作为9年经验的开发,现在的面试据说已经不仅仅是八股文了,本身到这个阶段对我而言,单纯的技术已经没有意义,还是要为业务去选择合适的技术,摘录一些我认为高频或者实用的场景设计题
1、消息推送中的已读/未读消息设计
“站内信”有两个基本功能:
点到点的消息传送。用户给用户发送站内信,管理员给用户发送站内信。
点到面的消息传送。管理员给用户(指定满足某一条件的用户群)群发消息
这两个功能实现起来也很简单:
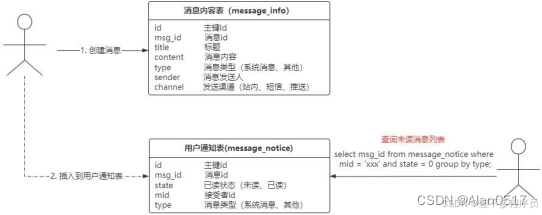
只需要设计一个消息内容表和一个用户通知表,当创建一条系统通知后,数据插入到消息内容表。消息内容包含了发送渠道,根据发送渠道决定后续动作。
如果是站内渠道,在插入消息内容后异步的插入记录到用户通知表。
这个方案看起来没什么问题,但实际上,我们把所有用户通知的消息全部放在一个表里面,如果有 10W 个用户,那么同样的消息需要存储 10W 条。
很明显,会带来两个问题:
- 随着用户量的增加,发送一次消息需要插入到数据库中的数据量会越来越大,导致耗时会越来越长;
- 用户通知表的数据量会非常大,对未读消息的查询效率会严重下降;
随着用户量的增加,发送一次消息需要插入到数据库中的数据量会越来越大,导致耗时会越来越长;
用户通知表的数据量会非常大,对未读消息的查询效率会严重下降;
所以上面这种方案很明显行不通,要解决这两个问题,我有两个参考解决思路。

- 第一个方式(如图),先取消用户通知表, 避免在发送平台消息的时候插入大量重复数据问题。
其次增加一个“message_offset”站内消息进度表,每个用户维护一个消息消费的进度Offset。
每个用户去获取未读消息的时候,只需要查询大于当前维护的 msg_id_offset 的数据即可。
在这种设计方式中,即便我们发送给 10W 人,也只需要在消息内容表里面插入一条记录即可。在性能上和数据量上都有较大的提升。 - 第二种方式,和第一种方式类似,使用 Redis 中的Set 集合来保存已经读取过的消息id。
使用 userid_read_message 作为key,这样就可以为每个用户保存已经读取过的所有 消息的id
当用户读取了未读消息后, 就直接在redis 的已读消息id 的set 中新增一条记录。这样,在已经得知到已读消息的数量和具体消息 id 的情况下,我们可以直接使用消息 id 来查询没有消费过的数据。
2、分布式ID策略
1.为什么需要它
分布式ID是确保系统中的每个数据项都具有全局唯一的标识,满足系统需求并提高开发效率的关键。
在分布式系统中,数据可能分布在多个服务器、数据库或其他存储设备上。为了确保系统中的每个数据项都具有全局唯一的标识,需要使用分布式ID。随着系统的数据量越来越大,单机MySQL已经无法满足需求,需要进行分库分表。数据库的自增主键已经无法满足生成的主键唯一性,此时就需要生成分布式ID。使用分布式ID可以解决数据分布和唯一标识的问题,满足系统需求并提高开发效率。
