = logger
# 描述和配置channel组件,此处使⽤是内存缓存的⽅式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 描述和配置source channel sink之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
解释
Flume 配置说明
- 定义 Agent 中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1 是 Flume agent 的名称。在这个 agent 中,我们定义了三个组件:source、sink 和 channel。
r1 是 source 的名字。
k1 是 sink 的名字。
c1 是 channel 的名字。
2 配置 Source 组件 r1
a1.sources.r1.type = netcat
a1.sources.r1.spoolDir = /home/hadoop/logs
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sources.r1.type = netcat:该配置表示使用 netcat 类型的 source。netcat 是一个可以通过网络接收数据的 source 类型。
a1.sources.r1.spoolDir = /home/hadoop/logs:这个配置通常用于 spooldir 类型的 source,但在 netcat 类型中可能不会使用到。它指定了一个目录路径(/home/hadoop/logs)用于收集日志文件。
a1.sources.r1.bind = localhost:表示该 source 会绑定到本地网络地址(localhost)。
a1.sources.r1.port = 44444:该配置指定了 source 监听的端口(44444)。该端口将接收来自其他应用或者客户端的网络数据。
- 配置 Sink 组件 k1
a1.sinks.k1.type = logger
a1.sinks.k1.type = logger:该配置表示使用 logger 类型的 sink。logger 是一个将接收到的数据打印到 Flume 日志的 sink,而不是将数据写入到其他存储系统。通常在开发和调试过程中使用。
- 配置 Channel 组件 c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c1.type = memory:表示该 channel 使用内存作为缓存。这种配置适用于简单场景,数据将被存储在内存中。
a1.channels.c1.capacity = 1000:该配置设置了 c1 channel 能够存储的最大事件数量。最多可以缓存 1000 个事件。
a1.channels.c1.transactionCapacity = 100:表示在一次事务中,最多可以处理 100 个事件。
