文章目录
前言
随着人工智能的不断发展,深度学习模型的体量也变得越来越大,但在某些应用场景下,深度学习模型的大体量却容易成为项目落地的障碍,因此我们迫切地需要想办法把模型变小。这里介绍一种能解决该痛点的轻量化模型Knowledge distillation(知识蒸馏)。
一、Knowledge distillation(知识蒸馏)是什么?
废话不多说,直接上文章,Distilling the Knowledge in a Neural Network,大家感兴趣的可以去阅读原论文,我也把代码附在本了文末的链接。下面来简单介绍一下这篇论文。
1.论文的研究动机
这是2014年发表在NIPS的一篇经典文章,作者有Geoffrey Hinton, Oriol Vinyals,和Jeff Dean. 大佬在文章的中介绍到,知识蒸馏是为了解决集成学习中算力消耗大,运算时间长,难以在移动端部署的问题而提出的。核心思想是训练一个小网络模型来模仿一个预先训练好的大型网络或者集成学习的网络。换种更形象的说就像是“teacher-student”模式,大型网络是“教师网络”,小型网络就是“学生网络”。这样我们将寄希望于学生网络能用更小的参数学习到教师网络的知识。
2.何为Knowledge(知识)
众所周知,深度学习模型之所以能行,核心在于其数量庞大的模型参数,这些参数通过配合激活函数经层层运算后,计算得出预测结果。如果把参数比喻成一个人的血肉,那么预测的结果就是血肉凝聚而成的精神灵魂。以多分类任务为例,我们有多个类别[cow,dog,cat,car,…],那么dog的labels为[0,1,0,0,…],网络输出predictions为[0.05,0.3,0.2,0.005,…],可以看出模型将图像分类为cow的概率是将其分类为car的概率的10倍。在这里label可以看做为hard targets,网络预测得到prediction可看做为soft targets,显然soft targets蕴含着更丰富的信息。而作者Hinton在论文中着重强调的学生网络需要从教师网络中蒸馏的便是这种潜藏的“知识”。

