前言
前面的一篇文章:3D目标检测深度学习方法中voxel-represetnation内容综述(一)中笔者分享了如果采用voxel作为深度学习网络输入的backbone的几个重要的模块。也就是目前比较流行的One-stage的方法SECOND的1.5版本,在KITTI和Nuscenes的榜单上都能算是19年比较经典和高效的方法,这一篇文章,笔者填一下上一篇文章的坑,上一篇文章中说到目前的方法可以按照精度和速度两个方面做出研究,其中因为voxel-representation的方法本身是高效的,因此主要在速度上做出研究的方法还是远远少于在精度上做文章的。
笔者看到的在精度上做文章的研究工作主要可以分为如下几种:(1)refine(2)loss(3)fusion(4)backboe -structure(5)others。
下面笔者就这几种改进方式选择一些典型的文章做一定的简单分享,如果要深入理解文章的改进,还是很需要研究文章本身和阅读其代码的。
1. Refine
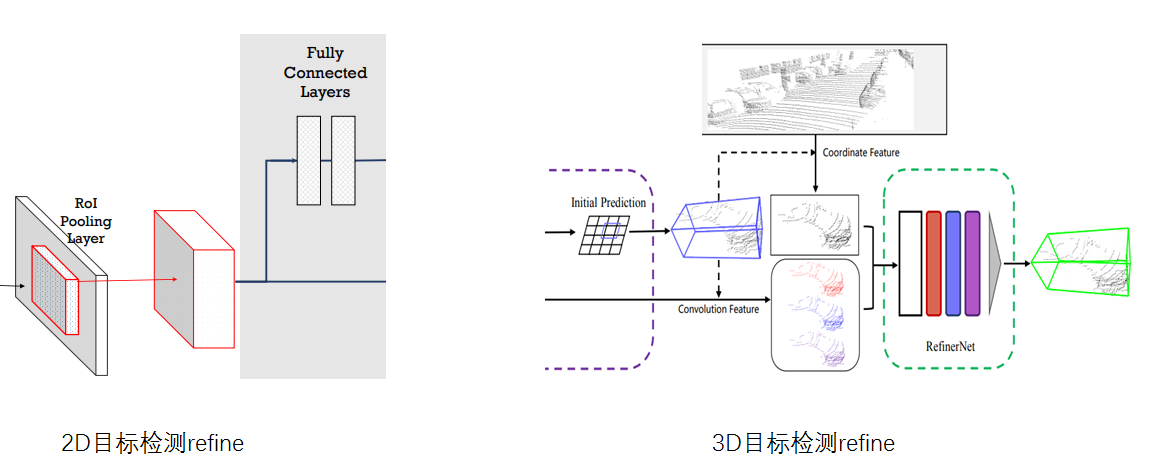
refine的工作从19年下半段的研究者做了比较多的工作,在ICCV19和NIPS19上有很多不错的工作;refine工作和二维的目标检测的RCNN系列对比起来看,可以这么理解,yolo和SSD系列的文章都是一阶段的方法,在feature-map上提出proposals后经过NMS就算结束了;refine工作就像RCNN系列的二阶段,需要对提出的proposals做一次精细的回归,但是和二维的refine工作存在不同,如下图所示,左边是笔者从fast-rcnn中结构图截出来的图,二维的refine实际上是采用roi-pooling在feature-map上对roi区域做进一步refine,利用的是feature-map的特征信息,这是因为feature-map和二维图像本身具有很多相似性,都是二维规整的表达形式。
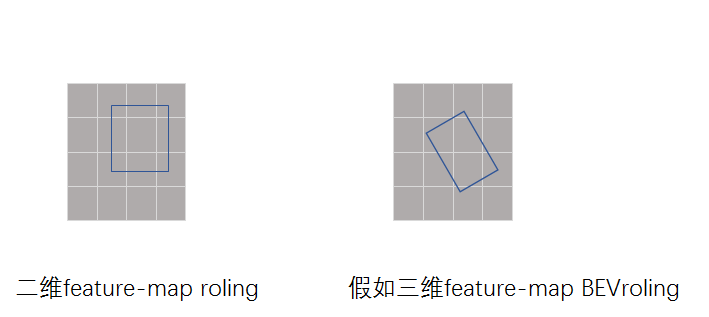
