学习cheerio模块,简单做一个爬取图片网站的图片,并且将这些图片下载到本地指定的文件夹下,很多图片网站都有一些反爬取的机制,找的好几个都会报302错误,所以我找了一个小的图片网站,这个没有反爬取机制,实现了一下,最后成功获取并下载到了图片,以下就是全部的完整代码,也不做太详细的记录了。
完整的爬取图片代码如下:
const https = require('https');
const request = require('request');
const fs = require('fs');
const cheerio = require("cheerio");
//下载爬取的图片文件夹
let downloadDir = 'C:/Users/admin/Desktop/spider/';
/**
* 开始爬取
* @param url
*/
function start(url) {
let result = [];
https.get(url, (response) => {
//获取响应数据
response.on('data', (chunk) => {
result.push(chunk);
})
//响应结束
response.on('end', () => {
//将数据转换为字符串(html字符串)
let data = result.join('');
spider(data)
})
})
}
/**
* 爬虫函数
* @param data 网页数据
*/
function spider(data) {
let $ = cheerio.load(data);
let items = $('.pli li');
console.log('爬取到的数据条数:', items.length);
items.each((index, item) => {
let url = $(item).find('.il_img img').attr('src');
url = url.split('!')?.[0];
url = `https:${url}`
let title = $(item).find('p a').text();
let imgType = url.split('.').pop();
request(url).pipe(fs.createWriteStream(`${downloadDir}/${title}_${index}.${imgType}`));
});
}
//开始爬取
start('https://www.k2r2.com/shaonv_c43757/9.html');
启动以后就会将爬取到的图片下载到指定文件夹中
原网页的图片列表
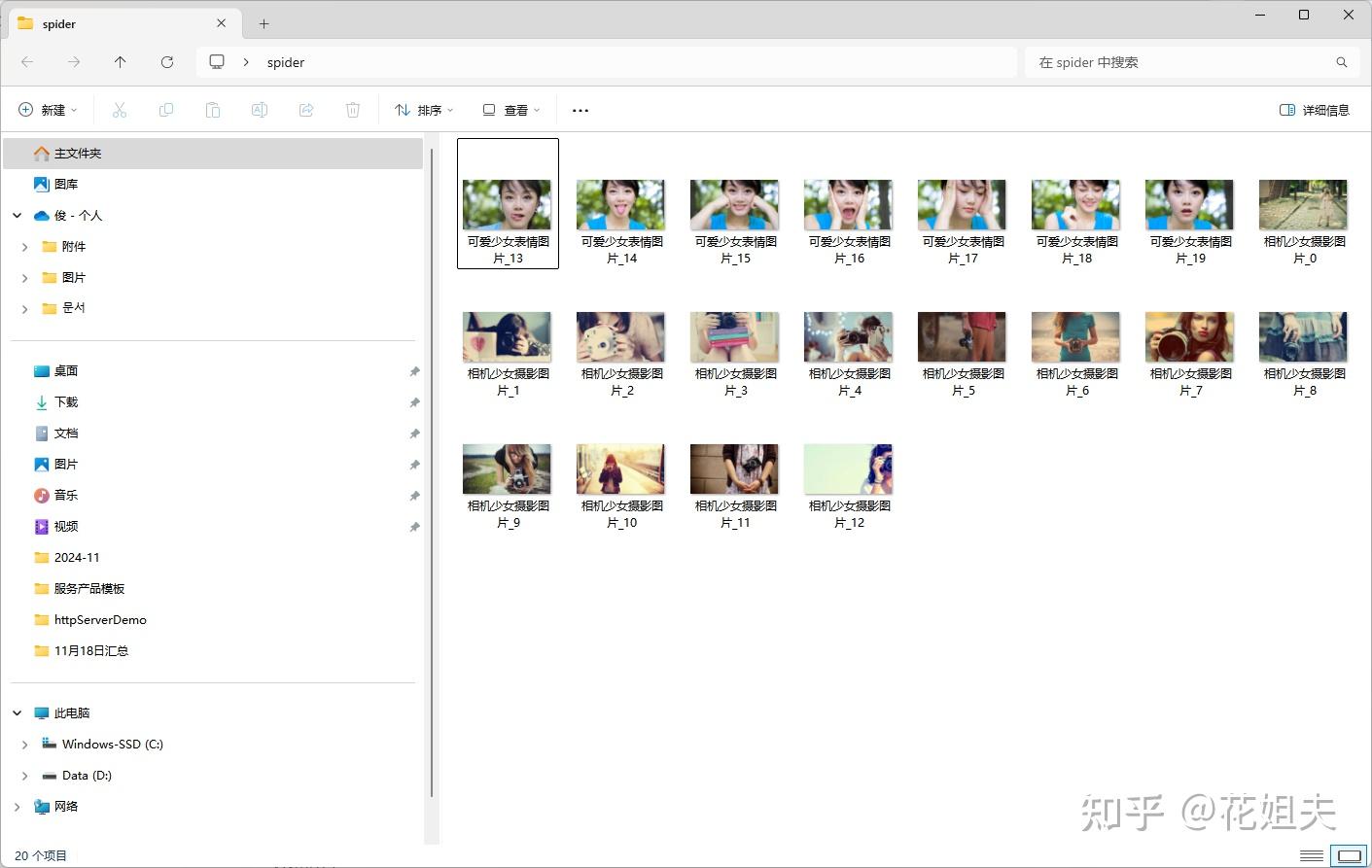
爬取到的图片