分布式ID需要满足的要求包括【重要】:
- 全局唯一性:ID在整个系统中是唯一的,不会出现重复的情况。
- 趋势递增:有利于保证写入的效率,尤其是在使用像MySQL数据库的InnoDB存储引擎时,其使用聚集索引和有序的主键ID。
- 单调递增:保证下一个ID大于上一个ID,这种情况可以保证事务版本号、排序等特殊需求实现。
- 信息安全:ID递增但是不规则是最好的,如果ID是连续的,容易被恶意爬取数据。
- 数量够用:根据公司的具体业务来评估在一定时间范围内会消耗多少个ID。
- 安全性:分布式ID生成的算法应该是安全的,防止恶意用户预测或推断出其他ID,甚至恶意篡改。
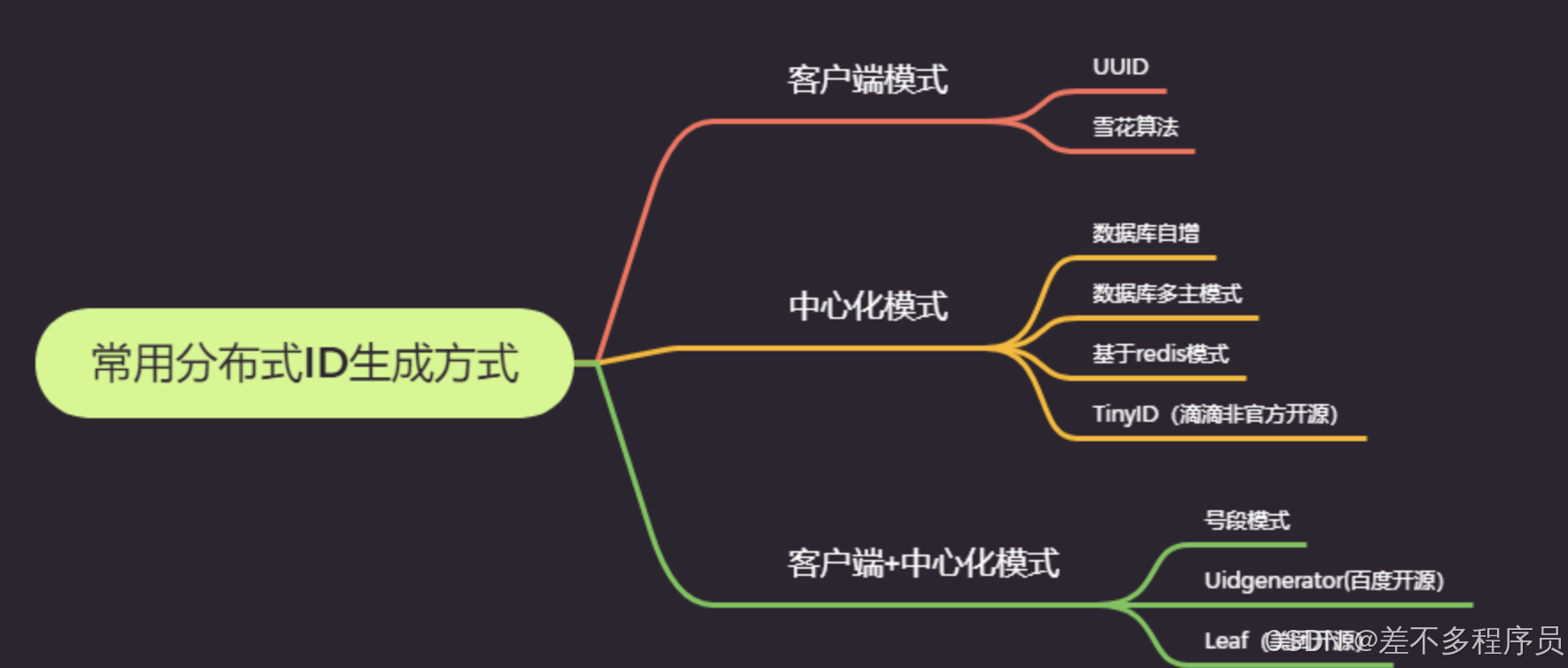
- 有序性:通常建议分布式ID具备有序性,不过需要根据实际的业务来决定。 常见的分布式ID生成方案包括以下几个;
UUID、数据库自增、号段模式、Redis实现、雪花算法(SnowFlake)、百度Uidgenerator、美团Leaf、滴滴TinyID等。
每种方案都有其优缺点,选择最适合的方案需要结合具体的业务场景和需求。
最终分布式ID肯定是要做DB存储的,这就意味着要满足索引或主键的一些要求
2.mysql的页分裂
分布式ID最终是要落库的,InnoDB存储引擎使用聚簇索引来组织表中的数据。
聚簇索引定义了数据在磁盘上的物理存储顺序。数据实际上是存储在索引的叶子节点上的。这意味着,当你通过主键查询数据时,InnoDB可以直接在索引中找到相应的数据,而无需进行额外的磁盘I/O操作。这就是所谓的“覆盖索引”查询,它可以大大提高查询性能。
然而,聚簇索引的一个潜在缺点是它可能导致数据页分裂。
那什么是数据分页呢? lnnoDB 不是按行来操作数据的,它可操作的最小单位是页,页加载进内存后才会通过扫描页来获取行记录比如查询 id=1,是获取 1所在的数据页,加载进内存后取出1这一行。
页的默认大小为16KB,64个连续的数据页称为一个extent(区),64个页组成一个区,所以区的大小为1MB(16*64=1024),连续的256个数据区称为一组数据区。
数据页分裂是一个相对昂贵的操作,因为它涉及到数据的移动和可能的磁盘I/O操作。
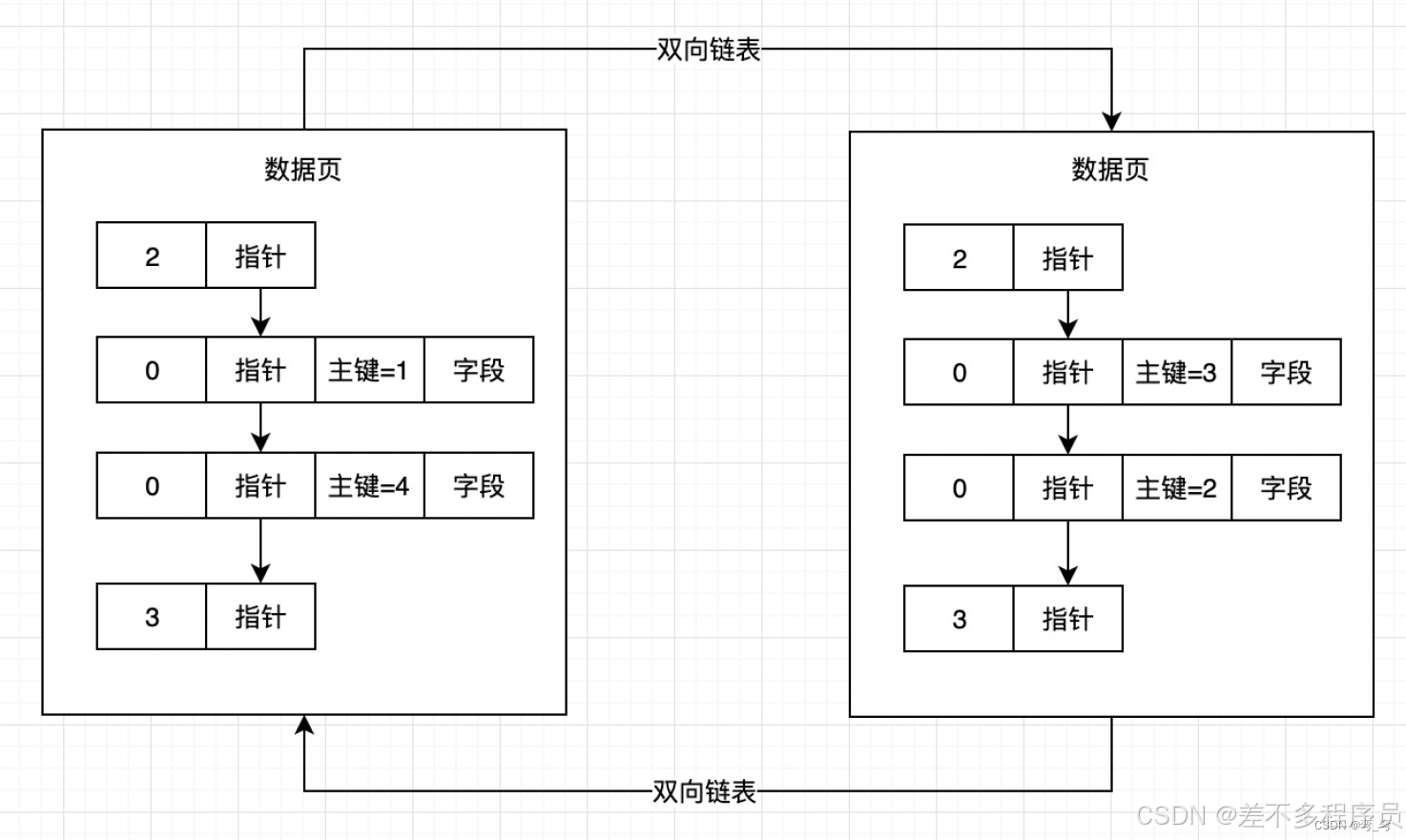
当一个数据页中的数据行太多放不下的时候就会生成一个新的数据页来存储, 同时使用双向链表来相连; 使用索引时,一个最基本的条件是后面数据中的数据行的主键值要大于前一个数据页中数据行的主键值。
如果我们设置的主键是乱序的, 就有可能会导致数据页中的主键值大小不能满足索引使用条件。所以就会要求主键必须有序。
如果值有序,但是插入的数据不是递增的,此时就会产生页分裂, 如下图的数据页:
可以发现后面数据页里的主键值比前一个数据页的主键值小, 里面的数据就会进行数据挪动,那这就是我们所说的页分裂。
