尽管多代理协作的大规模语言模型(LLMs)在Text-to-SQL任务中取得了显著突破,但其性能仍受多种因素限制。这些因素包括框架的不完整性、无法遵循指令以及模型幻觉问题。为解决这些问题,我们提出了OpenSearch-SQL,将Text-to-SQL任务划分为四个主要模块:预处理、提取、生成和优化,并基于一致性对齐机制引入了对齐模块。该架构通过对齐模块对代理的输入和输出进行对齐,减少了指令执行失败和幻觉现象。此外,我们设计了一种称为SQL-Like的中间语言,并优化了基于SQL-Like的结构化CoT。同时,我们开发了一种自学习形式的Query-CoT-SQL动态少样本策略。这些方法显著提高了LLMs在Text-to-SQL任务中的性能。
在模型选择方面,我们直接应用了基础LLMs,而未进行任何微调,从而简化了任务链并增强了框架的可移植性。实验结果表明,OpenSearch-SQL在BIRD开发集上实现了69.3%的执行准确率(EX),在测试集上达到72.28%,奖励有效性评分(R-VES)为69.36%,三项指标均排名第一。这些结果展示了所提方法在有效性和效率方面的全面优势。
Text-to-SQL任务旨在自动将自然语言查询(NLQ)转换为结构化查询语言(SQL)。此任务可以提高数据库访问能力,无需掌握SQL知识 (Katsogiannis-Meimarakis 和 Koutrika 2023) 。由于Text-to-SQL问题难度较大,几十年来一直是数据库社区的圣杯 (Katsogiannis-Meimarakis 和 Koutrika 2023) 。早期工作将查询答案定义为图结构 (Hristidis, Papakonstantinou, 和 Gravano 2003; Hristidis 和 Papakonstantinou 2002) 或基于语法结构解析问题 (Iyer 等人 2017; C. Wang, Cheung, 和 Bodik 2017) 。随后的方法将Text-to-SQL任务视为神经机器翻译(NMT)问题 (Bailin Wang 等人 2019; J. Guo 等人 2019a) 。最近,随着大规模语言模型的发展,研究人员越来越多地通过监督微调(SFT) (Thorpe, Duberstein, 和 Kinsey 2024; H. Li 等人 2024; Maamari 等人 2024) 、思维链(CoT) (Wei 等人 2023) 、代理 (Pourreza 和 Rafiei 2024a; Dong 等人 2023) 以及上下文学习 (Bing Wang 等人 2023; D. Gao 等人 2023) 等方法完成任务,取得了远超以往方法的结果。
局限性。 虽然由LLMs驱动的方法显著提升了Text-to-SQL任务的能力上限,但我们对先前工作的分析显示:
- 由于总体框架的模糊性,方法论层面存在一些差距。这阻碍了这些方法发挥潜力。例如,缺乏对数据库存储信息的验证,没有对生成结果的错误纠正,以及缺少少样本学习。
- LLM驱动的方法通常依赖于多代理协作。然而,由于LLMs的不稳定性以及代理之间缺乏保证的一致性和耦合,后执行的代理可能不使用或仅部分使用前运行代理的输出。这导致了累积幻觉和性能损失。
- 指导LLMs的指令和步骤对其生成的SQL质量有显著影响。在LLM时代之前,采用中间语言生成SQL的方法解决了这一问题 (Katsogiannis-Meimarakis 和 Koutrika 2023) ,但目前对指令构建的研究仍然不足。
受上述挑战的启发,我们详细分析了人类完成Text-to-SQL任务的工作流程:理解数据库结构并选择所需的特定表、列和值以生成SQL。这个过程通常需要执行几个简单的SQL查询,例如调查某一列的具体值形式或检索特定值在数据库中的存储方式。接下来,根据NLQ的具体情况,选择适当的聚合函数和SQL语法构造SQL查询的主干,然后填充相关语句。最后,人类通常会根据查询结果逐步修改SQL,直到满足要求。对于更复杂的问题,人类往往会参考或借用他人的公式寻求解决方案。基于这种方法,我们开发了OpenSearch-SQL方法,具体如下。
1.0.0.1 框架。
为了解决 [l1] ,我们的研究基于人类完成SQL构造的过程定义了一个 标准Text-to-SQL框架 。该框架涵盖了当前LLMs驱动的Text-to-SQL任务研究。我们认为一个完整的Text-to-SQL任务框架应包括四个步骤: 预处理 、 提取 、 生成 、 优化 :
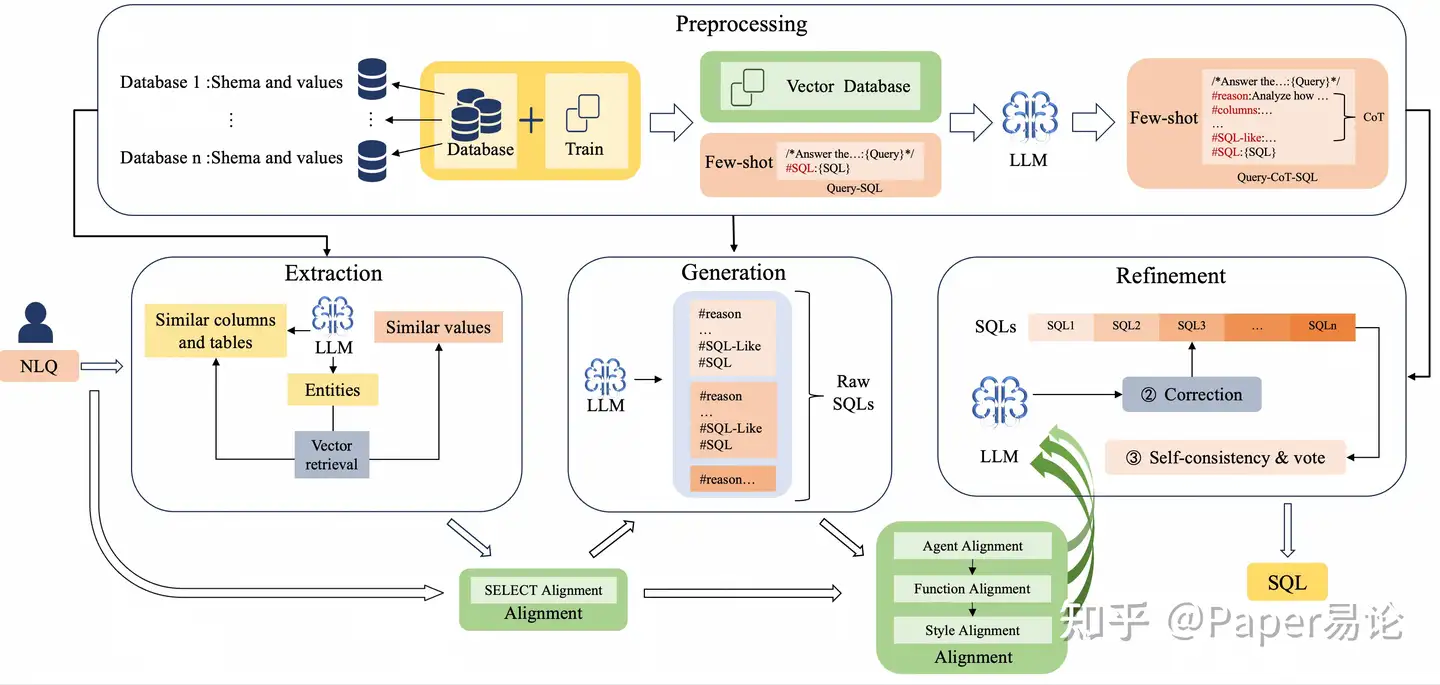
- 预处理。 处理和构建所有与NLQ无关的辅助信息,包括数据库模式信息、嵌入式数据库、少样本库等。
- 提取。 从数据库中提取和选择生成SQL所需的各种元素,包括子NLQ、少样本、表、列、值等。
- 生成。 基于SQL语法、少样本和准备的信息将NLQ转换为SQL。
- 优化。 使用对齐策略和规则根据执行结果检查和优化SQL。然后,基于自我一致性和投票结果选择最终的SQL。
对于 [l2] ,我们分析了多代理协作驱动的Text-to-SQL任务中常见的幻觉现象,并为这些幻觉设计了基于一致性对齐的 对齐代理 。通过确保特定代理的功能、输入和输出的一致性,我们旨在减少模型生成过程中的幻觉现象。这种对齐方法还可以扩展以对代理的输出进行有针对性的调整。如图 [overview] 所示,我们提出了OpenSearch-SQL框架,该框架结合了标准的Text-to-SQL框架和对齐机制。
此外,我们使用此框架扩展了LLMs驱动的多代理方法研究。对于 [l3] ,我们开发了一种自学习少样本增强机制,通过补充带有 思维链(CoT) 信息的查询-SQL对,创建了 Query-CoT-SQL 对。这种丰富的少样本方法可以提高LLMs的性能。此外,我们在CoT逻辑内设计了一种名为SQL-Like的中间语言,允许LLMs首先生成SQL的主干,然后再生成具体的SQL细节,从而降低了任务对模型的复杂性。
在实际应用中,为特定查询任务准备大量定制化的SQL训练数据并非易事。因此,考虑到现实需求,我们的目标不仅是实现特定评估任务的良好效果,还要确保所提方法具有强大的迁移能力。我们希望该方法能够轻松应用于各种数据库查询任务,而无需进行微调。这意味着面对任何问题时,我们可以简单地修改代理和对齐方法,而无需重新训练模型,从而高质量地满足用户需求。
基于此,我们直接在预训练的LLM模型上实施了我们的方法,未采用任何监督微调(SFT)或强化学习(RL)。在实验中,我们选择了广泛认可的BIRD数据集 (J. Li 等人 2024) 进行测试,该数据集记录了三个指标:开发集上的执行准确率(EX)、测试集上的EX以及测试集上的奖励有效性评分(R-VES)。我们的实验结果表明,在开发集上达到了69.3%的EX,在测试集上达到了72.28%的EX,R-VES得分为69.3%。所有三项指标在提交时均排名第一,证明了我们的方法不仅生成准确的SQL语句,在时间效率上也有明显优势。我们希望这种基于一致性对齐的方法能为未来研究探索更高效的一致性对齐策略提供灵感。
