无论你是刚入行的新手,还是想要进阶的从业者,掌握有效的学习方法都是成为大数据开发高手的关键。
目录

本文将为你揭示如何高效学习大数据开发,让你在这个领域脱颖而出。
理解大数据开发的本质
首先,我们需要明确什么是大数据开发。大数据开发是指利用各种工具和技术来处理、分析和解释大规模、复杂的数据集。它涉及数据采集、存储、处理、分析和可视化等多个环节。

作为一名大数据开发者,你需要掌握的核心技能包括:
- 编程语言(如Java、Python、Scala)
- 分布式计算框架(如Hadoop、Spark)
- 数据库技术(如MySQL、MongoDB、Cassandra)
- 数据分析和机器学习算法
- 数据可视化工具
学习大数据开发的有效方法
1. 建立增强回路

1.1 自我认可
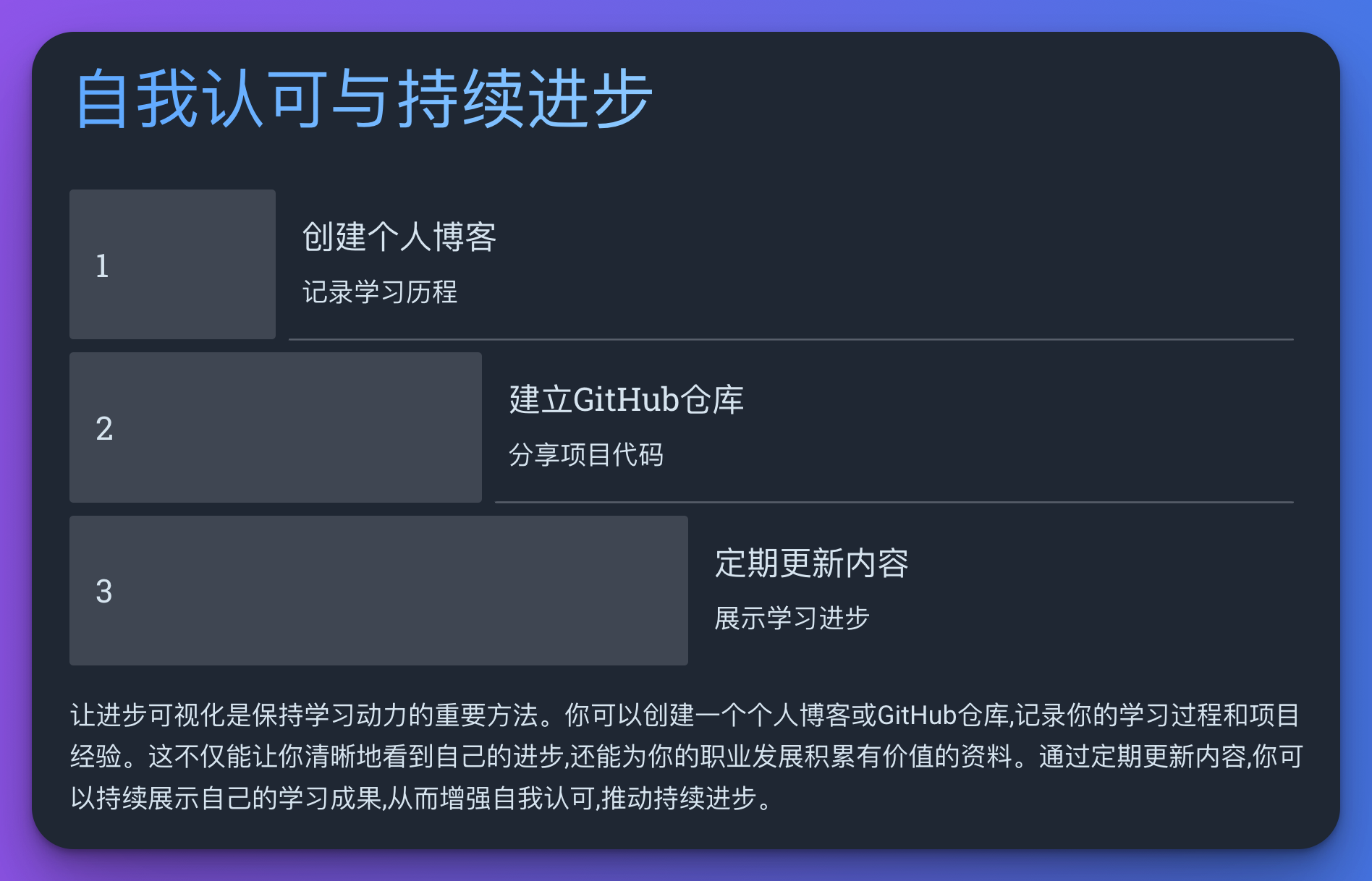
让进步可视化是保持学习动力的重要方法。你可以创建一个个人博客或GitHub仓库,记录你的学习过程和项目经验。
例如,你可以创建一个名为"我的大数据之旅"的GitHub仓库,定期更新你的学习笔记和项目代码。这不仅能让你清晰地看到自己的进步,还能为你的职业发展积累有价值的资料。
1.2 他人认可
参与开源项目或技术社区是获得他人认可的好方法。你可以从简单的文档贡献开始,逐步提交代码修复或新功能。

