注:本文为 “NAT traversal ”相关的几篇文章合辑。
未整理去重。
NAT 穿越技术原理
Li_yy123 于 2020-12-08 18:54:26 发布
一、NAT 由来
为了解决全球公有 IPv4 的稀缺,提出了 NAT 技术。NAT 是 Network Address Translation 网络地址转换的缩写。
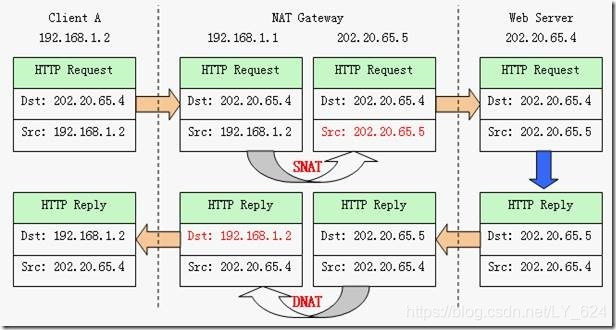
NAT 将私有 IP 地址通过 NAT 网关转换成公网 IP 地址,在网关的 NAT 地址转换表记录下转换映射记录,当外部数据返回时,网关使用 NAT 技术查询 NAT 转换表,再将目标地址替换成内网用户 IP 地址。
当一个公司内部配置了这些私有地址后,内部的计算机在和外网通信时,公司的网关会通过 NAT 或者 PAT 技术,将内部的私有地址转换成公网 IP,外部看到的源地址是公司网关转换过的公网 IP 地址,这在某种意义上也增加了内部网络的安全性,如下图。

二、NAT 的几个关键特点
- 网络被分为私网和公网两个部分,NAT 网关设置在私网到公网的路由出口位置,双向流量必须都要经过 NAT 网关;
- 网络访问只能先由私网侧发起,公网无法主动访问私网主机;
- NAT 网关在两个访问方向上完成两次地址的转换或翻译,出方向做源信息替换,入方向做目的信息替换;
- NAT 网关的存在对通信双方是保持透明的;
- NAT 网关为了实现双向翻译的功能,需要维护一张关联表,把会话的信息保存下来。
随着后面对 NAT 的深入描述,读者会发现,这些特点是鲜明的,但又不是绝对的。其中第二个特点打破了 IP 协议架构中所有节点在通讯中的对等地位,这是 NAT 最大的弊端,为对等通讯带来了诸多问题,当然相应的克服手段也应运而生。事实上,第四点是 NAT 致力于达到的目标,但在很多情况下,NAT 并没有做到,因为除了 IP 首部,上层通信协议经常在内部携带 IP 地址信息。
三、NAT 优点
-
使多台计算机共享 Internet 连接,这一功能很好地解决了公共 IP 地址紧缺的问题。通过这种方法,可以只申请一个合法 IP 地址,就把整个局域网中的计算机接入 Internet 中。
-
处于 NAT 网关内,隐藏了公网地址,NAT 对来自外部的数据查看其 NAT 映射记录,对没有相应记录的数据包进行拒绝,提高了网络的安全性。
-
网络发生变化时,避免重新编址(这个问题具有亲身体会,原本所在的实习单位搬迁,我们搬到了新的住处,网络环境发生了一些变化,但是由于 nat 技术的特点,我们局域网的地址并没有发生改变,我们依然使用着最初的编址方案)。
NAT 对我们来说最大的贡献就是帮助我们节省了大量的 ip 资源。
四、NAT 限制和解决方案
1.IP 端到端服务模型
IP 协议的一个重要贡献是把世界变得平等。在理论上,具有 IP 地址的每个站点在协议层面有相当的获取服务和提供服务的能力,不同的 IP 地址之间没有差异。人们熟知的服务器和客户机实际是在应用协议层上的角色区分,而在网络层和传输层没有差异。一个具有 IP 地址的主机既可以是客户机,也可以是服务器,大部分情况下,既是客户机,也是服务器。端到端对等看起来是很平常的事情,而意义并不寻常。
但在以往的技术中,很多协议体系下的网络限定了终端的能力。正是 IP 的这个开放性,使得 TCP/IP 协议族可以提供丰富的功能,为应用实现提供了广阔平台。因为所有的 IP 主机都可以服务器的形式出现,所以通讯设计可以更加灵活。
使用 UNIX/LINUX 的系统充分利用了这个特性,使得任何一个主机都可以建立自己的 HTTP、SMTP、POP3、DNS、DHCP 等服务。
与此同时,很多应用也是把客户端和服务器的角色组合起来完成功能。例如在 VoIP 应用中,用户端向注册服务器登录自己的 IP 地址和端口信息过程中,主机是客户端;而在呼叫到达时,呼叫处理服务器向用户端发送呼叫请求时,用户端实际工作在服务器模式下。在语音媒体流信道建立过程后,通讯双向发送语音数据,发送端是客户模式,接收端是服务器模式。
而在 P2P 的应用中,一个用户的主机既为下载的客户,同时也向其他客户提供数据,是一种 C/S 混合的模型。
上层应用之所以能这样设计,是因为 IP 协议栈定义了这样的能力。试想一下,如果 IP 提供的能力不对等,那么每个通信会话都只能是单方向发起的,这会极大限制通信的能力。
细心的读者会发现,前面介绍 NAT 的一个特性正是这样一种限制。没错,NAT 最大的弊端正在于此 —— 破坏了 IP 端到端通信的能力。
2.NAT 弊端
NAT 在解决 IPv4 地址短缺问题上,并非没有副作用,其实存在很多问题。
(1)NAT 使 IP 会话的保持时效变短。
因为一个会话建立后会在 NAT 设备上建立一个关联表,在会话静默的这段时间,NAT 网关会进行老化操作。这是任何一个 NAT 网关必须做的事情,因为 IP 和端口资源有限,通信的需求无限,所以必须在会话结束后回收资源。
通常 TCP 会话通过协商的方式主动关闭连接,NAT 网关可以跟踪这些报文,但总是存在例外的情况,要依赖自己的定时器去回收资源。而基于 UDP 的通信协议很难确定何时通信结束,所以 NAT 网关主要依赖超时机制回收外部端口。
通过定时器老化回收会带来一个问题,如果应用需要维持连接的时间大于 NAT 网关的设置,通信就会意外中断。因为网关回收相关转换表资源以后,新的数据到达时就找不到相关的转换信息,必须建立新的连接。当这个新数据是由公网侧向私网侧发送时,就会发生无法触发新连接建立,也不能通知到私网侧的主机去重建连接的情况。这时候通信就会中断,不能自动恢复。即使新数据是从私网侧发向公网侧,因为重建的会话表往往使用不同于之前的公网 IP 和端口地址,公网侧主机也无法对应到之前的通信上,导致用户可感知的连接中断。
NAT 网关要把回收空闲连接的时间设置到不发生持续的资源流失,又维持大部分连接不被意外中断,是一件比较有难度的事情。在 NAT 已经普及化的时代,很多应用协议的设计者已经考虑到了这种情况,所以一般会设置一个连接保活的机制,即在一段时间没有数据需要发送时,主动发送一个 NAT 能感知到而又没有实际数据的保活消息,这么做的主要目的就是重置 NAT 的会话定时器。
(2)NAT 在实现上将多个内部主机发出的连接复用到一个 IP 上,这就使依赖 IP 进行主机跟踪的机制都失效了。
如网络管理中需要的基于网络流量分析的应用无法跟踪到终端用户与流量的具体行为的关系。基于用户行为的日志分析也变得困难,因为一个 IP 被很多用户共享,如果存在恶意的用户行为,很难定位到发起连接的那个主机。即便有一些机制提供了在 NAT 网关上进行连接跟踪的方法,但是把这种变换关系接续起来也困难重重。
基于 IP 的用户授权不再可靠,因为拥有一个 IP 的不等于一个用户或主机。一个服务器也不能简单把同一 IP 的访问视作同一主机发起的,不能进行关联。有些服务器设置有连接限制,同一时刻只接纳来自一个 IP 的有限访问 (有时是仅一个访问),这会造成不同用户之间的服务抢占和排队。有时服务器端这样做是出于 DOS 攻击防护的考虑,因为一个用户正常情况下不应该建立大量的连接请求,过度使用服务资源被理解为攻击行为。但是这在 NAT 存在时不能简单按照连接数判断。
总之,因为 NAT 隐蔽了通信的一端,把简单的事情复杂化了。
(3)NAT 工作机制依赖于修改 IP 包头的信息,这会妨碍一些安全协议的工作。
因为 NAT 篡改了 IP 地址、传输层端口号和校验和,这会导致认证协议彻底不能工作,因为认证目的就是要保证这些信息在传输过程中没有变化。
对于一些隧道协议,NAT 的存在也导致了额外的问题,因为隧道协议通常用外层地址标识隧道实体,穿过 NAT 的隧道会有 IP 复用关系,在另一端需要小心处理。
ICMP 是一种网络控制协议,它的工作原理也是在两个主机之间传递差错和控制消息,因为 IP 的对应关系被重新映射,ICMP 也要进行复用和解复用处理,很多情况下因为 ICMP 报文载荷无法提供足够的信息,解复用会失败。
IP 分片机制是在信息源端或网络路径上,需要发送的 IP 报文尺寸大于路径实际能承载最大尺寸时,IP 协议层会将一个报文分成多个片断发送,然后在接收端重组这些片断恢复原始报文。IP 这样的分片机制会导致传输层的信息只包括在第一个分片中,NAT 难以识别后续分片与关联表的对应关系,因此需要特殊处理。
(4)有一些应用程序虽然是用 A 端口发送数据的,但却要用 B 端口进行接收,不过 NAT 设备翻译时却不知道这一点,它仍然建立一条针对 A 端口的映射,结果对方响应的数据要传给 B 端口时,NAT 设备却找不到相关映射条目而会丢弃数据包。
(5)如果 NAT 本身又位于另一个 NAT 之后,则也会出现一些问题,为了节约 IP 资源,现在很多的 ISP 在它们 内部架设 NAT,然后再把服务提供给用户,比如长城、聚友等 ISP 通常都是以城域网的方式为用户提供宽带上网服务的。
从关联表管理角度来说,无法有效的控制在哪个 NAT 网关上建立关联表以及维护。
(6)NAT 下,网络访问只能先由私网侧发起,公网侧无法主动访问私网主机。
所有的主机都 “隐藏” 在 NAT 网关下,不利于全局性的管理。它隐藏了发送报文的主机的有关信息,使得外部网络难于对它们进行管理,例如,若内部网络中某台主机在 Internet 上违反安全规则,Internet 就无法查处 “元凶”。
(7)一些 P2P 应用在 NAT 后无法进行。
对于那些没有中间服务器的纯 P2P 应用来说,如果大家都位于 NAT 设备之后,双方是无法建立连接的。因为没有中间服务器的中转,NAT 设备后的 P2P 程序在 NAT 设备上是不会有映射条目的,也就是说对方是不能向你发起一个连接的。
(8)如果网络规模增大,访问 Internet 的主机增多,地址对应表的规模必然会越来越大,这将导致效率的降低。也会增加错误寻址的可能性。
我们来深入理解 NAT 一下对 IP 端到端模型的破坏力:
NAT 通过修改 IP 首部的信息变换通信的地址。但是在这个转换过程中只能基于一个会话单位。当一个应用需要保持多个双向连接时,麻烦就很大。NAT 不能理解多个会话之间的关联性,无法保证转换符合应用需要的规则。
当 NAT 网关拥有多个公有 IP 地址时,一组关联会话可能被分配到不同的公网地址,这通常是服务器端无法接受的。更为严重的是,当公网侧的主机要主动向私网侧发送数据时,NAT 网关没有转换这个连接需要的关联表,这个数据包无法到达私网侧的主机。
这些反方向发送数据的连接总有应用协议的约定或在初始建立的会话中进行过协商。但是因为 NAT 工作在网络层和传输层,无法理解应用层协议的行为,对这些信息是无知的。NAT 希望自己对通信双方是透明的,但是在这些情况下这是一种奢望。
五、后 IPv4 时代的 NAT
NAT 是为延缓 IPv4 地址耗尽而推出的技术。毫无疑问,它已经出色完成了自己的历史使命,IPv4 比预期走得更远。作为继任者的 IPv6 吸取了 IPv4 的教训,被赋予充足地址空间的同时在各个方面做了优化 —— 安全、高效、简洁。但是 IPv6 无法平滑地取代 IPv4,导致 IP 升级步伐缓慢。尽管网络协议的分层设计很清晰,大量应用层协议和互联网软件中仍内嵌了 IPv4 地址的处理,要 Internet 全网升级到 IPv6,必须先完成应用的改造。因为 NAT 和它的穿越技术结合能够满足大部分用户的需求,所以 IPv6 时代被不断推迟。
随着 IPv4 地址的濒临耗尽,再经济的模式也无以为继,IPv4 必须退出历史舞台。人们自然会认为,NAT 作为 IPv4 的超级补丁技术使命已经完结。实际情况是,IPv4 向 IPv6 过渡的阶段,NAT 仍然是一项必不可少的技术手段。因为 Internet 无法在一日之内完成全网升级,必然是局部升级,逐渐替换。在两套协议并存的时期,用户和服务资源分布在不同网络之间,跨网访问的需求必须得到满足。这正是 NAT 所擅长的领域,地址替换,因此 NAT-PT 应运而生。由于 IPv4 和 IPv6 之间的差异,NAT 要做的事比以往更复杂,有更多的限制和细节。
此外,IETF 也在制定纯 IPv6 网络使用的 NAT 规范。虽然人们还看不到这种应用的强烈需求,但是 NAT 仍有其独特的作用,比如隐藏内部网络的地址,实现重叠地址网络的合并等。
六、NAT 穿透技术
NAT 阻碍主机进行 P2P 通信的主要原因是 NAT 不允许外网主机主动访问内网主机,因为 NAT 设备上没有相关转发表项,要在 NAT 网络环境中进行有效的 P2P 通信,就必须寻找相应的解决方案。
解决上述问题的权宜之计
要解决上面的部份问题,可以应用 NAT 穿越技术 (NAT Traversal),NAT 穿越技术拥有这样的功能,它能够让网络应用程序 (如 MSN Messenger) 主动发现自己位于 NAT 设备之后,并且会主动获得 NAT 设备的公网 IP,并为自己建立端口映射条目,注意这些都是 NAT 设备后的应用程序自动完成的,也就是说,在 NAT 穿越技术中,NAT 设备后的应用程序处于主动地位,它已经明确地知道 NAT 设备要修改它外发的数据包,于是它主动配合 NAT 设备的操作,主动地建立好映射,这样就不像以前由 NAT 设备来建立映射了。这样就会解决很多以前由 NAT 引起的网络连接问题。
(1) 解决了嵌入式 IP 地址或端口的问题,因为现在应用程序已经知道了自己映射的公网条目,那么它在 IP 数据包的应用数据部分嵌入 IP 地址和端口时就会嵌入映射后的公网条目,这样对方通信时就不会出现问题了。
