from bs4 import BeautifulSoup
from collections import OrderedDict
import urllib.request
import urllib.error
import re
import xlwt
import sqlite3
class doubanCatch:
def __init__(self,baseurl,head,savepath,complileDict,dbpath):
self.baseurl = baseurl
self.head = head
self.savepath = savepath
self.complileDict = complileDict
self.datalist = []
self.conn = sqlite3.connect(dbpath)
# 1.准备工作
def preWork(self):
#TODO 验证传入的参数是否符合规范,初始化数据啼
return 1
# 2.爬取网页
def askURL(self):
htmls = []
for i in range(10): # 调用获取页面信息的函数
url = self.baseurl + str(i * 25)
request = urllib.request.Request(url,headers=self.head)
try:
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
htmls.append(html)
except urllib.error.URLError as e:
if hasattr(e,'code'):
print('askURL: ',e.code)
if hasattr(e,'reson'):
print('askURL: ',e.reason)
return htmls
# 3.解析网页
def getData(self,html):
soup = BeautifulSoup(html,'html.parser')
for item in soup.find_all('div',class_='item'):
data = OrderedDict()
item = str(item)
#complileDict = {'findLink': findLink, 'findImg': findImg, 'findTitle': findTitle,
# 'findRating': findRating, 'findJudge': findJudge, 'findInq': findInq, 'findBd': findBd}
data['Link'] = re.findall(self.complileDict['findLink'],item)[0]
data['Img'] = re.findall(self.complileDict['findImg'],item)[0]
titles = re.findall(self.complileDict['findTitle'],item)
if len(titles) == 2 :
data['cTitle'] = titles[0]
data['oTitle'] = titles[1].replace('/','')
else:
data['cTitle'] = titles[0]
data['oTitle'] = ' '
data['Rating'] = re.findall(self.complileDict['findRating'],item)[0]
data['Judge'] = re.findall(self.complileDict['findJudge'], item)[0]
inqs = re.findall(self.complileDict['findInq'], item)
if len(inqs) != 0:
data['Inq'] = inqs[0].replace('.','')
else:
data['Inq'] = ' '
bd = re.findall(self.complileDict['findBd'], item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?',' ',bd)
bd = re.sub('/'," ",bd).strip()
bd = re.sub('"', " ", bd)
data['Bd'] = bd
self.datalist.append(data)
# 4.保存数据
def saveto_excel(self):
print('save ...')
book = xlwt.Workbook(encoding='utf-8',style_compression=0)
sheet = book.add_sheet('豆瓣电影TOP250',cell_overwrite_ok=True)
column = ('电影详情链接','图片链接','影片中文名','影片外国名','评分','评价数','概况','相关信息')
for i in range(len(column)):
sheet.write(0,i,column[i])
for i,d in enumerate(self.datalist,start=1):
print('第{}条'.format(i))
print(d)
for j,v in enumerate(d.values()):
sheet.write(i,j,v)
book.save(self.savepath)
def saveto_sqldb(self):
self.init_db()
cur = self.conn.cursor()
for d in self.datalist:
data = list(d.values())
data = [ '"'+i+'"' for i in data ]
sql = '''
insert into movie250 (
info_link,pic_link,cname,oname,score,rated,instroduction,info)
values({})
'''.format(','.join(data))
print(sql)
cur.execute(sql)
self.conn.commit()
else:
cur.close()
# 清理工作
def clear(self):
self.datalist.clear()
self.conn.close()
# 启动
def run(self):
flag = self.preWork() # 1.准备工作
if flag:
try:
htmls = self.askURL() # 2.爬取网页
for html in htmls: # 3.解析网页
self.getData(html)
self.saveto_excel() # 4.保存数据
