一、需求分析
早期业务借助Sqoop将Mysql中的数据同步到Hive、hdfs来进行数据分析,使用过程中也带来了一些问题:
- 虽然Sqoop支持增量同步但还属于粗粒度的离线同步,无法满足下游数仓实时性的需求(可能一个小时,或者一天)
- 每次同步Sqoop以sql的方式向Mysql发出数据请求也在一定程度上对Mysql带来一定的压力
- 同时Hive对数据更新的支持也相对较弱,由于Hive本身的语法不支持更新、删除等SQL原语,对于MySQL中发生Update/Delete的数据无法很好地进行支持
现在的需求是需要数仓和mysql中的数据保持在秒级别的一致;
我们想到了MySQL主从复制时使用的binlog日志,它记录了所有的 DDL 和 DML 语句(除了数据查询语句select、show等),以事件形式记录,还包含语句所执行的消耗时间。
目前的思路就是实时监听mysql binlog日志,使mysql中的数据变化实时同步到数仓中(这里需要注意的是,我们只监听insert,update,delete这几种event)
binlog记录了Mysql数据的实时变化,是数据同步的基础,服务需要做的就是遵守Mysql的协议,将自己伪装成Mysql的slave来监听业务从库,完成数据实时同步。
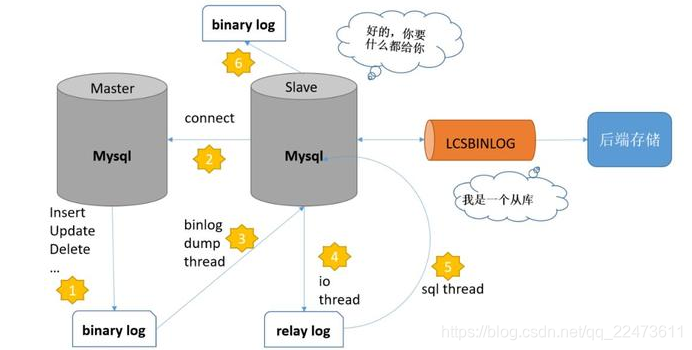
二、MySQL主从复制的原理,主要有以下几个步骤:
- master(主库)在每次准备提交事务完成数据更新前,将改变记录到二进制日志(binary log)中
- slave(从库)发起连接,连接到master,请求获取指定位置的binlog文件
- master创建dump线程,推送binlog的slave
- slave启动一个I/O线程来读取主库上binary log中的事件,并记录到slave自己的中继日志(relay log)中
- slave还会起动一个SQL线程,该线程从relay log中读取事件并在备库执行,完成数据同步
- slave记录自己的binlog
三、整体架构: 直接解析binlog日志,然后解析后的数据写入kafka。
1)监听mysql的binlog日志工具分析:canal、Maxwell、Databus、DTS
https://blog.csdn.net/weixin_38071106/article/details/88547660
2)mysql-binlog-connector-java (jar包直接读取binlog,然后send to kafka)
https://www.jianshu.com/p/5acb30ec8347
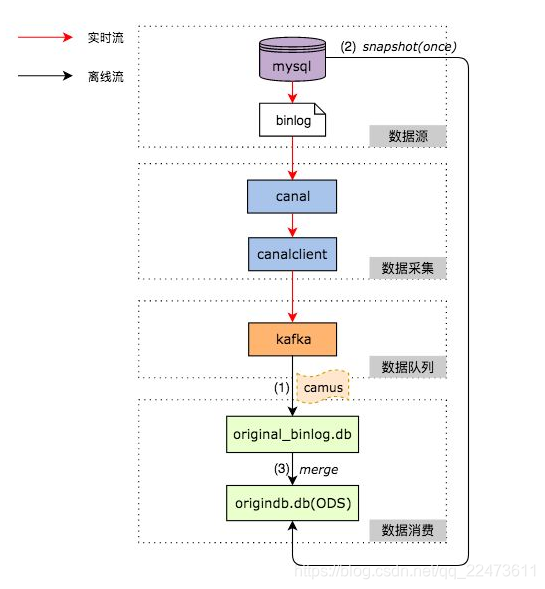
整体的架构如上图所示。在Binlog实时采集方面,我们采用了阿里巴巴的开源项目Canal,负责从MySQL实时拉取Binlog并完成适当解析。Binlog采集后会暂存到Kafka上供下游消费。整体实时采集部分如图中红色箭头所示。
离线处理Binlog的部分,如图中黑色箭头所示,通过下面的步骤在Hive上还原一张MySQL表:
-
采用Linkedin的开源项目Camus,负责每小时把Kafka上的Binlog数据拉取到Hive上。
-
对每张ODS表,首先需要一次性制作快照(Snapshot),把MySQL里的存量数据读取到Hive上,这一过程底层采用直连MySQL去Select数据的方式。
-
对每张ODS表,每天基于存量数据和当天增量产生的Binlog做Merge,从而还原出业务数据。
四、Binlog实时采集
1、开启mysql的binlog
(1)binlog简介
binlog,即二进制日志,它记录了数据库上的所有改变,并以二进制的形式保存在磁盘中;
记录数据库增删改,不记录查询的二进制日志.语句以“事件”的形式保存,它描述数据更改。
它可以用来查看数据库的变更历史、数据库增量备份和恢复、Mysql的复制(主从数据库的复制)。
(2)Binary Log记录方式
binlog记录更新事件的方式有三种:
一:statement(基于语句的复制),保存的是高层的sql语句,优点是传输的数据比较少,缺点是很难做到主从一致,譬如rand()会在不同的地方产生不同的值
二:row(基于行的复制),5.1.5版本的MySQL才开始支持row level的复制,它不记录sql语句上下文相关信息,仅保存哪条记录被修改。仅需要记录那一条记录被修改成什么了。
保存的是记录变化前和变化后的数据,优点是不容易出错,可以做到原样复制,缺点是传输的数据可能会很多,譬如某个delete语句删除一个表里几百万行,基于statement的方式只会产生一个event,而基于row的方式会产生几百万条
三:mixed(混合方式),不会在从库产生歧义的语句只记录sql语句,会产生歧义的语句使用row方式,兼顾前两者的优点
选择哪种可以在my.cnf里的binlog_formate进行修改
ps:在后续开发中将使用Row格式
(3)开启mysql的binlog
a.修改 /etc/my.cnf 配置
-
log-bin=mysql-bin # 开启binlog -
binlog-format=ROW # 设置Binary Log记录方式为Row -
server_id=1 # 记住id 后续开发会使用 -
# 指定binlog日志文件的名字为mysql-bin,以及其存储路径 -
# 如果没有对log-bin指定log文件,默认在 /var/lib/mysql目录下以mysqld-bin.00000X等作为名称。 -
# 而 mysqld-bin.index则记录了所有的log的文件名称 -
# 使用时则使用mysqlbinlog /var/lib/mysql|grep "*****"等来追踪database的操作。 -
log-bin=/var/lib/mysql/mysql-bin -
datadir=/var/lib/mysql -
socket=/var/lib/mysql/mysql.sock
b.重启mysql
service mysqld restart
c.查看开启状态
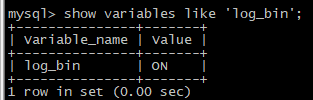
输入 show variables like 'log_bin'; 查看binlog开启状态。如下图所示。
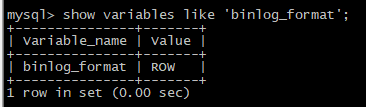
输入 show variables like 'binlog_format'; 查看Binary Log记录方式。如下图所示。
-
mysql> show variables like 'log_%'; -
+---------------------------------+-------------+ -
| Variable_name | Value | -
+---------------------------------+-------------+ -
| log_bin | ON | -
| log_bin_trust_function_creators | OFF | -
| log_error | .\mysql.err | -
| log_queries_not_using_indexes | OFF | -
| log_slave_updates | OFF | -
| log_slow_queries | ON | -
| log_warnings | 1 | -
+---------------------------------+-------------+ -
没有开启log_bin的值是OFF,开启之后是ON
-
mysql> SHOW VARIABLES LIKE 'character%'; -
+--------------------------+----------------------------+ -
| Variable_name | Value | -