但是在三维上,voxel的方法通过二维RPN回归了7个维度(中心点,长宽高,朝向),如果采用在feature-map上做roi-pooling,那么只能丢失高度信息截取feature信息,同时会存在一个朝向导致BBox不是平行于feature-map边界的问题(在二维中回归的Bbox都是平行于feature-map的边界的)。如下图表达的问题所示,如果三维feature-map上做BEV的roi-pooling就需要进一步提取和feature-map边界不平行的特征,这也是需要考虑和研究怎么做的,因为笔者没研究过,而且目前也没有着方面的研究工作,所以这里也只是抛砖引玉一下。回到正题,和二维refine不一样的是,如上图右边,三维中的roi-pooing目前都是在三维空间做的,而refine-network也是借助pointnet来做的。但是如何在三维空间的point上做refine,不同的文文章有不同的处理方法。
1.1 Fast-PointRcnn
ICCV19上的文章,文章链接 :https://arxiv.org/pdf/1908.02990
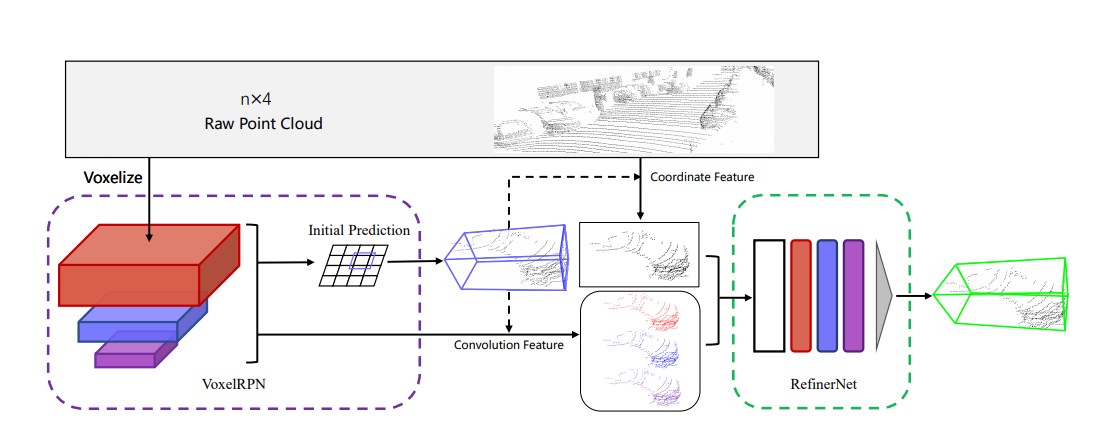
如下图,这是一个两阶段的方法,第一个阶段是体素化,采用Voxel-RPN网络产生少量的预测,然后第二阶段采用注意力机制通过结合坐标信息和提取到的特征信息获得每个预测框的信息,进行进一步优化。可以比较清晰的看到Voxel-RPN结构实际上也就是笔者在综述(一)中介绍到的内容。后续的refine算作是这篇文章的核心创新点。
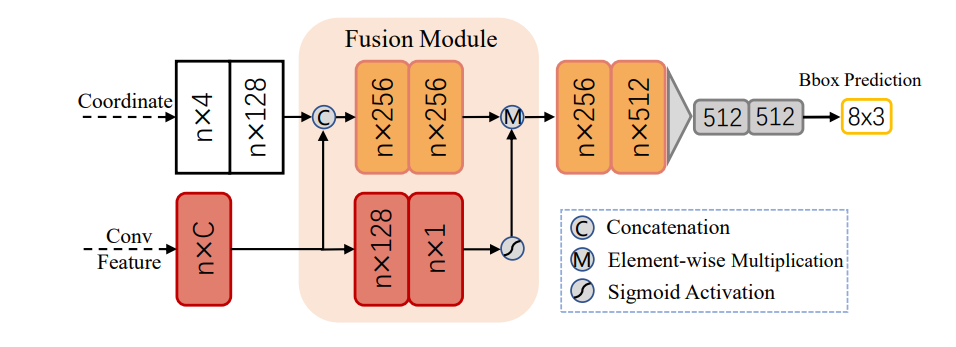
上面的Voxel-RPN结构不细讲,如下的网络结构即是作者所提出的refine-network,前文说过,在三维中的refine网络无法和二维中一样方便的利用在feature-map中的特征做优化,所以回到原始的空间点云结构中,同时把和Voxel-RPN的特征也通过索引concat到点云中。从下图中我们看到refine实际上存在两个分支,同时refine网络是MLP构建,即采用了类似pointnet的网络设计。
