一、背景
在文档搜索场景中,高效精准的搜索功能至关重要,能提升检索效率,为用户提供精准、快速的信息获取体验,提高工作效率。在文档管理系统里,全文搜索是非常重要的功能之一。随着文档数量增长,如何快速从大量文档中找到所需内容成为关键。全文搜索允许用户输入关键词,即可检索到包含该关键词的文档内容,提升查找便捷性与准确性,帮助用户快速定位信息。
我们曾经使用 ES 搜索引擎来实现相关功能,但由于我们的产品是私有化部署,每个用户都需要自行部署 ES 才能使用系统,这带来了较高的技术门槛和运维成本,而且部署过程复杂,在结果处理上也存在诸多不便,最终放弃了这一方案。
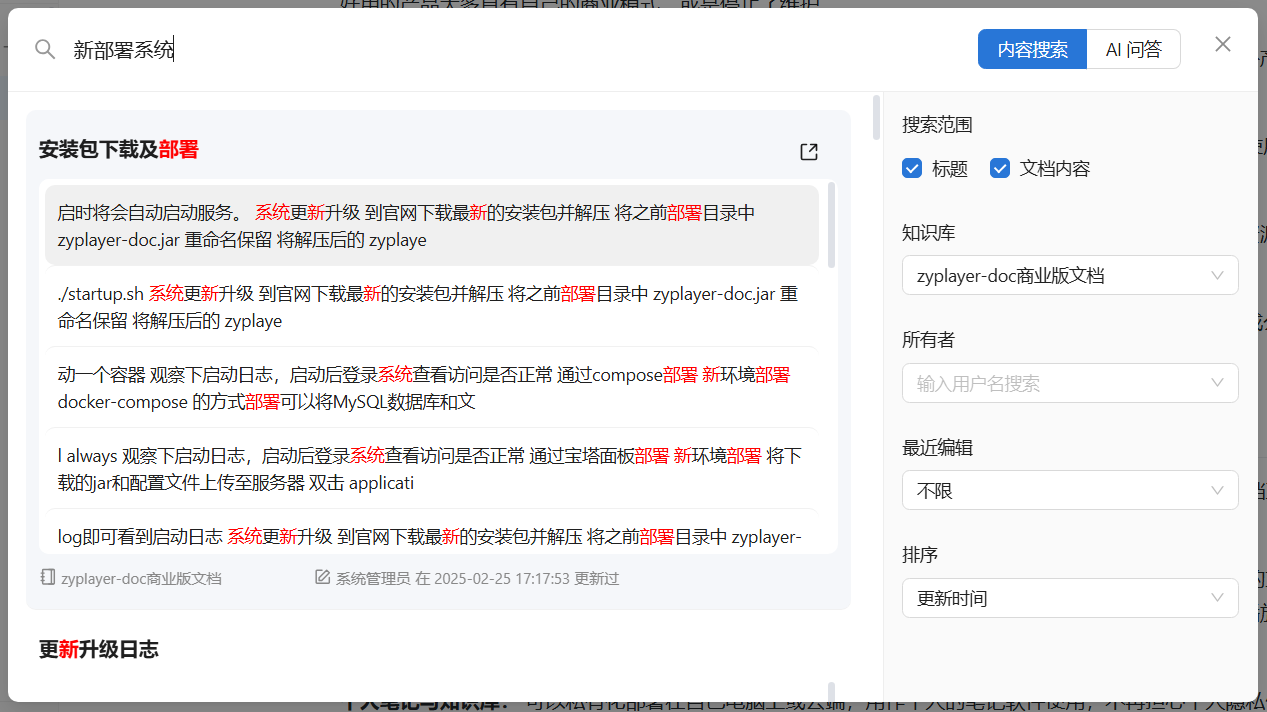
我们目标是使用 MySQL 实现高效搜索,达到结果按关键字自行分段处理的效果,同时对每个分段进行打标,以便前端在用户点击分段时,能够跳转到该文档并自动滚动到该段落展示,当前的搜索展示结果是这样的:

以下均为我们在使用MySQL搜索中的一些技术和心得,如有不理解的地方或更好的方案欢迎随时交流。
内容讲述的还算比较完整,尝试将文档给AI大模型让其写一个Java的工具类实现效果还是差不多,只有些边界值判断和细节需要自己再优化下。
二、数据来源和存储方式
我们是一个文档管理系统,数据来源包含用户在线编辑的Markdown、富文本、在线表格、Word、PPT、Excel等可解析的结构化文档,还有API接口、思维导图、Drawio等非机构化的文档。
数据的存储可理解为一张表上有两个字段,一个编辑保存的原始内容字段和一个用于搜索的纯文本字段。
在纯文本内容获取上,不同的格式需要使用不同的工具来解析,比如网页上使用 dom.textContent获取,后端使用Jsoup、Docx4J、Apache PIO 等工具包,最终得到的是一个不包含样式的纯文本内容。

三、全文搜索和结果处理
用户输入预处理
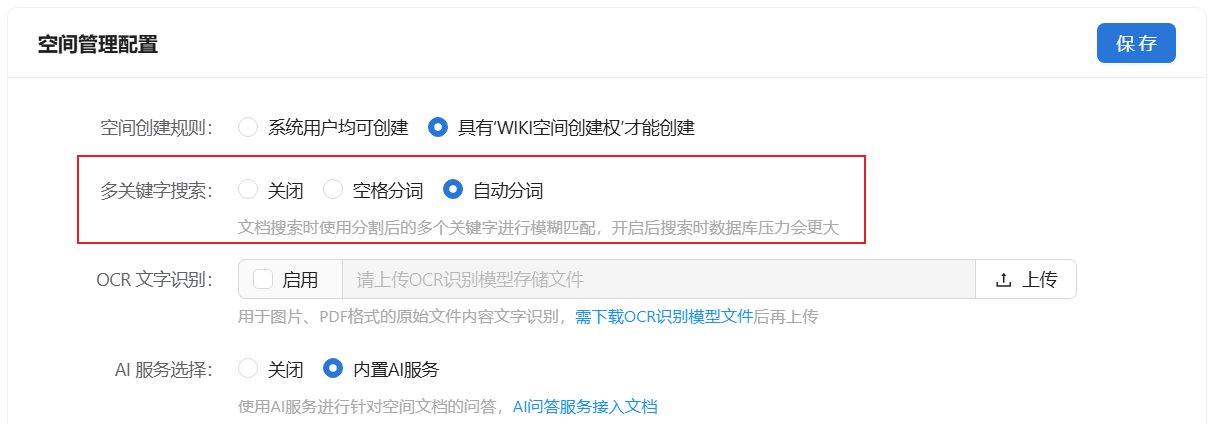
首先根据用户选择的按空格分割还是自动分词对用户输入的内容进行预处理,空格分割:StringUtils.split(search, " "),或者自动分词:HanLP.segment(search) ,再对结果进行去重和排序处理,将分割内容按长度从多到少的进行排序,为了防止内容太多就取前面10个词语。对取到的值进行停用词的过滤,比如:的、了、或、在、是 等意义不大的单个字,对搜索结果的意义性不大,过滤掉还能提升一点速度。
再对分割后的词语进行按文字长度打分,中文一个字得一分,英文一个单词得一分,得分可用于数据库匹配结果的排序和后续结果的重排序。
数据库搜索和排序
因为我们是按空间划分的,单个空间下也不会有千万级、亿级的海量文档数据,搜索结果也无需翻页,仅展示前10个文档即可,在测试和评估后仅使用MySQL的正则搜索或模糊搜索是能满足需求的。
对分割后的词语使用正则的方式拼接,在数据库中使用REGEXP的方式进行模糊搜索匹配,对文档中匹配到的文字数量进行得分累加排序,处理后的SQL大概是这样:
select
(
if(preview LIKE '%新%', 1, 0) + if(preview LIKE '%部署%', 2, 0) + if(preview LIKE '%系统%', 2, 0)