+--------------------------+----------------------------+ -
| character_set_client | utf8 | -
| character_set_connection | utf8 | -
| character_set_database | latin1 | -
| character_set_filesystem | binary | -
| character_set_results | utf8 | -
| character_set_server | latin1 | -
| character_set_system | utf8 | -
| character_sets_dir | /usr/share/mysql/charsets/ | -
+--------------------------+----------------------------+
注意:每次服务器(数据库)重启,服务器会调用flush logs;,新创建一个binlog日志
由于我之前重启过数据库,因此这里有mysql-bin.000001到mysql-bin.000002这2个文件。这里你们看到的
应该只有mysql-bin.000001和mysql-bin.index两个文件
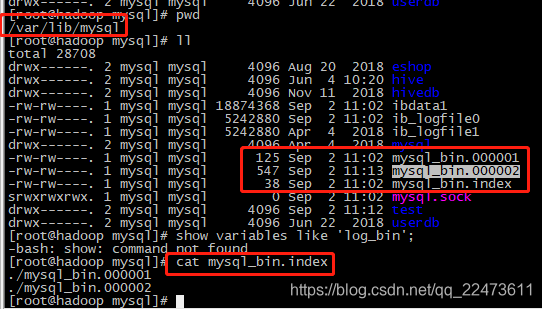
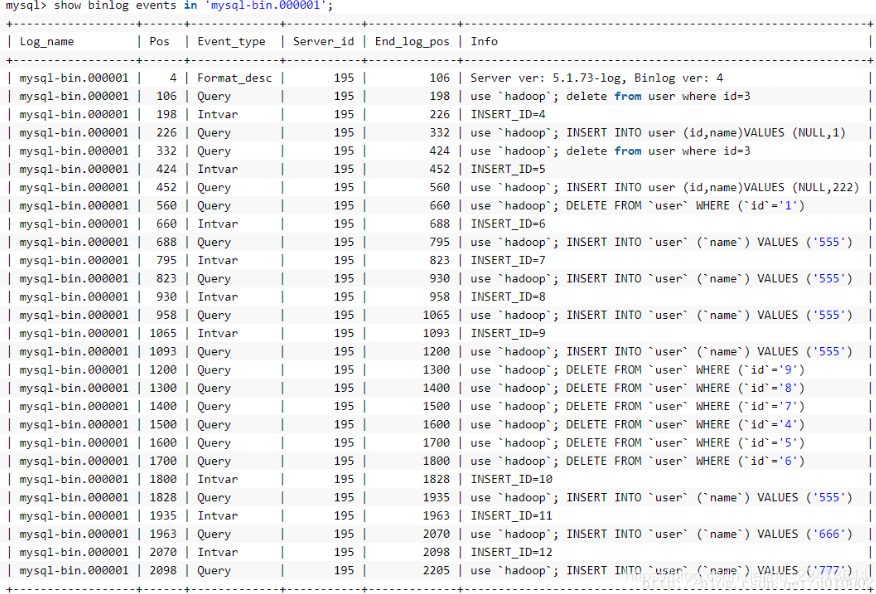
查看指定binlog文件的内容
mysql> show binlog events in 'mysql-bin.000002'; 或者cat /var/lib/mysql/mysql-bin.000002
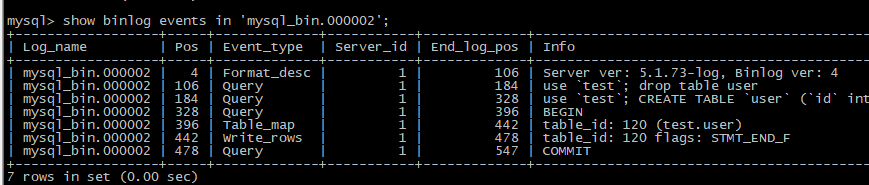
-
# /var/lib/mysql/mysql-bin.000002 是二进制文件路径 -
mysqlbinlog --no-defaults --database=test --start-datetime="2017-09-17 07:21:09" --stop-datetime="2019-09-19 07:59:50" mysql_bin.000002 > sanjiaomao.txt -
mysqlbinlog --no-defaults --database=test --start-datetime="2017-09-17 07:21:09" --stop-datetime="2019-09-19 07:59:50" mysql_bin.000002 | more -
#v如果需要过滤,只查询insert,update,delete的语句,可以这样写: -
mysqlbinlog --no-defaults --database=test mysql_bin.000002 |grep update |more -
mysqlbinlog --no-defaults --start-position=2098 --stop-position=2205 -d test /var/lib/mysql/mysql_bin.000002
5、mysql工具mysqlbinlog常用参数
| mysqlbinlog命令常用参数 | 参数说明 |
| -d ,--database=name | 根据指定库拆分binlog(拆分单表binlog可通过SQL关键字过滤) |
| -r ,--result-file=name | 指定解析binlog输出SQL语句的文件 |
| -R,--read-from-remote-server | 从mysql服务器读取binlog日志,是下面参数的别名 |
| -j,--start-position=# | 读取binlog的起始位置点,#号是具体的位置点 |
| --stop-position=# | 读取binlog的停止位置点,#号是具体的位置点 |
| --start-datetime=name | 读取binlog的起始位置点,name是具体的时间,格式为:2004-12-25 11:25:26 |
| --stop-datetime=name | 读取binlog的停止位置点,name是具体的时间,格式为:2004-12-25 11:25:26 |
| --base64-output=decode-rows | 解析row级别binlog日志的方法,例如:mysqlbinlog --base64-output=decode-rows -v mysqlbin.000016 |
方式一:mysql-binlog-connector-java
-
import com.github.shyiko.mysql.binlog.BinaryLogClient; -
import com.github.shyiko.mysql.binlog.event.Event; -
public class BinlogParse { -
public static void main(String[] args) throws Exception { -
final BinaryLogClient client = new BinaryLogClient("10.23.92.189", 3306, "root", "hadoop"); -
/* -
这里需要注意的是,如果你不指定如下参数,程序将从mysql当前binlog位置开始同步数据, -
这显然不是我们需要的,更多的时候我们需要灵活的从任意位置读取数据 -
*/ -
client.setBinlogFilename("mysql-bin.000002"); -
client.setBinlogPosition(123); //从指定的位置读取binlog,具体位置可以在mysql中查看 -
client.registerEventListener(new BinaryLogClient.EventListener() { -
public void onEvent(Event event) { -
System.out.println(event.toString()); -
System.out.println(client.getBinlogPosition()); -
} -
}); -
client.connect(); -
} -
} -
/*...之后我手动登录到mysql,分别进行了updata,insert,delete,监听到的log如下: -
Event{header=EventHeaderV4{timestamp=1529247253000, eventType=TABLE_MAP, serverId=1, headerLength=19, dataLength=34, nextPosition=346, flags=0}, data=TableMapEventData{tableId=110, database='testdb', table='hello', columnTypes=8, 15, columnMetadata=0, 40, columnNullability={1}}} -
Event{header=EventHeaderV4{timestamp=1529247253000, eventType=EXT_UPDATE_ROWS, serverId=1, headerLength=19, dataLength=46, nextPosition=411, flags=0}, data=UpdateRowsEventData{tableId=110, includedColumnsBeforeUpdate={0, 1}, includedColumns={0, 1}, rows=[ -
{before=[3, Will], after=[3, David]} -
]}} -
... -