(2) 对于从公网访问内部网络服务,再也用不着手动去配置静态映射了,因为这一切已经由应用程序自动配置好了。
(3) 对于上面 NAT 弊端部分所讲的第四种情况,由于是应用程序自己建立映射条目,那么它也会自动建立针对 B 端口的映射,而再也不会建立针对 A 端口的映射了。
(4) 对于那种没有中间服务器支持的 P2P 应用来说,它们之前通信也不会再有问题了,因为映射条目已经建立好了。
不过对于那种 NAT 设备位于另一个 NAT 设备之后的情况,NAT 穿越技术也无能为力,所以选择 ISP 的时候需要关注这一点。
1.NAT 分类
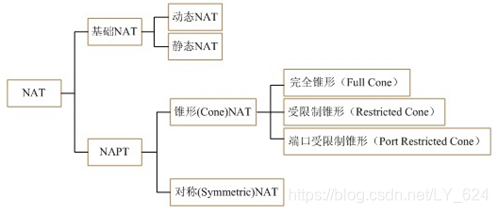
下面围绕上图进行介绍。
从基本方式来说,NAT 分为三类:动态 NAT、静态 NAT 和 NAPT(网络端口地址转换)。
(1)静态 NAT 是指一个内部主机唯一对应一个公网 IP 地址(一对一),显然这种方式对于节约 IP 资源来说没有多大意义;
(2)动态 NAT 是指在路由器上配置一个外网 IP 地址池(M 对 N),当内部有计算机需要和外部通信时,就从地址池里动态的取出一个外网 IP,并将他们的对应关系绑定到 NAT 表中,通信结束后,这个外网 IP 才被释放,可供其他内部 IP 地址转换使用。N 个公网 IP 对应 M 个内部 Ip, 不固定的一对一 IP 转换关系。同一时间,有 M-N 个主机无法联网;
(3)NAPT 是指将端口引入此技术中,即多台主机共用一个公网地址(多对一),利用这一个公网 IP 的不同端口与外部进行通信。
NAPT 从端口角度来说,分为两大类:锥型 NAT 和对称 NAT。其中锥型 NAT 又分为完全锥型、受限制锥型、端口受限制锥型三种。
(1)完全锥型(Full Cone):将从同一内部 IP 地址和端口来的所有请求,都映射到相同的外部 IP 地址和端口。而且,任何外部主机通过向映射的外部地址发送报文,可以实现和内部主机进行通信。这是一种比较宽松的策略,只要建立了内部网络的 IP 地址和端口与公网 IP 地址和端口的映射关系,则所有 Internet 上的主机都可以访问该 NAT 之后的主机,在图 7-1 中,完全锥型 NAT 会将内网地址 {X:y} (x 代表内网主机的 IP 地址,Y 代表端口) 映射成公网地址 {A:b}(A 代表映射的公网 IP 地址,b 代表映射的端口) 并绑定。任何数据分组都可以通过公网地址 {A:b} 送到此内网主机。
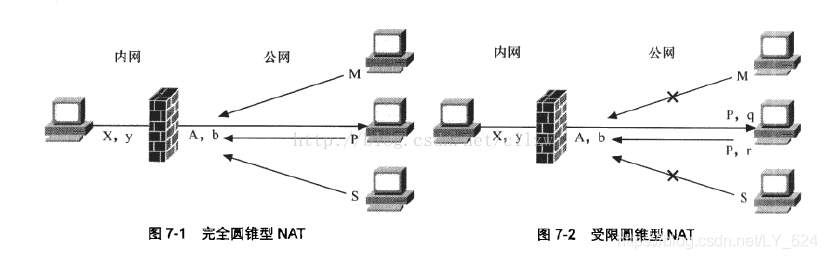
(2)受限制锥型(Restricted Cone):将从相同的内部 IP 地址和端口来的所有请求,映射到相同的公网 IP 地址和端口。但是与完全圆锥型 NAT 不同,当且仅当内网主机之前己经向公网主机 (假设 IP 地址为 P) 发送过分组,此公网主机才能够向内网主机发送分组。在图 7-2 中,受限制锥型 NAT 会将内网地址 {X:y} 映射成公网地址 {A:b〕并绑定,只有源地址为 P 的分组才能和此内网主机通信。
(3)端口受限制锥型(Port Restricted Cone):类似于受限圆锥型 NAT,但更严格。端口受限圆锥型 NAT 增加了端口号的限制,当且仅当内网主机之前已经向公网主机发送了分组,公网主机才能和此内网主机通信。在图 7-3 中,端口受限制圆锥型 NAT 会将内网地址 {X:y} 映射成公网地址 {A:b} 并绑定,由于内网主机之前己经分别与地址为 M, 端口为 n 的主机以及地址为 P, 端口为 q 的主机通信,所以只有来自这两个公网地址和端口的分组才能到达内网主机。
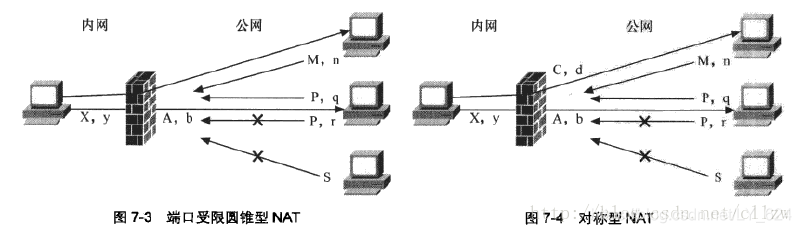
(4)对称(Sysmmetric):把从同一内网地址和端口到相同目的地址和端口的所有请求,都映射到同一个公网地址和端口。如果同一个内网主机,用相同的内网地址和端口向另一个目的地址发送分组,则会使用不同的映射,而且公网主机只有在接收到分组后,才能向与发送分组的内网主机进行通信。可见,对称 NAT 是所有 NAT 类型中限制最为严格的。 在图 7-4 中,对称型 NAT 会将内网地址 {X:y} 转换成公网地址 {A:b} 并绑定为 {X=Y}|{A:b}< 一 >{P:q}。这就意味着 NAT 只允许地址 {A:b} 接收来自 {P:q} 的分组,将它转给 {X:y} 。当客户机请求一个不同的公网地址 {M:n} 时,NAT 会新分配一个外部端口 {C:d}。
由上可见:安全性系数有,对称型 > 端口受限锥型 > 受限锥型 > 全锥型。
事实上,这些术语的引入是很多混淆的起源。现实中的很多 NAT 设备是将这些转换方式混合在一起工作的,而不单单使用一种,所以这些术语只适合描述一种工作方式,而不是一个设备。
比如,很多 NAT 设备对内部发出的连接使用对称型 NAT 方式,而同时支持静态的端口映射,后者可以被看作是全锥型 NAT 方式。而有些情况下,NAT 设备的一个公网地址和端口可以同时映射到内部几个服务器上以实现负载分担,比如一个对外提供 WEB 服务器的站点可能是有成百上千个服务器在提供 HTTP 服务,但是对外却表现为一个或少数几个 IP 地址。
2. 不同 NAT 的穿透性
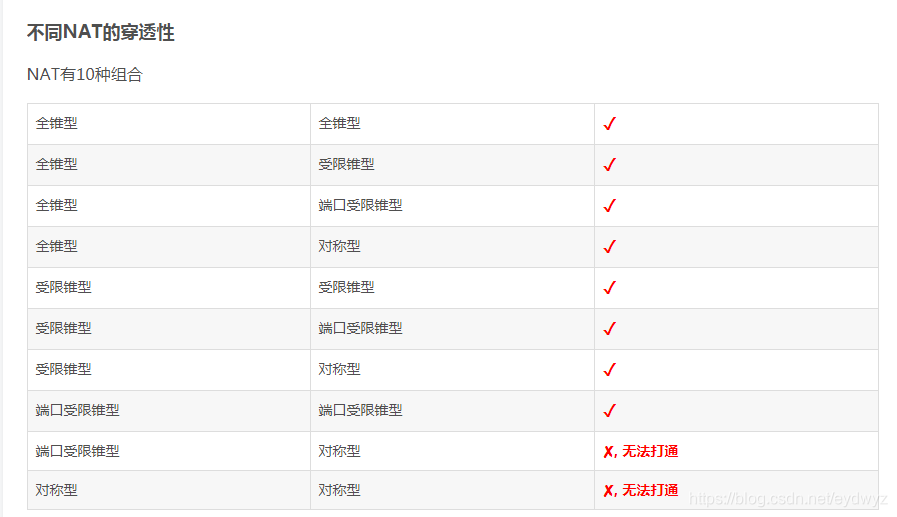
注:原文表格截图未体现 A 端、B 端,对应表格栏目 “
| NAT A 类型 | NAT B 类型 | 能否 udp 打洞 |”下文有完整表格。
3.UDP 打洞简单过程
client A 位于 NAT A 后,私网地址为 192.168.10.11
client B 位于 NAT B 后,私网地址为 192.168.20.22
(即两台客户机均置于两个不同的 NAT 网关后)
Server S 运行在公网中,公网地址为 300.30.30.30
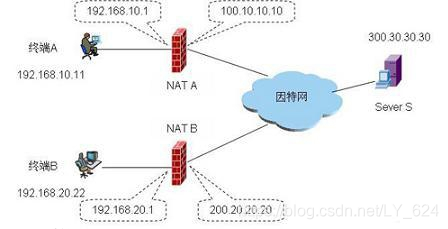
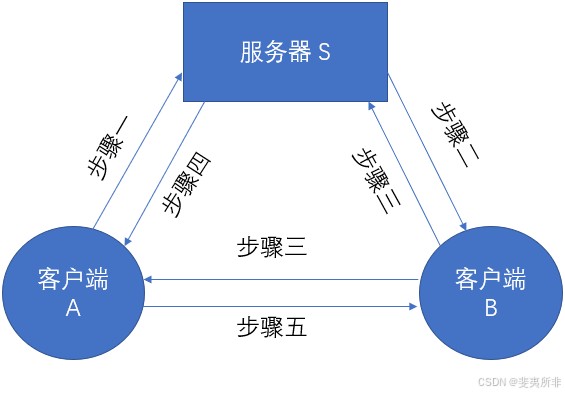
两个客户端 A 和 B 的通信,大致过程如下:
- Client A 请求 Server S,Server S 记录 Client A 的公网 IP:Port(即 100.10.10.10:Port1)
- Client B 请求 Server S,Server S 记录 Client B 的公网 IP:Port(即 200.20.20.20:Port2)
若 A 需要和 B 通信
步骤一:A 把连接 B 的请求发给 S
步骤二:S 把 A 的连接申请通知 B,并把 A 的公网 IP:Port 也告知 B
步骤三:B 对 A 的公网 IP:Port 进行打洞,且通知 S
步骤四:S 把 B 打洞消息通知 A,且把 B 的公网 IP:Port 也告知 A(即经过 S,让 A 信任 B)
步骤五:A 开始和 B 直接通信
上述过程如下图:
参考地址
上述所有,是在前人总结的基础上写来的,各位博友写的都很详细,所以拿来直接用,以备自己之后阅览,在此附上内容原博客地址。
1.NAT基本原理(链接已沉寂)
https://www.cnblogs.com/imstudy/p/5458133.html
2.NAT穿透原理与实现 - 被遗忘的曙光 技术博客
https://www.fdawn.com/Default/17.html
3.P2P网络中NAT穿透详解
https://blog.csdn.net/eydwyz/article/details/87364157
4.udp打洞简明步骤图解 - 小天1981 - 博客园
https://www.cnblogs.com/lzj1981/archive/2013/05/01/3053192.html
5.浅谈NAT的原理缺陷及其解决之道_不会被发现nat-CSDN博客
https://blog.csdn.net/xiaofei0859/article/details/6630451
P2P,UDP 和 TCP 穿透 NAT
chengweiv5于 2009-11-29 14:56:00 发布
1. NAT 简介
NAT(Network Address Translation ,网络地址转换) 是一种广泛应用的解决IP 短缺的
有效方法, NAT 将内网地址转和端口号换成合法的公网地址和端口号,建立一个会话,与公网主机进行通信。
1.1. NAT 分类
NAT 从表面上看有三种类型:静态 NAT 、动态地址 NAT 、地址端口转换 NAPT 。
(1)静态 NAT :静态地址转换将内部私网地址与合法公网地址进行一对一的转换,且每个内部地址的转换都是确定的。
(2)动态 NAT :动态地址转换也是将内部本地地址与内部合法地址一对一的转换,但是动态地址转换是从合法地址池中动态选择一个未使用的地址来对内部私有地址进行转换。
(3)NAPT :它也是一种动态转换,而且多个内部地址被转换成同一个合法公网地址,使用不同的端口号来区分不同的主机,不同的进程。
从实现的技术角度,又可以将 NAT 分成如下几类:全锥NAT(Full Cone NAT) 、限制性锥NAT (Restricted Cone NAT )、端口限制性锥NAT( Port Restricted Cone NAT) 、对称NAT ( Symmetric NAT) 。
(1)全锥 NAT :全锥NAT 把所有来自相同内部IP 地址和端口的请求映射到相同的外部IP 地址和端口。任何一个外部主机均可通过该映射发送数据包到该内部主机。
(2)限制性锥 NAT :限制性锥NAT 把所有来自相同内部 IP 地址和端口的请求映射到相同的外部IP 地址和端口。但是, 和全锥NAT 不同的是:只有当内部主机先给外部主机发送数据包, 该外部主机才能向该内部主机发送数据包。
(3)端口限制性锥 NAT :端口限制性锥 NAT 与限制性锥NAT 类似, 只是多了端口号的限制, 即只有内部主机先向外部地址:端口号对发送数据包, 该外部主机才能使用特定的端口号向内部主机发送数据包。
(4)对称 NAT :对称 NAT 与上述3 种类型都不同,不管是全锥 NAT ,限制性锥 NAT 还是端口限制性锥 NAT ,它们都属于锥NAT (Cone NAT )。当同一内部主机使用相同的端口与不同地址的外部主机进行通信时,对称NAT 会重新建立一个Session ,为这个Session 分配不同的端口号,或许还会改变IP 地址。
1.2. NAT 的作用
NAT 不仅实现地址转换,同时还起到防火墙的作用,隐藏内部网络的拓扑结构,保护内部主机。 NAT 不仅完美地解决了 lP 地址不足的问题,而且还能够有效地避免来自网络外部的攻击,隐藏并保护网络内部的计算机。 这样对于外部主机来说,内部主机是不可见的。但是,对于P2P 应用来说,却要求能够建立端到端的连接,所以如何穿透NAT 也是P2P 技术中的一个关键。
2. P2P 穿透NAT
要让处于NAT 设备之后的拥有私有IP 地址的主机之间建立P2P 连接,就必须想办法穿
透NAT ,现在常用的传输层协议主要有TCP 和UDP ,下面就是用这两种协议来介绍穿透NAT 的策略。
2.1. 网络拓扑结构
下面假设有如图1 所示网络拓扑结构图。
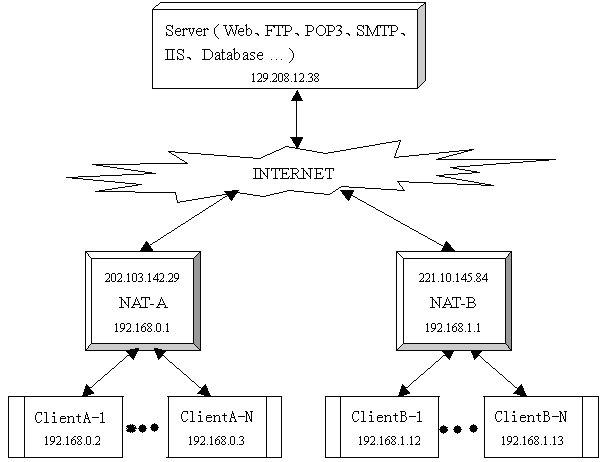
图1. 网络拓扑结构图
Server (129.208.12.38 )是公网上的服务器,NAT-A 和NAT-B 是两个NAT 设备(可能是集成NAT 功能的路由器,防火墙等),它们具有若干个合法公网IP ,在NAT-A 阻隔的私有网络中有若干台主机【ClientA-1 ,ClientA-N 】,在NAT-B 阻隔的私有网络中也有若干台主机【ClientB-1 ,ClientB-N 】。为了以后说明问题方便,只讨论主机ClientA-1 和ClientB-1 。
假设主机ClientA-1 和主机ClientB-1 都和服务器Server 建立了“连接”,如图2 所示。
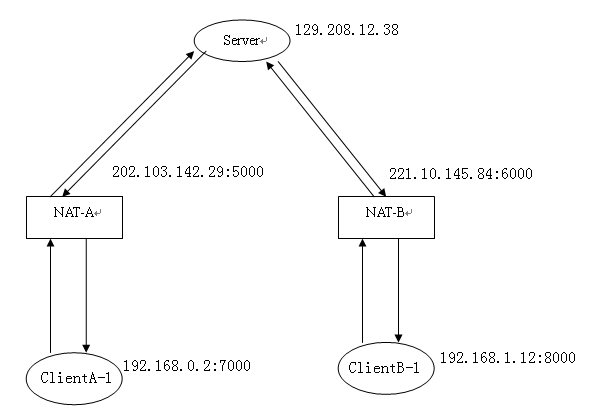
图2.ClientA-1 ,ClientB-1 和Server 之间通信
由于NAT 的透明性,所以ClientA-1 和ClientB-1 不用关心和Server 通信的过程,它们只需要知道Server 开放服务的地址和端口号即可。根据图1 ,假设在ClientA-1 中有进程使用socket (192.168.0.2 :7000 )和Server 通信,在ClientB-1 中有进程使用socket (192.168.1.12:8000 )和Server 通信。它们通过各自的NAT 转换后分别变成了socket (202.103.142.29 :5000 )和socket (221.10.145.84 :6000 )。
2.2. 使用 UDP 穿透 NAT
通常情况下,当进程使用UDP 和外部主机通信时,NAT 会建立一个Session ,这个Session 能够保留多久并没有标准,或许几秒,几分钟,几个小时。假设ClientA-1 在应用程序中看到了ClientB-1 在线,并且想和ClientB-1 通信,一种办法是Server 作为中间人,负责转发ClientA-1 和ClientB-1 之间的消息,但是这样服务器太累,会吃不消。另一种方法就是让ClientA-1 何ClientB-1 建立端到端的连接,然后他们自己通信。这也就是P2P 连接。根据不同类型的NAT ,下面分别讲解。
(1 )全锥NAT ,穿透全锥型NAT 很容易,根本称不上穿透,因为全锥型NAT 将内部主机的映射到确定的地址,不会阻止从外部发送的连接请求,所以可以不用任何辅助手段就可以建立连接。