这里可能需要注意的是voxel-RPN网络仅仅是一个不断下采样的encoder的过程,所以可以直接建立对原始点云的空间索引,通过索引还回到点云表达上。我们可以对比前面提到的,如果在三维中feature-map上做roi-pooling,那么会存在如何处理Bbox和feature边界不平衡的问题,那么如果直接将featurea通过索引到3D点云中就不会存在这样的考虑,同时可以结合最原始的点云信息。
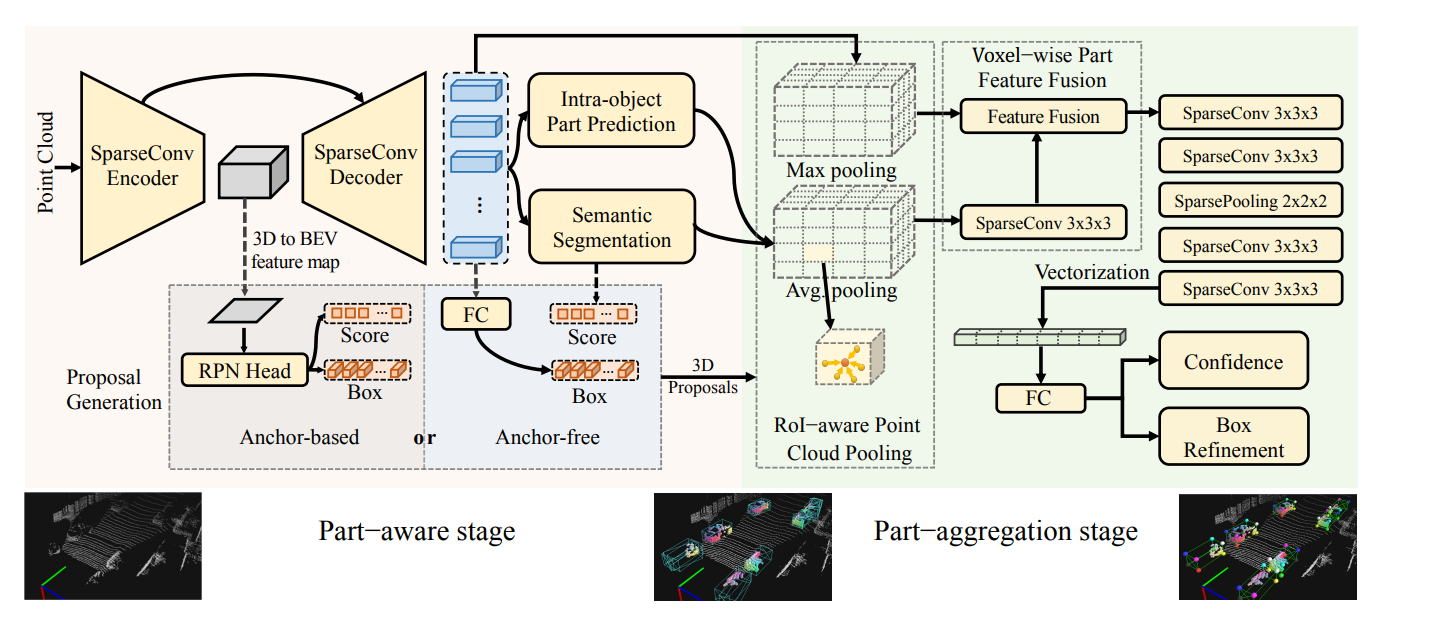
1.2 Part-A2 Net
PAMI2020的文章,文章地址:https://arxiv.org/pdf/1907.03670.pdf
网络结构图如下所示,是一个two-stage的方法,分为part-aware-stage(也就是上一篇文章中的backbone的proposals提出过程),第二个阶段则是part-aggregation -stage(也就是文章提出的refine方法);从下图的网络结构可以看出是一个encoder-decoderr的过程,笔者前文介绍的voxel-representation的backbone就是这里的encoder的过程,而本文的研究内容则是考虑通过decoder得到原始空间大小的voxels,再通过特取到的特征做进一步的refine。
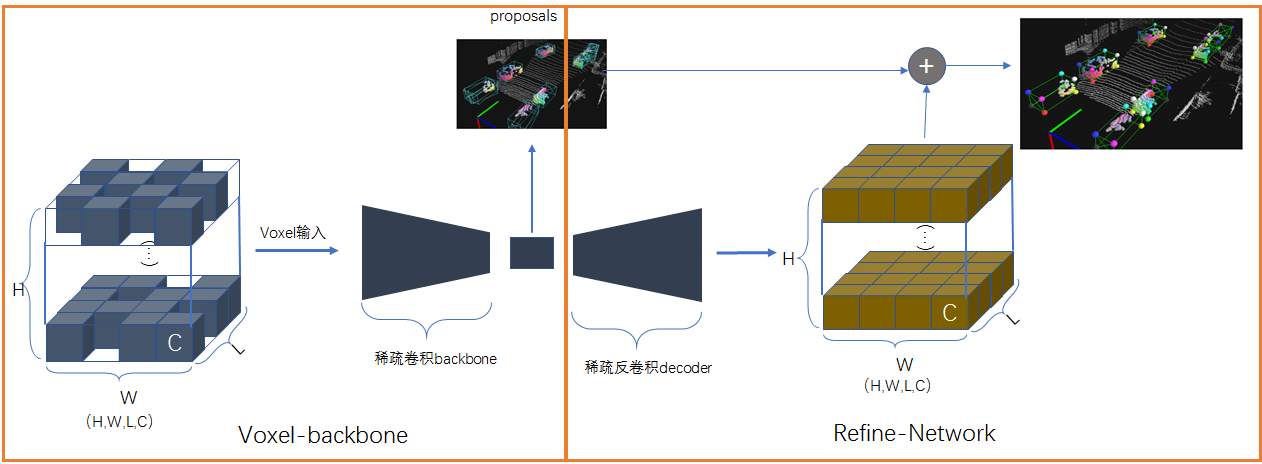
笔者把上面的文章结构图简化如下,笔者简化后可以看的更加清楚,前面这部分voxel-backbone即是综述(一)大篇幅介绍的内容,右边通过稀疏decoder可以将encoder部分提取到的特征传递给全局的voxels(这里可能会将全局的voxels,包括空的voxel都会被传递为含有特征的voxels),所以refine仅仅在proposals内部包含的voxel的特征做进一步优化,也算是在三维中的进一步优化。优化的方法是先会选择14个key-point,然后将voxel特征融合到point上,最后再采用FC连接做进一步的优化,这实际上和在fast-PointRcnn有一些类似的想法,但是该结构在decoder的部分进一步做了分割任务,可以利用到相关任务的所学习的特征对最终的Bbox做出好的优化。
