
在这个AI和大数据主宰的时代,Python无疑是最炙手可热的编程语言之一。无论你是想转行还是提升技能,学习Python都是一个明智之选。但是,该如何开始呢?今天,让我们聊聊"糙快猛"的Python学习之道。
什么是"糙快猛"学习法?
"糙快猛"学习法,顾名思义,就是:
- 糙:不追求完美,允许存在粗糙
- 快:以最快的速度推进
- 猛:勇往直前,不畏困难

这种方法强调在学习过程中保持前进的动力,而不是过分追求完美主义。
我的故事:从0到1的大数据之旅
作为一个曾经的Python小白,我深知学习编程的困难。还记得我刚开始学习时,常常被各种概念和语法搞得头昏脑胀。有一次,我花了整整一周时间来理解"列表推导式"这个概念。
那时候,我遵循传统的学习方法:细嚼慢咽,力求完美。结果呢?进度缓慢,常常陷入自我怀疑的泥潭。
直到有一天,我偶然看到"糙快猛"这个词,灵光乍现。我决定改变学习策略,开始了我的"糙快猛"Python学习之旅。

"糙快猛"学习Python的实践指南
1. 从简单的项目开始,快速上手
别被复杂的概念吓到,先从简单的项目开始。比如,写一个简单的计算器:
def calculator():
operation = input("请选择运算 (+, -, *, /): ")
num1 = float(input("请输入第一个数字: "))
num2 = float(input("请输入第二个数字: "))
if operation == '+':
result = num1 + num2
elif operation == '-':
result = num1 - num2
elif operation == '*':
result = num1 * num2
elif operation == '/':
result = num1 / num2
else:
return "无效的运算符"
return f"结果是: {result}"
print(calculator())
这个简单的项目已经包含了变量、函数、条件语句等基本概念。

2. 利用AI助手,快速解决问题
在这个AI盛行的时代,我们要学会利用工具。遇到不懂的问题,可以先问问ChatGPT。但记住,AI是助手,不是替身。理解和消化知识的过程还是需要我们自己来完成。
3. 不断实践,在错误中学习

记住,"糙快猛"不等于粗心大意。我们的目标是通过大量实践来加深理解。比如,试着用不同方法实现同一个功能:
# 方法1:使用for循环
def sum_numbers1(numbers):
total = 0
for num in numbers:
total += num
return total
# 方法2:使用sum()函数
def sum_numbers2(numbers):
return sum(numbers)
# 方法3:使用递归
def sum_numbers3(numbers):
if len(numbers) == 0:
return 0
return numbers[0] + sum_numbers3(numbers[1:])
numbers = [1, 2, 3, 4, 5]
print(sum_numbers1(numbers))
print(sum_numbers2(numbers))
print(sum_numbers3(numbers))
通过比较不同方法的优劣,我们可以更深入地理解Python的特性。
4. 建立自己的知识体系

在"糙快猛"的学习过程中,我们可能会遗漏一些细节。没关系,重要的是要及时整理,建立自己的知识体系。可以使用思维导图或者编写简单的文档来梳理所学内容。
5. 参与开源项目,提升实战能力

