1、前期准备
- 掌握上一节SparkStreaming入门知识
2、内容概要
- sparkStreaming的checkpoint机制
- sparkStreaming的容错机制
- sparkStreaming整合sparksql
- sparkStreaming整合kafka
- sparkStreaming调优
3、课程目标
- 掌握sparkStreaming如何容错
- 掌握sparkStreaming整合kafka
- 掌握sparkStreaming调优
4、知识要点
1. Checkpoint
1.1 Checkpoint基本介绍
- checkpoint是sparkStreaming当中为了解决流式处理程序意外停止造成的数据丢失的问题,checkpoint的目的是保证长时间运行的任务在意外挂掉之后能够拉起的时候不丢失数据。
- checkpoint中包含两种数据
- metadata:元数据信息,用于恢复Driver端的数据
- 保存定义了 Streaming 计算逻辑到类似 HDFS 的支持容错的存储系统。用来恢复 Driver,元数据包括:
- DStream 的操作信息: 定义了 Spark-Stream 应用程序的计算逻辑的 DStream 操作信息
- 未处理完的 batch 信息: batch已经开始却没有处理完
- 配置信息:创建 Spark-Streaming 应用程序的配置信息,比如 SparkConf
- data
- 阶段性的存储RDD至可靠的文件系统上,供恢复时使用。这对于某些有状态的转化操作(updateStateByKey 和 reduceByKeyAndWindow)是必须的,因为这些转化操作不断的整合不同的批次,它依赖于前面的批次信息,这样就会形成一个很长的依赖链,为了防止无限的增长,就要定期将中间生成的 RDDs 保存到可靠的存储系统上来切断依赖链。
1.2 什么时候需要使用到Checkpoint
满足以下任一条件:
- 使用了 stateful 转换 - 如果 application 中使用了updateStateByKey或reduceByKeyAndWindow等 stateful 操作,必须提供 checkpoint 目录来允许定时的 RDD checkpoint。
- 希望能从意外中恢复 driver
如果 streaming app 没有 stateful 操作,也允许 driver 挂掉后再次重启的进度丢失,就没有启用 checkpoint的必要了。
1.3 如何使用checkpoint
启用 checkpoint,需要设置一个支持容错 的、可靠的文件系统(如 HDFS、s3 等)目录来保存 checkpoint 数据。通过调用 streamingContext.checkpoint(checkpointDirectory) 来完成。另外,如果你想让你的 application 能从 driver 失败中恢复,你的 application 要满足:
- 若 application 为首次重启,将创建一个新的 StreamContext 实例
- 如果 application 是从失败中重启,将会从 checkpoint 目录导入 checkpoint 数据来重新创建 StreamingContext 实例
通过 StreamingContext.getOrCreate 可以达到目的
- checkpoint不仅仅可以保存运算结果中的数据,还可以存储Driver端的信息
- 通过checkpoint可以实现Driver端的高可用
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
/**
* 通过checkpoint来恢复Driver端
*/
object DriverHAWordCount {
val checkpointPath="hdfs://node01:8020/checkpointDir"
def creatingFunc(): StreamingContext ={
Logger.getLogger("org").setLevel(Level.ERROR)
// todo: 1、创建SparkConf对象
val sparkConf: SparkConf = new SparkConf().setAppName("DriverHAWordCount").setMaster("local[2]")
// todo: 2、创建StreamingContext对象
val ssc = new StreamingContext(sparkConf,Seconds(2))
//设置checkpoint目录
ssc.checkpoint(checkpointPath)
//todo: 3、接受socket数据
val socketTextStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999)
//todo: 4、对数据进行处理
val result: DStream[(String, Int)] = socketTextStream.flatMap(_.split(" ")).map((_,1)).updateStateByKey(updateFunc)
//todo: 5、打印结果
result.print()
ssc
}
//currentValue:当前批次中每一个单词出现的所有的1
//historyValues:之前批次中每个单词出现的总次数,Option类型表示存在或者不存在。 Some表示存在有值,None表示没有
def updateFunc(currentValue:Seq[Int], historyValues:Option[Int]):Option[Int] = {
val newValue: Int = currentValue.sum + historyValues.getOrElse(0)
Some(newValue)
}
def main(args: Array[String]): Unit = {
val ssc: StreamingContext = StreamingContext.getOrCreate(checkpointPath,creatingFunc _)
//开启流式计算
ssc.start()
ssc.awaitTermination()
}
}
checkpoint在本程序中的作用:
- 可以保存之前批次的数据结果
- 可以保存之前Driver端的元数据信息(程序的执行逻辑)
注意:如果你的程序中断之后,对代码进行了修改变更,此时checkpoint目录也就没有意义
程序执行逻辑分析:
- 如果 checkpointDirectory 存在,那么
StreamingContext将导入 checkpoint 数据。如果目录不存在,函数 functionToCreateContext 将被调用并创建新的StreamingContext - 除调用 getOrCreate 外,还需要你的集群模式支持 driver 挂掉之后重启之。例如,在 yarn 模式下,driver 是运行在 ApplicationMaster 中,若 ApplicationMaster 挂掉,yarn 会自动在另一个节点上启动一个新的 ApplicationMaster。
- 需要注意的是,随着 streaming application 的持续运行,checkpoint 数据占用的存储空间会不断变大。因此,需要小心设置checkpoint 的时间间隔。设置得越小,checkpoint 次数会越多,占用空间会越大;如果设置越大,会导致恢复时丢失的数据和进度越多。一般推荐设置为 batch duration 的5~10倍。
2、 SparkStreaming和SparkSQL整合
pom.xml里面添加
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.3</version>
</dependency>
代码开发
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
/**
* sparkStreaming整合sparksql
*/
object SocketWordCountForeachRDDDataFrame {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.ERROR)
// todo: 1、创建SparkConf对象
val sparkConf: SparkConf = new SparkConf().setAppName("NetworkWordCountForeachRDDDataFrame").setMaster("local[2]")