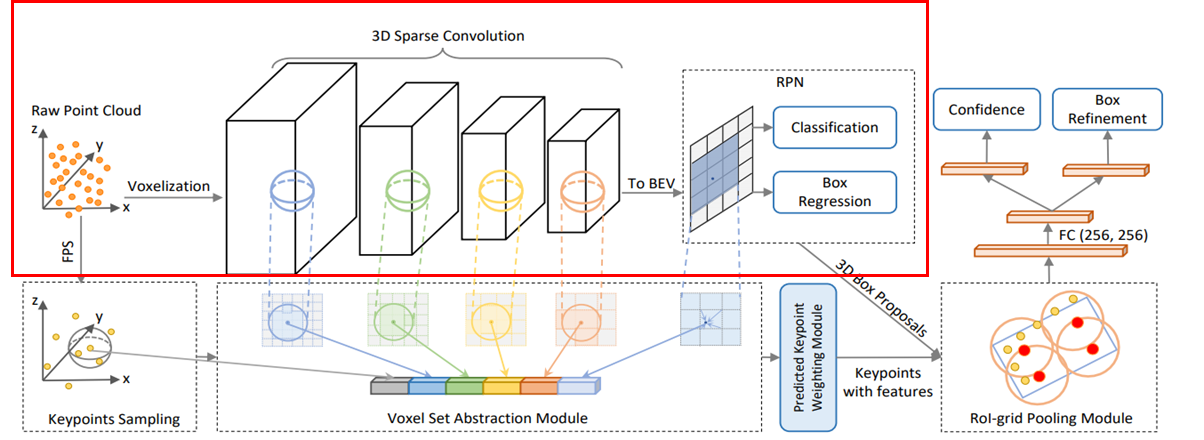
1.3 PV-RCNN
这一篇和上一篇是同一个作者,发表在CVPR20,在3D目标检测上效果表现非常好,问斩链接: https://arxiv.org/pdf/1912.13192.pdf
代码链接: https://github.com/sshaoshuai/PCDet
网络结果设计如下,其中笔者标出的红色框表示RPN网络,其余部分也就是这里主要想要谈的refine模块,可以注意到,作者在多refine的时候也是在point的基础上做refine的,而特征则是采用了multi-scale的voxel-backbone特征,将voxel特征通过转化到point表示上,并采用多层特征concat的方式,然后通过作者设计的roi-grid -pooling方式将前面的voxel多层特征转化到proposals中的grid点融合,然后再根据这些grid连接一下为优化设计的FC层即可。
1.4 refine工作小结
refine的研究工作比较多,笔者也选择了几个比较典型的研究工作做了简单的介绍,其中从上面的介绍中可以注意到:(1)refine是回到三维点山做的,和二维在feature-map做refine是不一样的(2)refine的过程是在点上采用前面提取到的特征用pointnet结构对回归的位置做精细的优化。
但是也可以看出做refine的工作各有各的方式,有就上面的几种方法,由最开始的fast-point-rcnn直接利用RPN-Feature-map到后面part-A^2采用decoder分割任务的特征做优化,以及进一步的在PV-RCNN中采用多尺度的voxel-net-feature做refine。
但是,做refine的研究目前还没有一个统一的比较好的方案,还在处于当前的研究阶段, 后续更多好的研究工作还是很值得期待的。
2 loss