(2 )限制性锥NAT 和端口限制性锥NAT (简称限制性NAT ),穿透限制性锥NAT 会丢弃它未知的源地址发向内部主机的数据包。所以如果现在ClientA-1 直接发送UDP 数据包到ClientB-1 ,那么数据包将会被NAT-B 无情的丢弃。所以采用下面的方法来建立ClientA-1 和ClientB-1 之间的通信。
1 .ClientA-1 (202.103.142.29:5000 )发送数据包给Server ,请求和ClientB-1 (221.10.145.84:6000 )通信。
2. Server 将ClientA-1 的地址和端口(202.103.142.29:5000 )发送给ClientB-1 ,告诉ClientB-1 ,ClientA-1 想和它通信。
3. ClientB-1 向ClientA-1 (202.103.142.29:5000 )发送UDP 数据包,当然这个包在到达NAT-A 的时候,还是会被丢弃,这并不是关键的,因为发送这个UDP 包只是为了让NAT-B 记住这次通信的目的地址:端口号,当下次以这个地址和端口为源的数据到达的时候就不会被NAT-B 丢弃,这样就在NAT-B 上打了一个从ClientB-1 到ClientA-1 的孔。
4. 为了让ClientA-1 知道什么时候才可以向ClientB-1 发送数据,所以ClientB-1 在向ClientA-1 (202.103.142.29:5000 )打孔之后还要向Server 发送一个消息,告诉Server 它已经准备好了。
5. Server 发送一个消息给ClientA-1 ,内容为:ClientB-1 已经准备好了,你可以向ClientB-1 发送消息了。
6. ClientA-1 向ClientB-1 发送UDP 数据包。这个数据包不会被NAT-B 丢弃,以后ClientB-1 向ClientA-1 发送的数据包也不会被ClientA-1 丢弃,因为NAT-A 已经知道是ClientA-1 首先发起的通信。至此,ClientA-1 和ClientB-1 就可以进行通信了。
2.3. 使用TCP 穿透 NAT
使用TCP 协议穿透NAT 的方式和使用UDP 协议穿透NAT 的方式几乎一样,没有什么本质上的区别,只是将无连接的UDP 变成了面向连接的TCP 。值得注意是:
1. ClientB-1 在向ClientA-1 打孔时,发送的SYN 数据包,而且同样会被NAT-A 丢弃。同时,ClientB-1 需要在原来的socket 上监听,由于重用socket ,所以需要将socket 属性设置为SO_REUSEADDR 。
2. ClientA-1 向ClientB-1 发送连接请求。同样,由于ClientB-1 到ClientA-1 方向的孔已经打好,所以连接会成功,经过3 次握手后,ClientA-1 到ClientB-1 之间的连接就建立起来了。
2.4. 穿透对称 NAT
上面讨论的都是怎样穿透锥(Cone )NAT ,对称NAT 和锥NAT 很不一样。对于 对称NAT ,当一个私网内主机和外部多个不同主机通信时,对称NAT 并不会像锥(Cone ,全锥,限制性锥,端口限制性锥)NAT 那样分配同一个端口。而是会新建立一个Session ,重新分配一个端口。参考上面穿透限制性锥NAT 的过程,在步骤3 时:ClientB-1 (221.10.145.84: ?)向ClientA-1 打孔的时候,对称NAT 将给ClientB-1 重新分配一个端口号,而这个端口号对于Server 、ClientB-1 、ClientA-1 来说都是未知的。同样, ClientA-1 根本不会收到这个消息,同时在步骤4 ,ClientB-1 发送给Server 的通知消息中,ClientB-1 的socket 依旧是(221.10.145.84:6000 )。而且,在步骤6 时:ClientA-1 向它所知道但错误的ClientB-1 发送数据包时,NAT-1 也会重新给ClientA-1 分配端口号。所以,穿透对称NAT 的机会很小。下面是两种有可能穿透对称NAT 的策略。
2.4.1 同时开放TCP ( Simultaneous TCP open)策略
如果一个 对称 NAT 接收到一个来自 本地 私有网 络 外面的 TCP SYN 包, 这 个包想 发 起一个 “ 引入*”* 的 TCP 连 接,一般来 说 , NAT 会拒 绝这 个 连 接 请 求并扔掉 这 个 SYN 包,或者回送一个TCP RST (connection reset ,重建 连 接)包 给请 求方。但是,有一 种 情况 却会接受这个“引入”连接。
RFC 规定:对于对称NAT , 当 这 个接收到的 SYN 包中的源IP 地址 : 端口、目 标 IP 地址 : 端口都与NAT 登 记 的一个已 经 激活的 TCP 会 话 中的地址信息相符 时 , NAT 将会放行 这 个 SYN 包。 需要 特 别 指出 的是:怎样才是一个已经激活的TCP 连接?除了真正已经建立完成的TCP 连接外,RFC 规范指出: 如果 NAT 恰好看到一个 刚刚发 送出去的一个 SYN 包和 随之 接收到的SYN 包中的地址 :端口 信息相符合的 话 ,那 么 NAT 将会 认为这 个 TCP 连 接已 经 被激活,并将允 许这 个方向的 SYN 包 进 入 NAT 内部。 同时开放TCP 策略就是利用这个时机来建立连接的。
如果 Client A -1 和 Client B -1 能 够 彼此正确的 预 知 对 方的 NAT 将会 给 下一个 TCP 连 接分配的公网 TCP 端口,并且两个客 户 端能 够 同 时 地 发 起一 个面向对方的 “ 外出 ” 的 TCP 连 接 请求 ,并在 对 方的 SYN 包到达之前,自己 刚发 送出去的 SYN 包都能 顺 利的穿 过 自己的 NAT 的 话 ,一条端 对 端的 TCP 连 接就 能 成功地建立了 。
2.4.2 UDP 端口猜测策略
同时开放TCP 策略非常依赖于猜测对方的下一个端口,而且强烈依赖于发送连接请求的时机,而且还有网络的不确定性,所以能够建立的机会很小,即使Server 充当同步时钟的角色。下面是一种通过UDP 穿透的方法,由于UDP 不需要建立连接,所以也就不需要考虑“同时开放”的问题。
为了介绍ClientB-1 的诡计,先介绍一下STUN 协议。STUN (Simple Traversal of UDP Through NATs )协议是一个轻量级协议,用来探测被NAT 映射后的地址:端口。STUN 采用C/S 结构,需要探测自己被NAT 转换后的地址:端口的Client 向Server 发送请求,Server 返回Client 转换后的地址:端口。
参考4.2 节中穿透NAT 的步骤2 ,当ClientB-1 收到Server 发送给它的消息后,ClientB-1 即打开3 个socket 。socket-0 向STUN Server 发送请求,收到回复后,假设得知它被转换后的地址:端口( 221.10.145.84:600 5 ),socket-1 向ClientA-1 发送一个UDP 包,socket-2 再次向另一个STUN Server 发送请求,假设得到它被转换后的地址:端口( 221.10.145.84:60 20 )。通常,对称NAT 分配端口有两种策略,一种是按顺序增加,一种是随机分配。如果这里对称NAT 使用顺序增加策略,那么,ClientB-1 将两次收到的地址:端口发送给Server 后,Server 就可以通知ClientA-1 在这个端口范围内猜测刚才ClientB-1 发送给它的socket-1 中被NAT 映射后的地址:端口,ClientA-1 很有可能在孔有效期内成功猜测到端口号,从而和ClientB-1 成功通信。
2.4.3 问题总结
从上面两种穿透对称NAT 的方法来看,都建立在了严格的假设条件下。但是现实中多数的NAT 都是锥NAT ,因为资源毕竟很重要,反观对称NAT ,由于太不节约端口号所以相对来说成本较高。所以,不管是穿透锥NAT ,还是对称NAT ,现实中都是可以办到的。除非对称NAT 真的使用随机算法来分配可用的端口。
用 TCP 穿透 NAT(TCP 打洞)的实现
AAA20090987于 2013-04-17 17:23:38 发布
1. TCP 穿透原理
我们假设在两个不同的局域网后面分别有 2 台客户机 A 和 B,AB 所在的局域网都分别通过一个路由器接入互联网。互联网上有一台服务器 S。
现在 AB 是无法直接和对方发送信息的,AB 都不知道对方在互联网上真正的 IP 和端口, AB 所在的局域网的路由器只允许内部向外主动发送的信息通过。对于 B 直接发送给 A 的路由器的消息,路由会认为其 “不被信任” 而直接丢弃。
要实现 AB 直接的通讯,就必须进行以下 3 步:A 首先连接互联网上的服务器 S 并发送一条消息(对于 UDP 这种无连接的协议其实直接初始会话发送消息即可),这样 S 就获取了 A 在互联网上的实际终端(发送消息的 IP 和端口号)。接着 B 也进行同样的步骤,S 就知道了 AB 在互联网上的终端(这就是 “打洞”)。接着 S 分别告诉 A 和 B 对方客户端在互联网上的实际终端,也即 S 告诉 A 客户 B 的会话终端,S 告诉 B 客户 A 的会话终端。这样,在 AB 都知道了对方的实际终端之后,就可以直接通过实际终端发送消息了(因为先前双方都向外发送过消息,路由上已经有允许数据进出的消息通道)。
2. 程序思路
1:启动服务器,监听端口 8877
2:第一次启动客户端(称为 client1),连上服务器,服务器将返回字符串 first,标识这个是 client1,同时,服务器将记录下这个客户端的(经过转换之后的)IP 和端口。
3:第二次启动客户端(称为 client2),连上服务器,服务器将向其返回自身的发送端口(称为 port2),以及 client1 的(经过转换之后的)IP 和端口。
4:然后服务器再发 client1 返回 client2(经过转换之后的)IP 和端口,然后断开与这两个客户端的连接(此时,服务器的工作已经全部完成了)
5:client2 尝试连接 client1,这次肯定会失败,但它会在路由器上留下记录,以帮忙 client1 成功穿透,连接上自己,然后设置 port2 端口为可重用端口,并监听端口 port2。
6:client1 尝试去连接 client2,前几次可能会失败,因为穿透还没成功,如果连接 10 次都失败,就证明穿透失败了(可能是硬件不支持), 如果成功,则每秒向 client2 发送一次 hello, world
7:如果 client1 不断出现 send message: Hello, world,client2 不断出现 recv message: Hello, world,则证明实验成功了,否则就是失败了。
3. 声明
1:这个程序只是一个 DEMO,所以肯定有很多不完善的地方,请大家多多见谅。
2:在很多网络中,这个程序并不能打洞成功,可能是硬件的问题(毕竟不是每种路由器都支持穿透),也可能是我程序的问题,如果大家有意见或建议,欢迎留言或给我发邮件(邮箱是:[email protected])
4. 上代码:
服务器端:
/*
文件:server.c
PS:第一个连接上服务器的客户端,称为client1,第二个连接上服务器的客户端称为client2
这个服务器的功能是:
1:对于client1,它返回"first",并在client2连接上之后,将client2经过转换后的IP和port发给client1;
2:对于client2,它返回client1经过转换后的IP和port和自身的port,并在随后断开与他们的连接。
*/
#include <stdio.h>
#include <unistd.h>
#include <signal.h>
#include <sys/socket.h>
#include <fcntl.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
#include <arpa/inet.h>
#define MAXLINE 128
#define SERV_PORT 8877
//发生了致命错误,退出程序
void error_quit(const char *str)
{
fprintf(stderr, "%s", str);
//如果设置了错误号,就输入出错原因
if( errno != 0 )
fprintf(stderr, " : %s", strerror(errno));
printf("\n");
exit(1);
}
int main(void)
{
int i, res, cur_port;
int connfd, firstfd, listenfd;
int count = 0;
char str_ip[MAXLINE]; //缓存IP地址
char cur_inf[MAXLINE]; //当前的连接信息[IP+port]
char first_inf[MAXLINE]; //第一个链接的信息[IP+port]
char buffer[MAXLINE]; //临时发送缓冲区
socklen_t clilen;
struct sockaddr_in cliaddr;
struct sockaddr_in servaddr;
//创建用于监听TCP协议套接字