self.saveto_sqldb()
except Exception as e:
print('run: ',e)
finally:
self.clear() # 5.清理工作
# 初始化数据库
def init_db(self):
sql = '''
create table movie250
(
id integer primary key autoincrement,
info_link text,
pic_link text,
cname varchar,
oname varchar,
score numeric,
rated numeric,
instroduction text,
info text
)
''' # 创建数据表单
cursor = self.conn.cursor()
try:
cursor.execute(sql)
self.conn.commit()
finally:
cursor.close()
if __name__ == "__main__":
baseurl = 'https://movie.douban.com/top250?start=' #TODO 改造从配置文件读取设定
head = {'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.3239.132 Safari/537.36'}
savepath = './豆瓣电影TOP250.xls'
dbpath = 'douban.db'
complileDict = OrderedDict()
# 匹配超链接 例如:<a href="">
findLink = re.compile(r'<a href="(.*?)">')
#<img alt="肖申克的救赎" class="" src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" width="100"/>
findImg = re.compile(r'<img.*src="(.*?)"',re.S)
#<span class="title">肖申克的救赎</span>
findTitle = re.compile(r'<span class="title">(.*)</span>')
#<span class="rating_num" property="v:average">9.7</span>
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
#<span>2147325人评价</span>
findJudge = re.compile(r'<span>(\d*)人评价</span>')
#<span class="inq">希望让人自由。</span>
findInq = re.compile(r'<span class="inq">(.*?)</span>')
#<p class="">
# 导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br/>
# 1994 / 美国 / 犯罪 剧情
# </p>
findBd = re.compile(r'<p class="">(.*?)</p>',re.S)
#正则匹配字典构造
complileDict= {'findLink':findLink,'findImg':findImg,'findTitle':findTitle,'findRating':findRating,'findJudge':findJudge,'findInq':findInq,'findBd':findBd}
try:
d = doubanCatch(baseurl,head,savepath,complileDict,dbpath)
d.run()
except Exception as e:
print('main: ',e)
finally:
pass
由于run调用了存储数据在Excel和SQLite所以如下检查:
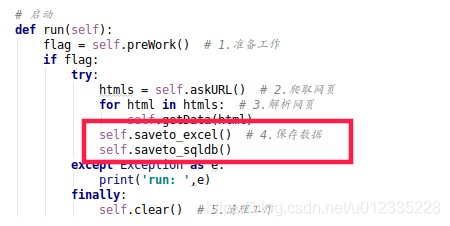
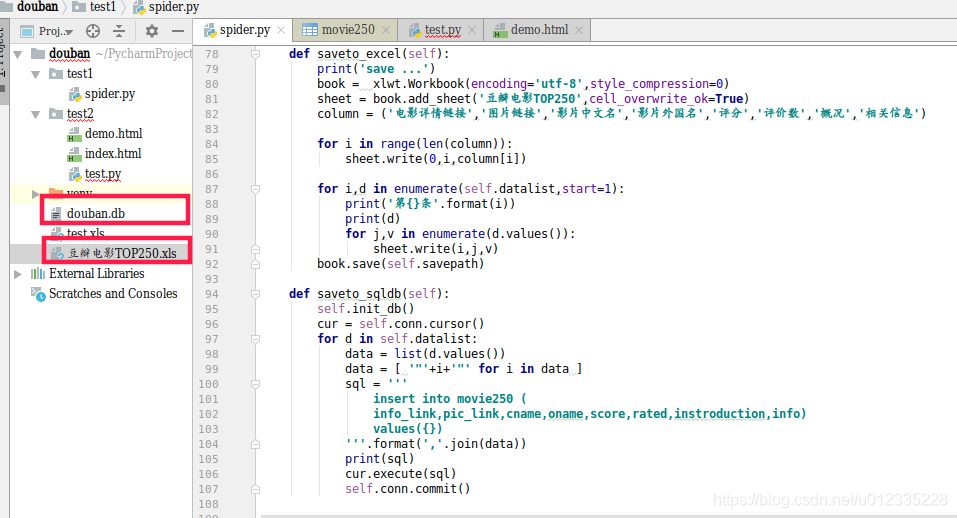
查看SQLite数据库是否存储数据

查看Excel文件是否存储数据
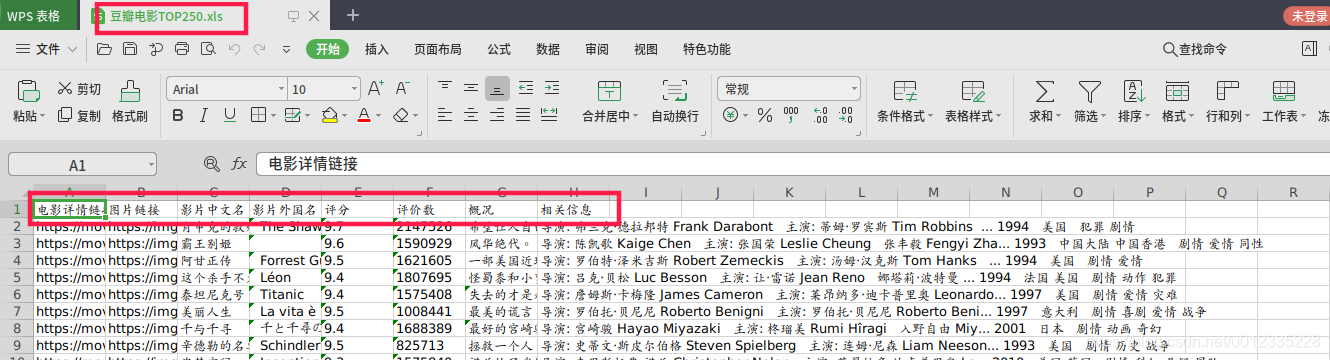
有了数据就可以做分析了
from flask import Flask,render_template
import sqlite3
import jieba
from matplotlib import pyplot as plt
from wordcloud import WordCloud
import numpy as np
from PIL import Image
import threading
app = Flask(__name__)
@app.route('/')
def root():
return render_template('temp.html')
@app.route('/index')
def index():
return render_template('index.html')
@app.route('/movie')
def movie():
datalist = []
con = sqlite3.connect('douban.db')
cur = con.cursor()
sql = "select * from movie250"
data = cur.execute(sql)
for item in data:
datalist.append(item)
cur.close()
con.close()
return render_template('movie.html',movies=datalist)
@app.route('/word')
def word():
def wordcloud():
con = sqlite3.connect('douban.db')
cur = con.cursor()
sql = "select instroduction from movie250"
data = cur.execute(sql)
text = ''
for item in data:
text += item[0]
cur.close()
con.close()
cut = jieba.cut(text)
string = ' '.join(cut)
img = Image.open(r'./static/assets/img/tree.jpg')
img_array = np.array(img)
wc = WordCloud(
background_color='white',
mask = img_array,
font_path='/home/yzx/PycharmProjects/douban_flask/templates/MSYH.TTF'