当你掌握了基础知识后,不要停滞不前。去GitHub上找一些简单的开源项目参与进去。这不仅能提升你的编码能力,还能让你学会如何在团队中协作。
进阶:“糙快猛"到"精益求精”
在掌握了"糙快猛"的学习方法后,我们不能就此止步。真正的Python大师知道何时该"糙快猛",何时该"精益求精"。让我们来看看如何将你的Python技能提升到下一个层次。
1. 深入理解Python的设计哲学
Python之父Guido van Rossum曾说:"Python是一门优雅的语言。“要真正掌握Python,我们需要理解它的设计哲学。例如,Python的"禅”:
import this
运行这行代码,你会看到Python的19条设计原则。
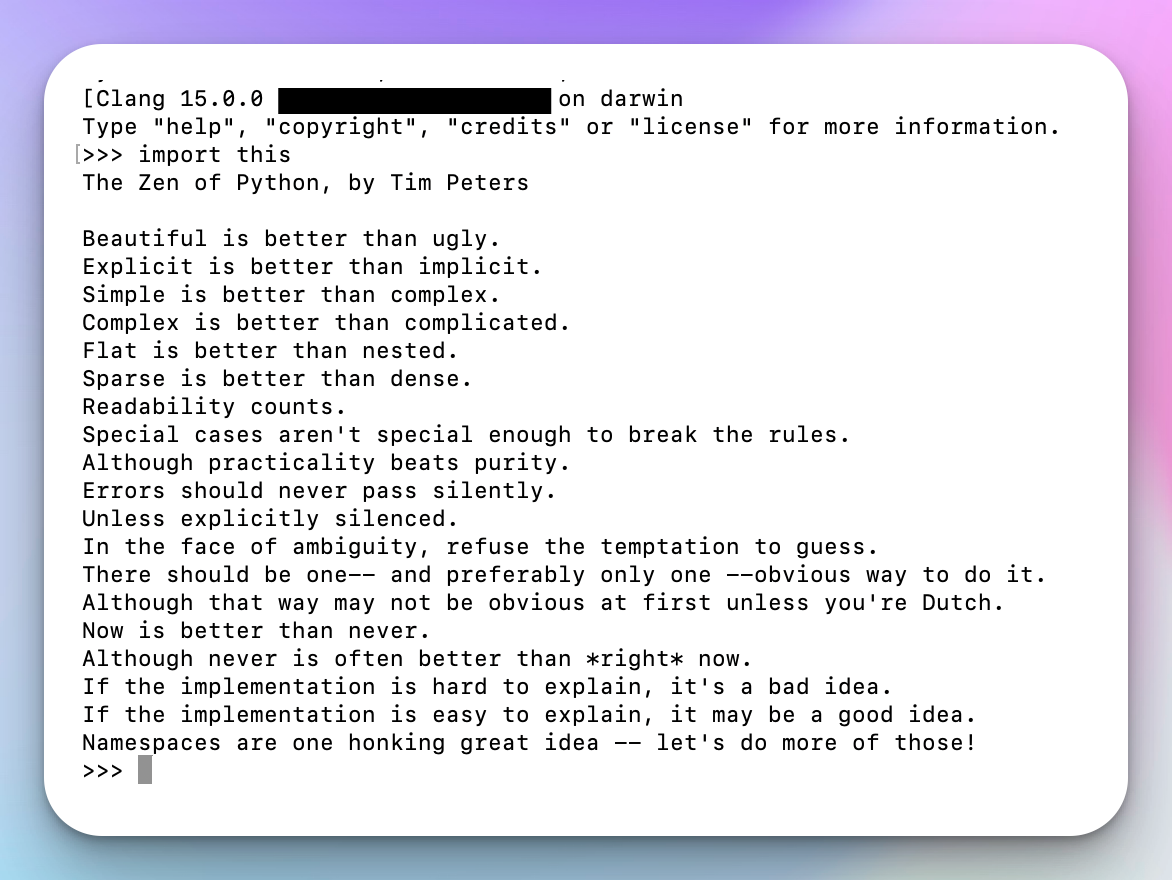
让我们来解读其中一条:
简单胜于复杂。
这句话启示我们,在编写代码时应该追求简洁和可读性。比如:
# 不够Pythonic的写法
def is_even(num):
if num % 2 == 0:
return True
else:
return False
# 更Pythonic的写法
def is_even(num):
return num % 2 == 0
2. 掌握Python的高级特性

当你对基础知识了如指掌后,是时候挑战一些高级特性了。例如,装饰器:
def timing_decorator(func):
import time
def wrapper(*args, **kwargs):
start = time.time()
result = func(*args, **kwargs)
end = time.time()
print(f"{func.__name__} took {end - start} seconds to execute.")
return result
return wrapper
@timing_decorator
def slow_function():
import time
time.sleep(2)
slow_function()
这个例子展示了如何使用装饰器来测量函数的执行时间,而不需要修改原函数的代码。
3. 数据结构和算法:Python的制胜法宝

