说点无关的话:这文章是我在http://www.uml.org.cn/mobiledev/201211063.asp#5这里读到的,整整花了两天时间看完的,权当是了解这个系统的内部构造了,感觉应该有时间再次翻看一下,于是就转载过来,文章很长,请耐心!
本文内容,主题是透过应用程序来分析Android系统的设计原理与构架。我们先会简单介绍一下Android里的应用程序编程,然后以这些应用程 序在运行环境上的需求来分析出,为什么我们的Android系统需要今天这样的设计方案,这样的设计会有怎样的意义, Android究竟是基于怎样的考虑才变成今天的这个样子,所以本文更多的分析Android应用程序设计背后的思想,品味良好架构设计的魅力。分五次连 载完成,第一部分是最简单的部分,解析Android应用程序的开发流程。
Android应用程序开发以及背后的设计思想深度剖析 3
Android应用程序开发以及背后的设计思想深度剖析 4
Android应用程序开发以及背后的设计思想深度剖析 5
1. Android应用程序
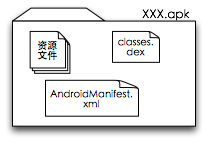
在目前Android大红大紫的情况下,很多人对编写Android应用程序已经有了足够深入的了解。即便是没有充分的认识,在现在Android 手机已经相当普及的情况下,大家至少也会知道Android的应用程序会是一个以.apk为后缀名的文件(在Windows系统里,还会是一个带可爱机器 人图标的文件)。那这个apk包又有什么样的含义呢?
如果您正在使用Linux操作系统,可以使用命令file命令来查看这一文件的类型。比如我们下载了一个Sample.apk的文件,则使用下面的命令:
$file Sample.apk Sample.apk: Zip archive data, at least v1.0 to extract |
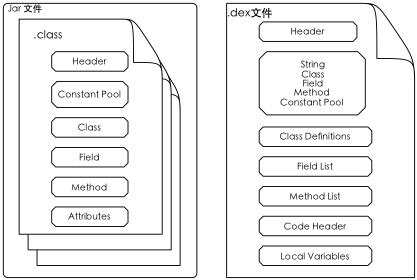
对,没有看错,只一个简单的zip文件。要是做过Java开发的人,可以对这种格式很亲切,因为传说中的.jar、.war格式,都是Zip压缩格 式的文件。我们可继续使用unzip命令将这一文件解压(或是任何的解压工具,zip是人类历史是最会古老最为普及的压缩格式之一,几乎所有压缩工具都支 持)。通过解压,我们就得到了下面的文件内容:
AndroidManifest.xml, classes.dex, resources.arsc, META-INF, res, |
到这里,我们就可以看到一个Android应用程序结构其实是异常简单的。这五部分内容(其中META-INF和res是目录,其他是文件)除了 META-INF是这一.apk文件的校验信息,resources.arsc是资源的索引文件,其他三部分则构成了Android应用程序的全部。
- AndroidManifest.xml,这是每个Android应用程序包的配置文件,这里会保存应用程序名字、作者、所实现的功能、以及一些权限验证信息。但很可惜,在编译完成的.apk文件里,这些文件都被编译成了二进制版本,我们暂时没有办法看到内容,后面我们可以再看看具体的内容。
- classes.dex,这则是Android应用程序实现的逻辑部分,也就是通过Java编程写出来而被编译过的代码。这种特殊的格式,是Android里特定可执行格式,是可由Dalvik虚拟机所执行的代码,这部分内容我们也会在后续的介绍Dalvik虚拟机的章节里介绍。
- res,这一目录里则保存了Android所有图形界面设计相关的内容,比如界面应该长成什么样子、支持哪些语言显示等等。
从一个android应用程序的包文件内容,我们可以看到android应用程序的特点,这也是Android编程上的一些特征:
1 简单:最终生成的结果是如些简单的三种组成,则他们的编程上也不会有太大的困难性。这并不是说 Android系统里无法实现很复杂的应用程序,事实上Android系统拥有世界上仅次于iOS的应用程序生态环境,也拥有复杂的办公软件、大型3D游 戏。而只是说,如果要实现和构成同样的逻辑,它必然会拥有其他格式混杂的系统更简化的编程模式。
2 Java操作系统:既然我们编译得到的结果,classes.dex文件,是用于Java虚拟机 (虽然是Dalvik虚拟机,但实际上这一虚拟机只是一种特定的Java解析器和虚拟机执行环境 )解析执行的,于是我们也可以猜想到,我们的Android系统,必然是一个Java操作系统。我们在后面会解释,如果把Android系统直接看成 Linux内核和Java语言组合到一起的操作系统很不准确,但事实上Android,也还是Java操作系统,Java是唯一的系统入口。
使用MVC设计模式:所谓的MVC,就是Model,View,Controller的首字母组合起来的一种设计模 式,主要思想就是把显示与逻辑实现分离。Model用于保存上下文状态、View用于显示、而Controller则是用于处理用户交互。三者之间有着如 下图所示的交互模型,交互只到Controller,而显示更新只通过View进行,这两者再与Model交换界面状态信息:
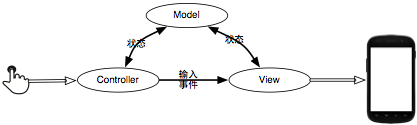
在现代的图形交互相关的设计里,MVC几乎是在图形交互处理上的不二选择,这样系统设计包括一些J2EE的应用服务器框架,最受欢迎的 Firefox浏览器,iOS,MacOSX等等。这些使用MVC模式的最显著特点就是显示与逻辑分离,在Android应用程序里我们看到了用于逻辑实 现的classes.dex,也看到用于显示的res,于是我们也可以猜想到在UI上便肯定会使用MVC设计模式。
当然,所谓的Android应用程序编程,不会只有这些内容。到目前为止,我们也只是分析.apk文件,于是我们可以回过头来看看Android应用被编译出来的过程。
2. Android编程
从编程角度来说,Android应用程序编程几乎只与Java相关,而Java平台本身是出了名跨平台利器,理论上来说,所有Java环境里使用的 编程工具、IDE工具,皆可用于Android的编程。Android SDK环境里提供的编程工具,是基于标准的Java编译工具ant的,但事实上,一些大型的Android软件工程,更倾向于使用Maven这样的并行化 编译工具(maven.apache.org)。如果以前有过Java编程经验,会知道Java环境里的图形化IDE(Integrated Development Environment)工具,并非只有Eclipse一种,实际上Java的官方IDE是NetBeans,而商用化的Java大型项目开发者,也可能 会比较钟意于使用IntelliJ,而从底层开发角度来说,可能使用vim是更合适的选择,可以灵活地在C/C++与Java代码之间进行切换。总而言 之,几乎所有的Java环境的编程工具都可以用于Android编程。
对于这些工具呢,熟悉工具的使用是件好事,所谓“磨刀不误砍柴工”,为将来提升效率,这是件好事。但是要磨刀过多,柴没砍着,转型成“磨刀工”了。如果过多地在这些编程工具上纠结尝试,反而忽视了所编代码的本身,这倒会舍本逐末。
我们既然是研究Android编程,这时仅说明两种Android官方提供的编程方法:使用Android SDK工具包编程,或是使用Eclipse + ADT插件编程。
2.1 使用Android SDK工具包
在Android开发过程中,如果Eclipse环境不可得的情况下,可以直接使用SDK来创建应用程序工程。首先需要安装某一个版本的Android SDK开发包,这个工具包可以到http://developer.android.com/sdk/index.html这 个网址去下载,根据开发所用的主机是Windows、Linux还是MacOS X(MacOS仅支持Intel芯片,不支持之前的PowerPC芯片),下载对应的.zip文件,比如android-sdk_r19- linux.zip。下载完成后,解压到一个固定的目录,我们这里假定是通过环境变量$ANDROID_SDK_PATH指定的目录。
下载的SDK包,默认是没有Android开发环境支持的,需要通过tools目录里的一个android工具来下载相应的SDK版本以用于开发。我们通过运行$ANDROID_SDK_PATH/tools/android会得到如下的界面:

在上面的安装界面里选择不同的开发工具包,其中Tools里包含一些开发用的工具,如我们的SDK包,实际上也会在这一界面里进行更新。而对于不同 的Android版本,1.5到4.1,我们必须选择下载某个SDK版本来进行开发。而下载完之后的版本信息,我们既可以在这一图形界面里看到,也可以通 过命令行来查看。
$ANDROID_SDK_PATH/tools/android list targets
id: 1 or "android-16"
Name: Android 4.1
Type: Platform
API level: 16
Revision: 1
Skins: HVGA, QVGA, WQVGA400, WQVGA432, WSVGA, WVGA800 (default), WVGA854, WXGA720, WXGA800, WXGA800-7in
ABIs : armeabi-v7a
----------
id: 2 or "Google Inc.:Google APIs:16"
Name: Google APIs
Type: Add-On
Vendor: Google Inc.
Revision: 1
Description: Android + Google APIs
Based on Android 4.1 (API level 16)
Libraries:
* com.google.android.media.effects (effects.jar)
Collection of video effects
* com.android.future.usb.accessory (usb.jar)
API for USB Accessories
* com.google.android.maps (maps.jar)
API for Google Maps
Skins: WVGA854, WQVGA400, WSVGA, WXGA800-7in, WXGA720, HVGA, WQVGA432, WVGA800 (default), QVGA, WXGA800
ABIs : armeabi-v7a |
通过android list targets列出来的信息,可以用于后续的开发之用,比如对于不同的target,最后得到了id:1、id:2这样的信息,则可以被用于应用程序工程 的创建。而细心一点的读者会看到同一个4.1版本的SDK,实际可分为”android-16”和"Google Inc.:Google APIs:16",这样的分界也还有有意义的,”android-16”用于“纯”的android 4.1版的应用程序开发,而“Google Inc.:Google APIs:16”则加入了Google的开发包。
配置好环境之后,如果我们需要创建Android应用程序。tools/android这个工具,同时也具备可以创建Android应用程序工程的能力。我们输入:
$ANDROID_SDK_PATH/tools/android create project -n Hello -t 1 -k org.lianlab.hello -a Helloworld -p hello |
这样我们就在hello目录里创建了一个Android的应用程序,名字是Hello,使用API16(Android 4.1的API版本),包名是org.lianlab.hello,而默认会被执行到的Activity,会是叫Helloworld的Activity 类。
掌握Android工具的一些使用方法也是有意义的,比如当我们的Eclipse工程被破坏的情况下,我们依然可以手工修复这一Android应用程序工程。或是需要修改该工程的API版本的话,可以使用下面的命令:
$ANDROID_SDK_PATH/tools/android updateproject -t 2 -p .
在这个工程里,如果我们不加任何修改,会生成一个应用程序,这个应用程序运行的效果是生成一个黑色的图形界面,打印出一行"Hello World, Helloworld"。如果我们需要对这一工程进行编译等操作的话,剩下的事情就属于标准的Java编译了,标准的Java编译,使用的是 ant(ant.apache.org)编译工具。我们先改变当前目录到hello,然后就可以通过” ant –projecthelp”来查看可以被执行的Android编译工程,
$ ant -projecthelp
Buildfile: /Users/wuhe/android/workspace/NotePad/bin/tmp/hello/build.xml
Main targets:
clean Removes output files created by other targets.
debug Builds the application and signs it with a debug key.
install Installs the newly build package. Must be used in conjunction with a build target
(debug/release/instrument). If the application was previously installed, the application
is reinstalled if the signature matches.
installd Installs (only) the debug package.
installi Installs (only) the instrumented package.
installr Installs (only) the release package.
installt Installs (only) the test and tested packages.
instrument Builds an instrumented packaged.
release Builds the application in release mode.
test Runs tests from the package defined in test.package property
uninstall Uninstalls the application from a running emulator or device.
Default target: help |
但如果只是编译,我们可以使用antdebug生成Debug的.apk文件,这时生成的文件,会被放到bin/Hello-debug.apk。 此时生成的Hello-debug.apk,已经直接可以安装到Android设备上进行测试运行。我们也可以使用ant release来生成一个bin/Hello-release-unsigned.apk,而这时的.apk文件,则需要通过jarsigner对文件进 行验证才能进行安装。
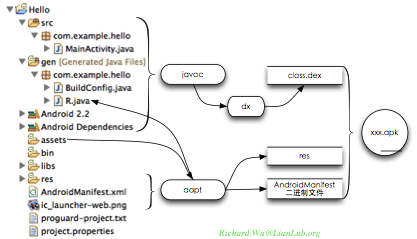
通过antdebug这一编译脚本,我们可以看到详细的编译过程。我们可以看到,一个Android的工程,最后会是通过如图所示的方式生成最后的.apk文件。
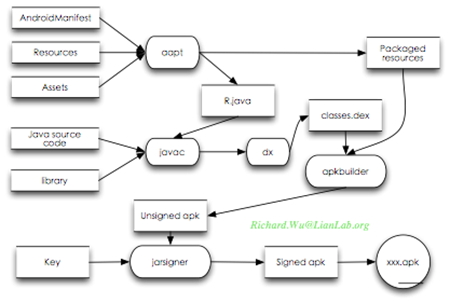
把一个Android的源代码工程编译成.apk的Android应用程序,其过程如下:
1) 所有的资源文件,都会被aapt进行处理。所有的XML文件,都会被aapt解析成二进制格式,准确地说,这样的二进制格式,是可以被直接映射到内存里的 二进制树。做过XML相关开发的工程师,都会知道,XML的验证与解析是非常消耗时间与内存的,而通过编译时进行XML解析,则节省了运行时的开销。当然 解析的结果最后会被aapt通过一个R.java保存一个二进制树的索引,编程时可通过这个R.java文件进行XML的访问。aapt会处理所有的资源 文件,也就是Java代码之外的任何静态性文件,这样处理既保证了资源文件间的互相索引得到了验证,也确保了R.java可以索引到这个应用程序里所有的 资源。
2) 所有的Java文件,都会被JDK里的javac工具编译成bin目录下按源代码包结构组织的.class文件(.class是标准的Java可解析执行 的格式),比如我们这个例子里生成的bin/classes/org/lianlab/hello/*.class文件。然后这些文件,会通过SDK里提 供的一个dx工具转换成classes.dex文件。这一文件,就是会被Dalvik虚拟机所解析执行的
3) 最后我们得到的编译过的二进制资源文件和classes.dex可执行文件,会通过一个apkbuilder工具,通过zip压缩算法打包到一个文件里,生成了我们所常见的.apk文件。
4) 最后,.apk文件,会通过jarsigner工具进行校验,这一校验值会需要一个数字签名。如果我们申请了Android开发者帐号,这一数字签名就是 Android所分发的那个数字证书;如果没有,我们则使用debug模式,使用本地生成的一个随机的数字证书,这一文件位于~/.android /debug.keystore。
虽然我们只是下载了SDK,通过一行脚本创建了Android应用程序工程,通过另一行完成了编译。但也许还是会被认为过于麻烦,因为需要进行字符界面的 操作,而且这种开发方式也不是常用的方式,在Java环境下,我们有Eclipse可用。我们可以使用Eclipse的图形化开发工具,配合ADT插件使 用。
2.2 使用Eclipse+ADT插件
在Android环境里可以使用Java世界里几乎一切的开发工具,比如NetBeans等,但Eclipse是Android官方标准的开发方 式。使用Eclipse开发,前面提到的开发所需SDK版本下载,也是必须的,然后还需要在Eclipse环境里加装ADT插件,Android Development Toolkit。
我们在Eclipse的菜单里,选择”Help” à “Install New Software…”,然后在弹出的对话框里的Workwith:输入ADT的发布地址:https://dl-ssl.google.com/android.eclipse,回车,则会得到下面的软件列表。选择Select All,将这些插件全都装上,则得到了可用于Android应用程序开发的环境。
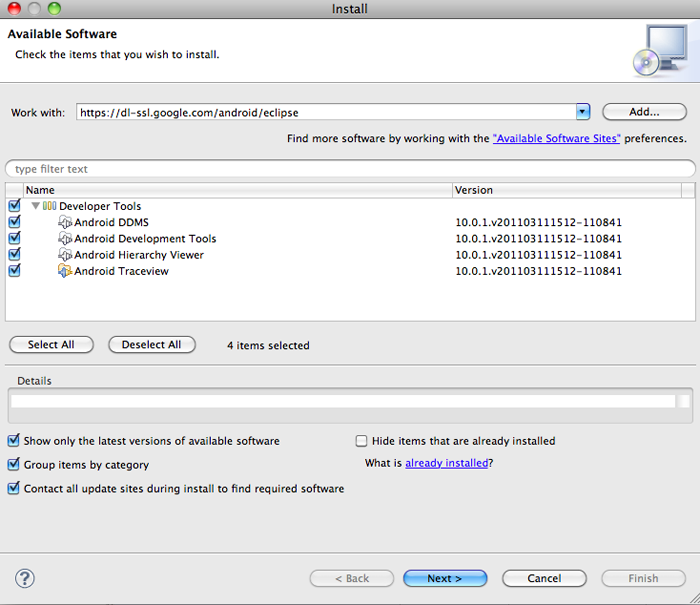
这里还需要指定SDK的地址,Windows或是Linux里,会是在菜单“Window” à “Preferences”,在MacOS里,则会是”Eclipse” à“Preferences” 。在弹出的对话框里,选择Android,然后填入Android SDK所保存的位置。