从loss出发本身算不上一个最大的创新点,所以很多文章也都是稍微提出一些loss以适应自己改进的结构,这里笔者先简单叙述一下在3D检测中backbone中用到的最原始的Loss函数。如下图所示,笔者把一阶段proposals的loss函数称为RPN-LOSS,也就是由分类loss和回归loss组成,这里的分类loss一般采用focal-loss,回归loss则是采用的smooth-L1-loss,如下式,回归的回归的七个维度正是proposals的x,y,z,l,h,w和偏航角。
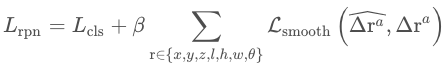
2.1 Focal Loss in 3D Object Detection
文章地址:https://arxiv.org/pdf/1809.06065.pdf
这是一篇发表在IEEE RA-L 2019上的文章,核心内容是研究了focal-loss对3D目标检测的精度的影响,focal-loss出自于文章Focal Loss for Dense Object Detection(FAIR,ICCV17),该loss是为了解决one-stage目标检测中正负样本比例严重失衡的问题。该损失函数降低了大量简单负样本在训练中所占的权重,这在自动驾驶数据集中是很基本的一个问题,无论是做分割还是检测,目前都是清一色的focal-loss。focal-loss的表达式子可以表示为如下:
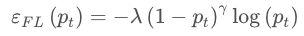
2.2 IoU Loss
文章地址是:https://arxiv.org/pdf/1908.03851
先补充一点关于IOU知识,IOU即是Intersection over Union,也就是两个Bbox之间的交集和并集的比值,如下图所示,一般在NMS和判定proposals是否为positative,在二维目标检测中IOU-loss已经被用来优化Bbox的回归项,同时还延伸出来了例如GIOU、DIOU、CIOU等不同的IOU损失函数;相比于直接回归二维中的左上角和右下角的坐标而言,IOU可以比较真实的反映预测检测框与真实检测框的检测效果。同时具有尺度不变性的特性,有兴趣的读者推荐阅读知乎上的这个回答:https://zhuanlan.zhihu.com/p/94799295。
