为什么使用cookie呢?
首先我们要清楚网络请求是无状态的,也就是说请求响应一次就结束了,下一次再去请求,服务器根本不知道这次和上次请求是不是同一个来源,所以呢,cookie就诞生了,就是服务器在接收请求之后,会创建cookie,响应的时候将cookie发送给客户端,下次如果客户端发送请求的时候把cookie中的信息一起发送给服务端,那服务端就会确定这次和上次请求是同一个客户端发起的。
如何在爬虫程序中使用cookie呢?
爬虫中使用cookie分为以下几步:
- 实例化MozillaCookieJar,为了保存cookie
- 创建handler对象,这个是cookie的处理器
- 创建opener对象,用来发送请求
- 发送请求获取响应
- 保存cookie文件
准备导入的库及需要使用的对象
# 需要发送请求所以要导入request
import urllib.request
# 需要保存cookie,所以要引入cookieJar
from http import cookiejar
# 需要把cookie保存到文本文件中,需要定义文件名称
filename='cookie.txt'
实例化MozillaCookieJar对象
cookie=cookiejar.MozillaCookieJar(filename)
创建handler对象
handler=urllib.request.HTTPCookieProcessor(cookie)
创建opener对象并发送请求
opener=urllib.request.build_opener(handler)
url = 'http://www.baidu.com'
resp=opener.open(url)
保存cookie
cookie.save()
完整的代码
# 需要发送请求所以要导入request
import urllib.request
# 需要保存cookie,所以要引入cookieJar
from http import cookiejar
# 需要把cookie保存到文本文件中,需要定义文件名称
filename='cookie.txt'
#写一个函数获取cookie
def get_cookie():
# 1.实例化MozillaCookieJar
cookie=cookiejar.MozillaCookieJar(filename)
# 2.创建handler对象
handler=urllib.request.HTTPCookieProcessor(cookie)
# 3.创建opener对象
opener=urllib.request.build_opener(handler)
# 4.发送请求.只有发送请求后服务器才能创建cookie信息发送给客户端
url = 'http://www.baidu.com'
resp=opener.open(url)
# 5.保存cookie
cookie.save()
查看cookie,也就是加载客户端的cookie
# 读取cookie信息
def use_cookie():
#拿到MozillaCookieJar对象
cookie=cookiejar.MozillaCookieJar();
#加载客户端的cookie.txt文件
cookie.load(filename)
#打印cookie内容
print(cookie)
测试一下
#main方法中调用测试一下
if __name__ == '__main__':
# 获取cookie
get_cookie()
# 查看cookie
use_cookie()
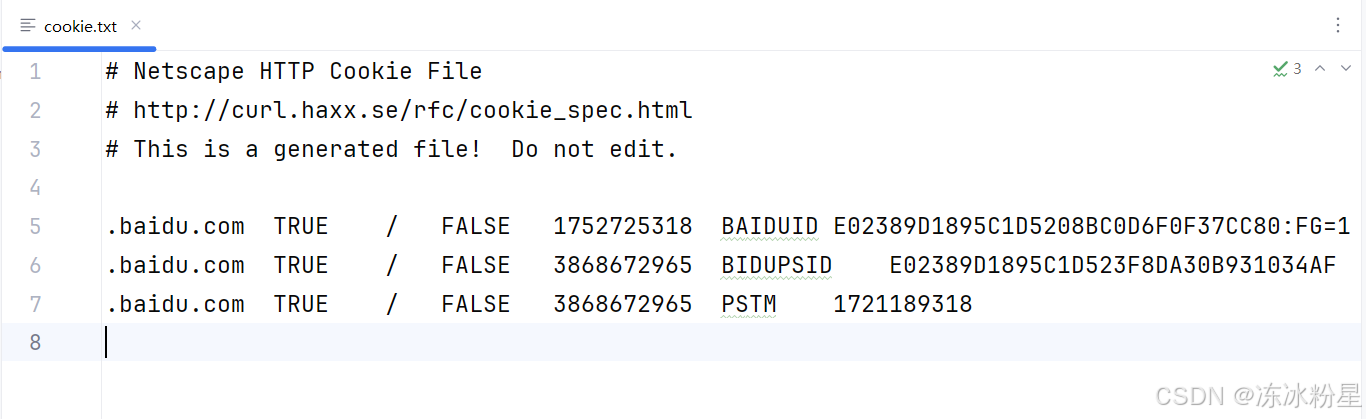
打印信息(这就是cookie):
<MozillaCookieJar[<Cookie BAIDUID=E02389D1895C1D5208BC0D6F0F37CC80:FG=1 for .baidu.com/>, <Cookie BIDUPSID=E02389D1895C1D523F8DA30B931034AF for .baidu.com/>, <Cookie PSTM=1721189318 for .baidu.com/>]>
txt文件