// todo: 2、创建StreamingContext对象
val ssc = new StreamingContext(sparkConf,Seconds(2))
//todo: 3、接受socket数据
val socketTextStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999)
//todo: 4、对数据进行处理
val words: DStream[String] = socketTextStream.flatMap(_.split(" "))
//todo: 5、对DStream进行处理,将RDD转换成DataFrame
words.foreachRDD(rdd=>{
//获取得到sparkSessin,由于将RDD转换成DataFrame需要用到SparkSession对象
val sparkSession: SparkSession = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
import sparkSession.implicits._
val dataFrame: DataFrame = rdd.toDF("word")
//将dataFrame注册成表
dataFrame.createOrReplaceTempView("words")
//统计每个单词出现的次数
val result: DataFrame = sparkSession.sql("select word,count(*) as count from words group by word")
//展示结果
result.show()
})
//todo: 6、开启流式计算
ssc.start()
ssc.awaitTermination()
}
}
3、SparkStreaming容错
3.1 SparkStreaming运行流程回顾
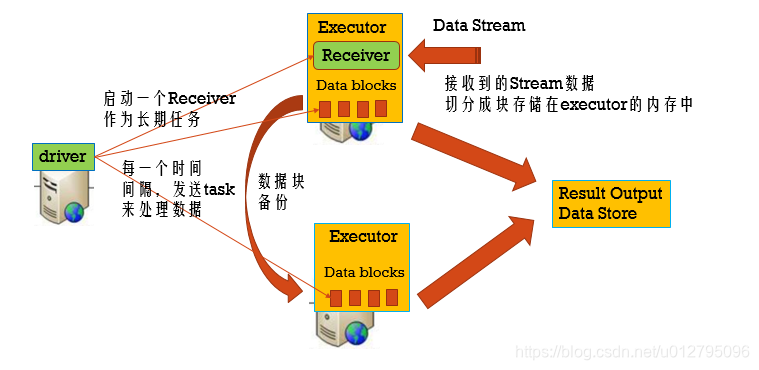
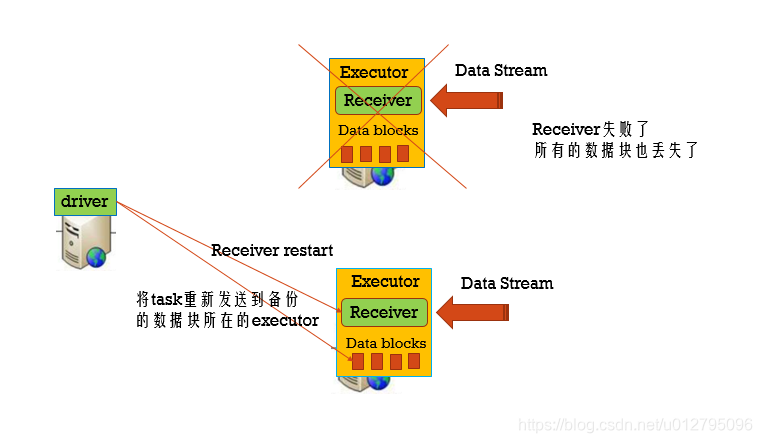
3.2 Executor失败
Tasks和Receiver自动的重启,不需要做任何的配置
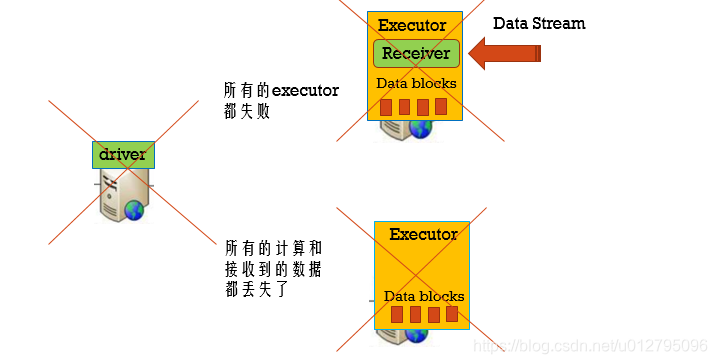
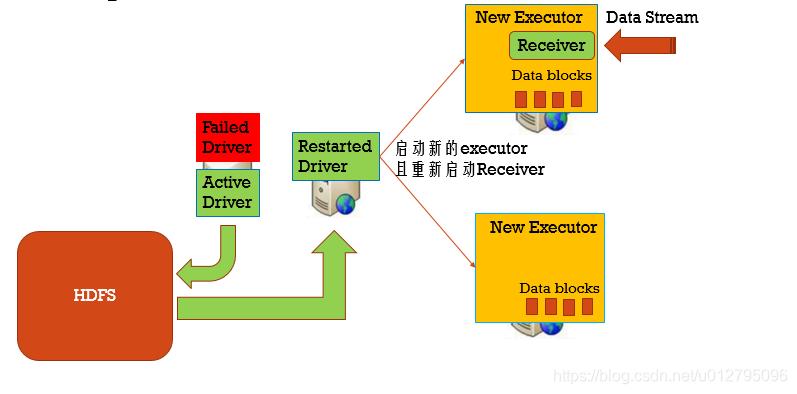
3.3 Driver失败
用checkpoint机制恢复失败的Driver
定期的将Driver信息写入到HDFS中。
步骤一:设置自动重启Driver程序
Standalone:
在spark-submit中增加以下两个参数:
--deploy-mode cluster
--supervise #失败后是否重启Driver
使用示例:
spark-submit \
--master spark://node101:7077 \
--deploy-mode cluster \
--supervise \
--class com.aaa.streaming.Demo \
--executor-memory 1g \
--total-executor-cores 2 \
original-sparkStreamingStudy-1.0-SNAPSHOT.jar
Yarn:
在spark-submit中增加以下参数:
--deploy-mode cluster
在yarn配置中设置yarn.resourcemanager.am.max-attemps参数 ,默认为2,例如:
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>
The maximum number of application master execution attempts.
</description>
</property>
使用示例:
spark-submit \
--master yarn \
--deploy-mode cluster \
--class com.aaaa.streaming.Demo \
--executor-memory 1g \
--total-executor-cores 2 \
original-sparkStreamingStudy-1.0-SNAPSHOT.jar
步骤二:设置HDFS的checkpoint目录
streamingContext.setCheckpoint(hdfsDirectory)
步骤三:代码实现
// Function to create and setup a new StreamingContext
def functionToCreateContext(): StreamingContext = {
val ssc = new StreamingContext(...) // new context
val lines = ssc.socketTextStream(...) // create DStreams
...
ssc.checkpoint(checkpointDirectory) // set checkpoint directory
ssc
}
// Get StreamingContext from checkpoint data or create a new one
val context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)
// Do additional setup on context that needs to be done,
// irrespective of whether it is being started or restarted
context. ...
// Start the context
context.start()
context.awaitTermination()
3.4 数据丢失如何处理
利用WAL把数据写入到HDFS中
步骤一:设置checkpoint目录
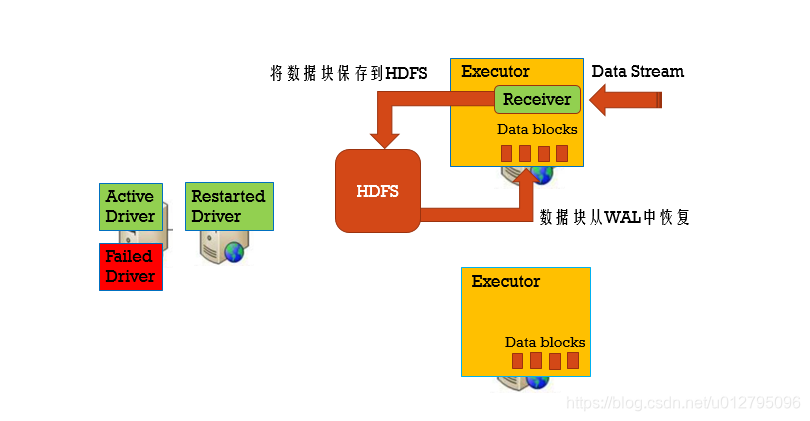
streamingContext.setCheckpoint(hdfsDirectory)
步骤二:开启WAL日志
sparkConf.set("spark.streaming.receiver.writeAheadLog.enable", "true")
步骤三:需要reliable receiver
当数据写完了WAL后,才告诉数据源数据已经消费,对于没有告诉数据源的数据,可以从数据源中重新消费数据
步骤四:取消备份
//使用StorageLevel.MEMORY_AND_DISK_SER来存储数据源,不需要后缀为2的策略了,因为HDFS已经是多副本了。
val socketTextStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999,StorageLevel.MEMORY_AND_DISK_SER)
Reliable Receiver : 当数据接收到,并且已经备份存储后,再发送回执给数据源
Unreliable Receiver : 不发送回执给数据源
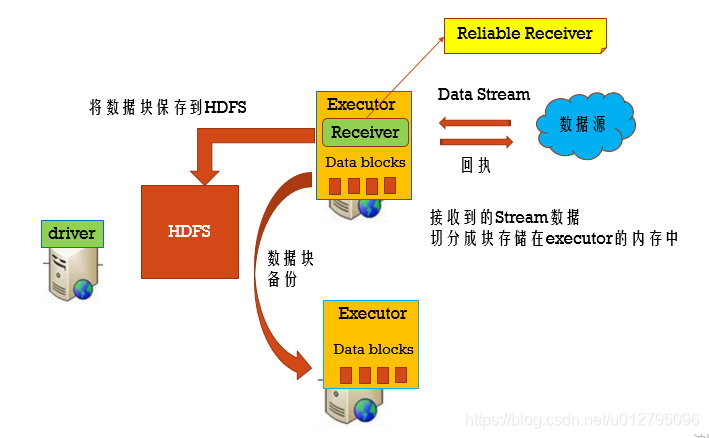
WAL
WAL使用在文件系统和数据库中用于数据操作的持久性,先把数据写到一个持久化的日志中,然后对数据做操作,如果操作过程中系统挂了,恢复的时候可以重新读取日志文件再次进行操作。
对于像kafka和flume这些使用接收器来接收数据的数据源。接收器作为一个长时间的任务运行在executor中,负责从数据源接收数据,如果数据源支持的话,向数据源确认接收到数据,然后把数据存储在executor的内存中,然后在exector上运行任务处理这些数据。
如果wal启用了,所有接收到的数据会保存到一个日志文件中去(HDFS), 这样保存接收数据的持久性,此外,如果只有在数据写入到log中之后接收器才向数据源确认,这样driver重启后那些保存在内存中但是没有写入到log中的数据将会重新发送,这两点保证的数据的无丢失。
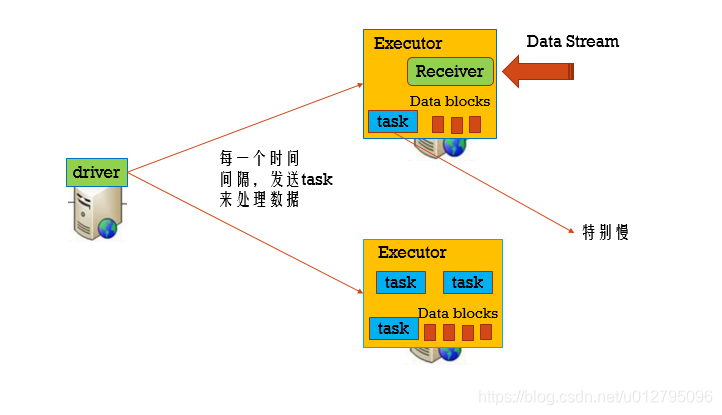
3.5 当一个task很慢容错
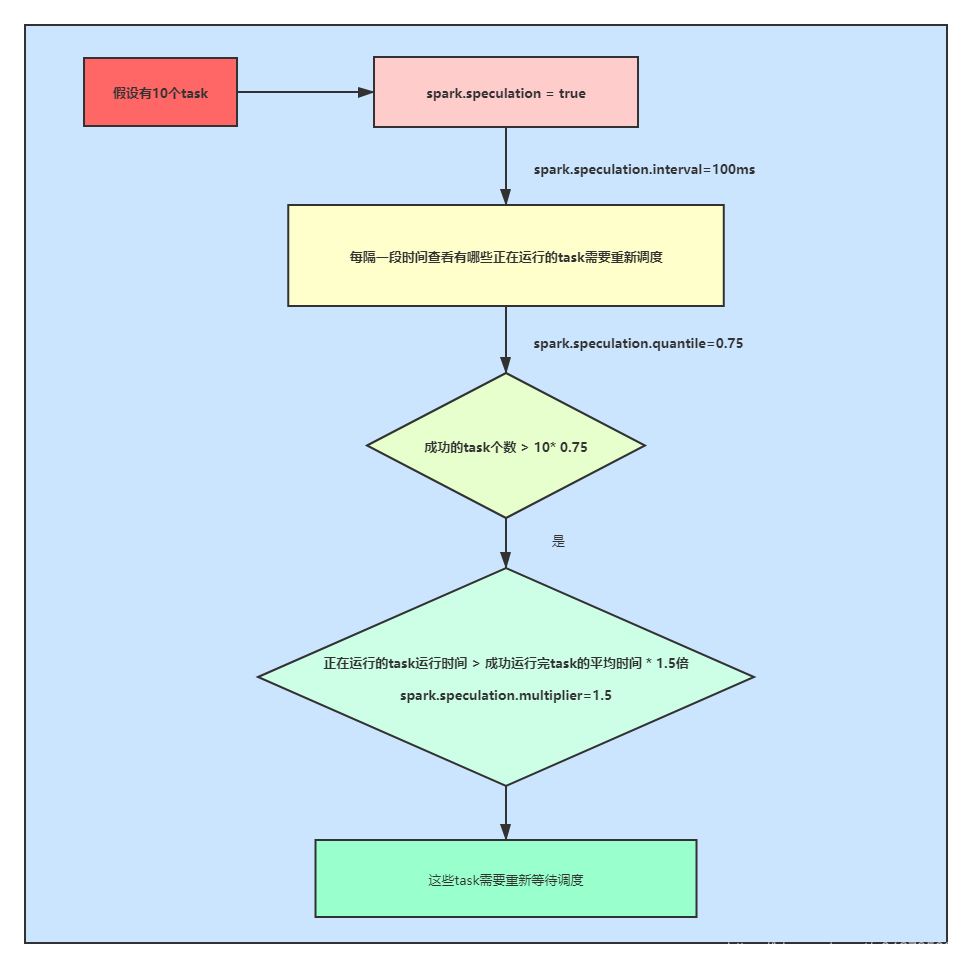
开启推测机制:
spark.speculation=true,每隔一段时间来检查有哪些正在运行的task需要重新调度(spark.speculation.interval=100ms),假设总的task有10个,成功的task的数量 > 0.75 * 10(spark.speculation.quantile=0.75),正在运行的task的运行时间 > 1.5 * 成功运行task的平均时间(spark.speculation.multiplier=1.5),则这个正在运行的task需要重新等待调度。
注意:
在分布式环境中导致某个Task执行缓慢的情况有很多,负载不均、程序bug、资源不均、数据倾斜等,而且这些情况在分布式任务计算环境中是常态。Speculative Task这种以空间换时间的思路对计算资源是种压榨,同时如果Speculative Task本身也变成了Slow Task会导致情况进一步恶化。
4、 SparkStreaming任务优雅关闭
流式任务需要7*24小时执行,但是有时涉及到升级代码需要主动停止程序,由于Spark Streaming流程序比较特殊,所以不能直接执行kill -9 这种暴力方式停掉,如果使用这种方式停程序,那么就有可能丢失数据或者重复消费数据。
如果要停,也一定要确认当前正在处理的数据执行完毕,并且不能在接受新的数据,只有这样才能保证不丢不重。所以配置优雅的关闭就显得至关重要了。
== 优雅停止方案 == :使用外部文件系统来控制内部程序关闭。
- 在驱动程序中,加一段代码,这段代码的作用每隔一段时间可以是10秒也可以是5秒,扫描HDFS上某一个文件,如果发现这个文件存在,就调用StreamContext对象stop方法,自己优雅的终止自己,其实这里HDFS可以换成redis,zk,hbase,db都可以,这里唯一的问题就是依赖了外部的一个存储系统来达到消息通知的目的,如果使用了这种方式后。停止流程序就比较简单了,登录上有hdfs客户端的机器,然后touch一个空文件到指定目录,然后等到间隔的扫描时间到之后,发现有文件存在,就知道需要关闭程序了。
代码开发:
运行主类:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
//todo: 优雅的关闭sparkStreaming程序
object StreamingStopGracefully {
def main(args: Array[String]): Unit = {
//todo: 构建StreamingContext
val ssc: StreamingContext = StreamingContext.getActiveOrCreate("./ck", () => createSSC())
//todo: 启动检测线程
new Thread(new MonitorStop(ssc)).start()
//todo: 启动流处理程序
ssc.start()
ssc.awaitTermination()
}
//todo: 创建StreamingContext对象,编写业务处理逻辑
def createSSC(): StreamingContext = {
val update: (Seq[Int], Option[Int]) => Some[Int] = (values: Seq[Int], status: Option[Int]) => {
//当前批次内容的计算
val sum: Int = values.sum
//取出状态信息中上一次状态
val lastStatu: Int = status.getOrElse(0)
//累加结果返回
Some(sum + lastStatu)
}
val sparkConf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("StreamingStopGracefully")
//todo: 设置优雅的关闭
sparkConf.set("spark.streaming.stopGracefullyOnShutdown", "true")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("warn")
ssc.checkpoint("./ck")
val line: ReceiverInputDStream[String] = ssc.socketTextStream("node01", 9999)
val word: DStream[String] = line.flatMap(_.split(" "))
val wordAndOne: DStream[(String, Int)] = word.map((_, 1))
//累加
val wordAndCount: DStream[(String, Int)] = wordAndOne.updateStateByKey(update)
//打印啥结果
wordAndCount.print()
//返回streamingContext
ssc
}
}
线程类
import java.net.URI
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.streaming.{StreamingContext, StreamingContextState}
class MonitorStop(ssc: StreamingContext) extends Runnable {
override def run(): Unit = {
val fs: FileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration(), "hadoop")
while (true) {
try
Thread.sleep(5000)
catch {
case e: InterruptedException =>
e.printStackTrace()
}
val state: StreamingContextState = ssc.getState
val bool: Boolean = fs.exists(new Path("hdfs://node01:8020/stopSpark"))
if (bool) {
if (state == StreamingContextState.ACTIVE) {
//第一个参数为true表示:停止SparkContext对象
// 第二个参数为true表示:等待所有接收数据的处理完成而优雅地停止
ssc.stop(stopSparkContext = true, stopGracefully = true)
System.exit(0)
}
}
}
}
}
5、 SparkStreaming整合Kafka
kafka当中的数据消费语义介绍:
在消费kafka当中的数据的时候,可以有三种语义的保证:
- at most once:至多一次,数据最多处理一次或者没有被处理,有可能造成数据丢失的情况。
- at least once : 至少一次,数据最少被处理一次,有可能存在重复消费的问题。
- exactly once:消费一次且仅一次,一条记录只被处理一次,它最严格,实现起来也是比较困难。
5.1 SparkStreaming与Kafka-0.8整合
5.1.1 Receiver-based Approach(不推荐使用)
此方法使用Receiver接收数据。Receiver是使用Kafka高级消费者API实现的。与所有接收器一样,从Kafka通过Receiver接收的数据存储在Spark执行器中,然后由Spark Streaming启动的作业处理数据。但是在默认配置下,此方法可能会在失败时丢失数据(请参阅接收器可靠性。为确保零数据丢失,必须在Spark Streaming中另外启用Write Ahead Logs(在Spark 1.2中引入)。这将同步保存所有收到的Kafka将数据写入分布式文件系统(例如HDFS)上的预写日志,以便在发生故障时可以恢复所有数据,但是性能不好。
pom.xml文件添加如下:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.3.3</version>
</dependency>
核心代码:
import org.apache.spark.streaming.kafka._
val kafkaStream = KafkaUtils.createStream(streamingContext,
[ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
代码演示:
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* sparkStreaming使用kafka 0.8API基于recevier来接受消息
