一.hive排序以及对比
| 排序名称 | reducer个数 | 说明 |
| 全局排序(order by) | 1个 | |
| 内部排序(sort by) | 多个 |
Sort by
为每个
reducer
产生一个排序文件。每个
Reducer
内部进行排序,对全局结果集
来说不是排序。
|
| 分区排序(Distribute By) |
一定要分配多
reduce
进行处理
|
在有些情况下,我们需要控制某个特定行应该到哪个
reducer
,通常是为
了进行后续的聚集操作。
distribute by
子句可以做这件事。
distribute by
类似
MR
中
partition
(自定义分区),进行分区,结合
sort by
使用。
|
| Cluster By | 多个 |
当
distribute by
和
sorts by
字段相同时,可以使用
cluster by
方式。
只能是升序
排序,
不能指定排序规则为
ASC
或者
DESC
|
二.详细介绍
1.全局排序(Order By)
(1)Order By:全局排序,只有一个 Reducer
(2)排序方式
ASC
(
ascend
)
:
升序(默认)
DESC
(
descend
)
:
降序
(3)位置: ORDER BY 子句在 SELECT 语句的结尾
(举例)
查询员工信息按工资升序排列
select * from emp order by sal;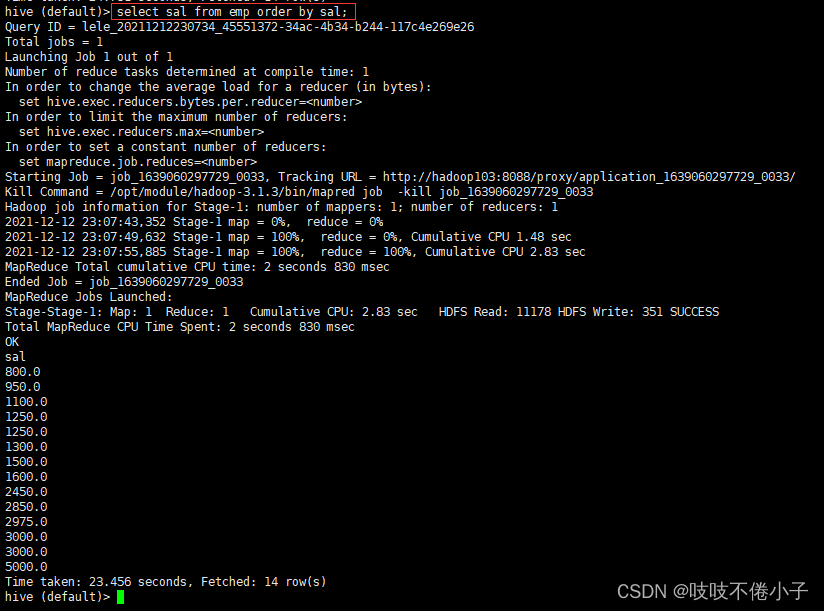
