介绍
使用 Tensorboard 是TF 的可视化工具,它通过对Tensoflow程序运行过程中输出的日志文件进行可视化Tensorflow程序的运行状态,如下所示。
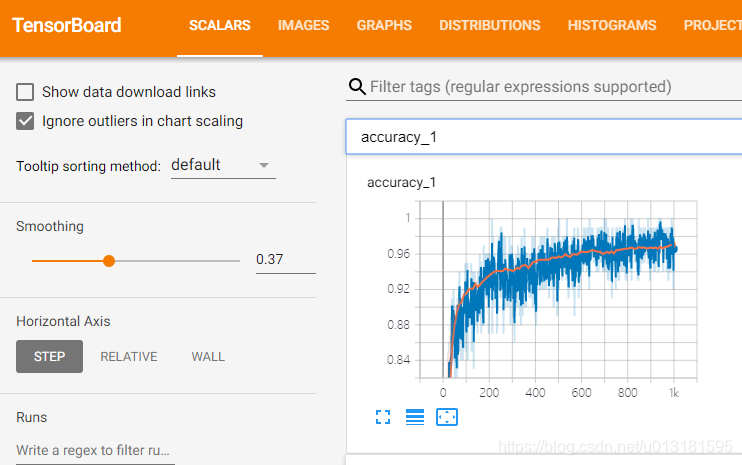
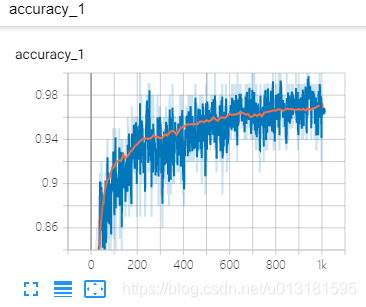
SCALARS
对标量数据进行汇总和记录,使用方法:
tf.summary.scalar(tags, values, collections=None, name=None)
IMAGE
汇总数据中的图像,例如MNIST中可以将输入的向量还原成图片的像素矩阵,使用方法:
tf.summary.image(tag, tensor, max_images=3, collections=None, name=None)

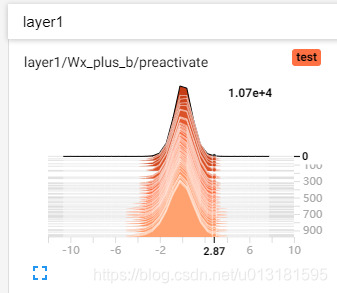
HISTOGRAMS
记录变量的直方图(张量中元素的取值分布),使用方法:
tf.summary.histogram(tag, values, collections=None, name=None)
GRAPHS
可视化Tensorflow计算图的结构及计算图上的信息,使用方法:
tf.summary.FileWriter(logdir, graph)
计算图可以很好展现整个神经网络的结构。下来将计算图中的图标进行总结:
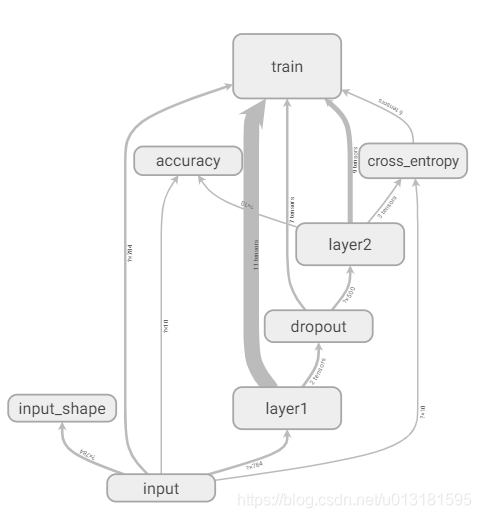
- 边,计算图中的节点之间有两种不同的边:
- 实线:刻画了数据的传输,箭头代表方向
- 虚线:表达了计算之间的依赖关系
有些边上的箭头是双向的表示一个节点可能会修改另一个节点,同时边上还标注了张量的维度信息,边上的粗细表示了两个节点之间传输的标量维度的总大小(不是传输的标量个数)。 - 图, TensorBoard会智能的调整可视化效果图上的节点,将计算图分成了主图(Main Graph)和辅助图(Auxiliary nodes)。也可以手动调整,对图中的节点进行移除(不会保存手工修改结果,刷新后还原)。
- 节点,当点击可视化图中的节点时,界面右上角会弹出该节点的基本信息(输入、输出、依赖关系以及消耗时间和内存信息等)。
- 空心小椭圆:对应计算图上一个计算节点
- 矩形:对应了计算图上的一个命名空间
使用流程
- 添加记录节点:tf.summary.scalar/image/histogram()等
- 汇总记录节点:merged = tf.summary.merge_all()
- 运行汇总节点:summary = sess.run(merged),得到汇总结果
- 日志书写器实例化:summary_writer = tf.summary.FileWriter(logdir, graph=sess.graph),实例化的同时传入 graph 将当前计算图写入日志
- 调用日志书写器实例对象 summary_writer 的 add_summary(summary, global_step=i)方法将所有汇总日志写入文件
- 调用日志书写器实例对象 summary_writer 的 close() 方法写入内存,否则它每隔 120s 写入一次
例程
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
max_steps = 1000
learning_rate = 0.001
dropout = 0.9
data_dir = './input_data'
log_dir = './logs'
mnist = input_data.read_data_sets(data_dir, one_hot=True)
sess = tf.InteractiveSession()
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name = 'x_input')
y_ = tf.placeholder(tf.float32, [None, 10], name = 'y_input')
with tf.name_scope('input_shape'):
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', image_shaped_input, 10) # 最多保存10张图片
# 定义权重及偏置的初始化方法
def weight_variables(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variables(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
# 对Variable变量的数据汇总函数, 对这些标量数据使用tf.summary.scalar进行记录和汇总
def variable_summaries(var):
with tf.name_scope('summaries'):
tf.summary.scalar('mean', tf.reduce_mean(var))
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
tf.summary.histogram('histogram', var)
# 定义网络结构
def nn_layer(input_tensor, input_dim, output_dim, layer_name,
act=tf.nn.relu):
with tf.name_scope(layer_name):
