使用 Magic-PDF 工具进行 PDF 文档解析与内容提取
magic-pdf 是一款强大的命令行工具,利用深度学习模型解析 PDF 文档中的文本、布局、公式和表格等内容,并将解析结果转换为结构化格式(如 Markdown)。本文将详细介绍如何在 Windows 系统中配置、运行以及使用 magic-pdf 工具进行 PDF 文档处理。
一、环境配置与工具安装
在开始使用 magic-pdf 工具之前,需要完成以下环境配置:
1. 安装 Conda 并创建虚拟环境
确保你已经安装了 Anaconda。打开命令行工具(如 PowerShell 或 CMD),运行以下命令创建并激活虚拟环境:
conda create -n MinerU python=3.10
conda activate MinerU
2. 安装 Magic-PDF 工具
运行以下命令安装 magic-pdf 及其所有依赖项:
pip install -U magic-pdf[full] --extra-index-url https://wheels.myhloli.com
如果下载速度较慢,可以选择使用国内镜像源:
pip install -U magic-pdf[full] -i https://mirrors.aliyun.com/pypi/simple
二、下载模型和配置文件
magic-pdf 工具依赖多个预训练模型和配置文件,这些文件可以通过以下脚本自动下载:
1. 下载辅助脚本
运行以下命令下载脚本文件:
curl -L https://gitee.com/myhloli/MinerU/raw/master/scripts/download_models_hf.py -o download_models_hf.py
2. 运行脚本下载模型
执行脚本以下载所需模型和配置文件:
python download_models_hf.py
运行后,脚本会将模型文件保存在以下路径:
- 模型路径:
C:\Users\<YourUser>\.cache\huggingface\hub\models--opendatalab--PDF-Extract-Kit-1.0 - 配置文件:
C:\Users\<YourUser>\magic-pdf.json
三、命令行工具选项详解
magic-pdf 提供了灵活的命令行选项来满足不同的解析需求。以下是常用选项及其说明:
1. 基本选项
| 参数 | 说明 |
|---|---|
-v, --version | 显示当前版本并退出。 |
-p, --path | 指定要解析的本地 PDF 文件路径或目录(必填)。 |
-o, --output-dir | 指定解析结果的输出目录(必填)。 |
-m, --method | 指定解析方法:ocr(OCR 方式)、txt(纯文本方式)、auto(自动选择,默认)。 |
-l, --lang | 输入 PDF 中的语言简写以提高 OCR 准确度(参考 PaddleOCR 支持语言)。 |
-s, --start | 指定起始解析页码,从 0 开始。 |
-e, --end | 指定结束解析页码,从 0 开始。 |
-d, --debug | 启用详细调试信息。 |
--help | 显示帮助信息并退出。 |
2. 示例命令
以下是解析单个 PDF 文件的示例命令:
magic-pdf -p "C:\Users\Again\Desktop\example.pdf" -o "C:\Users\Again\Desktop\output" -m auto
我的命令
(MinerU) C:\Users\Again>magic-pdf -p "C:\Users\Again\Desktop\Bolya et al_2022_YOLACT++2.pdf" -o "C:\Users\Again\Desktop\output" -m auto
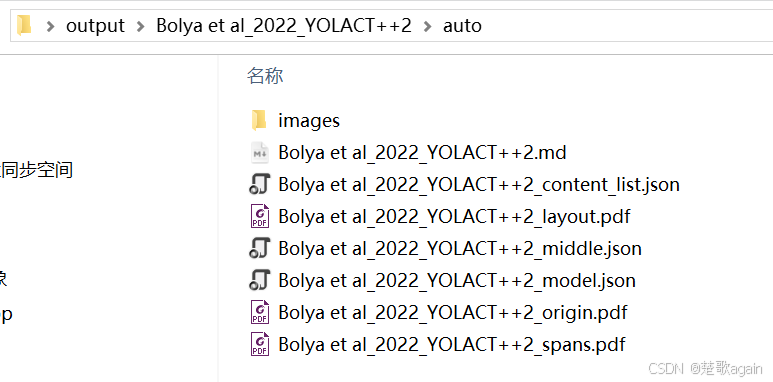
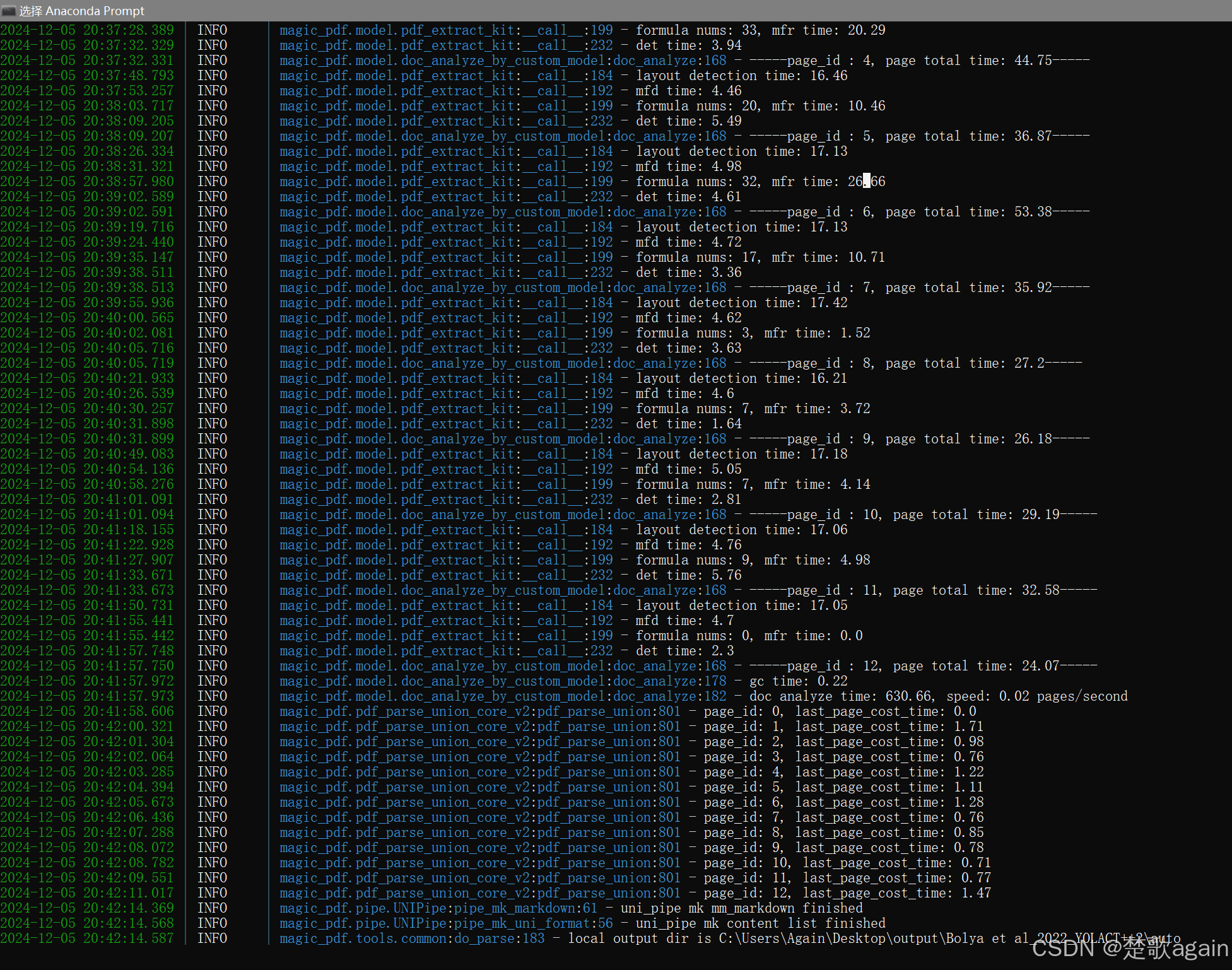
四、解析结果文件结构
运行成功后,magic-pdf 会在输出目录生成以下文件和文件夹:
├── example.md # 转换后的 Markdown 文件
├── images # 提取的图片文件夹
├── example_layout.pdf # 布局分析绘图
├── example_middle.json # 中间处理结果文件
├── example_model.json # 模型推理结果
├── example_origin.pdf # 原始 PDF 文件
├── example_spans.pdf # 最小粒度的 BBox 位置信息绘图
└── example_content_list.json # 按阅读顺序排列的富文本 JSON 文件
五、工作流程详解
以下是 magic-pdf 的完整工作流程,包括预处理、内容提取、管线处理和结果质检四个阶段:
1. 分类预处理
- 读取元数据:从 PDF 文件中提取基本信息,准备后续处理。
2. 内容提取
使用深度学习模型提取内容,包含以下步骤:
- 布局检测:通过
LayoutLMv3_ft检测 PDF 文档的布局。 - 公式检测:使用
YOLOv8_ft模型检测公式位置。 - 公式识别:通过
UniMERNet对公式进行解析。 - OCR:使用
PaddleOCR提取 PDF 中的光学字符。 - 表格识别:通过
RapidTable识别表格结构。
3. 管线处理
对提取的内容进行进一步处理:
- 确定块顺序:按照逻辑顺序排列文本块。
- 删除无用元素:去除不必要的内容(如水印、噪声等)。
- 顺序和拼装:将内容按照页面顺序拼接。
- 替换合并:根据需要替换或合并文本块。
4. 结果质检
确保生成结果的准确性和完整性,检查输出文件是否符合预期。
六、配置文件说明
在使用 magic-pdf 工具时,配置文件 magic-pdf.json 是非常重要的一部分,它用于定义各种解析选项,包括模型的存储路径、设备模式、布局分析模型、公式识别模型以及表格提取配置等。以下是配置文件各个部分的详细说明:
{
"bucket_info": {
"bucket-name-1": [
"ak", // 存储桶 1 的访问密钥 (Access Key)
"sk", // 存储桶 1 的密钥 (Secret Key)
"endpoint" // 存储桶 1 的终端节点 (Endpoint),通常用于指向特定的存储服务
],
"bucket-name-2": [
"ak", // 存储桶 2 的访问密钥
"sk", // 存储桶 2 的密钥
"endpoint" // 存储桶 2 的终端节点
]
},
