点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:Eric Wallace
编译:ronghuaiyang
导读
你没有看错,确实是通过增大模型的大小,大家别忘了,在训练的时候,有个隐含条件,那就是模型需要训练到收敛。
模型训练会很慢
在深度学习中,使用更多的计算(例如,增加模型大小、数据集大小或训练步骤)通常会导致更高的准确性。考虑到最近像BERT这样的无监督预训练方法的成功,这一点尤其正确,它可以将训练扩展到非常大的模型和数据集。不幸的是,大规模的训练在计算上非常昂贵的,尤其是在没有大型工业研究实验室的硬件资源的情况下。因此,在实践中,我们的目标通常是在不超出硬件预算和训练时间的情况下获得较高的准确性。
对于大多数训练预算,非常大的模型似乎不切实际。相反,最大限度提高训练效率的策略是使用隐藏节点数较小或层数量较少的模型,因为这些模型运行速度更快,使用的内存更少。
大模型训练的更快
然而,在我们的最近的论文中,我们表明这种减少模型大小的常见做法实际上与最佳的计算效率训练策略相反。相反,当在预算内训练Transformer模型时,你希望大幅度增加模型大小,但是早点停止训练。换句话说,我们重新思考了模型必须被训练直到收敛的隐含假设,展示了在牺牲收敛性的同时,有机会增加模型的大小。