贡献 总之,我们的贡献如下。 - 据我们所知,我们首次提出了一种基于一致性对齐的多代理协作框架用于Text-to-SQL任务。这种对齐机制显著减少了代理之间的信息传递损失和代理生成结果中的幻觉现象。
- 我们引入了一种新颖的自学习动态少样本方法和SQL-Like CoT机制。这增强了LLMs生成SQL的性能和稳定性。
- 我们提出的OpenSearch-SQL方法未使用微调或引入任何专用数据集。在提交时,它在BIRD基准验证集上实现了69.3%的EX,在测试集上实现了72.28%的EX,R-VES为69.36%,均排名第一。
2 预备知识
我们首先介绍本文依赖的两个重要模块:大规模语言模型(LLMs)和Text-to-SQL任务。
2.1 大规模语言模型
预训练的大规模语言模型通过在大规模文本数据上进行无监督学习获得了广泛的语言知识和语义信息。这种预训练通常采用自回归架构(如GPT类模型)或自编码结构(如BERT类模型)。LLMs可以通过微调在各种下游任务中取得优异表现。自从深度学习时代以来,大规模语言模型在Text-to-SQL任务中相比经典模型和方法有了显著进步,目前最先进水平的工作完全依赖于LLMs的性能。
2.2 Text-to-SQL

在当前最先进的Text-to-SQL任务中,多代理协作已成为提升性能的关键策略。常见模块包括值检索、模式链接、少样本驱动、CoT提示、SQL校正和自我一致性。受这些方法的启发,本文首先系统地组织了这些模块。我们将现有方法分为四个阶段: 预处理 、 提取 、 生成 和 优化 。预处理独立于特定的NLQ,旨在获取清晰的数据库结构信息并准备其他有助于模型生成SQL的辅助信息;提取分析具体查询并从准备的信息中过滤出高质量的辅助信息;生成组织提取的信息并生成候选SQL;优化阶段进一步优化候选SQL以提高SQL的质量。
基于这一基础,我们提出了OpenSearch-SQL,一种基于 动态少样本 和 一致性对齐 机制的Text-to-SQL框架。动态少样本的设计旨在加强各个阶段中每个模块的性能,而 对齐 模块用于对齐Text-to-SQL的不同阶段,从而减少LLMs在多代理协作工作流中产生的幻觉。OpenSearch-SQL的设计简化了复杂的指令系统,通过对齐专注于提高多代理协作的有效性。在以下章节中,我们将详细介绍OpenSearch-SQL框架的具体组件。
2.3 幻觉
幻觉 (Zhang 等人 2023) 是深度学习中的常见问题,通常指模型生成的内容不符合现实或预期结果,即模型产生不准确或不合理的信息。文本幻觉可以表现为以下形式:
- 无关内容:模型生成的文本与输入或上下文无关,或包含无关细节。
- 错误事实:生成的文本包含错误的事实或不存在或不准确的真实世界信息。
- 逻辑错误:生成的文本逻辑不一致或不合理。
在Text-to-SQL中,这表现为:结果包含不存在的数据库信息,未能遵循提示中的指令,以及拼写和语法错误。此外,为了方便处理,在Text-to-SQL任务中,我们还包括了非零温度下随机性引起的偏差和因提示微小变化导致的错误。因为幻觉的本质在于训练过程与实际使用场景之间的差异。因此,对于幻觉问题,常见的处理方法包括:针对幻觉问题进行专门的微调,使用自我一致性机制减少随机性,以及后处理。由于本文重点在于架构级别的优化,我们的工作旨在通过上述提到的最后两种方法减少幻觉。
3 方法
在本节中,我们将详细说明OpenSearch-SQL的具体内容。我们将在概述整个过程之前,更深入地描述对齐和动态少样本的核心概念。为了确保解释流畅,我们将每个阶段与其相应的对齐集成在一起,并按照它们在OpenSearch-SQL框架中操作的顺序进行描述。
3.1 对齐
LLM幻觉 (Zhang 等人 2023) 是影响LLMs可用性的关键问题,也存在于Text-to-SQL任务中。此外,多代理协作过程中累积的错误加剧了LLMs中的幻觉问题。例如,如果负责 提取 功能的代理以某种方式从数据库中选择列,并由于模型幻觉生成了错误的列名,这种错误将在后续的 生成 阶段持续存在,因为它缺乏正确的数据库结构知识。因此,前一代理产生的幻觉被继承下来,难以在多代理LLM工作流中自发消失;幻觉总量几乎呈单调非递减趋势。
基于这一现象,我们定义对齐代理为:\[A_{Aligment}(x+A'(x))=A(x)-A'(x),\]

在Text-to-SQL任务中,常见的幻觉现象主要表现为未能遵循指令和输出结果不稳定。具体表现为:生成不存在的列、更改数据库列名、语法错误、数据库值与列不匹配以及未能遵守提示中设置的规则。为解决这些问题,我们提出了一种一致性对齐方法:在每个代理完成输出后,使用一个 对齐 代理将其当前代理的输出与上游代理的输出对齐,确保各代理的功能实现逻辑一致性,并将对齐后的结果传递给下游代理。这种机制类似于残差连接 (He 等人 2015) , 有效地延长了多个代理之间的协作链,同时最大限度地减少幻觉的引入。每种对齐的具体细节将在以下代理介绍中详细呈现。
3.2 自学习少样本
少样本是协助LLMs生成的重要方法,MCS-SQL (Lee 等人 2024) , DAIL-SQL (D. Gao 等人 2023) 研究了问题表示在Text-to-SQL任务中的关键作用,并提出使用问题相似性选择适当的少样本以驱动LLMs生成SQL,取得了显著成果。
受此启发,我们尝试使用动态少样本增强Text-to-SQL任务中代理的效率。此外,我们考虑如何更好地利用少样本,通过从样本中提取更多信息。因此,在OpenSearch-SQL中,我们首先使用 掩码问题相似性(MQs) (C. Guo 等人 2023) 选择相似查询。然后,我们通过自学习升级Query-SQL格式的少样本。对于列表中所示的Query-SQL对 [query-SQL] , 我们使用LLM补充CoT信息以将NLQ转换为SQL。如列表 [query-CoT-SQL] 所示,这产生了包含逻辑信息的 Query-CoT-SQL 对。与简单的Query-SQL对相比,这些自学习的少样本提供了更丰富的信息。
然后,对于 优化 中的错误校正,我们为不同类型的错误准备了不同的少样本,使LLMs在 优化 期间可以根据不同错误更清楚地了解如何校正SQL。少样本的格式如列表 [reffewshot] 所示,其中 原始SQL 和 校正建议 对应于错误类型。
/* 回答以下问题:(*@\color{red}{\{question\}}@*) */