*/
object KafkaReceiver08 {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.ERROR)
//1、创建StreamingContext对象
val sparkConf= new SparkConf()
.setAppName("KafkaReceiver08")
.setMaster("local[2]")
//开启WAL机制
.set("spark.streaming.receiver.writeAheadLog.enable", "true")
val ssc = new StreamingContext(sparkConf,Seconds(2))
//需要设置checkpoint,将接受到的数据持久化写入到hdfs上
ssc.checkpoint("hdfs://node01:8020/wal")
//2、接受kafka数据
val zkQuorum="node01:2181,node02:2181,node03:2181"
val groupid="KafkaReceiver08"
val topics=Map("test" ->1)
//(String, String) 元组的第一位是消息的key,第二位表示消息的value
val receiverDstream: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc,zkQuorum,groupid,topics)
//3、获取kafka的topic数据
val data: DStream[String] = receiverDstream.map(_._2)
//4、单词计数
val result: DStream[(String, Int)] = data.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
//5、打印结果
result.print()
//6、开启流式计算
ssc.start()
ssc.awaitTermination()
}
}
5.1.2 Direct Approach (No Receivers)
这种新的不基于Receiver的直接方式,是在Spark 1.3中引入的,从而能够确保更加健壮的机制。替代掉使用Receiver来接收数据后,这种方式会周期性地查询Kafka,来获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumer api来获取Kafka指定offset范围的数据。
这种方式有如下优点:
1、简化并行读取:
如果要读取多个partition,不需要创建多个输入DStream然后对它们进行union操作。Spark会创建跟Kafka partition一样多的RDD partition,并且会并行从Kafka中读取数据。所以在Kafka partition和RDD partition之间,有一个一对一的映射关系。
2、高性能
如果要保证零数据丢失,在基于receiver的方式中,需要开启WAL机制。这种方式其实效率低下,因为数据实际上被复制了两份,Kafka自己本身就有高可靠的机制,会对数据复制一份,而这里又会复制一份到WAL中。而基于direct的方式,不依赖Receiver,不需要开启WAL机制,只要Kafka中作了数据的复制,那么就可以通过Kafka的副本进行恢复。
3、一次且仅一次的事务机制
基于receiver的方式,是使用Kafka的高阶API来在ZooKeeper中保存消费过的offset的。这是消费Kafka数据的传统方式。这种方式配合着WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。因为Spark和ZooKeeper之间可能是不同步的。
4、降低资源
Direct不需要Receivers,其申请的Executors全部参与到计算任务中;而Receiver-based则需要专门的Receivers来读取Kafka数据且不参与计算。因此相同的资源申请,Direct 能够支持更大的业务。
5、降低内存
Receiver-based的Receiver与其他Exectuor是异步的,并持续不断接收数据,对于小业务量的场景还好,如果遇到大业务量时,需要提高Receiver的内存,但是参与计算的Executor并无需那么多的内存。而Direct 因为没有Receiver,而是在计算时读取数据,然后直接计算,所以对内存的要求很低。实际应用中我们可以把原先的10G降至现在的2-4G左右。
6、鲁棒性更好
Receiver-based方法需要Receivers来异步持续不断的读取数据,因此遇到网络、存储负载等因素,导致实时任务出现堆积,但Receivers却还在持续读取数据,此种情况很容易导致计算崩溃。Direct 则没有这种顾虑,其Driver在触发batch计算任务时,才会读取数据并计算。队列出现堆积并不会引起程序的失败。
5.2 SparkStreaming与Kafka-0-10整合
支持0.10版本,或者更高的版本(推荐使用这个版本)
pom.xml文件添加内容如下:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.3.3</version>
</dependency>
代码演示:
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, StreamingContext}
object KafkaDirect10 {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.ERROR)
//1、创建StreamingContext对象
val sparkConf= new SparkConf()
.setAppName("KafkaDirect10")
.setMaster("local[2]")
val ssc = new StreamingContext(sparkConf,Seconds(2))
//2、使用direct接受kafka数据
//准备配置
val topic =Set("test")
val kafkaParams=Map(
"bootstrap.servers" ->"node01:9092,node02:9092,node03:9092",
"group.id" -> "KafkaDirect10",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"enable.auto.commit" -> "false"
)
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] =
KafkaUtils.createDirectStream[String, String](
ssc,
//数据本地性策略
LocationStrategies.PreferConsistent,
//指定要订阅的topic
ConsumerStrategies.Subscribe[String, String](topic, kafkaParams)
)
//3、对数据进行处理
//如果你想获取到消息消费的偏移,这里需要拿到最开始的这个Dstream进行操作
//如果你对该DStream进行了其他的转换之后,生成了新的DStream,新的DStream不在保存对应的消息的偏移量
kafkaDStream.foreachRDD(rdd =>{
//获取消息内容
val dataRDD: RDD[String] = rdd.map(_.value())
//打印
dataRDD.foreach(line =>{
println(line)
})
//4、提交偏移量信息,把偏移量信息添加到kafka中
val offsetRanges: Array[OffsetRange] =
rdd.asInstanceOf[HasOffsetRanges].offsetRanges
kafkaDStream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
})
//5、开启流式计算
ssc.start()
ssc.awaitTermination()
}
}
5.3 解决SparkStreaming与Kafka0.8版本整合数据不丢失方案
方案设计如下:
一般企业来说无论你是使用哪一套api去消费kafka中的数据,都是设置手动提交偏移量。
如果是自动提交偏移量(默认60s提交一次)这里可能会出现问题?