listenfd = socket(AF_INET, SOCK_STREAM, 0);
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
servaddr.sin_port = htons(SERV_PORT);
//把socket和socket地址结构联系起来
res = bind(listenfd, (struct sockaddr *)&servaddr, sizeof(servaddr));
if( -1 == res )
error_quit("bind error");
//开始监听端口
res = listen(listenfd, INADDR_ANY);
if( -1 == res )
error_quit("listen error");
while( 1 )
{
//接收来自客户端的连接
connfd = accept(listenfd,(struct sockaddr *)&cliaddr, &clilen);
if( -1 == connfd )
error_quit("accept error");
inet_ntop(AF_INET, (void*)&cliaddr.sin_addr, str_ip, sizeof(str_ip));
count++;
//对于第一个链接,将其的IP+port存储到first_inf中,
//并和它建立长链接,然后向它发送字符串'first',
if( count == 1 )
{
firstfd = connfd;
cur_port = ntohs(cliaddr.sin_port);
snprintf(first_inf, MAXLINE, "%s %d", str_ip, cur_port);
strcpy(cur_inf, "first\n");
write(connfd, cur_inf, strlen(cur_inf)+1);
}
//对于第二个链接,将其的IP+port发送给第一个链接,
//将第一个链接的信息和他自身的port返回给它自己,
//然后断开两个链接,并重置计数器
else if( count == 2 )
{
cur_port = ntohs(cliaddr.sin_port);
snprintf(cur_inf, MAXLINE, "%s %d\n", str_ip, cur_port);
snprintf(buffer, MAXLINE, "%s %d\n", first_inf, cur_port);
write(connfd, buffer, strlen(buffer)+1);
write(firstfd, cur_inf, strlen(cur_inf)+1);
close(connfd);
close(firstfd);
count = 0;
}
//如果程序运行到这里,那肯定是出错了
else
error_quit("Bad required");
}
return 0;
}
客户端:
/*
文件:client.c
PS:第一个连接上服务器的客户端,称为client1,第二个连接上服务器的客户端称为client2
这个程序的功能是:先连接上服务器,根据服务器的返回决定它是client1还是client2,
若是client1,它就从服务器上得到client2的IP和Port,连接上client2,
若是client2,它就从服务器上得到client1的IP和Port和自身经转换后的port,
在尝试连接了一下client1后(这个操作会失败),然后根据服务器返回的port进行监听。
这样以后,就能在两个客户端之间进行点对点通信了。
*/
#include <stdio.h>
#include <unistd.h>
#include <signal.h>
#include <sys/socket.h>
#include <fcntl.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
#include <arpa/inet.h>
#define MAXLINE 128
#define SERV_PORT 8877
typedef struct
{
char ip[32];
int port;
}server;
//发生了致命错误,退出程序
void error_quit(const char *str)
{
fprintf(stderr, "%s", str);
//如果设置了错误号,就输入出错原因
if( errno != 0 )
fprintf(stderr, " : %s", strerror(errno));
printf("\n");
exit(1);
}
int main(int argc, char **argv)
{
int i, res, port;
int connfd, sockfd, listenfd;
unsigned int value = 1;
char buffer[MAXLINE];
socklen_t clilen;
struct sockaddr_in servaddr, sockaddr, connaddr;
server other;
if( argc != 2 )
error_quit("Using: ./client <IP Address>");
//创建用于链接(主服务器)的套接字
sockfd = socket(AF_INET, SOCK_STREAM, 0);
memset(&sockaddr, 0, sizeof(sockaddr));
sockaddr.sin_family = AF_INET;
sockaddr.sin_addr.s_addr = htonl(INADDR_ANY);
sockaddr.sin_port = htons(SERV_PORT);
inet_pton(AF_INET, argv[1], &sockaddr.sin_addr);
//设置端口可以被重用
setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &value, sizeof(value));
//连接主服务器
res = connect(sockfd, (struct sockaddr *)&sockaddr, sizeof(sockaddr));
if( res < 0 )
error_quit("connect error");
//从主服务器中读取出信息
res = read(sockfd, buffer, MAXLINE);
if( res < 0 )
error_quit("read error");
printf("Get: %s", buffer);
//若服务器返回的是first,则证明是第一个客户端
if( 'f' == buffer[0] )
{
//从服务器中读取第二个客户端的IP+port
res = read(sockfd, buffer, MAXLINE);
sscanf(buffer, "%s %d", other.ip, &other.port);
printf("ff: %s %d\n", other.ip, other.port);
//创建用于的套接字
connfd = socket(AF_INET, SOCK_STREAM, 0);
memset(&connaddr, 0, sizeof(connaddr));
connaddr.sin_family = AF_INET;
connaddr.sin_addr.s_addr = htonl(INADDR_ANY);
connaddr.sin_port = htons(other.port);
inet_pton(AF_INET, other.ip, &connaddr.sin_addr);
//尝试去连接第二个客户端,前几次可能会失败,因为穿透还没成功,
//如果连接10次都失败,就证明穿透失败了(可能是硬件不支持)
while( 1 )
{
static int j = 1;
res = connect(connfd, (struct sockaddr *)&connaddr, sizeof(connaddr));
if( res == -1 )
{
if( j >= 10 )
error_quit("can't connect to the other client\n");
printf("connect error, try again. %d\n", j++);
sleep(1);
}
else
break;
}
strcpy(buffer, "Hello, world\n");
//连接成功后,每隔一秒钟向对方(客户端2)发送一句hello, world
while( 1 )
{
res = write(connfd, buffer, strlen(buffer)+1);
if( res <= 0 )
error_quit("write error");
printf("send message: %s", buffer);
sleep(1);
}
}
//第二个客户端的行为
else
{
//从主服务器返回的信息中取出客户端1的IP+port和自己公网映射后的port
sscanf(buffer, "%s %d %d", other.ip, &other.port, &port);
//创建用于TCP协议的套接字
sockfd = socket(AF_INET, SOCK_STREAM, 0);
memset(&connaddr, 0, sizeof(connaddr));
connaddr.sin_family = AF_INET;
connaddr.sin_addr.s_addr = htonl(INADDR_ANY);
connaddr.sin_port = htons(other.port);
inet_pton(AF_INET, other.ip, &connaddr.sin_addr);
//设置端口重用
setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &value, sizeof(value));
//尝试连接客户端1,肯定会失败,但它会在路由器上留下记录,
//以帮忙客户端1成功穿透,连接上自己
res = connect(sockfd, (struct sockaddr *)&connaddr, sizeof(connaddr));
if( res < 0 )
printf("connect error\n");
//创建用于监听的套接字
listenfd = socket(AF_INET, SOCK_STREAM, 0);
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
servaddr.sin_port = htons(port);
//设置端口重用
setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &value, sizeof(value));
//把socket和socket地址结构联系起来
res = bind(listenfd, (struct sockaddr *)&servaddr, sizeof(servaddr));
if( -1 == res )
error_quit("bind error");
//开始监听端口
res = listen(listenfd, INADDR_ANY);
if( -1 == res )
error_quit("listen error");
while( 1 )
{
//接收来自客户端1的连接
connfd = accept(listenfd,(struct sockaddr *)&sockaddr, &clilen);
if( -1 == connfd )
error_quit("accept error");
while( 1 )
{
//循环读取来自于客户端1的信息
res = read(connfd, buffer, MAXLINE);
if( res <= 0 )
error_quit("read error");
printf("recv message: %s", buffer);
}
close(connfd);
}
}
return 0;
}
5. 运行示例:
第一个终端
qch@qch ~/program/tcode $ gcc server.c -o server
qch@qch ~/program/tcode $ ./server &
[1] 4688
qch@qch ~/program/tcode $ gcc client.c -o client
qch@qch ~/program/tcode $ ./client localhost
Get: first
ff: 127.0.0.1 38052
send message: Hello, world
send message: Hello, world
send message: Hello, world
.................
第二个终端:
qch@qch ~/program/tcode $ ./client localhost
Get: 127.0.0.1 38073 38074
connect error
recv message: Hello, world
recv message: Hello, world
recv message: Hello, world
..................