#SQL: (*@\color{red}{\{SQL\}}@*)
/* 回答以下问题:(*@\color{red}{\{question\}}@*) */
#reason: 分析如何根据问题生成SQL。
#columns: 最终用在SQL中的所有列
#values: SQL中的过滤条件
#SELECT: SELECT内容表.列。
#SQL-like: 忽略Join条件的SQL-like语句
#SQL: (*@\color{red}{\{SQL\}}@*)
{"Result: None": """/* 修复SQL并回答问题 */
#question: (*@\color{red}{\{question\}}@*)
#Error SQL: (*@\color{red}{\{Raw SQL\}}@*)
Error: Result: None
#values: (*@\color{red}{\{Database中的值\}}@*)
#Change Ambiguity: (*@\color{red}{\{校正建议\}}@*)
#SQL:(*@\color{red}{\{corrected SQL\}}@*)""",
...}
3.3 预处理
在 预处理 中,我们根据其真实结构构建了数据库。此外,为了确保LLMs生成的SQL与数据库的实际状态一致,我们索引了数据库中的值。这使得SQL可以避免因字符差异引起的错误。值得注意的是,我们只对字符串类型的数据进行索引以节省构建检索数据库所需的空间。
此外,动态少样本的构建也在这一阶段完成。这包括添加CoT信息和为不同错误类型设计的校正少样本示例。
总体而言,在预处理阶段,输入来自数据库和训练集的信息。输出是一个向量数据库、Query-CoT-SQL格式的少样本和数据库模式。此过程是自动化的,不需要人工干预,完全由代理驱动。
3.4 提取
提取 的目标是根据特定的NLQ准备必要的信息,包括模式链接、存储的数据库值、少样本示例和任何所需的指令。这部分与特定的数据库查询语言解耦,仅与数据存储格式和解决问题所需的辅助信息有关。例如,C3-SQL (Dong 等人 2023) 利用清晰提示(CP)提供有效的提示,而DIN-SQL (Pourreza 和 Rafiei 2024a) 则采用模式链接和分类及分解来分类和分解NLQ。
(*@\colorbox{yellow}{输入:}@*)
/* 数据库模式 */
(*@\color{red}{\{db\_info\}}@*)
(*@\color{red}{\{rule\}}@*)
/* 回答以下问题: (*@\color{red}{\{query\}}@*) */
(*@\colorbox{yellow}{输出:}@*)
(*@\color{red}{\{reason\}}@*)
(*@\color{red}{\{column\}}@*)
(*@\color{red}{\{values\}}@*)
OpenSearch-SQL中的 提取 过程包括实体提取、值提取和列过滤。在 提取 之后,我们使用信息对齐将提取的信息与输入对齐以产生最终输出。我们在列表 [extract_prompt] 中展示了提取提示及其输入和输出的格式。我们通过LLM获得候选列和值,并使用另一个简单的提示直接从NLQ中提取实体。具体细节如下所述:
3.4.0.1 实体提取
为了在数据库中找到相似的值并进行列过滤,我们首先使用LLM理解和处理NLQ和基本数据库信息以提取潜在实体。然后,我们将一些预定义的实体术语与这些实体一起组织起来,以进行后续的值检索和列过滤。
3.4.0.2 值检索。
从提取的实体中,我们执行向量检索以找到与实体词嵌入相似度最高的结果。由于嵌入相似性的性质,这种方法可以防止由拼写错误或其他字符级差异引起的不匹配。此外,对于短语和较长文本,我们执行分段检索以避免因数据库存储格式差异而导致的召回失败。在召回阶段,我们过滤掉低于特定阈值的前K个最相似实体的部分,保留作为最终结果。
3.4.0.3 列过滤。
具体来说,我们使用两种方法召回相关表和列。首先,我们使用大型语言模型(LLM)从完整数据库信息中选择与自然语言查询(NLQ)相关的表和列。然后,我们使用向量检索查找与NLQ实体相似度超过一定阈值的数据库列,整合这些列形成最终模式信息的初步子集。尽管这种多路径召回方法在过滤上可能缺乏一些精度,但它在过程中更加轻量化和精简。
3.4.0.4 信息对齐
在提取阶段结束时,我们使用Info对齐代理对齐SELECT语句的风格:从NLQ中提取与生成的SELECT内容一一对应的短语或子句。这确保了SELECT内容的数量和顺序符合预期。为了避免因不同表中同名列引起的误选,我们通过重新整合每个表的主键和所有与列过滤中选择的列同名的列,扩展模式信息,确保所选列的准确性和完整性。最后,所有提取的信息和对齐的内容都将输入到 生成 中。
3.5 生成
生成 的定义是:使用适当的方法驱动LLMs生成特定组件并完成SQL。MAC-SQL (Bing Wang 等人 2023) 生成子SQL并将其组装成最终结果,而DAIL-SQL (D. Gao 等人 2023) 通过少样本学习驱动LLMs生成SQL。此外,一些方法 (Talaei 等人 2024; Maamari 等人 2024; Lee 等人 2024) 在监督微调(SFT)期间利用LLMs或生成多组SQL以完成任务。
(*@\colorbox{y(*@\color{yellow}{输入:}@*)
(*@\color{red}{\{fewshot\}}@*)
/* 数据库模式 */
(*@\color{red}{\{db\_info\}}@*)
(*@\colorbox{yellow}{输入:}@*){red}{\{fewshot\}}@*)
/* 数据库模式 */
(*@\color{red}{\{db\_info\}}@*)
(*@\color{red}{\{相似值\}}@*)
(*@\color{red}{\{rule\}}@*)
(*@\color{darkgreen}{规则示例:涉及除法部分包含整数类型时,将其转换为REAL}@*)
/* 回答以下问题:1990年后有多少患者的Ig A水平正常? 正常Ig A水平指IGA > 80 且 IGA < 500;*/
(*@\color{red}{\{info alignment\}}@*)
(*@\color{darkgreen}{信息对齐示例:SELECT内容: [多少患者]}@*)
(*@\colorbox{yellow}{输出:}@*)
#reason: 该问题希望统计1990年后Ig A水平正常的患者数量,因此SELECT将根据指定条件统计不同患者。
#columns: Patient.ID, Laboratory.IGA, Patient.`First Date`