(1)数据处理失败了,自动提交了偏移量。会出现数据的丢失。
(2)数据处理成功了,自动提交偏移量成功(比较理想),但是有可能出现自动提交偏移量失败。
会出现把之前消费过的数据再次消费,这里就出现了数据的重复处理。
自动提交偏移量风险比较高,可能会出现数据丢失或者数据被重复处理,一般来说就手动去提交偏移量,这里我们是可以去操作什么时候去提交偏移量,把偏移量的提交通过消费者程序自己去维护。
代码开发,偏移量存入Zookeeper
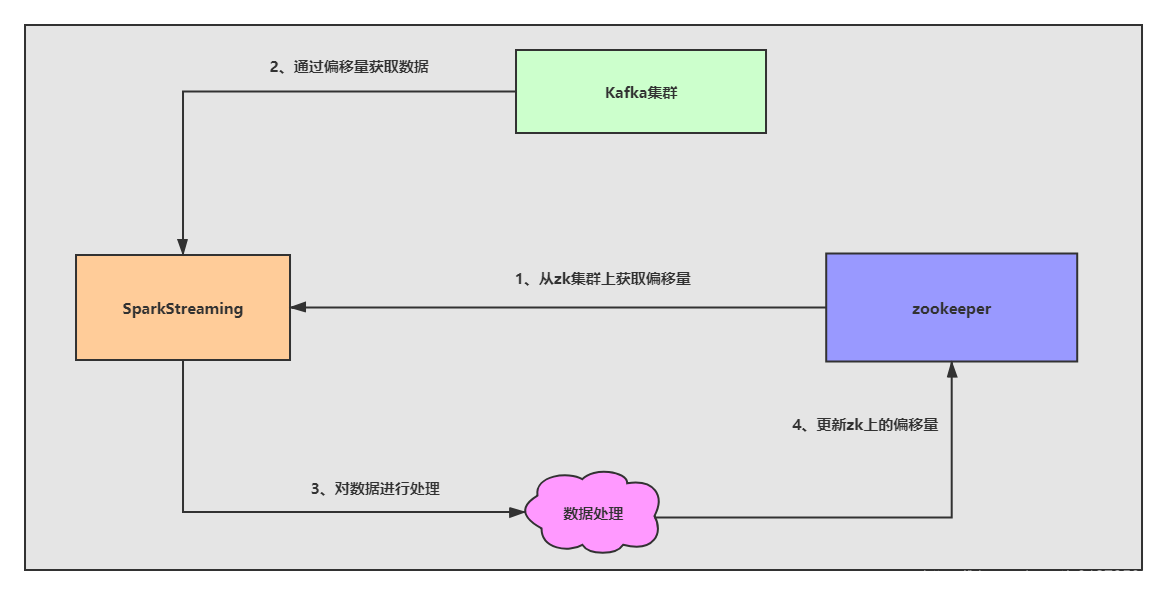
import kafka.common.TopicAndPartition
import kafka.message.MessageAndMetadata
import kafka.serializer.StringDecoder
import kafka.utils.{ZKGroupTopicDirs, ZkUtils}
import org.I0Itec.zkclient.ZkClient
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaUtils}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 使用直连方式 SparkStreaming连接kafka0.8获取数据
* 手动将偏移量数据保存到zookeeper中
*/
object KafkaManagerOffset08 {
def main(args: Array[String]): Unit = {
//todo:1、创建SparkConf 提交到集群中运行 不要设置master参数
val conf = new SparkConf().setAppName("KafkaManagerOffset08").setMaster("local[4]")
//todo: 2、设置SparkStreaming,并设定间隔时间
val ssc = new StreamingContext(conf, Seconds(5))
//todo:3、指定相关参数
//指定组名
val groupID = "consumer-kaikeba"
//指定消费者的topic名字
val topic = "wordcount"
//指定kafka的broker地址
val brokerList = "node01:9092,node02:9092,node03:9092"
//指定zookeeper的地址,用来存放数据偏移量数据,也可以使用Redis MySQL等
val zkQuorum = "node01:2181,node02:2181,node03:2181"
//创建Stream时使用的topic名字集合,SparkStreaming可同时消费多个topic
val topics: Set[String] = Set(topic)
//创建一个 ZKGroupTopicDirs 对象,就是用来指定在zk中的存储目录,用来保存数据偏移量
val topicDirs = new ZKGroupTopicDirs(groupID, topic)
//获取 zookeeper 中的路径 "/consumers/consumer-kaikeba/offsets/wordcount"
val zkTopicPath = topicDirs.consumerOffsetDir
//构造一个zookeeper的客户端 用来读写偏移量数据
val zkClient = new ZkClient(zkQuorum)
//准备kafka的参数
val kafkaParams = Map(
"metadata.broker.list" -> brokerList,
"group.id" -> groupID,
"enable.auto.commit" -> "false"
)
//todo:4、定义kafkaStream流
var kafkaStream: InputDStream[(String, String)] = null
//todo:5、获取指定的zk节点的子节点个数
val childrenNum = getZkChildrenNum(zkClient,zkTopicPath)
//todo:6、判断是否保存过数据 根据子节点的数量是否为0
if (childrenNum > 0) {
//构造一个map集合用来存放数据偏移量信息
var fromOffsets: Map[TopicAndPartition, Long] = Map()
//遍历子节点
for (i <- 0 until childrenNum) {
//获取子节点 /consumers/consumer-kaikeba/offsets/wordcount/0
val partitionOffset: String = zkClient.readData[String](s"$zkTopicPath/$i")
// /wordcount-----0
val tp = TopicAndPartition(topic, i)
//获取数据偏移量 将不同分区内的数据偏移量保存到map集合中
// wordcount/0 -> 1001
fromOffsets += (tp -> partitionOffset.toLong)
}
// 泛型中 key:kafka中的key value:hello tom hello jerry
//创建函数 解析数据 转换为(topic_name, message)的元组
val messageHandler = (mmd: MessageAndMetadata[String, String]) => (mmd.topic, mmd.message())
//todo:7、利用底层的API创建DStream 采用直连的方式(之前已经消费了,从指定的位置消费)
kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, (String, String)](ssc, kafkaParams, fromOffsets, messageHandler)
} else {
//todo:7、利用底层的API创建DStream 采用直连的方式(之前没有消费,这是第一次读取数据)
//zk中没有子节点数据 就是第一次读取数据 直接创建直连对象
kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
}
//todo:8、直接操作kafkaStream
//依次迭代DStream中的kafkaRDD 只有kafkaRDD才可以强转为HasOffsetRanges 从中获取数据偏移量信息
//之后是操作的RDD 不能够直接操作DStream 因为调用Transformation方法之后就不是kafkaRDD了获取不了偏移量信息
kafkaStream.foreachRDD(kafkaRDD => {
//强转为HasOffsetRanges 获取offset偏移量数据
val offsetRanges = kafkaRDD.asInstanceOf[HasOffsetRanges].offsetRanges
//获取数据
val lines: RDD[String] =kafkaRDD.map(_._2)
//todo:9、接下来就是对RDD进行操作 触发action
lines.foreachPartition(patition => {
patition.foreach(x => println(x))
})
//todo: 10、手动提交偏移量到zk集群上
for (o <- offsetRanges) {
//拼接zk路径 /consumers/consumer-kaikeba/offsets/wordcount/0
val zkPath = s"${topicDirs.consumerOffsetDir}/${o.partition}"
//将 partition 的偏移量数据 offset 保存到zookeeper中
ZkUtils.updatePersistentPath(zkClient, zkPath, o.untilOffset.toString)
}
})
//开启SparkStreaming 并等待退出
ssc.start()
ssc.awaitTermination()
}
/**
* 获取zk节点上的子节点的个数
* @param zkClient
* @param zkTopicPath
* @return
*/
def getZkChildrenNum(zkClient:ZkClient,zkTopicPath:String):Int ={
//查询该路径下是否有子节点,即是否有分区读取数据记录的读取的偏移量
// /consumers/consumer-kaikeba/offsets/wordcount/0
// /consumers/consumer-kaikeba/offsets/wordcount/1
// /consumers/consumer-kaikeba/offsets/wordcount/2
//子节点的个数
val childrenNum: Int = zkClient.countChildren(zkTopicPath)
childrenNum
}
}
6、 SparkStreaming应用程序如何保证Exactly-Once