比如,你可以加入Apache Hadoop或Apache Spark的社区,从回答新手问题开始,慢慢深入到代码贡献。每一次的贡献都会给你带来成就感和认可。(这个很难,如果做到了,就成了大神了。。。)
2. 建立调节回路

2.1 设定明确目标
制定SMART(具体、可衡量、可实现、相关、有时限)目标是进行有效学习的第一步。
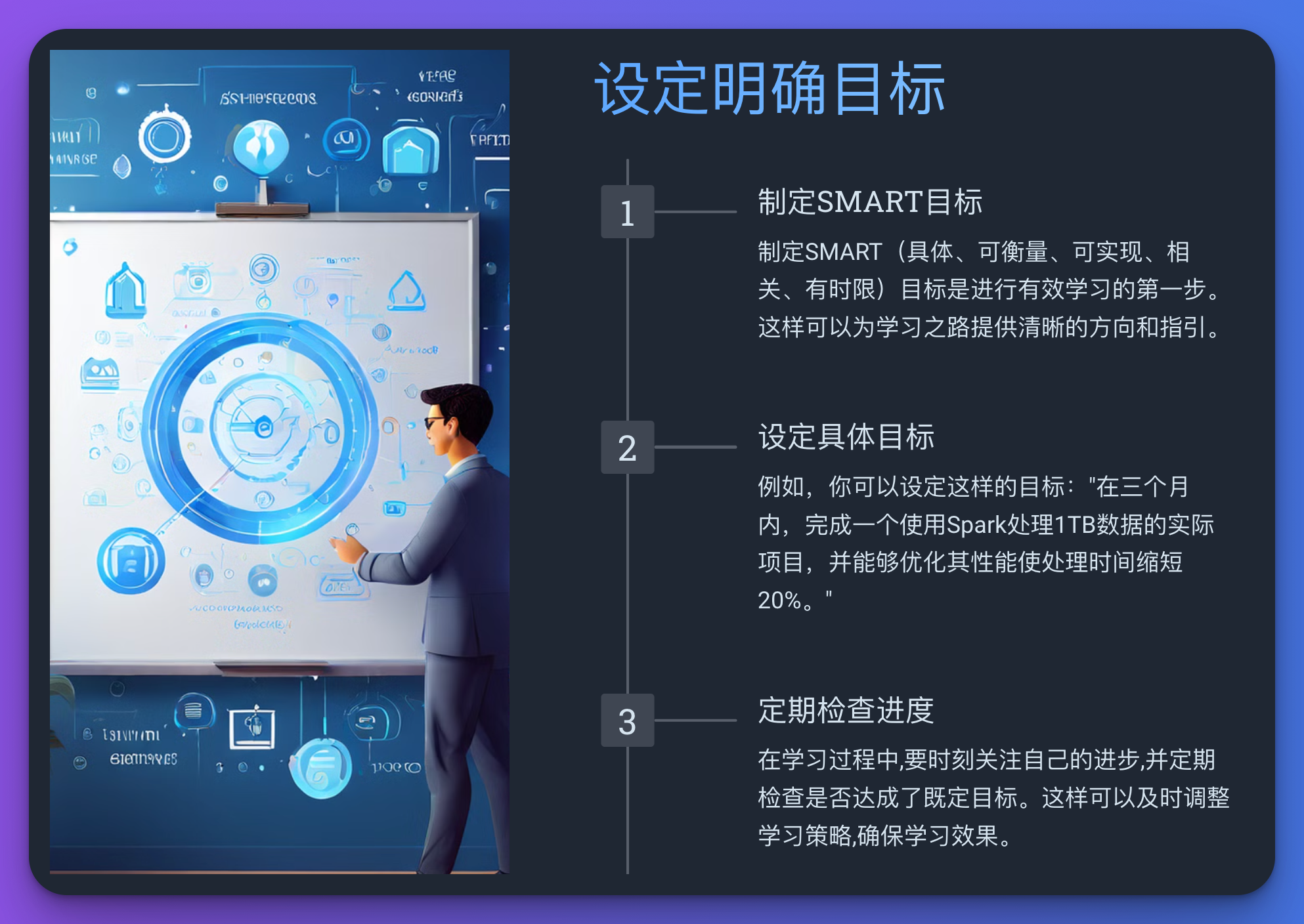
例如,你可以设定这样的目标:“在三个月内,完成一个使用Spark处理1TB数据的实际项目,并能够优化其性能使处理时间缩短20%。”
2.2 获取及时反馈
找到合适的反馈渠道至关重要。你可以:
- 使用性能分析工具作为"镜子"
- 寻找经验丰富的同事或导师作为"教练"
- 参加编程竞赛,将其他参赛者视为"对手"

