一、连接查询
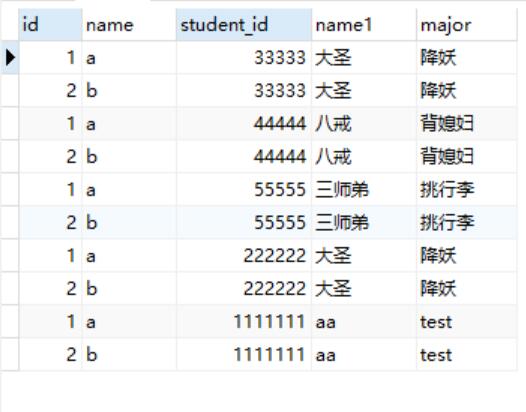
1、交叉连接:CROSS JOIN 把表A和表B的数据进行一个NM的组合,即笛卡尔积。如本例会产生44=16条记录,在开发过程中我们肯定是要过滤数据,所以这种很少用。
DROP TABLE IF EXISTS `t2`;
CREATE TABLE `t2` (
`student_id` int(11) NOT NULL,
`name` varchar(32) DEFAULT NULL,
`major` varchar(32) DEFAULT NULL,
PRIMARY KEY (`student_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `t1`;
CREATE TABLE `t1` (
`id` int(11) NOT NULL,
`name` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
SELECT *
FROM t1
CROSS JOIN t2
2、**内连接:**SELECT * FROM TableA INNER JOIN TableB ON TableA.name = TableB.name
INNER JOIN 产生的结果是AB的交集 。
从左表中取出每一条记录,去右表中与所有的记录进行匹配: 匹配必须是某个条件在左表中与右表中相同最终才会保留结果,否则不保留.
基本语法:左表 [inner] join 右表 on 左表.字段 = 右表.字段; on表示连接条件: 条件字段就是代表相同的业务含义(如my_student.c_id和my_class.id)
字段别名以及表别名的使用: 在查询数据的时候,不同表有同名字段,这个时候需要加上表名才能区分, 而表名太长, 通常可以使用别名.
内连接可以没有连接条件: 没有on之后的内容,这个时候系统会保留所有结果(笛卡尔积)
内连接还可以使用where代替on关键字,但效率差很多。
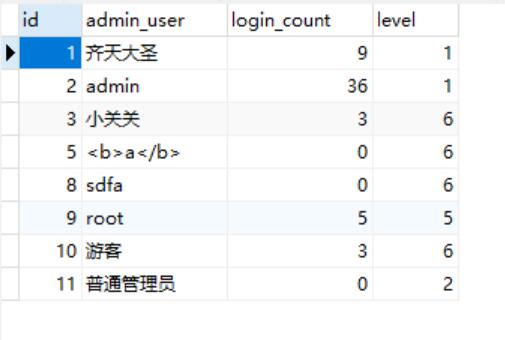
DROP TABLE IF EXISTS `cms_manage`;
CREATE TABLE `cms_manage` (
`id` int(11) NOT NULL,
`admin_user` varchar(32) DEFAULT NULL,
`login_count` int(11) DEFAULT NULL,