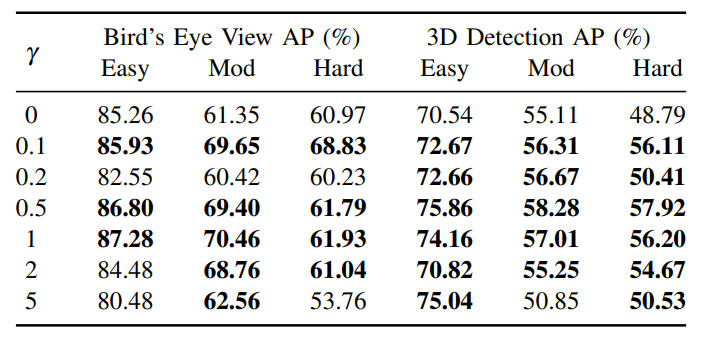
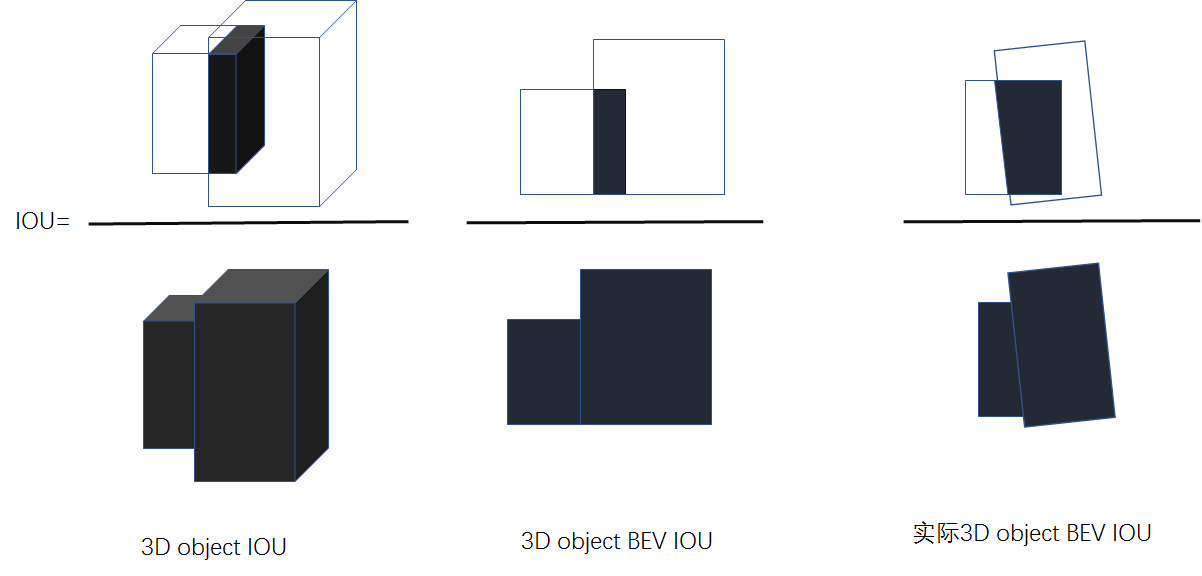
那么在三维中的IOU是啥呢,和二维一样也是对应的交叠区域和联合区域的比值,可以表示为如下,左边表示的是在原始空间坐标中IOU的计算,中间边表示的是在俯视图上丢失了高度信息后的IOU计算。但是这种交叠方式并不是真实的,在3D目标检测中因为朝向的存在,所以和二维的IOU不同之处在于交叠区域是含有yaw轴的旋转性的。所以本文就如何在3D目标检测中使用IOU-LOSS做了一定的研究。
本文的IOU-loss设计如下式子:
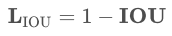
核心人物就是如何计算这里带旋转的IOU,作者按照以前的步骤进行计算:
(1)计算gt的面积,也就是先计算两点之间的距离,然后再通过长×宽的方式求得gt的面积
(2)计算预测框的面积:和计算gt同样的方式。
(3)确定重叠区域的顶点。
(4)按逆时针顺序对这些多边形顶点进行排序
(5)计算overlap
(6)得到了overlap和两个box的面积,也就得到了相应的IOU
但是这里作者指出了由于两个旋转的Bbox之间的交集的复杂性,IoU计算过程的方向传播解决方案目前还没有被深度学习框架提供。 特别是,存在一些自定义操作(两个边的相交和对顶点进行排序等),这些自定义操作的派生函数尚未在现有的深度学习框架中实现。 因此在后续作者会开源这个研究工作,期待吧。
3 补充知识
后续还有几个方面的知识留在下一次的综述内容做总结了,这里还想分享一点再3D目标检测中的anchor-free和acnhor-based方法的区别,这可能会成为后续的一个研究方向。我们知道在二维目标检测中,anchor-free方法在一阶段方法中成为了18,19年的研究大热,而在兴起不久的3D目标检测中目前的研究情况还比较少。