3.蒸馏知识的方法
既然网络的预测结果中蕴含着潜藏的知识,那么又如何将其蒸馏出来呢,文章中给到的方法是:
a.获取预先练好的教师网络所输出的一个类别的概率分布
b.把教师网络的输出预测作为学生网络的指导,输出一个类别概率分布
c.设计学生网络的损失函数,最小化以上两个概率分布之间的差距
总结起来,其实还是那句话,即训练一个学生网络模型来模仿一个预先训练好的教师网络模型所预测输出的概率分布。
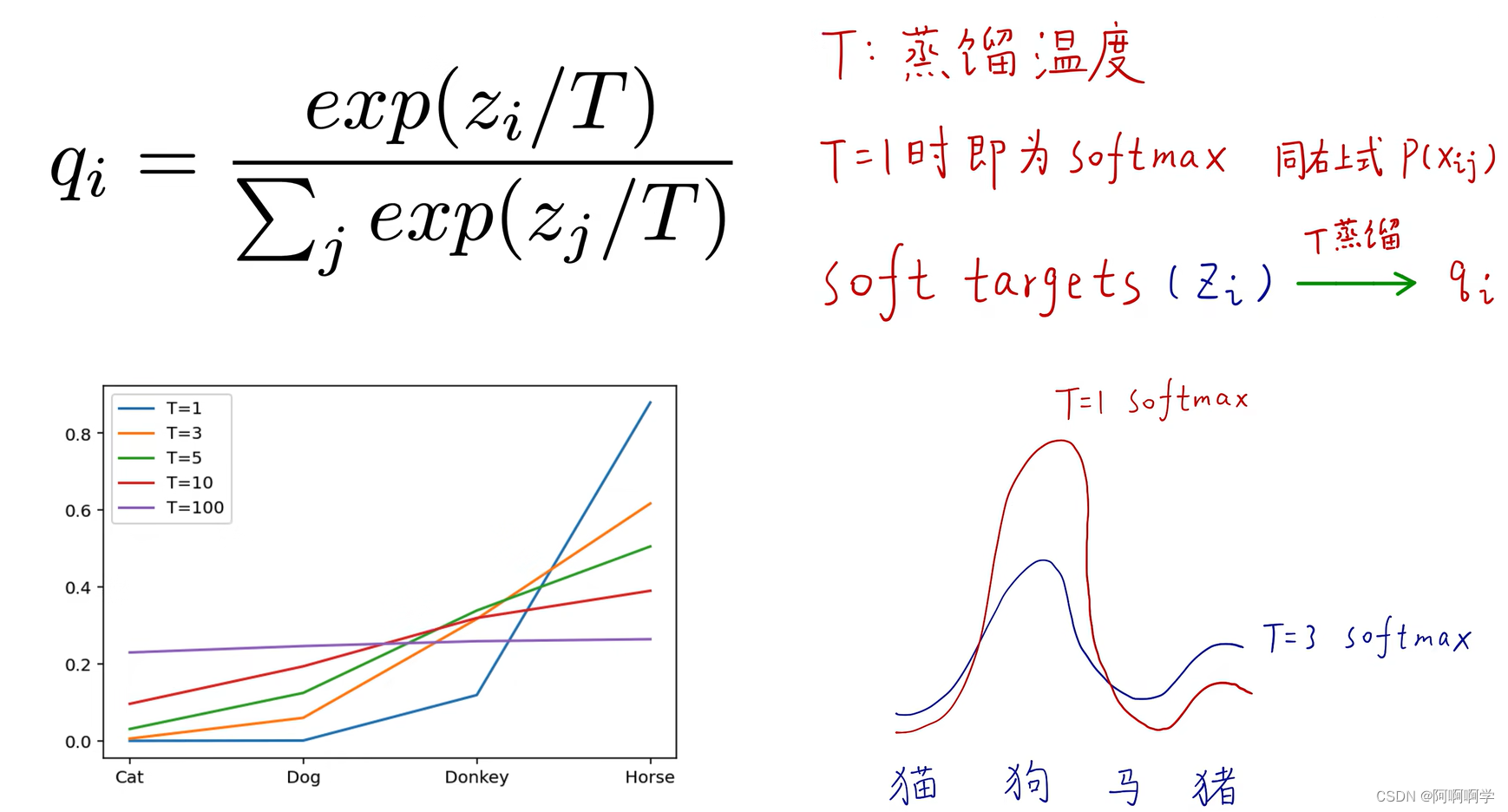
4.温度参数T(temperature)
想要让知识从教师网络中蒸馏出来,还需要用到温度参数T来修正输出标签的soft度,才能把输出的Soft Target变得更加Sof。蒸馏温度T使用在softmax函数中,如下图,当T为1是,整个式子就是原始的softmax函数,当T等于3时,可以看到softmax的曲线改变了很多,相关分类的相似度降低了,其他不相关分类的相似度有所增加。左下角的图可以看到,当T变大,每个分类所获得的相似度就越平均(越soft),太大的话每个分类的相似度就会相同,越小会发现每个类别的差异会很大。softmax是做归一化,凸显每个分类之间的差别。
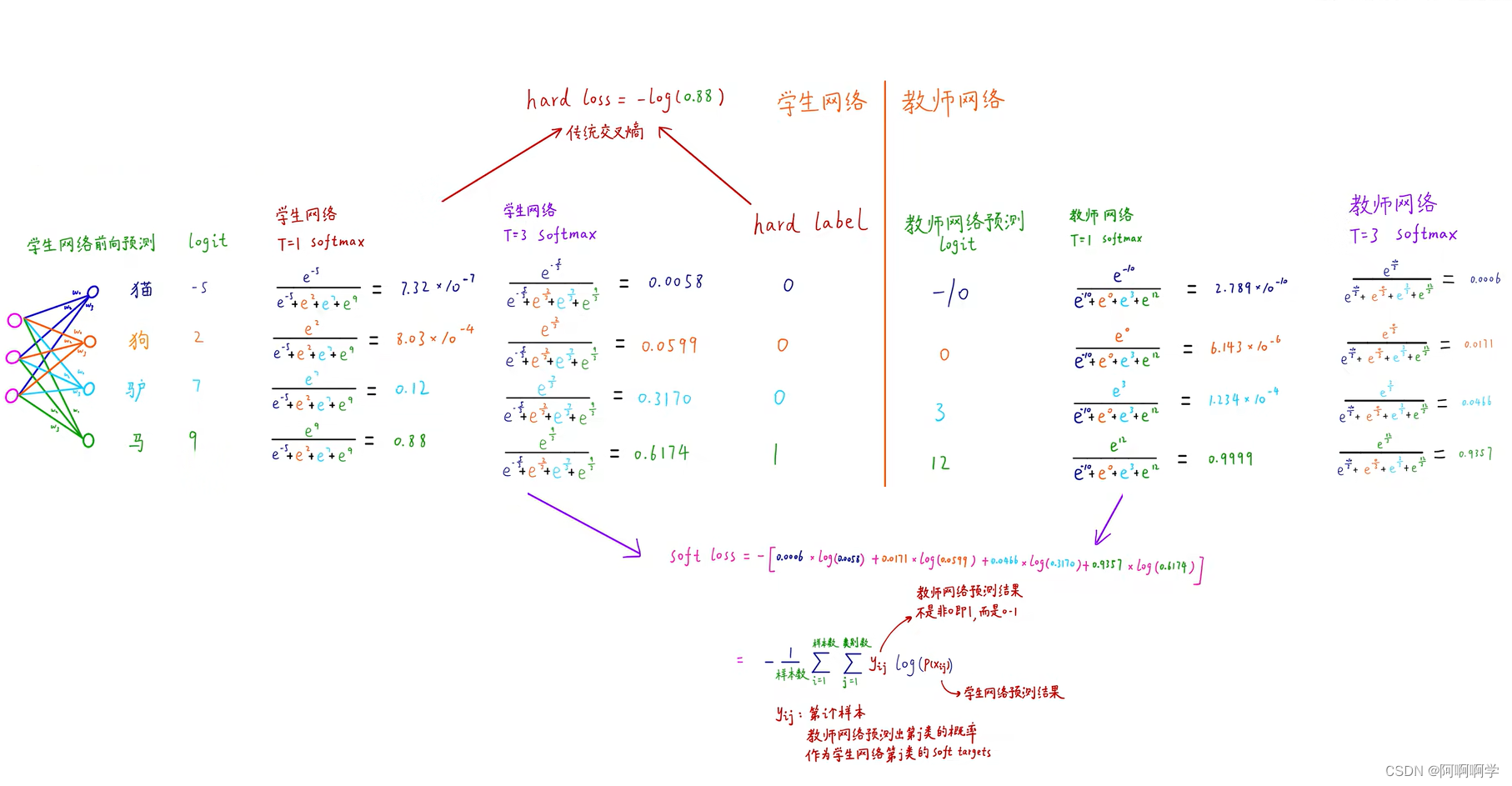
5.蒸馏的过程
万事具备,只欠东风。既然已经了解了蒸馏的方法,还有所需控制的温度,接下来要做的便是如何把控student模型的训练过程了。
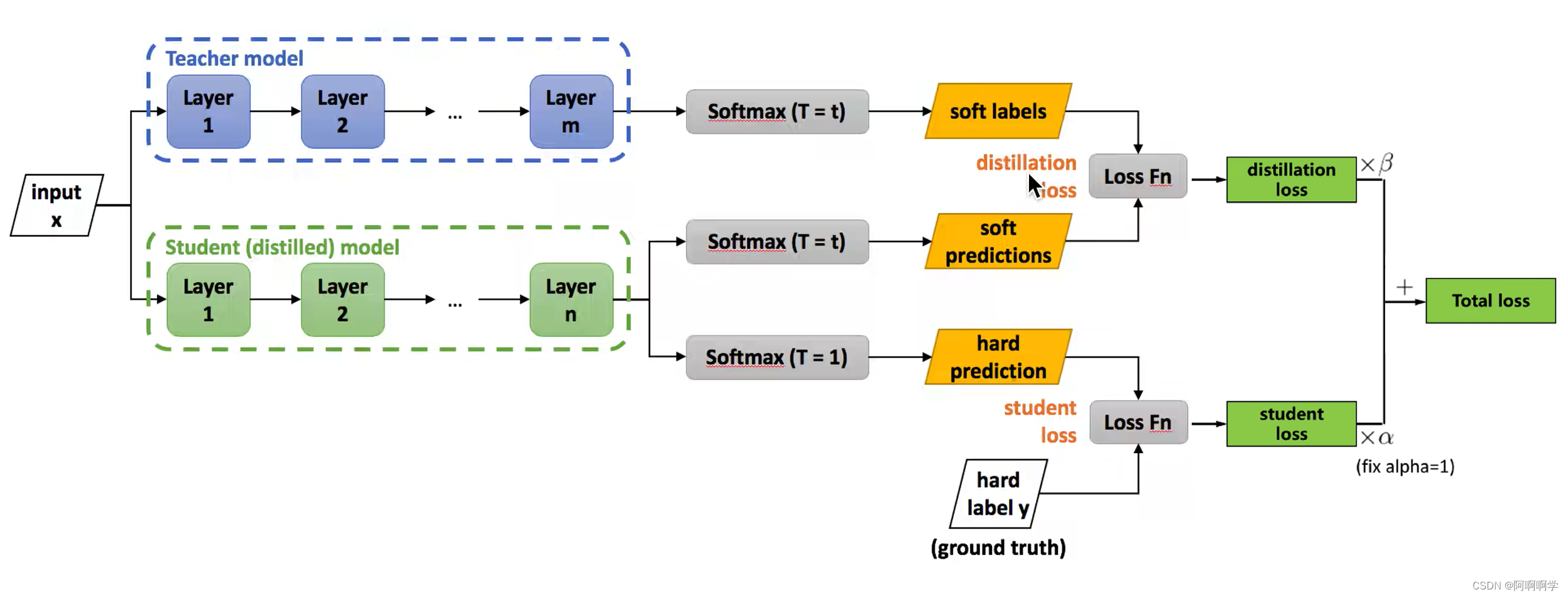
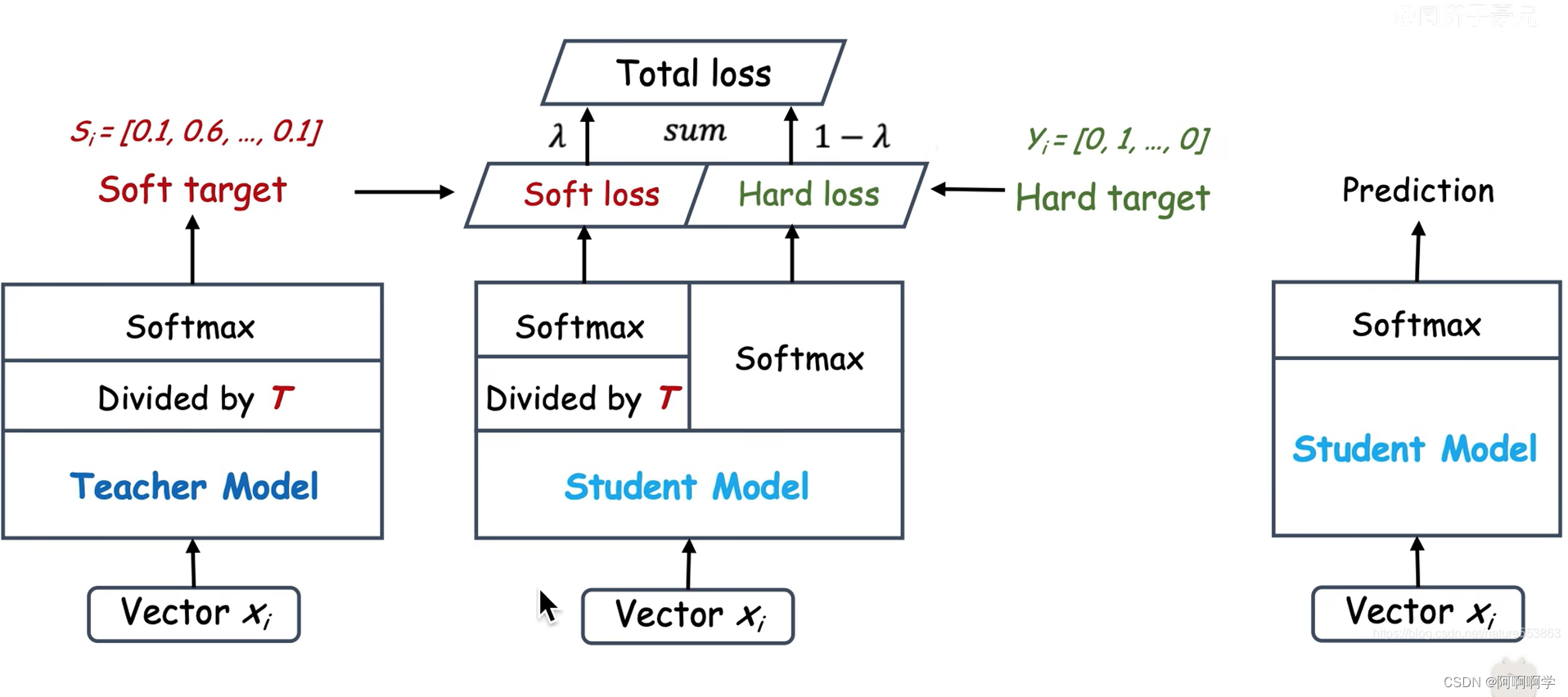
首先教师网络和学生网络都要经过添加了蒸馏温度T的softmax,二者进行一个loss求值,这个loss被称为disiliation loss,这个过程是学生网络在模拟老师网络的预测结果。
其次学生网络还要使用不添加蒸馏温度T的softmax进行一次计算,然后将结果和hard label进行一次loss计算,这里的loss称为student loss,这部分是学生网络在模拟真正的结果。