`level` int(32) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
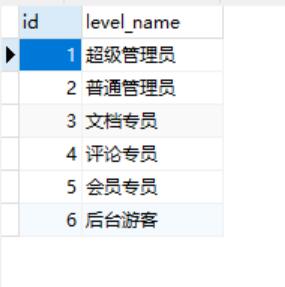
DROP TABLE IF EXISTS `cms_level`;
CREATE TABLE `cms_level` (
`id` int(11) NOT NULL,
`level_name` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
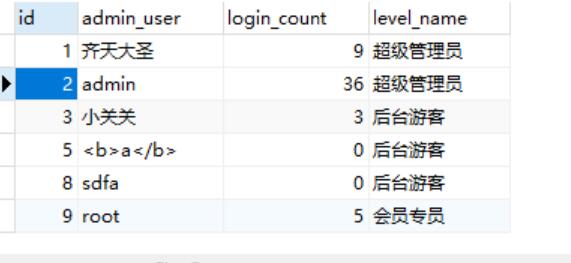
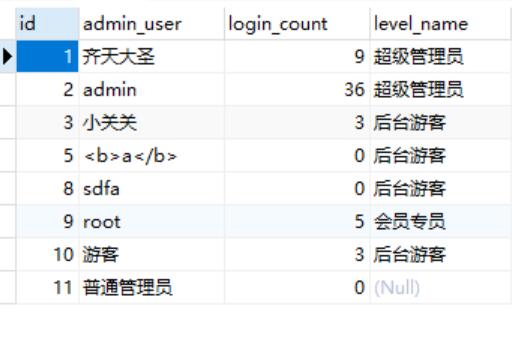
SELECT
m.id,
m.admin_user,
m.login_count,
l.level_name
FROM
cms_manage as m
JOIN cms_level as l ON m.level = l.id
3、外连接: 以某张表为主,取出里面的所有记录, 然后每条与另外一张表进行连接: 不管能不能匹配上条件,最终都会保留: 能匹配,正确保留; 不能匹配,其他表的字段都置空NULL.
外连接分为两种: 是以某张表为主: 有主表
left join: 左外连接(左连接), 以左表为主表
right join: 右外连接(右连接), 以右表为主表
基本语法: 左表 left/right join 右表 on 左表.字段 = 右表.字段;
修改成
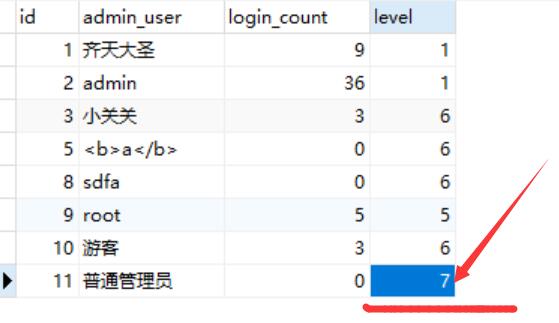
SELECT
m.id,
m.admin_user,
m.login_count,
l.level_name
FROM
cms_manage as m
LEFT JOIN cms_level as l ON m.level = l.id
4、**自然连接:**略(基本不用自然连接)
**
二、联合查询
**
1、**联合查询:**将多次查询(多条select语句), 在记录上进行拼接(字段不会增加)
基本语法:多条select语句构成: 每一条select语句获取的字段数必须严格一致(但是字段类型无关)
Select 语句1
Union [union选项]
Select语句2…
Union选项: 与select选项一样有两个
All: 保留所有(不管重复)
Distinct: 去重(整个重复): 默认的
SELECT *
FROM t2
UNION
SELECT *
FROM t2