通过页分裂,我们只要将主键为2的数据行与主键值为4的数据行互相挪动一下位置,就可以保证后面一个数据页的主键值比前一个数据页中的主键值大了,
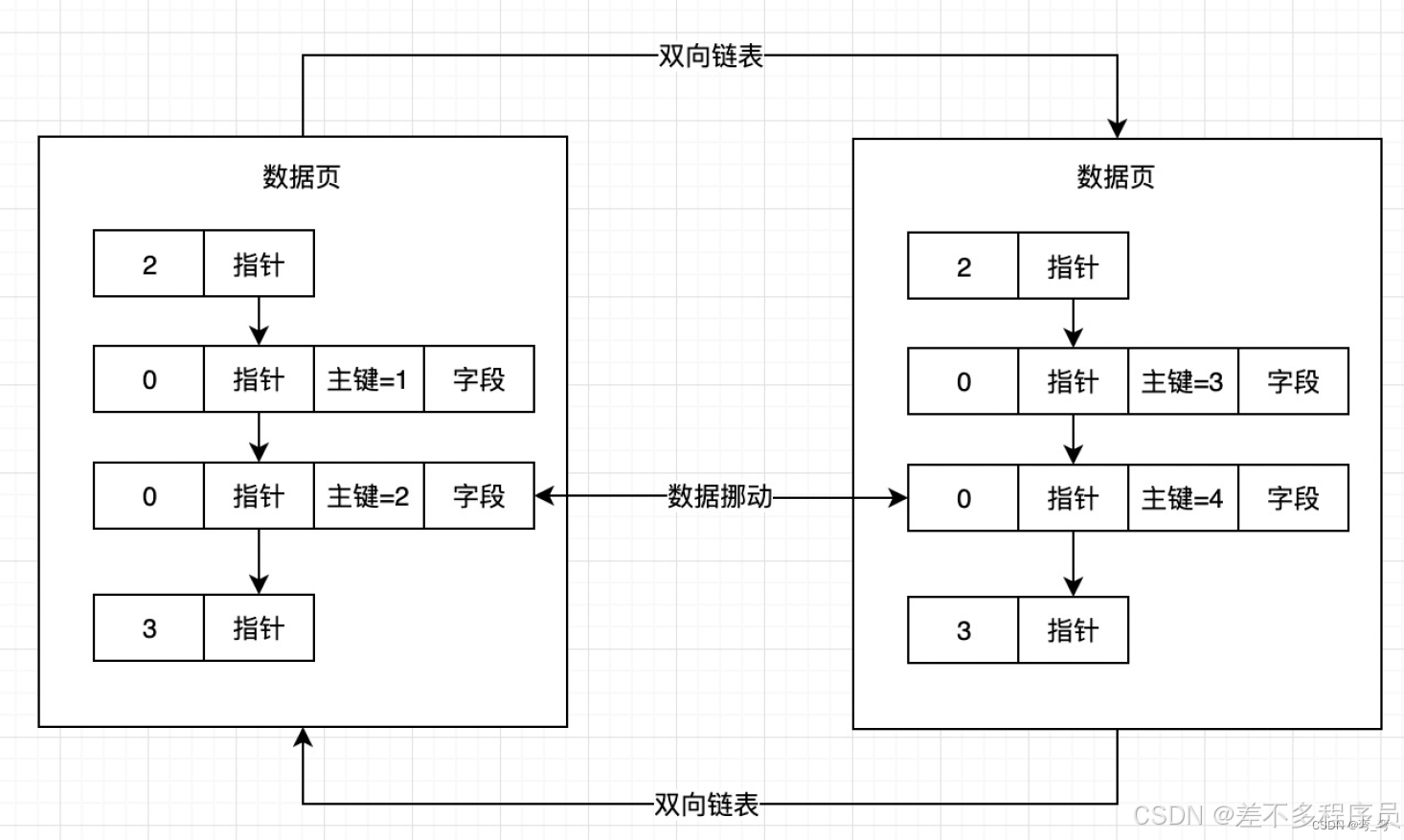
为了更清晰地理解页分裂,我们可以将其步骤概括为:
检查空间:当InnoDB尝试插入新的数据时,它首先会检查当前数据页是否有足够的空间来容纳新数据。
分裂决策:如果当前页没有足够的空间,InnoDB就会决定进行页分裂。它会创建一个新的数据页,并将原数据页中的一部分数据(通常是中位数附近的数据)移动到新页中,以确保新插入的数据可以放在合适的位置。
数据移动:实际的数据移动过程涉及将原数据页中的一部分行复制到新页中,并更新相关的索引和指针以反映这种变化。这可能涉及到多个数据页的调整,以确保数据的连续性和索引的正确性。
更新链接:InnoDB会更新数据页之间的双向链表指针,以确保分裂后的数据页仍然按照正确的顺序链接在一起。同时,它也会更新索引结构以反映新数据页的存在和位置。
插入新数据:一旦页分裂完成,InnoDB就可以在新的位置插入新数据了。这通常是在分裂后留下的空间中进行的。
需要注意的是,页分裂不仅发生在插入操作中。当更新操作导致行的大小增加,使得当前页无法容纳时,也可能发生页分裂。同样地,删除操作可能导致页的合并,以释放空间并提高存储效率。
为了减少页分裂的频率和提高写入性能,可以采取以下策略:
- 有序插入:如您所述,通过保持插入数据的顺序性(如使用自增主键),可以减少页分裂的次数。这是因为有序插入可以使得新数据总是被添加到索引的末尾,从而避免了在中间位置插入数据所需的复杂操作。
- 批量插入:将多个插入操作组合成一个批量插入操作可以减少单个插入操作的开销,并提高整体的写入性能。这可以通过使用InnoDB的批量插入优化来实现。
- 调整页大小:虽然InnoDB的默认页大小是16KB,但在某些情况下,调整页大小可能有助于优化性能。然而,这需要谨慎操作,因为页大小的更改会影响到整个数据库的存储和性能特性。
- 优化索引设计:通过合理设计索引和使用覆盖索引等技术,可以减少不必要的数据页访问和I/O操作,从而提高写入性能并减少页分裂的可能性。
所以,其结论就是主键值最好是有序的, 不仅可以不用页分裂,还能充分使用到索引。否则必须进行页分裂来保证索引的使用。
3.根据场景选择
2.1 UUID
UUID (Universally Unique Identifier),通用唯一识别码的缩写。UUID的标准型式包含32个16进制数字,标准格式为:8-4-4-4-12,总长度为36个字符(包括4个-号)
优点
(1)技术实现简单,一行代码即可。
(2)本地即可生成,出错率低。
(3)ID生成性能高。
缺点
(1)无序,影响数据库的数据写入性能。
(2)存储成本高,就算去掉4个“-”,长度也是32。
(3)可读性差。
场景
分布式链路追踪ID