点击OK之后,则可以进行Android开发了。选择”File” à “New”à “Project” à “Android”,在Eclipse 3.x版本里,会是“Android Project”,在Eclipse 4.x版本里,会是“Android Application Project”。如果我们需要创建跟前面字符界面下一模一样的应用程序工程,则在弹出的创建应用程序对话框里填入如下的内容:
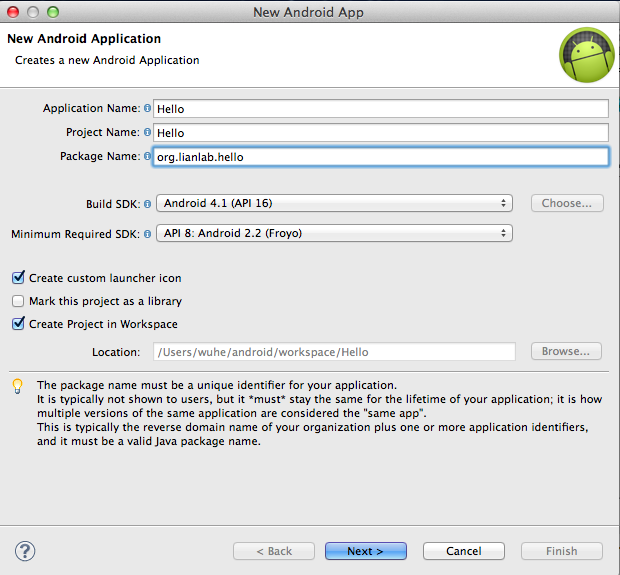
然后我们选择Next,一直到弹出最后界面提示,让我们选择默认Activity的名字,最后点击”Finish”,我们就得到一个Android 应用程序工程,同时在Eclipse环境里,我们既可以通过图形化界面编辑Java代码,也可以通过图形化的界面编辑工具来绘制图形界面。
(注意: 如果Android工程本身比较庞大,则最好将Eclipse里的内存相关的配置改大。在Windows和Linux里,是修改eclipse里的 eclipse.ini文件,而在MacOS里,则是修改Eclipse.app/Contents/MacOS/eclipse.ini。一般会将如下 的值加大成两倍:
--launcher.XXMaxPermSize 512m -vmargs -Xms80m -Xmx1024m ) |
我们得到工程目录,在Eclipse环境里会是如下图所示的组织方式。代码虽然是使用一模一样的编译方式,唯一的改变是,我们不再需要使用脚本来完 成编译,我们可以直接使用Eclipse的”Project”à“Build project”来完成编译过程。如果我们使用默认设置,则代码是使用自动编译的,我们的每次修改都会触发增量式的编译。
我们从这些android编程的过程,看不出来android跟别的Java编程模式有什么区别,倒至少验证了我们前面对android编程特点的 猜想,就是很简单。如果同样我们使用Eclipse开发Java的图形界面程序,需要大量地时间去熟悉API,而在Android这里学习的曲线被大大降 低,如果我们只是要画几个界面,建立起简单的交互,我们几乎无须学习编程。
而从上面的步骤,我们大概也可以得到Android开发的另一个好处,就是极大的跨平台性,它的开发流程里除了JDK没有提及任何的第三方环境需 求,于是这样的开发环境,肯定可以在各种不同的平台执行。这也是Android上进行开发的好处之一,跨平台,支持Windows,Linux与 MacOS三种。
我们再来看一个,我们刚才创建的这个工程里,我们怎么样进行下一步的开发。在Android开发里,决定我们应用程序表现的,也就是我们从一个.apk文件里看到的,我们实际上只需要:
- 修改AndroidManifest.xml文件。AndroidManifest.xml是Android应用程序的主控文件,类型于Windows里的注册表,我们通过它来配置我们的应用程序与系统相关的一些属性。
- 修改UI显示。在Android世界里,我们可以把UI编程与Java编程分开对待,处理UI控件 的语言,我们可以叫它UI语言,或是layout语言,因为它们总是以layout类型的资源文件作为主入口的。Android编程里严格地贯彻MVC的 设计思路,使我们得到了一个好处,就是我们的UI跟要实现的逻辑没有任何必然联系,我们可先去调整好UI显示,而UI显示后台的实现逻辑,则可以在后续的 步骤里完成。
- 改写处理逻辑的Java代码。也就是我们MVC里的Controller与Model部分,这些部 分的内容,如果与UI没有直接交互,则我们可以放心大胆的改写,存在交互的部分,比如处理按钮的点击,取回输入框里的文字等。作为一个定位于拓展能力要求 最高的智能手机操作系统,android肯定不会只实现画画界面而已,会有强大的可开发能力,在android系统里,我们可以开发企业级应用,大型游 戏,以及完整的Office应用。
无论是通过tools/android工具生成的Android源代码目录,还是通过Eclipse来生成的Android源代码工程,都需要进一 步去自定义这个步骤来完成一个Android应用程序。当然,还有一种特殊的情况就是,这个源代码工程并非直接是一个Android应用程序,只是 Unit Test工程或是库文件工作,并不直接使用.apk文件,这里则可能后续的编程工作会变得不同。我们这里是分析Android应用程序,于是后面分别来看 应用程序编程里的这三部分的工作如何进行。
2.3 AndroidManifest.xml
先来看看AndroidManifest.xml文件,一般出于方便,这一文件有可能也被称为manifest文件。像我们前面的例子里的创建的Android工程,得到的AndroidManifest.xml文件就很简单:
<?xml version="1.0" encoding="utf-8"?>
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="org.lianlab.hello"
android:versionCode="1"
android:versionName="1.0">
<application android:label="@string/app_name">
<activity android:name=".Helloworld"
android:label="@string/app_name">
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
</activity>
</application>
</manifest>
<div id="chart" style="width:360px;height:200px"/>
</body>
</html> |
作为xml文件,所有的<>都会是成对的,比如我们看到的<manifest></manifest>,这被 称为标签(Tag)。标签可以包含子标签,从而可以形成树型的结点关系。如果没有子标签,则我们也可以使用</>来进行标识,比如我们上面看 到的<actionandroid:name=”android.intent.action.MAIN” />。
<manifest>,是主标签,每个文件只会有一个,这是定义该应用程序属性的主入口,包含应用程序的一切信息,比如我们的例子里定义了xml的命名空间,这个应用程序的包名,以及版本信息。
<application>,则是用于定义应用程序属性的标签,理论上可以有多个,但多个不具有意义,一般我们一个应用程序只会有一个,在这个标签里我们可以定义图标,应用程序显示出来的名字等。在这一标签里定义的属性一般也只是辅助性的。
<activity>,这是用来定义界面交互的信息。我们在稍后一点的内容介绍Android编程细节时会描述到这些信息,这一标签里的属性定义会决定应用程序可显示效果。比如在启动界面里的显示出来的名字,使用什么样的图标等。
<intent-filter>,这一标签则用来控制应用程序的能力的,比如该图形界面可以完成什么样的功能。我们这里的处理比较简单,我们只是能够让这个应用程序的HelloWorld可以被支持点击到执行。
从这个最简单的AndroidManifest.xml文件里,我们可以看到Android执行的另一个特点,就是可配置性强。它跟别的编程模型很不一样的地方是,它没有编程式规定的main()函数或是方法,而应用程序的表现出来的形态,完全取决于<activity>字段是如何定义它的。
2.4 图形界面(res/layout/main.xml)
我们可以再来看android的UI构成。UI也是基于XML的,是通过一种layout的资源引入到系统里的。在我们前面看到的最简单的例子里,我们会得到的图形界面是res/layout/main.xml,在这一文件里,我们会看到打开显示,并在显示区域里打印出Hello World, Helloworld。
<?xml version="1.0" encoding="utf-8"?>
<RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent" >
<TextView
android:id="@+id/textView1"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_centerInParent="true"
android:padding="@dimen/padding_medium"
android:text="@string/hello_world"
tools:context=".HelloWorld" />
</RelativeLayout> |
在这个图形界面的示例里,我们可以看到,这样的图形编程方式,比如传统的方式里要学习大量的API要方便得多。
<LinearLayout>,这一标签会决定应用程序如何在界面里摆放相应的控件
<TextView>,则是用于显示字符串的图形控件
使用这种XML构成的UI界面,是MVC设计的附属产品,但更大的好处是,有了标准化的XML结构,就可以创建可以用来画界面的IDE工具。一流的系统提供工具,让设计师来设计界面、工程师来逻辑,这样生产出来的软件产品显示效果与用户体验会更佳,比如iOS;二流的系统,界面与逻辑都由工程师来完成,在这种系统上开发出来的软件,不光界面不好看,用户体验也会不好。我们比如在Eclipse里的工程里查看,我们会发现,我们打开res/layout/main.xml,会自动弹出来下面的窗口,让我们有机会使图形工具来操作界面。
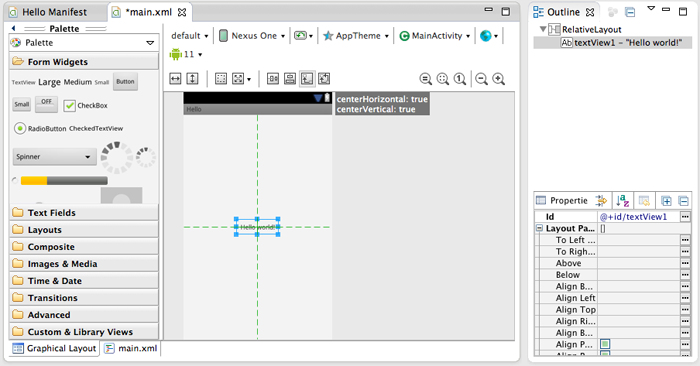
在上面IDE工具里,左边是控件列表,中间是进行绘制的工作区,右边会是控件一些微调窗口。一般我们可以从左边控制列表里选择合适的控件,拖到中间的工作区来组织界面,原则上的顺序是layout à 复合控件 à 简单控件。中间区域可以上面还有选择项用于控制显示属性,在工作区域里我们可以进一步对界面进行微调,也可以选择控件点击左键,于是会出来上下文菜单来操作控件的属性。到于右边的操作界面,上部分则是整个界面构成的树形结构,而下部分则是当我们选择了某个界面元素时,会显示上下文的属性。最后,我们还可以在底部的Graphic Layout与main.xml进行图形操作界面与源代码编辑两种操作方式的切换。
有了这种工具,就有可能实现设计师与工程师合作来构建出美观与交互性更好的Android应用程序。但可惜的是,Android的这套UI设计工具,太过于编程化,而且由于版本变动频繁的原因,非常复杂化,一般设计师可能也不太容易学好。更重要的一点,Android存在碎片化,屏幕尺寸与显示精度差异性非常大,使实现像素级精度的界面有技术上的困难。也这是Android上应用程序不如iOS上漂亮的原因之一。但这种设计至少也增强了界面上的可设计性,使Android应用程序在观感上也有不俗表现。
我们可以再回过头来看看应用程序工程里的res目录,res目录里包含了Android应用程序里的可使用的资源,而资源文件本身是可以索引的,比如layout会引用drawable与values里的资源。对于我们例子里使用的<TextView … android:text="Hello World,Helloworld" …>,我们可以使用资源来进行引用,<TextView …android:text=” @string/hello_string” …>,然后在res/values/strings.xml里加入hello_string的定义。
.<string name="hello_world">Hello world!</string>
从通过这种方式,我们可以看另外一些特点,就是Android应用程序在多界面、多环境下的自适应性。对于上面的字符串修改的例子,我们如果像下面的示例环境那样定义了res/layout-zh/strings.xml,并提供hello_string的定义:
<string name="hello_world">欢迎使用!</string>
最后,得到的应用程序,在英文环境里会显示‘Hello world!’,而如果系统当前的语言环境是中文的话,就会显示成‘欢迎使用!’。这种自适应方式,则是不需要我们进行编程的,系统会自动完成对这些显示属性的适配。
当然,这时可能会有人提疑问,如果这时是韩文或是日文环境会出现什么情况呢?在Android里,如果不能完成相应的适配,就会使用默认值,比如即使是我们创建了res/values-zh/strings.xml资源,在资源没有定义我们需要使用的字符串,这时会使用英文显示。不管如何,Android提供自适应显示效果,但也保证总是不是会出错。
这些也体现出,一旦Android应用程序写出来,如果对多语言环境不满意,这时,我们完全可以把.apk按zip格式解开,然后加入新的资源文件定义,再把文件重新打包,也就达到了我们可能会需要的汉化的效果。
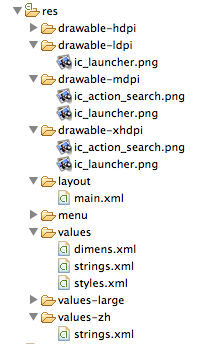
在res目录里,我们看到,对于同一种类型的资源,比如drawable、values,都可以在后面加一个后缀,像mdpi,hdpi, ldpi是用于适配分辨率的,zh是用来适配语言环境的,large则是用来适配屏幕大小的。对于这种显示上的自适应需求,我们可以直接在Eclipse里通过创建Android XML文件里得到相应的提示,也可以参考http://developer.android.com/training/basics/supporting-devices/查看具体的使用方式。
于是,透过资源文件,我们进一步验证了我们对于Android MVC的猜想,在Android应用程序设计里,也跟iOS类似,可以实现界面与逻辑完全分离。而另一点,就是Android应用程序天然具备屏幕自适应的能力,这一方面带来的影响是Android应用程序天生具备很强的适应性,另一方面的影响是Android里实现像素精度显示的应用程序是比较困难的,维护的代价很高。
我们可以再通过应用程序的代码部分来看看应用程序是如何将显示与逻辑进行绑定的。
2.5 Java编程(src/org/lianlab/hello/HelloWorld.java)
在Android编程里,实现应用程序的执行逻辑,几乎就是纯粹的Java编程。但在编程上,由于Android的特殊性,这种Java编程也还是被定制过的
我们看到我们例子里的源代码,如果写过Java代码,看到这样的源代码存放方式,就可以了解到Android为什么被称为Java操作系统的原因了,像这种方式,就是标准的Java编程了。事实上,在Android的代码被转义成Dalvik代码之前,Android编程都可被看成标准的Java编程。我们来看这个HelloWorld.java的源代码。
package org.lianlab.hello;
import android.os.Bundle;
import android.app.Activity;
public class HelloWorld extends Activity {
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
}
} |
代码结构很简单,我们所谓的HelloWorld,就是继承了Activity的基类,然后再覆盖了Acitivity基于的onCreate()方法。
Activity类,是Android系统设计思路里的很重要的一部分,所有与界面交互相关的操作类都是Activity,是MVC框架里的Controller部分。那Model部分由谁来提供呢?这是由Android系统层,也就是Framework来提供的功能。当界面失去焦点时,当界面完全变得不可见时,这些都属于Framework层才会知道的状态,Framework会记录下这些状态变更的信息,然后再回调到Activity类提供的相应状态的回调方法。关于Activity我们后面来详细说明,而见到Activity类的最简单构成,我们大体上就可以形成Android世界里的完整MVC框架构成完整印象了。
我们继承了Activity类之后,就会覆盖其onCreate()回调方法。这里我们使用了”@Override”标识,这是一种Java语言里的Annotation(代码注释)技术,相当于C语言里的pragma,用于告诉编译器一些相应参数。我们的Override则告诉javac编译器,下面的方法在构建对象时会覆盖掉父类方法,从而提高构建效率。Activity类里提供的onXXX()系列的都可以使用这种方法进行覆盖,从而来实现自定义的方法,切入到Android应用程序不同状态下的自定义实现。
我们覆盖掉的onCreate()方法,使用了一个参数,savedInstanceState,这个参数的类型是Bundle。Bundle是构建在Android的Binder IPC之上的一种特殊数据结构,用于实现普通Java代码里的Serialization/Deserializaiton功能,序列化与反序列化功能。在Java代码里,我们如果需要保存一些应用程序的上下文,如果是字符串或是数据值等原始类型,则可以直接写到文件里,下次执行时再把它读出来就可以了。但假设我们需要保存的是一个对象,比如是界面的某个状态点,像下面的这样的数据结构:
class ViewState {
public int focusViewID;
public Long layoutParams ;
public String textEdited;
…
} |
这时,我们就无法存取这样的结构了,因为这样的对象只是内存里的一些标识,存进时是一个进程上下文环境,取回来时会是另一种,就会出错。为了实现这样的功能,就需要序列化与反序列化,我们读写时都不再是以对象为单位,而是以类似于如下结构的一种字典类型的结构,最后进行操作的是一个个的键值对, ViewState[‘focusViewID’]的值会是valueOfViewID,一个整形值。
‘ViewState’ {
‘focusViewID’: valueOfViewID,
‘LayoutParams’:valueOfLayoutParams,
‘textEdited’: ‘User input’,
} |
我们按这种类似的格式写到文件里,当再读取出来时,我们就可以新建一个ViewState对象,再使用这些保存过的值对这一对象进行初始化。这样就可以实现对象的保存与恢复,这是我们onCreate()方法里使用Bundle做序列化操作的主要目的,我们的Activity会有不同生存周期,当我们有可能需要在进程退出后再次恢复现象时,我们就会在退出前将上下文环境保存到一个onSavedInstance的Bundle对象里,而在onCreate()将显示的上下文恢复成退出时的状态。
而另一个必须要使用Bundle的理由是,我们的Activity与实现Activity管理的Framework功能部件ActivityManager,是构建在不同进程空间上的,Activity将运行在自己独立的进程空间里,而Framework则是运行在另一个系统级进程SystemServer之上。我们的Bundle是一种进行过序列化操作的对象,于是相应的操作是系统进程会触发Activity的进行onCreate()回调操作,而同时会转回一个上下文环境的Bundle,可将Activity恢复到系统指定的某种图形界面状态。Bundle也可能为空,比如Activity是第一个被启动的情况下,这个空的onSavedInstance则会被忽略掉。
我们进入到onCreate()方法之后,第一行便是
super.onCreate(savedInstanceState);
从字面上看,这种方式相当于我们继承了父类方法,然后又回调到父类的onCreate()来进行处理。这种方式貌似很怪,但这是设计模式(Design Pattern)里鼎鼎大名的一种,叫IoC ( Inversion of Control)。通过这样的设计模式,我们可以同时提供可维护性与可调试性,我们可以在通过覆盖的方法提供功能更丰富的子类,实际上每次调用子类的onCreate()方法,都将调用到各个Activity拓展类的onCreate()方法。而这个方法一旦进入,又会回调到父类的onCreate()方法,在父类的onCreate()方法里,我们可以提供更多针对诸多子类的通用功能(比如启动时显示的上下文状态的恢复,关闭时一些清理性工作),以及在这里面插入调试代码。
然后,我们可以加载显示部分的代码的UI,
setContentView(R.layout.main);
这一行,就会使我们想要显示的图形界面被输出到屏幕上。我们可以随意地修改我们的main.xml文件,从而使setContentView()之后显示出来的内容随之发生变化。当然,作为XML的UI,最终是在内存里构成的树形结构,我们也可以在调用setContentView()之前通过编程来修改这个树形结构,于是也可以改变显示效果。
到目前为止,我们也只是实现了将内容显示到屏幕上,而没有实现交互的功能。如果要实现交互的功能,我们也只需要很简单的代码就可以做到,我们可以将HelloWorld.java改成如下的内容,从而使用我们的”Hello world”字符串可以响应点击事件:
package org.lianlab.hello;
import android.os.Bundle;
import android.app.Activity;
import android.view.View;
import android.view.View.OnClickListener;
import android.widget.TextView;
public class HelloWorld extends Activity {
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
((TextView)findViewById(R.id.textView1)).setOnClickListener(
new OnClickListener() {
@Override
public void onClick(View v) {
finish();
}
});
}
} |
我们使用Activity类的findViewById()方法,则可以找到任何被R.java所索引起来的资源定义。我们在这里使用了R.id.textView1作为参数,是因为我们在main.xml就是这么定义TextView标签的:android:id="@+id/textView1"。
而我们找到字段之后,会调用TextView对象的setOnClickListener()方法,给TextView注册一个onClickListener对象。这样的对象,是我们在Android世界里遇到的第二次设计模式的使用(事实上Android的实现几乎使用到所有的Java世界里的通用设计模式),Listener本身也会被作为Observer设计模式的一种别称,主要是用于实现被动调用逻辑,比如事件回馈。
Observer(Listener)设计模式的思路,跟我们数据库里使用到的Trigger功能类似,我们可对需要跟踪的数据操作设置一个Trigger,当这类数据操作进行时,就会触发数据库自动地执行某些操作代码。而Observer(Listener)模式也是类似的,监听端通过注册Observer来处理事件的回调,而真正的事件触发者则是Observer,它的工作就是循环监听事件,然后再调用相应监听端的回调。
这样的设计,跟效率没有必然联系,太可以更大程度地降低设计上的复杂度,同时提高设计的灵活性。一般Observer作为接口类,被监听则会定位成具体的Subject,真正的事件处理,则是通过实现某个Observer接口来实现的。对于固定的事件,Subject对象与Observer接口是无须变动的,而Observer的具体实现则可以很灵活地被改变与扩充。如下图所示:

如果我们对于监听事件部分的处理,也希望能加入这样的灵活性,于是我们可以继续抽象,将Subject泛化成一个Observable接口,然后可以再提供不同的Observable接口的实现来设计相应的事件触发端。
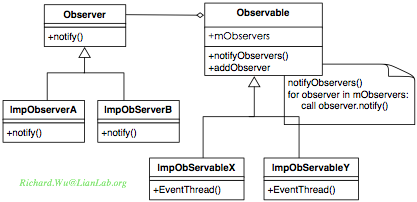
针对于我们的Android里的OnClickListener对象,则是什么情况呢?其实不光是OnClickListener,在Android里所有的事件回调,都有类似于Observer的设计技巧,这样的回调有OnLongClickListener,OnTouchListener,OnKeyListener,OnContextMenuListener,以及OnSetOnFocusChangeListener等。但Android在使用设计模式时很简洁,并不过大地提供灵活性,这样可以保证性能,也可以减小出错的概率(基本上所有的设计复杂到难以理解的系统,可维护性远比简单易懂但设计粗糙的系统更差,因为大部分情况下人的智商也是有限的资源)。于是,从OnClickLister的角度,我们可以得到下图所示的对象结构。
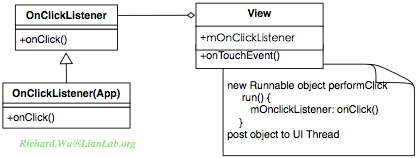
Click事件的触发源是Touch事件,而当前View的Touch事件在属于点击事件的情况下,会生成一个performClick的Runnable对象(可交由Thread对象来运行其run()回调方法)。在这个Runnable对象的run()方法里会调用注册过的OnClickListener对象的OnClick()方法,也就是图示中的mOnClickListener::onClick()。当这个对象被post()操作发送到主线程时(作为Message发送给UI线程的Hander进行处理),我们覆盖过的OnClick()回调方法就由主线程执行到了。
我们注册的Click处理,只有简单的一行,finish(),也就是通过点击事件,我们会将当前的Activity关闭掉。如果我们觉得这样不过瘾,我们也可通过这次点击触发另一个界面的执行,比如直接搜索这个字符串。这样的改动代码量很小,首先,我们需要在HelloWorld.java的头部引入所需要的Java包,
import android.app.SearchManager; import android.content.Intent; |
然后可以将我们的OnClick()方法改写成启动一个搜索的网页界面,查找这个字符串,而当前界面的Activity则退出。这时,我们新的OnClick()方法则会变成这个样子:
public void onClick(View v) {
Intent query = new Intent(Intent.ACTION_WEB_SEARCH);
query.putExtra(SearchManager.QUERY,
((TextView)v).getText());
startActivity(query);
finish();
} |
但是可能还是无法解决我们对于Android应用程序与Java环境的区别的疑问:
- Android有所谓的MVC,将代码与显示处理分享,但这并非是标准Java虚拟机环境做不到。一些J2EE的软件框架也有类似的特征
- AndroidManifest.xml与On*系列回调,这样的机制在JAVA ME也有,JAVA ME也是使用类似的机制来运行的,难道Android是JAVA ME的加强版?
- 至于Listener模式的使用,众所周知,Java是几乎所有高级设计模式的实验田,早就在使用Listener这样模式在处理输入处理。唯一不同的是ClickListener,难道Android也像是可爱的触摸版Ubuntu手机一样,只在是桌面Java界面的基础加入了触摸支持?
- Activity从目前的使用上看,不就是窗口(Window)吗?Android开发者本就有喜欢取些古怪名字的嗜好,是不是他们只是标新立异地取了个Activity的名字?
对于类似这样的疑问,则是从代码层面看不清楚了,我们得回归到Android的设计思想这一层面来分析,Android应用程序的执行环境是如何与众不同的。
不过,我们可以从最后的那行Activity调用另一个Activity的例子里看出一些端倪,在这次调用里,我们并没有显式地创建新的Activity,如果从代码直接去猜含义的话,我们只是发出了个执行某种操作的请求,而这个请求并没有指定有谁来完成。这就是Android编程思想的基础,一种全开放的“无界化”编程模型。
Android的系统设计,与别的智能手机操作系统有很大区别,甚至在以往的任何操作系统里,很难找到像Android这样进行全面地系统级创新的操作系统。从创新层面上来说,Android编程上的思想和支持这种应用程序运行环境的系统,这种理念本身就是一种大胆的创新。
整个Android系统,实际主要目的,就是打造一个功能共享的世界。
功能共享最重要的交互,于是Android创造出一种Intent和IntentFilter配合的低耦合的交互模型,Intent只是一种描述要完成什么工作跨进程的结构体,而最终如何解析这些Intent并完成其响应,是由IntentFilter来进行换算,最终是由用户来决定如何完成。
而在Intent这种超级交互消息之上,Android进一步把应用程序的实现逻辑拆分成多种特殊的实现:
- Activity:带显示与交互能力的部分
- Service:不带显示与交互能力的部分
- Content Provider:在功能交互之外,提供数据交互能力的部分
- Broadcast Receiver:用来处理广播交互的部分
这四种功能上的拆分,也体现了Android设计者在设计上抽象思绪能力,即便是随着Android迅猛发展,目前已经到了4.1这么功能丰富、用户体验良好的状态,我们编程也还是与这四种功能组件打交道,可以满足我们任何的编程时所需要的任何行为。
而这四种基本组件组成部分,使Android应用程序反倒成了一个“空壳子”。静态上看,应用程序只是一种包装这些功能的容器;从运行态来看,所谓的应用程序,也只是承载某些功能的进程。
1.1 所谓的Android应用程序
我们从前面的例子中看到,无论是编写的代码,还是最后生成的.apk文件,都是没有所谓的应用程序的。应用程序本身是一种虚无的概念,只是一种以zip格式进行压缩的一个文件,一种容器而已。
如我们前面的Helloworld的例子里所看到的那样,其实一个应用程序里最重要的一个配置文件就是AndroidManifest.xml文件。一个最简单的项目,除了基本的代码与UI资源,也会需要有个AndroidManifest.xml文件。甚至一些极端一点的例子,我们去市场上下载一些什么主题包、插件包、权限包之类的.apk文件,解压开,这时可以发现这样的.apk文件里,连代码都没有,只有一些图片之类的文件。
于是,我们可以得到Android里关于应用程序的第一个印象,作为Android应用程序的载体,.apk文件只是一种进行包装与传输的格式,而每个.apk文件必然包含一个AndroidManifest.xml文件,由这一文件来描述该.apk文件提供的内容。当然,我们在稍后会看到,这一文件里,还会包含一些权限控制的信息。
我们可以给我们的应用程序创建两个一模一样的图形界面,直接从我们的前面的HelloWorld开始下手,比如将HelloWorld.java在Eclipse里拷贝到HelloAgain.java(这样可以减少改代码的麻烦)。这时可以得到两个界面的应用程序,然后我们再把我们的AndoridManifest.xml文件,改成如下的样子:
<?xml version="1.0" encoding="utf-8"?>
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="org.lianlab.hello"
android:versionCode="1"
android:versionName="1.0">
<applicationandroid:label="@string/app_name">
<activity android:name=".Helloworld"
android:label="@string/app_name">
<intent-filter>
<action android:name="android.intent.action.MAIN"/>
<category android:name="android.intent.category.LAUNCHER"/>
</intent-filter>
</activity>
<activity android:name=".HelloAgain"
android:label="@string/app_name">
<intent-filter>
<action android:name="android.intent.action.MAIN"/>
<category android:name="android.intent.category.LAUNCHER"/>
</intent-filter>
</activity>
</application>
</manifest> |
这时我们编译、安装到Android设备(或者是虚拟机)里,这时再打开主界面查看安装过的应用程序,这时是不是发生了什么很奇怪的现象?这时界面上会出现两个叫Helloworld的应用程序。我们这时如果在设备里去“设置”à “应用程序”,我们仍只看到一个应用程序。
通过对AndroidManifest.xml的小恶作剧,我们可以看到Android应用程序的第二个特点,就是没有所谓的主入口(即我们点击的图标时触发的执行效果)。应用程序在安装完成后,只是通过AndroidManifest.xml来决定在系统上应该表现成什么样子。
如果希望应用程序可以表现不如此变态,这时,我们可以回到AndroidManifest.xml里,把<activityandroid:name=".HelloAgain"…这个标签里的<intent-filter>标签删掉,这时应用程序的表现就正常了。
到目前为止,我们就已经接触了android编程里的两个概念,一个是Activity,另一个是Intent(而我们AndroidManifest.xml文件里的Intent Filter实际是辅助Intent的)。Android毕竟是种图形界面的编程环境,我们常见的应用程序里,可能绝大部分只会与这两种概念打交道。而两者的概念组合,就很容易体现出Android应用程序在编程上的“无界化”思想。
1.2 Android世界里的共享
作为一个智能手机操作系统,其用户可能在功能上有各种各样的功能组合。比如最简单的打电话,则后续动作会有保存联系人,同时需要给联系人拍照做来电大头贴。又比如需要来了个短信通信用户到某个地方干什么事情,这时,用户需要打开地图,搜索一下地址,然后还有可能需要定位到那个位置。

