站在老罗的肩膀上:https://blog.csdn.net/luoshengyang/article/details/50558942
在Chromium中,Render进程是通过Browser进程下载网页内容的,后者又是通过共享内存将下载回来的网页内容交给前者的。Render进程获得网页内容之后,会交给WebKit进行处理。WebKit所做的第一个处理就是对网页内容进行解析,解析的结果是得到一棵DOM Tree。DOM Tree是网页的一种结构化描述,也是网页渲染的基础。
网页的DOM Tree的根节点是一个Document。Document是依附在一个DOM Window之上。DOM Window又是和一个Frame关联在一起的。Document、DOM Window和Frame都是WebKit里面的概念,其中Frame又是和Chromium的Content模块中的Render Frame相对应的。Render Frame是和网页的Frame Tree相关的一个概念。关于网页的Frame Tree,可以参考前面Chromium Frame Tree创建过程分析一文。
上面描述的各种对象的关系可以通过图1描述,如下所示:
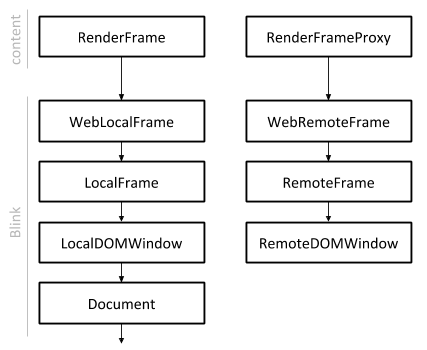
图1 Frame、DOM Window和Document的关系
从前面Chromium Frame Tree创建过程分析一文可以知道,有的Render Frame只是一个Proxy,称为Render Frame Proxy。Render Frame Proxy描述的是在另外一个Render进程中进行加载和渲染的网页。这种网页在WebKit里面对应的Frame和DOM Window分别称为Remote Frame和Remote DOM Window。由于Render Frame Proxy描述的网页不是在当前Render进程中加载和渲染,因此它是没有Document的。
相应地,Render Frame描述的是在当前Render进程中进行加载和渲染的网页,它是具有Document的,并且这种网页在WebKit里面对应的Frame和DOM Window分别称为Local Frame和Local DOM Window。
接下来,我们就结合源码分析WebKit在解析网页内容的过程中创建DOM Tree的过程。从前面Chromium网页URL加载过程分析一文可以知道,Browser进程一边下载网页的内容,一边将下载回来的网页交给Render进程的Content模块。Render进程的Content模块经过简单的处理之后,又会交给WebKit进行解析。WebKit是从ResourceLoader类的成员函数didReceiveData开始接收Chromium的Content模块传递过来的网页内容的,因此我们就从这个函数开始分析WebKit解析网页内容的过程,也就是网页DOM Tree的创建过程。
ResourceLoader类的成员函数didReceiveData的调用和实现如下所示:
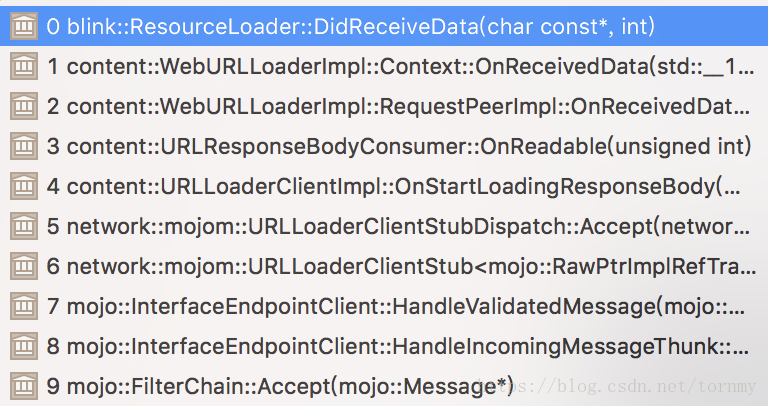
void ResourceLoader::DidReceiveData(const char* data, int length) {
CHECK_GE(length, 0);
Context().DispatchDidReceiveData(resource_->Identifier(), data, length);
resource_->AppendData(data, length);
}src/third_party/blink/renderer/platform/loader/fetch/resource_loader.cc
void Resource::AppendData(const char* data, size_t length) {
...
ResourceClientWalker<ResourceClient> w(Clients());
while (ResourceClient* c = w.Next())
c->DataReceived(this, data, length);
}src/third_party/blink/renderer/platform/loader/fetch/resource.cc
从前面Chromium网页URL加载过程分析一文可以知道,DocumentLoader对象是从ResourceClient类继承下来的,它负责创建和加载网页的文档对象。接下来我们就继续分析它的成员函数dataReceived的实现,如下所示:
void DocumentLoader::DataReceived(Resourc