千万不要忽视索引重建带来的问题,看下我们公司之前的表,200w+的核心表,单字段索引+联合索引有14个,造成的结果是索引物理存储几乎是数据的5倍,如果采用的分布式id做索引或者主键,其带来的索引重建,随机IO和频繁的页分裂,肯定是不小

2.2 数据库自增id
基于数据库的auto_increment自增ID完全可以充当分布式ID:
优点
- 实现简单,ID单调自增,数值类型查询速度快
缺点
- DB单点存在宕机风险,无法扛住高并发场景
- 单调增长,存在被攻击的情况
- 扩展性问题,随着业务量的增长,如果采用分库分表这个模式做改造就很麻烦
场景
单库低业务量场景
2.3 数据库号段模式
CREATE TABLE id_generator (
`id` int(10) NOT NULL,
`max_id` bigint(20) NOT NULL COMMENT '当前最大id',
`step` int(20) NOT NULL COMMENT '号段的步长',
`biz_type` int(20) NOT NULL COMMENT '业务类型',
`version` int(20) NOT NULL COMMENT '版本号乐观锁',
PRIMARY KEY (`id`)
)
等ID都用了,再去数据库获取,然后更改最大值
update id_generator set max_id = #{max_id+step}, version = version + 1 where version = # {version} and biz_type = XXX
优点
- 容灾性高,虽然强依赖于数据库,但是分布式ID发号器可以内存级别缓存一定的号段,即使数据库宕机也能提供一段时间的服务。(建议号段的步长step设置为QPS的600倍,数据库宕机后也可以用10min)。
- 有比较成熟的方案,像百度Uidgenerator,美团Leaf
缺点
- 强依赖于数据库实现
- ID号码不够随机,能够泄露发号数量的信息,不太安全。不适合做订单的ID
- 当号段使用完后,需要向数据库请求新的号段,性能会卡在数据库的IO性能上
- DB宕机或者发生主从切换,会导致一段时间的服务不可用
场景
优缺点明显,偏向业务复杂的场景,感觉使用这个模式的公司,都是在业务发展前期设计的,后续打了很多的补丁,使用上和运营依旧会遇见很多不可控的问题;
2.4 redis自增
Redis分布式ID实现主要是通过提供像INCR 和 INCRBY 这样的自增原子命令,由于Redis单线程的特点,可以保证ID的唯一性和有序性;
这种实现方式,如果并发请求量上来后,就需要集群,不过集群后,又要和传统数据库一样,设置分段和步长;
优点
- Redis性能相对比较好,又可以保证唯一性和有序性
缺点
- 需要依赖Redis来实现,系统需要引进redis组件(对于微服务来说不是问题)
- 单调增长的特性,id存在被攻击的风险
场景
还真没见有人用过这个做分布式环境的发号器