Event{header=EventHeaderV4{timestamp=1529247347000, eventType=TABLE_MAP, serverId=1, headerLength=19, dataLength=34, nextPosition=634, flags=0}, data=TableMapEventData{tableId=110, database='testdb', table='hello', columnTypes=8, 15, columnMetadata=0, 40, columnNullability={1}}} -
Event{header=EventHeaderV4{timestamp=1529247347000, eventType=EXT_WRITE_ROWS, serverId=1, headerLength=19, dataLength=31, nextPosition=684, flags=0}, data=WriteRowsEventData{tableId=110, includedColumns={0, 1}, rows=[ -
[4, Frank] -
]}} -
... -
Event{header=EventHeaderV4{timestamp=1529247404000, eventType=TABLE_MAP, serverId=1, headerLength=19, dataLength=34, nextPosition=907, flags=0}, data=TableMapEventData{tableId=110, database='testdb', table='hello', columnTypes=8, 15, columnMetadata=0, 40, columnNullability={1}}} -
Event{header=EventHeaderV4{timestamp=1529247404000, eventType=EXT_DELETE_ROWS, serverId=1, headerLength=19, dataLength=30, nextPosition=956, flags=0}, data=DeleteRowsEventData{tableId=110, includedColumns={0, 1}, rows=[ -
[2, Bill] -
]}} -
*/
读出来的binlog日志我们会封装成一个json字符串push到kafka,然后再从kafka消费数据到数仓,这样的话数仓中就有最实时的数据,olap引擎采用impala
需要注意的是delete from table 这种操作,表中数据是一条一条删除,如果表中数据非常大的话binlog日志也会非常大
二、和上面同样代码 https://www.jb51.net/article/166757.htm
-
public static void main(String[] args) { -
BinaryLogClient client = new BinaryLogClient("hostname", 3306, "username", "passwd"); -
EventDeserializer eventDeserializer = new EventDeserializer(); -
eventDeserializer.setCompatibilityMode( -
EventDeserializer.CompatibilityMode.DATE_AND_TIME_AS_LONG, -
EventDeserializer.CompatibilityMode.CHAR_AND_BINARY_AS_BYTE_ARRAY -
); -
client.setEventDeserializer(eventDeserializer); -
client.registerEventListener(new BinaryLogClient.EventListener() { @ -
Override -
public void onEvent(Event event) { -
// TODO -
dosomething(); -
logger.info(event.toString()); -
} -
}); -
client.connect(); -
} -
/** -
这个完全是根据官方教程里面写的,在onEvent里面可以写自己的业务逻辑,由于我只是测试,所以我在里面将每一个event都打印了出来. -
之后我手动登录到mysql,分别进行了增加,修改,删除操作,监听到的log如下: -
00:23:13.331 [main] INFO util.MysqlBinLog - Event{header=EventHeaderV4{timestamp=0, eventType=ROTATE, serverId=1, headerLength=19, dataLength=28, nextPosition=0, flags=32}, data=RotateEventData{binlogFilename='mysql-bin.000001', binlogPosition=886}} -
00:23:13.334 [main] INFO util.MysqlBinLog - Event{header=EventHeaderV4{timestamp=1556468403000, eventType=FORMAT_DESCRIPTION, serverId=1, headerLength=19, dataLength=100, nextPosition=0, flags=0}, data=FormatDescriptionEventData{binlogVersion=4, serverVersion='5.7.23-0ubuntu0.16.04.1-log', headerLength=19, dataLength=95}} -
00:23:23.715 [main] INFO util.MysqlBinLog - Event{header=EventHeaderV4{timestamp=1556468603000, eventType=ANONYMOUS_GTID, serverId=1, headerLength=19, dataLength=46, nextPosition=951, flags=0}, data=null} -
00:23:23.716 [main] INFO util.MysqlBinLog - Event{header=EventHeaderV4{timestamp=1556468603000, eventType=QUERY, serverId=1, headerLength=19, dataLength=51, nextPosition=1021, flags=8}, data=QueryEventData{threadId=4, executionTime=0, errorCode=0, database='pf', sql='BEGIN'}} -
00:23:23.721 [main] INFO util.MysqlBinLog - Event{header=EventHeaderV4{timestamp=1556468603000, eventType=TABLE_MAP, serverId=1, headerLength=19, dataLength=32, nextPosition=1072, flags=0}, data=TableMapEventData{tableId=108, database='pf', table='student', columnTypes=15, 3, columnMetadata=135, 0, columnNullability={}}} -