)
wc.generate_from_text(string)
#绘制图片
fig = plt.figure(1)
plt.imshow(wc)
plt.axis('off')
plt.show()
# plt.savefig('./static/assets/img/word.jpg',dpi=500)
t = threading.Thread(target=wordcloud,name='wordcloud',daemon=True)
t.start()
return render_template('word.html')
@app.route('/team')
def team():
return render_template('team.html')
@app.route('/score')
def score():
score = []
count = []
con = sqlite3.connect('douban.db')
cur = con.cursor()
sql = "select score,count(score) from movie250 group by score"
data = cur.execute(sql)
for item in data:
score.append(item[0])
count.append(item[1])
cur.close()
con.close()
return render_template('score.html',score=score,count=count)
if __name__ == '__main__' :
app.run()
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta content="width=device-width, initial-scale=1.0" name="viewport">
<title>Mamba Bootstrap Template - Index</title>
<meta content="" name="descriptison">
<meta content="" name="keywords">
<!-- Favicons -->
<link href="static/assets/img/favicon.png" rel="icon">
<link href="static/assets/img/apple-touch-icon.png" rel="apple-touch-icon">
<!-- Google Fonts -->
<link href="https://fonts.googleapis.com/css?family=Open+Sans:300,300i,400,400i,600,600i,700,700i|Raleway:300,300i,400,400i,600,600i,700,700i,900" rel="stylesheet">
<!-- Vendor CSS Files -->
<link href="static/assets//vendor/bootstrap/css/bootstrap.min.css" rel="stylesheet">
<link href="static/assets//vendor/icofont/icofont.min.css" rel="stylesheet">
<link href="static/assets//vendor/boxicons/css/boxicons.min.css" rel="stylesheet">
<link href="static/assets//vendor/animate.css/animate.min.css" rel="stylesheet">
<link href="static/assets//vendor/venobox/venobox.css" rel="stylesheet">
<link href="static/assets//vendor/aos/aos.css" rel="stylesheet">
<!-- Template Main CSS File -->
<link href="static/assets//css/style.css" rel="stylesheet">
</head>
<body>
<!-- ======= Header ======= -->
<header id="header">
<div class="container">
<div class="logo float-left">
<h1 class="text-light"><a href="index.html"><span>Mamba</span></a></h1>
<!-- Uncomment below if you prefer to use an image logo -->
<!-- <a href="index.html"><img src="astatic/assets/img/logo.png" alt="" class="img-fluid"></a>-->
</div>
<nav class="nav-menu float-right d-none d-lg-block">
<ul>
<li class="active"><a href="/index">首页 <i class="la la-angle-down"></i></a></li>
<li><a href="/movie">电影</a></li>
<li><a href="/score">评分</a></li>
<li><a href="/word">词云</a></li>
<li><a href="/team">团队</a></li>
</ul>
</nav><!-- .nav-menu -->
</div>
</header><!-- End Header -->
<main id="main">
<!-- ======= Our Team Section ======= -->
<section id="team" class="team">
<div class="container">
<div class="section-title">
<h2>豆瓣电影TOP250数据分析</h2>
<p>应用Python爬虫、Flask框架、Echarts、WordCloud等技术实现</p>
</div>
<section class="counts section-bg">
<div class="container">
<div class="row">
<div class="col-lg-3 col-md-6 text-center" data-aos="fade-up">
<a href="/movie">
<div class="count-box">