#values: 正常Ig A水平指Laboratory.IGA > 80 AND Laboratory.IGA < 500;1990年后就诊指strftime('%Y', Patient.`First Date`) >= '1990'
#SELECT: 多少患者指COUNT(DISTINCT Patient.ID)
#SQL-like: 显示 COUNT(DISTINCT Patient.ID) WHERE Laboratory.IGA > 80 AND Laboratory.IGA < 500 AND YEAR(Patient.`First Date`) >= '1990'
#SQL: SELECT COUNT(DISTINCT T1.ID) FROM Patient AS T1 INNER JOIN Laboratory AS T2 ON T1.ID = T2.ID WHERE T2.IGA > 80 AND T2.IGA < 500 AND strftime('%Y', T1.`First Date`) >= '1990'
3.5.0.1 SQL生成。

列表[generate]通过一个例子展示了生成阶段输入和输出的组成。
- 在输入中,我们通过规则和数据库模式提供必要的输出要求和数据库信息,并通过Query-CoT-SQL格式的少样本提供类似示例。相似值提供了与NLQ相关的数据库中的具体值,而信息对齐则使LLMs的SELECT风格与数据集对齐。
- 在输出中,我们要求按顺序生成:原因:对NLQ的分析;列:SQL中的相关列;值:相关值;SELECT:SELECT语句的内容。然后生成忽略语法格式的SQL-Like查询,并最终生成最终的SQL查询。
(*@\color{blue}{\textbf{代理对齐:}}@*)
(*@\color{darkgreen}{原始SQL}@*): SELECT ID FROM table WHERE table.name= 'John'
数据库中的值: table.name='JOHN'
(*@\color{darkgreen}{对齐后的SQL}@*): SELECT ID FROM table WHERE table.name= 'JOHN'
(*@\color{blue}{\textbf{功能对齐:}}@*)
(*@\color{darkgreen}{原始SQL}@*): SELECT ID FROM table ORDER BY MAX(score)
(*@\color{darkgreen}{对齐后的SQL}@*): SELECT ID FROM table GROUP BY ID ORDER BY score
(*@\color{blue}{\textbf{风格对齐:}}@*)
(*@\color{darkgreen}{原始SQL}@*): SELECT ID FROM table ORDER BY score DESC LIMIT 1
(*@\color{darkgreen}{对齐后的SQL}@*): SELECT ID FROM table WHERE score IS NOT NULL ORDER BY score DESC LIMIT 1
3.5.0.2 对齐
SQL查询生成过程中的错误主要源于语法、数据库、自然语言查询(NLQ)和数据集风格的差异。此外,使用大型模型在较高温度下采样以获得多样答案可能会引入错误和噪声。因此,我们尝试通过对齐机制减少这些差异引起的偏差。具体来说,如列表[align]所示,对齐机制包括以下三个组件:
- 代理对齐:确保数据库中的列和值在SQL中正确表示。如果存在不匹配,则进行修正。常见示例是SQL中的WHERE条件与数据库中存储的信息不匹配。
- 功能对齐:标准化SQL聚合函数以防止由错误表达式引起的错误。这包括处理不适当的AGG函数、嵌套和冗余JOIN。
- 风格对齐:解决与数据集特征相关的问题,例如使用IS NOT NULL以及选择MAX和LIMIT 1。
完成上述步骤后,执行SQL并在优化过程中对其进行优化,并根据执行结果选择最终的SQL。
3.6 优化
优化的工作包括优化和选择生成的SQL。这包括根据执行结果纠正错误,以及从多个候选SQL中选择最佳答案。
由于LLMs生成的结果具有变异性以及复杂任务中经常出现的指令遵循问题,我们提出了一种基于检查的一致性对齐机制以提高SQL的质量。如图1所示,在对齐生成的SQL后,优化包括以下两个步骤:
- 校正:执行SQL并根据执行结果中的错误细节(如语法错误或空结果)进行修复。每种类型的错误对应不同的少样本和错误校正指令。此步骤的目的是避免因小细节问题导致的结果缺失或执行失败。



架构:优化通过校正和一致性 & 投票优化SQL以获得最佳SQL。
值得注意的是,自我一致性通常会导致更高的成本。在评估中,当仅在生成中生成一条SQL且未使用自我一致性机制时,OpenSearch-SQL v2仍然在BIRD基准上排名第一。
3.7 算法
在本节中,我们对OpenSearch-SQL进行了总体概述,并在算法[alg]中呈现了整个框架。在这个算法中,我们以NLQ为例,涵盖了从预处理到最终生成SQL的具体步骤。


3.8 优化
OpenSearch-SQL已取得显著成果,但仍有许多优化空间。目前,我们尚未完全专注于OpenSearch-SQL中提示的详细调整以及列和值的精确选择。此外,在生成任务中,我们仅使用单个提示作为LLM生成SQL候选集的指令,未进行额外优化。另一方面,SFT模型在提高Text-to-SQL性能方面显示出巨大潜力。研究表明,CHESS (Talaei 等人 2024), MCS-SQL (Lee 等人 2024) 和 distillery (Maamari 等人 2024) 已经证明了这些方法的有效性,表明可以在这些方向上进一步优化。
在OpenSearch-SQL的方法内,我们认为少样本方法不仅限于Query-CoT-SQL对,还有其他选项,提供了增强性能的潜力。此外,对齐研究仍处于早期阶段,表明在提高Text-to-SQL任务性能方面仍有改进空间。
4 实验
在本节中,我们通过实验展示OpenSearch-SQL的有效性,并探讨其各个模块的作用。
4.1 实验设置
4.1.0.1 数据集
我们在表[tabdataset]中展示了这两个数据集的特性。考虑到数据集的具体查询和SQL复杂性。Bird的数据集包含较少类型的数据库,但具有更复杂的数据库结构和较高的平均SQL难度。相比之下,Spider拥有丰富的数据库种类,但SQL的平均难度相对较低。
4.1.0.2 BIRD