00:23:23.724 [main] INFO util.MysqlBinLog - Event{header=EventHeaderV4{timestamp=1556468603000, eventType=EXT_WRITE_ROWS, serverId=1, headerLength=19, dataLength=23, nextPosition=1114, flags=0}, data=WriteRowsEventData{tableId=108, includedColumns={0, 1}, rows=[ -
[[B@546a03af, 2] -
]}} -
00:23:23.725 [main] INFO util.MysqlBinLog - Event{header=EventHeaderV4{timestamp=1556468603000, eventType=XID, serverId=1, headerLength=19, dataLength=12, nextPosition=1145, flags=0}, data=XidEventData{xid=28}} -
00:23:55.872 [main] INFO util.MysqlBinLog - Event{header=EventHeaderV4{timestamp=1556468635000, eventType=ANONYMOUS_GTID, serverId=1, headerLength=19, dataLength=46, nextPosition=1210, flags=0}, data=null} -
00:23:55.872 [main] INFO util.MysqlBinLog - Event{header=EventHeaderV4{timestamp=1556468635000, eventType=QUERY, serverId=1, headerLength=19, dataLength=51, nextPosition=1280, flags=8}, data=QueryEventData{threadId=4, executionTime=0, errorCode=0, database='pf', sql='BEGIN'}} -
00:23:55.873 [main] INFO util.MysqlBinLog - Event{header=EventHeaderV4{timestamp=1556468635000, eventType=TABLE_MAP, serverId=1, headerLength=19, dataLength=32, nextPosition=1331, flags=0}, data=TableMapEventData{tableId=108, database='pf', table='student', columnTypes=15, 3, columnMetadata=135, 0, columnNullability={}}} -
00:23:55.875 [main] INFO util.MysqlBinLog - Event{header=EventHeaderV4{timestamp=1556468635000, eventType=EXT_UPDATE_ROWS, serverId=1, headerLength=19, dataLength=31, nextPosition=1381, flags=0}, data=UpdateRowsEventData{tableId=108, includedColumnsBeforeUpdate={0, 1}, includedColumns={0, 1}, rows=[ -
{before=[[B@6833ce2c, 1], after=[[B@725bef66, 3]} -
]}} -
00:23:55.875 [main] INFO util.MysqlBinLog - Event{header=EventHeaderV4{timestamp=1556468635000, eventType=XID, serverId=1, headerLength=19, dataLength=12, nextPosition=1412, flags=0}, data=XidEventData{xid=41}} -
00:24:22.333 [main] INFO util.MysqlBinLog - Event{header=EventHeaderV4{timestamp=1556468662000, eventType=ANONYMOUS_GTID, serverId=1, headerLength=19, dataLength=46, nextPosition=1477, flags=0}, data=null} -
00:24:22.334 [main] INFO util.MysqlBinLog - Event{header=EventHeaderV4{timestamp=1556468662000, eventType=QUERY, serverId=1, headerLength=19, dataLength=51, nextPosition=1547, flags=8}, data=QueryEventData{threadId=4, executionTime=0, errorCode=0, database='pf', sql='BEGIN'}} -
00:24:22.334 [main] INFO util.MysqlBinLog - Event{header=EventHeaderV4{timestamp=1556468662000, eventType=TABLE_MAP, serverId=1, headerLength=19, dataLength=32, nextPosition=1598, flags=0}, data=TableMapEventData{tableId=108, database='pf', table='student', columnTypes=15, 3, columnMetadata=135, 0, columnNullability={}}} -
00:24:22.335 [main] INFO util.MysqlBinLog - Event{header=EventHeaderV4{timestamp=1556468662000, eventType=EXT_DELETE_ROWS, serverId=1, headerLength=19, dataLength=23, nextPosition=1640, flags=0}, data=DeleteRowsEventData{tableId=108, includedColumns={0, 1}, rows=[ -
[[B@1888ff2c, 3] -
]}} -
00:24:22.335 [main] INFO util.MysqlBinLog - Event{header=EventHeaderV4{timestamp=1556468662000, eventType=XID, serverId=1, headerLength=19, dataLength=12, nextPosition=1671, flags=0}, data=XidEventData{xid=42}} -
*/
实现思路
- 支持对单个表的监听,因为我们不想真的对所有数据库中的所有数据表进行监听.
- 可以多线程消费.
- 把监听到的内容转换成我们喜闻乐见的形式(文中的数据结构不一定很好,我没想到更加合适的了).
实现思路大致如下:
- 封装个客户端,对外只提供获取方法,屏蔽掉初始化的细节代码.
- 提供注册监听器(伪)的方法,可以注册对某个表的监听(重新定义一个监听接口,所有注册的监听器实现这个就好).
- 真正的监听器只有客户端,他将此数据库实例上的所有操作,全部监听到并转换成我们想要的格式LogItem放进阻塞队列里面.
- 启动多个线程,消费阻塞队列,对某一个LogItem调用对应的数据表的监听器,做一些业务逻辑.