"models-dir": "C:\\Users\\Again\\.cache\\huggingface\\hub\\models--opendatalab--PDF-Extract-Kit-1.0\\snapshots\\38e484355b9acf5654030286bf72490e27842a3c\\models",
// 存储下载的 PDF 提取模型的本地路径。此路径下保存的是从 HuggingFace 下载的 PDF 提取模型。
"layoutreader-model-dir": "C:\\Users\\Again\\.cache\\huggingface\\hub\\models--hantian--layoutreader\\snapshots\\641226775a0878b1014a96ad01b9642915136853",
// 存储 LayoutReader 模型的本地路径。该模型用于进行文档布局分析。
"device-mode": "cpu",
// 指定计算设备模式。可以设置为 "cpu" 或 "gpu",表示使用 CPU 或 GPU 进行计算。默认使用的是 CPU 模式。
"layout-config": {
"model": "layoutlmv3"
},
// 布局分析配置,指定使用的布局模型。在此配置中,使用的是 `layoutlmv3`,它是专为文档布局分析设计的深度学习模型。如果希望使用其他布局模型,可以在此处更改,例如使用 `doclayout_yolo`。
"formula-config": {
"mfd_model": "yolo_v8_mfd", // 公式检测模型,默认使用 "yolo_v8_mfd"
"mfr_model": "unimernet_small", // 公式识别模型,默认使用 "unimernet_small"
"enable": true // 默认启用公式检测和识别功能。如果不需要此功能,可以将该项设置为 false。
},
// 公式配置,定义了公式检测 (`mfd_model`) 和公式识别 (`mfr_model`) 使用的模型。
// "enable" 字段为 true 表示启用公式识别功能,设置为 false 则禁用该功能。
"table-config": {
"model": "rapid_table", // 默认使用 "rapid_table" 作为表格提取模型。也可以更改为 "tablemaster" 或 "struct_eqtable" 以使用其他表格提取模型。
"enable": false, // 表格提取功能默认禁用。如果需要开启表格识别,请将该字段设置为 true。
"max_time": 400 // 设置表格提取的最大处理时间,单位为毫秒。默认值为 400ms。
},
// 表格提取配置,默认使用 "rapid_table" 模型进行表格提取。如果需要使用其他模型,请在此处更改。
// "enable" 字段控制是否启用表格识别功能,"max_time" 字段用于限制表格提取的最大时间。
"config_version": "1.0.0"
// 配置文件的版本信息,用于追踪和管理不同版本的配置文件。
}
配置项详细说明
-
bucket_info
- 用于配置云存储的访问密钥(Access Key)、密钥(Secret Key)和终端节点(Endpoint)。这些配置项适用于需要与云存储进行交互的场景。如果你不需要云存储功能,可以忽略这部分配置。