2.5 雪花算法
组成结构
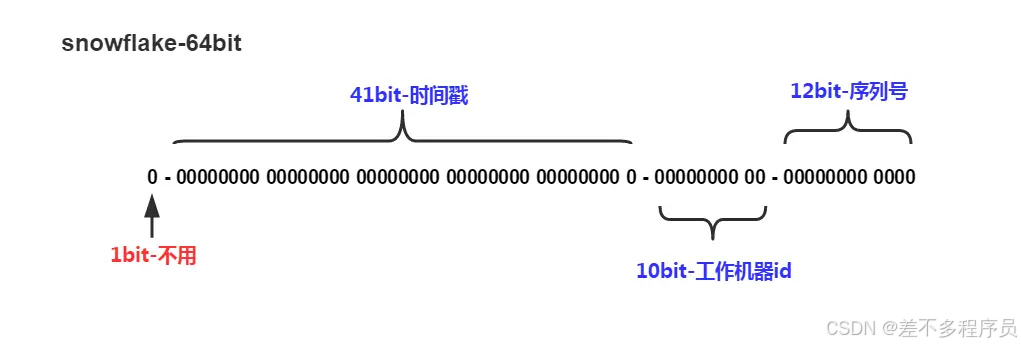
| 位置 | 取值 | 说明 |
|---|---|---|
| 1bit | 固定0 | 代表正整数 |
| 41bit时间戳 | 2^41-1 | 1个数=1毫秒=>69年 |
| 10bit机器id | 2^10=1024 | 机房+机器一共10位=>1024个节点 |
| 12bit序列号 | 2^12-1=4095 | 单节点1毫秒可产生4095个ID序号 |
速记口诀:一是一,要灵要饿【141,1012】
从上面的组成可以看出来,雪花算法基础逻辑上可以保证以下两个特点:
- 不依赖于数据库,完全在内存中生成,速度快
- id是按照时间趋势递增的,但是1ms带来的id变化量很客观,暴力攻击不太可能
- 从整个分布式系统内部而言,不会产生重复的id(机房id+机器id)
场景实战
在了解其组成结构以后,我结合网上的资料,改造了一个工具类:
@Slf4j
@Data
public class DistributeIdGenerator {
/**
* workerId部分1:数据中心占用的位数 原默认5
*/
private int dataCenterBitNum = 0;// 此处我设置的0
/**
* workerId部分2:机器码占用的位数,原默认5
*/
private int machineBitNum;
/**
* 随机数的占位
*/
private int sequenceBitNum;
/**
* 起始的时间戳
*/
private static final long TIMESTAMP = 1716981729000L;
/**
* 用于进行末尾sequence随机数产生
*/
private static final Random RANDOM = new Random();
/**
* datacenter编号 我们不用,默认值为0
*/
private long datacenterId = 0;
/**
* 机器编号
*/
private volatile long machineId = -1;
/**
* 上次生成id的最新时间戳
*/
private long lastStamp = -1L;
/**
* 时间戳偏移位数:机房位+机器位+序列位
*/
private int timestampLeftShift;
/**
* datacenter偏移位数:机器位+序列位
*/
private int datacenterIdShift;
/**
* 机器id偏移位数:序列位
*/
private int machineIdShift;
/**
* 每秒产生的最大序列值:~(-1L << sequenceBitNum)
* 假如sequenceBitNum=12