SELECT *
FROM t2
UNION all
SELECT *
FROM t2

联合查询只要求字段一样, 跟数据类型无关
SELECT *
FROM t1
UNION all
SELECT *
FROM t2

联合查询的意义:
-
查询同一张表,但是需求不同: 如查询学生信息, 男生身高升序, 女生身高降序.
-
多表查询: 多张表的结构是完全一样的,保存的数据(结构)也是一样的.
FROM t2
WHERE `name`="大圣"
UNION all
SELECT *
FROM t2
WHERE `name`="aa"
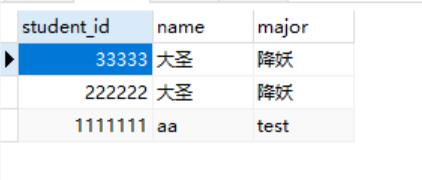
Order by使用
在联合查询中: order by不能直接使用,需要对查询语句使用括号才行;另外,要orderby生效: 必须搭配limit: limit使用限定的最大数即可.

**
三、子查询
**
子查询: 查询是在某个查询结果之上进行的.(一条select语句内部包含了另外一条select语句).
子查询分类
子查询有两种分类方式: 按位置分类;和按结果分类
按位置分类: 子查询(select语句)在外部查询(select语句)中出现的位置
From子查询: 子查询跟在from之后
Where子查询: 子查询出现where条件中
Exists子查询: 子查询出现在exists里面
按结果分类: 根据子查询得到的数据进行分类(理论上讲任何一个查询得到的结果都可以理解为二维表)
标量子查询: 子查询得到的结果是一行一列
列子查询: 子查询得到的结果是一列多行
行子查询: 子查询得到的结果是多列一行(多行多列) (1,2,3出现的位置都是在where之后)
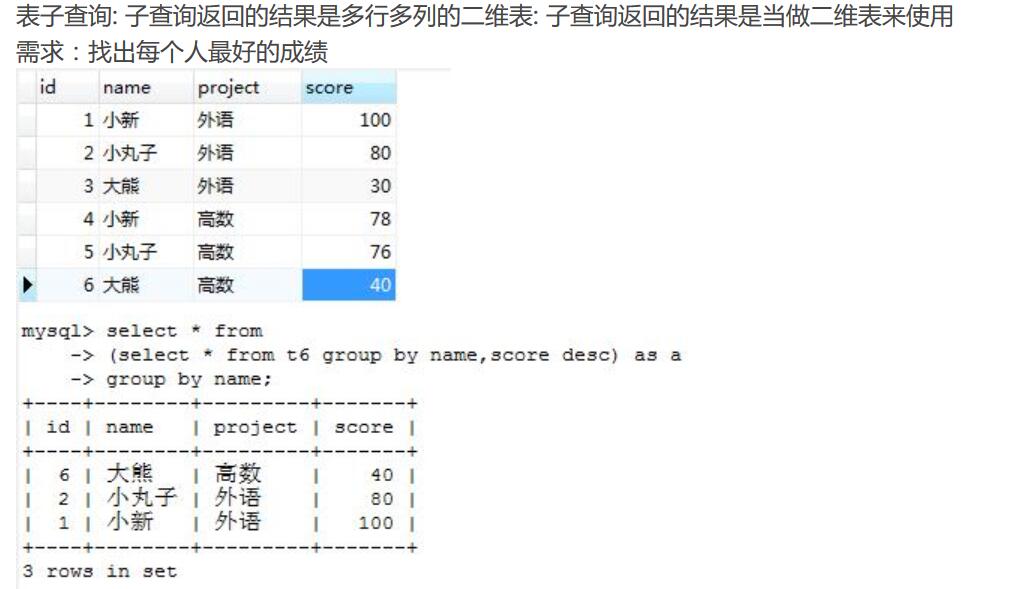
表子查询: 子查询得到的结果是多行多列(出现的位置是在from之后)
1、标量子查询
需求: 找到分类为科技的所有文章标题
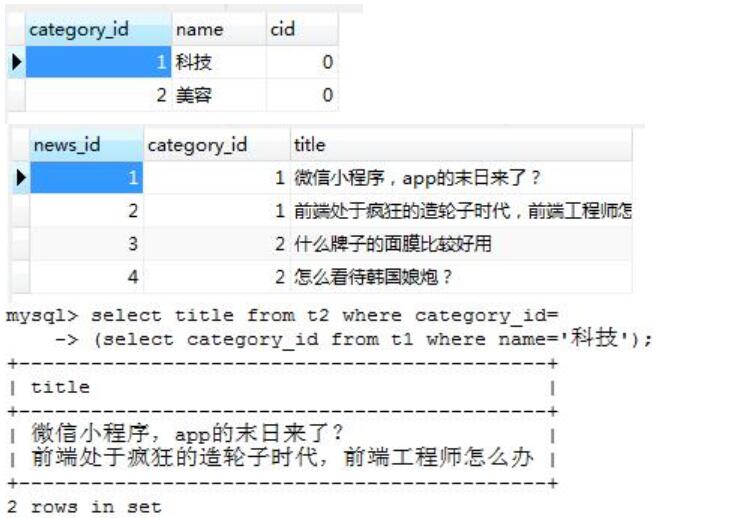
SELECT title
FROM t22
WHERE category_id=(SELECT category_id FROM t11 WHERE name='科技')
列子查询

行子查询

表子查询
Exists子查询