在计算机视觉领域,最基本也最经典的一个问题就是目标识别(Object Detection):给出一张图像,用detector检测出图像中特定的object(如人脸)。这方面的论文最经典的恐怕要数《Rapid Object Detection using a Boosted Cascade of Simple Features》这篇了,截止目前(2015.4.2)已经引用10834次。Matlab的Computer Vision System Toolbox中的vision.CascadeObjectDetector System 以及 OpenCV中提供的Cascade Classification 都是基于这篇论文的算法。该算法的特点是在保证高准确率的基础上,速度也非常快。本文就结合自己的理解,对这篇论文做一个简略的阅读笔记。由于太过经典,网上有各种关于该论文的资料可供读者参详,本文只是个人笔记,不求详尽。
首先,目标检测的基本原理就是先通过训练集学习一个分类器,然后在测试图像中以不同scale的窗口滑动扫描整个图像;每次扫描做一下分类,判断一下当前的这个窗口是否为要检测的目标。算法的核心是分类,分类的核心一个是用什么特征,一个是用哪种分类器。该论文的贡献也就是在这两个方面。
特征
我们的分类器是对一个窗口(如20*20)进行分类,那就需要用到这个窗口的特征,比如颜色直方图、SIFT特征。本文中用的是 Harr-like 特征。解释一下。
Harr-like 特征是一类矩形特征,该文用了以下四种:
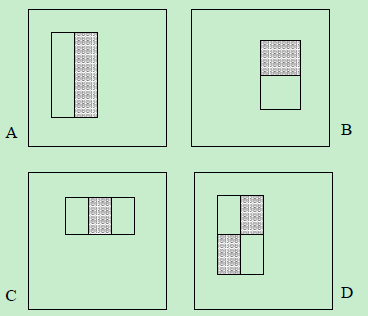
特征值的计算方式是:先分别求灰色矩阵和白色矩阵中的像素值(对于灰度图就是它的灰度值)的和,然后两者相减。由于四种中的每一种又可以有不同的大小,不同的位置,通过计算,可以验证一个24*24的窗口中有16万个这样的特征。
首先补充一下为什么这样的特征可以用,举个例子吧,看下图,两个矩形是通过后面的adaboost选出来的最好用的中的两个。第一个可以反映出眼睛区域更dark;第二个反映出眼睛比鼻梁上端更dark。

第二个问题是,这么多特征,每一个都要计算矩形里面的像素值和,计算量太大了有木有!该论文的一个贡献是提出了用Integral Image来重新表示一幅图像,其实是个很简单的trick,但把计算量一下就缩减了一个量级。
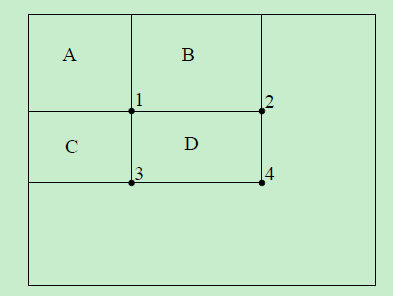
图像I中的x,y处的像素值用 i(x,y)表示; 积分图像II(与I大小一样)中x,y处的像素值用ii(x,y)表示。对应位置怎么转换呢? 其实就是把原图像中该位置左边和上边的所有像素值加起来。用公式表达:

是个迭代的式子。把原图像逐个像素扫描一遍就得到积分图像。于是,矩形D的像素值和就可以用 4+1-(2+3)算了,复杂度是O(1)。
第三个问题是,难道我分类器要用这么多特征吗,难道我每次检测一个窗口要计算16万个特征吗?这就是该论文的第二个贡献了,用AdaBoost选择少数几个最好用的特征。
AdaBoost分类器
AdaBoost是一种ensemble分类器,也就是把多个弱分类器结合起来形成一个强分类器。每个弱分类器的准确率并不高,但最后形成的强分类器的准确率就很高了,而且已经被证明有很大的margin,也就是有很好的泛化能力。
16万个特征,用每个特征做一个弱分类器,弱分类器使用决策树这种最简单的分类器。说白了,就是用一个固定大小和位置的矩形特征,在所有正负样本上训练,找到一个阈值让它的分类错误率最低。
所谓AdaBoost也就是:迭代T次,对于第t次,所有的弱分类器都做一下分类,选择一个分类错误率最低的弱分类器;迭代T次,就产生T个弱分类器。这T个弱分类器加起来就是最后得到的强分类器。
AdaBoost的核心的分类器的权重和根据错误率做的权重更新,这里不赘述,比较简单。
可以看到,最后产生的强分类器使用了T个特征,而不是全部的16万个。论文中说道,用200个特征就能产生95%的识别率了。
到这里,我们的分类器就搞定了,就可以拿来做object detection了。 But, one more thing…
Cascade 分类器
上面得到了分类器,在检测图像时,对于每个窗口,我们都要计算T个特征。这固然可以,但是,作者的第三个贡献就是提出级联分类器的方法,检测一个窗口未必要计算所有这T个特征。
该方法的assumption是在检测的所有窗口中,false的占觉得大多数。
我们前面得到了一个强分类器。这里呢,我们需要m个强分类器。从头到尾串起来。每次检测一个窗口,先用第一个强分类器检测,如果是false,直接放弃后面m-1个分类器的检测,该处没有object;否则就继续执行第二个强分类器的检测… 如果中间某个stage(强分类器)结果是false,直接结束,该处没有object;如果所有m个分类器全部是true,那么该处有object。 级联分类器的关键是强分类器的次序安排:把简单的、false negative低的安排在最前面。 这样可以快速判断出那些不相关的区域,把更多的计算量用在潜在区域。
举例
这里以论文中的人脸识别实验为例,做些补充。
- 训练集:图像大小2424.正样本只有人脸,共49162个(包括镜面图像);负样本是不包含人脸的图片,随机选择了9544个24*24的子窗口。正负样本基本平衡。
- 实验中级联分类器前5层含有的特征数(也就是弱分类器数)分别是:1, 10, 25, 25, 50.如果第一层能拒绝掉大部分非相关区域的话,可以看到计算量小的喜人。
- 训练集的图像如果不是上述大小,要平滑一下并做上采样或下采样。然后转为灰度图。测试图像也用灰度图。
- 测试图像大小无所谓。滑动窗口的初始大小也是24*24,然后以1.2倍的速度放大(由于Harr特征的特殊性,分类器的scaling比测试图像的scaling更方便)。
- 一个位置处会检测出好多框,把重叠的求个均值。
遗留问题:级联分类器的具体训练和选择方法。
参考和推荐:
Viola P, Jones M. Rapid object detection using a boosted cascade of simple features[C]//Computer Vision and Pattern Recognition, 2001. CVPR 2001. Proceedings of the 2001 IEEE Computer Society Conference on. IEEE, 2001, 1: I-511-I-518 vol. 1.
[http://blog.csdn.net/watkinsong/article/details/7631241]
[http://cn.mathworks.com/help/vision/ref/vision.cascadeobjectdetector-class.html]
[http://docs.opencv.org/modules/objdetect/doc/cascade_classification.html]