2.3 针对性训练

根据"技能分层图"进行针对性训练:
- 硬件层:了解分布式系统架构
- 代码层:精通核心编程语言和框架
- 应用层:熟悉各种大数据处理场景
- 表现层:提高问题分析和解决能力
实战案例:优化Spark作业
让我们通过一个实际的例子来说明如何应用这些方法。假设你正在优化一个Spark作业,目标是减少处理时间。
-
设定目标:将作业运行时间从2小时减少到1小时以内。
-
编写基准代码:

from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("DataProcessing").getOrCreate()
# 读取数据
df = spark.read.csv("hdfs://data/large_dataset.csv")
# 进行一些复杂的数据处理
processed_df = df.groupBy("category").agg({"value": "sum"}).orderBy("sum(value)", ascending=False)
# 将结果保存
processed_df.write.csv("hdfs://data/output")
spark.stop()
-
使用Spark UI作为"镜子",分析作业的瓶颈。
-
咨询有经验的同事(“教练”),获取优化建议。
-
针对性优化:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
spark = SparkSession.builder.appName("OptimizedDataProcessing").getOrCreate()
# 优化1:设置合适的分区数
spark.conf.set("spark.sql.shuffle.partitions", "200")
# 优化2:缓存频繁使用的数据
df = spark.read.csv("hdfs://data/large_dataset.csv").cache()
# 优化3:使用更高效的操作
processed_df = df.groupBy("category").agg({"value": "sum"}).orderBy(col("sum(value)").desc())
# 优化4:使用更高效的输出格式
processed_df.write.parquet("hdfs://data/output")
spark.stop()
-
比较优化前后的性能,计算提升百分比。
-
在技术博客或社区中分享你的优化经验,获得反馈和认可。
通过这个过程,你不仅优化了Spark作业,还提升了自己的技能,并在社区中获得了认可。这种正向循环将持续推动你向大数据开发高手的目标迈进。
大数据开发的核心技能树