NAT 打洞(udp 打洞和 tcp 打洞)
coding_myway 于 2015-09-16 17:59:44 发布
UDP 打洞
对于两个 peer,A 和 B。
1、若 A 和 B 位于同一个 nat 之后。如果 nat 支持回环转换,A 和 B 之间打洞时使用彼此的外网地址是可以连通的。但是最好是优先尝试内网连接。
2、若 A 和 B 位于不同的 nat 之后。若两个 nat 都是公网地址,则属于 “典型” 连接过程,连接相对简单可靠。
3、若 A 和 B 位于多级 nat 之后。
a) A 和 B 有相同的出口 nat。则使用内网地址连接,可能会存在明显错误(需要鉴别)。若顶级 nat 不支持回环转换,则连接会失败。
b) A 和 B 在不同的出口 nat 后。则过程类似情况 2。
4、若 A 和 B 只有一方在 nat 之后。利用反向连接的方法完成。(也可以采用 tcp 协议连接)。
连接过程:
依据 stun 协议鉴别出的 nat 类型,采取合适的连接过程。
两个 nat4 之后的 peer 仍然无法直接完成连接,有需要时可采用 TURN 协议建立 “连接”(通过中继完成的通信)。
重要问题:
udp 会经常收到非预期的数据包,所以需要做过滤和鉴别。比如,双方连接时,需要从服务器拿到相同的令牌,数据包提交了这个令牌才认为是有效的。
TCP 打洞
tcp 打洞也需要 NAT 设备支持才行。
tcp 的打洞流程和 udp 的基本一样,但 tcp 的 api 决定了 tcp 打洞的实现过程和 udp 不一样。
tcp 按 cs 方式工作,一个端口只能用来 connect 或 listen,所以需要使用端口重用,才能利用本地 nat 的端口映射关系。(设置 SO_REUSEADDR,在支持 SO_REUSEPORT 的系统上,要设置这两个参数。)
连接过程:(以 udp 打洞的第 2 种情况为例(典型情况))
nat 后的两个 peer,A 和 B,A 和 B 都 bind 自己 listen 的端口,向对方发起连接(connect),即使用相同的端口同时连接和等待连接。因为 A 和 B 发出连接的顺序有时间差,假设 A 的 syn 包到达 B 的 nat 时,B 的 syn 包还没有发出,那么 B 的 nat 映射还没有建立,会导致 A 的连接请求失败(连接失败或无法连接,如果 nat 返回 RST 或者 icmp 差错,api 上可能表现为被 RST;有些 nat 不返回信息直接丢弃 syn 包(反而更好)),(应用程序发现失败时,不能关闭 socket,closesocket()可能会导致 NAT 删除端口映射;隔一段时间(1-2s)后未连接还要继续尝试);但后发 B 的 syn 包在到达 A 的 nat 时,由于 A 的 nat 已经建立的映射关系,B 的 syn 包会通过 A 的 nat,被 nat 转给 A 的 listen 端口,从而进去三次握手,完成 tcp 连接。
从应用程序角度看,连接成功的过程可能有两种不同表现:(以上述假设过程为例)
1、连接建立成功表现为 A 的 connect 返回成功。即 A 端以 TCP 的同时打开流程完成连接。
2、A 端通过 listen 的端口完成和 B 的握手,而 connect 尝试持续失败,应用程序通过 accept 获取到连接,最终放弃 connect(这时可 closesocket (conn_fd))。
多数 Linux 和 Windows 的协议栈表现为第 2 种。
但有一个问题是,建立连接的 client 端,其 connect 绑定的端口号就是主机 listen 的端口号,或许这个 peer 后续还会有更多的这种 socket。虽然理论上说,socket 是一个五元组,端口号是一个逻辑数字,传输层能够因为五元组的不同而区分开这些 socket,但是是否存在实际上的异常,还有待更多观察。
另外的问题:
Windows XP SP2 操作系统之前的主机,这些主机不能正确处理 TCP 同时开启,或者 TCP 套接字不支持 SO_REUSEADDR 的参数。需要让 AB 有序的发起连接才可能完成。
上述 tcp 连接过程,仅对 NAT1、2、3 有效,对 NAT4(对称型)无效。
由于对称型 nat 通常采用规律的外部端口分配方法,对于 nat4 的打洞,可以采用端口预测的方式进行尝试。
基于 TCP/UDP 的 P2P 网络通信协议研究与实现
连志安的博客于 2019-11-21 19:57:20 发布
摘 要
对等式网络(peer-to-peer,简称 P2P),又称点对点技术,是一种实现网络中不同主机直接通信的技术。在物联网的应用中,大量的设备需要能进行点对点的通信。但如今的互联网中存在着一些中间件,如 NAT 和防火墙,导致两个不在同一内网的客户端无法直接通信。本文讨论如何跨越 NAT 实现网络中的主机直接通信的问题,研究与实现基于 TCP/UDP 的 P2P 网络通信协议。
关键词:P2P,点对点,网络通信,NAT
第 1 章 前言
P2P 是(Peer to Peer)的缩写,在计算机网络通信中 P2P 是相对于服务器 / 客户端模式而言的,通常的服务器 / 客户端模式下有一台强大的服务器接受大量的客户端的连接。当客户端之间需要通信的时候需要经由服务器转发。这种模式当客户端规模扩展到一定程度时对于服务器的 CPU 处理能力、带宽都是很大的考验。P2P 技术可以让客户端之间直接通信,实现所谓的端到端(P2P)直接通信,此时中心服务器的负荷明显降低。随着物联网的兴起,大量设备的接入,网络通信的需求越来越大,传统的服务器 / 客户端模式已经很难满足需求。P2P 技术为万物互联的概念提供了关键的技术基础。
第 2 章 常见的几种 中间件
本章将介绍 P2P 通信网络中的各种中间件,以及它们在整个网络通信过程中起的作用。
2.1 防火墙(Firewall)
防火墙技术是通过有机结合各类用于安全管理与筛选的软件和硬件设备,帮助计算机网络于其内、外网之间构建一道相对隔绝的防护屏障,用以保护用户资料和信息安全性的一种技术。
防火墙主要限制内网和公网的通信,通常会丢弃未经许可的数据包。防火墙会检测试图进入内网数据包的 IP 地址和端口号信息。
2.2 网络地址转换器(NAT)
NAT 最初定义在 RFC1631,用在接入广域网中,通过修改 IP 报文的地址信息,实现将内部网络的私有 IP 地址到外部网络的公有 IP 地址的转换。私有 IP 地址是指内部网络或主机的 IP 地址,公有 IP 地址是指在因特网上全球唯一的 IP 地址。
如图 2-1 显示:
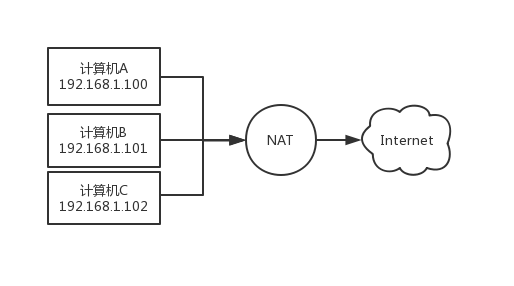
图 2-1 NAT 数据传输过程
1.计算机 A 要连接 Internet 时,数据包会先发送给 NAT 主机,此时数据包的 Header 的 sourceIP(源 IP)为 192.168.1.100
2.NAT 主机接收到这个数据包的时候,会将计算机 A 对外发送的数据包的 sourceIP(192.168.1.100)修改成 ppp0 这个接口所具有的公共 IP。因为是公共 IP 这个数据包就可以连上 Internet 了,同时 NAT 会记下这个数据包是由哪个(192.168.1.100)计算机发送过来的。
3.由 Internet 传送回来的数据包,也会经过 NAT,这个时候 NAT 主机会查询原本记录的路由信息,并将 IP 由 ppp0 上面的公共 IP 改回原来的 192.168.1.100
4.最后由 NAT 将该数据包传送给原先的计算机 A(192.168.1.100)
2.3 基本 NAT
基本 NAT 会将内网主机的 IP 地址映射为一个公网 IP,不改变其 TCP/UDP 端口号。基本 NAT 通常只有 NAT 有公网 IP 池的时候才会起作用。
2.4 网络地址 - 端口转换器(NAPT)
目前为止最常见的是 NAPT,会检测并修改出入数据包的 IP 和端口号,从而允许内网多个主机共享同一个公网 IP。
2.5 锥形 NAT(Cone NAT)
在建立一对(公网 IP,公网端口号 和 内网 IP、内网端口号)二元组的绑定后,Cone NAT 会重用这组绑定用于接下里该应用程序的所有会话(同一个内网 IP 和端口号),只要有一个会话还是激活状态的。
2.6 对称 NAT(Cone NAT)
对称 NAT 正好相反,不在所有公网 - 内网对的会话中维持一个固定的端口绑定。其为每个新的会话开辟一个新的端口。
第 3 章 常见的几种 P2P 技术实现方式
根据客户端的不同,本章将介绍现有的 P2P 通信的几种技术实现方式。
3.1 中继(Relaying)
技术原理
中继技术是目前最靠谱也是最简单的一种 P2P 通信实现技术。原理是通过一个有公网 IP 的服务器,对两个内网的客户端数据进行中继转发。如图 3-1 所示:
图 3-1 中继架构图
客户端 A 和客户端 B 不直接通信,而是先通过服务器 S 建立链接。客户端 A 把数据发送给服务器 S,再由服务器 S 将数据转发给客户端 B。
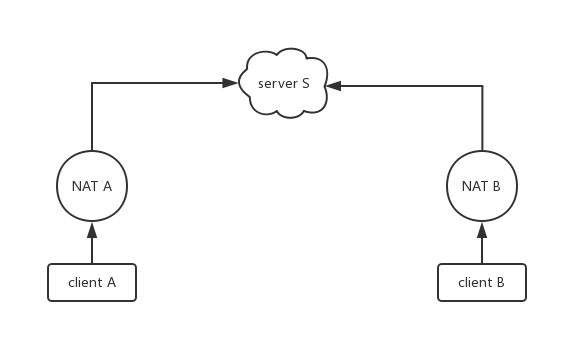
很明显,当链接的客户端变多了之后,会显著增加服务器的负担,完全没有体现出 P2P 的优势。
3.2 UDP 打洞(UDP hole punching)
3.2.1 技术原理
UDP 打洞是被广泛采用的 P2P 通信技术,也称之为 “P2P 打洞”。UDP 打洞技术依赖于通常防火墙和 cone NAT 允许正当的 P2P 应用程序在中间件中打洞且与对方建立直接链接的特性。
以下主要考虑两种常见的场景,以及应用程序如何设计去完美地处理这些情况。第一种场景代表了大多数情况,即两个需要直接链接的客户端处在两个不同的 NAT 之后;第二种场景是两个客户端在同一个 NAT 之后,但客户端自己并不需要知道。
3.2.2 端点在不同的 NAT 之下
假设客户端 A 和客户端 B 的地址都是内网地址,且在不同的 NAT 下。A、B 上运行的 P2P 应用程序和服务器 S 都使用了 UDP 端口 8888,A 和 B 分别初始化了与 Server 的 UDP 通信,地址映射如图 3-2 所示:
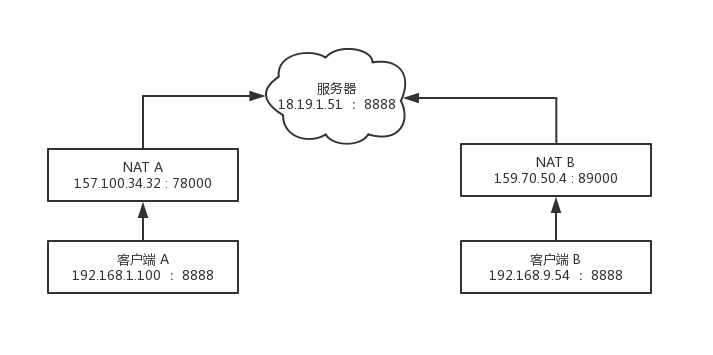
图 3-2 不同的 NAT
1.NAT A 将 客户端 A 的 IP 地址、端口号映射为 公网 IP(157.100.34.32 : 7800)。NAT B 将客户端 B 的 IP 地址、端口号映射为 公网 IP(159.70.50.4:8900)。
2.假设此时客户端 A 打算与客户端 B 建立一个 UDP 的通信会话。此时客户端 A 直接往客户端 B 的公网地址 159.70.50.4:8900 送 UDP 数据,NAT B 将很可能会无视进入的数据(除非是 Full Cone NAT),因为源地址和端口与 S 不匹配,而最初只与 S 建立过会话。B 往 A 直接发信息也类似。
3.假设 A 开始给 B 的公网地址发送 UDP 数据的同时,给服务器 S 发送一个中继请求,要求 B 开始给 A 的公网地址发送 UDP 信息。A 往 B 的输出信息会导致 NAT A 打开一个 A 的内网地址与与 B 的外网地址之间的新通讯会话,B 往 A 亦然。一旦新的 UDP 会话在两个方向都打开之后,客户端 A 和客户端 B 就能直接通讯,而无须再通过引导服务器 S 了。
4.UDP 打洞技术有许多有用的性质。一旦一个的 P2P 链接建立,链接的双方都能反过来作为 “引导服务器” 来帮助其他中间件后的客户端进行打洞,极大减少了服务器的负载。应用程序不需要知道中间件具体是什么(如果有的话),因为以上的过程在没有中间件或者有多个中间件的情况下也一样能建立通信链路。
3.2.3 端点在相同的 NAT 之下
现在考虑这样一种情景,两个客户端 A 和 B 正好在同一个 NAT 之后(而且可能他们自己并不知道),因此在同一个内网网段之内。客户端 A 和服务器 S 建立了一个 UDP 会话,NAT 为此分配了公网端口 62000,B 同样和 S 建立会话,分配到了端口 62001,如下图:

图 3-2 相同的 NAT
假设 A 和 B 使用了上节介绍的 UDP 打洞技术来建立 P2P 通路。首先 A 和 B 会得到由 S 观测到的对方的公网 IP 和端口号,然后给对方的地址发送信息。两个客户端只有在 NAT 允许内网主机对内网其他主机发起 UDP 会话的时候才能正常通信,我们把这种情况称之为 " 回环传输 “(lookback translation),因为从内部到达 NAT 的数据会被 “回送” 到内网中而不是转发到外网。例如,当 A 发送一个 UDP 数据包给 B 的公网地址时,数据包最初有源 IP 地址和端口地址 10.0.0.1:1234 和目的地址 155.99.25.11:62001,NAT 收到包后,将其转换为源 155.99.25.11:62000(A 的公网地址)和目的 10.1.1.3:1234,然后再转发给 B。即便 NAT 支持回环传输,这种转换和转发在此情况下也是没必要的,且有可能会增加 A 与 B 的对话延时和加重 NAT 的负担。