在大数据领域,高效的数据结构和算法至关重要。让我们来看一个使用堆(heap)来找出列表中第K大元素的例子:
import heapq
def find_kth_largest(nums, k):
return heapq.nlargest(k, nums)[-1]
numbers = [3, 2, 1, 5, 6, 4]
k = 2
print(f"The {k}th largest number is: {find_kth_largest(numbers, k)}")
这个例子展示了如何利用Python的heapq模块高效地解决问题。
4. 拥抱Python生态系统

Python的强大不仅在于语言本身,更在于其丰富的生态系统。作为一名大数据开发者,你应该熟悉以下库:
- Pandas:数据处理和分析
- NumPy:科学计算
- Scikit-learn:机器学习
- PySpark:大规模数据处理
让我们用Pandas来解决一个实际问题:
import pandas as pd
# 假设我们有一个包含销售数据的CSV文件
df = pd.read_csv('sales_data.csv')
# 按月份汇总销售额
monthly_sales = df.groupby(pd.to_datetime(df['date']).dt.to_period('M'))['amount'].sum()
# 找出销售额最高的月份
best_month = monthly_sales.idxmax()
print(f"销售额最高的月份是: {best_month}, 销售额为: {monthly_sales[best_month]}")
这个例子展示了如何使用Pandas进行数据分析,这在大数据领域是一项必备技能。
持续学习:保持"糙快猛"的心态
记住,技术世界日新月异,我们必须保持学习的态度。以下是一些建议:
- 关注Python官方博客和PEP(Python增强提案):了解Python的最新发展。
- 参与Python社区:Stack Overflow、Python论坛等都是学习和分享的好地方。
- 阅读优秀的Python代码:研究知名开源项目的源码,学习最佳实践。
- 尝试教别人:教是最好的学。尝试写博客、做视频分享你的Python知识。
Python在大数据开发中的应用:从"糙快猛"到"游刃有余"
作为一名大数据开发者,我深知Python在这个领域的重要性。让我们深入探讨Python在大数据开发中的具体应用,以及如何从"糙快猛"的学习阶段过渡到"游刃有余"的专业水平。
1. 数据采集与ETL过程

在大数据开发中,数据采集和ETL(提取、转换、加载)过程是基础工作。Python提供了强大的工具来简化这些任务。
使用Scrapy进行网络爬虫
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
这个例子展示了如何使用Scrapy框架创建一个简单的网络爬虫。在实际工作中,你可能需要处理更复杂的网站结构,处理反爬虫机制,或者使用异步技术来提高爬虫效率。
使用Apache Airflow进行ETL流程管理
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2023, 1, 1),
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
dag = DAG(
'my_etl_dag',
default_args=default_args,
description='A simple ETL DAG',
schedule_interval=timedelta(days=1),
)
def extract():
# 从数据源提取数据
pass
def transform():
# 转换数据
pass
def load():
# 加载数据到目标系统
pass
t1 = PythonOperator(
task_id='extract',
python_callable=extract,
dag=dag,
)
t2 = PythonOperator(
task_id='transform',
python_callable=transform,
dag=dag,
)
t3 = PythonOperator(
task_id='load',
python_callable=load,
dag=dag,
)
t1 >> t2 >> t3
这个例子展示了如何使用Apache Airflow创建一个简单的ETL DAG(有向无环图)。在实际工作中,你可能需要处理更复杂的依赖关系,处理错误和重试逻辑,或者集成各种外部系统。
2. 大规模数据处理