用户在主界面里点击相应功能的应用程序之后,就可能有非常多的功能性的组合,因为用户的想法是不可预估的。我们当然也可以限制用户当前菜单下可以干什么事情,但这样就失去了智能系统的意义。
我们也可以假设用户都会按一个“Home”键回到主界面,这时原来的执行的程序就会被锁定当前状态,用户重新打开另外一个应用程序,操作完再按“Home”键可以退回到原来的应用程序。通过这种“应用程序”到“Home”到“应用程序”的循环,我们也可以达到我们想要达到的目的。但这时,出于交互性的考虑,我们也还是需要有限地提供一些交互手段,比如“短信”应用程序里包含地址信息,一点击可以直接打开“地图”进行后续操作,但这些有限交互是可以在系统设计阶段被固化。这时,我们是不是就得到了我们想要的能够应付用户任何操作组合的系统?是的,恭喜您,您得到了iPhone的设计思路。但此时的用户交互流程则被改变成这个样子:
这种解决问题的办法也不是不可以,但需要很固化的设计,应用程序的行为比较受限。虽然通过横扫全世界的iPhone证明了这样的设计可能是比较合乎用户体验之道的(不容易出错),但这样的解决思路从系统设计角度来看,并不是很灵活。另外一个麻烦是必须要有苹果级设计功底的“Home”键,山寨货则用不了多久就会因为键盘失灵而失效。当然即使苹果级设计,iPhone里的“Home”键还是会失效,于是又不得不在屏幕上加上触摸的Home手势。
作为开源系统的Android,当然不可能基于iOS的交互思路来解决问题,何这种交互时多了一步不停要回到主界面这一步。在Android的设计里,最重要的是能够解决一个应用程序之间进行交互的问题,然后可以实现我们想要在Android系统里完成某种操作时,可以享受从一路顺畅完成的快感。
Android的解决之道,则是将传统意义上的应用程序,细化成一个个完成某项功能的部分,这种功能部分,在Android世界里被称为Activity。Activity都应该被设计成可以独立地被执行以解决某个问题,当它完成或是用户选择退出执行时,又会自动跳回到调用这一Activity的界面,当然这时跳回的位置肯定是另外一个Activity。当然,在一个Android系统里有可能存在无限多的Activity,在他们进行跳转切换时,我们就需要一种很灵活的消息传输机制(因为我们必须兼容系统里所有可能的互相调用的情况)。而且这种传输机制还必须能够跨进程,不然,我们所有的涉及Activity互相调用部分都必须在同一进程里完成。于是,Android系统里又有了Intent,用于解决交互通信。
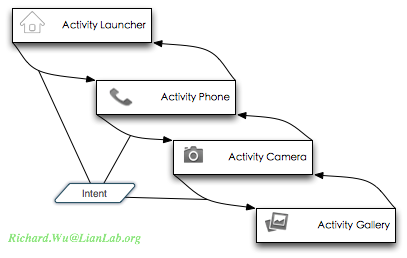
这样的编程模型也需要有一定前提,那就是我们Application概念必须被弱化,我们不能有main函数入口(如果系统执行依赖main作入口,则不能实现Activity之间互相调用了,所有的Activity执行之前,必须先通过main入口来初始化环境)。出于这样的设计,所以Application必须只是一个容器,将各种不同的Activity实现包装起来加载到系统里。
当然,将功能拆分成一个个的单一功能界面之后,我们需要有种机制可以将用户一路点击过去历史记录下来,当用户处理完时,可以退回到他们之前操作过的界面,这次就可以由多个应用程序组合出像是在用同一个应用程序的效果。有了Activity,有了Activity之间起到调用作用的Intent,这时所有界面间操作变得有点像是函数调用一样,于是我们可以找函数调用时的基本数据结构—栈来帮忙,发生调用时,需要退出的Activity及其状态压栈,当从调用退出时则进行栈的弹出操作,这时我们的Activity管理就演变成如下图所示的简单栈管理。
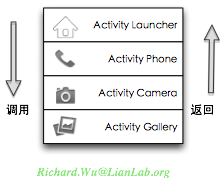
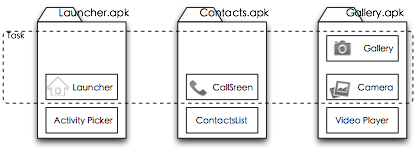
有了这样的概念,于是我们响应用户点击操作的问题便迎刃而解,我们在设计应用程序时,不再是设计一个复杂的功能实现,而是实现一组完成单项功能的实现,也就是Activity。然后这些Activity,只会通过用户点击来驱动它们之间是如何进行交互的。比如,我们前面看到的地图、搜索、定位三个功能,虽然它都会被包装到同一个地图的应用程序里,但在实现上会是地图、搜索、定位三个不同的Activity。
因为现在我们的界面上的互相调用,已经变成了一种函数式的调用,这样,整个手机上的功能都被切分成各个单一的小功能,而真正要在Android系统上完整地实现某复杂个操作,则会提交由用户的点击来组合生成。这样的复杂功能,则已经不是一个编程上的概念了,在Android系统里,这种需要完成什么事情的操作被抽象成一个虚拟的概念Task。比如我们前面提到的打电话加拍大头贴的操作组合,就构成一个Task,这一Task需要由Launcher.apk,Contacts.apk,Gallery.apk来协同完成
如果我们有两个能够提供同样功能的Activity,这种执行模式的灵活性表现得会更加明显。比如中间打电话的功能,我们系统里有三个Activit(CallScreen, SipPhone, Dialer)都可以完成电话呼叫的功能,这时执行上的路径则会有三种可能性,会在进行跳转时弹出圣对话框由用户来选择:
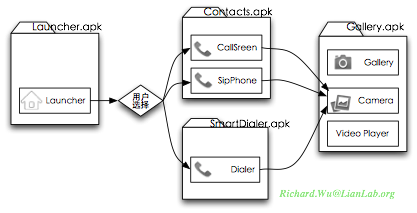
通过Activity的这种可以动态被用户选择的特点,当用户对某一功能不满意时,完全就有可能通过下载另一个能实现这种功能的应用程序进行替换,甚至可以自己写一个。事实上,Android系统里除了系统状态条与锁屏界面之后,没有任何的不可被替换的功能,这也是Android设备总是会长得千奇百怪的原因之一。
到这时,我们就可以看到Activity之所以会不被称为Window的原因,它也是单个界面或是MVC里的Controller实现部分那么简单,Activity这个名字代表的是某种单一交互功能上的实现。这种功能的实现将在系统里通过Intent串接起来,构成了一个在功能上具备极大可拓展性的系统。基于这样的特点,Android也就被称作是“无边界”系统,因为它在功能上延展不再受限于系统的能力,而只受限于智商与创意。
这就是Android世界里的功能共享。
在这种功能共享模型之下,可能还是会有一些微调的需求:
1. 我们有一些情况下不宜使用这种栈式Activity管理,比如我们写一个需要注册的应用程序,注册完开始使用,然后再按退出,我们又会一步步退回到注册填个人信息的界面,而不合理地完全退出。这样可能不合适。这时,我们可以使用Intent的Flag参数, 加上Activity的Affinity属性进行组合控制。
2. 如果不停地跳出对话框让用户选,用户会崩溃掉。当然,用户可以在选择时点选一个“始终”的默认选择,这时下次就会使用默认的Activity处理某种操作。但还是有可能会不合理地使用跨.apk文件里使用Activity,造成性能上的开销,这时,我们也可以在执行下次Activity执行操作时进行强制性地指定。
当然,我们通过Activity这种概念还需要另外一个前提,这就是Android会有别于传统操作系统的前提,那就是单窗口。想像一下,在多窗口环境下,我们的栈式管理Activity在进行跳转和返回时将会构成多大的灾难啊。好在使用电容屏的设备,单窗口是天生的需求。由于手指触摸的精度非常低,无法点准过小的按钮,比如窗口上的关闭按钮,如果将这些按钮放大,又造成了屏幕显示空间上的浪费。iPhone带来的“后PC时代”革命,最重要的一点就是使用“返祖”式的单窗口显示。
这种怪异的操作方式,实际上在我们生活中也有类似的例子,就比如说我们的动态网页。动态网页,特别是HTML5构建的网络应用程序,其操作模式,就是可以在不同的链接里不断地点击下去,如果不是弹出新窗口,我们始终还可以退回到发起这一连串点击的起始页面。Android应用程序,XML构成的UI语言的作用跟Html页面类似,而Java构建的Activity就相当与网页交互中使用的JavaScript,有了这样的相似性,Android编程环境可以说是最接近HTML5的一种编程环境了,但可惜不能像HTML5那样可以跨平台。
我们解析了能完成单一功能的Activty,这时还需要了解Intent,就像是我们了解过了函数实现原理,我们还需要掌握函数之间的参数传递。当然,一般在介绍编程的思路里,会结合起来说明,或是先说明参数传递。但Android环境里有点特殊性,一是Intent是一种能够实现跨进程调用的信息传递机制,二是Intent在消息传递上又很灵活,有一定的动态性。Intent不光服务于Activity之间的调用,还会用于一些不直接与界面打交道的逻辑实现部分,比如我们后面将提到的Service,Broadcast Receiver,以及 Notification。
1.3 Intent与Intent Filter
Intent,英文原意就是要“干什么”的意思,之所以取这个名字,也是因为在Android系统里,Intent所起到的作用就是用来指明下一步具体是做什么,具体是不是执行,由谁来执行,则会由根据当前的系统状态(能不能解析这个Intent请求)来决定。这不只是简简单单地发个消息而已,而是一种更安全的、更加松散的消息机制。
在一个Intent消息对象里,共有六个成员(并不都是必须赋值的,只要一个Intent对象能够被解析,就会得以执行,否则就会会被舍弃):
| 成员 | 类型 | 说明 | 示例 |
| ComponentName | String | 用于定义谁将处理这一Intent。它由一个Activity的具体实现的全名(加上包名)来指定 | org.lianlab.hello.HelloActivity |
| Action | String | 用于定义这一动作是做什么,可以被拓展自定义类型 | ACTION_CALL 开始通话. ACTION_EDIT 进行编辑. |
| Data | String | 用一个URI来指定Intent的操作对象,因为URI一般会包含种类信息,于是这个值也可能被用作MIME设别。 | “content://contacts/people/1” 指定联系列表中的第一个 |
| Category | String | 用来进一步明确什么样的可执行实体将处理这一Intent。是可选项,也可多选。 | CATEGORY_HOME 主界面应用程序 CATEGORY_LAUNCHER 可在主界面里被点击 |
| Type | String | 用来指定特定的MIME类型 | "video/*" 视频 |
| Extra | Bundle | 用来传递额外的数据传递,前面我们也介绍了Bundle是一种key:value配对的字典类型,于是Extra里可以转递复杂的数据 | putExtra("sms_body", "some text"); 发短信时指定内容 |
Flags | int | 预定义一系列用来控制Intent行为的属性值 |
在这个成员变量里,最能体现灵活性的就是Component,如果指定了这个值,则我们在通过startActivity()方法来发送Intent时,就会自动启动Component指定的Activity。如果没有指定,则会由系统来选择一个能够处理这一Intent的Activity来执行,这时就引入了Intent Filter的概念。
Intent Filter在Android里是一种类似于Windows里的注册表一样的东西,虽然我们也可以通过编程来进行Intent Filter的控制,但一般情况下,我们只在AndroidManifest.xml文件里进行定义,对它一个<intent-filter>的标签进行指定。应用程序在安装过程中,它的AndroidManifest.xml会被系统扫描并汇总到系统环境里,这时<intent-filter>也会被导入。当Activity发送出来的Intent,没有指定Component时,系统就会通过<intent-filter>找到合适的处理对象,如果只有一个或是用户设置了默认项,则启动这个功能部件来完成任务;如果有多个<intent-filter>匹配同时用户又没有指定默认项,则会弹出对话框让用户选择。当然,默认项也会随着系统里新增了同一Intent匹配项而失效,用户也可以通过“设置”à “应用程序”来取消默认值。
在AndroidManifest.xml里面定义<intent-filter>很简单,就是通过指定Intent对象的Action,Data,Type,和Category这四个成员变量来指定。比如:
<activityandroid:name=".PlayerActivity"android:label="@string/app_name"
android:configChanges="orientation" >
<intent-filter>
<actionandroid:name="android.intent.action.MAIN" />
<categoryandroid:name="android.intent.category.LAUNCHER" />
</intent-filter>
<intent-filter>
<actionandroid:name="android.intent.action.VIEW" />
<categoryandroid:name="android.intent.category.DEFAULT" />
<dataandroid:scheme="file" />
</intent-filter>
...
</activity> |
当我们的某个Activity,发送了一个Intent,其Action是”android.intent.action.VIEW”,data又是以file:///开始的URI指定的内容(也就是文件类型),这时上面例子里的PlayerActivity就会成为播放时的候选项。
我们可以继续修改我们前面的HelloWorld的例子,我们新建一个Intent,将Action设成”android.intent.action.VIEW”(可以通过Intent.ACTION_VIEW这个预变量来转义),data使用某个文件“file:///sd-ext/Movies/test.mp4”,这时就会匹配到我们上面的<intent-filter>定义:
public void onClick(Viewv) {
Intent request = new Intent(Intent.ACTION_VIEW);
request.putData(“file:///sd-ext/Movies/test.mp4”);
startActivity(request);
finish();
} |
当然,我们并不一定需要代码来进行这样的测试,我们也可以使用设备上的am命令来完成。要完成与上面的点击操作一样的功能,也可以通过adb来执行这条命令:
$adb shell am start –aandroid.intent.action.VIEW –d file:///sd-ext/Movies/test.mp4
在我们具体写代码过程中,我们可以根据需求来定义我们所需要的<intent-filter>,可以将过滤规则写得很细,也可以写得很粗,让我们的Activity有更多地被执行到的机会。在这些规则里,可能最重要的规则,就是我们前面也示范过的:
<action android:name="android.intent.action.MAIN" /> <category android:name="android.intent.category.LAUNCHER" /> |
这两行<intent-filter>规则,将使用我们的应用程序可以被主界面所收集,使用户可以在主界面里点击运行这个Activity。
有了Activity,我们就可以构建基于功能共享而实现所谓应用程序,而有了Intent,使用我们在共享时所受的限制可以变得更小。而且,由于是简单化的单窗口模式,再加上一些在性能设计上的精细设计,于是我们的Android系统便有了良好的人机交互体验。
1.4 编程角度的应用程序
光有Activity与Intent,并不是Android应用程序编程时的全部。应用程序除了有人机交互界面之外,有可能还需要使用到一些不直接与人交互而在后台长期运行操作;我们还需要有某种机制,能够提供数据共享,并且在数据共享时能使用统一的访问机制;最后,我们可能还需要处理以广播方式发送的消息,广播与Intent不同之处在于一到多的方式传播,同时消息只在某个时间段内有效。
事实上,我们的Android编程,是被包装成四个不同的类型,同时通过Intent将这些类包装起来,以解决我们上面提到的,在编写图形应用程序里可能遇到的问题的:
- Intent: 全局性的、松散的消息传递机制
- Activity:带图形界面的,可以与用户进行交互的逻辑实现。
- Service: 不带图形界面的,不直接与用户交互的代码。一般会被用于在后台做些什么事情,比如监听网络、下载、拷贝文件等。(这可能是一般的Android工程师觉得没有必要实现的部分,笔者在讲解Android应用程序相关的课程时,就常有问及,Actiivity会进入到后台,然后有可能被杀死掉,这样的问题如何解决?实际上Activity只解决交互,需要在后台时还需要继续执行的代码,需要用Service来实现。只自己可访问的Service,可以使用简单的本地Service,而需要提供给别的进程来访问的情况下,我们需要通过AIDL编写Remote Service。Service的实现,我们在后台再详细说明,因为Android系统的核心Framework,本身就是由大量这样的Remove Service来组成的。)
- Content Provider: 提供数据层共享,以CRUD(Create Read Update Delete)方式进行数据访问来统一化数据读写指口一种模型。如果使用了Sqlite做后台的数据支持(实际上相当于应用程序MVC模型里的Model部分被Sqlite延展开来),我们可以通过ContentProvider来各系统内的其他部分提供数据源,当然系统本身也给我们提供了大量这样的ContentProvider,像Setting里的设置的值、联系列表、多媒体文件扫描结果等。(这种数据层上的共享机制,也是应用程序编程上需要加强的技巧之一,因为有了Content Provider,我们则有可能使用Cursor式进行访问,这时我们就可以使用CursorAdapter来自动化地处理数据源。)
- Broadcast Receiver:处理广播类消息的监听器,从而可以给应用程序提供广播式的信息处理,同时也提供系统消息的广播式分发。比如,Android会将一些系统事件广播出来,像电话振铃、电量状态变化、网络状态变化等,我们需要能够处理这样的事件,电话振铃时我们写的多媒体播放器就应该静音、电量过低时需要保存状态等。对我们应用程序而言,广播方式也是一种很好的通信机制,我们不需要写一个循环通知所有的Activity、Service我们状态发生了改变,而只需要发一个广播,则所有关心这一事件的部分都可以收到。
这些功能实体,都是我们通过Java代码根据不同的基类(Service、 ContentProvider、BroadcastReceiver)派生出相应的子类,再加以具体实现。这样的功能实现不需要自己去创建这个对象,会通过AndroidManifest.xml里的定义,由系统按执行的需要自动创建。有了这些不同的功能实体,我们最后的应用程序,实际上就成了这个样子:
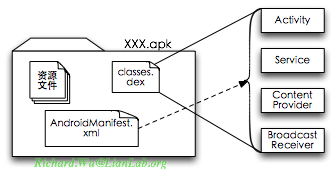
而我们的所有代码,从运行态行为来看,都不再是直接的互相调用关系,而是全部都通过Intent来进行彼此之间的交互。而这样的交互,也不再是传统式地自己陪自己玩,而是会进入到一个大的功能集合体时,提供功能给系统内其他应用程序所使用,而自己也会调用其他部分的代码。

当然,随着Android版本变更,Android系统又新增了一些新的概念,比如针对多窗口功能的Fragment、针对于使用异步机制操作Cursor的Loader等。但万变不离其宗,这些Android的核心原理则一直如此。
总结一下Android编程思想,我们就会知道其实在Android整个生态环境最重要的元素,应用程序,反倒是Android编程上最不重要的。所谓的Android编程,就是要通过编写一个个的Activity、Service、Content Provider、Broadcast Receiver实现,通过功能上的共享与数据上的共享进一步丰富用户可用的功能。当用户可以通过Market或自己下载取得我们封装到.apk文件里的实现之后,这些功能就会无缝地被Intent整合到了一起。
从Android这个编程原则来看,我们可以看到,如果我们使用某种Java执行环境,将Android应用程序的这些组成部分的支持都加入进来,我们也可以得到一个Android兼容的环境。的确如此,已经有人在打这方面的主意,有将Android环境移植到Windows环境里的BlueStack商业解决方案,也有号称兼容Android应用程序,通过一个类似于JAVA ME的虚拟机环境来支持Android应用程序的BlackBerryOS。但我们可以再来看看Android的真正的支持环境,我们可以看到,Android有其独特的特性,也不是那么容易被取代
我们接下来从安全性,性能,功能,可移植性的角度分别分析Android系统为应用程序提供的支撑。
1. 支撑应用程序的Android系统
分析一个系统的构成,可以有多个出发点。从不同出发点,我们可从不同侧面分析这个系统的设计,以及为什么要这样设计:
- 从系统结构出发,Android系统给我们的感觉就是一种简洁的,分层式的构架实现,从这种分层式的构架实现角度,我们可以理解这个系统是如何被组织到一起。
- 从系统的运行态角度出发,我们又可以从Android的整个启动过程里做了哪些工作,系统是由哪些运行态的组成部分来构造起来的。
- 从源代码的结构出发,我们可以通过Android的源代码,来分析Android系统具体实现。设计最终都会落实到代码,通过代码,我们可以逆向地看出来这个系统是如何构建起来的。
这种不同的分析角度,通常也包含着不同的用意,一般是在Android开发里从事不同的方向所导向的最方便的一种选择。比如,作为底层移植者而言,大部分都是BSP(Board Support Package)工程师的工作,比较接近硬件底层,一般就会暴力一点,从Linux启动开始分析,得到运行态的Android系统概念。作为高级的软件设计师,看这个系统,可能更多的会是从系统结构出发,来了解这一系统设计上的技巧与原理。而更多的学习者或是爱好者,则会是直接从源代码来着手,一行行代码跟,最后也会理解到Android的系统的构架。
我们前面粗浅地介绍了Android的编程,并非只是浪费篇张,而是作为我们这里独特的分析角度的一种铺垫。我们的角度,由会先看应用程序,然后回过头来再分析Android系统是如何支持应用程序运行的,如何通过精巧设计来完成基于功能来共享的Android系统的。这种角度可能更接近逆向工程,但这时我们也能了解到Android系统构架的各种组织部分,而且更容易理解为什么Android系统,会是这样看上去有点怪的样子。
作为Android这样的系统,或者是任何的智能手持设备上的操作系统,其实最大挑战并非功能有多好、性能有多好,而首先面临是安全性问题。桌面操作系统、服务器操作系统,在设计上的本质都是要尽可能提供一种多人共享化的系统,而所谓的智能手机操作系统,包含了个人的隐私信息,需要在保护这些隐私信息条件下来提供尽可能多的功能,这对安全性要求是一个很大的挑战。特别像Android这样,设计思路本就是用户会随时随地地下载更多应用程序到系统里,相当于是添加了更多功能到系统里,这时就必须解决安全性问题。
以安全性角度出发,Android必然会引入一些特殊的设计,而这些设计带来的一个直接后果就是会带来一些连锁性的设计上的难题:即要保持足够的性能、同时又要控制功耗;即要功能丰富,同时又需要灵活的权限控制;需要尽可能实现简单,但同时又需要提供灵活性。所有这些后续问题的解决,就构成了我们的Android系统。
1.1 Android应用程序运行环境所带来的需求
我们在实现类似于Android应用程序的支撑环境时,必然会遇到一些比较棘手的问题,当我们能够解决这些问题时,我们就得到了我们想要的Android系统。这类问题有:
- 安全性:作为一个功能可灵活拓展的系统,都将面临安全性的挑战。特别是Android又是一个开源操作系统,它不能像iOS那样保持封闭来保持一定的安全性,又不能过于严格地限制开发者自由来达到安全性目的的,而且由于是嵌入式设备,还不能过于复杂,复杂则执行效率不够。于是,安全性是Android这套运行机制最大的挑战。
- 性能:如果Android系统仅仅只是能够提供桌面上的Java Applet,或是老式手机上的JAVA ME那样的性能,则Android系统则会毫无吸引力。而我们的安全性设计,总会带来一定的性能上的开销,这时可能会导致Android系统的表现还不如标准的Java环境。
- 跨进程交互:因为有了Intent与Activity,我们的系统可能随时随地都在交互,而且会是跨进程的交互,我们需要了解Android里独特的进程间通信的方式。
- 功耗控制:所有使用电池供电的设备,都天生地有强烈的功耗控制的需求。随着处理器的能力加强,这时功耗会变得得更大,提供合理的功耗控制是一种天生地需求。
- 功能:如前面所说,我们提供了安全性系统,又不能限制应用程序在使用上的需求,我们应该尽可能多地提供系统里有的硬件资源,系统能够提供的软件层功能。
- 可移植性:作为一个开源的野心勃勃的智能手机操作系统,Android必须在可移植性上,甚至是跨平台上都要表现良好。只有这样,才会有更多厂商乐意生产Android设备,开发者会提供更多应用程序,从而像今天这样形成良性循环的Android生态环境。
我们再来针对这些应用程序所必须解决的问题,一个个地看Android是如何解决的。
1.2 安全性设计
安全性是软件系统永恒的主题,其紧迫程度与功能的可拓展性成正比。越是可以灵活拓展的系统,越是需要一种强大的安全控制机制。世界上最安全的系统,就是一坨废铁,因为永远不可能有新功能加入,于是绝对安全。如果我们可以在其上编写程序,则需要提供一定程度的安全控制,这时程序有好有坏,也有可能出错。如果我们的软件,会通过互联网这样的渠道可以获得,则这种安全上需求会更强烈,因为各种各样的邪恶用意都有可能存在。大体上说,安全性控制会有四种需求:
- 应用程序绝对不能对系统造成破坏。作为一个系统,它的首要目标当然是共享给运行于其上的应用程序以各种系统级的功能。但如果这些应用程序,如果可以通过某种渠道对这个共享的系统造成破坏,这样的系统去运行程序就没有意义,因为这时系统过于脆弱。
- 应用程序之间,最好不能互相干扰。如果我们的应用程序,互相之间可以破坏对方的数据,则也不会有很好的可用性,因为这时单个的应用程序也还是脆弱的。
- 应用程序与系统,应用程序之间,应该提供共享的能力。在安全性机制下,我们也还是需要提供手段,让应用程序与系统层之间、应用程序之间可以交互。
- 还需要权限控制。我们可以通过权限来保护系统,一些非法的代码在没有权限的情况就无法造成破坏。在给不同应用程序提供系统层功能、提供共享时,应用程序有权限才能执行,没有权限则会拒绝应用程序的访问。
解决这类安全性需求的办法,有繁有简,像Android这样追求简洁,当然会使更简洁的方案,同时这套方案得非常可靠。于是Android的运行模型就参考了久经40年考验的单内核操作系统的安全模型。
为了解释得更清楚一点,我们先来从单内核操作系统开始说起。
在计算机开始出现的原始时期,我们的计算机是没有所谓操作系统的。即使是我们的PC,也是由DOS开始,这样的所谓操作系统,实际上也只是把一些常用的库封闭起来,可以支持一个字符的操作界面,运行完一个任务会退回到操作界面,然后才能再运行下一个。这样的操作系统性能不高,在做一些耗时操作则必须等待。

于是,大家又给CPU的中断控制入手,一些固定的中断源(比如时钟中断)会打断CPU操作而强制让CPU进入一段中断处理代码,在这种中断处理代码里加入一些代码跳转执行的逻辑,就允许代码可以有多种执行序列。这样的代码序列被抽象成任务,而这种修改过的中断处理代码则被称为调度器,这样得到的操作系统就叫多任务操作系统,因为这些操作系统上运行的代码像是有多个任务在并行一样。

这种模型实现简单,同时所谓的任务调度只是一次代码跳转,开销也小,实际上我们今天也在广泛地用它,比如大部分的实时操作系统。但在这种模式里有个很致命的缺陷,就是任务间的内存是共享的,这就跟我们想达到的安全性机制不符,应用程序会有可能互相破坏。这是目前大家在实时操作系统做开发的一个通病,90%的比较有历史的实时系统里,大量使用全局变量(因为内存是可以共享访问的),几乎到了无法维护的程度了。大部分情况下,决定代码质量的,并非框架设计,而是写代码的人。当系统允许犯使用全局变量的错误,大家就会隔三差五的因为不小心使用到,而累积到最后,就会是一大坨无法再维护的全局变量。
于是,在改进的操作系统里,不但让每个任务有独立的代码执行序列,同时也给它们虚拟出来独立的内存空间。这时,系统里的每个任务执行的时候,它自己会以为整个世界里只有它存在,于是很开心地执行,想怎么玩就怎么玩,就算把自己玩挂掉,对系统里的其他执行的任务完全没有影响,因为这时每个任务所用的内存都是虚拟出来互相独立的空间。当然,此时还会有一些共享的需求,比如访问硬件,访问一些所有任务都共享的数据,还有可能需要多个任务之间进行通信。这时,就再设立一种特权模式,在这种模式里则使用同一份内存,来完成这种共享的需求。任务要使用这种模式,必须通过一层特殊的系统调用来进入。在Unix系列的操作系统里,我们这里的任务(task)被称为进程,给每个进程分配的独立的内存区域,被称为用户空间,而进程间特权模式下共享的那段空间,被称为内核空间。