(J. Li 等人 2024) (大规模数据库支持的Text-to-SQL评估的大规模基准)代表了一个开创性的跨领域数据集,用于研究大规模数据库内容对Text-to-SQL解析的影响。BIRD包含超过12,751个独特的问答-SQL对,95个大型数据库,总大小为33.4 GB。它涵盖了37个以上的专业领域,如区块链、曲棍球、医疗保健和教育等。BIRD数据集在2004年7月4日发布了开发集的更清洁版本。然而,为了公平起见,我们仍将使用7月前的开发数据进行评估。
4.1.0.3 Spider
(T. Yu, Zhang, 等人 2018) 是一个大规模复杂和跨域语义解析和Text-to-SQL数据集,由11名耶鲁大学学生标注。Spider挑战的目标是开发跨域数据库的自然语言接口。它由200个数据库上的10,181个问题和5,693个独特的复杂SQL查询组成,覆盖138个不同领域。在Spider中,我们在开发集上进行调优,假设测试集不可用。
4.1.0.4 评估
根据BIRD (J. Li 等人 2024)和Spider测试套件(R. Zhong, Yu, 和 Klein 2020)的评估标准,我们评估了两个指标:执行准确率(EX)和奖励有效性评分(R-VES)。EX定义为预测SQL与黄金SQL执行结果相同的比例。R-VES的目的是衡量预测SQL在执行相同任务时的效率。
4.1.0.5 基线
我们选择了来自BIRD和Spider排行榜的LLM驱动方法作为基线:
- GPT-4 (OpenAI 等人 2024) 使用零样本Text-to-SQL提示生成SQL。
- DIN-SQL (Pourreza 和 Rafiei 2024a) 通过多个模块将问题分为不同类型,并通过各种提示指导LLM生成最终SQL。
- DAIL-SQL (D. Gao 等人 2023) 通过选择相似的问答-SQL对作为少样本示例来协助LLM生成SQL。
- MAC-SQL (Bing Wang 等人 2023) 通过使用子数据库和子问题简化LLM面临的挑战来生成SQL。
- MCS-SQL (Lee 等人 2024) 使用多组提示生成多组SQL,并通过统一的多选(MCS)选择最终的SQL。
- C3-SQL (Dong 等人 2023) 通过三个模块:清晰提示(CP)、带有提示的校准(CH)和一致输出(CO),构建了系统的零样本Text-to-SQL方法。
- CHESS (Talaei 等人 2024) 通过构建高效的检索和模式修剪方法来减少冗余信息的干扰,从而提高SQL生成的有效性。
- Distillery (Maamari 等人 2024) 认为随着LLMs的发展,模式链接的重要性已经减弱,经过微调的SFT GPT-4o取得了最优结果。
4.1.0.6 实现细节
为了展示OpenSearch-SQL v2的能力,我们选择的具体模型版本是GPT-4o-0513 (OpenAI 等人 2024) 用于生成,bge-large-en-v1.5 (Xiao 等人 2023)用于检索。

4.2 主要结果
为了展示OpenSearch-SQL的有效性,我们在Spider和BIRD数据集上的表现达到了最先进的(SOTA)水平,突显了我们方法的稳定性和优越性。在表[main result]中,我们将我们的方法与BIRD数据集上的基线方法进行了比较。此外,表[main result2]展示了Spider数据集上的实验结果。由于Spider排行榜自2024年2月起不再接受新提交,结果由当前排行榜数据和相关论文报告的数据组成。值得注意的是,BIRD数据集在7月进行了开发集清理,可能导致比较中的差异。为了确保与先前评估的可比性,我们继续使用7月前的数据进行实验。
4.2.0.1 BIRD 结果
我们在表[main result2]中展示了Baseline和OpenSearch-SQL v2在BIRD数据集上的性能。表中的结果完全来自BIRD排行榜。在提交时,我们的方法在BIRD开发集上实现了69.3%的EX,在BIRD保留测试集上实现了72.28%的EX和69.36%的R-VES,均排名第一。值得注意的是,我们的方法并未涉及任何微调以定制LLM。同时,我们展示了未应用自我一致性 & 投票的OpenSearch-SQL的性能。可以看到,即使使用单个生成的SQL,OpenSearch-SQL也实现了67.8的EX,仍然在开发集上保持领先地位。
在图2中,我们比较了我们的方法在不同难度级别上的表现。显然,自我一致性 & 投票在困难问题上表现出最显著的改进,绝对差异达到7.64%。然而,对于简单和中等问题,几乎没有明显差异。这表明随着问题难度的增加,大型模型对幻觉的敏感性也随之增加。
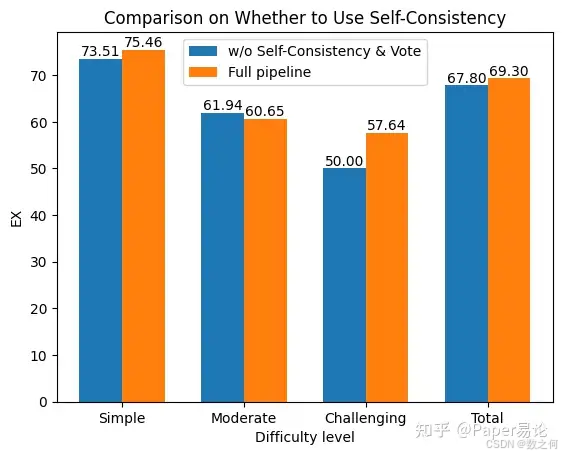
不同难度级别下使用一致性 & 投票的影响比较。
4.2.0.2 Spider 结果

4.3 模块消融
表[component]详细概述了在移除每个模块时的执行准确率(EX)。我们特别考察了提取、生成、优化和对齐模块的作用。此外,我们还研究了关键子模块如检索、少样本、思维链(CoT)和自我一致性 & 投票的影响。值得注意的是,自我一致性 & 投票作为多个SQL选择的最后一步。为了更清楚地说明每个模块对单个SQL优化的影响,我们单独展示了这部分的EX结果。

- 随着工作流的推进,SQL的EX单调递增,表明不同模块对SQL优化有显著的积极影响,证实了每个模块的必要性。
- 在没有提取的情况下,直接使用完整的数据库模式,绕过值检索和列过滤。可以看出,值检索和列过滤对单个SQL的综合改进大约等于提取提供的改进,表明它们的作用重叠较小。
- 少样本在生成阶段表现出显著效果,并在优化阶段进一步增强了最终SQL的性能,突显了动态少样本方法的重要性。我们推测,少样本可以大大增强模型的潜力,同时提高生成结果的稳定性。关于少样本的进一步分析将在实验4.4中进行。

- 对齐模块在各个阶段都发挥了积极作用,显著提升了单个SQL的性能,从而展示了其独特的优化潜力。具体而言,生成阶段后应用的对齐可以帮助校正模块准确修复错误SQL,而不仅仅是使其可执行。
- 显然,自我一致性 & 投票持续提升了LLM的性能上限。根据我们对生成SQL的观察,这一机制主要帮助避免低概率随机性引起的错误。
4.4 少样本
在表[fewshotexp]中,我们探讨了不同动态少样本策略对Text-to-SQL的影响。首先,在生成阶段,我们比较了经典Query-SQL对与我们的Query-COT-SQL对的少样本效果,并评估了无少样本的情况。我们还研究了少样本在其他阶段的影响。从表中我们可以总结以下几点: - 少样本策略显著提高了LLMs生成SQL的准确率上限。无论是Query-SQL对还是Query-CoT-SQL对,相比无少样本,这些格式在每个阶段显著提升了LLMs的性能。然而,少样本在优化阶段的提升相对较小。