在处理大规模数据时,Python的单机处理能力可能不足。这时,我们需要借助分布式计算框架。
使用PySpark进行分布式数据处理
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, sum
# 创建SparkSession
spark = SparkSession.builder \
.appName("SalesAnalysis") \
.getOrCreate()
# 读取数据
df = spark.read.csv("hdfs://path/to/sales_data.csv", header=True, inferSchema=True)
# 按产品类别汇总销售额
result = df.groupBy("category") \
.agg(sum("sales").alias("total_sales")) \
.orderBy(col("total_sales").desc())
# 显示结果
result.show()
# 停止SparkSession
spark.stop()
这个例子展示了如何使用PySpark进行简单的数据分析。在实际工作中,你可能需要处理更复杂的数据转换,优化Spark作业性能,或者集成机器学习算法。
3. 数据可视化
数据可视化是大数据开发中不可或缺的一部分。Python提供了多种强大的可视化库。
使用Matplotlib和Seaborn创建高级图表
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 读取数据
df = pd.read_csv("sales_data.csv")
# 设置样式
sns.set_style("whitegrid")
# 创建图表
plt.figure(figsize=(12, 6))
sns.lineplot(x="date", y="sales", hue="category", data=df)
# 设置标题和标签
plt.title("Sales Trend by Category", fontsize=20)
plt.xlabel("Date", fontsize=14)
plt.ylabel("Sales", fontsize=14)
# 旋转x轴标签
plt.xticks(rotation=45)
# 显示图例
plt.legend(title="Category", title_fontsize=12)
# 保存图表
plt.savefig("sales_trend.png", dpi=300, bbox_inches="tight")
# 显示图表
plt.show()
这个例子展示了如何使用Matplotlib和Seaborn创建一个销售趋势图。在实际工作中,你可能需要创建更复杂的可视化,如交互式图表或仪表板。
4. 机器学习和人工智能
在大数据领域,机器学习和人工智能的应用越来越广泛。Python是这些领域的主导语言之一。
使用Scikit-learn进行机器学习
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
import pandas as pd
# 加载数据
df = pd.read_csv("customer_data.csv")
# 准备特征和目标变量
X = df.drop("churn", axis=1)
y = df["churn"]
# 分割训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建和训练模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))
这个例子展示了如何使用Scikit-learn构建一个简单的客户流失预测模型。在实际工作中,你可能需要处理更复杂的特征工程,进行超参数调优,或者部署模型到生产环境。
Python大数据开发:进阶技巧与未来趋势
在掌握了基础知识和主要工具之后,让我们深入探讨一些进阶主题和前沿技术,这些将帮助你在Python大数据开发领域更上一层楼。

1. 性能优化:从"能用"到"高效"
在处理大规模数据时,性能优化至关重要。以下是一些在Python中进行性能优化的技巧:
使用生成器和迭代器处理大数据集

当处理大型数据集时,使用生成器可以显著减少内存使用:
def process_large_file(file_path):
with open(file_path, 'r') as file:
for line in file:
# 处理每一行
yield process_line(line)
# 使用生成器
for processed_line in process_large_file('large_data.txt'):
print(processed_line)
利用多进程提高CPU密集型任务的效率
对于CPU密集型任务,可以使用multiprocessing模块来充分利用多核处理器:
from multiprocessing import Pool
def cpu_bound_task(data):
# 进行一些复杂计算
return result
if __name__ == '__main__':
with Pool() as pool:
results = pool.map(cpu_bound_task, large_dataset)
使用Numba进行即时编译

对于数值计算密集的任务,可以使用Numba库进行即时编译,大幅提升性能:
from numba import jit
import numpy as np
@jit(nopython=True)
def monte_carlo_pi(nsamples):
acc = 0
for i in range(nsamples):
x = np.random.random()
y = np.random.random()
if (x**2 + y**2) < 1.0:
acc += 1
return 4.0 * acc / nsamples
print(monte_carlo_pi(10000000))
2. 最佳实践:编写可维护的大数据代码
在大数据项目中,代码的可维护性和可扩展性同样重要。以下是一些最佳实践:
模块化设计