特权模式里的代码经过精心设计,确保执行时不出错,这时就完善了我们前面提到的安全性模型。
有了多任务的支持后,特别是历史上计算机曾经极度昂贵,这时大家觉得只一个人占着使用,有了多任务也很浪费,希望可以让多人共享使用。这时,每个可以使用计算机的人,都分配一个标签,可以在操作系统里通过这个系统认可的标签来运行任务。这时因为所执行的任务都互相独立的,加入标签之后,这些任务在执行时也以不同标签为标识,这样就可以根据标签来进行权限的判断,比如用户创建的文件可以允许其他人操作,也可以不允许其他人操作。这种标签通常只是一个整形值,被称为用户ID(User ID,简称uid)。而用户ID在权限上会有一定的共性,可以被组织成群组,比如所有人是一个群组、负责服务器维护的是一个群组等等。于是可以在用户ID基础上进一步得一个群组ID(Group ID,简称gid)的概念,用于有组织的共享。每个世界都需要超人,有了多用户的操作系统,都必须要有一个超人可以求我们于水火,于是在uid/gid体系里,就把uid与gid都为0的用户作为超人,可以完成系统内任何操作,这一用户也一般称为root。
基于调度器与内存空间独立的设计,使我们得到了安全的多任务支持;而基于uid/gid的权限控制,使我们得到了多用户支持。支持多用户与多任务的操作系统,则是Unix系统。我们的Linux内核也属于Unix系统的一种变种。在4、5年前,我们谈及代码时总是会说Unix/Linux系统的什么什么。除了性能上和功能上的细致差异,Linux与其他Unix系统几乎没有区别(当然实现上差异很大)。只不过近年来Linux的表现实在太过威猛,以至于于我们每次不单独把Linux提出来讲,就显得我们没有表现出来滔滔江水般的崇拜之情。
等一下,难道我们这是在普及操作系统的基础知识?
稍安勿躁,我们的这些操作系统知识在Android环境还是很有帮助的。Android系统是借用的Linux内核,于是这个原则性的东西是有效的。而更重要的是,Android的应用程序管理模型,与Unix系统进程模型有极大的相似性,更容易说明问题。
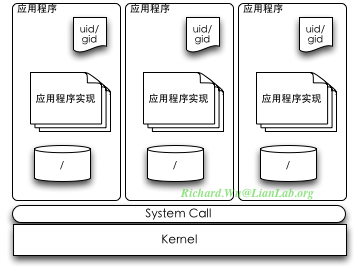
首先,我们的应用程序,不是需要一种安全的执行环境吗?这时,Linux的进程就提供了良好的支持。假如所有的应用程序,都会以非root的uid权限运行(这时就应用程序就不会有权限去破坏系统级功能),又拥有各自独立的进程空间,还可以通过系统调用来进行共享,这时,我们的安全性需求基本上就得到满足了。当然,这时的Android系统,在构架上跟普通的嵌入式Linux方案没有任何区别。
然后,我们再来看uid/gid。在传统的服务器环境里,Linux系统里的uid/gid是一把利器,可以让成千上万的用户登录到上面,共享这台机器上的服务,因为它本就是服务器。即便是我们的PC(个人计算机),我们也有可能使用uid来使多个人可以安全地共享这台机器。但是,放到嵌入式平台,试想一下,咱们的手机,会不会也有多人共享使用?这是不可能的,手机是个私人性的设备。于是,uid在手机上便是废物了。
而传统Linux运行环境里的另外一个问题是共享,作为环境,是提供尽可能友好的环境,让用户可以共享这台机器上的资源。比如文件系统,每个用户共享机器里的一切文件系统,除了唯一个私人目录环境/home之外,所有用户都可以共享一切文件环境。而无论是PC还是服务器,并不完全控制应用的访问环境的,比如应用程序都是想上网就上网。这些在一个更私人化的嵌入式执行环境里则会是灾难性地,想像一下您的手机,您下载的应用程序,想上网就上网,想打电话就打电话,所有的隐私信息,就泄露得一干二净了。
在纯正Linux环境里做嵌入式系统,我们就面临了更精细的权限控制的问题,需要通过权限来限制使用系统里的资源的共享。我们也可以使用很复杂的方案,Linux本身完全是可以提供军用级安全能力的,有selinux这个几乎可以控制一切的方案。但这样的方案实现起来很复杂,而且我们需要考虑到传统Linux环境是需要一个管理员的,如果我们提供一套智能手机方案,同时还要为这台手机配置一个Linux系统管理员,这就太搞笑了。
在Android的设计里,既然面临这样的挑战,于是系统就采取了一种简单有效的方案,这种方案就是基于uid/gid的“沙盒”(Sandbox)。既然uid/gid在嵌入式系统里是个废物,于是我们可以进行废物利用。应用程序在安装到系统里时,则给每个机程都分配一个独立的uid,如果有共享的需求,则给需要共享的应用程序分配同样的gid,应用程序在执行时,我们都使用这种uid/gid来执行应用程序,则可以根据uid/gid来控制应用程序的能力。应用程序被安装到系统后,它就不再使用完整的根目录,只给它一个特定目录作为它的根目录,每个应用程序的根目录,不再是系统的/目录,也是每个应用程序都不一样的。让每个应用程序使用不同根目录环境,技术上倒不复杂,我们Linux上很多交叉编译工具都是这样方式运行的,这样可以让编译环境完全与主机环境隔离,不会因为主机环境里提供的库文件或是头文件而造成编译成功,但无法运行。
同时,当应用程序发生系统级请求时,都会根据uid/gid来决定它有什么权限,有怎么样的权限。
这样的模型就更加符合手机平台的需求了,应用程序都以独立的进程执行,这时应用程序无论写得多糟糕多邪恶,它只能进行自残,而不能破坏其他应用程序的执行环境。而它们的文件系统都是互相隔离的,则这种文件系统上有可能互相破坏的潜在风险也被解决掉了。这时,我们只需要通过一层库文件,或是在内核里加一层机制可以让所有系统功能的使用都需要经过uid/gid进行权限控制就可以了。
这时,造成的另一个问题是,如果是使用这样的沙盒模型,则库文件与资源,每个进程的私有空间里都需要一份。另外,加入权限验证到库文件里,或是到内核里,都不是软件工程上的合理选择:库文件的方式,需要引入一层权限验证到每个应用程序,在通用性上会带来挑战;而修改Linux内核,则是下下策,核心组件是最不应该改动的,有可能影响内核的正常工作,也可能造成Android对内核的依赖,如果哪天我们不想使用Linux内核了怎么办?
假如,我们把Android核心层的功能,抽出来做成一个独立的进程,这些就迎刃而解了。这个(或是可有多个)核心进程,运行在设备真实的根目录(/)环境里,也会有高于用户态的权限。这时,应用程序可以使用一个最小化的根目录,只需要应用程序执行所需要最基本环境,而对系统级的请求,这些应用程序都可以发出请求到核心进程来完成。这时,我们就可以在核心进程里进行权限控制了。
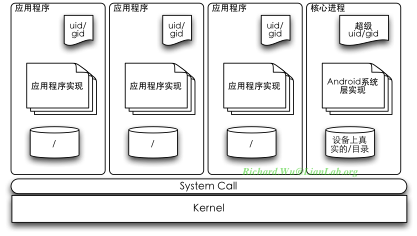
这样,是不是就完美了?首先这种设计没有依赖性,如果我们哪天把Linux内核干掉,换用FreeBSD或是iOS使用的Darwin内核,这种设计也将是有效的(也就是我们有可能在iOS系统里兼容Android应用程序)。而跟我们Unix的进程实现模型作对比的话,是不是有点熟悉?我们可以将应用程序视为进程,核心进程视为内核层,它们之类的通讯方式,则是用户态发生的一层System Call层。是的,这时,我们相当于在用户态环境又抽象出一套操作系统层。
但是,这跟我们前面介绍的Android环境好像是对不上号,我们的Android应用程序不是Java写的吗?这是安全性设计里更高一级的方案,Java是一种基于虚拟机解析运行的环境,也常被称为托管环境(Hosted),因为需要执行的逻辑并不直接与机器打交道,于是更安全。可惜的是,我们的Android系统从2.3之后,就可以使用一种叫Native Activity的逻辑实体,可以使用C++代码来写应用程序(主要用于编写游戏),这会一定程度上影响到这种托管机制带来的安全性。但问题并不是很严重,我们在后面的内容会看到,实际上,Native Activity最终还是需要通过JNI调用,才能访问到Android里的系统功能,因为这部分是由Java来实现的。
我们再来看看,真实的使用Java的Android系统。
从Java诞生之日起,就给予开发者无限的期望,这种语言天生具备的各种特点,曾在一段时间里被认为可以取代其他任何编程语言。
- 跨平台。Java是一种翻译型语言,则具备了“编写一次,到处运行”的能力,天生可以跨平台。
- 纯面向对象。Java语言是一种高级语言,是完全面向对象的语言,不能使用指针、机器指令等底层技术,同时还带自动垃圾回收机制,这样可以使用代码更健壮,编程更容易。
- 重用性。由于纯面向对象,Java语言的重用性很高,绝大部分源代码几乎不需要修改就可以直接使用。由于Java语言的易用性,很多开发的原型系统,都基于Java开发,几乎所有的设计模式都在Java环境里先实现。更因为Java的历史悠久,这种编程资源的积累,使它的重用性优势更加明显。
- 安全的虚拟机。Java是基于虚拟机环境,虚拟机环境实际上是一种通过程序模拟出来的机器执行环境,更安全。所谓执行的代码,只是程序所能理解的一种伪代码,而且代码代码执行的最坏情况,也就仅能破坏虚拟机环境,完全影响不到运行的实际机器。Java虚拟机这样的执行环境,一般被称为托管(Hosted)编程环境,可以进一步将执行代码的潜在破坏能力限制到一个进程范围内,就是像PC上的虚拟机,再怎么威猛的病毒,最多也只是破坏了虚拟机的执行程序,完全影响不到实际的机器,像.Net,Java等都有这样的加强的健壮性。
- 性能。我们并不总是需要再编译执行的,上次翻译出来的代码,我们也可以缓冲起来,下次支持调用机器代码,这样,Java的执行效率跟实际机器代码的效率相关不大。因为虚拟机是软件,我们可以在虚拟机环境里追踪代码的执行历史,在这种基础上,可以更容易进行虚拟机里面代码的执行状况分析,甚至加入自动化优化,甚至可以超过真实机器的执行效率。比如,在Java环境里,我们执行过一次handler.post(msgTouch),当下次通过msgTouch这个Object作为参数来执行handler.post()方法时,我们完全不需要再执行一次,我们已经可以得到其执行的结果,我们只需要把结果操作再做一次。对于一些大运算量而重复性又比较高的代码,我们的执行效率会得到成倍地提升。这种技术是运行态的优化技术,叫JIT(Just In Time)优化,在实际机器上是很难实现的,而几乎所有使用虚拟机环境的编程语言都支持。
所有的Java语言在编程上的优势,都使它可以成为Android的首选编程环境,这跟WebOS选择JavaScript、WindowsPhone选择.Net都是同样的道理。比如安全性,如果我们上面描述的执行模型是纯Java的,则其安全性得到进一步提升。
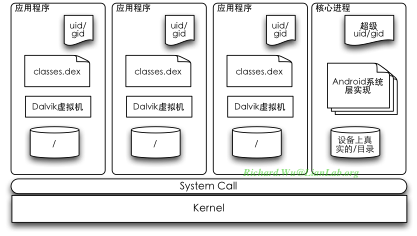
但是,纯Java环境不要说在嵌入式平台上,就是在PC环境里,也是以缓慢淡定著称的,Java的自优化能力与处理器能力、内存大小成正比。使用纯Java写嵌入式方案,最终达到的结果也就只会是奇慢无比的JAVA ME。另外,Java是使用商业授权的语言,无论是在以前它的创建者Sun公司,还是现在已经收购Sun公司的Oracle,对Java一贯会收取不低的商业授权费用,一旦基于纯粹Java环境来构建系统,最后肯定会造成Android系统不再是免费的午餐。既然Android所需要的环境只是Java语言本身,原始的Java虚拟机的授权又难以免费,这就迫使Android的开发者,开发出来另一套Java虚拟机环境,也就是我们的Dalvik虚拟机。
于是,我们基于多进程模型的系统构架,出于跨平台、安全、编程的简易性等多方面的原因,使我们得到的Android的设计方案成为下面的这个新的样子:核心进程这部分的实现我们还没分析到,但应用程序此时在引入Java环境之后,都变成了通过Dalvik虚拟机所管理起来的更受限的环境,于是更安全。
而在Java环境里,一个Java程序的主入口实际上还是传统的main()入口的方式,而以main()方法作为主入口,则意味着编程时,特别是图形界面编程,需要用户更多地考虑如何实现,如何进行交互。整个Java环境,全都是由一个个的有一定生存周期的对象组合而成,任何一个对象里存在的static属性的main()方法,则可以在Java环境里作为一个程序的主入口得到执行。如果使用标准Java编程,则我们的图形界面编程将复杂得多,比如我们下面的使用Swing编程写出来的,跟我们前面的Helloworld类似的例子:
importjavax.swing.JFrame;
importjavax.swing.JButton;
importjavax.swing.JOptionPane;
importjava.awt.event.ActionListener;
importjava.awt.event.ActionEvent;
publicclass Swing {
publicstaticvoid main(String[] args) {
JFrame frame = newJFrame("Hello Swing");
JButton button = newJButton("Click Me");
button.addActionListener(newActionListener() {
publicvoidactionPerformed(ActionEvent event) {
JOptionPane.showMessageDialog(null,
String.format("<html>Hello from <b>Java</b><br/>" +
"Button %s pressed", event.getActionCommand()));
}
});
frame.getContentPane().add(button);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.pack();
frame.setVisible(true);
}
} |
这种方式里,我们这个Helloworld的例子运行起来,会需要另外有窗口管理器来维护应用程序的状态。通过main()进入之后,会有很大的实现上的自由度,过大的自由会导致最终编写出来的应用程序,在代码实现角度就已经会是千奇百怪的,同时,也加大了开发者在编程上的负担。
而Android的编程上,应该绕开这些Java标准化编程上的局限性,应用程序的行为模式应该被规范化,同时也需要减小应用程序开发时的开销。于是,我们的Android环境里,Activity、Service、Content Provider、Broadcast Receiver,不光有共享功能的作用,实际上还起到了减少编程工作量的作用。大部分情况下,我们的通用行为,已经被基类所实现,编程时只是需要将基类的功能按需求进行拓展。而从完全性的角度,我们也限制了应用程序的自由度,不再是从一个main()方法进入来实现所有的逻辑,而是仅能拓展一些特定的回调点,比如Activity的onStart(),onStop()等。从应用程序的角度来看,实际上编程是这个样子的:
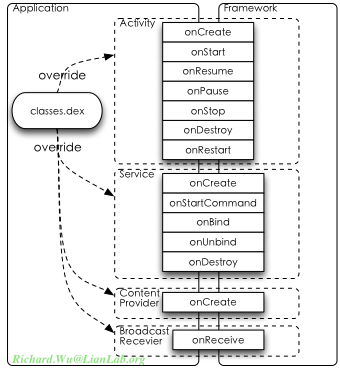
这种实现的技巧,对于Android系统来说,虽然应用程序会通过自己的classes.dex来实现一些各自不同的功能实现,但对于Android系统来说,这些不同实现都是土头土脑的一个样子,可以方便管理。有了这种方便管理之后,实际又能达到灵活的目的,比如我们去修改这种应用程序的管理框架时,应用程序则完全不需要改变,自然而然被管理起来。对于Android的应用程序,则通过这种抽象的工作,大规模地减小了工作量,如果我们很懒不愿意浪费时间写垃圾代码,我们都可以借用Android内部已经提供的实现,而所谓的借用实际上是什么都不用干,由系统来自动完成。而这些具体的生命周期,我们在后面的内容里再讨论它们的意义。
引入了Java对Android来说,带来的好处是明显的,不说可移植性。就是对于安全性设计而言,就已经进一步强化了沙盒式的开发模型。但也还有悬而未决的问题,比如性能,比如说功耗控制。我们先来看Android的性能解决之道。
1.3 跨进程通信
从Android的“沙盒”模型,我们可以知道,这种多进程模型,必须需要一种某种通过在多个进程之间进行消息互通的机制。与其他系统不同的是,Android对于这种多进程之间通信的要求会更高。在Android世界里,出于功能共享的需求,进程间的交互随时都在进行,所以必然需要一种性能很高的解决方案。由于Android是使用Java语言作为运行环境的,这样的情况下,通讯机制就需要跟Java环境结合,可以提供面向对象的访问方式,并且最好能够与自动化垃圾回收整合到一起。
出于这些设计上的考虑,Android最终在选择跨进程通信方式时使用了一种叫Binder的通信机制,绝大部分系统的运行,以及系统与应用程序的交互,都是通过Binder通信机制来完成的。但Android系统里并不只有Binder,实际上,在与已有的解决方案进行整合的过程中,Android也可能会使用其他的跨进程通信机制,比如进程管理上会使用Signal,在处理3G Modem时会使用Socket通信,以及为了使用BlueZ这套比较成熟的蓝牙解决方案,也被迫使用Dbus。
任何一种计算环境,都会有实现的功能部件之间进行交互的需求。如果是统一的地址空间,这时解决方式可以简单粗暴,比如通过读写全局变量等来完成。如果是各部件之间的地址空间互相独立,这就会是多进程的操作系统环境,我们就需要某种在两个进程空间之间传递消息的能力,这就是跨进程通信。一般在多进程操作系统里,这都被称为进程间通信(Inter-Process Communication,IPC)。
在传统的操作系统环境里,IPC进程并非必须的选项,只是一种支持多进程环境设计的一种辅助手段。而由于这种非强制性的原因,IPC机制在长期的操作系统发展历史被约定俗成的固化下来,会包括信号(Signal)、信号量(Semaphore)、管道(PIPE)、共享内存(Share Memory)、消息队列(Message Queue)、套接字(Socket)等。
在这些IPC机制里,对系统唯一的必须选项是信号。要是研究过系统的进程调度方向的,都知道信号不光是进程之间提供简单消息传递的一种机制,同时也被用于进程管理。比如在Linux的进程管理框架里,会通过SIGCHLD(Signal No. 20)的信号来管理父子进程,通过SIGKILL(Signal No. 9)来关闭进程,以及SIGSEGV(Signal No. 11)来触发段错误。所以对于进程管理而言,信号同时也是一种进程管理机制,像SIGKILL,在内核进行进程调度时会立即处理,不进入到用户态,也无法进行被屏蔽。既然构建于Linux内核之上,Android必然会使用到信号。
这些常用IPC机制构造出一种灵活的支持环境,可以让多进程软件的设计者可以灵活地选择。但问题是过于灵活也是毛病,这样的灵活机制也不能对上层交互消息作任何假设,只能作为进程间交互的一种最裸的手段,在上层传输还需要进行封装。每个多进程软件在设计里会自己设计一套内部通讯的方案,在与其他软件有交互时再吵架协商出一套通用的交互方案,最后才能组合出一套整个操作系统级别的通讯机制。比如我们的Linux桌面环境里,Firefox有自己的一套IPC机制、Gnome有自己的一套通过Gconf构建的IPC机制,OpenOffice又有另一套。这些软件刚开始只关注自己的实现和改进时,这种IPC不统一的缺陷还不是那么的严重,到后来需要协同工作时,由于IPC不统一造成的无法共同协作的问题就进一步严重起来,于是又通过一番痛苦的标准化过程,又形成了Linux环境里统一的IPC机制—Dbus。
前车之鉴,后事之师,既然以前的Linux解决方案会因为IPC机制不统一造成了缺陷,于是就不能重蹈复辙了。于是Android权衡了设计上的需求,在性能、面向对象、以进程为单位、可以自动进行垃圾回收的多方位的需求,于是选用了一种叫Binder的通信机制。Binder源自于Palm公司开源出来的一套IPC机制OpenBinder,正如名字上所看到的,Binder比OpenBinder拼写简化了一些,也是OpenBinder的一种简化版。
OpenBinder本用于构建传统的操作系统BeOS的系统级消息传递机制的,在BeOS退出历史舞台之后,又被Palm收购用于Palm的编程环境。但对于Android来说,OpenBinder的设计过于复杂,它本质是非常接近微软的COM通信机制全功能级IPC,在Binder体系里,可用于包装系统里的一切对象,同时也具备像CORBA那样的可以绑定到多种语言支持环境里,甚至它里面还有shell环境支持!这对Android来讲就有点杀鸡用牛刀了。于是Android简化了OpenBinder,只借用其内核驱动部分,上层则重新进行封装,于是得到我们常说的Binder。从学习角度而言,我们只需要理解与分析Binder,也不应该被一般误导性的说明去研究OpenBinder,OpenBinder绝大部分功能是在Android里碰不到的,而Android里的Binder实现与应用的完整源代码,总共也没几行,分析起来更容易一些。
Binder构建于Linux内核里的一个叫binder的驱动之上,系统里所有涉及Binder通信的部分,都通过与/dev/binder的设备驱动交互来得到信息互通的功能。而binder本身只是一种借用内存作后端的“伪驱动”,并不对应到硬件,而只是作用于一段内存区域。通过这个binder驱动,最终在Android系统里得到了进程间通信所需要的特点:
- 高性能:基于Binder的通信全都使用ioctl来进行通信,做过实时系统的人都会知道,ioctl则会绕开文件系统缓冲,达到实时交互的目的。同时,基于Binder传递的数据,binder可以灵活地选用不同的机制传递数据,两次复制(用于传递小数据量),一次复制(用于ServiceManager),零复制(通过IMemory对象共享,数据只在内核空间里存在一份,用户态进行内存映射),于是在效率上灵活性都可以很高。
- 面向对象:与传统的仅提供底层通信能力的IPC不同,Android系统是一种面向对象式开发的系统,于是需要更高层的具备面向对象的抽象能力的IPC机制。使用底层IPC加以封装也不是不可以,像Mozilla这种设计也可以解决问题,但Android是作为操作系统开发的,没必要产生这样的开销。而使用Binder之后,就得到了天然的面向对象的IPC,在设计上与实现上都得到了简化。使用Binder进行通信异常简单,只需要通过直接或是间接的方式继承IBinder基类即可。
- 绑定到Dalvik虚拟机:一般的系统设计里使用IPC,都是先将就底层,再设计更面向高层的IPC接口。还拿Mozilla来作例子的话,Mozilla里的IPC先是提供C/C++编程接口,然后再绑定到其他高级语言,像Java、JavaScript、Python。而Android里的Binder则不同,更多地是面向Java的,直接通过JNI绑定到Java层的Dalvik虚拟机,先满足Java层的编程需求,然后再考虑到C/C++。使用C/C++语言来对Binder进行编程,更像是在Java底层的hack层,无论Binder怎么被扩展,其服务对象都是Java层的,从这个意义上来说,Android的Binder,也是面向Java的。
- 自动垃圾回收:在传统的IPC机制里,垃圾回收或者说内存回收,都是IPC编程框架之外的,IPC本身只负责通信,并不管理内存。而Android里使用Binder也不一样,因为它是面向对象式的,于是更容易使用基于对象引用计数的内存管理。在使用Binder时,我们可能会经常遇到sp<>,wp<>这样的模板类,这种模板则是直接服务于垃圾回收的,以Java语言的Soft Reference、Weak Reference来管理对象的生存周期。
- 简单灵活:与传统IPC相比,或是标准OpenBinder实现相比,Binder都具备了实现更简单灵活的特点。Binder在消息传递机制之上,附加了一定的内存管理功能,大大简化了编程,同时在实现上又非常简单,大家可以看到frameworks/base/libs/binder下的实现,也没有几行代码,而对于驱动来说,也仅有一个drivers/stage/android/binder.c一个文件而已。这种简单实现也给上层使用上提供了更多灵活性。
- 面向进程:除了Signal之外,传统IPC机制几乎没有办法获取访问者(也就是进程)相关的信息,而只以内核态的文件描述符为单位进行通信。但Binder在设计里,就是以进程为单位的,所有的信息在传递过程里都以PID作为分发的基础,这时也为Android的多进程模型提供了便捷性。在维护进程之间通信状态时,Binder底层本身是可以得到进程是否已经出错挂掉等信息。Binder这种特性也间接提供了一定的进程调度的能力,处于Binder通信过程里的进程,在没有Binder通信发生时,实际一直会处于休眠状态,并不会盲目运行。
- 安全:我们前面分析过基于进程空间的“沙盒”模型,它是基于uid/gid为基础的单进程模型。如果我们的Binder提供的传递机制也是以进程为单位进行通信,这时这种进程间通信的模型也可以得以强化,进程运行时的uid/gid也会在Binder通信时被用于权限判断。
当然,Android系统并非依赖Binder处理全部逻辑,在特殊性况下也会使用到其他的IPC机制,比如我们前面提到的RIL与BlueZ。在与进程管理模型相适配时,Android也会使用到信号,关闭应用程序是通过简单的SIGKILL,还会在某些代码调试部分的实现里使用SIGUSR1、SIGUSR2等。但对于Android整个系统的核心实现而言,都会通过Binder来组织系统内部的消息传递与处理。应用程序之间的万能信息Intent,实际上底层是使用的Binder,而应用程序要访问到系统里的功能,则会是使用Binder封装出来的Remote Service。整个系统的基本交互图如下所示:
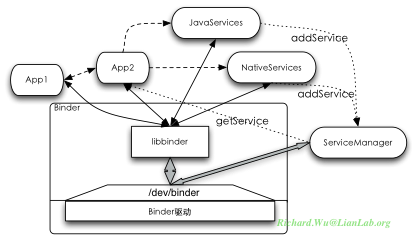
在binder之上,framework里会把binder通信的基本操作封装到libbinder库(frameworks/base/libs/binder)实现里,当然libbinder则会通过JNI绑定到Dalvik虚拟机的执行环境。应用程序App1与App2之间进行通信,只会通过Binder之上再包装出来的Intent来完成具体的交互。同时,在Android的系统实现的,我们提供的系统级功能,大部分会是Java实现的Remote Service,有一小部分是使用的C/C++实现的Native Service,而所有的这些Service,会通过一个叫ServiceManager的进程来进行管理,不论是Java实现的Service还是NativeService,都将使用addService()注册到ServiceManager里。当任何一个应用程序需要访问系统级功能时,由会通过调用ServiceManager的getService方法取回一个系统级Service的实例,然后再与这些Service进行交互。
图中我们可以看到,实线代表交互,虚线代表基于Binder的远程交互,从上图中我们也可以看出,实际上,系统里基本上都不会有多个功能实现间的直接调用,所有的可执行部分,都只是通过libbinder封装库来与binder设备进行通信,而通信的结果就是实现了虚线所示的跨进程间的调用。当然,在代码里是看出来这些猫腻的,我们代码上可能大部分都貌似是直接调用的,比如WIFI访问:
mWifiManager = (WifiManager) context.getSystemService(Context.WIFI_SERVICE);
intwifiApState = mWifiManager.getWifiApState();
if (isChecked&& ((wifiApState == WifiManager.WIFI_AP_STATE_ENABLING) ||
(wifiApState == WifiManager.WIFI_AP_STATE_ENABLED))) {
mWifiManager.setWifiApEnabled(null, false);
} |
我们在代码调用上根本看不到有Binder存在,就像是在当前进程里调用了某个方法一样。在这代码示例里,我们只是通过getSystemService()取回一个Context.WIFI_SERVICE的实例,然后就通过这一实例来访问gitWifiApState()方法,但在底层实现上,getSystemService()与getWifiApState()都是运行另一个进程空间里的代码。这就是Android在实现上的厉害之处,虽然是简单的封装,但使我们的代码具备了强大跨进程的功能。
而这些所谓的Service,跟我们在应用程序编程里看到的Service基本上是一样的,唯一的区别是会通过addService()加载到ServiceManager的管理框架里,于是所有的进程都可以共享这种Service。在addService()成功之后,应用程序或是系统的其他部分,不需要再通过Intent来调用Service,而是可以直接通过getService()取回被调用的实例,然后直接进行跨进程调用。当然,Service概念的引入也给系统设计带来了方便,这些Service,即可以以独立进程的方式运行,也可以以线程方式被托管到另一个进程。在Android世界里,这样的技巧被反复使用,一般情况下,都会将系统级的Service以线程方式运行在SystemServer这个系统进程里,但如果有功能上或是稳定性上的考虑,则有可能以独立的进程来执行Service,比如MediaServer、StageFlinger就都是这样的例子。但对于调用它们的上层来说,都是透明的,无论哪种方式都没有区别。
对于我们应用程序,我们最关心的可能还是Intent。其实,如何回到前面我们提及过的onSavedInstance这种序列化对象,我们就可以了解到Intent这种神奇机制是如何实现的了。我们前面说明了,其实onSavedInstance的类型是Bundle,是一个用于恢复Activity上下文现场的用于序列化处理的特殊对象,而这种所谓序列化,就是将其转换成字典类型的结构,以key对应value的方式进行保存与读取。Bundle类可以处理一些Java原始支持的数据类型,像String,Int等,可以使只使用这些数据类型的对象可以被序列化(字典化),于是可以将这样的Bundle对象保存起来或是在跨进程间传递。同时,Bundle里可以把另一个Bundle对象作为其属性变量,于是通过Bundle实际上可以描述所有对象,而且是以一种进程无关机器无关的状态描述,这种结构天生就可以跨进程。
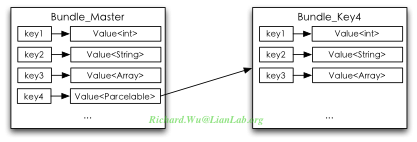
像我们的这例子里,我们可以通过Bundle来描述Bundle_Master对象,但因为Bundle_Master里又包含另一个对象,于是使用Bundle_Key4来描述。这些在编程上则不是直接使用Bundle对象进行进程间的数据传递,因为需要使用Binder来传递对象,于是我们又会得到一个Parcel类,把字典结构的Bundle对象,转换成基于Binder IPC进制的Parcel对象。Parcel对象,实际上也没有什么特殊性,只是提供一种跨进程交互时的简便性罢了,它内部使用一个Bundle来存储中间结果,同时会通过Binder来标识访问的活跃状态,然后提供writeToParcel()与readFromParcel()两个读写的接口方法也提供中间数据的读写。在使用Parcel进行封装时,可以通过实现Parcelable接口来实现。最后得到的Parcel对象如下所示:
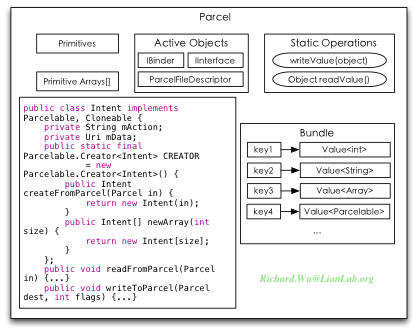
如上所示,实现了一个Parcel接口之后,我们得到的某个Parcelable的类,内部除了自己定义的属性与方法之外,还需要提供一个static final的CREATOR对象。Static final表明,所有这些Parcelable的对象(比如我们例子里的Intent),都会共享同一CREATOR对象来初始化对象,或是对象的数组。此时便提供了对象初始化方法的跨进程性。进一步需要提供两个接口方法,readFromParcel()与writeToParcel()两个方法,则此时对象就可以通过这两个接口来进行不同上下文环境里的读写,也就是对象本身可被“自动”序列化了。当然,对于Bundle内保存的中间数据,有可能也需要单个的读写,所以也会提供readValue()与writeValue()方法来进行内部属性的读写,严格地说是Getter/Setter。我们这里是以Intent为例子说明的,这我们就可以看到Intent的起源,其实Intent也只是通过Binder来拓展出来的Bundle序列化对象而已。
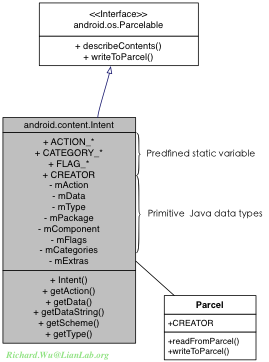
在我们Intent对象里包含的信息里,绝大部分是Java的基本类型,比如Action,Data都是String,于是大部分情况下我们都是直接Parcelable的接口操作即可完成共享。而唯一需要进一步使用Parcel的,是Extras属性,通过Extras可以传递极其复杂的对象为参数,于是Extras便成为Intent的属性里唯一会被Parcel进一步包装的部分。
通过Binder可以很高效而且安全实现数据的传递,于是我们整个Android世界便毫无顾忌地使用Intent在多进程的环境里运行,Intent的发送与处理,实际上一直处理多进程的交互环境里,用户本质上并没有进程内与跨进程的概念。
对于应用程序之间是如此,对于应用程序与系统之间的交互也是如此,我们也需要达到一种简单高效,同时让应用程序看不到本地与远程变化的效果。Android对于Java环境里的系统级编程,也提供了良好的封装,使Java环境里编写系统级服务也很简单。
使用Binder之后,所有的跨进程的访问,都可以通过一个Binder对象为接口,屏蔽掉调用端与实现端的细节:

比如,我们这个应用环境里,进程1访问进程2的ClassOther时,我们并非直接访问另一进程的对象,而在进程1的地址空间里,会有一个objectRemote的远程引用,这一远程引用通过一个IBinder接口会引用到进程2的ClassRemote的实例。当在进程1里访问进程2的某个方法时,则直接会通过这一引用调用其ClassRemote里实现的具体的方法。
这种命名方式跟我们的Android对不上号,这是因为Android里使用了一种叫Proxy的设计模式。Proxy设计模式,可以将设计与实现分离开。先定义接口类,调用端会通过一个Proxy接口来进行调用,而实现端则只通过接口类的定义来向外暴露其实现。

如图所示,调用方会通过接口找到Proxy,而通过Proxy才会具体地找到合适的Stub实现来进行通信。通过这样的抽象,可以使代码的互相合作时的耦合度被大大降低,Proxy实现部分可以根据调用的具体需要来向不同的实现发出调用请求,同时实现接口的部分也会因此而灵活,对同一接口可以有多个实现,也可以对接口之外的调用进行灵活地拓充。
对应到Android环境,我们就需要能够将Binder的实现,进一步通过Proxy设计模式包装起来,从而能够提高实现上的灵活性。于是Android里应用程序与系统的交互模型,就会变成这样:
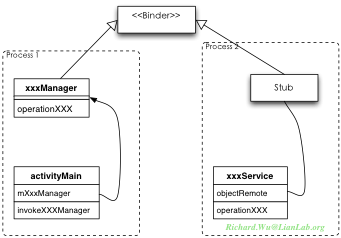
首先继承自Binder的,不再是某一个对象,而是被拆分成Proxy与Stub两个部分,Proxy部分被重命名为xxxManager(与现实生活相符,我们总是不直接找某个人,而是找他的经验来解决问题),而Stub部分则是通过继承自Binder来得到一个Stub对象,这个Stub对象会作为一个xxxService的属性,从而对于某些功能xxx的存在周期,将通过Service的生命周期来进行管理。通过这样的代码重构的Proxy访问模式,使我们的系统的灵活性得以大大提高,这也是为什么我们在系统里可以见到大量的xxxManager.java,xxxService.java的原因,Manager供应用程序使用,属于Proxy运行在应用程序进程空间,Service提供实现,一般运行在某个系统进程空间里。
通过这种Proxy方式简化之后,可能还是会有个代码重复性的问题,比如我们的Manager怎么写、Service怎么写,总是会不停地重复写这些交互的代码,但对于通信过程而言,本质上从Manager的信息,怎么到Service端,基本上是比较固化的。于是,Android里提供了另一套机制,来简化设计,减小需要重复的代码量。
AIDL跟传统的IDL有类似之处,但区别也很大,更加简单,只用于Java环境,不能用于网络环境里。AIDL提供的功能,就是将这些重复性的通信代码(Proxy与Stub的基本实现),固化到AIDL工具自动生成的代码里,这部分代码用户看不到,也不用去改写它。

这时,在Android里,写一个系统级的Service,就不再有明显的Proxy类、Service类,而变成调用端直接调用,实现端只提供Stub的具体实现即可。当然,我们系统环境里的Proxy接口会复杂一些,需要考虑权限、共享、电源控制等多种需求,所以我们还是可以见到大量的Manager类的实现。
我们在Android系统编程里研究得深入一点,也会发现Remote Service,也就是我们AIDL机制的妙用,很简单地就可以提供一些方法或是属性给另一个进程。Android系统,其实说白了,也就是大量这样的基于AIDL的Remote Service的实现。
当我们遇到性能问题时,我们还可以在Binder之上,“黑”掉正常的Java代码,全部使用C/C++来响应应用程序的请求,这就是所谓的Native Service。当然,我们就不能再使用AIDL了,AIDL是专用于Java环境里跨进程调用所用的,必须自己手动来实现所有的Proxy接口与Stub接口。从这个意义上来说,Android也是Java操作系统,因为使用C/C++反而是比较受限的编程环境。
于是,我们的跨进程通信的问题,几乎可以得到完美解决了。可以再强调一下的是,在Android世界里,如果是应用程序编程,可能只会与Activity打交道,因为大部分情况下,我们只是把界面画出来进行交互。而学习Android底层,需要做Android移植,甚至需要进行Android定制化的改进,对Binder、Remote Service、Native Service的深入理解与灵活使用则是关键点。不了解这些特点的Android系统工程,都将在性能、内存使用上遇到难以避免的麻烦,因为系统本身都依赖于这种机制而存在。由于这样的重要性,我们在后面会专门以这三个主题展开分析,说明在实践运用时,我们可以怎么灵活使用这三种功能部件。
紧接连载三,我们接下从性能的角度分别分析Android系统为应用程序提供的支撑。
1.4 性能
Android使用Java作为编程语言,这一直被认为是一局雄心万丈,但凶险异常的险棋。Java的好处是多,前面我们只是列举了一小部分,但另一种普遍的现象是,Java在图形编程上的应用环境并不是那么多。除了出于Java编程的目的,我们是否使用过Java编写的应用程序?我们的传统手机一般都支持Java ME版本,有多少人用过?我们是否见过Java写就的很流畅的应用程序?是否有过流行的Java操作系统?答应应该是几乎为零。通过这些疑问,我们就可以多少了解,Android这个Java移动操作系统难度了,还不用说,我们前面看到各种设计上的考量。
首先,得给Java正名,并非Java有多么严重的性能问题,事实上,Java本是一种高效的运行环境。Android在设计上的两个选择,一个Linux内核,一个Java编程语言,都是神奇的万能胶,从服务器、桌面系统、嵌入式平台,它们都在整个计算机产业里表现了强大的实力,在各个领域里都霸主级的神器(当然,两者在桌面领域表现都不是很好,都受到了Windows的强大压力)。从Java可以充当服务器的编程语言,我们就可以知道Java本身的性能是够强大的。标准的Java虚拟机还有个特点,性能几乎会与内存与处理器能力成正比,内存越大CPU能力越强,当JIT的威力完全发挥出来时,Java语言的性能会比C/C++写出来的代码的性能还要好。
但是,这不是嵌入式环境的特色,嵌入式设备不仅是CPU与内存有限,而且还不能滥用,需要尽可能节省电源的使用。这种特殊的需求下,还需要使用Java虚拟机,就得到一个通用性极佳,但几乎无用的JAVA ME环境,因为JAVA ME的应用程序与本地代码的性能差异实在太大了。在iPhone引发的“后PC时代”之前,大家没得选择,每台手机上几乎都支持,但使用率很低。而我们现在看到的Android系统,性能上是绝对不成问题,即便是面对iPhone这样大量使用加速引擎的嵌入式设备,也没有明确差异,这里面窍门在哪里呢?
我们前面也说明了,Java在嵌入式环境里有性能问题,运行时过低的执行效率会引发使用体验问题,同时还有版权问题,几乎没有免费的嵌入式Java解决方案。如果正向去解,困难重重,那我们是否可以尝试逆向的解法呢?
在计算机工程领域,逆向思维从来都是重要武器之一,当我们在设计、算法上遇到问题时,正向解决过于痛苦时,可以逆向思考一下,往往会有奇效。比如我们做算法优化,拼了命使用各种手法提高性能,收效也不高,这时我们也可以考虑一下降低其他部分的性能。成功案例在Android里就有,在Android环境里,大量使用Thumb2这样非优化指令,只优化性能需求最强的代码,这时系统整体的性能反而比全局优化性能更好。我们做安全机制,试验各种理论模型,最终都失败于复杂带来的开销,而我们反向思考一下,借用进程模型来重新设计,这时我们就得到了“沙盒”这种模型,反而简便快捷。只要思路开阔,在计算机科学里条条大路通罗马,应该是没有解不掉的问题的。
回到Android的Java问题,如果我们正向地顺着传统Java系统的设计思路会走入痛苦之境,何不逆向朝着反Java的思路去尝试呢?这时还带来了边际收益,Java语言的版权问题也绕开了。于是,天才的Android设计者们,得到了基于Dalvik虚拟机方案:
基于寄存器式访问的Dalvik VM
Java语言天生是用于提升跨平台能力的,于是在设计与优化时,考虑得更多是如何兼容更多的环境,于它可以运行在服务器级别的环境里,也在运行在嵌入式环境。这种可伸缩的能力,便源自于它使用栈式的虚拟机实现。所谓的栈式虚拟机,就是在Java执行环境在边解释边执行的时候,尽可能使用栈来保存操作数与结果,这样可设计更精练的虚拟指令的翻译器,性能很高,但麻烦就在于需要过多地访问内存,因为栈即内存。
比如,我们写一个最简单的Java方法,读两个操作数,先加,然后乘以2,最后返回:
public int test01( int i1, int i2 ) {
int i3 = i1 + i2;
return i3 * 2;
} |
这样的代码,使用Java编译器生成的.class文件里,最后就会有这样的伪代码(虚拟机解析执行的代码):
0000: iload_1 // 01 0001: iload_2 // 02 0002: iadd 0003: istore_3 // 03 0004: iload_3 // 03 0005: iconst_2 // #+02 0006: imul 0007: ireturn |
出于栈式虚拟机的特点,这样的伪指令追成的结果会操作到栈。比如iload_1, iload_2,iadd,istore_3,这四行,就是分别将参数1,2读取到栈里,再调用伪指令add将栈进行加操作,然后将结果写入栈顶,也就是操作数3。这种操作模式,会使我们的虚拟机在伪指令解析器上实现起来简单,因为简单而可以实现得高效,因为伪指令必然很少(事实上,通用指令用8位的opcode就可以表达完)。可以再在这种设计基础上,针对不同平台进行具体的优化,由于是纯软件的算法,通用性非常好,无论是32位还是64位机器,都可以很灵活地针对处理器特点进行针对性的实现与优化。而且这种虚拟机实现,相当于所有操作都会在栈上有记录,对每个伪指令(opcode)都相当于一次函数调用,这样实现JIT就更加容易。
但问题是内存的访问过多,在嵌入式设备上则会造成性能问题。嵌入式平台上,出于成本与电池供电的因素,内存是很有限的,Android刚开始时使用的所谓顶级硬件配置,也才不过192MB。虽然现在我们现在的手机动不动就上G,还有2G的怪兽机,但我们也不太可能使用太高的内存总线频率,频率高了则功耗也就会更高,而内存总线的功耗限制也使内存的访问速度并不会太高,与PC环境还是有很大差异的。所以,直到今天,标准Java虚拟的ARM版本也没有实现,只是使用JAVA ME框架里的一种叫KVM的一种嵌入式版本上的特殊虚拟机。
基于Java虚拟机的实现,于是这时就可以使用逆向思维进行设计,栈式虚拟机的对立面就是寄存器式的。于是Android在系统设计便使用了Dan Bornstein开发的,基于寄存器式结构的虚拟机,命名源自于芬兰的一个小镇Dalvik,也就是Dalivk虚拟机。虽然Dalvik虚拟机在实现上有很多技巧的部分,有些甚至还是黑客式的实现,但其核心思想就是寄存器式的实现。
所谓的寄存器式,就是在虚拟机执行过程中,不再依赖于栈的访问,而转而尽可能直接使用寄存器进行操作。这跟传统的编程意义上的基于寄存器式的系统构架还是有概念上的区别,即便是我们的标准的栈式的标准Java虚拟机,在RISC体系里,我们也会在代码执行被优化成大量使用寄存器。而这里所指的寄存器,是指执行过程里的一种算法上的思路,就是不依赖于栈式的内存访问,而通过伪指令(opcode)里的虚拟寄存器来进行翻译,这种虚拟寄存器会在运行态被转义成空闲的寄存器,进行直接数操作。如果这里的解释不够清晰,大家可以把栈式看成是正常的函数式访问,几乎所有的语言都基于栈来实现函数调用,此时虚拟机里每个伪指令(opcode),都类似于基于栈进行了函数调用。而基于寄存器式,则可以被看成是宏,宏在执行之前就会被编译器翻译成直接执行的一段代码,这时将不再有过多的压栈出栈操作,而是会尽可能使用立即数进行运算。
我们上面标准虚拟机里编译出来的代码,经过dx工具转出来的.dex文件,格式就会跟上面很不一样:
代码编译伪指令
9000 0203 0000 add-int v0, v2, v3 da00 0002 0002 mul-int/lit8 v0, v0, #int 2 // #02 0f00 0004 return v0 |
对着代码,我们可以看到(或者可以猜测),在Dalvik的伪指令体系里,指令长度变成了16bit,同时,根本去除了栈操作,而通过使用00, 02, 03这样的虚拟寄存器来进行立即数操作,操作完则直接将结果返回。大家如果对Dalvik的伪指令体系感兴趣,可以参考Dalvik的指令说明:http://source.android.com/tech/dalvik/dalvik-bytecode.html
像Dalvik这样虚拟机实现里,当我们进行执行的时候,我们就可以通过将00,02,03这样的虚拟寄存器,找一个空闲的真实的寄存器换上去,执行时会将立即数通过这些寄存器进行运算,而不再使用频繁的栈进行存取操作。这时得到的代码大小、执行性能都得到了提升。
如果寄存器式的虚拟机实现这么好,为什么不大家都使用这种方式呢?也不是没有过尝试,寄存器试的虚拟机实现一直是学术研究上的一个热点,只是在Dalvik虚拟机之前,没有成功过。寄存器式,在实际应用中,未必会比栈式更高效,而且如果是通用的Java虚拟机,需要运行在各种不同平台上,寄存器式实现还有着天生的缺陷。比如说性能,我们也看到在Dalvik的这种伪指令体系里,使用16位的opcode用于实现更多支持,没有栈访问,则不得不靠增加opcode来弥补,再加需要进行虚拟寄存器的换算,这时解析器(Interpreter)在优化时就远比简单的8位解析器要复杂得多,复杂则优化起来更困难。从上面的函数与宏的对比里,我们也可以看到寄存器实现上的毛病,代码的重复量会变大,原来不停操作栈的8bit代码会变成更长的加寄存器操作的代码,理论上这种代码会使代码体系变大。之所以在前面我们看到.dex代码反而更精减,只不过是Dalvik虚拟机进行了牺牲通用性代码固化,这解决了问题,但会影响到伪代码的可移植性。在栈式虚拟机里,都使用8bit指令反复操作栈,于是理论上16bit、32bit、64bit,都可以有针对性的优化,而寄存器式则不可能,像我们的Dalvik虚拟机,我们可以看到它的伪代码会使用32位里每个bit,这样的方式不可能通用,16bit、32bit、64bit的处理器体系里,都需要重新设计一整套新的指令体系,完全没有通用性。最后,所有的操作都不再经过栈,则在运行态要得到正确的运算操作的历史就很难,于是JIT则几乎成了不可能完成的任务,于是Dalvik虚拟机刚开始则宣称JIT是没有必要,虽然从2.2开始加入了JIT,但这种JIT也只是统计意义上的,并不是完整意义上的JIT运算加速。所有这些因素,都导致在标准Java虚拟机里,很难做出像Dalvik这样的寄存器式的虚拟机。
幸运的是,我们上面说的这些限制条件,对Android来说,都不存在。嵌入式环境里的CPU与内存都是有限的资源,我们不太可能通过全面的JIT提升性能,而嵌入式环境以寄存器访问基础的RISC构架为主,从理论上来说,寄存器式的虚拟机将拥有更高的性能。如果是嵌入式平台,则基本上都是32位的处理器,而出于功耗上的限制,这种状况将持续很长一段时间,于是代码通用性的需求不是那么高。如果我们放弃全面支持Java执行环境的兼容性,进一步通过固化设计来提升性,这时我们就可以得到一个有商用价值的寄存器式的虚拟机,于是,我们就得到了Dalvik。
Dalvik虚拟机的性能上是不是比传统的栈式实现有更高性能,一直是一个有争议的话题,特别是后面当Dalvik也从2.2之后也不得不开始进行JIT尝试之后。我们可以想像,基于前面提到的寄存器式的虚拟机的实现原理,Dalvik虚拟机通过JIT进行性能提升会遇到困难。在Dalvik引入JIT后,性能得到了好几倍的提升,但Dalvik上的这种JIT,并非完整的JIT,如果是栈式的虚拟机实现,这方面的提升会要更强大。但Dalvik实现本身对于Android来讲是意义非凡的,在Java授权上绕开了限制,更何况在Android诞生时,嵌入式上的硬件条件极度受限,是不太可能通过栈式虚拟机方式来实现出一个性能足够的嵌入式产品的。而当Android系统通过Dalvik虚拟机成功杀出一条血路,让大家都认可这套系统之后,围绕Android来进行虚拟机提速也就变得更现实了,比如现在也有使用更好的虚拟机来改进Android的尝试,比如标准栈式虚拟机,使用改进版的Java语言的变种,像Scalar、Groovy等。
我们再看看,在寄存器式的虚拟机之外,Android在性能设计上的其他一些特点。
以Android API为基础,不再以Java标准为基础
当我们对外提供的是一个系统,一种平台之时,就必须要考虑到系统的可持续升级的能力,同时又需要保持这种升级之后的向后兼容性。使用Java语言作为编程基础,使我们的Android环境,得到了另一项好处,那就是可兼容性的提升。
在传统的嵌入式Linux方案里,受限于有限的CPU,有限的内存,大家还没有能力去实施一套像Android这样使用中间语言的操作系统。使用C语言还需要加各种各样的加速技巧才能让系统可以运行,基至有时还需要通过硬件来进行加速,再在这种平台上运行虚拟机环境,则很不靠谱。这样的开发,当然没有升级性可言,连二次开发的能力都很有限,更不用说对话接口了,所谓的升级,仅仅是增加点功能,修改掉一些Bug,再加入再多Bug。而使用机器可以直接执行的代码,就算是能够提供升级和二次开发的能力,也会有严重问题。这样的写出来的代码,在不同体系架构的机器(比如ARM、X86、MIPS、PowerPC)上,都需要重新编译一次。更严重的是,我们的C或者C++,都是通过参数压栈,再进行指令跳转来进行函数调用的,如果升级造成了函数参数变动,则还必须修改所开发的源代码,不然会直接崩溃掉。而比较幸运的是,所有的嵌入式Linux方案,在Android之前,都没有流行开,比较成功的最多也不过自己陪自己玩,份额很小,大部分则都是红颜薄命,出生时是demo,消亡时也是demo。不然,这样的产品,将来维护起来也会是个很吐血的过程。
而Android所使用的Java,从一开始就是被定位于“一次编写,到处运行”的,不用说它极强大的跨平台能力,就是其升级性与兼容性,也都是Java语言的制胜法宝之一。Java编译生成的结果,是.class的伪代码,是需要由虚拟器来解析执行的,我们可以提供不同体系构架里实现的Java虚拟机,甚至可以是不同产商设计生产的Java虚拟机,而这些不同虚拟机,都可以执行已经编译过的.class文件,完全不需要重新编译。Java是一种高级语言,具有极大的重用性,除非是极端的无法兼容接口变动,都可以通过重载来获得更高可升级能力。最后,Java在历史曾应用于多种用途的运行环境,于是定义针对不同场合的API标准,这些标准一般被称为JSR(Java Specification Request),特别是嵌入式平台,针对带不带屏幕、屏幕大小,运算能力,都定义了详细而复杂的标准,符合了这些标准的虚拟机应该会提供某种能力,从而保证符合同一标准的应用程序得以正常执行。我们的JAVA ME,就是这样的产物,在比较长周期内,因为没有可选编程方案,JAVA ME在诸多领域里都成为了工业标准,但性能不佳,实用性较差。
JAVA ME之所以性能会不佳的一个重要原因,是它只是一种规范,作为规范的东西,则需要考虑到不同平台资源上的不同,不容易追求极致,而且在长期的开发与使用的历史里,一些历史上的接口,也成为了进一步提升的负担。Android则不一样,它是一个新生事物,它不需要遵守任何标准,即使它能够提供JAVA ME兼容,它能得到资源回报也不会大,而且会带来JAVA ME的授权费用。于是,Android在设计上就采取了另一次的反Java设计,不兼容任何Java标准,而只以Android的API作为其兼容性的基础,这样就没有了历史包袱,可以轻装上阵进行开发,也大大减小了维护的工作量。作为一个Java写的操作系统,但又不兼容任何Java标准,这貌似是比较讽刺的,但我们在整个行业内四顾一下,大家应该都会发现这样一种特色,所有不支持JAVA ME标准的系统,都发展得很好,而支持JAVA ME标准,则多被时代所淘汰。这不能说JAVA ME有多大的缺陷,或是晦气太重,只不过靠支持JAVA ME来提供有限开发能力的系统,的确也会受限于可开发能力,无法走得太远罢了。
这样会不会导致Java写的代码在Android环境里运行不起来呢?理论上来说不会。如果是一些Java写的通用算法,因为只涉及语言本身,不存在问题。如果是代码里涉及一些基本的IO、网络等通用操作,Android也使用了Apache组织的Harmony的Java IO库实现,也不会有不兼容性。唯一不能兼容的是一些Java规范里的特殊代码,像图形接口、窗口、Swing等方面的代码。而我们在Android系统里编程,最好也可以把算法与界面层代码分离,这样可以增加代码复用性,也可以保证在UI编程上,保持跟Android系统的兼容性。
Android的版本有两层作用,一是描述系统某一个阶段性的软硬件功能,另外就是用于界定API的规范。描述功能的作用,更多地用于宣传,用于说该版本的Android是个什么东西,也就是我们常见的食物版本号,像éclair(2.0,2.1),Froyo(2.2), Gingerbread(2.3),Icecream Sandswich(4.0),Jelly Bean(4.1),大家都可以通过这些美味的版本号,了解Android这个版本有什么功能,有趣而易于宣传。而对于这样的版本号,实际上也意味着API接口上的升级,会增加或是改变一些接口。
所谓的API版本,是位于应用程序层与Framework层之间的一层接口层,如下所示:

应用程序只通过AndroidAPI来对下进行访问,而我们每一个版本的Android系统,都会通过Framework来对上实现一套完整的API接口,提供给应用程序访问。只要上下两层这种调用与被调用的需求能够在一定范围内合拍,应用程序所需要的最低API版本低于Framework所提供的版本,这时应用程序就可以正常执行。从这个意义来说,API的版本,更大程度算是Android Framework实现上的版本,而Android系统,我们也可以看成就是Android的Framework层。
这种机制在Android发展过程中一直实施得很好,直到Android 2.3,都保持了向前发展,同时也保持向后兼容。Android 2.3也是Android历史上的一个里程碑,一台智能手机所应该实现的功能,Android2.3都基本上完成了。但这时又出现了平板(pad)的系统需求,从2.3又发展出一个跟手机平台不兼容的3.0,然后这两个版本再到4.0进行融合。在2.3到4..0,因为运行机制都有大的变动,于是这样的兼容性遇到了一定的挑战,现在还是无法实现100%的从4.0到2.3的兼容。
只兼容自己API,是Android系统自信的一种体现,同时,也给它带来另一个好处,那就是可以大量使用JNI加速。
大量使用JNI加速
JNI,全称是Java本地化接口层(Java Native Interface),就是通过给Java虚拟机加动态链接库插件的方式,将一些Java环境原本不支持功能加入到系统中。
我们前面说到过Dalvik虚拟机在JIT实现上有缺陷,这点在Android设计人员的演示说明里,被狡猾地掩盖了。他们说,在Android编程里,JIT不是必须的,Android在2.2之前都不提供JIT支持,理由是应用程序不可能太复杂,同时Android本身是没有必要使用JIT,因为系统里大部分功能是通过JNI来调用机器代码(Native代码)来实现的。这点也体现了Android设计人员,作为技术狂热者的可爱之处,类似这样的错误还不少,比如Android刚开始的设计初衷是要改变大家编程的习惯,要通过Android应用程序在概念上的封装,去除掉进程、线程这样底层的概念;甚至他们还定义了一套工具,希望大家可以像玩积木一样,在图形界面里拖拉一下,在完全没有编程背景的情况下也可以编程;等等。这些错误当然也被Android强大的开源社区所改正了。但对于Android系统性能是由大量JNI来推进的,这点诊断倒没有错,Android发展也一直顺着这个方向在走。
Android系统实现里,大量使用JNI进行优化,这也是一个很大的反Java举动,在Java的世界里,为了保持在各个环境的兼容性,除了Java虚拟机这个必须与底层操作系统打交道的执行实体,以及一些无法绕开底层限制的IO接口,Java环境的所有代码,都尽可能使用Java语言来编写。通过这种方式,可以有效减小平台间差异所引发的不兼容。在Java虚拟机的开发文档里,有详尽的JNI编程说明,同时也强烈建议,这样的编程接口是需要避免使用的,使用了JNI,则会跟底层打上交道,这时就需要每个体系构架,每个不同操作系统都提供实现,并每种情况下都需要编译一次,维护的代价会过高。
但Android则是另一个情况,它只是借用Java编程语言,应用程序使用的只是Android API接口,不存在平台差异性问题。比如我们要把一个Android环境运行在不那么流行的MIPS平台之上,我们需要的JNI,是Android源代码在MIPS构架上实现并编译出来的结果,只要API兼容,则就不存在平台差异性。对于系统构架层次来说,使用JNI造成的差异性,在Framework层里,就已经被屏蔽掉了:

如上图所示,Android应用程序,只知道有Framework层,通过API接口与Framework通信。而我们底层,在Library层里,我们就可以使用大量的JNI,我们只需要在Framework向上的部分保持统一的接口就可以了。虽然我们的Library层在每个平台上都需要重新编译(有些部分可能还需要重新实现),但这是平台产商或是硬件产商的工作,应用程序开发者只需要针对API版本写代码,而不需要关心这种差异性。于是,我们即得到高效的性能(与纯用机器实现的软件系统没有多少性能差异),以使用到Java的一些高级特性。
单进程虚拟机
使用单进程虚拟机,是Android整个设计方案里反Java的又一表现。我们前面提到了,如果在Android系统里,要构建一种安全无忧的应用程序加载环境,这时,我们需要的是一种以进程为单位的“沙盒(Sandbox)”模型。在实现这种模型时,我们可以有多种选择,如果是遵循Java原则的话,我们的设计应该是这个样子的:

我们运行起Java环境,然后再在这个环境里构建应用程序的基于进程的“小牢房”。按照传统的计算机理论,或是从资源有效的角度考虑,特别是如果需要使用栈式的标准Java虚拟机,这些都是没话说的,只有这种构建方式才最优。
Java虚拟机,之所以被称为虚拟机,是因为它真通过一个用户态的虚拟机进程虚拟出了一个虚拟的计算机环境,是真正意义上的虚拟机。在这个环境里,执行.class写出来的伪代码,这个世界里的一切都是由对象构成的,支持进程,信号,Stream形式访问的文件等一切本该是实际操作系统所支持的功能。这样就抽象出来一个跟任何平台无关的Java世界。如果在这个Java虚拟世界时打造“沙盒”模式,则只能使用同一个Java虚拟机环境(这不光是进程,因为Java虚拟机内部还可以再创建出进程),这样就可以通过统一的垃圾收集器进行有效的对象管理,同时,多进程则内存有可能需要在多个进程空间里进行复制,在使用同一个Java虚拟机实例里,才有可能通过对象引用减小复制,不使用统一的Java虚拟机环境管理,则可复用性就会很低。
但这种方案,存在一些不容易解决的问题。这种单Java虚拟机环境的假设,是建立在标准Java虚拟机之上的,但如前面所说,这样的选择困难重重,于是Android是使用Dalvik虚拟机。这种单虚拟机实例设计,需要一个极其强大稳定的虚拟机实现,而我们的Dalvik虚拟机未必可以实现得如此功能复杂同时又能保证稳定性(简单稳定容易,复杂稳定则难)。Android必须要使用大量的JNI开发,于是会进一步破坏虚拟机的稳定性,如果系统里只有一个虚拟机实例,则这个实例将会非常脆弱。当在Java环境里的进程,有恶意代码或是实现不当,有可能破坏虚拟机环境,这时,我们只能靠重启虚拟机来完成恢复,这时会影响到虚拟机里运行的其他进程,失去了“沙盒”的意义。最后,虚拟机必须给预足够的权限运行,才能保证核心进程可访问硬件资源,则权限控制有可能被某个恶意应用程序破坏,从而失去对系统资源的保护。
Android既然使用是非标准的Dalvik虚拟机,我们就可以继续在反Java的道路上尝试得更远,于是,我们得到的是Android里的单进程虚拟机模型。在基于Dalvik虚拟机的方案里,虚拟机的作用退回到了解析器的阶段,并不再是一个完整的虚拟机,而只是进程中一个用于解析.dex伪代码的解析执行工具:
在这种沙盒模式里,每个进程都会执行起一个Dalvik虚拟机实例,应用程序在编程上,只能在这个受限的,以进程为单位的虚拟机实例里执行,任何出错,也只影响到这个应用程序的宿主进程本身,对系统,对其他进程都没有严重影响。这种单进程的虚拟机,只有当这个应用程序被调用到时才予以创建,也不存在什么需要重启的问题,出了错,杀掉出错进程,再创建一个新的进程即可。基于uid/gid的权限控制,在虚拟机之外的实现,应用程序完全不可能通过Java代码来破坏这种操作系统级别的权限控制,于是保护了系统。这时,我们的系统设计上反有了更高的灵活度,我们可以放心大胆地使用JNI开发,同时核心进程也有可能是直接通过C/C++写出来的本地化代码来实现,再通过JNI提供给Dalvik环境。而由于这时,由于我们降低了虚拟机在设计上的复杂程序,这时我们的执行性能必然会更好,更容易被优化。
当然,这种单进程虚拟机设计,在运行上也会带来一些问题,比如以进程以单位进行GC,数据必然在每个进程里都进行复制,而进程创建也是有开销的,造成程序启动缓慢,在跨进程的Intent调用时,严重影响用户体验。Java环境里的GC是标准的,这方面的开销倒是没法绕开,所以Android应用程序编程优化里的重要一招就是减小对象使用,绕开GC。但数据复制造成的冗余,以及进程创建的开销则可以进行精减,我们来看看Android如何解决这样的问题。
尽可能共享内存
在几乎所有的Unix进程管理模型里,都使用延时分配来处理代码的加载,从而达到减小内存使用的作用,Linux内核也不例外。所谓的进程,在Linux内核里只是带mm(虚存映射)的task_struct而已,而所谓的进程创建,就是通过fork()系统调用来创建一个进程,而在新创建的进程里使用execve()系列的系统调用来执行新的代码。这两个步骤是分两步进行,父进程调用fork(),子进程里调用execve():
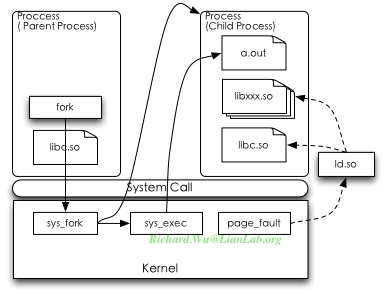
上图的实线代表了函数调用,虚线代码内存引用。在创建一个进程执行某些代码时,一个进程会调用fork(),这个fork()会通过libc,通过系统调用,转入内核实现的sys_fork()。然后在sys_fork()实现里,这时就会创建新的task_struct,也就是新的进程空间,形成父子进程关系。但是,这时,两个进程使用同一个进程空间。当被创建的子进程里,自己主动地调用了execve()系列的函数之后,这时才会去通过内核的sys_execve()去尝试解析和加载所要执行的文件,比如a.out文件,验证权限并加载成功之后,这时才会建立起新的虚存映射(mm),但此时虽然子进程有了自己独立的进程空间,并不会分配实际的物理内存。于是有了自己的进程空间,当下次执行到时,才会通过一次缺页中断加载a.out的代码段,数据段,而此时,libc.so因为两个进程都需要使用,于是会直接通过一次内存映射来完成。
通过Linux的进程创建,我们可以看到,进程之间虽然有独立的空间,但进程之间会大量地通过页面映射来实现内存页的共享,从而减小内存的使用。虽然在代码执行过程中都会形成它自己的进程空间,有各自独立的内存类,但对于可执行文件、动态链接库等这些静态资源,则在进程之间会通过页面映射进行共享进行共享。于是,可以得到的解决思路,就是如何加强页面的共享。
加强共享的简单一点的思路,就是人为地将所有可能使用到的动态链接库.so文件,dalvik虚拟机的执行文件,都通过强制读一次,于是物理内存里便有了存放这些文件内容的内存页,其他部分则可以通过mmap()来借用这些被预加载过的内存页。于是,当我们的用户态进程被执行时,虽然还是同样的执行流程,但因为内存里面有了所需要的虚拟机环境的物理页,这时缺页中断则只是进行一次页面映射,不需要读文件,非常快就返回了,同时由于页面映射只是对内存页的引用,这种共享也减小实际物理页的使用。我们将上面的fork()处理人为地改进一下,就可以使用如下的模式:
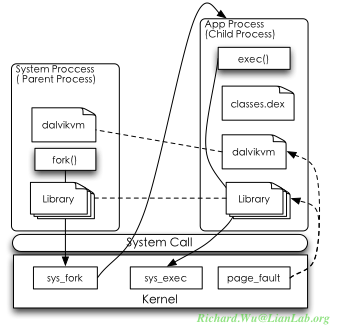
这时,对于任一应用程序,在dalvik开始执行前,它所需要的物理页就都已经存在了,对于非系统进程的应用程序而言,它所需要使用的Framework提供的功能、动态链接库,都不会从文件系统里再次读取,而只需要通过page_fault触发一次页面映射,这时就可以大大提供加载时的性能。然后便是开始执行dalvik虚拟,解析.dex文件来执行应用程序的独特实现,当然,每个classes.dex文件的内容则是需要各自独立地进行加载。我们可以从.dex文件的解析入手,进一步加强内存使用。
Android环境里,会使用dx工具,将.class文件翻译成.dex文件,.dex文件与.class文件,不光是伪指令不同,它们的文件格式也完全不同,从而达到加强共享的目的。标准的Java一般使用.jar文件来包装一个软件包,在这个软件里会是以目录结构组织的.class文件,比如org/lianlab/hello/Hello.class这样的形式。这种格式需要在运行时进行解压,需要进行目录结构的检索,还会因为.class文件里分散的定义,无法高效地加载。而在.dex文件里,所有.class文件里实现的内容,会合并到一个.dex文件里,然后把每个.class文件里的信息提取出来,放到同一个段位里,以便通过内存映射的方式加速文件的操作与加载。
这时,我们的各个不同的.class文件里内容被检索并合并到同一个文件里,这里得到的.dex文件,有特定情况下会比压缩过的.jar文件还要小,因为此时可以合并不同.class文件里的重复定义。这样,在可以通过内存映射来加速的基础上,也从侧面降低了内存的使用,比如用于.class的文件系统开销得到减小,用于加载单个.class文件的开销也得以减小,于是得到了加速的目的。
这还不是全部,需要知道,我们的dalvik不光是一个可执行的ELF文件而已,还是Java语言的一个解析器,这时势必需要一些额外的.class文件(当然,在Android环境里,因为使用了与Java虚拟机不兼容的Dalvik虚拟机,这样的.class文件也会被翻译成.dex文件)里提供的内容,这些额外的文件主要就是Framework的实现部分,还有由Harmony提供的一些Java语言的基本类。还不止于此,作为一个系统环境,一些特定的图标,UI的一些控件资源文件,也都会在执行过程里不断被用到,最好我们也能实现这部分的预先加载。出于这样的目的,我们又会面临前面的两难选择,改内核的page_fault处理,还是自己设计。出于设计上的可移植性角度考虑,还是改设计吧。这时,就可以得到Android里的第一个系统进程设计,Zygote。
我们这时对于Zygote的需求是,能够实现动态链接库、Dalvik执行进程的共享,同时它最好能实现一些Java环境里的库文件的预加载,以及一些资源文件的加载。出于这样的目的,我们得到了Zygote实现的雏形:
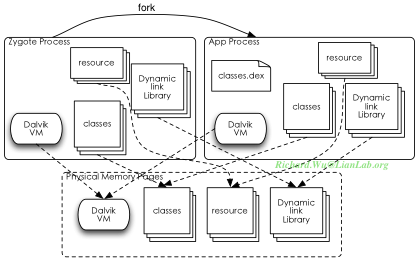
这时,Zygote基本上可以满足我们的需求,可以加载我们运行一个应用程序进程除了classes.dex之外的所有资源,而我们前面也看到.dex这种文件格式本身也被优化过,于是对于页面共享上的优化基本上得以完成了。我们之后的操作完全可以依赖于zygote进程,以后的设计里,我们就把所有的需要特权的服务都在zygote进程里实现就好了。
有了zygote进程则我们解决掉了共享的问题,但如果把所有的功能部分都放在Zygote进程里,则过犹不及,这样的做法反而更不合适。Zygote则创建应用程序进程并共享应用程序程序所需要的页,而并非所有的内存页,我们的系统进程执行的绝大部分内容是应用程序所不需要的,所以没必要共享。共享之后还会带来潜在问题,影响应用程序的可用进程空间,另外恶意应用程序则可以取得我们系统进程的实现细节,反而使我们的辛辛苦苦构建的“沙盒”失效了。
Zygote,英文愿意是“孵化器”的意思,既然是这种名字,我们就可以在设计上尽可能保持其简单性,只做孵化这么最简单的工作,更符合我们目前的需求。但是还有一个实现上的小细节,我们是不是期望zygote通过fork()创建进程之后,每个应用程序自己去调用exec()来加载dalvik虚拟机呢?这样实现也不合理,实现上很丑陋,还不安全,一旦恶意应用程序不停地调用到zygote创建进程,这时系统还是会由于创建进程造成的开销而耗尽内存,这时系统也还是很脆弱的。这些应该是由系统进程来完成的,这个系统进程应该也需要兼职负责Intent的分发。当有Intent发送到某个应用程序,而这个应用程序并没有被运行起来时,这时,这个系统进程应该发一个请求到Zygote创建虚拟机进程,然后再通过系统进程来驱动应用程序具体做怎么样的操作,这时,我们的Android的系统构架就基本上就绪了。在Android环境里,系统进程就是我们的System Server,它是我们系统里,通过init脚本创建的第一个Dalvik进程,也就是说Android系统,本就是构建在Dalvik虚拟机之上的。
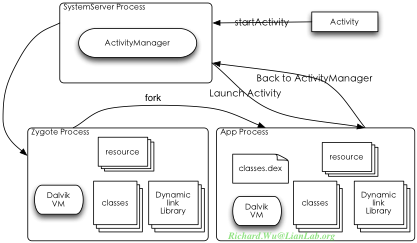
在SystemServer里,会实现ActivityManager,来实现对Activity、Service等应用程序执行实体的管理,分发Intent,并维护这些实体生命周期(比如Activity的栈式管理)。最终,在Android系统里,最终会有3个进程,一个只负责进程创建以提供页面共享,一个用户应用程序进程,和我们实现一些系统级权限才能完成的特殊功能的SystemServer进程。在这3种进程的交互之下,我们的系统会坚固,我们不会盲目地创建进程,因为应用程序完全不知道有进程这回事,它只会像调用函数那样,调用一个个实现具体功能的Activity,我们在完成内存页共享难题的同时,也完成Android系统设计的整体思路。
这时对于应用程序处理上,还剩下最后一个问题,如果加快应用程序的加载。
应用程序进程“永不退出”
虽然我们拥有了内存页的预加载实现,但这还是无法保证Android应用程序执行上的高效性的。根据到现在为此我们分析到的Android应用程序支持,我们在这方面必将面临挑战。像Activity之间进行跳转,我们如果处理跳转出的Activity所依附的那个进程呢?直接杀死掉,这时,当我们从被调用Activity返回时怎么办?
这也会是个比较复杂的问题。一是前一个进程的状态如何处理,二是我们又如何对待上一个已经暂时退出执行的进程。
我们老式的应用程序是不存在这样的问题的,因为它不具备跨进程交互的能力,唯一的有可能进行跨进程交互的方式是在应用程序之间进行复制/粘贴操作。而对于进程内部的界面之间的切换,实际上只会发生在同一个While循环里面,一旦退出某一个界面,则相应的代码都不会被执行到,直到处理完成再返回原始界面:

而这种界面模型,在Android世界里,只是一个UI线程所需要完成的工作,跟界面交互倒并不相关。我们的Android 在界面上进行交互,实际上是在Activity之间进行切换,而每个进程内部再维护一套上述的UI循环体:

在这样的运行模式下,如果我们退出了某一个界面的执行,则没有必要再维持其运行,我们可以通过特殊的设计使其退出执行。但这种调用是无论处理完,还是中途取消,我们还是会回到上一个界面,如果要达到一体化看上去像同一个应用程序的效果,这里我们需要恢复上一个界面的状态。比如我们例子里,我们打了联系列表选择了某个联系人,然后通过Gallery设置大头贴,再返回到联系人列表时,一定要回到我们正在编译联系人的界面里。如果这时承载联系人列表的进程已经退出了话,我们将要使整个操作重做一次,很低效。
所以综合考虑,最好的方式居然会是偷懒,对上个进程完全不处理,而需要提供一种暂停机制,可以让不处理活跃交互状态的进程进入暂停。当我们返回时则直接可以到上次调用前的那个界面,这时对用户来说很友好,在多个进程间协作在用户看来会是在同一个应用程序进行,这才是Android设计的初衷。
因为针对需要暂停的处理,所以我们的应用程序各个实体便有了生命周期,这种生命周期会随着Android系统变得复杂而加入更多的生命周期的回调点。但对于偷懒处理,则会有后遗症,如果应用程序一直不退出,则对系统会是一个灾难。系统会因为应用程序不断增加而耗尽资源,最后会崩溃掉。
不光Android会有这样的问题的,Linux也会有。我们一直都说Linux内核强劲安全,但这也是相对的,如果我们系统里有了一些流氓程序,也有可能通过耗尽资源的方式影响系统运行。大家可以写一些简单的例子做到这点,比如:
while(1)
{
char * buf = malloc (30 * 1000);
memset (buf, ‘a’, 30*1000);
if (!fork() )
fork();
} |
这时会发现系统还是会受到影响,但Linux的健壮性表现在,虽然系统会暂时因为资源不足而变得响应迟缓,但还是可以保证系统不会崩溃。为了进程数过多而影响系统运行,Linux内核里有一种OOM Killer(Out Of Memory Killer)机制,系统里通过一种叫notifier的机制(顾名思义,跟我们的Listener设计模式类似的实现)监听目前系统里内存使用率,当内存使用达到比率时,就开始杀掉一些进程,回收内存,这里系统就可以回到正常执行。当然,在真正发生Out Of Memory错误也会提前触发这种杀死进程的操作。
一旦发生OOM事件,这时系统会通过一定规则杀死掉某种类型的进程来回收内存,所谓枪打出头鸟,被杀的进程应该是能够提供更多内存回收机会的,比如进程空间很大、内存共享性很小的。这种机制并不完全满足Android需要,如果刚好这个“出头鸟”就是产生调用的进程,或是系统进程,这时反而会影响到Android系统的正常运行。
这时,Android修改了Linux内核里标准的OOM Killer,取而代之是一个叫LowMemKiller的驱动,触发Out Of Memory事件的不再是Linux内核里的Notifier,而由Android系统进程来驱动。像我们前面说明的,在Android里负责管理进程生成与Activity调用栈的会是这个系统进程,这样在遇到系统内存不够(可以直接通过查询空闲内存来得到)时,就触发Low Memory Killer驱动来杀死进程来释放内存。
这种设计,从我们感性认识里也可以看到,用adb shell free登录到设备上查看空闲内存,这时都会发现的内存的剩余量很低。因为在Android设备里,系统里空闲内存数量不低到一定的程度,是不会去回收内存的,Android在内存使用上,是“月光族”。Android通过这种方式,让尽可能多的应用程序驻留在内存里,从而达到一个加速执行的目的。在这种模型时,内存相当于一个我们TCP协议栈里的一个窗口,尽可能多地进行缓冲,而落到窗口之外的则会被舍弃。
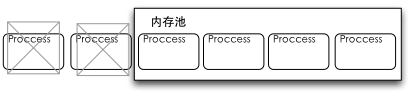
理论上来说,这是一种物尽其用,勤俭执家的做法,这样使Android系统保持运行流畅,而且从侧面也刺激了Android设备使用更大内存,因为内存越多则内存池越大,可同时运行的任务越多,越流畅。唯一不足之处,一些试图缩减Android内存的厂商就显得很无辜,精减内存则有可能影响Android的使用体验。
我们经常会见到系统间的对比,说Android是真实的多任务操作系统,而其他手机操作平台只是伪多任务的。这是实话,但这不是被Android作为优点来设计的,而只是整个系统设计迫使Android系统不得不使用这种设计,来维持系统的流畅度。至于多任务,这也是无心插柳柳成荫的运气吧。
Pre-runtime运算
在Android系统里,无论我们今天可以得到的硬件平台是多么强大,我们还是有降低系统里的运算量的需求。作为一个开源的手机解决方案,我们不能假设系统具备多么强劲的运算能力,出于成本的考虑,也会有产商生产一些更廉价的低端设备。而即便是在一些高端硬件平台之上,我们也不能浪费手机上的运算能力,因为我们受限于有限的电池供电能力。就算是将来这些限制都不存在,我们最好也还是减少不必要的损耗,将计算能力花到最需要使用它们的地方。于是,我们在前面谈到的各种设计技巧之外,又增加了降低运算量的需求。
这些技巧,貌似更高深,但实际上在Android之前的嵌入式Linux开发过程里,大家也被迫干过很多次了。主要的思路时,所有跟运行环境无关运算操作,我们都在编译时解决掉,与运行环境相关的部分,则尽可能使用固化设计,在安装时或是系统启动时做一次。
与运算环境无关的操作,在我们以前嵌入式开发里,Codec会用到,比如一些码表,实际上每次算出来都是同样或是类似的结构,于是我们可以直接在编译时就把这张表算出来,在运行时则直接使用。在Android里,因为大量使用了XML文件,而XML在运行时解析很消耗内存,也会占用大量内存空间,于是就把它在编译时解析出来,在应用程序可能使用的内存段位里找一个空闲位置放进去,然后再将这个内存偏移地址写到R.java文件里。在执行时,就是直接将二进制的解析好的xml树形结构映射到内存R.java所指向的位置,这时应用程序的代码在执行时就可以直接使用了。
在Android系统里使用的另一项编译态运算是prelink。我们Linux内核之睥系统环境,一般都会使用Gnu编译器的动态链接功能,从而可以让大量代码通过动态链接库的方式进行共享。在动态链接处理里,一般会先把代码编译成位置无关代码(Position Independent Code,PIC),然后在链接阶段将共用代码编译成.so动态链接库,而将可执行代码链接到这样的.so文件。而在动态链接处理里,无论是.so库文件还是可执行文件,在.text段位里会有PLT(Procedure Linkage Table),在.data段位里会有GOT(Global Offset Table)。这样,在代码执行时,这两个文件都会被映射到同一进程空间,可执行程序执行到动态链接库里的代码,会通过PLT,找到GOT里定位到的动态链接库里代码具体实现的位置,然后实现跳转。
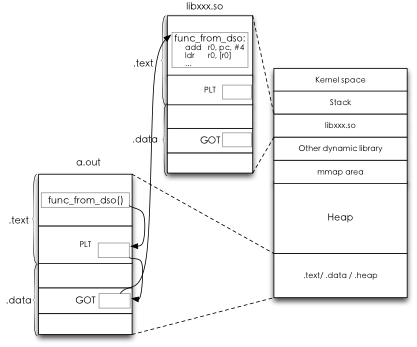
通过这样的方式,我们就可以实现代码的共享,如上图中,我们的可执行文件a.out,是可以与其他可执行程序共享libxxx.so里实现的func_from_dso()的。在动态链接的设计里,PLT与GOT分开是因为.text段位一般只会被映射到只读字段,避免代码被非法偷换,而.data段位映射后是可以被修改的,所以一般PLT表保持不动,而GOT会根据.so文件被映射到进程空间的偏移位置再进行转换,这样就实现了灵活的目的。同时,.so文件内部也是这样的设计,也就是动态链接库本身可以再次使用这样的代码共享技术链接到其他的动态链接库,在运行时这些库都必须被映射到同一进程空间里。所以,实际上,我们的进程空间可能使用到大量的动态链接库。
动态链接在运行时还进行一些运行态处理,像GOT表是需要根据进程上下文换算成正确的虚拟地址上的依稀,另外,还需要验证这些动态链接代码的合法性,并且可能需要处理链接时的一些符号冲突问题。出于加快动态连接库的调用过程,PLT本身也会通过Hash表来进行索引以加快执行效率。但是动态链接库文件有可能很大,里面实现的函数很多很复杂,还有可能可执行程序使用了大量的动态链接库,所有这些情况会导致使用了动态链接的应用程序,在启动时都会很慢。在一些大型应用程序里,这样的开销有可能需要花好几秒才能完全。于是有了prelink的需求。Prelink就是用一个交叉编译的完整环境,模拟一次完整地运行过程,把参与运行的可执行程序与动态链接所需要使用的地址空间都算出来一个合理的位置,然后再就这个值写入到ELF文件里的特殊段位里。在执行时,就可以不再需要(即便需要,也只是小范围的改正)进行动态链接处理,可以更快完成加载。这样的技术一直是Linux环境里一个热门研究方向,像firefox这样的大型应用程序经过prelink之后,可以减少几乎一半的启动时间,这样的加速对于嵌入式环境来说,也就更加重要了。
但这种技术有种致命缺陷,需要一台Linux机器,运行交叉编译环境,才能使用prelink。而Android源代码本就设计成至少在MacOS与Linux环境里执行的,它使用的交叉编译工具使用到Gnu编译的部分只完成编译,链接还是通过它自己实现的工具来完成的。有了需求,但受限于Linux环境,于是Android开发者又继续创新。在Android世界里使用的prelink,是固定段位的,在链接时会根据固定配置好地址信息来处理动态链接,比如libc.so,对于所有进程,libc.so都是固定的位置。在Android一直到2.3版本时,都会使用build/core/prelink-linux-arm.map这个文件来进行prelink操作,而这个文件也可以看到prelink处理是何其简单:
# core system libraries libdl.so 0xAFF00000 # [<64K] libc.so 0xAFD00000 # [~2M] libstdc++.so 0xAFC00000 # [<64K] libm.so 0xAFB00000 # [~1M] liblog.so 0xAFA00000 # [<64K] libcutils.so 0xAF900000 # [~1M] libthread_db.so 0xAF800000 # [<64K] libz.so 0xAF700000 # [~1M] libevent.so 0xAF600000 # [???] libssl.so 0xAF400000 # [~2M] libcrypto.so 0xAF000000 # [~4M] libsysutils.so 0xAEF00000 # [~1M] |
就像我们看到的,libdl.so,对于任何进程,都会是在0xAFD00001(libc.so结束)到0xAFF00000之间这个区域之间,而
在Android发展的初期,这种简单的prelink机制,一直是有效的,但这不是一种很合理的解决方案。首先,这种方式不通用,也不够节省资源,我们很难想像要在系统层加入firefox、openoffice这样大型软件(几十、上百个.so文件),同时虽然绝大部分的.so是应用程序不会用到的,但都被一股脑地塞了进来。最好,这些链接方式也不安全,我们虽然可以通过“沙盒”模式来打造应用程序执行环境的安全性,但应用程序完全知道一些系统进程使用的.so文件的内容,则破解起来相对比较容易,进程空间分布很固定,则还可以人为地制造一些栈溢出方式来进行攻击。
虽然作了这方面的努力,但当Android到4.0版时,为了加强系统的安全性,开始使用新的动态链接技术,地址空间分布随机化(Address Space Layout Randomization,ASLR),将地址空间上的固定分配变成伪随机分布,这时就也取消了prelink。
Android系统设计上,对于性能,在各方面都进行了相当成功的尝试,最后得到的效果也非常不错。大家经常批评Android整个生态环境很恶劣,高中低档的设备充斥市场,五花八门的分辨率,但抛开商业因素不谈,Android作为一套操作系统环境,可以兼容到这么多种应用情境,本就是一种设计上很成功的表现。如果说这种实现很复杂,倒还显得不那么神奇,问题是Android在解决一些很难的工程问题的时候,用的技巧还是很简单的,这就非常不容易了。我们写过代码的人都会知道,把代码写得极度让人看不懂,逻辑复杂,其实并不需要太高智商,反而是编程能力不行所致。逻辑清晰,简单明了,又能解决问题,才真正是大神级的代码,业界成功的项目,linux、git、apache,都是这方面的典范。
Android所有这些提升性能的设计,都会导致另一个间接收益,就是所需使用的电量也相应大大降低。同样的运算,如果节省了运算上的时间,变相地也减少了电量上的损失。但这不够,我们的手机使用的电池非常有限,如果不使用一些特殊的省电技术,也是不行的。于是,我们可以再来透过应用程序,看看Android的功耗管理。
1.5 功耗控制
在嵌入式领域,功耗与运算量几乎成正比。操作系统里所需要的功能越来越复杂、安全性需求越来越高,则会需要更强大的处理能力支持。像在老式的实时操作系统里,没有进程概念,不需要虚拟内存支持,这时即便是写一些简单应用,所需要的运算量、内存都非常小,而一旦换用支持虚拟内存的系统,则所需要的硬件处理能力、电量都会成倍上涨,像一些功能性手机平台,可以成为一台不错的手机,但运行起一个Linux操作系统都很困难。而随着操作系统能力增强,则所能支持的硬件又得以提升,可以使用更大的屏幕、使用更大量内存、支持更多的无线芯片,这些功能增强的同时,也进一步加剧了电量的消耗。虽然现在芯片技术不断提高生产工艺降低制程(就是芯片内部烧写逻辑时的门电路尺寸),几乎都已经接近了物理上的极限(40纳米、28纳米、22纳米),但是出于设计更复杂芯片为目的的,随着双核、四核、以及越来越高的工作频率,事实上,功耗问题不但没有降低,反而进一步被加剧了。
面对这样越来越大的功耗上的挑战,Android在设计上,必须在考虑其他设计因素之前,更关注功耗控制问题。Android在设计上的一些特点,使系统所需要的功耗要高于传统设计:Android是使用Java语言执行环境的,所有在虚拟机之上运行的代码都需要更大的运算量,使用机器代码中需要一条指令的地方,在虚拟机环境下执行则可能需要十几条指令;与其他伪多任务不同,Android是真实多任务的,多任务则意味着在同一时刻会有更多任务在运行;Android是构建上Linux内核之上的系统,Linux内核在性能上表现奇佳,在功耗处理上则是短板,就拿PC环境来说,Linux的桌面环境在功耗控制上从来不如其他操作系统,MacOS或是Windows。
当然,有时没有历史包袱,也未必就是坏事,比如Linux内核在功耗管理上做得还不够好,于是就不会在Linux内核环境里死磕,Android可以通过新的设计来进行功耗控制上的提升。出于跟前面我们所说过的可减小对Linux内核依赖性、加强系统可移植性的设计需求,于是不可避免的,功耗控制将会尽可能多地被推到系统的上层。在我们前面对于安全性的分层中可以看到,Android相当于把整个操作系统都在用户态重新设计了一次,SystemServer这个系统级进程相当于用户态的一个Linux内核,于是将功耗控制更多地抽到用户态来执行,也没有什么不合理的。
在Android的整体系统设计里,功耗控制会先从应用程序着手,通过多任务并行时减小不必要的开销开始;在整个系统构架里,唯一知道当前系统对功耗需求的是SystemServer,于是可以通过相应的安全接口,将功耗的控制提取出来,可由SystemServer来进行后续的处理。Android系统所面临的运行环境需求里,电源是极度有限的资源,于是功耗控制应该是暴力型的,尽可能有能力关闭不需要使用的电源输出。当然暴力关电,则可能引起某些外设芯片不正常工作,于是在芯片驱动里需要做小范围修改。与其他功能部分的设计不同,既然我们功耗控制是通过与驱动打交道来实现,可能无法避免地需要驱动,但要让修改尽可能小,以提供可移植性。
在这种修改方案里,最需要解决的当然首先是多任务处理。我们可以得到的就是我们的生命周期。所谓的生命周期,是不是仅仅只是提供更多一些编程上的回调接口而已呢?不仅如此,我们的所谓生命周期是一种休眠状态点,更多地起到休眠操作时我们有机会插入代码的作用。如果仅是提供编程功能,我们可以参考JAVA ME里对于应用程序实现:
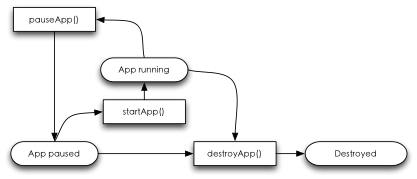
JAVA ME框架里对待应用程序只有三个状态点,运行、暂停、关闭,对应提供三种回调接口就可以驱动起这种编程模型。但我们的Android不是这样处理的,Android在编程模型上,把带显示与不带显示的代码逻辑分别抽象成Activity与Service,每种不同逻辑实现都有其独特的生命周期,以更好地融入到系统的电源管理框架里。
像我们的与显示相关的处理,Activity,它拥有6种不同状态:
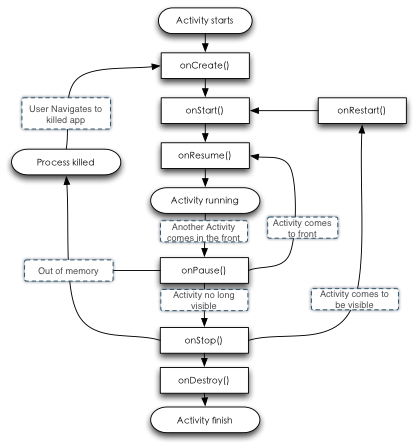
它的不同生命周期阶段,取决于这一Activity是否处于交互状态,是否处理可见状态。如果加入这两个限制条件,于是Activity的生命周期则是为这两种状态而设计的。onResume()与onResume()分别是进入交互与退出交互时的状态点,在onResume()执行完之后,这时系统进入了交互状态,也就是Activity的Running状态,而此时如果由于Activity发生调用或是另一个Activity主动执行,弹出一个小对话框,使原来处于Running状态的Activity被挡住,这时Activity就被视为不需要交互了,这时Activity进入不可见互状态,触发onPause()回调。onStart()与onStop()则是对应于是否可见,在onStart()回调之后,应用程序这里就可以被显示出来,但不会真正进入交互期,当Activity变得完全不可见之后,则会触发onStop()。而Android的多任务实现,还会造成进程会被杀死掉,于是也提供两个onCreate()与onDestroy()两种回调方法来提供进程被创建之后与进程被杀死之前的两种不同操作。
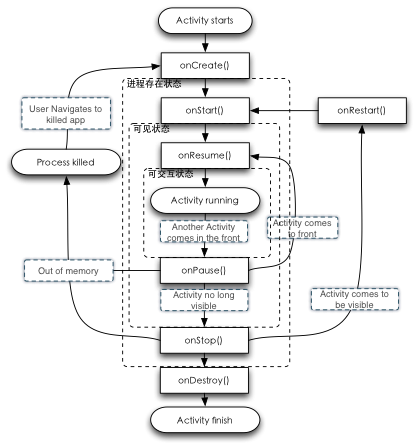
这种设计的技巧在于,当Activity处于可交互状况时,这是系统里的全马力执行的周期。而再向外走一个状态期,只是处于可见但不可交互状态时,我们就可以开始通过技巧降功耗了,比如此时界面不再刷新、可以关闭一些所有与用户交互相关的硬件。当Activity再进一步退出可见状态时,可以进一步退出所有硬件设备的使用,这时就可以全关电了。编写应用程序时,当我们希望它有不一样的表现时,我们可以去通过IoC去灵活地覆盖并改进这些回调接口,而假如这种标准的模型满足我们的需求,我们就什么都不需要用,自动地被这种框架所管理起来。
当然,这种模型也不符合所有的需求,比如对于很多应用程序来说,在后台不可见状态下,仍然需要做一些特定的操作。于是Android的应用程序模型里,又增加了一个Service。对于一些暴力派的开发者,比较喜欢使用后台线程来实现这种需求,但这种实现在Android并不科学,因为只通过Activity承载的后台线程,有可能会被杀死掉,在有状态更新需求时,后台线程需要通过Activity重绘界面,实际上这样也会破坏Android在功耗控制上的这种合理性设计。比较合适的做法,所有不带界面、需要在后台持续进行某些操作的实现,都需要使用Service来实现,而状态显示的改变应该是在onStart()里完成的,状态上的交互则需要放到onResume()方法里,这样的实现可以有效绕开进程被杀死的问题。并且在我们后面介绍AIDL的部分,还可以看到,这样实现还可以加强后台任务的可交互性,当我们进一步将Service通过AIDL转换成Remote Service之后,则我们的实现会具备强大的可复用性,多个进程都可以访问到。
Service也会有其生存周期,但Service的生存周期相对而言要简单得多,因为它的生存周期只存在“是否正在被使用”的区别。当然,同样出于Android的多任务设计,“使用中”这个状态之外,也会有进程是否存在的状态。

于是,我们的Service也可被纳入到这种代码活跃状态的受控环境,当是不需要与后台的Service发生交互,这时,我们可能只是通过一个startService()发出Intent,这时Service在执行完相应的处理请求则直接退出。而如果是一个AIDL方式抛出的Remote Service,或是自己进程范围内的Service,但使用bindService()进行了交互,这时,Service的运行状态,只处于onBind()与OnUnbind()回调方法之间。
当我们的应用程序的各种不同执行逻辑,都是处于一个可控状态下时,这时,我们的功耗控制就可以被集中到一个系统进程的SystemServer来完成。这时,我们面临一种设计上的选择,是默认提供一种松散的电源控制,让应用程序尽可能多自由地控制电源使用,还是提供一种严格逻辑,默认情况下实施严格的电源输出管理,只允许应用程序出于特殊的需求来调高它的需求?当然,前一种方式灵活,但出于电源的有限性,这时Android系统里使用了第二次逻辑,尽可能多地严格电源输出控制。
在默认情况下,Android会尝试让系统尽可能多地进入到休眠状态之中。在从用户开始进行了最后一次交互之后,系统则会触发一个计时器,计时器会在一定的时间间隔后超时,但每次用户的交互操作都会重置这一计时器。如果用户一直没有进行第二次交互,计时器超时则触发一些功耗控制的操作。比如第一步,会先变暗直至关闭系统的屏幕,如果在后续的一定时间内用户继续没有任何操作,这时系统则会进一步尝试将整个系统变成休眠状态。
休眠部分的操作,基本上是Linux内核的功耗控制逻辑了。休眠操作的最后,会将内存控制器设成自刷新模式,关掉CPU。到这种低功耗运行模式之下,这时系统功耗会降到最低,如果是不带3G模组的芯片,待机电流应该处于1mA以下。但我们的系统是手机,一般2G、3G、或是4G是必须存在的,而且待机状态时关掉这种不同网络制式下的Modem,也失去了手机存在的意义,于是,一般功耗上会加上一个移动Modem,专业术语是基带(Baseband)的功耗,这时一般要控制在10 – 30mA的待机电流,100mW左右的待机功耗。如果这时,用户按些某些用于唤醒的按键、或是基带芯片上过来了一些短信或是电话之类的信息,则系统会通过唤醒操作,回到休眠之前的状态。
但是Linux内核的Suspend与Resume方案,是针对ACPI里通用计算环境(我们的PC、笔记本、服务器)的功耗控制方案,并不完全与手机的使用需求相符合。而Linux内核所缺失的,主要是UI控制上功耗管理,手机平台上耗电最大的元器件,是屏幕与背光,是无法通过Linux内核的suspend/resume两级模型来实现高效的电源管理。于是,Android系统,在原始的suspend与resume接口之外,再增加了两级early_suspend与late_resume,用于UI交互时的提前休眠。
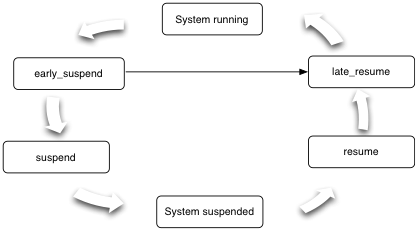
我们的Android系统,在出现用户操作超时的情况下,会先进入early_suspend状态点,关闭一些UI交互相关的硬件设备,比如屏幕、背光、触摸屏、Sensor、摄像头等。然后,在进一步没有相应唤醒操作时,会进入suspend关闭系统里的其他类的硬件。最后系统进入到内存自刷新、CPU关电的状态。如果在系统完全休眠的情况下,发生了某种唤醒事件,比如电话打进来、短信、或是用户按了电源键,这时就会先进resume,将与UI交互不相关的硬件唤醒,再进入late_resume唤醒与UI交互相关的硬件。但如果设备在进入early_suspend状态但还没有开始suspend操作之前发生了唤醒事件,这时就直接会走到late_resume,唤醒UI交互的硬件驱动,从而用户又可以看到屏幕上的显示,并且可以进行交互操作。
经过了这样的修改,在没有用户操作的情况下,系统会不断进入休眠模式省电,而用户并不会感受到这种变化,在频繁操作时,实际上休眠与唤醒只是快进快出的UI相关硬件的休眠与唤醒。但完全暴力型的休眠也会存在问题,比如我们有些应用程序,QQ需要保持登录,下载需要一直在后台下载,这些都不符合Android的需求的,于是,我们还需要一种机制,让某些特殊的应用程序,在万不得已的情况下,我们还是可以得这些应用程序足够的供电运行得下去。
于是Android在设计上,又提出了一套创新框架,wake_lock,在多加了early_suspend与late_resume之外,再加上可以提供功耗上的特殊控制。Wake_lock这套机制,跟我们C++里使用的智能指针(Smart pointer),借用智能指针的思想来设计电源的使用和分配。我们也知道Smart Pointer都是引用,则它的引用计数会自动加1,取消引用则引用计数减1,使用了智能指针的对象,当它的引用计数为0时,则该对象会被回收掉。同样,我们的wake_lock也保持使用计数,只不过这种“智能指针”的所使用的资源不再是内存,而是电量。应用程序会通过特定的WakeLock去访问硬件,然后硬件会根据引用计数是否为0来决定是不是需要关闭这一硬件的供电。
Suspend与wake_lock这两种新加入的机制,最后也是需要加放SystemServer这个进程里,因为这是属于系统级的服务,需要特权才能保证“沙盒”机制。于是,我们得到了Android里的电源管理框架:
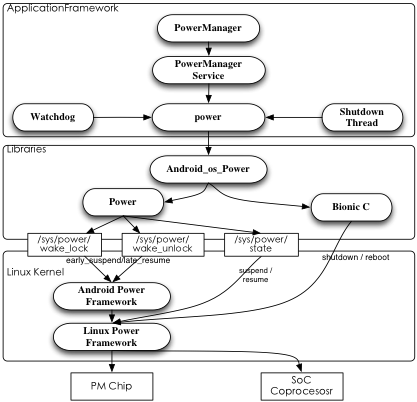
当然,这里唯一不太好的地方,就是Android系统设计必须对Linux内核原有的电源管理机制进行改动,需要加入wake_lock机制的处理,也需要在原始的内核驱动之上加入新的early_suspend与late_resume两个新的电源管理级别与wake_lock相配套。这部分的代码,则会造成Android系统所需要的驱动,与标准Linux内核的驱动并不完全匹配,同时这种简单粗暴的方式,也会破坏掉内核原有的清晰简要的风格。这方面也造成了Linux社区与Android社区之间曾一度吵得很凶,Linux内核拒绝Android提交的修改,而Android源代码则不再使用标准的Linux内核源代码,使用自己特殊的分支进行开发。
我们再来看Android系统对于功能接口的设计。
1.6 功能接口设计
我们实现一个系统,必须尽可能多地提供给应用程序尽可能多的开发接口,作为一个开源系统更应该如此。虽然我们前面提到了,我们需要有权限控制机制来限制应用程序可访问系统功能与硬件功能,但是这是权限控制的角度,如果应用程序得到了授权,应该有理由来使用这一功能,一个能够获得所有权限的应用程序,则理所当然应该享受系统里所提供的一切功能。
对于一个标准的Java系统,无论是桌面环境里使用的Java SE还是嵌入式环境里使用的Java ME,都不存在任何问题,因为这时Java本就只是系统的一层“皮”,每个Java写成的应用程序,只是一层底层系统上的二次封装,实际上都是借用底层操作系统来完成访问请求的。对于传统的应用程序,一个main()进入死循环处理UI,也不存在这个问题,通过链接到系统里的动态链接库或是直接访问设备文件,也可以实现。但这样的方式,到了Android系统里,就会面临一个功能接口的插分问题。因为我们的Android,不再是一层操作系统之上的Java虚拟机封装,而是抽象出来的在用户态运转的操作系统,同时还会有“沙盒”模式,应用程序并不见得拥有所有权限来访问系统资源,则又不能影响它的正常运行。
于是,对于Android在功能接口设计上,会被划分成两个层次的,一种是以“受托管”环境下通过一个系统进程SystemServer来执行,另一种是被映射到应用程序的进程空间内来完成。而我们前面分析的使用Java编程语言,而Framework层功能只以API方式向上提供访问接口,就变得非常有远见。使用了Java语言,则我们更容易实现代码结构上的重构,如果我们的功耗接口有变动,则可以通过访问接口的重构来隐藏掉这样的差异性;只以Framework的API版本为标准来支持应用程序,则进一步提供封装,在绝大部分情况下,虽然我们底层结构已经发生了巨大变动,应用程序却完全不受影响,也不会知道有这样的变化。
从这种设计思路,我们再去看Android的进程模型,我们就可以看到,通常意义上的Framework,实际上被拆分成两部分:一部分被应用程序用Java实现的classes.dex所引用,这部分用来提供应用程序运行所必须的功能;另一部分,则是由我们的SystemServer进程来提供。
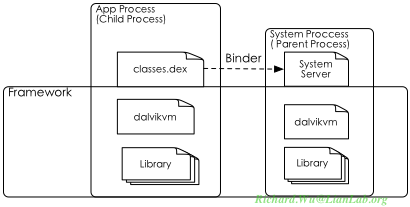
在应用程序只需要完成基本的功能,比如只是使用Activity来处理图形交互时,通过Activity来构建方便用户使用的一些功能时,这时会通过自己进程空间内映射的功能来完成。而如果要使用一些特殊功能,像打电话、发短信,则需要通过一种跨进程通讯,将请求提交到SystemServer来完成。
这种由于特殊设计而得到的运行模型很重要,也是Android系统有别于其他系统很重要的一个区别。这样的框架设计,使Android与传统Linux上所面临的易用性问题在设计角度就更容易解决。
比如显示处理。我们传统的嵌入式环境里,要不就是简单的Framebuffer直接运行,要么会针对通用性使用一个DirectFB的显示处理方案,但这种方案通用性很低,安全性极差。为了达到安全性,同时又能尽可能兼容传统桌面环境下的应用程序,大都会传承桌面环境里的一个Xorg的显示系统,比如Meego,以及Meego的前身Maemo,都是使用了Xorg用来处理图形。但Xorg有个很严重的性能问题:

使用Xorg处理显示的,所有的应用程序实际上只是一个客户端,通过Unix Socket,使用一种与传统兼容的X11的网络协议。用户交互,应用程序会在自己的交互循环里,通过X11发起创建窗口的请求,之后的交互,则会通过输入设备读取输入事件,再通过Xorg服务器,转回客户端,而应用程序界面上的重绘操作,则还是会通过X11协议,走回到Xorg Server之后,再进行最后的绘制与输出。虽然现在我们使用的经过模块化重新设计的XorgR7.7,已经尽可能通过硬件加速来完成这种操作,Xorg服务器还是有可能会成为整个图形交互的瓶颈,更重要的是复杂度太高,在这种构架里修改一个bug都有点困难,更不要说改进。在嵌入式平台上更是如此,性能本就不够的系统环境,Xorg的缺陷暴露无移,比如使用Xorg的Meego更新过程远比Android要困难,用户交互体验也比较差。
在Android里,处理模型则跟传统的Xorg构架很不一样。从设计角度来讲,绘制图形界面与获取输入设备过来的输入事件,本来不需要像Xorg那样的中控服务器,尤其像Android运行环境这样,并不存在多窗口问题(多窗口的系统需要有个服务器决定哪个窗口处于前台,哪个窗口处于交互状态中)。而从实现的角度,如果能够提供一种设计,将图形处理与最终输出分开,则更容易实现优化处理。基于图形界面的交互,实际上将由三个不同的功能实体来完成:应用程序、负责将图层进行叠加渲染的SurfaceFlinger、以及负责输入事件管理和选择合适的地址进行发送的SystemServer。当然,我们的上层的应用程序不会看到内部的复杂逻辑,它只知道通过android.view这个包来访问所有的图形交互功能。
于是得到Android系统的图形处理框架:

我们的SurfaceFlinger,是Android里的一种Native Service的实现,所以有原理上来说,只要有一个承载它的执行体(进程、线程皆可),就可以在系统里执行。在实现过程里,SurfaceFlinger作为一个线程在SystemServer这个进程空间里完成也是可以的,只是出于稳定性的考虑,一般将它独立成一个单独的SurfaceFlinger的独立进程。
这种设计,可以达到一个低耦合设计的优势,这套图形处理框架将变得更简单,同时也不会将Xorg那样需要大量的特殊内核接口与其适配,如果在别的操作系统内核之上进行移植,也不会有太大的依赖性。但这时会带来严重的性能问题,因为图层的处理和输出是需要大量内存的(如果是24位真彩色输出,即使是800x480的分辩率,每秒60桢的输出频率,也需要3*800*480*60 = 69120000,69M Byte/s),这种开销对于嵌入式方案而言,是难以承受的。在进程间传递数据时,会先需要在一个进程执行上下文环境里通过copy_from_user()把数据从用户态拷贝到内核态,然后在另一个进程执行的上下文环境里通过copy_to_user()把数据拷贝从内核态拷贝到另一个用户态环境,这样才能保证互不干扰。
而回过头来看Linux内核,搞过Linux内核态开发的都知道,在Linux系统的进程之间减小内存拷贝的开销,最直接的手段就是通过mmap()来完成内存映射,让保存数据的内存页只会在内核态里循环,这时就没有内存拷拷贝的开销了。使用了mmap()之后,内存页是直接在内核态分配的内存,两个进程都通过mmap()把这段区域映射到自己的用户空间,然后可以一个进程直接操作内存,另一个进程就可以直接访问到。在图层处理上,最好这些在内核态申请的内存是连续内存,这时就可以直接通过LCD控制器的DMA直接输出,Android于是提供了一种新的特殊驱动pmem,用来处理连续物理内存的分配与管理。同时,这种方式很裸,最好还在上层提供一次抽象,编程时则灵活度会更高,针对这种需求,就有了我们的Gralloc的HAL接口。加入了这两种接口之后,Android在图像处理上便自成体系,不再受限于传统实现了。
我们的图层,是由应用程序在创建是通过Gralloc来申请图层存储空间,然后被包装成上层的Surface类,在Activity实现里Surface则是按需要进行重绘(调用view的draw()方法),并在绘制完成后通过post()将绘制完成的消息发送给SurfaceComposer远程对象。而在SurfaceFlinger这段,则是将已经绘制完成的Surface通过其对应的模式,进行图层的合成并输出到屏幕。对于上层实现,貌似是一种很松散的交互,而对于底层实现,实际则是一种很高效的流水线操作。
这里,值得一提的是Surface本身也包含了图层处理加速的另一种技巧,就是double buffer技术。一个Surface会有两个图层buffer,一桢在后台被绘制,另一桢在前台进行输出。当后台绘制完成后,会通过一次Page Flipping操作,原来的后台桢被换到前台进行输出,而绘制操作则继续在后台完成。这样用户总会看到绘制完整的图像,因为图层总是绘制完成后才能输出。而有了double buffer,使我们图形输出的性能也得到提升,我们输出绘制与输出使用独立的循环,通过流水线加快了图层处理,尤其在Android里,可能有多个绘制的逻辑部分,性能得以进一步加速。在Android 4.1里面,这种图形处理得以进一步优化,使用了triple buffer(三重缓冲),加深了图层处理的流水线操作能力。
这种显示处理上的灵活性,在Android系统里也具备非常重要的意义,可以让整个系统在功能设计上可以变得更加灵活。我们提供了一种“零拷贝”图层处理技术之后,最终上层都可以通过一个特殊的可以跨进程的Surface对象来进行异步的绘制处理(如果我们不是直接操作控件,而是通过“打洞”方式来操作图形界面上的某个区域,则属于SurfaceView提供的,当然,这时也只是操作Surface的某一部分)。我们的Surface的绘制与post()异步进行的,于是多个执行体可以并行处理图层,而用户只会看到通过post()发送的图层绘制完成的同步事件之后的完整图层,图层质量与流畅性反而可以更佳。比如,我们的VOIP应用程序,可以会涉及多个功能实体的交互,Camera、多媒体编解码、应用程序、SurfaceFlinger。
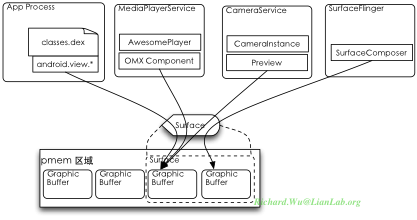
应用程序、多媒体编解码与Camera都只会通过一个Surface对象来在后台桢上进行交互界面的绘制,像前摄像头出来的回显,从网络解码出来的远端的视频,然后应用程序的操作控件,都将重绘后台图层。而如果这一应用程序处于Activity的可交互状态(见前面的生命周期的部分),就会通过找到同一Surface对象,将这一Surface对象的前台桢(也就是绘制完成但还没有输出的图层)输出。输出完则对这一Surface对象的前后两桢图层进行对调,于是这样的流水线则可以很完美的运行下去。
Android并非是最高效的方案,而只是一种通过面向对象方式完全重新设计的嵌入式解决方案,高效是其设计的一部分要素。如果单从效率角度出发,无进程概念的实时操作系统最高效,调度开销也小,没有虚址切换时的开销。作为Android系统,通过目前我们看到的功能性接口的设计,至少得到了以良好的构架为基础同时又兼顾性能的一种设计。
当然,我们前面所总结的,对于Android系统的种种特性,最终得到的一种印象是每种设计都是万能胶,同一种设计收获了多种的好处。那是不是这种方式最好,大家都应该遵循这种设计上的思路与技巧?That depends,要看情况。像Android这样要完整地实现一整套这种在嵌入式环境里运行的,面向对象式的,而且是基于沙盒模式的系统,要么会得到效率不高的解决方案,要么会兼顾性能而得到大量黑客式的接口。Android最终也就是这么一套黑客式的系统,这个系统一环套一环,作为系统核心部分的设计,都彼此过分依赖,拆都拆不开,对它进行拆分、精减或是定制,其实都很困难。但Android,其系统的核心就是Framework,而所谓的Framework,从软件工程学意义上来说,这样的构架却是可以接受的。所谓的Framework,对上提供统一接口,保持系统演进时的灵活性;对下则提供抽象,封装掉底层实现的细节。Android的整个系统层构架,则很好的完成了这样的抽象,出于这样的角度,我们来看看Android的可移植性设计。
1.7 可移植性
单纯从可移植性角度来说,Linux内核是目前世界上可移植性最强的操作系统内核,没有之一。目前,只要处理器芯片能够提供基本的运算能力(可以支撑多进程在调度上的开销),只要能够提供C语言的编译器(准确地说是Gnu C编译工具链),就可以运行Linux内核。Linux内核在设计上保持了传统Unix的特点,大部分使用了C语言开发,极少部分机器相关的代码使用汇编,这种结构使其可移植性很强。在Linux内核发展到2.6版本之后,这种强大的可移植性得到进一步提升,通过驱动模型与驱动框架的引入和不断加强,使Linux内核里绝大部分源代码几乎都没有硬件平台上的依赖性。于是,Linux内核几乎能够运行在所有的硬件平台之上,常见有的X86、ARM,不那么常见但可能也会在不知道不觉地使用到的有MIPS、PowerPC、Alpha,另外还有一些我们听都没有听过的,像Blackfin,Cris、SuperH、Xtensa,Linux内核都支持,平台支持可参考linux内核源代码的arch目录。甚至,出于Linux内核的可移植性,Linux一般也被作为芯片验证的工具,芯片从FPGA设计到最终出厂前,都会通过Linux内核来检测这一芯片是否可以运行,是否存在芯片设计上的错误。
得益于Linux内核,构建于其上的操作系统,多多少少可继承这样的可移植性。但Android又完成应用程序运行环境的二次抽象,在用户态几乎又构造出一层新的操作系统,于是它的可移植性多多少少会受此影响,而且,像我们前面所分析出来的,Android的核心层构建本身,也因为性能上的考虑,耦合性也有点强,于是在可移植性也会面临挑战。“穷山恶水出刁民”,正因为挑战大,于是Android反倒通过各种技巧来加强系统本身的可移植性,反而做得远比其他系统要好得多。Android在可移植性上的特点有:
- 按需要定制可移植性。与传统嵌入式Linux操作系统不同,Android在设计上有明确的设计思想与目标,不会为了使用更多开源软件而提供更高兼容性的编译环境,而是列出功能需求,按功能需求来定制所需要的开源软件。有些开源软件能够提供更复杂的功能,但在Android环境里,只会选择其验证过的必需功能,像蓝牙,BlueZ本身可以提供更复杂的蓝牙控制,但Android只选择了BlueZ的基本功能,更多功能是由Android自己来实现,于是减小了依赖性,也降低了移植时的风险性。
- 尽可能跨平台。与以前的系统相比,Android在跨平台上得益于Java语言的使用,使其跨平台能力更强,在开发上几乎可以使用任何Java环境可以运行的操作系统里。而在源代码级别,它也能够在MacOSX与Linux环境里进行编译,这也是一个大的突破。
- 硬件抽象层。Android在系统设计的最初,便规划了硬件抽象层,通过对硬件访问接口的抽象,使硬件的访问接口相对稳定,而具体的实现则可在底层换用不同硬件访问接口时灵活地加以实现,不要说应用程序,就是Framework都不会意识到这种变动。这是以前的嵌入式Linux操作系统所没有的一种优点。硬件抽象层的使用,使Android并不一定需要局限于Linux内核之上,如果将底层偷换成别的接口,也不会有太大的工作量。
- 实现接口统一的规范化。Android在构架上,都是奉行一种统一化的思路,先定义好API,然后会有Framework层的实现,然后再到硬件抽象层上的变动。API可在同一版本上拓展,Framework也在逐步加强,而硬件抽象层本身可提供的能力也越来越强,但这一切都在有组织有纪律的环境下进行,变动在任何一次版本更新上来看,都是增量的小范围变动,而不会像普通的Linux环境那样时刻都在变,时刻都有不兼容的风险。从可移植性角度来说,这种规范化提供的好处,便是大幅降低了移植时的工作量。
- 尽可能简单。简单明了是Android系统构成上的一大特色,这种特色在可移植性上也是如此。像编译环境,Android在交叉编译环境上,是通过固化编译选项来达到简编译过程的上的,最终,Android源代码的编译工程,会是一个个由Android.mk来构造的可编译环境,这当然会降低灵活性,但直接导致了这套框架在跨平台上表现非常出色。再比如硬件抽象层,同样的抽象在现代嵌入式操作系统上可能都有,但是大都会远比Android的HAL层要复杂,简单于是容易理解和开发,在跨平台性方面也会表现更好。
我们传统的嵌入式Linux环境,几乎都会遵从一种约定俗成的传统,就是专注于如何将开源软件精减,然后尽可能将PC上的运行环境照搬到嵌入式。在这种思路引导下开发出来的系统,可移植性本身是没什么问题的,只是不是跟X86绑定的源代码,铁定是可以移植。但是,这样构建出来的系统,一般都在结构上过于复杂,会有过多的依赖性,应用程序接口并不统一,升级也困难。所有这样的系统,最后反倒是影响到了系统的可移植性。比如开源嵌入式Linux解决方案,maemo,就是一个很好的例子:

对于Maemo的整体框架而言,我们似乎也可以看到类似于Android的层次化结构,但注意看这种系统组成时,我们就不难发现,这样的层次化结构是假的,在Maemo环境里,实际上就是一个小型化的Linux桌面环境,有Xorg,有gtk,有一大堆的依赖库,编程环境几乎与传统Linux没任何区别。这种所谓的软件上的构架,到了Maemo的后继者Meego,也是如此,只不过把gtk的图形界面换成了Qt的,然后再在Qt库环境里包装出所谓的UX,换汤不换药,这时,Meego还是拥有一颗PC的心。
一般这种系统的交叉编译环境,还必须构建在一套比较复杂的编译环境之上,通过在编译环境里模拟出一个Linux运行环境,然后才能编译尽可能多的源代码。这样的交叉编译环境有Open Embedded,ScratchBox等。虽然有不同的交叉编译实现上的思路,但并没有解决可移植性问题,它们必须在Linux操作系统里运行,而且使用上的复杂程度,不是经验丰富的Linux工作者还没办法灵活使用。即便是比较易用的ScratchBox,也会有如下令人眼花缭乱的结构。

针对这样的现状,Android在解决可移植性问题时的思路就要简单得多。既然原来的尝试不成功,PC被精减到嵌入式环境里效果并不好,这时就可以换一种思路,一种“返璞归真”的思路,直接从最底层来简化设计,简化交叉编译。这样做法的一个最重要前提条件,就是Android本身是完整重新设计与实现的,是一个自包含的系统,所有的编译环境,都可以从源代码里把系统编译出来。
在系统结构上,Android在设计上便抛弃了传统的大肆搜刮开源代码的做法,由自己的设计来定位需要使用的开源代码,如果没有合适的开源代码,则会提供一个简单实现来实现这一部分的功能。于是,得到我们经常见到的Android的四层结构:
从这样简化过的四层结构里,最底层的Linux内核层,这些都与其他嵌入式Linux解决方案是共通的特性,都是一样的。其他三层就与其他操作系统大相径庭了:应用程序层是一种基于“沙盒”模式的,以功能共享为最终目的的统一开发层,并非只是用于开发,同时还会通过API来规范这些应用程序的行为;Framework层,这是Android真正的核心层,而从编程环境上来说,这一层算是Java层,任何底层功能或硬件接口的访问,都会通过JNI访问到更低层次来实现;给Framework提供支撑的就是Library层,也就是使用的一个自己实现的,或是第三方的库环境,这一层以C/C++编写的可以直接在机器上执行的ELF文件为主。
有了这种更简化的层次关系,使Android最后得到的源代码相对来说更加固定,应用程序这层我们只会编译Java,Framework层的编译要么是Java要么是JNI,而Library层则会是C/C++的编译。在比较固定的编译目标基础上,编译环境所需要解决的问题则会比较少,于是更容易通过一些简化过的编译环境来实现。Android使用了最基本的编译环境GnuMake,然后再在其上使用最基本的Gnu工具链(不带library与动态链接支持)来编译源代码,最后再通过简化过的链接器来完成动态链接。得到的结果是几乎不需要编译主机上的环境支持,从而可以在多种操作系统环境里运行,Android的编译工程文件还比较简单,更容易编写,Android.mk这种Android里的编译工程文件,远比天书般的autoconf工具要简单,比传统的Makefile也更容易理解。

Android的编译系统,由build目录里一系列.mk编译脚本和其他脚本组成,以build/main.mk作为主入口。main.mk文件会改到配置项,然后再通过配置项循环地去编译出所需要的LOCAL_MODULE。而这些LOCAL_MODULE的编译目标,是由Android.mk来定义的,而到底如何编译目标对象,则是由简单的include $(BUILD_*)这样的编译宏选项来提供,比如include $(BUILD_SHARED_LIBRARY)则会编译生成动态链接库.so文件。这样的编译系统抛弃autoconf的灵活性,换回了跨平台、编写简单。
当然,这样的编译工具,也不是没有代价的,使用简易化的Android编译环境则意味着Android放弃了一些现有绝大部分代码的可移植性,Linux环境里的一些常用库移植到Android环境则需要大量移植工作,像万能播放器核心ffmpeg,目前几乎只有商用应用程序才肯花精力将它移植到Android系统里。
当然,光有自己代码结构,光有更简易的编译环境,并不解决所有问题,我们的Android系统,最后还必须通过访问系统调用、读写驱动的设备文件来完成底层的操作。不然我们的Android系统就只会是一个光杆司令,什么都不是,没有任何功能。既然我们拥有了相关简化的系统结构,我们在内部自己按自己的想法去访问硬件也是可以,只是这样在升级与维护起来的代码会变得很大,比如我们通过”/dev/input/event0”来读触摸屏,”/dev/input/event1”来读重力感应器,如果换个平台,这些设备名字变了怎么办?或者有些私有化平台,都完全不使用这样的标准化设备文件命名时怎么办?难道针对每个平台准备一份源代码来做这些修改?于是就有了内部访问接口统一化的问题,Android在对于底层的设备文件的访问上,又完成了一层抽象,也就是我们的硬件抽象层。
硬件抽象层,准确地说,是介于Framework层与Linux内核层之间的一个层次,Framework通过硬件抽象层的统一接口来向下访问,在Linux内核上硬件访问接口上的差异性,则通过硬件抽象层来进行屏蔽。硬件抽象层,英文是Hardware Abstraction Layer,简称HAL,于是也就是我们常见到的AndroidHAL层。
提供硬件抽象层之后,这时Framework层与底层Linux内核之间的耦合性,就完全消除掉了。如果要将Android部署到其他操作系统、或是操作系统内核之上,只需要将HAL层的相应接口实现换成其他平台上的访问机制即可,而Framework只会使用HAL层的统一接口向下访问,完全不知道底层变动信息。
在Android的世界里,硬件抽象其实是包含多种含义的,可能会有多种的硬件访问实现,比如RIL、BlueZ这样的尽可能兼容已有解决方案的广义上的HAL,Framework会通过Socket来访问传统方式实现的daemon,也有Gralloc、Camera这样先定义Framework向下访问的接口,然后由硬件向上提供接口实现的狭义上的HAL。我们的Android上的HAL实现,更多地专指狭义上的HAL,由源代码里的hardware目录提供。
狭义上的HAL,在实现上也会分成两种:一种基于函数直接访问的方式来实现,这种方式比较简单粗暴,所以在命名上,被称为libhardware_legacy实现,由目录hardware/libhardware_legacy里实现的一个个动态链接库来实现;另一种则使用了面向对象的技巧,上层通过一个hardware_module_t来访问,而具体的某一类HAL的实现,则会将这一hardware_module_t按需求进行拓展,这种方式被称为libhardware实现,由hardware/libhardware提供hardware_modult_t的访问接口,硬件访问的实现部分,也是动态链接库文件,但会在运行时根据板卡的具体配置,进行动态加载。从长远看,libhardware_legacy结构的HAL实现是一种中间方案,在Android发展过程里有可能会被libhardware方式的实现所取代,比如Android 4.0里,Audio、Camera完成了libhardware_legacy到libhardware的转变。
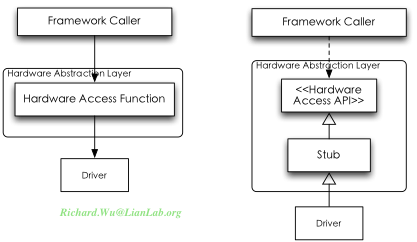
从设计的角度来看,libhardware_legacy虽然解决了与Linux内核的耦合问题,但是直接函数接口的访问,终究还是灵活性不够。以libhardware_legacy实现HAL的动态链接库,必须被直接链接到Framework的实现里,通过JNI进行直接访问,不具备动态性,不能支持同一份Android可执行环境支持不同硬件平台。从设计角度来说,任何抽象都是由另一次间接调用来实现,于是,我们在硬件访问接口里再加入一层抽象,这就是libhardware.so。Framework并不直接访问具体的动态链接库实现,而是通过libhardware.so里实现的通用接口来向下访问,并且也只会调用到预定义好的一些访问接口,而HAL实现的,是以Stub方式来提供到系统里一些功能访问的具体实现。如果不好理解的,可以认为是系统提供头文件,也就是我们右图中的<<Hardware Access API>>,这些只是接口类定义。而实现上,并不是直接通过头文件来实现,而是通过实现一个具有一定特性的hardware_module_t的数据结构,来向上提供具体的函数调用接口,与头文件里所需要的接口相对应。为什么叫它Stub呢?是因为在libhardware这种模式里,把接口定义与具体的实现抽离开来,虽然不一定会使用面向对象语言来实现(一般是通过C来实现的),但提供了Interface+Stub这样面向对象式的实现,所以libhardware有时也被称为stub模式实现的HAL。
使用libhardware之后,HAL层实现上的可复用性与运行时的灵活性则被大大增强了。在libhardware框架下,Framework都不再直接调用HAL层,而是通过hw_get_module()方法来在/system/lib/hw和/system/vendor/lib/hw这两个目录里循环寻找合适的.so实现,比如针对sensor,会有sensor.default.so,sensor.goldfish.so,sensor.xxx.so,会有不同种实现,以用于加载合适的实现。虽然这些只会在开机时执行一次,但通过简单方式至少也实现了用同一份二进制代码提供多种硬件平台的支持。使用libhardware实现的HAL,当我们的实现的HAL有问题时,我们可以删掉有问题的HAL,此时启动时会使用一个xxx.default.so的纯软件实现的不进行任何硬件访问的.so文件,让我们还是可以绕开启动时的HAL加载错误。
Android这种强化可移植性的设计,最终使Android的移植移植过程变得相对比较简单。如果是做Android的手机或是平板的开发,也许我们需要做的只是提供板块相关的配置文件,从而可以改变一些编译时的配置参数。如果我们的硬件平台跟Android源代码时使用的标准平台(比如Google的“亲儿子”手机Nexus系列的产品,或是pandaboard这样作为参考设计的产品),对于移植过程而言,我们可能什么都不需要做,直接可以编译运行,然后再做产品化的微调;如果我们使用的硬件平台跟某些产商提供的开源项目的硬件结构一样,比如Qualcomm提供的codeaurora.org,TI的Omapedia,还有各大厂商都涌跃参与的linaro.org项目等等,这时需要完成的移植工作也会类似的很小;如果我们的提供的硬件平台跟Android这些已有的开源资源很不一样,这时,我们需要完成的移植工作也不会很大,只需要根据特定的硬件平台实现HAL,这一过程所需要的工作量远小于其他平台的移植过程。
Android的移植过程,基本上分为:
- Bootloader与Linux内核的移植
- Repo环境(Android源代码基于repo管理,最后使用repo)
- 交叉编译器、Bionic C库与Dalvik虚拟机的移植(如果不是ARM、X86和MIPS这三种基本构架)
- 提供板卡支持所需要的配置
- 实现所需要使用的HAL
- Android产品化,完成界面或是功能上的定制
这些移植过程的步骤如下图所示:
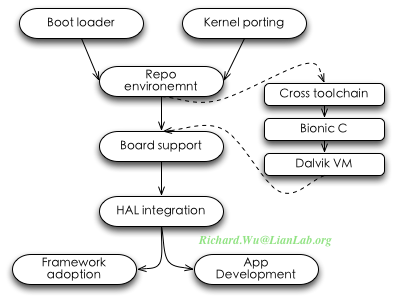
对于我们做Android移植与系统级开发而言,可能我们所需要花的代码并不是那么大。像Bootloader与Linux内核的移植,这一般都在进行Android系统移植时早就会就绪的,比如我们去选购某个产商的主芯片时(Application Processor,术语为AP),这些Android之前的支持大都已经就绪。而作为产业的霸主,我们除非极其特殊的情况,我们也不需要接触交叉编译器和Dalvik虚拟机的移植。所以一般情况下,我们的Android移植是从建立repo源代码管理环境开始,然后再进行板卡相关的配置,然后实现HAL。而Android的产品化这个步骤,Framework的细微调整与编写自己平台上特殊的应用程序,严格意义上来说,Framework也不属于Android移植工作范围内的,我们一般把它定位于Android产品化或是Android定制化这个步骤里。Android移植相对来说非常简单,而真正完成Android产品化则会是一个比较耗时耗人力的过程。
所谓的板卡的配置文件,一般是放在一个专门的目录里,在2.3以前,是发在vendor目录下,从2.3开始,vendor目录只存放二进制代码,配置文件移到了device目录。在这一目录里,会以“产商名/设备名”的命名方式来规范配置的目录结构。比如是产商名是ti,设备名是panda,则会以“device/ti/panda”来存放这些配置文件,再在这个目录里放置平台相关的配置项。配置文件,则是会几个关键文件构成:
} vendorsetup.sh,使用add_lunch_combo将配置项导入编译环境
} AndroidProducts.mk,这是会被编译系统扫描的文件,通过在这一文件里再导入具体的编译配置文件,比如ti_panda.mk
} ti_panda.mk,在这一文件里定义具体的产品名,设备名这些关键变量,这些变量是在Android编译过程里起关键配置作用的变量。一般说来,这个文件不会很复杂,主要依赖导入一些其他的配置文件来完成所有的配置,比如语言配置等。而设备特殊的设置,则一般是使用同目录下的device.mk文件来进行定制化的设置。
} device.mk,在这一文件会使用一些更加复杂一些配置,包含一些需要编译的子工程,设置某些特殊的编译参数,以及进行系统某些特性的定制化,比如需要自定义怎样的显示效果、配置文件等
} BoardConfig.mk,在这一文件则是板子相关的一些定制项,以宏的方式传入到编译过程里,比如BOARD_SYSTEMIMAGE_PARTITION_SIZE来控制system分区的大小, TARGET_CPU_SMP来控制是否需要使用SMP(对称多处理器)支持等。一般,对于同一个板卡环境,这些参数可以照抄,勿须修改。
所有的这些配置文件,并不是必须的,只不过是建议性的,在这一点上也常会透露出产商在开源文化的素质。毕竟是开源的方案,如果都使用约定俗成的解决方案,则大家都会不用看也知道怎么改。但一些在开源做得不好的厂商,对这些的配置环境都喜欢自己搞一套东西出来,要显得自己与众不同,所以对于配置文件的写法与移植过程,也需要具体情况具体对待。
当我们完成了这些配置上的工作后,可以先将这些配置上传到repo的服务器管理起来,剩下的移植工作就是实现所需要的HAL了。在Android移植过程里,很多HAL的实现,是可以大量复用的,可以找一个类似的配置复制过来,然后再进行细微调整,比如使用ALSA ASoC框架的音频支持,基本功能都是通用的,只需要在Audio Path和HiJack功能上进行微调即可。