这种现象发生的原因是,与较小的模型相比,较大的模型在较少的梯度更新中可以收敛于较低的测试误差。此外,这种收敛速度的提高超过了使用更大模型的额外计算成本。因此,在考虑训练时间时,较大的模型可以更快地获得更高的精度。
我们在下面的两条训练曲线中展示了这一趋势。在左侧,我们绘制了预训练的验证误差RoBERTa,这是BERT的一个变体。RoBERTa模型越深,其混乱度就越低(我们的论文表明,对于更宽的模型也是如此)。这一趋势也适用于机器翻译。在右侧,我们绘制了验证BLEU分数(越高越好),当训练一个英语到法语的Transformer机器翻译模型。在相同的训练时间下,深度和宽度模型比小模型获得更高的BLEU分数。
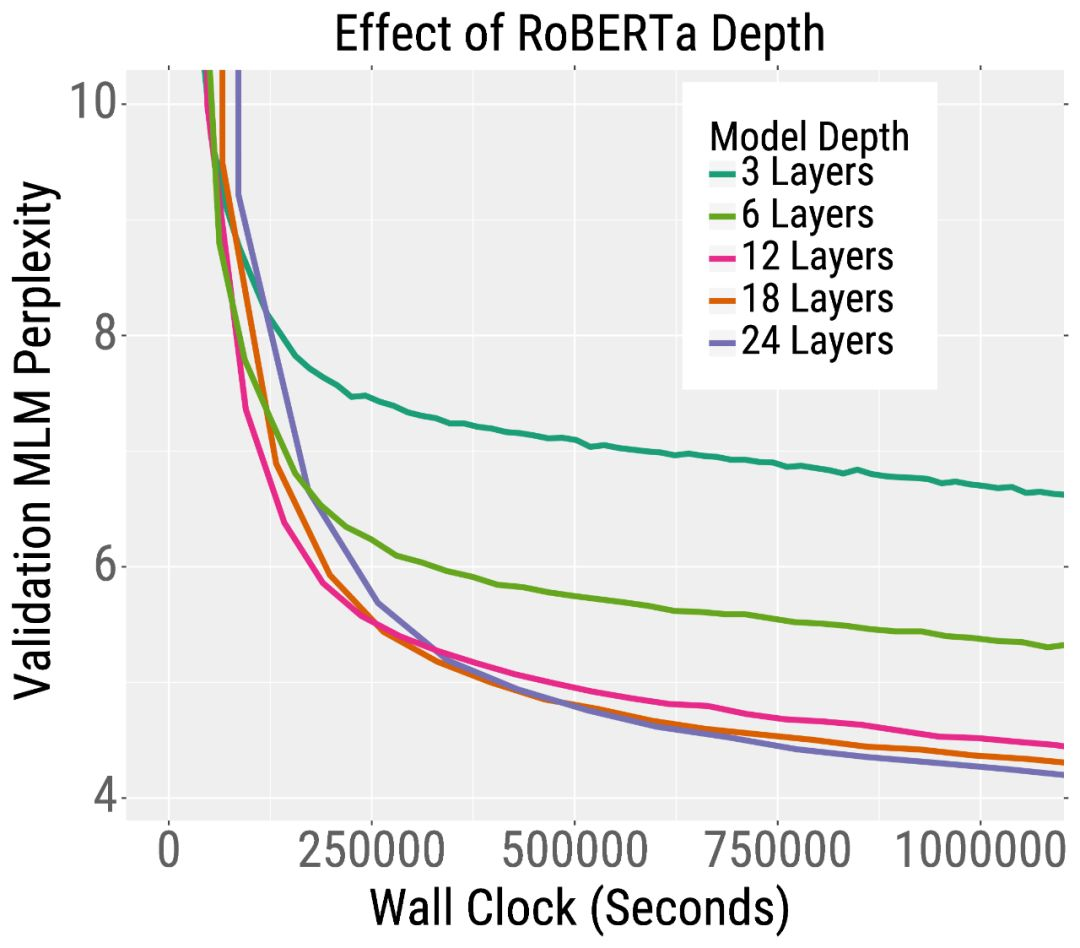
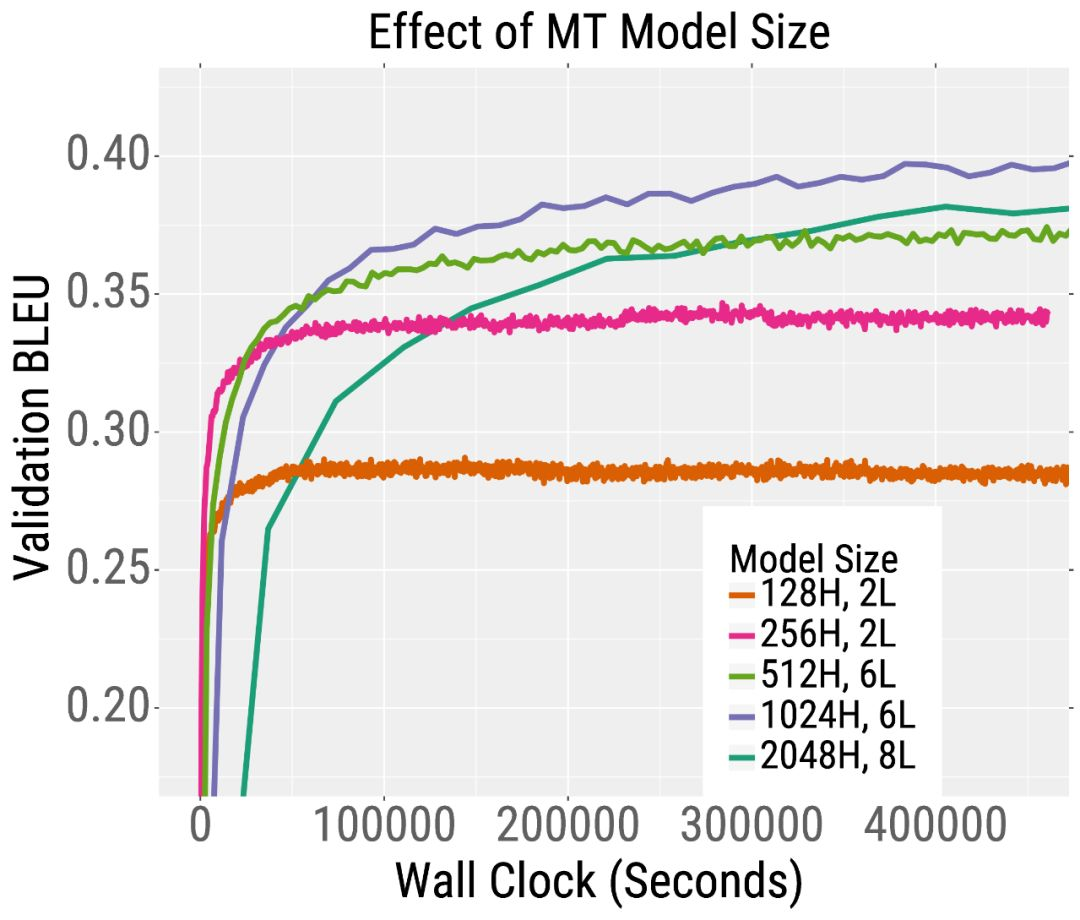
有趣的是,对于训练前的RoBERTa来说,增加模型的宽度和/或深度都会导致更快的训练。对于机器翻译,更宽的模型比更深的模型表现得更好。因此,我们建议在深入之前尝试增加宽度。
我们还建议增加模型大小,而不是batch size大小。具体地说,我们确认一旦batch size接近临界范围,增加batch size大小只会在训练时间上提供微小的改进。因此,在资源受限的情况下,我们建议在这个关键区域内使用batch size大小,然后使用更大的模型。
测试时间怎么办呢?