) as keyword_weight
from wiki_page_content
where preview REGEXP '新|部署|系统'
order by keyword_weight desc, id desc
limit 10;据说like的效率会高一点,过滤条件也可以改为:where preview like '%新%' or preview like '%部署%' or preview like '%系统%'
可以用全文索引来查,但效果不理想,总是查不出数据来,分词方式也不可控,暂不考虑。
结果分段和关键字标红
遍历搜索结果的所有文档,新建一个函数传入关键字列表和文档内容,再遍历关键字列表,在文档内容中找到该关键字的索引下标,通过下标减40和加40个字符为一个分段:【下标 -40,关键字,下标 +40】,这样一个段落大概80 ~ 90个字符,再从下标 +40 处截断文档内容,进行下一个段落的匹配,匹配完后再匹配下一个关键字,直到全部搜索完成。单个文档的段落数最多匹配20个,再后面的相关性不高意义不大。
每次分段后需要将开始和结束的下标存起来,如果下一个关键字在已有的开始结束范围内则跳过,防止分段内容重复。
关键字标红会比较麻烦一点,首先遍历所有的分段,再新建一个函数传入分段文本和关键字列表,遍历关键字列表去匹配分段文本,匹配到之后将文本进行拆分,拆成【左、中、右】三个分段或两个分段,并对关键字的段打标,示例:
分段文本:
支持单机部署这个文档系统
第一次拆分:
[{text: "支持单机"}, {text: "部署", keyword: true}, {text: "这个文档系统"}]
第二次拆分:
[{text: "支持单机"}, {text: "部署", keyword: true}, {text: "这个文档"}, {text: "系统", keyword: true}]
.... 一直遍历关键字和拆分结果,直到把内容全部处理完。
最后使用字符串拼接将拆分结果拼起来,关键字的文本前后增加 <span style="color:red;"></span> 标红的行级元素包裹起来,如果有连续的关键字需要进行合并标红。
分段的打分和重排序
上述处理的拆分段落是按文档内容顺序排序的,会导致一些不重要的关键字段落排在了前面,关键字较多的段落排到了后面的情况,所以还需要对段落和文档进行重排序,优先展示关键字更多的段落。
这里使用在 用户输入预处理 中的关键字得分来进行计算,处理后的分段文本:
{text: '支持单机部署这个文档系统', score: 4}
再对单个文档中的分段按得分进行排序,对所有文档按段落总分进行重排序,现在看上去匹配效果好了很多,匹配更多的段落放到了最前面。
四、后续规划和想法
这样做的匹配展示效果还算可以,主要的性能瓶颈就在于数据库的模糊匹配,考虑到一个空间最多就几千一万左右的有效文档,搜索基本能做到秒返回,对于中小企业来说已经足够了,在后续使用中我们还会根据使用效果和反馈不断的优化检索的易用性和准确率。
当然随着文档的不断增加,后期还是会接入ES等专业的搜索引擎来做搜索,在检索速度上会有一定提升。