- 在生成过程中,对于单个SQL查询,少样本策略提供了最大的性能提升,Query-CoT-SQL对形式比Query-SQL对形式绝对EX提高了3.0%,比无少样本场景下的EX提高了6.4%。
- 在优化和自我一致性 & 投票的影响下,不同形式的少样本之间的差距逐渐缩小,表明不同阶段的SQL优化内容存在一些冗余。
- 尽管少样本策略在优化阶段对单个SQL查询的优化效果有限,但它可以提高一致性与投票的最终EX,表明少样本驱动的SQL校正结果彼此之间具有更高的一致性。
4.5 自我一致性 & 投票
在我们的结果中,我们使用单个提示生成21个结果作为答案。为了研究单个提示下光束搜索生成的SQL输出数量对自我一致性的影响,我们设计了图3所示的实验。

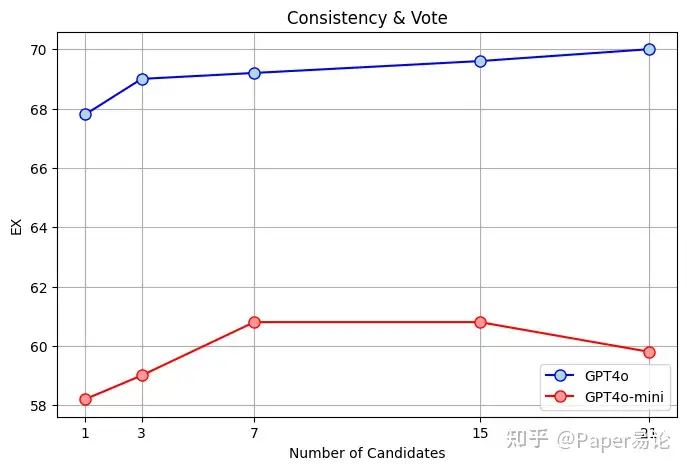
不同候选数量对模型性能的影响比较
4.6 执行成本
在表[cost]中,我们简单估计了使用OpenSearch-SQL与GPT-4o的时间和资源消耗。通常,整个过程的执行时间主要取决于大型语言模型(LLM)调用、检索时间和SQL执行时间。在实践中,使用HNSW (Malkov 和 Yashunin 2018)可以显著减少检索延迟,从而使主要时间消耗转移到LLM响应和SQL执行上。
具体来说,提取和生成阶段的令牌主要来源于数据库模式和少量示例。生成阶段耗时较长,因为它使用BeamSearch,生成的令牌数量多于提取阶段。除了每次触发的SELECT对齐外,其他对齐步骤仅在SQL出现问题时激活,因此在大多数情况下不会耗费太多时间。至于优化阶段,时间主要花在SQL执行和LLM校正上,而自我一致性 & 投票对时间消耗的贡献很小。
4.7 思维链(CoT)


总之,结构化CoT达到了最优结果。在对多个答案进行投票时,结构化CoT相比其他方法表现出更显著的相对提升。
5 相关工作
长期以来,计算机专业人士一直希望根据特定场景将自然语言查询转换为具体的数据库查询,以大幅降低个人的学习和使用成本,弥合外行用户与专家用户之间的差距,并提高使用、分析和查询数据库的效率。Text-to-SQL任务是这些尝试中最具代表性的例子之一,成功解决Text-to-SQL任务意味着类似的方法可以辅助各种SQL类任务。然而,这项任务仍然具有挑战性,特别是由于SQL结构与数据库结构之间的强关联性以及表达格式要求的限制(Katsogiannis-Meimarakis 和 Koutrika 2023)。
5.1 经典方法
经典方法通常不直接生成SQL,而是通过各种方式组装它。这些方法分别处理SELECT、WHERE等组件以构造SQL语句。例如,SQLNET(Xu, Liu, 和 Song 2017)采用了一种基于草图的方法,其中草图包含依赖图,使得一个预测仅考虑其依赖的前一个预测。RYANSQL(Choi 等人 2021)和SyntaxSQLNet(T. Yu, Yasunaga, 等人 2018)尝试泛化草图解码,不仅填补草图中的空白,还生成给定文本的适当草图。此外,还有一些方法利用图表示(Bogin, Gardner, 和 Berant 2019; Brunner 和 Stockinger 2021)和中间语言(J. Guo 等人 2019b; Rubin 和 Berant 2020)来增强LLMs的能力。这些方法可能受到模型固有能力的限制,导致性能不如预期。对于Text-to-SQL任务,它们的理论价值大于实际应用价值。
5.2 大规模语言模型
大规模语言模型(LLMs)是近年来人工智能领域的重要突破。它们基于深度学习技术,通常构建于Transformer架构之上。这些模型由大型神经网络组成,能够在大量文本数据上进行训练,从而赋予它们生成和理解自然语言文本的强大能力。
随着LLMs的发展,出现了几个著名的模型,最著名的是GPT(Generative Pre-trained Transformer)(Radford 等人 2019)和BERT(Bidirectional Encoder Representations from Transformers)(Devlin 等人 2019)。GPT在自然语言生成方面表现出色,而BERT在自然语言理解方面表现出色。这些模型广泛应用于各种领域,如文本生成、信息提取和机器翻译,有效地推动了自然语言处理的发展。
最近,一些更先进的模型出现了,如GPT-4 (OpenAI 等人 2024), LLAMA (Meta 2024), Qwenmax (Bai 等人 2023), 和 DeepSeekV2.5 (Liu 等人 2024), 其中DeepSeekV2.5采用了混合专家(MoE)架构。这些新兴模型由于在各种下游任务中的出色表现,可以被视为自然语言处理和机器学习领域的重大里程碑。得益于这些模型的卓越能力,自然语言处理在解决许多复杂且有意义的问题中发挥着越来越重要的作用。随着技术的不断进步,大规模语言模型有望对全球的科学研究、商业应用和日常生活产生深远影响。
5.3 基于LLM的代理和RAG
随着大模型时代的到来,大模型增强的能力简化了许多以往复杂的任务。基于LLM的代理是一种利用大模型的强大功能执行多种复杂任务的方法(L. Wang 等人 2024), 通常通过扮演特定角色(如程序员、教育者和领域专家)来完成任务(Qian 等人 2023)。检索增强生成(RAG)是一种通过检索高度相关文档来协助回答问题的代理类型(Y. Gao 等人 2024)。此外,包括模块化RAG(W. Yu 等人 2022; Shao 等人 2023)和高级RAG(Ma 等人 2023; L. Gao 等人 2022)在内的多种RAG技术,通过重新排序和重写等技术,帮助LLMs提供更准确和格式丰富的答案。
5.4 LLM用于Text-to-SQL
最新研究表明,最有效的Text-to-SQL方法主要依赖于基于LLMs的多代理算法。这些方法旨在通过代理为LLM提供最有用的信息,以协助预测SQL。在这个过程中,经典的Text-to-SQL任务基准逐渐演变并变得更加复杂,常用的Text-to-SQL评估任务从WiKiSQL(V. Zhong, Xiong, 和 Socher 2017)逐步转向Spider(T. Yu, Zhang, 等人 2018)和BIRD(J. Li 等人 2024)。在这些任务中,研究人员(Tai 等人 2023)通过思维链推理增强了LLM的Text-to-SQL能力。C3(Dong 等人 2023)开发了一种系统的零样本Text-to-SQL方法,包括几个关键组件。DIN-SQL(Pourreza 和 Rafiei 2024a)通过区分问题难度并相应调整提示来解决Text-to-SQL任务。DAIL-SQL(D. Gao 等人 2023)通过检索结构相似的问题或SQL作为少样本示例来帮助模型生成SQL,而MAC-SQL则通过任务分解和重组来提高能力。同时,一些研究选择通过微调+代理的方法完成Text-to-SQL任务,如Dubo-SQL(Thorpe, Duberstein, 和 Kinsey 2024), SFT CodeS(H. Li 等人 2024), DTS-SQL(Pourreza 和 Rafiei 2024b)。目前强大的方法包括MCS-SQL(Lee 等人 2024), 通过多组提示投票提高了Text-to-SQL任务的稳定性;CHESS(Talaei 等人 2024), 通过优秀的列过滤机制简化了生成难度;Distillery(Maamari 等人 2024), 通过微调GPT-4O优化任务。