最后的把步骤一得到的disiliation loss和步骤二得到的student loss进行加权求和,便得到了最终控制student模型的loss。
二、代码部分
1.引入库
import os
from teacher import teach
from student import stu
import torch
import torch.optim as optim
from torch.optim.lr_scheduler import StepLR
import torch.nn as nn
from torch.autograd import Variable
from utils import get_training_dataloader, get_test_dataloader
from torch.nn import functional as F
from utils import get_training_dataloader_cifar10, get_test_dataloader_cifar10
2.读入数据
# set data path
split_dir = os.path.join("F:\deep learning\My KD", "data", "data_split")
test_dir = os.path.join(split_dir, "test")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
# set data label
data_label = {"0negative": 0, "1positive": 1}
# set batchsize
BATCH_SIZE = 32
# set GPU
use_cuda = torch.cuda.is_available()
dtype = torch.cuda.FloatTensor if use_cuda else torch.FloatTensor
# set data mean and std
CIFAR10_TRAIN_MEAN = (0.485, 0.456, 0.406)
CIFAR10_TRAIN_STD = (0.229, 0.224, 0.225)
# Data Package
cifar10_training_loader = get_training_dataloader_cifar10(train_dir, data_label, BATCH_SIZE, num_workers=0, shuffle=True)
cifar10_test_loader = get_test_dataloader_cifar10(valid_dir, data_label, BATCH_SIZE, num_workers=0, shuffle=True)
3.训练代码
# set epoch,T and lambda_stu
EPOCH = 30
T,lambda_stu=5.0,0.05
# load teacher model
teacher=teach()
#net = xception()
teacher.load_state_dict(torch.load("F:/deep learning/My KD/pth/teacherNet_t.pth",map_location='cpu')
teacher.eval()
teacher.train(mode=False)
# load student model Waiting for training
student=stu()
# set optimizer、scheduler and lossfunction
optimizer = optim.Adam(student.parameters(),lr=1e-4,amsgrad=True,weight_decay=1e-4)
#optimizer = optim.SGD(student.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
scheduler = StepLR(optimizer, step_size=10, gamma=0.5)
lossKD=nn.KLDivLoss()
lossCE= nn.CrossEntropyLoss()
# start train
best_loss=None
best_acc=None
for i in range(1,EPOCH+1):
train(i)
loss,accuracy=eval_training(i)
best_loss,best_acc=save_best(loss,accuracy,best_loss,best_acc)
print(best_acc)
需要调用的train(), eval_training(), save_best()函数
def train(epoch):
student.train()
for batch_index, (images, labels) in enumerate(cifar10_training_loader):
if use_cuda:
images, labels = images.cuda(), labels.cuda()
images = Variable(images)
labels = Variable(labels)
optimizer.zero_grad()
# get student loss
y_student = student(images)
loss_student = lossCE(y_student, labels)
#get teacher software loss composed of teachers model and students model
y_teacher=teacher(images)
#y_student使用 F.log_softmax,而y_teacher使用F.softmax 是由于pytorch的nn.KLDivLoss()的计算方式造成的.