对于这个问题,解决方案是很直观的。当 A 和 B 最初通过 S 交换地址信息时,他们应该包含自身的 IP 地址和端口号(从自己看),同时也包含从服务器看的自己的地址和端口号。然后客户端同时开始从对方已知的两个的地址中同时开始互相发送数据,并使用第一个成功通信的地址作为对方地址。如果两个客户端在同一个 NAT 后,发送到对方内网地址的数据最有可能先到达,从而可以建立一条不经过 NAT 的通信链路;如果两个客户端在不同的 NAT 之后,发送给对方内网地址的数据包根本就到达不了对方,但仍然可以通过公网地址来建立通路。值得一提的是,虽然这些数据包通过某种方式验证,但是在不同 NAT 的情况下完全有可能会导致 A 往 B 发送的信息发送到其他 A 内网网段中无关的结点上去的。
3.3 不同的 NAT 对 UDP 打洞的影响
UDP 打洞技术目前依赖于 NAT 类型。本章将讨论不同的 NAT 下,UDP 打洞的可行性与技术难点。
目前 NAT 的主要分类是 锥形 NAT、对称 NAT。而锥形 NAT 又可分为三类:全锥形 NAT、受限锥形 NAT、端口受限锥形 NAT。
3.3.1 全锥形 NAT
在一个新会话建立了公网 / 内网端口绑定之后,全锥形 NAT 接下来会接受对应公网端口的所有数据,无论是来自哪个(公网)终端。全锥 NAT 有时候也被称为 “混杂” NAT(promiscuous NAT)。
故而,全锥形 NAT 是最容易实现 UDP 打洞技术的。一旦建立公网 / 内网端口绑定后,任何客户端都可以直接和内网的主机通信。
3.3.2 受限锥形 NAT
在受限锥形 NAT 只会转发符合某个条件的输入数据包。条件为:外部(源)IP 地址匹配内网主机之前发送一个或多个数据包的结点的 IP 地址。受限 NAT 通过限制输入数据包为一组 “已知的” 外部 IP 地址,有效地精简了防火墙的规则。
处于受限锥形 NAT 下的客户端 A 想和客户端 B 进行 P2P 通信,一开始,A 给 B 的公网地址发送 UDP 数据的同时,给服务器 S 发送一个中继请求,要求 B 开始给 A 的公网地址发送 UDP 信息。A 往 B 的输出信息会导致 NAT A 打开一个 A 的内网地址与与 B 的外网地址之间的新通讯会话,B 往 A 亦然。一旦新的 UDP 会话在两个方向都打开之后,客户端 A 和客户端 B 就能直接通讯。
3.3.3 端口受限锥形 NAT
端口受限锥形 NAT 类似于受限锥形,只当外部数据包的 IP 地址和端口号都匹配内网主机发送过的地址和端口号时才进行转发。端口受限锥形 NAT 为内部结点提供了和对称 NAT 相同等级的保护,以隔离未关联的数据。
端口受限锥形 NAT 实现 UDP 打洞的原理和受限锥形 NAT 一样,也是需要想服务器发送一个中继请求。
3.3.4 对称 NAT
假设客户端 A、B 都处于对称 NAT 下。一开始,A 给 B 的公网地址发送 UDP 数据的同时,给服务器 S 发送一个中继请求,要求 B 开始给 A 的公网地址发送 UDP 信息。由于对称 NAT 为每个新的会话开辟一个新的端口。此时 NAT 为 B 开启了一个新的端口,而服务器、A 都不知道这个新的端口是多少,故而无法实现 UDP 打洞。
3.3.5 四种 NAT 比较
假设客户端 A (192.168.0.3, 100) 和 server (1.1.1.1, 1111) 在路由器上建立好映射关系后,如果这个时候路由器 (8.8.8.8) 在 800 端口上收到从另外一台 server (2.2.2.2, 2222) 发来的数据,此时有四种情况:
1、无条件转发给 (192.168.0.3, 100), 这就是全锥型 (Full Cone) NAT。
2、如果 (192.168.0.3, 100) 之前给 (2.2.2.2) 发送过数据,则转发, 这就是受限锥型 (Restricted Cone)。
3、如果 (192.168.0.3, 100) 之前给 (2.2.2.2, 2222) 发送过数据,则转发,这就是端口受限锥型 (Port Restricted Cone)。
4、丢弃报文,拒绝转发,这就是对称型 NAT。
从上面也描述也可以看出,安全性系数:对称型 > 端口受限锥型 > 受限锥型 > 全锥型。
不同 NAT 的穿透性:
| NAT A 类型 | NAT B 类型 | 能否 udp 打洞 |
|---|---|---|
| 全锥型 | 全锥型 | ✓ |
| 全锥型 | 受限锥型 | ✓ |
| 全锥型 | 端口受限锥型 | ✓ |
| 全锥型 | 对称型 | ✓ |
| 受限锥型 | 受限锥型 | ✓ |
| 受限锥型 | 端口受限锥型 | ✓ |
| 受限锥型 | 对称型 | ✓ |
| 端口受限锥型 | 端口受限锥型 | ✓ |
| 端口受限锥型 | 对称型 | ✘, 无法打通 |
| 对称型 | 对称型 | ✘, 无法打通 |
表 3-1 不同的 NAT 传统性
第 4 章 P2P 技术实现
第 3 章节介绍了 P2P 打洞的基本原理和方法,本章节介绍一下当前主要应用于 P2P 通信的几个标准协议,主要有 STUN/RFC3489,STUN/RFC5389,TURN/RFC5766 以及 ICE/RFC5245。
4.1 STUN 技术
4.1.1 STUN 技术原理
RFC3489 和 RFC5389 的名称都是 STUN,但其全称是不同的。在 RFC3489 里,STUN 的全称是 Simple Traversal of User Datagram Protocol (UDP) Through Network Address Translators (NATs),即穿越 NAT 的简单 UDP 传输,是一个轻量级的协议,允许应用程序发现自己和公网之间的中间件类型,同时也能允许应用程序发现自己被 NAT 分配的公网 IP。这个协议在 2003 年 3 月被提出,已经被 STUN/RFC5389 所替代。
RFC5389 中,STUN 的全称为 Session Traversal Utilities for NAT,即 NAT 环境下的会话传输工具,是一种处理 NAT 传输的协议,但主要作为一个工具来服务于其他协议。和 STUN/RFC3489 类似,可以被终端用来发现其公网 IP 和端口,同时可以检测端点间的连接性,也可以作为一种保活(keep-alive)协议来维持 NAT 的绑定。
和 RFC3489 最大的不同点在于,STUN 本身不再是一个完整的 NAT 传输解决方案,而是在 NAT 传输环境中作为一个辅助的解决方法,同时也增加了 TCP 的支持。RFC5389 废弃了 RFC3489,因此后者通常称为 classic STUN,但依旧是后向兼容的。
STUN 是一个 C/S 架构的协议,支持两种传输类型。一种是请求 / 响(request/respond)类型,由客户端给服务器发送请求,并等待服务器返回响应;另一种是指示类型(indication transaction),由服务器或者客户端发送指示,另一方不产生响应。
两种类型的传输都包含一个 96 位的随机数作为事务 ID(transaction ID),对于请求 / 响应类型,事务 ID 允许客户端将响应和产生响应的请求连接起来;对于指示类型,事务 ID 通常作为 debugging aid 使用。
所有的 STUN 报文信息都含有一个固定头部,包含了方法,类和事务 ID。方法表示是具体哪一种传输类型(两种传输类型又分了很多具体类型),STUN 中只定义了一个方法,即 binding(绑定),其他的方法可以由使用者自行拓展;Binding 方法可以用于请求 / 响应类型和指示类型,用于前者时可以用来确定一个 NAT 给客户端分配的具体绑定,用于后者时可以保持绑定的激活状态。类表示报文类型是请求 / 成功响应 / 错误响应 / 指示。在固定头部之后是零个或者多个属性(attribute),长度也是不固定的。
4.1.2 STUN 报文结构
STUN 报文和大多数网络类型的格式一样,是以大端编码 (big-endian) 的,即最高有效位在左边。所有的 STUN 报文都以 20 字节的头部开始,后面跟着若干个属性。
STUN 头部包含了 STUN 消息类型,magic cookie,事务 ID 和消息长度,如下:
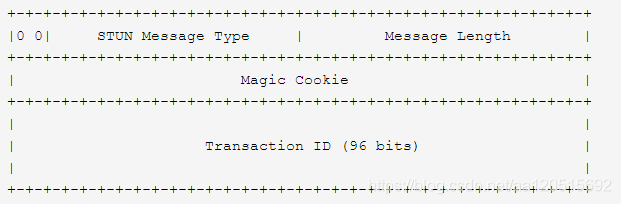
图 4-1 STUN 报文头部
最高的 2 位必须置零,这可以在当 STUN 和其他协议复用的时候,用来区分 STUN 包和其他数据包。
STUN Message Type 字段定义了消息的类型(请求 / 成功响应 / 失败响应 / 指示)和消息的主方法。虽然我们有 4 个消息类别,但在 STUN 中只有两种类型的事务,即请求 / 响应类型和指示类型。
响应类型分为成功和出错两种,用来帮助快速处理 STUN 信息。Message Type 字段又可以进一步分解为如下结构:
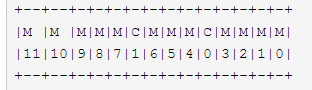
图 4-2 Message Type 字段
其中显示的位为从最高有效位 M11 到最低有效位 M0,M11 到 M0 表示方法的 12 位编码。C1 和 C0 两位表示类的编码。比如对于 binding 方法来说,0b00 表示 request,0b01 表示 indication,0b10 表示 success response,0b11 表示 error response,每一个 method 都有可能对应不同的传输类别。拓展定义新方法的时候注意要指定该方法允许哪些类型的消息。
Magic Cookie 字段包含固定值 0x2112A442,这是为了前向兼容 RFC3489,因为在 classic STUN 中,这一区域是事务 ID 的一部分。
另外选择固定数值也是为了服务器判断客户端是否能识别特定的属性。还有一个作用就是在协议多路复用时候也可以将其作为判断标志之一。
Transaction ID 字段是个 96 位的标识符,用来区分不同的 STUN 传输事务。对于 request/response 传输,事务 ID 由客户端选择,
服务器收到后以同样的事务 ID 返回 response;对于 indication 则由发送方自行选择。事务 ID 的主要功能是把 request 和 response 联系起来,
同时也在防止攻击方面有一定作用。服务端也把事务 ID 当作一个 Key 来识别不同的 STUN 客户端,因此必须格式化且随机在 0~2^(96-1) 之间。
重发同样的 request 请求时可以重用相同的事务 ID,但是客户端进行新的传输时,必须选择一个新的事务 ID。
Message Length 字段存储了信息的长度,以字节为单位,不包括 20 字节的 STUN 头部。由于所有的 STUN 属性都是都是 4 字节对齐(填充)的,
因此这个字段最后两位应该恒等于零,这也是辨别 STUN 包的一个方法之一。
4.1.3 STUN 通信过程
1.产生一个 Request 或 Indication
当产生一个 Request 或者 Indication 报文时,终端必须根据上文提到的规则来生成头部,class 字段必须是 Request 或者 Indication,而 method 字段为 Binding 或者其他用户拓展的方法。属性部分选择该方法所需要的对应属性,比如在一些情景下我们会需要 authenticaton 属性或 FINGERPRINT 属性,注意在发送 Request 报文时候,需要加上 SOFTWARE 属性(内含软件版本描述)。
2.发送 Requst 或 Indication
目前,STUN 报文可以通过 UDP,TCP 以及 TLS-over-TCP 的方法发送,其他方法在以后也会添加进来。STUN 的使用者必须指定其使用的传输协议,以及终端确定接收端 IP 地址和端口的方式,比如通过基于 DNS 的方法来确定服务器的 IP 和端口。
2.1 通过 UDP 发送
当使用 UDP 协议运行 STUN 时,STUN 的报文可能会由于网络问题而丢失。可靠的 STUN 请求 / 响应传输是通过客户端重发 request 请求来实现的,因此,在 UDP 运行时,Indication 报文是不可靠的。STUN 客户端通过 RTO(Retransmission TimeOut)来决定是否重传 Requst,并且在每次重传后将 RTO 翻倍。具体重传时间的选取可以参考相关文章,如 RFC2988。重传直到接收到 Response 才停止,或者重传次数到达指定次数 Rc,Rc 应该是可配置的,且默认值为 7。
2.2 通过 TCP 或者 TCP-over-TLS 发送
对于这种情景,客户端打开对服务器的连接。在某些情况下,此 TCP 链接只传输 STUN 报文,而在其他拓展中,在一个 TCP 链接里可能 STUN 报文和其他协议的报文会进行多路复用(Multiplexed)。数据传输的可靠性由 TCP 协议本身来保证。值得一提的是,在一次 TCP 连接中,STUN 客户端可能发起多个传输,有可能在前一个 Request 的 Response 还没收到时就再次发送了一个新的 Request,因此客户端应该保持 TCP 链接打开,认所有 STUN 事务都已完成。
3.接收 STUN 消息
当 STUN 终端接收到一个 STUN 报文时,首先检查报文的规则是否合法,即前两位是否为 0,magic cookie 是否为 0x2112A442,报文长度是否正确以及对应的方法是否支持。
如果消息类别为 Success/Error Response,终端会检测其事务 ID 是否与当前正在处理的事务 ID 相同。如果使用了 FINGERPRINT 拓展的话还会检查 FINGERPRINT 属性是否正确。完成身份认证检查之后,STUN 终端会接着检查其余未知属性。