- 配置 Source、Sink 和 Channel 之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sources.r1.channels = c1:表示 r1 source 组件将事件发送到 c1 channel。
a1.sinks.k1.channel = c1:表示 k1 sink 组件从 c1 channel 获取事件并进行处理。
整体流程
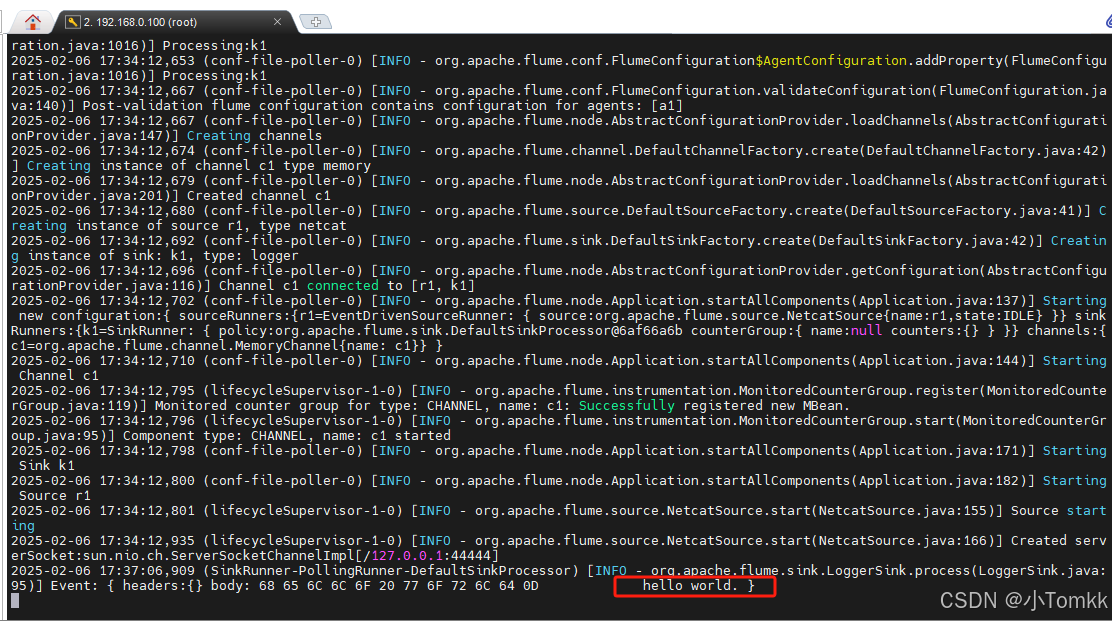
r1(netcat source)从 localhost:44444 端口接收数据。
接收到的数据会被传输到 c1(内存类型的 channel)。
k1(logger sink)从 c1 channel 获取事件并将其输出到 Flume 日志中。
采集
1、测试
先要往agent采集监听的端⼝上发送数据,让agent有数据可采。
随便在⼀个能跟agent节点联⽹的机器上:
telnet anget-hostname port
2、启动agent去采集数据
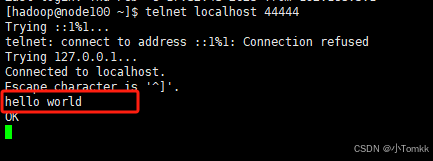
telnet localhost 44444
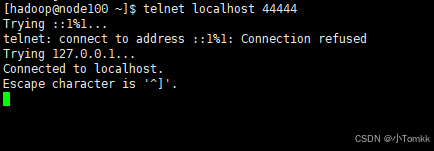
在看一个窗口
执行命令
bin/flume-ng agent --conf conf --conf-file conf/netcat-logger.conf --name a1 -Dflume.root.logger=INFO,console
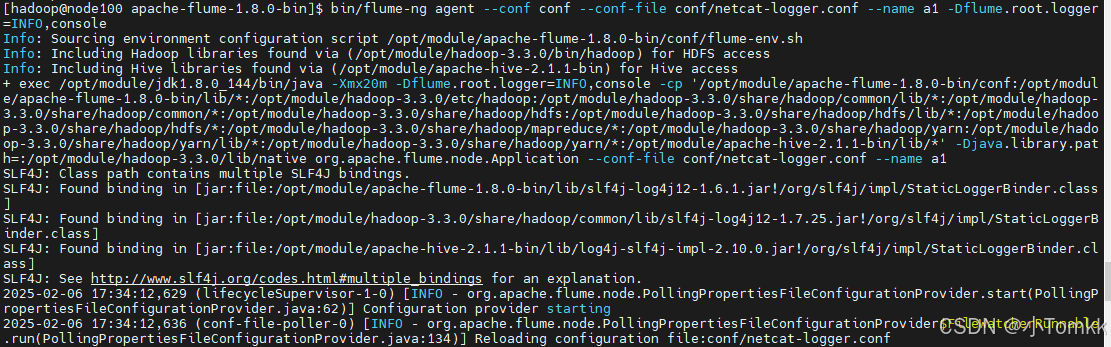
测试
打入 hello world
Flume 1.8.0 主要特点:
事件驱动的流处理: Flume 允许通过事件驱动的方式从各种来源(例如:日志文件、网络服务等)收集数据,并通过管道进行传输。
支持多种来源与接收器: Flume 提供了多种 Source、Sink 和 Channel,用于适应不同的数据源和存储需求。例如,可以从日志文件、数据库、HTTP 请求等多个来源中读取数据,并将数据发送到 HDFS、Kafka 等接收器。
可靠性和容错: Flume 在传输数据时具有内建的可靠性机制,能够确保在网络故障、节点崩溃等情况下尽量避免数据丢失。
高吞吐量与低延迟: Flume 被设计为高吞吐量、低延迟的流数据传输系统,适用于实时流数据的处理需求。
集成 Hadoop 生态: Flume 作为 Hadoop 生态的一部分,能够方便地将数据送入 HDFS 或 HBase,并与其他 Hadoop 组件如 Hive、Spark 等无缝集成。
改进的性能: Flume 1.8.0 在性能方面进行了优化,包括更好的内存管理、事件批处理优化等,使得在高负载场景下的处理更加高效。
新增功能与修复: 这个版本还修复了一些bug,并新增了一些功能,例如更灵活的配置选项、更丰富的监控工具等,提升了使用体验。
常见的应用场景:
日志收集: Flume 常被用来收集应用程序日志、服务器日志等,并将其传输到 Hadoop 存储系统中进行进一步分析。
实时数据流: 它还可以用于实时流数据的处理和分析,广泛应用于日志分析、监控系统等场景。