An End-to-End Spatio-Temporal Attention Model for Human Action Recognition from Skeleton Data 这是来自微软亚洲研究院的一篇文章,兰翠玲老师组的,他们在骨架动作识别方面出过不少佳作,微软毕竟是kinect亲妈。只是代码不开源,略坑。
网络结构
网络(Main LSTM Network)用于对特征进行提取、时域相关性利用和最终的分类。时域注意力子网络 (Temporal Attention)用于给不同帧分配合适的重要性。空域注意力子网络(Spatial Attention)用于给不同关节点分配合适的重要性。
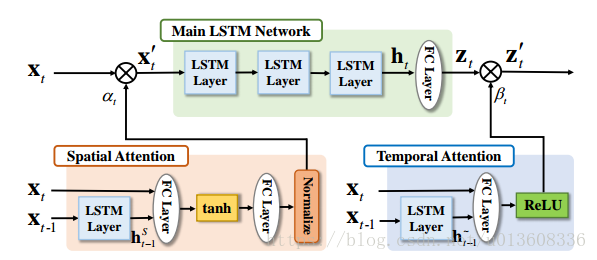
序列中的空域注意力和时域注意力具体为多大是没有参考的(不知道Groundtruth)。网络是以优化最终分类性能来自动习得注意力,以及加上一些正则项。
Spatial Attention with Joint-Selection Gates
就是普通的soft-attention 机制
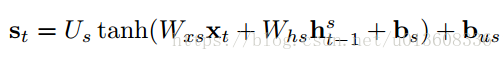
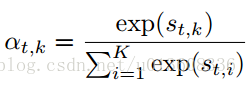
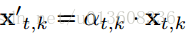
Temporal Attention with Frame-Selection Gate
与空间注意力不同的是,这里用了relu作为激活函数,没用softmax,而且是直接与lstm输出