2024-11-22,由Google DeepMind和MATS机构创建的ViSTa数据集,为评估视觉语言模型(VLMs)在理解基于顺序的任务方面的能力提供了新的视角,这对于强化学习中的成本降低和安全性提升具有重要意义。
数据集地址:ViSTa|视觉语言模型数据集|强化学习数据集
一、研究背景
强化学习(RL)在需要复杂顺序决策的任务中表现出色,如游戏和机器人技术。然而,为许多任务手工制作可靠的奖励函数是困难的,而且优化一个不完全捕捉我们意图的代理奖励函数可能导致意外甚至不安全的行为。
目前遇到困难和挑战:
1、手工制作奖励函数不仅困难而且成本高昂,无法精确指定的任务难以通过人类监督来教授。
2、人类监督可能因为无法细查每一帧而被策略欺骗,而这些策略表面上看起来表现良好但实际上并未完成任务。
3、尽管视觉语言模型(VLMs)在对象识别方面表现出色,但它们在理解顺序任务方面的能力尚未得到充分验证。
数据集地址:ViSTa|视觉语言模型数据集|强化学习数据集
二、让我们来看一下ViSTa数据集
ViSTa(Vision-based understanding of Sequential Tasks):是一个包含4000多个视频和逐步描述的层次化数据集,用于评估VLMs在不同复杂性任务中的表现。涵盖了虚拟家庭、Minecraft和现实世界环境中的任务视频,其独特的层次结构允许对VLMs在不同复杂性任务中的判断能力进行细粒度的理解。
数据集构建:
ViSTa数据集通过结合现有的训练数据集和基准测试,创建了包含基本单步任务的视频,这些任务可以组合成越来越复杂的多步任务。
数据集特点:
1、层次化结构:从单一动作任务到多动作任务的递进。
2、多环境覆盖:包括虚拟家庭、Minecraft和现实世界视频。
3、细粒度理解:允许对VLMs在不同复杂性任务中的表现进行评估。
使用ViSTa数据集,研究人员可以评估多种VLMs,包括CLIP、ViCLIP和GPT-4o等,通过视频描述匹配方法来测试模型对任务序列的理解。
基准测试:
通过ViSTa评估的模型显示,尽管它们在对象识别方面表现出色,但在理解顺序任务方面却表现不佳,只有GPT-4o实现了非平凡的性能。

ViSTa 是一个带有分步描述的视频分层数据集。ViSTa 支持在三种不同环境中对任务序列进行精细测试。任务按子任务的数量组织到 8 个级别的层次结构中。关卡中的视频被分组为问题集(图 D)。 2) 测试特定功能。

操作顺序理解的问题集。问题集是要与其描述匹配的视频组。每个集合都针对特定功能,例如理解 操作顺序。
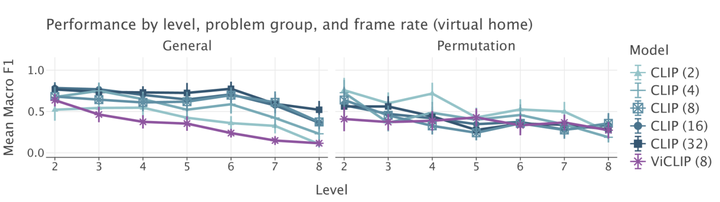
帧速率和模型比例在一般顺序任务中起着重要作用。我们看到 CLIP 的性能随着帧速率的增加而提高。当我们比较 CLIP-8 和 ViCLIP 时,它们都有 8 帧,我们发现 CLIP-8 的表现要好得多。
三、让我们一起展望数据集应用
在我的世界中这款游戏,要是我想给方块城搞个交通系统,那可真是个大工程。我得自己一个方块一个方块地搭铁路,还得记着哪儿是车站,哪儿是交叉口。道路网络也得自己铺,得保证路宽够,别让马车堵一块儿了。空中矿车系统更是头疼,得算好高度和距离,一不小心就可能翻车。那时候,我得花上好几个周末,一点点摸索,一点点建,有时候还得拆了重来,真是累人。
有了ViSTa数据集训练的系统后怎么操作:
它就像是个城市规划的专家,看过了ViSTa数据集里的所有视频和步骤,学会了怎么建交通系统。我跟它说,“嘿,AI,咱们方块城需要个交通系统。” 它就能自己开始规划了。
首先,它会在城市地图上画出铁路网络,连住宅区到商业区,再到工业区,每个站点都标得清清楚楚。然后,它会设计道路网络,哪些地方需要加宽,哪些地方要设置交通灯,它都心里有数。空中矿车系统就更酷了,AI会计算好每条路线的最佳高度和转弯点,保证既安全又快速。
现在有了AI,就像是有了个小帮手,可以帮我们优化我们的设计方案。在我的世界里建城市,也能享受到科技的便利啦!
 https://www.selectdataset.com/
https://www.selectdataset.com/