一,首先漫画的搜索,漫画每章节的标题,每章节的图片数量,这些东西都是最基础的数据,直接使用get方法就可以得到。
二,对于付费章节来说,每张图片的src链接都是使用js加密的。熟悉js的应该可以很简单就解析出来(本人完全小白,花费了很长时间解析,主要是走了很多弯路)。以下就是js解析的过程。
(1)获取章节源码:
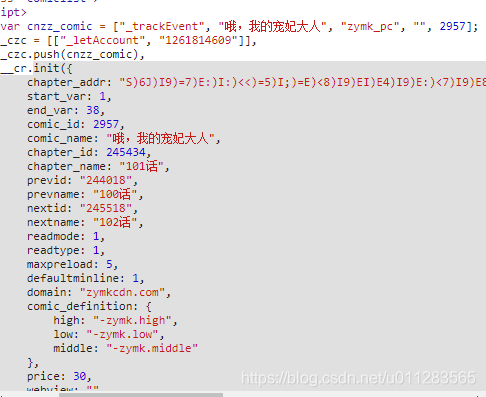
1,使用requests.get()直接获取,然后分析获取到的数据,我们发现:
如上图,这个script内容语法还是很简单的,__cr.init()代表要调用js中的init方法,然后去对应js中寻找该方法。至于如何找到对应js,可以在浏览器的开发者工具network里面如下图:
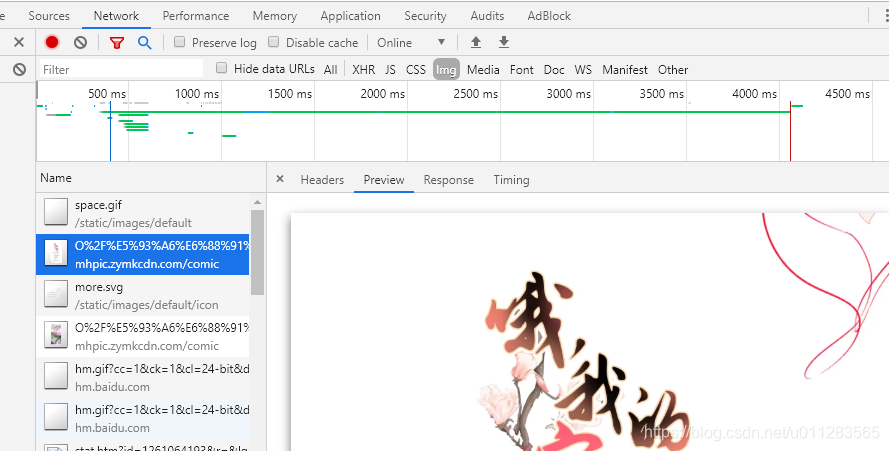
2,使用preview确定这个图片即是我们想要解析的
然后点headers旁边的X,就会出现该图片浏览器渲染解析该图片所要调用的js内容,可以看到,它要调用entry.read.e6782f.js