摘要: 这是文字识别OCR领域的一个小里程碑,后面的文章/项目或多或少都有它的影子,这里通过阅读理解代码的方式来解析一下。
1. 模型结构图
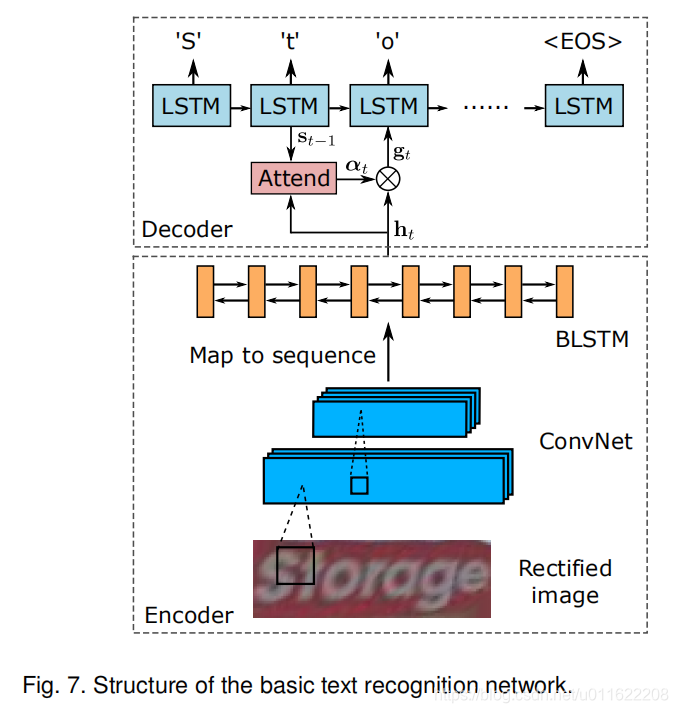
2. 模型结构
整个模型很清晰,有以下几个模块组成:
- STN文字矫正
- CNN+LSTM特征提取+序列特征学习
- 基于注意力机制的Decoder
3. 项目阅读
3.1 数据
- 数据采用3 × 64 ×256 的输入
- 归一化到[0,1],减0.5,除0.5
3.2 STN矫正模块
- STN的输入将3 × 64 ×256的图像,resize到 3 × 32 × 64,(可能是在小尺寸上更容易回归STN的控制关键点)
- STN输出为 3 × 32 × 100
3.3 CNN + LSTM特征提取+序列特征学习模块
- CNN的输入为STN输出的 3 × 32 × 100
- CNN输出为 25 × 512,其在宽度方向降采样了4,在高度方向降采样了32。(和CRNN一样)
- LSTM采用了一个2层双向的LSTM 来对序列特征进行学习
3.4 基于注意力机制的Decoder
这块是基于NLP中的seq2seq技术,最开始是用于处理NLP任务的。这里我们主要也详细解析一下这部分。整个Decoder是一个N步的循环:
for i in range(N):
state = 0 # 隐含状态初始化
context = cal_context(x, state) # calculate context
output, state = cal_per_decoder(context, target_pre, state)
aster的实现
state= torch.zeros(1, batch_size, self.sDim)
outputs = []
for i in range(max(lengths)):
if i == 0:
y_prev = torch.zeros((batch_size)).fill_(self.num_classes) # the last one is used as the <BOS>.
else:
y_prev = targets[:,i-1]
output, state = self.decoder(x, state, y_prev)
outputs.append(output)
outputs = torch.cat([_.unsqueeze(1) for _ in outputs], 1)
3.4.1 隐含状态初始化
state = torch.zeros(1, batch, hidden_dim)
3.4.2 context求解
因为解码是基于seq2seq的,是一步一步完成的。每一步都要把图像特征送入到decoder中。假设图像特征是一个 25 × 512 的矩阵,最简单的可以用一个linear层将 25 ----> 1,然后1 × 512就表示当前步的图像feature,然后送入Decode(一般用GRU + 一个输出层FC),得到当前步的输出:1 × lable_classes。然后一直循环N步,N的取值 = 定义的序列最大长度/batch内的序列最大长度。
Decode(一般用GRU + 一个输出层FC)一般是一样的。这里就是每步的context求解有不同。最多的就是求一个 alpha(25:表示每个step的权重,25个值的和为1) ,然后再alpha(25) × 图像feature(25 × 512)得到 context:1 × 512。
这里我们看一下aster.pytorch的求法:
batch_size, T, _ = x.size() # [b x T x xDim]
x = x.view(-1, self.xDim) # [(b x T) x xDim]
xProj = self.xEmbed(x) # [(b x T) x attDim]
xProj = xProj.view(batch_size, T, -1) # [b x T x attDim]
sPrev = sPrev.squeeze(0)
sProj = self.sEmbed(sPrev) # [b x attDim]
sProj = torch.unsqueeze(sProj, 1) # [b x 1 x attDim]
sProj = sProj.expand(batch_size, T, self.attDim) # [b x T x attDim]
sumTanh = torch.tanh(sProj + xProj)
sumTanh = sumTanh.view(-1, self.attDim)
vProj = self.wEmbed(sumTanh) # [(b x T) x 1]
vProj = vProj.view(batch_size, T)
alpha = F.softmax(vProj, dim=1) # attention weights for each sample in the minibatch
说明:
- 这里将图像feature X和上一步的隐含状态作为输入
- 主要就是一个linear(512, 1)的线性层和softmax 层, 其他层都是增加表达能力的层
- 最后输出alpha(25:表示每个step的权重,25个值的和为1)
- bmm(alpha,X) 得到 context (1 × 512)
3.4.3 单步Decoder
单步Decoder主要又两部分组成:
- GRU
output, state = self.gru(torch.cat([yProj, context], 1).unsqueeze(1), sPrev)将上一步的输出编码之后,再和context 融合,送入到 GRU中。 - FC输出层
output = self.fc(output)
最后经过一个线性输出层,降维到字符集空间。