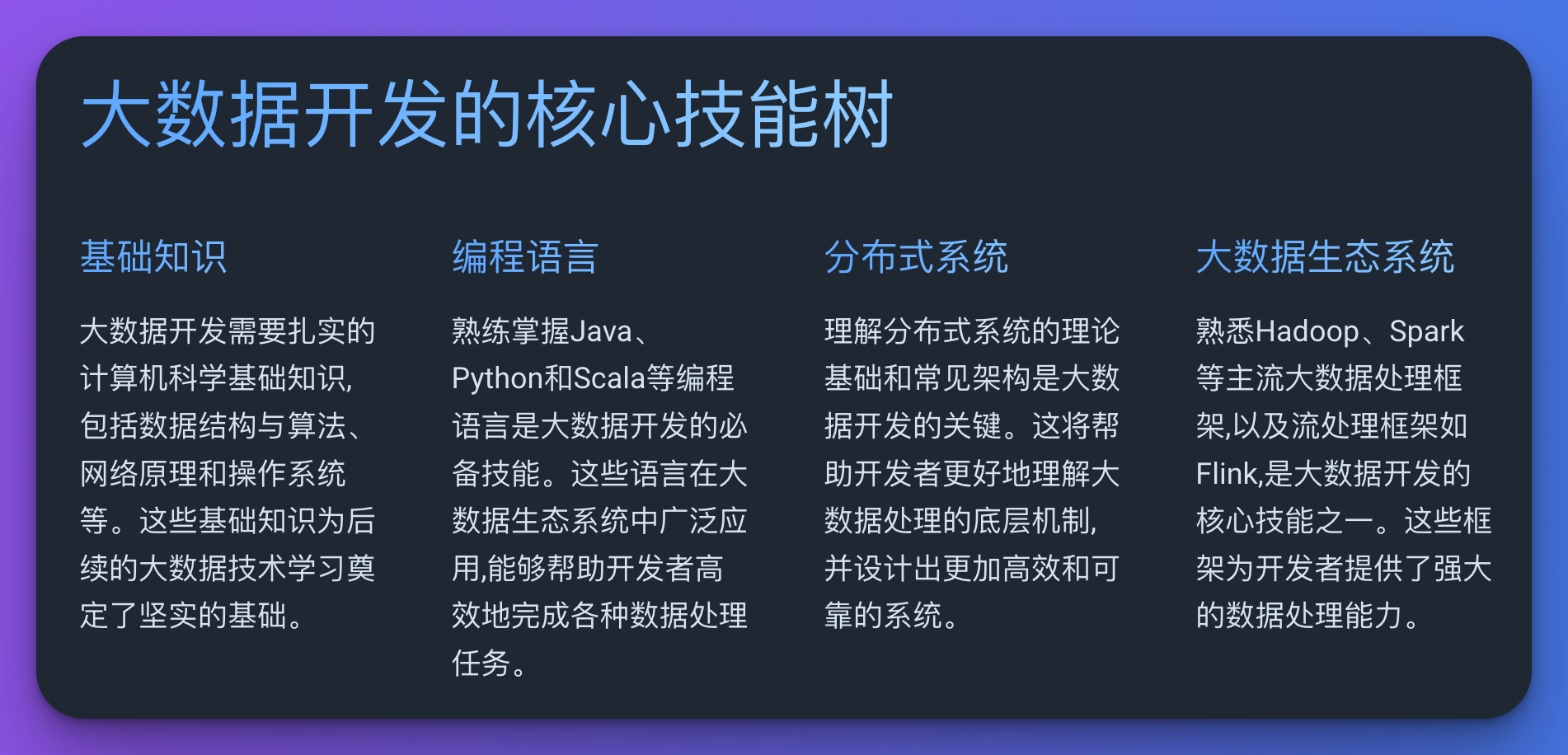
要成为大数据开发高手,你需要构建一个全面的技能树。以下是一个基本的技能树结构:
-
基础知识
- 计算机科学基础
- 数据结构与算法
- 网络原理
- 操作系统
-
编程语言
- Java
- Python
- Scala
-
分布式系统
- 理论基础
- 常见架构
-
大数据生态系统
- Hadoop生态
- Spark生态
- 流处理框架(如Flink)
-
数据存储
- 关系型数据库(如MySQL)
- NoSQL数据库(如MongoDB、Cassandra)
- 分布式文件系统(如HDFS)
-
数据处理与分析
- ETL流程
- 数据清洗技术
- 数据分析方法
- 机器学习基础
-
性能优化
- SQL优化
- Spark调优
- 集群配置与管理
-
数据可视化
- 可视化原理
- 常用工具(如Tableau、ECharts)
-
软技能
- 项目管理
- 团队协作
- 技术文档写作
实战学习路径
接下来,我们将通过一个实际的学习路径来说明如何系统地提升你的大数据开发技能。

阶段1:夯实基础(3-6个月)
- 学习Java或Python的基础语法和高级特性
- 复习数据结构与算法,刷题训练
- 学习Linux基本命令和Shell脚本编写
- 了解计算机网络基础知识
实践项目:开发一个简单的日志分析工具

import re
from collections import Counter
def analyze_log(log_file):
ip_pattern = r'\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}'
with open(log_file, 'r') as f:
log_contents = f.read()
ip_addresses = re.findall(ip_pattern, log_contents)
ip_counts = Counter(ip_addresses)
return ip_counts.most_common(10)
if __name__ == "__main__":
top_ips = analyze_log('access.log')
print("Top 10 IP addresses:")
for ip, count in top_ips:
print(f"{ip}: {count}")
阶段2:入门大数据生态(3-6个月)
- 学习Hadoop基础,包括HDFS和MapReduce原理
- 掌握Hive的使用,学习HQL
- 学习Spark核心概念和RDD编程模型
- 了解NoSQL数据库,如MongoDB或Cassandra