总体而言,随着大模型能力的不断提升,Text-to-SQL任务框架逐渐收敛并标准化为LLMs + 代理的形式。同时,Text-to-SQL方法的能力也在不断增强,成为真正能够简化人们日常工作中数据库操作的工具。
6 结论
本文介绍了OpenSearch-SQL,这是一种使用动态少样本和一致性对齐机制增强Text-to-SQL任务性能的方法。为了改进模型处理提示的能力,我们通过LLM扩展了原始示例并补充了CoT信息,形成了Query-CoT-SQL少样本配置。据我们所知,这是首次探索使用LLM扩展少样本CoT内容在Text-to-SQL任务中的应用。此外,我们基于一致性对齐机制开发了一种新方法,通过重新整合代理的输入和输出来减轻幻觉现象,从而提高代理输出的质量。我们的方法不依赖任何监督微调任务,完全基于现成可用的LLM和检索模型,代表了Text-to-SQL的纯架构升级。因此,在提交时,我们在BIRD排行榜的所有三个指标上均名列前茅,展示了我们方法的巨大优势。
我们的源代码将很快公开,我们希望这种少样本构建方法和基于一致性对齐的工作流能为Text-to-SQL和其他多代理协作任务提供新的视角和积极影响。
Bai, Jinze, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, et al. 2023. “Qwen技术报告。” arXiv预印本 arXiv:2309.16609.
Bogin, Ben, Matt Gardner, 和 Jonathan Berant. 2019. “全局推理数据库结构以进行Text-to-SQL解析。” arXiv预印本 arXiv:1908.11214.
Brunner, Ursin, 和 Kurt Stockinger. 2021. “Valuenet:一种从数据库信息中学习的自然语言到SQL系统。” 在2021 IEEE第37届国际数据工程会议 (ICDE), 2177–82. IEEE.
Choi, DongHyun, Myeong Cheol Shin, EungGyun Kim, 和 Dong Ryeol Shin. 2021. “Ryansql:递归应用草图填充以跨域数据库中处理复杂Text-to-SQL。” 计算语言学 47 (2): 309–32.
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, 和 Kristina Toutanova. 2019. “BERT:双向Transformer的深度预训练以实现语言理解。” https://arxiv.org/abs/1810.04805.
Dong, Xuemei, Chao Zhang, Yuhang Ge, Yuren Mao, Yunjun Gao, Jinshu Lin, Dongfang Lou, 等人. 2023. “C3:使用ChatGPT的零样本Text-to-SQL。” arXiv预印本 arXiv:2307.07306.
Gao, Dawei, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, 和 Jingren Zhou. 2023. “通过大型语言模型增强的Text-to-SQL:基准评估。” arXiv预印本 arXiv:2308.15363.
Gao, Luyu, Xueguang Ma, Jimmy Lin, 和 Jamie Callan. 2022. “无需相关标签的精确零样本密集检索。” arXiv预印本 arXiv:2212.10496.
Gao, Yunfan, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, 和 Haofen Wang. 2024. “大型语言模型的检索增强生成:综述。” https://arxiv.org/abs/2312.10997.
Guo, Chunxi, Zhiliang Tian, Jintao Tang, Pancheng Wang, Zhihua Wen, Kang Yang, 和 Ting Wang. 2023. “使用去语义化和骨架检索提示GPT-3.5进行Text-to-SQL。” https://arxiv.org/abs/2304.13301.
Guo, Jiaqi, Zecheng Zhan, Yan Gao, Yan Xiao, Jian-Guang Lou, Ting Liu, 和 Dongmei Zhang. 2019a. “面向跨域数据库的复杂Text-to-SQL:使用中间表示。” arXiv预印本 arXiv:1905.08205.
———. 2019b. “面向跨域数据库的复杂Text-to-SQL:使用中间表示。” arXiv预印本 arXiv:1905.08205.
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, 和 Jian Sun. 2015. “用于图像识别的深度残差学习。” https://arxiv.org/abs/1512.03385.
Hristidis, Vagelis, 和 Yannis Papakonstantinou. 2002. “关系数据库中的关键词搜索。” 在VLDB’02:第28届国际非常大数据会议论文集, 670–81. Elsevier.
Hristidis, Vagelis, Yannis Papakonstantinou, 和 Luis Gravano. 2003. “高效的IR风格关键词搜索。” 在Proceedings 2003 VLDB Conference, 850–61. Elsevier.
Iyer, Srinivasan, Ioannis Konstas, Alvin Cheung, Jayant Krishnamurthy, 和 Luke Zettlemoyer. 2017. “从用户反馈学习神经语义解析器。” arXiv预印本 arXiv:1704.08760.