3.1 处理 Request
如果请求包含一个或者多个强制理解的未知属性,接收端会返回 error response,错误代码 420(ERROR-CODE 属性),而且包含一个 UNKNOWN-ATTRIBUTES 属性来告知发送方哪些强制理解的属性是未知的。服务端接着检查方法和其他指定要求,如果所有检查都成功,则会产生一个 Success Response 给客户端。
3.1.1 生成 Success Response 或 Error Response
如果服务器通过某种验证方法(authentication mechanism)通过了请求方的验证,那么在响应报文里最好也加上对应的验证属性。服务器端也应该加上指定方法所需要的属性信息,另外协议建议服务器返回时也加上 SOFTWARE 属性。
对于 Binding 方法,除非特别指明,一般不要求进行额外的检查。当生成 Success Response 时,服务器在响应里加上 XOR-MAPPED-ADDRESS 属性。
对于 UDP,这是其源 IP 和端口信息,对于 TCP 或 TLS-over-TCP,这就是服务器端所看见的此次 TCP 连接的源 IP 和端口。
3.1.2 发送 Success Response 或 Error Response
发送响应时候如果是用 UDP 协议,则发往其源 IP 和端口,如果是 TCP 则直接用相同的 TCP 链接回发即可。
3.2 处理 Indication
如果 Indication 报文包含未知的强制理解属性,则此报文会被接收端忽略并丢弃。如果对 Indication 报文的检查都没有错误,则服务端会进行相应的处理,但是不会返回 Response。对于 Binding 方法,一般不需要额外的检查或处理。收到信息的服务端仅需要刷新对应 NAT 的端口绑定。
由于 Indication 报文在用 UDP 协议传输时不会进行重传,因此发送方也不需要处理重传的情况。
3.3 处理 Success Response
如果 Success Response 包含了未知的强制理解属性,则响应会被忽略并且认为此次传输失败。客户端对报文进行检查通过之后,就可以开始处理此次报文。
以 Binding 方法为例,客户端会检查报文中是否包含 XOR-MAPPED-ADDRESS 属性,然后是地址类型,如果是不支持的地址类型,则这个属性会被忽略掉。
3.4 处理 Error Response
如果 Error Response 包含了未知的强制理解属性,或者没有包含 ERROR-CODE 属性,则响应会被忽略并且认为此次传输失败。
随后客户端会对验证方法进行处理,这有可能会产生新的传输。
到目前为止,对错误响应的处理主要基于 ERROR-CODE 属性的值,并遵循如下规则:
如果 error code 在 300 到 399 之间,客户端被建议认为此次传输失败,除非用了 ALTERNATE-SERVER 拓展;
如果 error code 在 400 到 499 之间,客户端认为此次传输失败;
如果 error code 在 500 到 599 之间,客户端可能会需要重传请求,并且必须限制重传的次数。
任何其他的 error code 值都会导致客户端认为此次传输失败。
4.2 TURN 技术
4.2.1 TURN 技术原理
TURN 的全称为 Traversal Using Relays around NAT,是 STUN/RFC5389 的一个拓展,主要添加了 Relay 功能。如果终端在 NAT 之后,那么在特定的情景下,有可能使得终端无法和其对等端(peer)进行直接的通信,这时就需要公网的服务器作为一个中继,
对来往的数据进行转发。这个转发的协议就被定义为 TURN。TURN 和其他中继协议的不同之处在于,它允许客户端使用同一个中继地址(relay address)与多个不同的 peer 进行通信。
使用 TURN 协议的客户端必须能够通过中继地址和对等端进行通讯,并且能够得知每个 peer 的的 IP 地址和端口(确切地说,应该是 peer 的服务器反射地址)。
而这些行为如何完成,是不在 TURN 协议范围之内的。
如果 TURN 使用于 ICE 协议中,relay 地址会作为一个候选,由 ICE 在多个候选中进行评估,选取最合适的通讯地址。一般来说中继的优先级都是最低的。
TURN 协议被设计为 ICE 协议 (Interactive Connectivity Establishment) 的一部分,而且也强烈建议用户在他们的程序里使用 ICE,但是也可以独立于 ICE 的运行。
值得一提的是,TURN 协议本身是 STUN 的一个拓展,因此绝大部分 TURN 报文都是 STUN 类型的,作为 STUN 的一个拓展,TURN 增加了新的方法(method)和属性(attribute)。
4.2.2 TURN 传输过程
在协议中,TURN 服务器与 peer 之间的连接都是基于 UDP 的,但是服务器和客户端之间可以通过其他各种连接来传输 STUN 报文,比如 TCP/UDP/TLS-over-TCP. 客户端之间通过中继传输数据时候,如果用了 TCP, 也会在服务端转换为 UDP, 因此建议客户端使用
UDP 来进行传输。至于为什么要支持 TCP, 那是因为一部分防火墙会完全阻挡 UDP 数据,而对于三次握手的 TCP 数据则不做隔离。
1、分配 (Allocations)
要在服务器端获得一个中继分配,客户端须使用分配事务。客户端发送分配请求 (Allocate request) 到服务器,然后服务器返回分配成功响应,并包含了分配的地址。客户端可以在属性字段描述其想要的分配类型 (比如生命周期). 由于中继数据实现了安全传输,服务器会要求对客户端进行验证,主要使用 STUN 的 long-term credential mechanism。
一旦中继传输地址分配好,客户端必须要将其保活。通常的方法是发送刷新请求 (Refresh request) 到服务端。这在 TURN 中是一个标准的方法。刷新频率取决于分配的生命期,默认为 10 分钟。客户端也可以在刷新请求里指定一个更长的生命期,
而服务器会返回一个实际上分配的时间。当客户端想中指通信时,可以发送一个生命期为 0 的刷新请求.
服务器和客户端都保存有一个成为五元组 (5-TUPLE) 的信息,比如对于客户端来说,五元组包括客户端本地地址 / 端口,服务器地址 / 端口,和传输协议;服务器也是类似,只不过将客户端的地址变为其反射地址,因为那才是服务器所见到的。服务器和客户端在分配请求中都带有 5-TUPLE 信息,并且也在接下来的信息传输中使用,因此彼此都知道哪一次分配对应哪一次传输。
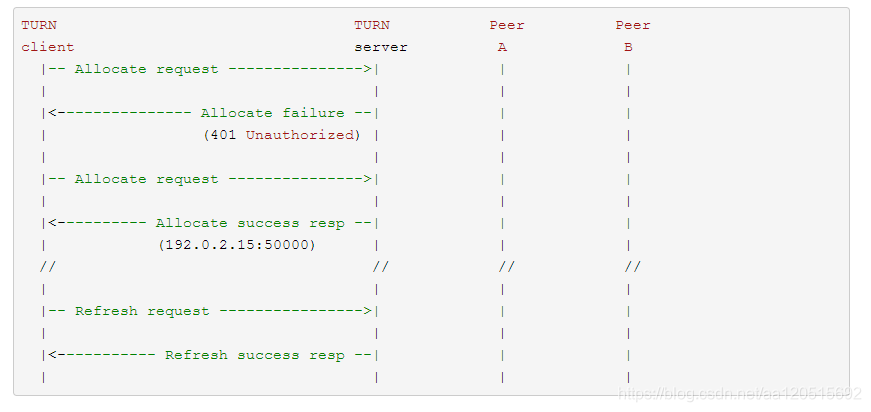
图 4-3 传输过程
如上图所示,客户端首先发送 Allocate 请求,但是没带验证信息,因此 STUN 服务器会返回 error response, 客户端收到错误后加上
所需的验证信息再次请求,才能进行成功的分配.
2、发送机制 (Send Mechanism)
client 和 peer 之间有两种方法通过 TURN server 交换应用信息,第一种是使用 Send 和 Data 方法 (method), 第二种是使用通道 (channels), 两种方法都通过某种方式告知服务器哪个 peer 应该接收数据,以及服务器告知 client 数据来自哪个 peer。
Send Mechanism 使用了 Send 和 Data 指令 (Indication). 其中 Send 指令用来把数据从 client 发送到 server, 而 Data 指令用来把数据从 server 发送到 client. 当使用 Send 指令时,客户端发送一个 Send Indication 到服务端,其中包含:
XOR-PEER-ADDRESS 属性,指定对等端的 (服务器反射) 地址.
DATA 属性,包含要传给对等端的信息.
当服务器收到 Send Indication 之后,会将 DATA 部分的数据解析出来,并将其以 UDP 的格式转发到对应的端点去,并且在封装数据包的时候把 client 的中继地址作为源地址。从而从对等端发送到中继地址的数据也会被服务器转发到 client 上。值得一提的是:Send/Data Indication 是不支持验证的,因为长效验证机制不支持对 indication 的验证,因此为了防止攻击,TURN 要求 client 在给对等端发送 indication 之前先安装一个到对等端的许可 (permission), 如下图所示,client 到 Peer B 没有安装许可,导致其 indication 数据包将被服务器丢弃,对于 peer B 也是同样。
TURN 支持两种方式来创建许可,一种是发送 CreatePermission request
3、信道机制 (Channels)
对于一些应用程序,比如 VOIP (Voice over IP), 在 Send/Data Indication 中多加的 36 字节格式信息会加重客户端和服务端之间的带宽压力。为改善这种情况,TURN 提供了第二种方法来让 client 和 peer 交互数据。该方法使用另一种数据包格式,即 ChannelData message, 信道数据报文. ChannelData message 不使用 STUN 头部,而使用一个 4 字节的头部,包含了一个称之为信道号的值 (channel number). 每一个使用中的信道号都与一个特定的 peer 绑定,即作为对等端地址的一个记号。
要将一个信道与对等端绑定,客户端首先发送一个信道绑定请求 (ChannelBind Request) 到服务器,并且指定一个未绑定的信道号以及对等端的地址信息。绑定后 client 和 server 都能通过 ChannelData message 来发送和转发数据。信道绑定默认持续 10 分钟,并且可以通过重新发送 ChannelBind Request 来刷新持续时间。和 Allocation 不同的是,并没有直接删除绑定的方法,只能等待其超时自动失效。
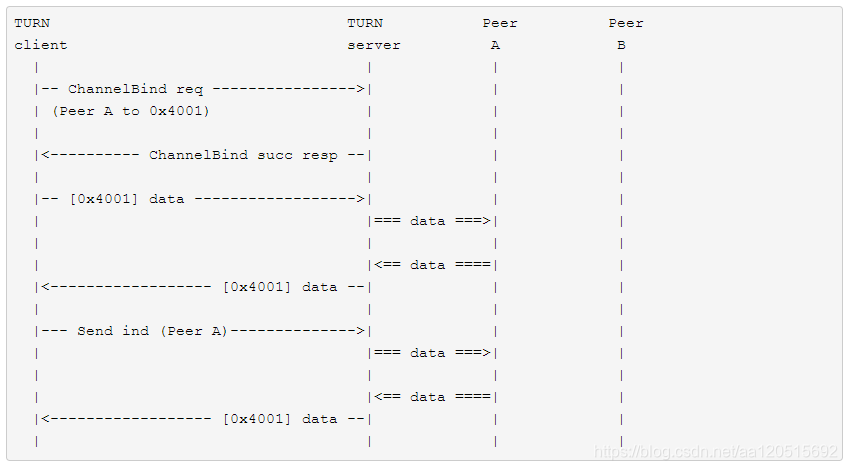
图 4-4 信道号
上图中 0x4001 为信道号,即 ChannelData message 的头部中头 2 字节,值得一提的是信道号的选取有如下要求:
0x0000-0x3FFF : 这一段的值不能用来作为信道号。
0x4000-0x7FFF : 这一段是可以作为信道号的值,一共有 16383 种不同值在目前来看是足够用的。
0x8000-0xFFFF : 这一段是保留值,留给以后使用。
4.3 ICE 技术
4.3.1 ICE 技术原理
ICE 的全称为 Interactive Connectivity Establishment, 即交互式连接建立。ICE 是一个用于在 offer/answer 模式下的 NAT 传输协议,主要用于 UDP 下多媒体会话的建立,其使用了 STUN 协议以及 TURN 协议,同时也能被其他实现了 offer/answer 模型的的其他程序所使用,比如 SIP(Session Initiation Protocol).
使用 offer/answer 模型 (RFC3264) 的协议通常很难在 NAT 之间穿透,因为其目的一般是建立多媒体数据流,而且在报文中还携带了数据的源 IP 和端口信息,这在通过 NAT 时是有问题的.RFC3264 还尝试在客户端之间建立直接的通路,因此中间就缺少
了应用层的封装。这样设计是为了减少媒体数据延迟,减少丢包率以及减少程序部署的负担。然而这一切都很难通过 NAT 而完成。
有很多解决方案可以使得这些协议运行于 NAT 环境之中,包括应用层网关 (ALGs),Classic STUN 以及 Realm Specific IP+SDP 协同工作等方法。不幸的是,这些技术都是在某些网络拓扑下工作很好,而在另一些环境下表现又很差,因此我们需要一个单一的,可自由定制的解决方案,以便能在所有环境中都能较好工作。
4.3.2 ICE 的工作流程
一个典型的 ICE 工作环境如下,
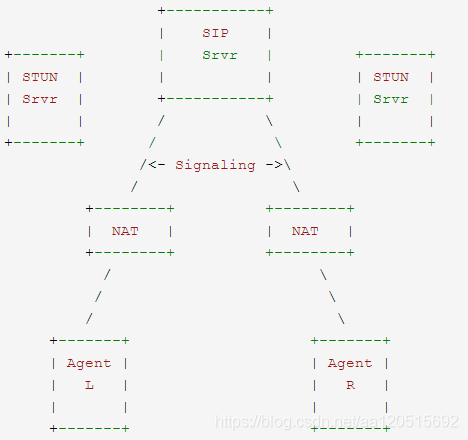
图 4-5 ICE 工作环境
有两个端点 L 和 R, 都运行在各自的 NAT 之后 (他们自己也许并不知道),NAT 的类型和性质也是未知的。L 和 R 通过交换 SDP 信息在彼此之间建立多媒体会话,通常交换通过一个 SIP 服务器完成。
ICE 的基本思路是,每个终端都有一系列传输地址 (包括传输协议,IP 地址和端口) 的候选,可以用来和其他端点进行通信.。其中可能包括:
直接和网络接口联系的传输地址 (host address)
经过 NAT 转换的传输地址,即反射地址 (server reflective address)
TURN 服务器分配的中继地址 (relay address)
虽然潜在要求任意一个 L 的候选地址都能用来和 R 的候选地址进行通信。但是实际中发现有许多组合是无法工作的。举例来说,如果 L 和 R 都在 NAT 之后而且不处于同一内网,他们的直接地址就无法进行通信.ICE 的目的就是为了发现哪一对候选地址的组合可以工作,并且通过系统的方法对所有组合进行测试 (用一种精心挑选的顺序).