-
//初始化代码: -
public MysqlBinLogListener(Conf conf) { -
BinaryLogClient client = new BinaryLogClient(conf.host, conf.port, conf.username, conf.passwd); -
EventDeserializer eventDeserializer = new EventDeserializer(); -
eventDeserializer.setCompatibilityMode( -
EventDeserializer.CompatibilityMode.DATE_AND_TIME_AS_LONG, -
EventDeserializer.CompatibilityMode.CHAR_AND_BINARY_AS_BYTE_ARRAY -
); -
client.setEventDeserializer(eventDeserializer); -
this.parseClient = client; -
this.queue = new ArrayBlockingQueue < > (1024); -
this.conf = conf; -
listeners = new ConcurrentHashMap < > (); -
dbTableCols = new ConcurrentHashMap < > (); -
this.consumer = Executors.newFixedThreadPool(consumerThreads); -
} -
//注册代码: -
public void regListener(String db, String table, BinLogListener listener) throws Exception { -
String dbTable = getdbTable(db, table); -
Class.forName("com.mysql.jdbc.Driver"); -
// 保存当前注册的表的colum信息 -
Connection connection = DriverManager.getConnection("jdbc:mysql://" + conf.host + ":" + conf.port, conf.username, conf.passwd); -
Map < String, Colum > cols = getColMap(connection, db, table); -
dbTableCols.put(dbTable, cols); -
// 保存当前注册的listener -
List < BinLogListener > list = listeners.getOrDefault(dbTable, new ArrayList < > ()); -
list.add(listener); -
listeners.put(dbTable, list); -
} -
//在这个步骤中,我们在注册监听者的同时,获得了该表的schema信息,并保存到map里面去,方便后续对数据进行处理. -
//监听代码: -
@Override -
public void onEvent(Event event) { -
EventType eventType = event.getHeader().getEventType(); -
if (eventType == EventType.TABLE_MAP) { -
TableMapEventData tableData = event.getData(); -
String db = tableData.getDatabase(); -
String table = tableData.getTable(); -
dbTable = getdbTable(db, table); -
} -
// 只处理添加删除更新三种操作 -
if (isWrite(eventType) || isUpdate(eventType) || isDelete(eventType)) { -
if (isWrite(eventType)) { -
WriteRowsEventData data = event.getData(); -
for (Serializable[] row: data.getRows()) { -
if (dbTableCols.containsKey(dbTable)) { -
LogItem e = LogItem.itemFromInsert(row, dbTableCols.get(dbTable)); -
e.setDbTable(dbTable); -
queue.add(e); -
} -
} -
} -
} -
} -
//消费代码: -
public void parse() throws IOException { -
parseClient.registerEventListener(this); -
for (int i = 0; i < consumerThreads; i++) { -
consumer.submit(() - > { -
while (true) { -
if (queue.size() > 0) { -
try { -
LogItem item = queue.take(); -
String dbtable = item.getDbTable(); -
listeners.get(dbtable).forEach(l - > { -
l.onEvent(item); -
}); -
} catch (InterruptedException e) { -
e.printStackTrace(); -
} -
} -
Thread.sleep(1000); -
} -
}); -
} -
parseClient.connect(); -
} -
//消费时,从队列中获取item,之后获取对应的一个或者多个监听者,分别消费这个item. -
//测试代码: -
public static void main(String[] args) throws Exception { -
Conf conf = new Conf(); -
conf.host = "hostname"; -
conf.port = 3306; -
conf.username = conf.passwd = "hhsgsb"; -
MysqlBinLogListener mysqlBinLogListener = new MysqlBinLogListener(conf); -