-
models-dir
- 该字段指定了下载的 PDF 提取模型存储路径。在默认情况下,
magic-pdf会从 HuggingFace 下载模型文件并保存在此路径中。
- 该字段指定了下载的 PDF 提取模型存储路径。在默认情况下,
-
layoutreader-model-dir
- 用于存储 LayoutReader 模型文件的路径。该模型专门用于 PDF 文档的布局分析,能够帮助提取文档的结构信息。
-
device-mode
- 指定使用的计算设备模式。可以选择
cpu(使用 CPU)或gpu(使用 GPU)。根据你的硬件配置选择合适的模式。如果没有 GPU 或不需要加速,可以选择 CPU。
- 指定使用的计算设备模式。可以选择
-
layout-config
- 定义布局分析模型的配置项。默认使用
layoutlmv3,如果需要使用其他布局分析模型(如doclayout_yolo),可以在此处进行修改。
- 定义布局分析模型的配置项。默认使用
-
formula-config
- 公式检测与识别的配置项:
mfd_model: 配置用于公式检测的模型,默认是yolo_v8_mfd。mfr_model: 配置用于公式识别的模型,默认是unimernet_small。enable: 控制是否启用公式识别功能,默认为启用(true)。如果不需要公式识别,可以将其设置为false。
- 公式检测与识别的配置项:
-
table-config
- 表格提取的配置项:
model: 配置用于表格提取的模型,默认使用rapid_table。如果需要其他表格模型,可以选择tablemaster或struct_eqtable。enable: 控制表格提取功能是否启用,默认为禁用(false)。如果需要启用表格提取,请将其设置为true。max_time: 设置表格提取的最大处理时间(单位:毫秒),默认为 400ms。可以根据需要调整此值。
- 表格提取的配置项:
-
config_version
- 配置文件的版本信息。该字段用于跟踪配置文件的版本,确保使用的是正确的配置版本。
配置文件修改示例
假设你希望更改以下配置:
- 使用
doclayout_yolo作为布局分析模型。 - 启用公式识别功能。
- 使用
tablemaster模型进行表格提取,并启用表格提取。
修改后的配置文件应如下所示:
{
"layout-config": {
"model": "doclayout_yolo"
},
"formula-config": {
"mfd_model": "yolo_v8_mfd",
"mfr_model": "unimernet_small",
"enable": true
},
"table-config": {
"model": "tablemaster",
"enable": true,
"max_time": 500
}
}
通过这种方式,你可以灵活地调整配置文件,以便适应不同的文档解析需求。
七、总结
通过本文,你已经了解如何在 Windows 系统中使用 magic-pdf 工具完成 PDF 文档的解析与提取工作。从环境配置、模型下载到具体操作,每一步都有详细的说明和示例。如果你想了解更多,请访问 Magic-PDF 项目官网。
如有疑问,欢迎留言交流!