为了执行 ICE, 客户端必须要识别出其所有的地址候选,ICE 中定义了三种候选类型,有些是从物理地址或者逻辑网络接口继承而来,其他则是从 STUN 或者 TURN 服务器发现的。很自然,一个可用的地址为和本地网络接口直接联系的地址,通常是内网地址,称为 HOST CANDIDATE, 如果客户端有多个网络接口,比如既连接了 WiFi 又插着网线,那么就可能有多个内网地址候选.
其次,客户端通过 STUN 或者 TURN 来获得更多的候选传输地址,即 SERVER REFLEXIVE CANDIDATES 和 RELAYED CANDIDATES, 如果 TURN 服务器是标准化的,那么两种地址都可以通过 TURN 服务器获得。当 L 获得所有的自己的候选地址之后,会将其按优先级排序,然后通过 signaling 通道发送到 R. 候选地址被存储在 SDP offer 报文的属性部分。当 R 接收到 offer 之后,就会进行同样的获选地址收集过程,并返回给 L。
这一步骤之后,两个对等端都拥有了若干自己和对方的候选地址,并将其配对,组成 CANDIDATE PAIRS. 为了查看哪对组合可以工作,每个终端都进行一系列的检查。每个检查都是一次 STUN request/response 传输,将 request 从候选地址对的本地地址发送到远端地址。连接性检查的基本原则很简单:
以一定的优先级将候选地址对进行排序.
以该优先级顺序发送 checks 请求
从其他终端接收到 checks 的确认信息
两端连接性测试,结果是一个 4 次握手过程:
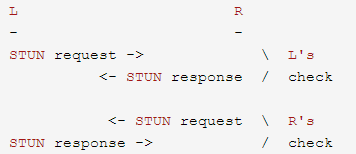
图 4-6 ICE 四次握手过程
值的一提的是,STUN request 的发送和接收地址都是接下来进多媒体传输 (如 RTP 和 RTCP) 的地址和端口,所以,客户端实际上是将 STUN 协议与 RTP/RTCP 协议在数据包中进行复用 (而不是在端口上复用)。
由于 STUN Binding request 用来进行连接性测试,因此 STUN Binding response 中会包含终端的实际地址,如果这个地址和之前学习的所有地址都不匹配,发送方就会生成一个新的 candidate, 称为 PEER REFLEXIVE CANDIDATE, 和其他 candidate 一样,也要通过 ICE 的检查测试.
连接性检查 (Connectivity Checks)
所有的 ICE 实现都要求与 STUN (RFC5389) 兼容,并且废弃 Classic STUN (RFC3489).ICE 的完整实现既生成 checks (作为 STUN client),
也接收 checks (作为 STUN server), 而 lite 实现则只负责接收 checks. 这里只介绍完整实现情况下的检查过程.
1.为中继候选地址生成许可 (Permissions)
2.从本地候选往远端候选发送 Binding Request
在 Binding 请求中通常需要包含一些特殊的属性,以在 ICE 进行连接性检查的时候提供必要信息。
PRIORITY 和 USE-CANDIDATE:
终端必须在其 request 中包含 PRIORITY 属性,指明其优先级,优先级由公式计算而得。如果有需要也可以给出特别指定的候选 (即 USE-CANDIDATE 属性)。
ICE-CONTROLLED 和 ICE-CONTROLLING:
在每次会话中,每个终端都有一个身份,有两种身份,即受控方 (controlled role) 和主控方 (controlling role)。主控方负责选择最终用来通讯的候选地址对,受控方被告知哪个候选地址对用来进行哪次媒体流传输,并且不生成更新过的 offer 来提示此次告知。发起 ICE 处理进程 (即生成 offer) 的一方必须是主控方,而另一方则是受控方。如果终端是受控方,那么在 request 中就必须加上 ICE-CONTROLLED 属性,同样,如果终端是主控方,就需要 ICE-CONTROLLING 属性.
生成 Credential
作为连接性检查的 Binding Request 必须使用 STUN 的短期身份验证。验证的用户名被格式化为一系列 username 段的联结,包含了发送请求的所有对等端的用户名,以冒号隔开;密码就是对等端的密码.
3.处理 Response
当收到 Binding Response 时,终端会将其与 Binding Request 相联系,通常通过事务 ID. 随后将会将此事务 ID 与候选地址对进行绑定.
失败响应
如果 STUN 传输返回 487 (Role Conflict) 错误响应,终端首先会检查其是否包含了 ICE-CONTROLLED 或 ICE-CONTROLLING 属性。如果有 ICE-CONTROLLED, 终端必须切换为 controlling role; 如果请求包含 ICE-CONTROLLING 属性,则必须切换为 controlled role. 切换好之后,终端必须使产生 487 错误的候选地址对进入检查队列中,并将此地址对的状态设置为 Waiting.
成功响应,一次连接检查在满足下列所有情况时候就被认为成功:
STUN 传输产生一个 Success Response
response 的源 IP 和端口等于 Binding Request 的目的 IP 和端口
response 的目的 IP 和端口等于 Binding Request 的源 IP 和端口
终端收到成功响应之后,先检查其 mapped address 是否与本地记录的地址对有匹配,如果没有则生成一个新的候选地址。即对等端的反射地址。如果有匹配,则终端会构造一个可用候选地址对 (valid pair). 通常很可能地址对不存在于任何检查列表中,检索检查列表中没有被服务器反射的本地地址,这些地址把它们的本地候选转换成服务器反射地址的基地址,并把冗余的地址去除掉。
静态 NAT、动态 NAT、PAT (端口多路复用) 的配置
posted @ 2017-03-03 13:47 立志做一个好的程序员
NAT 的实现方式有三种,即静态转换 Static Nat、动态转换 Dynamic Nat 和 端口多路复用 OverLoad。
静态转换 (Static Nat) 是指将内部网络的私有 IP 地址转换为公有 IP 地址,IP 地址对是一对一的,是一成不变的,某个私有 IP 地址只转换为某个公有 IP 地址。借助于静态转换,可以实现外部网络对内部网络中某些特定设备 (如服务器) 的访问。
动态转换 (Dynamic Nat) 是指将内部网络的私有 IP 地址转换为公用 IP 地址时,IP 地址对是不确定的,而是随机的,所有被授权访问上 Internet 的私有 IP 地址可随机转换为任何指定的合法 IP 地址。也就是说,只要指定哪些内部地址可以进行转换,以及用哪些合法地址作为外部地址时,就可以进行动态转换。动态转换可以使用多个合法外部地址集。当 ISP 提供的合法 IP 地址略少于网络内部的计算机数量时。可以采用动态转换的方式。
端口多路复用 (OverLoad) 是指改变外出数据包的源端口并进行端口转换,即端口地址转换 (PAT,Port Address Translation) 采用端口多路复用方式。内部网络的所有主机均可共享一个合法外部 IP 地址实现对 Internet 的访问,从而可以最大限度地节约 IP 地址资源。同时,又可隐藏网络内部的所有主机,有效避免来自 internet 的攻击。因此,目前网络中应用最多的就是端口多路复用方式。
网络拓扑图:
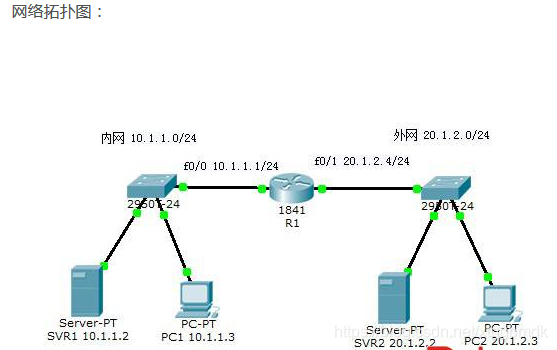
路由器 R1:f0/0 10.1.1.1/24 f0/1 20.1.2.0/24
内网:10.1.1.0/24
服务器 SVR1 10.1.1.2 开启 HTTP 服务
终端机 PC1 10.1.1.3
外网:20.1.2.0/24 未配置网关
服务器 SVR2 20.1.2.2 开启 HTTP 服务
终端机 PC2 20.1.2.3
一、静态 NAT
配置步骤:
首先,配置各接口的 IP 地址。内网使用私有 IP。外网使用公网 IP。并指定其属于内外接口。
其次,定义静态建立 IP 地址之间的静态映射。
最后,指定其默认路由。
配置示例:
将服务器 SRV1 的内网 IP 转换为外网地址,即 10.1.1.2 ——> 20.1.2.5,实现外部网络能访问内部网络中的服务器
Router>en (进入特权模式)
Router#config t(进入全局配置模式)
Router (config)#ho R1 (命名为 R1)
R1 (config)#no ip domain-lo
(关闭域名查询,在实验环境中,敲入错误的命令,它将进行域名查询,故关闭他)
R1 (config)#line c 0 (进入线路 CONSOLE 接口 0 下)
R1 (config-line)#logg syn (启用光标跟随,防止日志信息冲断命令显示的位置)
R1 (config-line)#exec-t 0 0 (防止超时,0 0 为永不超时)
R1 (config-line)#exit
R1 (config)#int f 0/0 (进入以太网接口 0 下)
R1 (config-if)#ip add 10.1.1.1 255.255.255.0(设置 IP 地址)
R1 (config-if)#ip nat inside (设置为内部接口)
R1 (config-if)#no shut
R1 (config-if)#exit
R1 (config)#int f 0/1 (进入以太网接口 1 下)
R1 (config-if)#ip add 20.1.2.4 255.255.255.0
R1 (config-if)#no shut
R1 (config-if)#ip nat outside (设置为外部接口)
R1 (config-if)#exit
R1 (config)#ip nat inside source static 10.1.1.2 20.1.2.5
(设置静态转换,其中 ip nat inside source 为 NAT 转换关键字,这里是静态,故为 STATIC)
R1 (config)#ip classless
R1 (config)#ip route 0.0.0.0 0.0.0.0 f0/1 (这里是出口或者下一跳地址)
R1 (config)#exit
结果:
在外网 PC2 浏览器中访问 http://20.1.2.5,但内网中的 PC1 不能访问 SRV2。
二、动态 NAT
配置步骤:
首先,配置各需要转换的接口的 IP,设置内外网 IP 等。
其次,定义动态地址转换池列表
再次,配置 ACL 列表,需要转换的内网 IP 地址(或者网段)。
最后,设置转换后的出口地址段及 MASK(多 IP 可以多分流,减轻转换后的负担)
配置示例:
实现内部网络能访问外部网络中的服务器
R1#config t
R1 (config)#int f 0/0
R1 (config-if)#ip add 10.1.1.1 255.255.255.0
R1 (config-if)#ip nat inside
R1 (config-if)#no shut
R1 (config-if)#exit
R1 (config)#int f 0/1
R1 (config-if)#ip add 20.1.2.4 255.255.255.0
R1 (config-if)#no shut
R1 (config-if)#ip nat outside
R1 (config-if)#exit
R1 (config)#ip nat inside source list 1 pool ds (动态地址池)
R1 (config)#access-list 1 permit 10.1.1.2 0.0.0.0
(ACL 列表,设置访问列表,允许内部的网络转换出去,网段自由设顶)
R1 (config)#access-list 1 permit 10.1.1.3 0.0.0.0
R1 (config)#ip nat pool ds 20.1.2.5 20.1.2.6 net 255.255.255.0 (转换出口地址段)
(这里的 IP 为能在公网上使用的 IP,这里设置了 2 个 IP,可以为几个,如果后面设置为 20.1.2.9,那么这里就有 5 个公网 IP,一般 2 个就够了)
R1 (config)#exit
三、PAT 配置
R1#config t
R1 (config)#int f 0/0
R1 (config-if)#ip add 10.1.1.1 255.255.255.0
R1 (config-if)#ip nat inside
R1 (config-if)#no shut
R1 (config-if)#exit
R1 (config)#int f 0/1
R1 (config-if)#ip add 20.1.2.4 255.255.255.0
R1 (config-if)#no shut
R1 (config-if)#ip nat outside
R1 (config-if)#exit
R1 (config)#ip nat inside source list 1 pool ds
(其中 ip nat inside source list X pool xx overload 为关键字)
R1 (config)#access-list 1 permit 10.1.1.1 255.255.255.0
R1 (config)#ip nat pool ds 20.1.2.5 20.1.2.7 net 255.255.255.0
R1 (config)#exit
via:
-
NAT 穿越技术原理_nat穿透技术-CSDN博客 Li_yy123 于 2020-12-08 18:54:26 发布
https://blog.csdn.net/LY_624/article/details/110228233 -
P2P,UDP 和 TCP 穿透 NAT_nat tcp 转发-CSDN博客 chengweiv5于 2009-11-29 14:56:00 发布
https://blog.csdn.net/leisure512/article/details/4900191 -
关于 TCP 打洞技术(P2P)_tcp 打洞端口复用-CSDN博客 Sidyhe 于 2011-02-13 03:09:00 发布-
https://blog.csdn.net/Sidyhe/article/details/6181828 -
用 TCP 穿透 NAT(TCP 打洞)的实现_tcp 穿透-CSDN博客 AAA20090987于 2013-04-17 17:23:38 发布
https://blog.csdn.net/small_qch/article/details/8815028 -
NAT 打洞(udp 打洞和 tcp 打洞)_nat4 打洞-CSDN博客 coding_myway 于 2015-09-16 17:59:44 发布
https://blog.csdn.net/nullzeng/article/details/48497681 -
基于 TCP/UDP 的 P2P 网络通信协议研究与实现_p2p底层协议 tcp-CSDN博客 连志安的博客于 2019-11-21 19:57:20 发布
https://blog.csdn.net/aa120515692/article/details/103189729 -
静态NAT、动态NAT、PAT(端口多路复用)的配置 - 立志做一个好的程序员 - 博客园 posted @ 2017-03-03 13:47 立志做一个好的程序员
https://www.cnblogs.com/oxspirt/p/6496344.html