FilterNet: Harnessing Frequency Filters for Time Series Forecasting
1.layerNorm

https://blog.csdn.net/weixin_41978699/article/details/122778085
1.1)NCHW 求CHW的均值和方差

1.2)NCHW 求C的均值和方差
先把C换到最后一位

1.3) N, seq_len, em_dim 求 em_dim的均值和方差

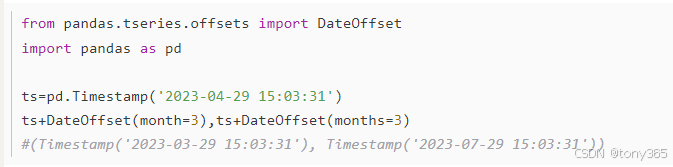
2.pandas.tseries
2.1 tseries.frequencies.to_offset

2.2 pandas.tseries.offsets
参考:https://blog.csdn.net/qq_40206371/article/details/130202526

3. StandardScaler
根据特征均值和标准差 normalization
每一行是一个样本,每一列是一个特征,求每个特征的均值和标准差进行计算。
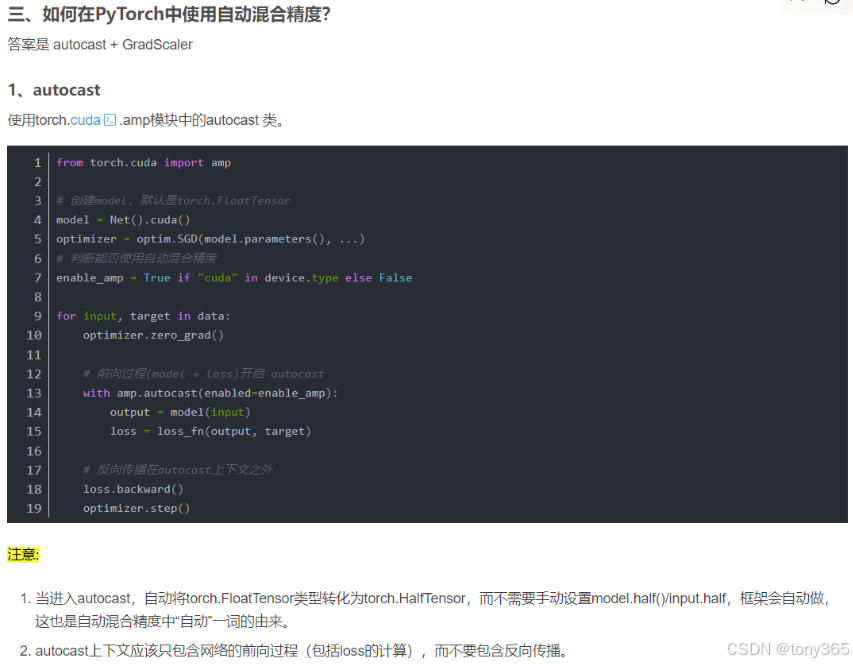
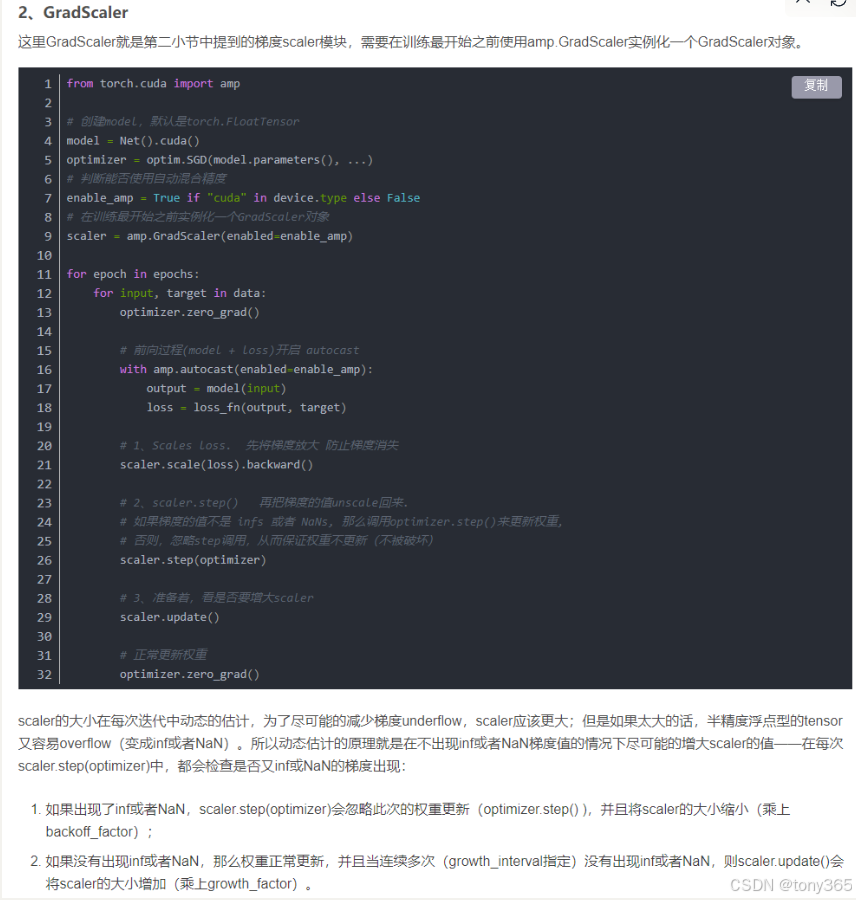
4. torch.cuda.amp
https://blog.csdn.net/qq_38253797/article/details/116210911
用法:
和
5.PaiFilter,对应论文4.1节
整体架构:
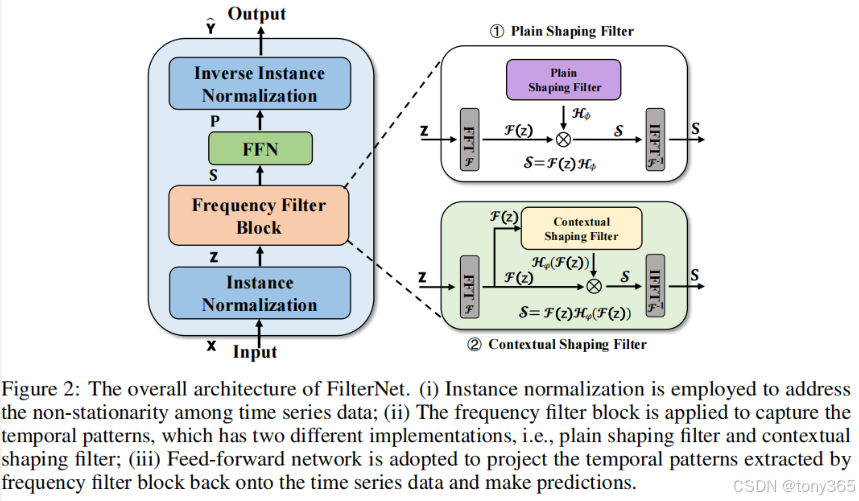
5.1 norm和denorm
假如是 [batch_size, seq_len , feature_num] 的数据
得到的均值和方差的 shape 是[batch_size, 1 , feature_num]
表示该序列长度seq_len中的数据的feature的均值和方差
import torch
import torch.nn as nn
class RevIN(nn.Module):
def __init__(self, num_features: int, eps=1e-5, affine=True, subtract_last=False):
"""
:param num_features: the number of features or channels