将大型数据处理流程拆分为小型、可重用的函数和类:
class DataCleaner:
def remove_duplicates(self, df):
# 实现去重逻辑
pass
def handle_missing_values(self, df):
# 实现处理缺失值的逻辑
pass
class DataTransformer:
def normalize_features(self, df):
# 实现特征归一化逻辑
pass
def encode_categorical_variables(self, df):
# 实现类别变量编码逻辑
pass
class DataPipeline:
def __init__(self):
self.cleaner = DataCleaner()
self.transformer = DataTransformer()
def process(self, df):
df = self.cleaner.remove_duplicates(df)
df = self.cleaner.handle_missing_values(df)
df = self.transformer.normalize_features(df)
df = self.transformer.encode_categorical_variables(df)
return df
# 使用
pipeline = DataPipeline()
processed_df = pipeline.process(raw_df)
使用类型提示提高代码可读性

Python 3.5+支持类型提示,这在大型项目中特别有用:
from typing import List, Dict
def process_customer_data(customers: List[Dict[str, Any]]) -> pd.DataFrame:
# 处理客户数据
pass
编写单元测试

为关键的数据处理函数编写单元测试,确保代码的正确性和稳定性:
import unittest
class TestDataCleaner(unittest.TestCase):
def setUp(self):
self.cleaner = DataCleaner()
def test_remove_duplicates(self):
df = pd.DataFrame({'A': [1, 2, 2, 3], 'B': [4, 5, 5, 6]})
result = self.cleaner.remove_duplicates(df)
self.assertEqual(len(result), 3)
if __name__ == '__main__':
unittest.main()
3. 前沿技术:拥抱Python生态系统的新发展
Python生态系统在不断发展,以下是一些值得关注的前沿技术:
使用Dask进行大规模数据并行计算
Dask提供了类似于Pandas的API,但支持大规模并行计算:
import dask.dataframe as dd
# 读取大型CSV文件
df = dd.read_csv('very_large_file.csv')
# 进行分组聚合操作
result = df.groupby('category').agg({'sales': 'sum'})
# 计算结果
print(result.compute())
利用Ray进行分布式机器学习
Ray是一个用于构建分布式应用的框架,特别适合分布式机器学习:
import ray
from ray import tune
ray.init()
def objective(config):
# 这里是你的机器学习模型
score = model.train(config)
return score
analysis = tune.run(
objective,
config={
"learning_rate": tune.loguniform(1e-4, 1e-1),
"batch_size": tune.choice([32, 64, 128])
}
)
print("Best config: ", analysis.get_best_config(metric="mean_accuracy"))
探索量子计算
虽然还处于早期阶段,但量子计算已经开始影响大数据和机器学习领域。Python库如Qiskit允许你开始探索量子算法:
from qiskit import QuantumCircuit, execute, Aer
# 创建量子电路
circuit = QuantumCircuit(2, 2)
circuit.h(0)
circuit.cx(0, 1)
circuit.measure([0, 1], [0, 1])
# 在模拟器上运行
backend = Aer.get_backend('qasm_simulator')
job = execute(circuit, backend, shots=1000)
result = job.result()
print(result.get_counts(circuit))
Python大数据开发:实战案例与未来展望
在掌握了基础知识、主要工具和进阶技巧之后,让我们通过一些实际案例来看看Python在大数据领域的应用,并探讨未来的发展方向。
1. 实战案例研究
案例1:构建实时推荐系统
在一个大型电商平台中,我们需要构建一个实时推荐系统,根据用户的浏览和购买行为提供个性化推荐。
技术栈:
- 数据收集:Kafka
- 数据处理:Spark Streaming (PySpark)
- 推荐算法:基于Python的协同过滤算法
- 数据存储:Redis (用于缓存热门商品)和MongoDB (用于存储用户行为数据)
核心代码片段:
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.ml.recommendation import ALS
# 创建SparkSession
spark = SparkSession.builder \
.appName("RealtimeRecommendation") \
.getOrCreate()