实践项目:使用Spark开发一个简单的单词计数程序
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("WordCount").getOrCreate()
# 读取文本文件
text_file = spark.read.text("hdfs://your-hdfs-path/input.txt")
# 进行单词计数
word_counts = text_file.rdd.flatMap(lambda line: line.value.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
# 将结果转换为DataFrame并显示
word_counts.toDF(["word", "count"]).show()
spark.stop()
阶段3:深入学习与实践(6-12个月)

- 深入学习Spark SQL、Spark Streaming和MLlib
- 学习数据仓库设计原理和实践
- 掌握数据清洗和特征工程技术
- 学习基本的机器学习算法及其在Spark中的应用
实践项目:开发一个实时流处理系统,分析社交媒体数据
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode, split, window
spark = SparkSession.builder.appName("TwitterStreamAnalysis").getOrCreate()
# 假设我们有一个持续输入的Twitter数据流
tweets = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "twitter_topic") \
.load()
# 解析JSON数据
parsed_tweets = tweets.selectExpr("CAST(value AS STRING)") \
.select(from_json("value", tweetSchema).alias("tweet"))
# 提取hashtags
hashtags = parsed_tweets.select(
explode(split(parsed_tweets.tweet.text, " "))
.alias("hashtag")
).where("hashtag like '#%'")
# 计算每分钟的热门hashtags
popular_hashtags = hashtags \
.groupBy(
window("timestamp", "1 minute"),
"hashtag"
) \
.count() \
.orderBy("window", "count DESC")
# 开始流处理
query = popular_hashtags \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
query.awaitTermination()
阶段4:优化与扩展(持续进行)

- 学习Spark性能调优技巧
- 深入研究分布式系统原理
- 学习容器技术(如Docker)和集群管理工具(如Kubernetes)
- 探索新兴的大数据技术,如Delta Lake、Apache Flink等
实践项目:优化大规模数据处理管道
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, when
spark = SparkSession.builder \
.appName("OptimizedDataPipeline") \
.config("spark.sql.adaptive.enabled", "true") \
.config("spark.sql.shuffle.partitions", "200") \
.getOrCreate()
# 读取大规模数据集
df = spark.read.parquet("hdfs://path/to/large_dataset.parquet")
# 数据清洗和转换
cleaned_df = df.dropDuplicates().na.fill(0)
# 复杂的数据处理逻辑
processed_df = cleaned_df.select(
col("id"),
when(col("value") > 100, "High")
.when(col("value") > 50, "Medium")
.otherwise("Low").alias("category")
)
# 聚合计算
result = processed_df.groupBy("category").count()
# 写入结果
result.write.mode("overwrite").partitionBy("category").parquet("hdfs://path/to/output")
spark.stop()
持续学习的方法
- 参与开源项目:贡献代码到Apache Hadoop或Apache Spark等项目。
- 关注技术博客:如Databricks的技术博客,了解最新的大数据技术发展。
- 参加技术会议:如Strata Data Conference,与行业专家交流。
- 阅读经典书籍:如《Designing Data-Intensive Applications》,深入理解分布式系统。
- 实践实践再实践:不断挑战自己,尝试解决更复杂的实际问题。
结语

成为大数据开发高手是一个持续学习和实践的过程。通过建立增强回路和调节回路,设定明确目标,获取及时反馈,进行针对性训练,你将能够更快、更有效地提升自己的技能水平。
记住,每一个小进步都是通往专业化的重要一步。保持好奇心和学习热情,相信不久的将来,你也能成为大数据领域的佼佼者。
通过系统学习、持续实践和不断反思,你将能够在这个快速发展的领域中站稳脚跟,并最终成为一名出色的大数据开发工程师。
记住,技术的本质是解决问题,而不仅仅是掌握工具。在学习技术的同时,也要培养解决实际问题的能力和创新思维。
一起加油~