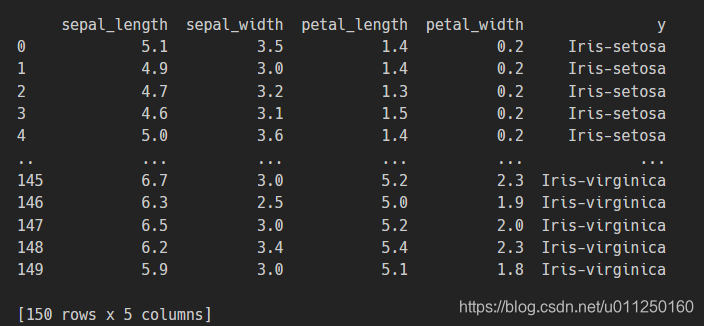
使用的数据集是iris
一共150行数据,
三种花各有50行数据,
这里取了前100行,
选两种花进行二分类。
数据集地址:https://github.com/hydra-ZD/AI/blob/main/iris.data
import torch
import numpy as np
import pandas as pd
import torch.nn as nn
import matplotlib.pyplot as plt
import torch.nn.functional as F
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torch.utils.data import random_split
from torch.utils.data import TensorDataset
class dataset(Dataset):
def __init__(self):
data = pd.read_csv('c:/Users/Administrator/Desktop/iris/iris.data',names=['sepal_length','sepal_width','petal_length','petal_width','y'])
data['new_y'] = data.iloc[:,[4]].replace(['Iris-setosa',