一个流式计算如果想要保证Exactly-Once,那么首先要有三点要求
(1)Source支持Replay。
(2)流计算引擎本身处理能保证Exactly-Once。
(3)Sink支持幂等或事务更新
幂等----->它是一个数学概念 -------> f(f(x))=f(x)
比如说你想mysql表执行一个更新的sql语句
实现数据被处理且只被处理一次,就需要实现数据结果保存操作与偏移量保存操作在同一个事务中,或者你可以实现幂等操作。
mysql实现幂等
hbase实现幂等
也就是说如果要想让一个SparkStreaming的程序保证Exactly-Once,那么从如下三个角度出发
(1)接收数据:从Source中接收数据。
(2)转换数据:用DStream和RDD算子转换。
(3)储存数据:将结果保存至外部系统。
如果SparkStreaming程序需要实现Exactly-Once语义,那么每一个步骤都要保证Exactly-Once。
案例演示:
<dependency>
<groupId>org.scalikejdbc</groupId>
<artifactId>scalikejdbc_2.11</artifactId>
<version>3.1.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.scalikejdbc/scalikejdbc-config -->
<dependency>
<groupId>org.scalikejdbc</groupId>
<artifactId>scalikejdbc-config_2.11</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.39</version>
</dependency>
代码开发:
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.slf4j.LoggerFactory
import scalikejdbc.{ConnectionPool, DB, _}
/**
* SparkStreaming EOS:
* Input:Kafka
* Process:Spark Streaming
* Output:Mysql
*
mysql支持事务操作:
* todo: 保证EOS:
* 1、偏移量自己管理,即enable.auto.commit=false,这里保存在Mysql中
* 2、使用createDirectStream
* 3、事务输出: 结果存储与Offset提交在Driver端同一Mysql事务中
*/
object SparkStreamingEOSKafkaMysqlAtomic {
@transient lazy val logger = LoggerFactory.getLogger(this.getClass)
def main(args: Array[String]): Unit = {
val topic="topic1"
val group="spark_app1"
//todo: Kafka配置
val kafkaParams= Map[String, Object](
"bootstrap.servers" -> "node01:9092,node02:9092,node03:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean),
"group.id" -> group)
//在Driver端创建数据库连接池
ConnectionPool.singleton("jdbc:mysql://node03:3306/bigdata", "root", "123456")
val conf = new SparkConf().setAppName(this.getClass.getSimpleName.replace("$",""))
val ssc = new StreamingContext(conf,Seconds(5))
//1)初次启动或重启时,从指定的Partition、Offset构建TopicPartition
//2)运行过程中,每个Partition、Offset保存在内部currentOffsets = Map[TopicPartition, Long]()变量中
//3)后期Kafka Topic分区动扩展,在运行过程中不能自动感知
val initOffset=DB.readOnly(implicit session=>{
sql"select `partition`,offset from kafka_topic_offset where topic =${topic} and `group`=${group}"
.map(item=> new TopicPartition(topic, item.get[Int]("partition")) -> item.get[Long]("offset"))
.list().apply().toMap
})
//todo: CreateDirectStream
//从指定的Topic、Partition、Offset开始消费
val sourceDStream =KafkaUtils.createDirectStream[String,String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Assign[String,String](initOffset.keys,kafkaParams,initOffset)
)
sourceDStream.foreachRDD(rdd=>{
if (!rdd.isEmpty()){
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
offsetRanges.foreach(offsetRange=>{
logger.info(s"Topic: ${offsetRange.topic},Group: ${group},Partition: ${offsetRange.partition},fromOffset: ${offsetRange.fromOffset},untilOffset: ${offsetRange.untilOffset}")
})
//todo: 统计分析
//将结果收集到Driver端
val sparkSession = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate()
import sparkSession.implicits._
val dataFrame = sparkSession.read.json(rdd.map(_.value()).toDS)
dataFrame.createOrReplaceTempView("tmpTable")
val result=sparkSession.sql(
"""
|select
| --每分钟
| eventTimeMinute,
| --每种语言
| language,
| -- 次数
| count(1) pv,
| -- 人数
| count(distinct(userID)) uv
|from(
| select *, substr(eventTime,0,16) eventTimeMinute from tmpTable
|) as tmp group by eventTimeMinute,language
""".stripMargin
).collect()
//在Driver端存储数据、提交Offset
//结果存储与Offset提交在同一事务中原子执行
//todo: 这里将偏移量保存在Mysql中
DB.localTx(implicit session=>{
//结果存储
result.foreach(row=>{
sql"""
insert into twitter_pv_uv (eventTimeMinute, language,pv,uv)
value (
${row.getAs[String]("eventTimeMinute")},
${row.getAs[String]("language")},
${row.getAs[Long]("pv")},
${row.getAs[Long]("uv")}
)
on duplicate key update pv=pv,uv=uv
""".update.apply()
})
//todo: Offset提交
offsetRanges.foreach(offsetRange=>{
val affectedRows = sql"""
update kafka_topic_offset set offset = ${offsetRange.untilOffset}
where
topic = ${topic}
and `group` = ${group}
and `partition` = ${offsetRange.partition}
and offset = ${offsetRange.fromOffset}
""".update.apply()
if (affectedRows != 1) {
throw new Exception(s"""Commit Kafka Topic: ${topic} Offset Faild!""")