* 第一步:11111111111111111111111111111111(32位)左移12位得到11111111111111111111000000000000
* 第二部:使用按位非操作 ~,即取反,每个 1 变成 0,每个 0 变成 1。所以,上面的二进制串取反后变为:00000000000000000000111111111111
* 第三步:二进制转10进制,其实就是2的12次方-1的值,即4095
*/
private Long maxSequenceValue;
/**
* 根据上面的规则初始化偏移量
*/
private void initShiftOffset() {
timestampLeftShift = this.dataCenterBitNum + this.machineBitNum + this.sequenceBitNum;
datacenterIdShift = this.machineBitNum + this.sequenceBitNum;
machineIdShift = this.machineBitNum;
maxSequenceValue = ~(-1L << sequenceBitNum);
}
/**
* 私有化构造,禁止new
*/
private DistributeIdGenerator() {
}
/**
* 产生下一个ID
*/
public synchronized long nextId() {
long currentStamp = System.currentTimeMillis();
if (currentStamp < this.lastStamp) {
long backMills = lastStamp - currentStamp;
if (backMills <= 5) {
try {
wait(backMills << 1);
currentStamp = System.currentTimeMillis();
if (currentStamp < this.lastStamp) {
}
} catch (InterruptedException e) {
// doNothing
throw new RuntimeException("服务节点时钟发回拔if (currentStamp < this.lastStamp) {
long backMills = lastStamp - currentStamp;
if (backMills <= 5) {
try {
wait(backMills << 1);
currentStamp = System.currentTimeMillis();
if (currentStamp < this.lastStamp) {
throw new RuntimeException("服务节点时钟发回拔,请重点关注!");
}
} catch (InterruptedException e) {
// doNothing