# 读取实时流数据
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "user_behaviors") \
.load()
# 解析JSON数据
parsed_df = df.select(
from_json(col("value").cast("string"), schema).alias("data")
).select("data.*")
# 使用ALS算法训练推荐模型
als = ALS(userCol="user_id", itemCol="product_id", ratingCol="rating")
model = als.fit(training_data)
# 为每个用户生成推荐
user_recs = model.recommendForAllUsers(10)
# 将推荐结果写入Redis
def write_to_redis(df, epoch_id):
# 将DataFrame转换为字典并写入Redis
# ...
# 启动流处理
query = user_recs \
.writeStream \
.outputMode("update") \
.foreachBatch(write_to_redis) \
.start()
query.awaitTermination()
学习要点:
- 实时数据处理:使用Spark Streaming处理实时数据流。
- 机器学习集成:在流处理中集成机器学习模型(ALS推荐算法)。
- 数据持久化:将处理结果实时写入缓存系统(Redis)。
案例2:大规模日志分析系统
为一个大型云服务平台构建日志分析系统,用于监控系统健康状况和识别潜在的安全威胁。
技术栈:
- 日志收集:Fluentd
- 数据处理:Apache Flink (PyFlink)
- 数据存储:Elasticsearch
- 可视化:Kibana
核心代码片段:
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment, EnvironmentSettings
import json
env = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(env)
# 创建源表
t_env.execute_sql("""
CREATE TABLE log_source (
timestamp BIGINT,
level STRING,
message STRING,
service STRING
) WITH (
'connector' = 'kafka',
'topic' = 'logs',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json'
)
""")
# 创建结果表
t_env.execute_sql("""
CREATE TABLE log_sink (
timestamp BIGINT,
level STRING,
message STRING,
service STRING,
alert_type STRING
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://localhost:9200',
'index' = 'log_alerts'
)
""")
# 定义处理逻辑
result = t_env.sql_query("""
SELECT
timestamp,
level,
message,
service,
CASE
WHEN level = 'ERROR' THEN 'High'
WHEN level = 'WARNING' AND message LIKE '%security%' THEN 'Medium'
ELSE 'Low'
END AS alert_type
FROM log_source
WHERE level IN ('ERROR', 'WARNING')
""")
# 将结果插入到Elasticsearch
result.execute_insert("log_sink").wait()
学习要点:
- 流处理SQL:使用PyFlink的SQL API进行复杂的流处理操作。
- 实时告警:根据日志级别和内容实时生成告警。
- 数据集成:将处理结果实时写入Elasticsearch,便于后续的可视化和分析。
2. 行业趋势分析
趋势1:Python在大数据和AI融合中的角色
随着大数据和人工智能的深度融合,Python正在扮演越来越重要的角色。例如,在金融行业,Python被广泛用于构建高频交易系统和风险模型:
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# 加载历史交易数据
data = pd.read_csv('trading_data.csv')
# 特征工程
data['price_change'] = data['close'] / data['open'] - 1
data['volume_change'] = data['volume'] / data['volume'].shift(1) - 1
# 准备特征和标签
X = data[['price_change', 'volume_change', 'open', 'high', 'low', 'close']]
y = np.where(data['close'].shift(-1) > data['close'], 1, 0) # 1表示价格上涨
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 模型评估
accuracy = model.score(X_test, y_test)
print(f"Model accuracy: {accuracy}")
# 实时预测
def predict_price_movement(current_data):
prediction = model.predict(current_data.reshape(1, -1))
return "Up" if prediction[0] == 1 else "Down"