:param eps: a value added for numerical stability
:param affine: if True, RevIN has learnable affine parameters
"""
super(RevIN, self).__init__()
self.num_features = num_features
self.eps = eps
self.affine = affine
self.subtract_last = subtract_last
if self.affine:
self._init_params()
def forward(self, x, mode:str):
if mode == 'norm':
self._get_statistics(x)
x = self._normalize(x)
elif mode == 'denorm':
x = self._denormalize(x)
else: raise NotImplementedError
return x
def _init_params(self):
# initialize RevIN params: (C,)
self.affine_weight = nn.Parameter(torch.ones(self.num_features))
self.affine_bias = nn.Parameter(torch.zeros(self.num_features))
def _get_statistics(self, x):
dim2reduce = tuple(range(1, x.ndim-1))
if self.subtract_last:
self.last = x[:,-1,:].unsqueeze(1) # batch_size,seq_len,feature_num seq_len最后一个
else:
self.mean = torch.mean(x, dim=dim2reduce, keepdim=True).detach( )# 特征的均值(每个序列 seq_len个样本 的均值)
self.stdev = torch.sqrt(torch.var(x, dim=dim2reduce, keepdim=True, unbiased=False) + self.eps).detach() # 特征的方差
def _normalize(self, x):
if self.subtract_last:
x = x - self.last
else:
x = x - self.mean
x = x / self.stdev
if self.affine:
x = x * self.affine_weight
x = x + self.affine_bias
return x
def _denormalize(self, x):
if self.affine:
x = x - self.affine_bias
x = x / (self.affine_weight + self.eps*self.eps)
x = x * self.stdev
if self.subtract_last:
x = x + self.last
else:
x = x + self.mean
return x
5.2 frequency filter
频域滤波
每个特征都是 长度为swq_len的序列,转换到频域信息,滤波,再转换回
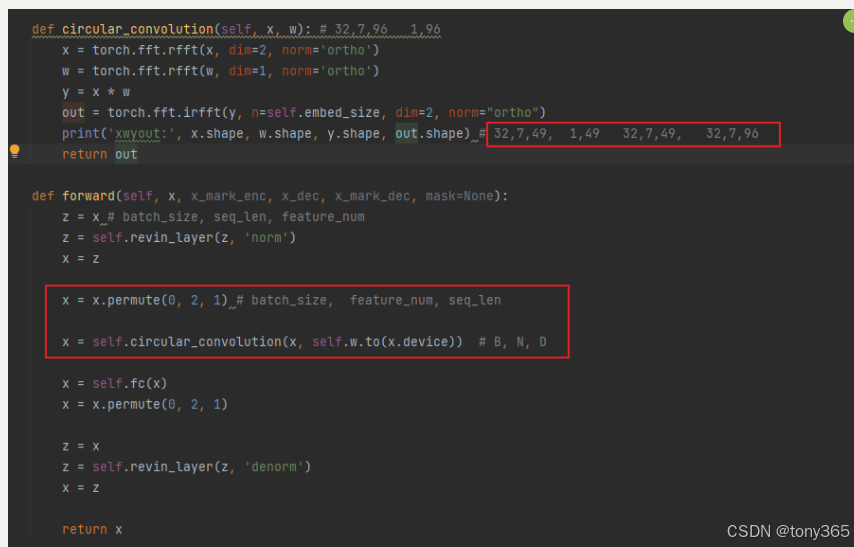
5.3 一个全连接层

直接看源代码还是比较清晰明了的,具体来说就是
5.4 paifilter总结
一共以下几个步骤:
input:batch_size, seq_len, feature_num
norm: 求每个特征的均值和方差(seq_len个数的均值和方差),以及norm
filter: x是输入,w 是可学习的滤波系数, 将两者转换到频域,相乘,再转回来。 频域也是针对feature而言的,就是求每个特征的 频域(seq_len个数的fft)
fc: 一个线性全连接层 输出 batch_size, pred_len, feature_num
denorm
关于数据,首先搞清楚输入输出,代码写的有点绕,对于ETTm1实验来说:
input是 seq_len=96的序列,预测 后面 pred_len=96的序列
6. TexFilter
直接看作者源码,有个疑问
in paifilter code: torch.fft.rfft(x, dim=1, norm=‘ortho’) is on seq_len , but texfilter code torch.fft.rfft is calculated on feature_num ?