查询员工信息按工资降序排列
select * from emp order by sal desc;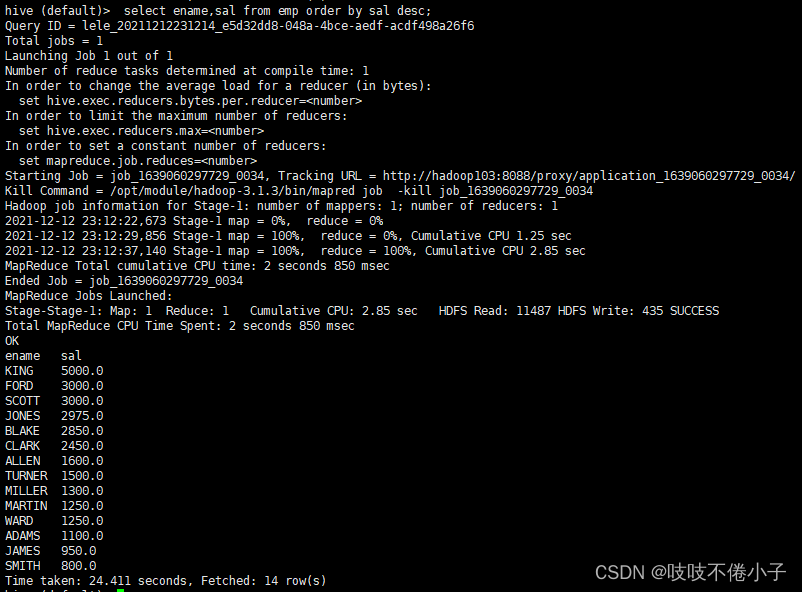
按照别名排序
select ename, sal*2 twosal from emp order by twosal;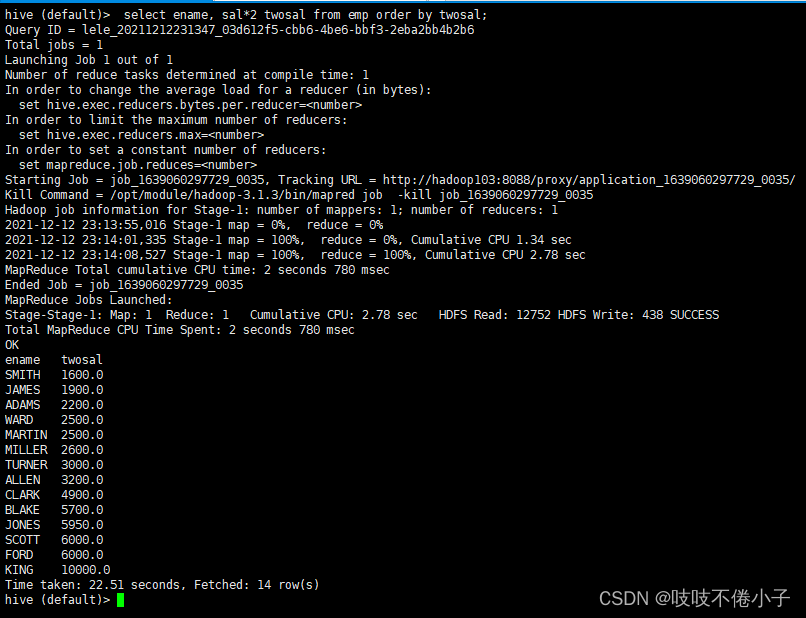
多个列排序
select ename, deptno, sal from emp order by deptno, sal ;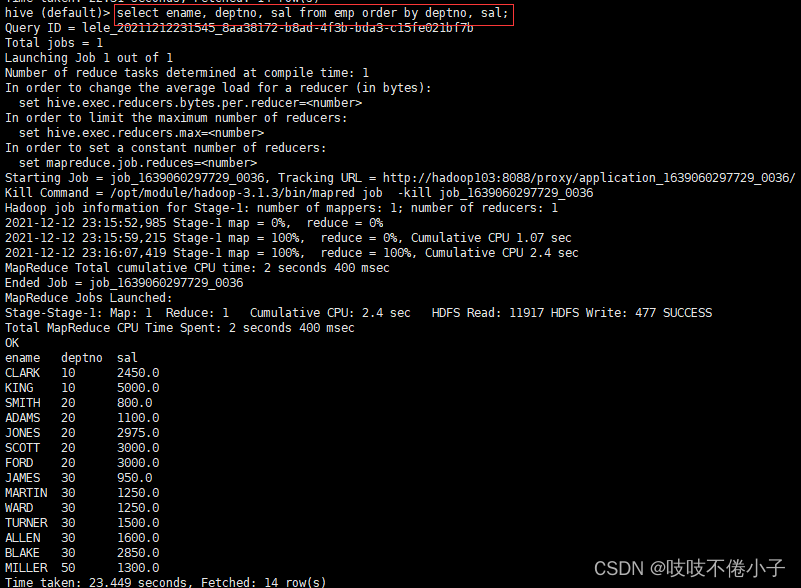
2. 每个 Reduce 内部排序(Sort By)
Sort By
:对于大规模的数据集
order by
的效率非常低。在很多情况下,并不需要全局排
序,此时可以使用
sort by
。
Sort by
为每个
reducer
产生一个排序文件。每个
Reducer
内部进行排序,对全局结果集
来说不是排序。
(1)设置
reduce
个数
set mapreduce.job.reduces=3;(2)查看设置 reduce 个数
set mapreduce.job.reduces;(3)根据部门编号降序查看员工信息
select * from emp sort by deptno desc;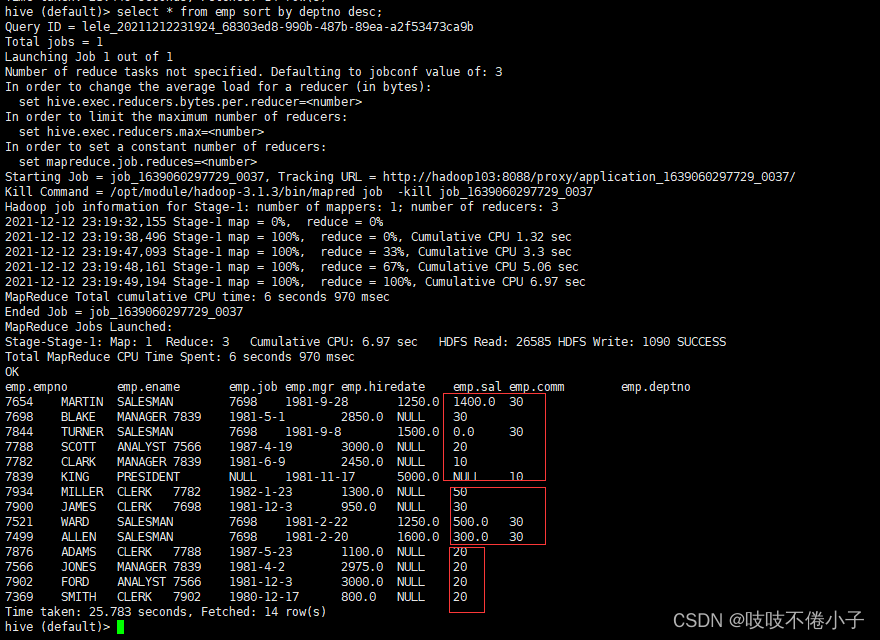
(4)将查询结果导入到文件中(按照部门编号降序排序)
insert
overwrite