尽管更大的模型具有更高的“训练效率”,但它们也增加了“推理”的计算和内存需求。这是有问题的,因为推理的总成本远远大于大多数实际应用的训练成本。然而,对于RoBERTa来说,我们证明了这种取舍可以与模型压缩相协调。特别是,与小型模型相比,大型模型对模型压缩技术更健壮。因此,人们可以通过训练非常大的模型,然后对它们进行大量的压缩,从而达到两全其美的效果。
我们使用量化和剪枝的压缩方法。量化以低精度格式存储模型权重,修剪将某些神经网络的权值设置为零。这两种方法都可以减少推理延迟和存储模型权值的内存需求。
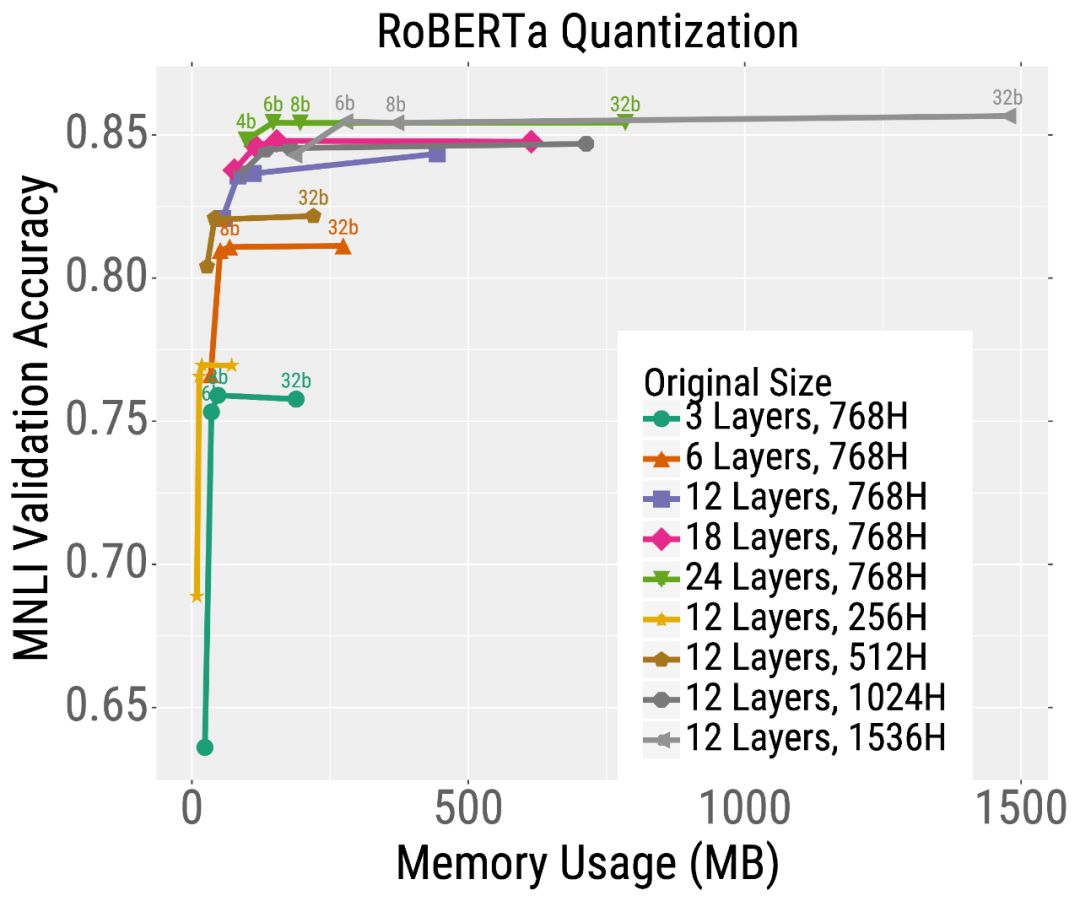
我们首先在相同的时间内预训练不同尺寸的RoBERTa模型。然后,我们在下游文本分类任务(MNLI)中对这些模型进行微调,并使用修剪或量化。我们发现,对于给定的测试时间预算,最好的模型是那些经过大量训练然后经过大量压缩的模型。
例如,考虑最深度模型的修剪结果(左图中的橙色曲线)。不需要修剪模型,它达到了很高的精度,但是使用了大约2亿个参数(因此需要大量的内存和计算)。但是,可以对这个模型进行大量的修剪(沿着曲线向左移动的点),而不会严重影响准确性。这与较小的模型形成了鲜明的对比,如粉红色显示的6层模型,其精度在修剪后严重下降。量化也有类似的趋势(下图)。总的来说,对于大多数测试预算(在x轴上选择一个点)来说,最好的模型是非常大但是高度压缩的模型。

总结
我们已经证明了增加Transformer模型的大小可以提高训练和推理的效率,即,应该先“大模型训练”,然后再“压缩”。这一发现引出了许多其他有趣的问题,比如为什么大的模型收敛得更快,压缩得更好。在我们的论文中,我们对这一现象进行了初步的调查,然而,未来的工作仍然是需要的。此外,我们的发现目前是NLP领域独特的 —— 我们想探索如何将这些结论推广到其他领域,如计算机视觉。
论文:“Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers”
论文链接:https://arxiv.org/abs/2002.11794

—END—
英文原文:https://bair.berkeley.edu/blog/2020/03/05/compress/

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!