}
})
})
}
})
ssc.start()
ssc.awaitTermination()
}
}
7、 SparkStreaming调优
7.1 调整BlockReceiver的数量
案例演示:
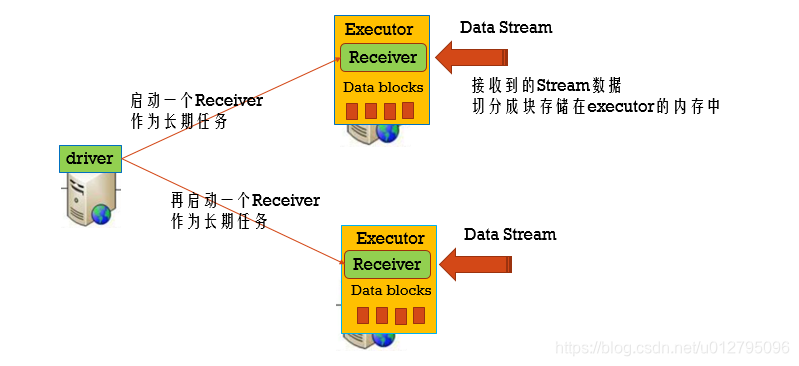
val kafkaStream = {
val sparkStreamingConsumerGroup = "spark-streaming-consumer-group"
val kafkaParams = Map(
"zookeeper.connect" -> "node01:2181,node02:2181,node03:2181",
"group.id" -> "spark-streaming-test")
val inputTopic = "test"
val numPartitionsOfInputTopic = 3
val streams = (1 to numPartitionsOfInputTopic) map {x =>
KafkaUtils.createStream(ssc, kafkaParams, Map(inputTopic -> 1), StorageLevel.MEMORY_ONLY_SER).map(_._2)
}
val unifiedStream = ssc.union(streams)
7.2 调整Block的数量
batchInterval : 触发批处理的时间间隔
blockInterval :将接收到的数据生成Block的时间间隔,spark.streaming.blockInterval(默认是200ms),那么,BlockRDD的分区数 = batchInterval / blockInterval,即一个Block就是RDD的一个分区,就是一个task
比如,batchInterval是2秒,而blockInterval是200ms,那么task数为10,如果task的数量太少,比一个executor的core数还少的话,那么可以减少blockInterval,blockInterval最好不要小于50ms,太小的话导致task数太多,那么launch task的时间久多了。
7.3 调整Receiver的接受速率
pps:permits per second 每秒允许接受的数据量(QPS -> queries per second)
Spark Streaming默认的PPS是没有限制的,可以通过参数spark.streaming.receiver.maxRate来控制,默认是Long.Maxvalue
7.4 调整数据处理的并行度
BlockRDD的分区数
- 通过Receiver接受数据的特点决定
- 也可以自己通过repartition设置
ShuffleRDD的分区数 - 默认的分区数为spark.default.parallelism(core的大小)
- 通过我们自己设置决定
val wordCounts = words.map(x => (x, 1)).reduceByKey((a: Int, b: Int) => a + b, new HashPartitioner(10))
7.5 数据的序列化
SparkStreaming两种需要序列化的数据:
- a. 输入的数据:默认是以StorageLevel.MEMORY_AND_DISK_SER_2的形式存储在executor上的内存中
- 缓存的数据:默认是以StorageLevel.MEMORY_ONLY_SER的形式存储的内存中
使用Kryo序列化机制,比Java序列化机制性能好
val conf = new SparkConf().setMaster(...).setAppName(...)
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
val sc = new SparkContext(conf)
7.6 内存调优
需要内存大小
和transformation的类型有关,如果使用的是updateStateByKey,Window这样的算子,那么内存就要设置得偏大。
数据存储级别
如果把接收到的数据设置的存储级别是MEMORY_DISK这种级别,也就是说如果内存不够可以把数据存储到磁盘上,其实性能还是不好的,性能最好的就是所有的数据都在内存里面,所以如果在资源允许的情况下,把内存调大一点,让所有的数据都存在内存里面。
7.7 Output Operations性能
保存结果到外部的存储介质中,比如mysql/hbase数据库
使用高性能的算子操作实现
// todo: 方案三
result.foreachRDD(rdd=>{
rdd.foreachPartition( iter =>{
val conn = DriverManager.getConnection("jdbc:mysql://node03:3306/test", "root", "123456")
val statement = conn.prepareStatement(s"insert into wordcount(word, count) values (?, ?)")
iter.foreach( record =>{
statement.setString(1, record._1)
statement.setInt(2, record._2)
statement.execute()
})
statement.close()
conn.close()
})
})
//todo: 方案四
result.foreachRDD(rdd=>{
rdd.foreachPartition( iter =>{
val conn = DriverManager.getConnection("jdbc:mysql://node103:3306/test", "root", "123456")
val statement = conn.prepareStatement(s"insert into wordcount(word, count) values (?, ?)")
//关闭自动提交
conn.setAutoCommit(false);
iter.foreach( record =>{
statement.setString(1, record._1)
statement.setInt(2, record._2)
//添加到一个批次
statement.addBatch()
})
//批量提交该分区所有数据
statement.executeBatch()
conn.commit()
// 关闭资源
statement.close()
conn.close()
})
})
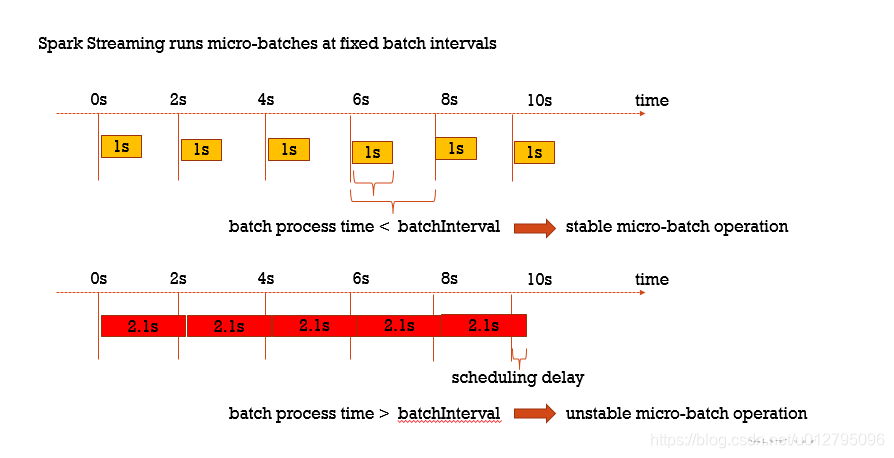
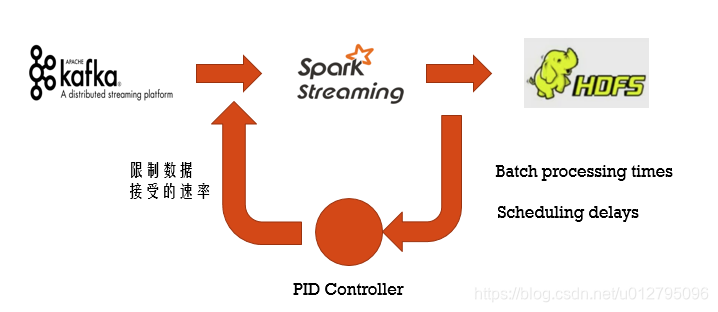
7.8 Backpressure背压机制
在默认情况下,Spark Streaming 通过 receivers (或者是 Direct 方式) 以生产者生产数据的速率接收数据。当 batch processing time > batch interval 的时候,也就是每个批次数据处理的时间要比 Spark Streaming 批处理间隔时间长;越来越多的数据被接收,但是数据的处理速度没有跟上,导致系统开始出现数据堆积,可能进一步导致 Executor 端出现 OOM 问题而出现失败的情况。
Feedback Loop : 动态使得Streaming app从unstable状态回到stable状态
从Spark1.5版本开始:spark.streaming.backpressure.enabled = true
把spark.streaming.backpressure.enabled 参数设置为ture,开启背压机制后Spark Streaming会根据延迟动态去kafka消费数据,上限由spark.streaming.kafka.maxRatePerPartition参数控制。
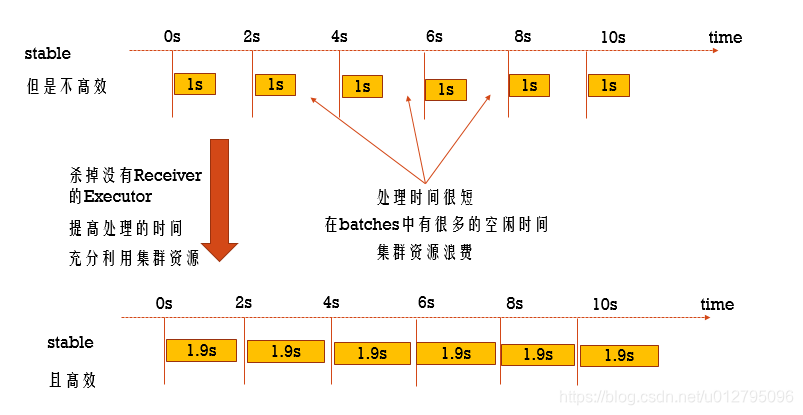