local directory '/opt/module/datas/sortby-result'
select
*
from
emp
sort by
deptno
desc;3.分区(Distribute By)
Distribute By
:在有些情况下,我们需要控制某个特定行应该到哪个
reducer
,通常是为
了进行后续的聚集操作。
distribute by
子句可以做这件事。
distribute by
类似
MR
中
partition
(自定义分区),进行分区,结合
sort by
使用。
对于
distribute by
进行测试,一定要分配多
reduce
进行处理,否则无法看到
distribute
by
的效果。
select
*
from
emp
distribute by
deptno
sort by
empno desc;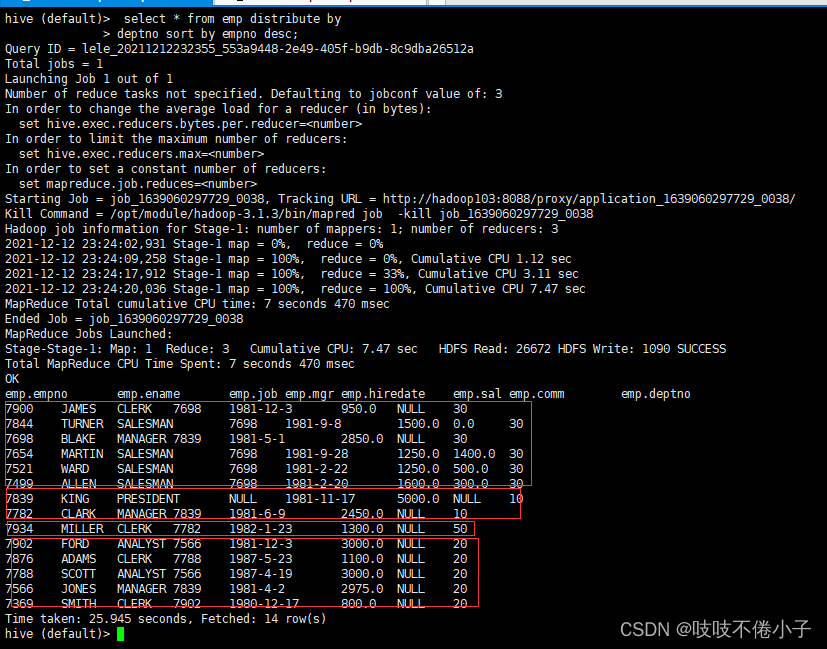
4.Cluster By
当distribute by和sorts by字段相同时,可以使用cluster by方式。
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
select * from emp cluster by deptno;等价于
select * from emp distribute by deptno sort by deptno;注意:按照部门编号分区,不一定就是固定死的数值,可以是20号和30号部门分到一个分区里面去。