3.1 什么是anchor-based的方法
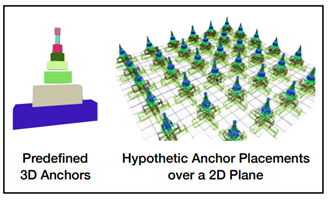
目标检测在判定proposals为positive还是negative是根据当前的proposals和gt之间的IOU决定的,但是实际上我们会首先在整个场景中设置很多的anchor,最后proposals的提出也是在anchor的基础上回归到ground-truth的偏移量。如下图所示,针对不同的类别,我们会在整个场景中设置一组anchor,也就是说网络每增加一个检测类别,相应的就需要多设置一种anchor,在KITTI上,研究者一般都是一个类别一个类别就行训练,然后做检测,一方面是个刷分技巧,另外一方面这也是因为整个场景多一组anchor是很大的显存占用。这也是anchor-free的方法出现的优势,但是就效果而言,anchor设置的方法还是效果好一些。之前介绍到的文章都是采用的anchor-based的方法。
3.2 anchor-free的研究情况
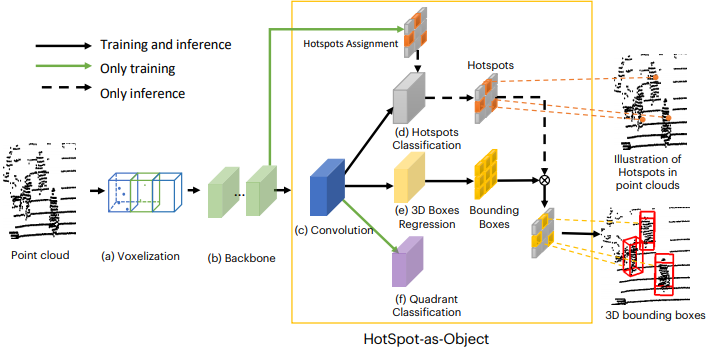
目前笔者看到过几篇研究anchor-free的文章,这里选择两篇做一下分享和总结。第一篇文章是arxiv19上的bject as Hotspots,文章链接:https://arxiv.org/pdf/1912.12791.pdf,网络结果如下图所示,主要的贡献可以总结为:
(1)以前的方法都是需要在预先对全部场景给出很多object级别的anchor,没有考虑效率,以及很对的Neg导致了背景和前景的不平衡。
(2)作者backbone和之前介绍的一样,首先是对点云通过voxel提取特征,随后根据原始点到fea map的映射关系和标注框来决定哪些是Hotspot,再然后,根据作者自己设计的reg -loss回归的是当前所在物体的中心坐标的偏移,(这里可以根据每一个voxel划分时得到的坐标值作为回归的量)。
(3)也就是采用了上面这种策略,使得不用在全场景中划分label,只需要在fea map中选择hotspots进行回归就行.