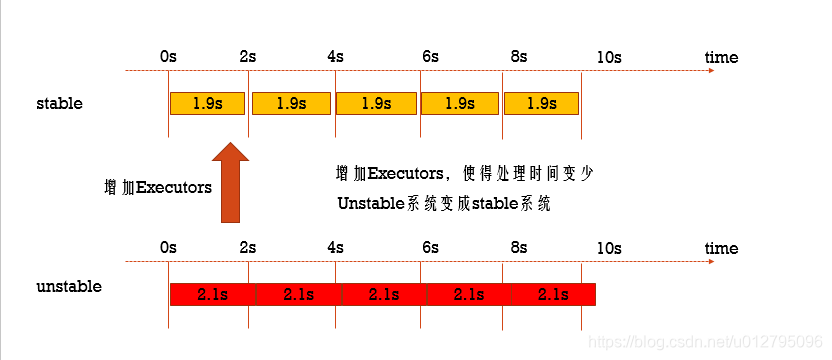
7.9 Elastic Scaling(资源动态分配)
动态分配资源:
批处理动态的决定这个application中需要多少个Executors:
- 当一个Executor空闲的时候,将这个Executor杀掉
- 当task太多的时候,动态的启动Executors
Streaming分配Executor的原则是比对 process time / batchInterval 的比率:
如果延迟了,那么就自动增加资源
从Spark2.0有这个功能,开启资源动态分配: spark.streaming.dynamicAllocation.enabled = true

7.10 数据倾斜调优
因为SparkStreaming的底层就是RDD,之前我们讲SparkCore的所有的数据倾斜的调优策略(见SparkCore调优)都适合于SparkStreaming,大家一定要灵活掌握,这个在实际开发的工作当中用得频率较高,各位同学面试的时候也可以从这个角度跟面试官聊。
mapreduce hive spark-core(RDD) sparksql sparkStreaming
其本质是什么-------》 就是要处理的数据中,具有某种特性的key太多了。
7.11 spark Streaming精准一次消费
- 手动维护偏移量
- 处理完业务数据后,再进行提交偏移量操作
- 极端情况下,如在提交偏移量时断网或者停电会造成spark程序第二次启动时重复消费问题,所以在涉及到金额或者精确性非常高的场景会使用事务保证精确一次消费。下级数据库需支持事务
7.12 spark streaming优雅关闭
- 正常关闭sparkContext对象,不再接受新的数据,把接受到的数据处理完毕后再停止。
- 实现方式见《4. SparkStreaming任务优雅关闭》
8、知识扩展-ScalikeJDBC
8.1 什么是ScalikeJDBC
ScalikeJDBC是Scala开发人员基于SQL的简洁数据库访问库。
该库自然包装JDBC API,为您提供易于使用且非常灵活的API。
更重要的是,QueryDSL使您的代码类型安全且可重用。
ScalikeJDBC是一个实用且适合生产的产品。 将此库用于实际项目.
8.2 IDEA项目中导入相关库
<!-- https://mvnrepository.com/artifact/org.scalikejdbc/scalikejdbc -->
<dependency>
<groupId>org.scalikejdbc</groupId>
<artifactId>scalikejdbc_2.11</artifactId>
<version>3.1.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.scalikejdbc/scalikejdbc-config -->
<dependency>
<groupId>org.scalikejdbc</groupId>
<artifactId>scalikejdbc-config_2.11</artifactId>
<version>3.1.0</version>
</dependency>
<!-- mysql " mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
8.3 数据库操作
8.3.1 数据库连接配置信息
在IDEA的resources文件夹下创建application.conf
#mysql的连接配置信息
db.default.driver="com.mysql.jdbc.Driver"
db.default.url="jdbc:mysql://node03:3306/spark"
db.default.user="root"
db.default.password="123456"
scalikeJDBC默认加载default配置,或者使用自定义配置
#mysql的连接配置信息
db.fred.driver="com.mysql.jdbc.Driver"
db.fred.url="jdbc:mysql://node03:3306/spark"
db.fred.user="root"
db.fred.password="123456"
8.3.2 加载数据配置信息
//默认加载default配置信息
DBs.setup()
//加载自定义的fred配置信息
DBs.setup('fred)
8.3.3 查询数据库并封装数据
//配置mysql
DBs.setup()
//查询数据并返回单个列,并将列数据封装到集合中
val list = DB.readOnly({implicit session =>
SQL("select content from post")
.map(rs =>
rs.string("content")).list().apply()
})
for(s <- list){
println(s)
}
case class Users(id:String, name:String, nickName:String)
/**
* 查询数据库,并将数据封装成对象,并返回一个集合
*/
//配置mysql
DBs.setup('fred)
//查询数据并返回单个列,并将列数据封装到集合中
val users = NamedDB('fred).readOnly({implicit session =>
SQL("select * from users").map(rs =>
Users(rs.string("id"), rs.string("name"),
rs.string("nickName"))).list().apply()
})
for (u <- users){
println(u)
}
8.3.4 插入数据
8.3.4.1 AutoCommit
/**
* 插入数据,使用AutoCommit
* @return
*/
val insertResult = DB.autoCommit({implicit session =>
SQL("insert into users(name, nickName) values(?,?)").bind("test01", "test01")
.update().apply()
})
println(insertResult)
8.3.4.2 插入返回主键标识
/**
* 插入数据,并返回主键
* @return
*/
val id = DB.localTx({implicit session =>
SQL("insert into users(name, nickName, sex) values(?,?,?)").bind("test", "000", "male")
.updateAndReturnGeneratedKey("nickName").apply()
})
println(id)
8.3.4.3 事务插入
/**
* 使用事务插入数据库
* @return
*/
val tx = DB.localTx({implicit session =>
SQL("insert into users(name, nickName, sex) values(?,?,?)").bind("test", "haha", "male").update().apply()
//下一行会报错,用于测试
var s = 1 / 0
SQL("insert into users(name, nickName, sex) values(?,?,?)").bind("test01", "haha01", "male01").update().apply()
})
println(s"tx = ${tx}")
8.3.4.4 更新数据
/**
* 更新数据
* @return
*/
DB.localTx({implicit session =>
SQL("update users set nickName = ?").bind("xiaoming").update().apply()
})