linux 创建百万级小文件
shell下一条命令即可生成一百万个1k小文件:
单核CPU:
seq 1000000 |xargs -i dd if=/dev/zero of={}.data bs=1024 count=1 >> /dev/null 2>&1
#生成百万不为空的随机文件
seq 1000000 |xargs -i dd if=/dev/urandom of={}.data bs=1024 count=1 >> /dev/null 2>&1
多核CPU:
seq 1000000 |xargs -i -P 0 dd if=/dev/zero of={}.data bs=1024 count=1 >> /dev/null 2>&1
#生成百万不为空的随机文件
seq 1000000 |xargs -i -P 0 dd if=/dev/urandom of={}.data bs=1024 count=1 >> /dev/null 2>&1
验证:
单核命令是顺序执行,效率慢
time seq 1000 |xargs -i dd if=/dev/zero of={}.data bs=1024 count=1 >> /dev/null 2>&1
real 0m1.025s
user 0m0.236s
sys 0m0.813s
可以看到,生成1000个小文件需要1s ,那么一百万文件差不多需要 16分钟。
多核执行效率:
time seq 1000 |xargs -i -P 0 dd if=/dev/zero of={}.data bs=1024 count=1 >> /dev/null 2>&1
real 0m0.369s
user 0m0.530s
sys 0m0.421s
可以看到处理速度快了接近3倍。
上面用-P 0选项指定了尽可能多地开启并发进程数量,如果要保证最高效率,应当设置并发进程数量等于cpu的核心数量(在我的机器上,应该设置为4)。
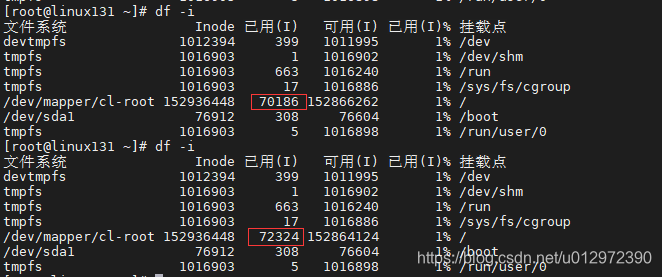
执行命令时查看进度:
df -i
查看inode数基本可以判断创建文件的速度。
其他
文件生成完成 需要ls时,会发现文件太多不能ls出来
使用ls -f |head -n 10 即可查看前10行,如下执行时间差距
-f do not sort, enable -aU, disable -ls --colo
[root@linux131 100w]# time ls -f> /dev/null
real 0m0.721s
user 0m0.176s
sys 0m0.215s
[root@linux131 100w]# time ls > /dev/null
real 0m38.755s
user 0m6.683s
sys 0m31.563s