Katsogiannis-Meimarakis, George, 和 Georgia Koutrika. 2023. “深度学习方法在Text-to-SQL中的应用综述。” The VLDB Journal 32 (4): 905–36.
Lee, Dongjun, Choongwon Park, Jaehyuk Kim, 和 Heesoo Park. 2024. “MCS-SQL:利用多提示和多选选择进行Text-to-SQL生成。” arXiv预印本 arXiv:2405.07467.
Li, Haoyang, Jing Zhang, Hanbing Liu, Ju Fan, Xiaokang Zhang, Jun Zhu, Renjie Wei, Hongyan Pan, Cuiping Li, 和 Hong Chen. 2024. “CodeS: 面向Text-to-SQL的开源语言模型构建。” https://arxiv.org/abs/2402.16347.
Li, Jinyang, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, 等人. 2024. “LLM能否已经作为数据库接口?大规模数据库支持的Text-to-SQL大基准。” Advances in Neural Information Processing Systems 36.
Liu, Aixin, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, 等人. 2024. “Deepseek-V2:强大、经济且高效的混合专家语言模型。” arXiv预印本 arXiv:2405.04434.
Ma, Xinbei, Yeyun Gong, Pengcheng He, Hai Zhao, 和 Nan Duan. 2023. “检索增强大型语言模型的查询重写。” arXiv预印本 arXiv:2305.14283.
Maamari, Karime, Fadhil Abubaker, Daniel Jaroslawicz, 和 Amine Mhedhbi. 2024. “模式链接已死?良好推理的语言模型时代下的Text-to-SQL。” https://arxiv.org/abs/2408.07702.
Malkov, Yu. A., 和 D. A. Yashunin. 2018. “使用分层导航小世界图高效稳健的近似最近邻搜索。” https://arxiv.org/abs/1603.09320.
Meta. 2024. “介绍Meta Llama 3:迄今为止最强大的开源LLM。” https://ai.meta.com/blog/meta-llama-3/.
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, 等人. 2024. “GPT-4技术报告。” https://arxiv.org/abs/2303.08774.
Pourreza, Mohammadreza, 和 Davood Rafiei. 2024a. “Din-SQL: Text-to-SQL的分解上下文学习与自校正。” Advances in Neural Information Processing Systems 36.
———. 2024b. “DTS-SQL:使用小型大型语言模型进行分解Text-to-SQL。” https://arxiv.org/abs/2402.01117.
Qian, Chen, Xin Cong, Cheng Yang, Weize Chen, Yusheng Su, Juyuan Xu, Zhiyuan Liu, 和 Maosong Sun. 2023. “用于软件开发的通信代理。” arXiv预印本 arXiv:2307.07924.
Radford, Alec, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, 等人. 2019. “语言模型是无监督的多任务学习者。” OpenAI博客 1 (8): 9.
Rubin, Ohad, 和 Jonathan Berant. 2020. “SmBoP: 半自回归自底向上的语义解析。” arXiv预印本 arXiv:2010.12412.
Shao, Zhihong, Yeyun Gong, Yelong Shen, Minlie Huang, Nan Duan, 和 Weizhu Chen. 2023. “通过迭代检索生成协同增强检索增强型大型语言模型。” arXiv预印本 arXiv:2305.15294.
Tai, Chang-You, Ziru Chen, Tianshu Zhang, Xiang Deng, 和 Huan Sun. 2023. “探索Text-to-SQL的思维链风格提示。” https://arxiv.org/abs/2305.14215.
Talaei, Shayan, Mohammadreza Pourreza, Yu-Chen Chang, Azalia Mirhoseini, 和 Amin Saberi. 2024. “CHESS:上下文约束的高效SQL合成。” https://arxiv.org/abs/2405.16755.
Thorpe, Dayton G, Andrew J Duberstein, 和 Ian A Kinsey. 2024. “Dubo-SQL:多样化的检索增强生成和微调用于Text-to-SQL。” arXiv预印本 arXiv:2404.12560.
Wang, Bailin, Richard Shin, Xiaodong Liu, Oleksandr Polozov, 和 Matthew Richardson. 2019. “Rat-SQL:Text-to-SQL解析器的关系感知模式编码和链接。” arXiv预印本 arXiv:1911.04942.
Wang, Bing, Changyu Ren, Jian Yang, Xinnian Liang, Jiaqi Bai, Qian-Wen Zhang, Zhao Yan, 和 Zhoujun Li. 2023. “Mac-SQL:Text-to-SQL的多代理协作。” arXiv预印本 arXiv:2312.11242.
Wang, Chenglong, Alvin Cheung, 和 Rastislav Bodik. 2017. “从输入输出示例中合成高度表达的SQL查询。” 在ACM SIGPLAN编程语言设计与实现会议论文集, 452–66.
Wang, Lei, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, 等人. 2024. “基于大规模语言模型的自主代理综述。” 计算机科学前沿 18 (6): 1–26.
Wei, Jason, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, 和 Denny Zhou. 2023. “思维链提示在大型语言模型中激发推理。” https://arxiv.org/abs/2201.11903.
Xiao, Shitao, Zheng Liu, Peitian Zhang, 和 Niklas Muennighoff. 2023. “C-Pack:推进通用中文嵌入的打包资源。” https://arxiv.org/abs/2309.07597.
Xu, Xiaojun, Chang Liu, 和 Dawn Song. 2017. “Sqlnet:无需强化学习的自然语言到SQL生成。” arXiv预印本 arXiv:1711.04436.
Yu, Tao, Michihiro Yasunaga, Kai Yang, Rui Zhang, Dongxu Wang, Zifan Li, 和 Dragomir Radev. 2018. “Syntaxsqlnet:复杂和跨域Text-to-SQL任务的语法树网络。” arXiv预印本 arXiv:1810.05237.
Yu, Tao, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, 等人. 2018. “Spider:大规模人工标注的复杂和跨域语义解析和Text-to-SQL任务数据集。” arXiv预印本 arXiv:1809.08887.
Yu, Wenhao, Dan Iter, Shuohang Wang, Yichong Xu, Mingxuan Ju, Soumya Sanyal, Chenguang Zhu, Michael Zeng, 和 Meng Jiang. 2022. “生成而非检索:大型语言模型是强大的上下文生成器。” arXiv预印本 arXiv:2209.10063.
Zhang, Yue, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, 等人. 2023. “AI海洋中的海妖之歌:大规模语言模型幻觉综述。” arXiv预印本 arXiv:2309.01219.
Zhong, Ruiqi, Tao Yu, 和 Dan Klein. 2020. “Text-to-SQL的语义评估:蒸馏测试套件。” https://arxiv.org/abs/2010.02840.
Zhong, Victor, Caiming Xiong, 和 Richard Socher. 2017. “Seq2sql:使用强化学习从自然语言生成结构化查询。” arXiv预印本 arXiv:1709.00103.
原论文:https://arxiv.org/pdf/2502.14913
Xiangjin Xie, Guangwei Xu, LingYan Zhao, Ruijie Guo