throw new RuntimeException("服务节点时钟发回拔系统异常,请重点关注!");
}
}
},请重点关注!");
}
}
}
long sequence = 0;
if (currentStamp == this.lastStamp) {
sequence = (sequence + 1) & this.maxSequenceValue;// 位运算保证始终就是在4096这个范围内
// 1毫秒内自增数超过设置的最大值,等待1ms,防止进位导致id重复
if (sequence > this.maxSequenceValue) {
sequence = 0L;// 此处不采用随机数是考虑到现有的都不够用了,就别在随机了,搞不好随机个值就更少了
currentStamp = getNextMills();
}
} else {
// 时间不相同时,默认sequence归0,容易导致大部分尾数雷同,采用随机数可以做到数据存储的分布均衡
sequence = RANDOM.nextInt(100);
}
// 维护最后一次生成的时间
this.lastStamp = currentStamp;
// 先按照雪花算法的结构对各part的值进行位移,然后做各个part的或运算就可以拿到最终的结果
long ts = (currentStamp - TIMESTAMP) << this.timestampLeftShift;
long dc = this.datacenterId << this.datacenterIdShift;
long work = this.machineId << this.machineIdShift;
return ts | dc | work | sequence;
}
/**
* 判断是否在1毫秒内
* - 是:阻塞,直到下一毫秒,返回下一毫秒的时间戳
* - 否:返回当前时间戳
*/
private long getNextMills() {
long timestamp = System.currentTimeMillis();
while (timestamp <= lastStamp) {
timestamp = System.currentTimeMillis();
}
return timestamp;
}
/**
* 静态工厂
*
* @param machineId 机器/节点id[0,1024]
* @param machineBitNum 机器码占用位数
* @param sequenceBitNum 随机数长度
* @return 生成器
*/
public static DistributeIdGenerator getInstance(Integer machineId, Integer machineBitNum, Integer sequenceBitNum) {