mysqlBinLogListener.parseArgsAndRun(args); -
mysqlBinLogListener.regListener("pf", "student", item - > { -
System.out.println(new String((byte[]) item.getAfter().get("name"))); -
logger.info("insert into {}, value = {}", item.getDbTable(), item.getAfter()); -
}); -
mysqlBinLogListener.regListener("pf", "teacher", item - > System.out.println("teacher ====")); -
mysqlBinLogListener.parse(); -
}
在这段很少的代码里,注册了两个监听者,分别监听student和teacher表,并分别进行打印处理,经测试,在teacher表插入数据时,可以独立的运行定义的业务逻辑.
注意:这里的工具类并不能直接投入使用,因为里面有许多的异常处理没有做,且功能仅监听了插入语句,可以用来做实现的参考.
方式二、基于Spark Streaming + Canal + Kafka对Mysql增量数据实时进行监测分析
基于Spark Streaming + Canal + Kafka对Mysql增量数据实时进行监测分析https://blog.csdn.net/github_39577257/article/details/88661052
方式三、基于Maxwell详解
-
MySQL 配置权限 -
--创建 用户 -
mysql> CREATE USER canal IDENTIFIED BY 'canal'; -
mysql>CREATE USER 'maxwell_sync'@'%' IDENTIFIED BY '123456'; -
-- % : 匹配所有主机 -
-- Maxwell需要在待同步的库上建立schema_database库,将状态存储在`schema_database`选项指定的数据库中(默认为`maxwell`) -
--授权 -
#全部权限 -
mysql> GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ; -
mysql> GRANT ALL PRIVILEGES ON *.* TO ‘username’@‘%’ IDENTIFIED BY 'password'; -
mysql> grant all privileges on databasename.* to username; -
mysql> GRANT ALL PRIVILEGES on maxwell.* to 'maxwell_sync'@'192.168.85.133'; -
--解释:grant all指的是授权所有操作权限(增删改查),*.*指的是所有数据库,maxwell指的是数据库名,maxwell_sync是用户,192.168.85.133指的是所要授权的远程IP地址 -
mysql>GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'maxwell_sync'@'%'; -
#部分权限 -
mysql> grant select,insert,update,delete,create on databasename.* to username; -
mysql>FLUSH PRIVILEGES; -- 刷新mysql用户权限,使修改生效
启动Maxwell
-
主要是配置config.properties文件,重要的配置参考如下: -
log_level=info -
host= -
user= -
password= -
port= -
jdbc_options=autoReconnect=true // mysql 超时重连 -
schema_database= // 用于在mysql中新建一个binlog相关的数据库实例 -
producer=kafka -
kafka.bootstrap.servers= -
kafka_topic= -
kafka.compression.type=snappy -
kafka.retries=1 -
kafka.acks=1 -
kinesis_stream=maxwell -
include_dbs= // 需要处理的数据库实例 -
include_tables= // 需要处理的表格,用逗号分隔 -
kafka_version=0.9.0.1 -
client_id= // 标识符,可以包含英文 -
replica_server_id= // 只能是数字 -
expire_logs_days=0 //防止binlog断,maxwell失败 -
# 可以用配置文件,也可以直接跟参数 -
启动maxwell 配置文件 -
nohup bin/maxwell --config config.properties --log_level DEBUG &
-
#输出到kafka -
bin/maxwell --user='maxwell_sync' -
--password='123456' -
--host='192.168.85.133' -
--port=3306 -
--producer=kafka -
--kafka.bootstrap.servers=192.168.85.133:9092 -
--kafka_version=0.9 -
--kafka_topic=mysql_binlog -
可以多跟几个参数对mysql的binlog进行过滤,只筛选某些数据库里的某些表 -
include_dbs, -
exclude_dbs, -
include_tables, -
exclude_tables -
#抽取多个库可添加include_dbs,逗号分隔 -
#指定数据表 include_tables ,逗号分隔 -
#maxwell模拟mysql slave,所以多个maxwell进程时,每个进程的client.id及replica_server_id保证不同 -
#binlog如果断了,可能会maxwell失败,最好设置mysql的expire_logs_days=0 -
#输出到控制台用如下配置 -
bin/maxwell --user='maxwell_sync' --password='123456' --host='192.168.85.133' --producer=stdout