# 在实际交易系统中使用
# ...
趋势2:Python在边缘计算中的应用
随着物联网(IoT)的发展,边缘计算变得越来越重要。Python凭借其简洁的语法和丰富的库,正在成为边缘设备上的首选语言之一:
from gpiozero import MotionSensor
from picamera import PiCamera
import time
import cv2
import numpy as np
pir = MotionSensor(4)
camera = PiCamera()
def detect_motion():
print("Motion detected!")
timestamp = time.strftime("%Y%m%d-%H%M%S")
camera.capture(f"/home/pi/images/{timestamp}.jpg")
def process_image(image_path):
img = cv2.imread(image_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
if len(faces) > 0:
print(f"Detected {len(faces)} faces in the image.")
# 进行进一步处理,如发送警报
# ...
pir.when_motion = detect_motion
while True:
time.sleep(1)
这个例子展示了如何在Raspberry Pi上使用Python进行简单的动作检测和图像处理。
3. Python在大数据领域的未来展望
-
更强大的并行和分布式计算支持:
Python社区正在不断改进Python的并行和分布式计算能力。例如,Python 3.9引入的新的multiprocessing共享内存模型,以及正在开发中的subinterpreters功能,都将大大提升Python在大规模数据处理中的性能。 -
与云原生技术的深度集成:
随着云计算的普及,Python将更深入地与Kubernetes、Serverless等云原生技术集成。例如,使用Python编写的Kubernetes Operator:from kopf import on, create import kubernetes @on.create('example.com/v1', 'myresources') def create_fn(spec, name, namespace, logger, **kwargs): logger.info(f"Creating MyResource {name} in namespace {namespace}") # 创建一个Deployment api = kubernetes.client.AppsV1Api() dep = kubernetes.client.V1Deployment( # Deployment配置 # ... ) api.create_namespaced_deployment(namespace=namespace, body=dep) -
AI和大数据的进一步融合:
Python将继续在AI和大数据的融合中扮演关键角色。例如,使用Dask和PyTorch结合进行分布式深度学习:import dask.array as da import torch import torch.nn as nn import torch.optim as optim # 使用Dask加载大规模数据集 X = da.random.random((1000000, 100), chunks=(10000, 100)) y = da.random.randint(0, 2, (1000000,), chunks=(10000,)) # 定义PyTorch模型 model = nn.Sequential( nn.Linear(100, 50), nn.ReLU(), nn.Linear(50, 2) ) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters()) # 分布式训练 for epoch in range(10): for batch in range(0, 1000000, 10000): X_batch = X[batch:batch+10000].compute() y_batch = y[batch:batch+10000].compute() outputs = model(torch.from_numpy(X_batch)) loss = criterion(outputs, torch.from_numpy(y_batch)) optimizer.zero_grad() loss.backward() optimizer.step() print("Training complete")
结语:拥抱变化,保持学习
Python大数据开发是一个不断发展的领域。从最初的"糙快猛"学习阶段,到掌握各种工具和框架,再到探索前沿技术,这是一个永无止境的学习过程。
记住,即使成为专家后,保持"糙快猛"的学习态度仍然重要。面对新技术时,不要犹豫,大胆尝试。同时,通过不断实践和积累经验,逐步提高代码质量和系统性能。
Python在大数据领域的应用正在不断扩展和深化。从最初的数据处理和分析,到现在的实时流处理、机器学习和边缘计算,Python已经成为连接各种大数据技术的关键纽带。
我记得在我职业生涯早期,曾经质疑过Python在处理大规模数据时的效率。但随着技术的发展和生态系统的完善,Python不仅跟上了大数据的步伐,还在很多方面引领着行业的发展。这让我深刻地认识到,在技术领域,保持开放的心态和持续学习的能力有多么重要。
所以,无论你是刚开始学习Python和大数据,还是已经是这个领域的专家,都要记住:技术在不断进化,我们也需要不断学习和适应。保持"糙快猛"的学习态度,勇于尝试新技术,同时不忘积累经验,提炼最佳实践。
在这个数据驱动的时代,Python给了我们强大的工具去解决复杂的问题,创造令人惊叹的解决方案。让我们一起在Python和大数据的海洋中继续探索,用代码改变世界!
思维导图
同系列文章
用粗快猛 + 大模型问答 + 讲故事学习方式快速掌握大数据技术知识