loss_teacher=lossKD(F.log_softmax(y_student / T, dim=1),F.softmax(y_teacher / T, dim=1))
#get KD loss
loss=lambda_stu*loss_student+(1-lambda_stu)*T*T*loss_teacher
loss.backward()
#Calculate and print the results
correct_1=0
#_,pred=y_student.topk(5,1,largest=True,sorted=True)
_,pred=y_student.topk(2,1,largest=True,sorted=True)
labels=labels.view(labels.size(0),-1).expand_as(pred)
correct=pred.eq(labels).float()
correct_1 += correct[:, :1].sum()
#correct_1 += correct[:, :1].sum()#top5
optimizer.step()
print(
'Training Epoch: {epoch} [{trained_samples}/{total_samples}]\tLoss: {:0.4f}\ttop-1 accuracy: {:0.4f}\t'.format(
loss.item(),(100.*correct_1)/len(y_student),epoch=epoch,
trained_samples=batch_index * BATCH_SIZE + len(images),
total_samples=len(cifar10_training_loader.dataset))
)
scheduler.step()
def eval_training(epoch):
student.eval()
test_loss = 0.0 # cost function error
correct = 0.0
for (images, labels) in cifar10_test_loader:
if use_cuda:
images, labels = images.cuda(), labels.cuda()
with torch.no_grad():
images, labels = Variable(images), Variable(labels)
outputs = student(images)
loss = lossCE(outputs, labels)
test_loss += loss.item()
_, preds = outputs.max(1)
correct += preds.eq(labels).sum()
loss = test_loss / len(cifar10_test_loader.dataset)
accuracy = (100. * correct.float()) / len(cifar10_test_loader.dataset)
print('Test set: Average loss: {:.4f}, Accuracy: {:.4f}'.format(
test_loss / len(cifar10_test_loader.dataset),
(100.*correct.float())/ len(cifar10_test_loader.dataset))
)
return loss,accuracy
def save_best(loss, accuracy, best_loss, best_acc):
if best_loss == None:
best_loss = loss
best_acc = accuracy
file = 'Pth/Stu_distillation.pth'
torch.save(student.state_dict(), file)
elif loss < best_loss and accuracy > best_acc:
#损失更小且准确率更高
best_loss = loss
best_acc = accuracy
file = 'Pth/Stu_distillation.pth'
torch.save(student.state_dict(), file)
return best_loss, best_acc
总结
这篇论文开创了模型压缩中的一个新方向,是蒸馏领域的开山之作,其蒸馏思想在NLP、CV等领域均有成功应用,并都证明了该方法的有效性和普适性,能够将大模型的知识迁移到小模型中,使得小模型拥有了大模型的能力。并且推动了轻量化网络的理论研究和应用落地。
此外压缩网络还可以采用以下方法,我们下期再讲。
————————————————
参考文章链接:https://blog.csdn.net/charles_zhang_/article/details/123627334