测试STDOUT:
-
mysql> insert into ruozedata(id,name,age,address) values(999,'jepson',18,'www.ruozedata.com'); -
maxwell输出: -
{ -
"database": "ruozedb", -
"table": "ruozedata", -
"type": "insert", -
"ts": 1525959044, -
"xid": 201, -
"commit": true, -
"data": { -
"id": 999, -
"name": "jepson", -
"age": 18, -
"address": "www.ruozedata.com", -
"createtime": "2018-05-10 13:30:44", -
"creuser": null, -
"updatetime": "2018-05-10 13:30:44", -
"updateuser": null -
} -
}
-
mysql> update ruozedata set age=29 where id=999; -
问题: ROW,你觉得binlog更新几个字段? -
maxwell输出: -
{ -
"database": "ruozedb", -
"table": "ruozedata", -
"type": "update", -
"ts": 1525959208, -
"xid": 255, -
"commit": true, -
"data": { -
"id": 999, -
"name": "jepson", -
"age": 29, -
"address": "www.ruozedata.com", -
"createtime": "2018-05-10 13:30:44", -
"creuser": null, -
"updatetime": "2018-05-10 13:33:28", -
"updateuser": null -
}, -
"old": { -
"age": 18, -
"updatetime": "2018-05-10 13:30:44" -
} -
}
改变数据库内容可看到如下结果:

启动kafka
-
#开启kafka消费者 -
kafka-console-consumer.sh --zookeeper localhost:2181 --topic rotopic --from-beginning
1、Merge
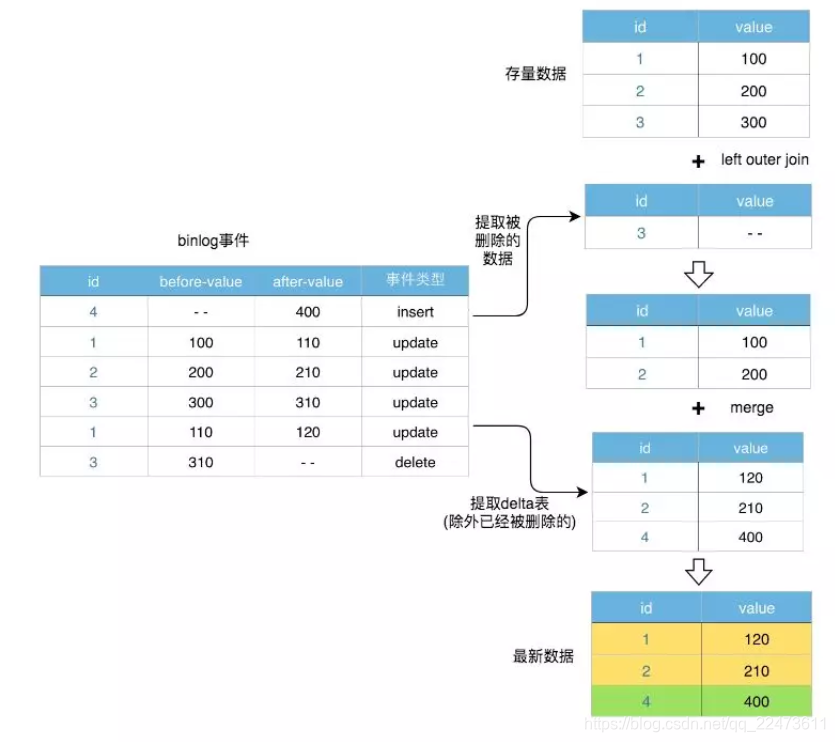
Binlog成功入仓后,下一步要做的就是基于Binlog对MySQL数据进行还原。Merge流程做了两件事,首先把当天生成的Binlog数据存放到Delta表中,然后和已有的存量数据做一个基于主键的Merge。Delta表中的数据是当天的最新数据,当一条数据在一天内发生多次变更时,Delta表中只存储最后一次变更后的数据。
把Delta数据和存量数据进行Merge的过程中,需要有唯一键来判定是否是同一条数据。如果同一条数据既出现在存量表中,又出现在Delta表中,说明这一条数据发生了更新,则选取Delta表的数据作为最终结果;否则说明没有发生任何变动,保留原来存量表中的数据作为最终结果。Merge的结果数据会Insert Overwrite到原表中,即图中的origindb.table。
Merge流程举例
下面用一个例子来具体说明Merge的流程。

数据表共id、value两列,其中id是主键。在提取Delta数据时,对同一条数据的多次更新,只选择最后更新的一条。所以对id=1的数据,Delta表中记录最后一条更新后的值value=120。Delta数据和存量数据做Merge后,最终结果中,新插入一条数据(id=4),两条数据发生了更新(id=1和id=2),一条数据未变(id=3)。
默认情况下,我们采用MySQL表的主键作为这一判重的唯一键,业务也可以根据实际情况配置不同于MySQL的唯一键。
合并更新删除操作 : https://blog.csdn.net/qq_22473611/article/details/102901625
2、Delete删除
Delete操作在MySQL中非常常见,由于Hive不支持Delete,如果想把MySQL中删除的数据在Hive中删掉,需要采用“迂回”的方式进行。
对需要处理Delete事件的Merge流程,采用如下两个步骤:
-
首先,提取出发生了Delete事件的数据,由于Binlog本身记录了事件类型,这一步很容易做到。将存量数据(表A)与被删掉的数据(表B)在主键上做左外连接(Left outer join),如果能够全部join到双方的数据,说明该条数据被删掉了。因此,选择结果中表B对应的记录为NULL的数据,即是应当被保留的数据。
-
然后,对上面得到的被保留下来的数据,按照前面描述的流程做常规的Merge。
-
二、Kafka Connect 实现MySQL增量同步(A表实时同步到B表)
https://www.jianshu.com/p/46b6fa53cae4
3. Kafka Connect
3.1 Connector
Kafka Connect是一个用于Kafka和其他数据系统之间进行数据传输的工具,它可以实现基于Kafka的数据管道,打通上下游数据源。我们需要做的就是在Kafka Connect服务上运行一个Connector,这个Connector是具体实现如何从/向数据源中读/写数据。Confluent提供了很多Connector实现,你可以在这里下载。不过今天我们使用Debezium提供的一个MySQL Connector插件,下载地址。
下载这个插件,并将解压出来的jar包全部拷贝到kafka lib目录下。注意:需要将这些jar包拷贝到Kafka集群所有机器上。
本文将使用Kafka Connect 实现MySQL增量同步,设计三种模式,分别为incrementing、timestamp、 timestamp+incrementing
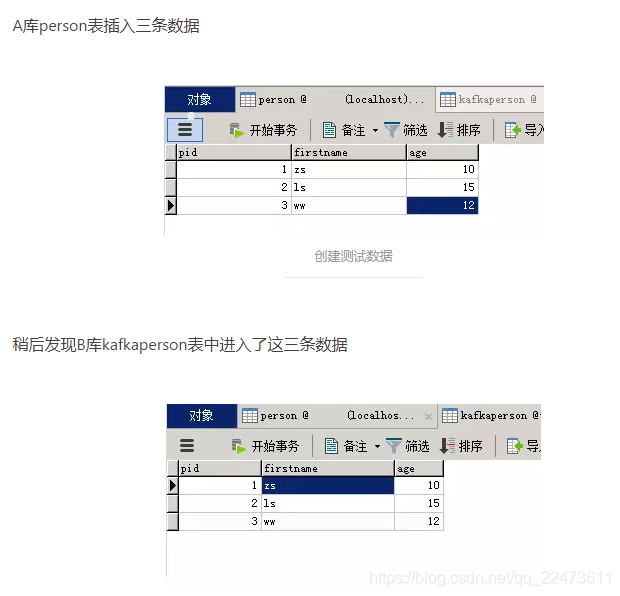
1、incrementing 自增模式(A表实时同步到B表)
切换目录 *\kafka_2.11-2.0.1\config
quickstart-mysql.properties(source)
-
name=mysql-a-source-person -