with tf.name_scope('weights'):
weights = weight_variables([input_dim, output_dim])
variable_summaries(weights)
with tf.name_scope('biases'):
biases = bias_variables([output_dim])
variable_summaries(biases)
with tf.name_scope('Wx_plus_b'):
preactivate = tf.matmul(input_tensor, weights) + biases
tf.summary.histogram('preactivate', preactivate)
activations = act(preactivate, name='preactivate')
tf.summary.histogram('activations', activations)
return activations
hidden1 = nn_layer(x, 784, 500, 'layer1')
with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32)
tf.summary.scalar('dropout_keep', keep_prob)
dropped = tf.nn.dropout(hidden1, keep_prob)
y = nn_layer(dropped, 500, 10, 'layer2', act=tf.identity)
# 对输出做softmax处理并计算交叉熵
with tf.name_scope('cross_entropy'):
diff = tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_)
with tf.name_scope('total'):
cross_entropy = tf.reduce_mean(diff)
tf.summary.scalar('cross_entropy', cross_entropy)
# 优化函数并统计准确率
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
with tf.name_scope('accuracy'):
with tf.name_scope('cross_prediction'):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.arg_max(y_, 1))
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
# 汇总所有的summary操作
merged = tf.summary.merge_all()
trian_write = tf.summary.FileWriter(log_dir + '/train', sess.graph)
test_write = tf.summary.FileWriter(log_dir + '/test')
tf.global_variables_initializer().run()
def feed_dict(train):
if train:
xs, ys = mnist.train.next_batch(100)
k = dropout
else:
xs, ys = mnist.test.images, mnist.test.labels
k = 1.0
return {x: xs, y_: ys, keep_prob: k}
'''
使用tf.train.Saver()保存器
每隔10步执行一次数据汇总,merge
'''
save = tf.train.Saver()
for i in range(max_steps):
if i%10 == 0:
summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False))
test_write.add_summary(summary, i)
print('Accuracy at step %s:%s' % (i, acc))
else:
if i % 100 == 99:
# 配置运行时要记录的信息
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
# 运行时记录运行信息的proto
run_metadata = tf.RunMetadata()
summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True),
options=run_options, run_metadata=run_metadata)
trian_write.add_run_metadata(run_metadata, 'step%03d' % i)
trian_write.add_summary(summary, i)
save.save(sess, log_dir+'/model.ckpt', i)
print('Adding run metadata for',i)
else:
summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True))
trian_write.add_summary(summary, i)
trian_write.close()
test_write.close()