if (machineId < 0 || machineId > (~(-1 << machineBitNum))) {
throw new RuntimeException("机器id越界,请重新设置");
}
DistributeIdGenerator generator = new DistributeIdGenerator();
generator.setMachineBitNum(machineBitNum);
generator.setSequenceBitNum(sequenceBitNum);
generator.setMachineId(machineId);
// 初始化偏移量
generator.initShiftOffset();
return generator;
}
public static void main(String args[]) {
try {
DistributeIdGenerator instance = DistributeIdGenerator.getInstance(1, 10, 12);
System.out.println("id:" + instance.nextId());
Thread.sleep(2000);
} catch (Exception e) {
e.printStackTrace();
}
}
}
实战总结
- 在了解清楚结构之后,这些运算和计算的逻辑,其实也很简单
- 数据中心一般实际情况下,设置0就行,把空间留给机器id(总体10位,1024个节点)
- 1毫秒生成的id数,理论上最多4095个,要注意边界的情况,发号发完了,就while等1毫秒
- 时间不相同的情况下,序列号sequence的起始值可以采用随机数处理,这可以保证数据在存储的时候,如果有场景是用的value取模做的存储,可以保证存储的均匀性
- 雪花算法能从我设置的TIMESTAMP值开始,用69年
- 时钟回波的问题也不可怕,个人认为再多的方案都不如抛异常靠谱,我的case里面的代码参考美团的leaf做了一次尝试,如果发生回拔的时间在网络波动范围内,则做一次retry;如果还是失败,则抛异常;这种策略至少不要修数据,远比id重复带来的数据混淆更加可控,让它崩;【人比机器靠谱,可以增加回拔的容错性,牺牲一点点性能,也就几ms】
10 参考资料
- https://blog.csdn.net/cxyxysam/article/details/136656172
- https://zhuanlan.zhihu.com/p/682656066
- https://www.elecfans.com/d/2313649.html
- https://blog.csdn.net/tang_huan_11/article/details/136526916【强推】
- https://www.jianshu.com/p/2a27fbd9e71a【强推】
3、接口限流
todo