写kafka生产者前先通过命令行创建topic主题和开启消费者:
①创建topic:
bin/kafka-topics.sh --zookeeper hadoop100:2181 --create --replication-factor 1 --partitions 2 --topic first②开启消费者:
bin/kafka-console-consumer.sh --zookeeper hadoop100:2181 --topic first一、最简单的生产者代码:
package tyh.Test;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class MyProducer {
public static void main(String[] args) {
//1、生产者配置信息
Properties properties = new Properties();
//将配置信息以key,value的形式put到properties中
//kafka集群
properties.put("bootstrap.servers", "hadoop100:9092");
//acks,默认所有
properties.put("acks", "all");
//重试次数,默认1次
properties.put("retries", 1);
//批次大小,默认16KB
properties.put("batch.size", 16384);
//等待时间,默认1ms
properties.put("linger.ms", 1);
//设置key的序列化
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//设置value的序列化
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//2、创建一个生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
//3、发送数据
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<String, String>("first", "tyh--" + i));
}
//4、关闭连接
producer.close();
}
}
思路:
①我们要创建的是kafka的生产者,万物皆对象,我们先new KafkaProducer
②发现KafkaProducer需要用到 Properties存储配置信息,一定要有的配置信息为:kafka集群,key、Value的序列化(注,创建KafkaProducer时需要知道key、value的类型,是什么类型的就用什么类型的序列化器)
③生产数据并发送给消费者,用到的是send方法,需要ProducerRecord对象,参数如下,在之前的博客中举例提到过

结果:
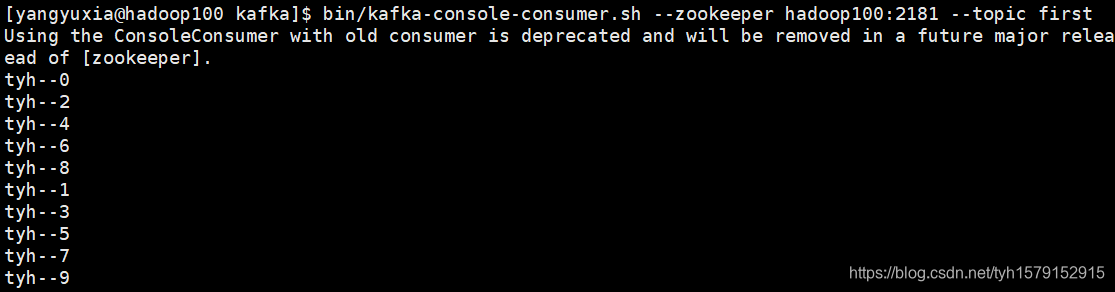
注:因为first主题有两个分区,而kafka是批量存储和消费数据的,所以是先消费一个分区再消费另一个,而数据在分区间是无序的,在分区内是有序的,而且分区分配也是按照轮询的方式分配的。
二、进阶一:存储配置信息的key很容易写错,kafka将配置文件的key封装在了一个对象中
package tyh.Test;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class MyProducer {
public static void main(String[] args) {
//1、生产者配置信息
Properties properties = new Properties();
//将配置信息以key,value的形式put到properties中
//kafka集群
// properties.put("bootstrap.servers", "hadoop100:9092");
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop100:9092");
//设置key的序列化
// properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
//设置value的序列化
// properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
//2、创建一个生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
//3、发送数据
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<String, String>("first", "tyh-" + i));
}
//4、关闭连接
producer.close();
}
}
①优化后可以不用记配置文件的key,而且可以通过类查看相应配置信息的说明:
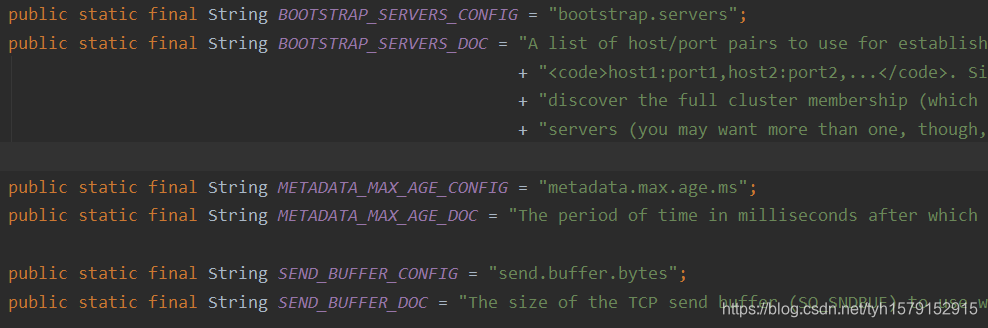
如图所示,每个配置信息都是一个config和一个DOC,config存储key,DOC存储这个配置的说明
②序列化的全类名不需要记,ctrl+N(idea)搜索类,记得要找Kafka包下的,是什么类型的就搜索:类型+serializer,找到类后右键copy references复制全类名就可以了
三、进阶二:带回调函数的生产者
package tyh.Producer;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class CallBackProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop100:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<String, String>("first", "tyh---" + i), new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.println(metadata.partition() + "-" + metadata.offset());
} else {
exception.printStackTrace();
}
}
});
}
producer.close();
}
}
结果如下:


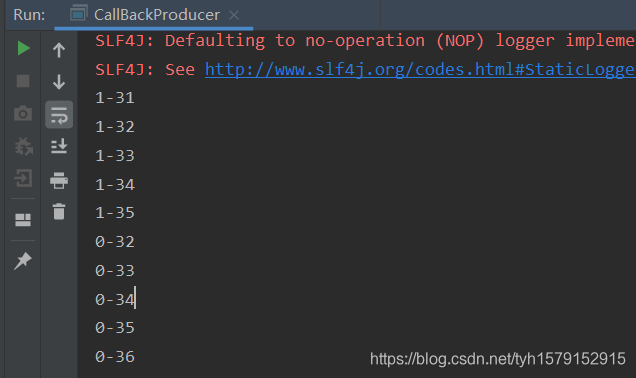
四、进阶三:自定义分区器
以下是kafka提供的的默认分区器
package org.apache.kafka.clients.producer.internals;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.ThreadLocalRandom;
import java.util.concurrent.atomic.AtomicInteger;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.utils.Utils;
public class DefaultPartitioner implements Partitioner {
private final ConcurrentMap<String, AtomicInteger> topicCounterMap = new ConcurrentHashMap<>();
public void configure(Map<String, ?> configs) {}
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
private int nextValue(String topic) {
AtomicInteger counter = topicCounterMap.get(topic);
if (null == counter) {
counter = new AtomicInteger(ThreadLocalRandom.current().nextInt());
AtomicInteger currentCounter = topicCounterMap.putIfAbsent(topic, counter);
if (currentCounter != null) {
counter = currentCounter;
}
}
return counter.getAndIncrement();
}
public void close() {}
}
我们可以通过自定义分区器,继承Partition抽象类来实现自定义分区器功能,根据自己的业务逻辑重写partition方法。
我在这简单讲述一下该默认分区器的逻辑结构:
①通过topic(主机)拿到partition对象,和分区数
②若没传入key值,则得到随机数值并自增,然后通过这个随机数与活着的topic数取余得到要传入partition的值
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);方法为得到活着的主机数
③若传入了key值,则得到key的hash值并于主机数取余得到要传入partition的值

最简单的一个分区器,将所有消息都传入0号分区
使用自定义分区的生产者:
package tyh.Producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import java.util.Properties;
public class PartitionProducer {
public static void main(String[] args) {
//生产者配置信息
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop100:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
//自定义Partition
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "tyh.Partitioner.MyPartitioner");
//创建一个生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
//生产者发送消息
for (int i = 0; i < 10; i++) {
}
//关闭资源
producer.close();
}
}
结果:只有一个消费者得到了数据


五、进阶四:同步发送的生产者
package tyh.Producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class ConsumerProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop100:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 10; i++) {
try {
Future<RecordMetadata> first = producer.send(new ProducerRecord<String, String>("first", "tyh" + i));
first.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
producer.close();
}
}
Kafka 的 Producer 发送消息采用的是异步发送的方式。在消息发送的过程中,涉及到了两个线程——main 线程和 Sender 线程,以及一个线程共享变量——RecordAccumulator。main 线程将消息发送给 RecordAccumulator,Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka broker。
同步发送的意思就是,一条消息发送之后,会阻塞当前线程,直至返回 ack。要使生产者同步发送消息,需要将主线程阻塞,直至sender线程结束,这样做可以保证kafka写入的消息是有序的。