也就是说,这个工作是根据原始点到最终feature-map的索引决定在feature-map中的grid是否为这里提到的hot-spots,如果是,就以该Grid为anchor直接预测proposals。
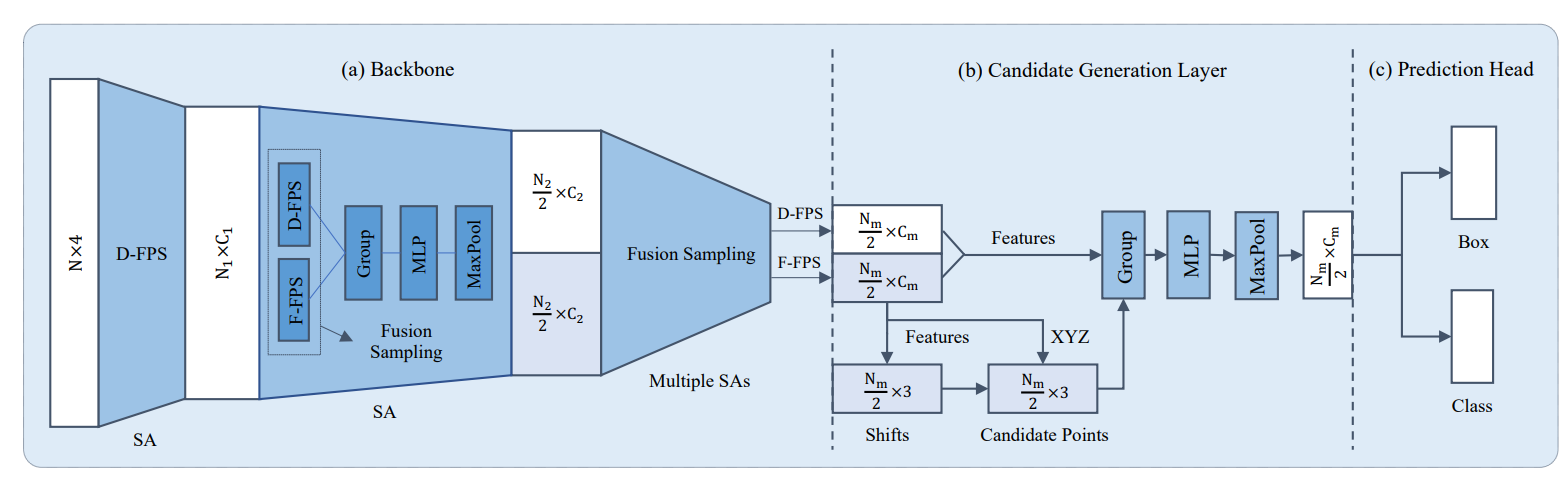
第二个要分享的文章是今年的CVPR20中point-based的方法3D-SSD,这一篇文章笔者在前面也有细致的分享过,具体结构如下所示,实际上也就是一个point-encoder的过程,随着point的下采样,最后一层的点数会逐渐变少,这里作者设置的是512个点,通过这篇文章提出的F-FPS方法(特征空间采样),这512个点中有比较多的是gt-bbox中的点,然后可以根据这些点做anchor-free的回归。
3.3 anchor-based和anchor-free方法总结
anchor-based的方法精度高,漏检的可能性比较小,但是由于3D目标检测中anchor的显存占用随着检测类别的增加呈现线性增加,所以在实用性上是需要被改进的,进一步的,在新的数据集上,诸如nusecene上,检测的类别多达10类,当然刷分可以一类一类train。因为其比较好的精度表现也成为了目前比较流行的方法。
就anchor-free的方法来说,都体现出一个原则就是先按照一定的方法选择一些"key-point’,无论是通过索引判定feature-map中的grid是否为hot-spots,还是设计新的采样方式得到更多的gt-box中的点,都是在做寻找hot-spots的工作,不过目前看来还是有发展的空间的。目前的研究也不是很多。
这次的分享就到这吧,下次把voxel-represtentation方法中的剩下的在精度上做出贡献的几个part做一定的分享。