<i class="icofont-simple-smile" style="color: #20b38e;"></i>
<span data-toggle="counter-up">250</span>
<p>经典电影</p>
</div>
</a>
</div>
<div class="col-lg-3 col-md-6 text-center" data-aos="fade-up" data-aos-delay="200">
<a href="/score">
<div class="count-box">
<i class="icofont-document-folder" style="color: #c042ff;"></i>
<span data-toggle="counter-up">1</span>
<p>评分报告</p>
</div>
</a>
</div>
<div class="col-lg-3 col-md-6 text-center" data-aos="fade-up" data-aos-delay="400">
<a href="/word">
<div class="count-box">
<i class="icofont-live-support" style="color: #46d1ff;"></i>
<span data-toggle="counter-up">1008</span>
<p>词汇统计</p>
</div>
</a>
</div>
<div class="col-lg-3 col-md-6 text-center" data-aos="fade-up" data-aos-delay="600">
<a href="/team">
<div class="count-box">
<i class="icofont-users-alt-5" style="color: #ffb459;"></i>
<span data-toggle="counter-up">5</span>
<p>团队成员</p>
</div>
</a>
</div>
</div>
</div>
</section><!-- End Counts Section -->
</div>
</section><!-- End Our Team Section -->
<!-- ======= Footer ======= -->
<footer id="footer">
<div class="container">
<div class="copyright">
© Copyright <strong><span>Mamba</span></strong>. All Rights Reserved
</div>
<div class="credits">
More Templates <a href="http://www.cssmoban.com/" target="_blank" title="模板之家">模板之家</a> - Collect from <a href="http://www.cssmoban.com/" title="网页模板" target="_blank">网页模板</a>
</div>
</div>
</footer><!-- End Footer -->
<a href="#" class="back-to-top"><i class="icofont-simple-up"></i></a>
<!-- Vendor JS Files -->
<script src="static/assets/vendor/jquery/jquery.min.js"></script>
<script src="static/assets/vendor/bootstrap/js/bootstrap.bundle.min.js"></script>
<script src="static/assets/vendor/jquery.easing/jquery.easing.min.js"></script>
<script src="static/assets/vendor/php-email-form/validate.js"></script>
<script src="static/assets/vendor/jquery-sticky/jquery.sticky.js"></script>
<script src="static/assets/vendor/venobox/venobox.min.js"></script>
<script src="static/assets/vendor/waypoints/jquery.waypoints.min.js"></script>
<script src="static/assets/vendor/counterup/counterup.min.js"></script>
<script src="static/assets/vendor/isotope-layout/isotope.pkgd.min.js"></script>
<script src="static/assets/vendor/aos/aos.js"></script>
<!-- Template Main JS File -->
<script src="static/assets/js/main.js"></script>
</body>
</html>movie.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta content="width=device-width, initial-scale=1.0" name="viewport">
<title>Mamba Bootstrap Template - Index</title>
<meta content="" name="descriptison">
<meta content="" name="keywords">
<!-- Favicons -->
<link href="static/assets/img/favicon.png" rel="icon">
<link href="static/assets/img/apple-touch-icon.png" rel="apple-touch-icon">
<!-- Google Fonts -->
<link href="https://fonts.googleapis.com/css?family=Open+Sans:300,300i,400,400i,600,600i,700,700i|Raleway:300,300i,400,400i,600,600i,700,700i,900" rel="stylesheet">
<!-- Vendor CSS Files -->
<link href="static/assets//vendor/bootst