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector -
tasks.max=1 -
connection.url=jdbc:mysql://localhost:3306/A?user=***&password=*** -
# incrementing 自增 -
mode=incrementing -
# 自增字段 pid -
incrementing.column.name=pid -
# 白名单表 person -
table.whitelist=person -
# topic前缀 mysql-kafka- -
topic.prefix=mysql-kafka-
quickstart-mysql-sink.properties(sink)
-
name=mysql-a-sink-person -
connector.class=io.confluent.connect.jdbc.JdbcSinkConnector -
tasks.max=1 -
#kafka的topic名称 -
topics=mysql-kafka-person -
# 配置JDBC链接 -
connection.url=jdbc:mysql://localhost:3306/B?user=***&password=*** -
# 不自动创建表,如果为true,会自动创建表,表名为topic名称 -
auto.create=false -
# upsert model更新和插入 -
insert.mode=upsert -
# 下面两个参数配置了以pid为主键更新 -
pk.mode = record_value -
pk.fields = pid -
#表名为kafkatable -
table.name.format=kafkaperson
启动 Kafka Connect
-
D:\com\kafka_2.11-2.0.1\bin\windows>connect-standalone.bat -
D:/com/kafka_2.11-2.0.1/config/connect-standalone.properties -
D:/com/kafka_2.11-2.0.1/config/quickstart-mysql.properties -
D:/com/kafka_2.11-2.0.1/config/quickstart-mysql-sink.properties
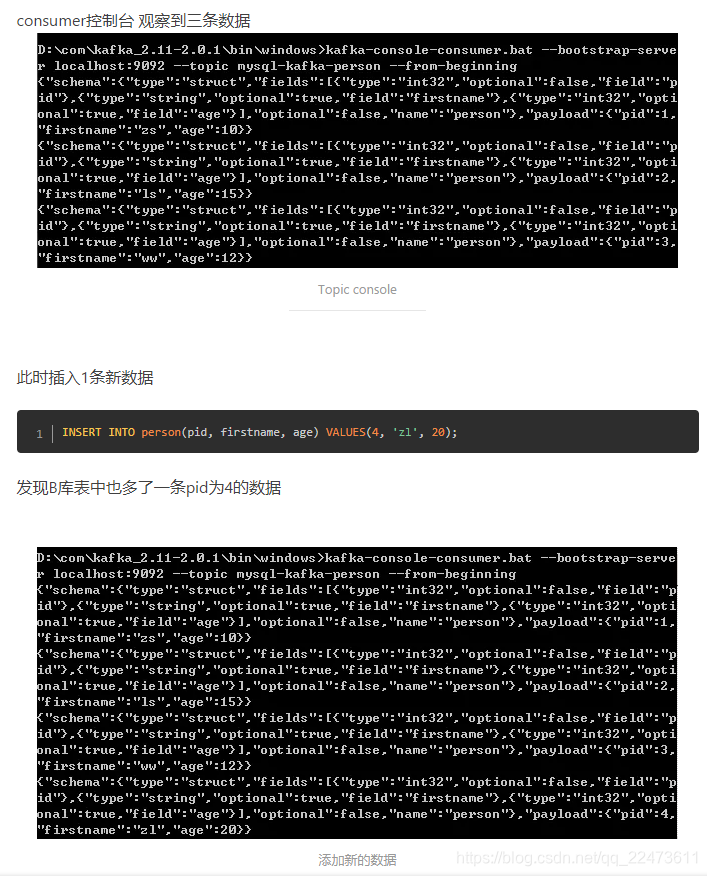
2、timestamp 时间戳模式
D:\com\kafka_2.11-2.0.1\config
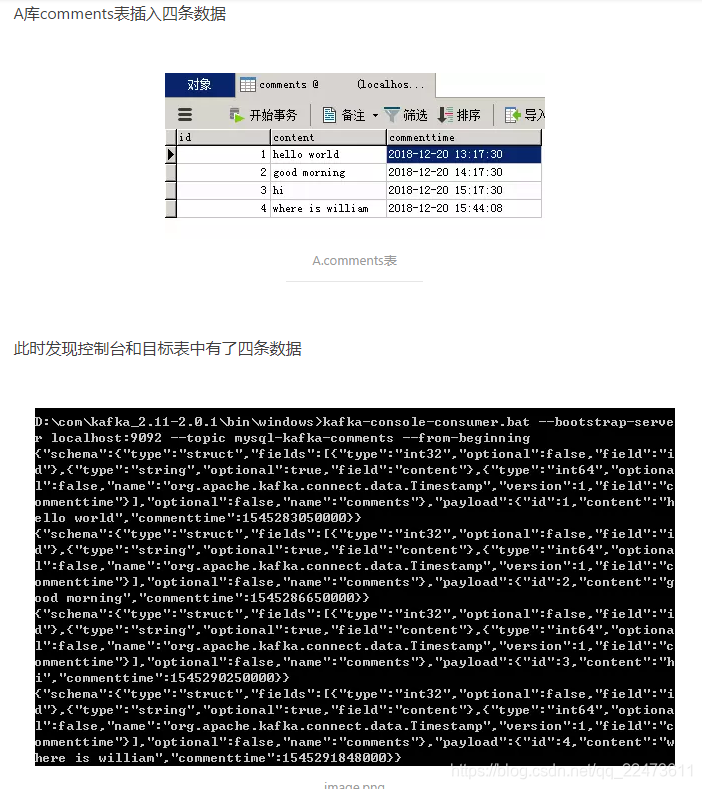
timestamp-mysql-source.properties(source)
-
name=mysql-b-source-comments -
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector -
tasks.max=1 -
connection.url=jdbc:mysql://localhost:3306/A?user=***&password=*** -
table.whitelist=comments -
mode=timestamp -
timestamp.column.name=commenttime -
topic.prefix=mysql-kafka-
timestamp-mysql-sink.properties(sink)
-
name=mysql-b-sink-comments -
connector.class=io.confluent.connect.jdbc.JdbcSinkConnector -
tasks.max=1 -
#kafka的topic名称 -
topics=mysql-kafka-comments -
# 配置JDBC链接 -
connection.url=jdbc:mysql://localhost:3306/B?user=***&password=*** -
# 不自动创建表,如果为true,会自动创建表,表名为topic名称 -
auto.create=false -
# upsert model更新和插入 -
insert.mode=upsert -
# 下面两个参数配置了以id为主键更新 -
pk.mode = record_value -
pk.fields = id -
#表名为kafkatable -
table.name.format=kafkacomments
-
D:\com\kafka_2.11-2.0.1\bin\windows>connect-standalone.bat -
D:/com/kafka_2.11-2.0.1/config/connect-standalone.properties -
D:/com/kafka_2.11-2.0.1/config/timestamp-mysql-source.properties -
D:/com/kafka_2.11-2.0.1/config/timestamp-mysql-sink.properties
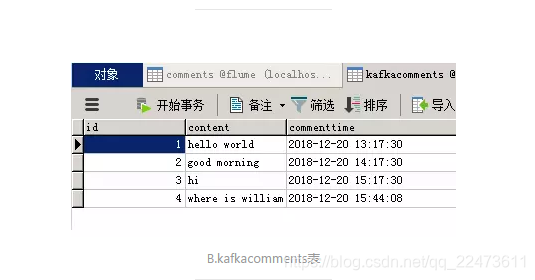
此时修改id为2和4的内容content,并修改评论时间commenttime
update comments set content = "show test data" ,commenttime="2018-12-20 15:55:10" where id in(2,4)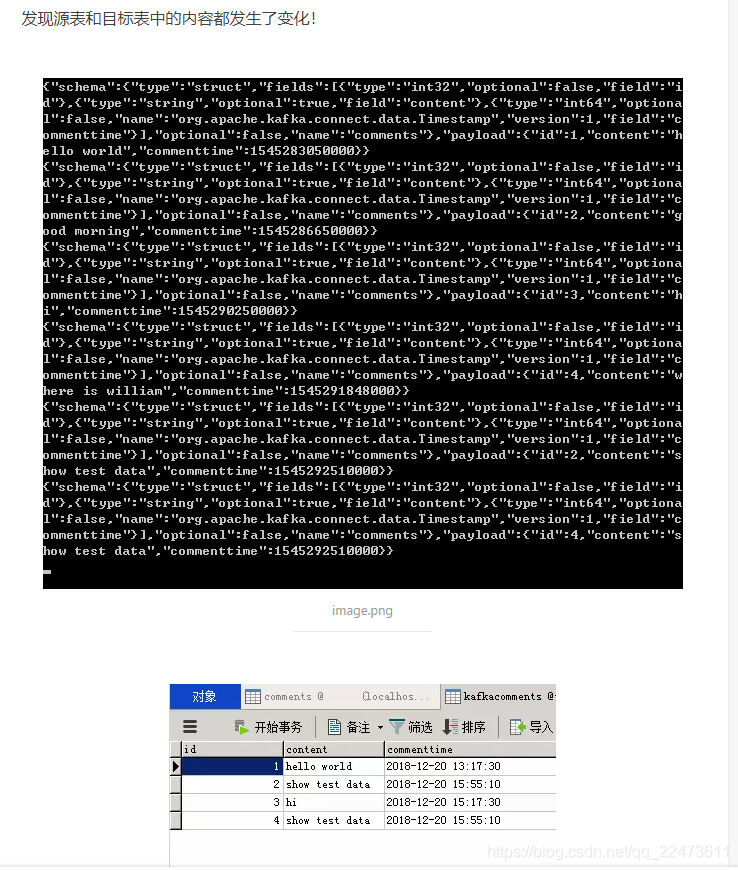
3、timestamp+incrementing 时间戳自增混合模式
实验过程同方法2不做赘述,唯一变动的是source的config文件
-
name=mysql-b-source-comments -
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector -
tasks.max=1 -
connection.url=jdbc:mysql://localhost:3306/A?user=***&password=*** -
table.whitelist=comments -
mode=timestamp+incrementing -
timestamp.column.name=commenttime -
incrementing.column.name=id -
topic.prefix=mysql-kafka-