欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
预览效果
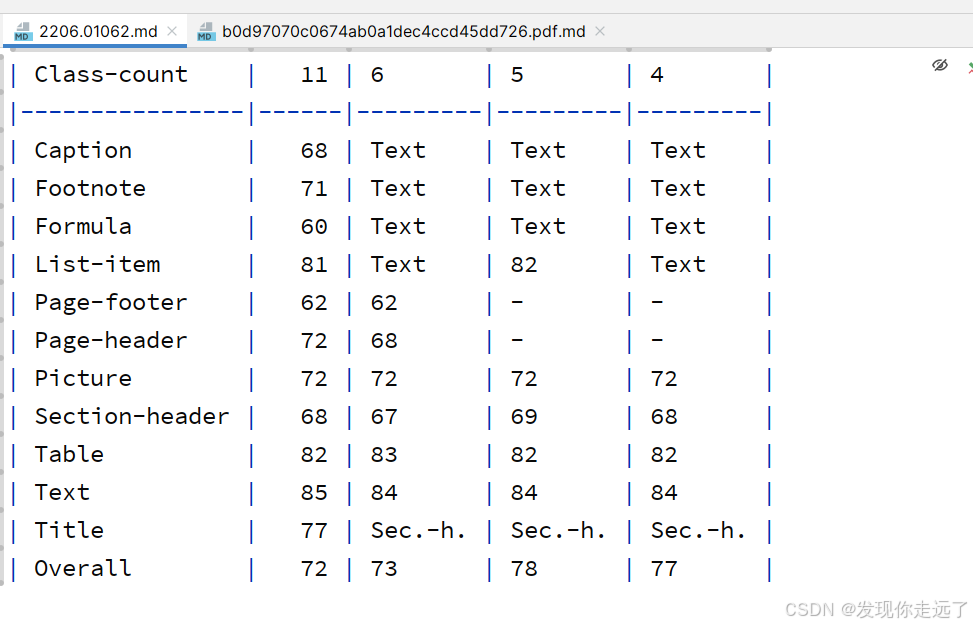
支持转化pdf的表格
安装
Docling 本身是专注于文档转换的工具,通常用于将文件(如 PDF)转换为其他格式(如 Markdown)
要求python3.11版本+
pip install docling
下载模型
- 第一次运行需要下载外网的模型,需要tz保证网络通畅,否则会一直飘红报错
- 可能需要较长时间计算分析,尤其是你没有GPU 使用CPU的情况
Fetching 9 files: 100%|██████████| 9/9 [00:00<00:00, 15840.85it/s]
Neither CUDA nor MPS are available - defaulting to CPU. Note: This module is much faster with a GPU.
测试代码
from docling.document_converter import DocumentConverter
# 第一次运行需要下载外网的模型,需要tz保证网络通畅
# 外网pdf论文
# source = "https://arxiv.org/pdf/2206.01062" # document per local path or URL
# 可以是网页
# source = "https://blog.csdn.net/u011027547/article/details/143885170" # document per local path or URL
# 可以是pdf
source = "https://www.gov.cn/zhengce/zhengceku/2022-11/12/5726417/files/b0d97070c0674ab0a1dec4ccd45dd726.pdf" # document per local path or URL
# 初始化 DocumentConverter
converter = DocumentConverter()
# 执行转换
result = converter.convert(source)
# 获取转换后的 Markdown 内容
markdown_content = result.document.export_to_markdown()
# 保存到 .md 文件
with open(source.split('/')[-1]+".md", "w", encoding="utf-8") as md_file:
md_file.write(markdown_content)
print("Markdown 文件已保存为 "+source.split('/')[-1]+".md")
总结
大家喜欢的话,给个👍,点个关注!给大家分享更多计算机专业学生的求学之路!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2023 mzh
Crated:2023-3-1
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
『未完待续』