文章目录
介绍
深度学习语义分割(Semantic Segmentation)是一种计算机视觉任务,它旨在将图像中的每个像素分类为预定义类别之一。与物体检测不同,后者通常只识别和定位图像中的目标对象边界框,语义分割要求对图像的每一个像素进行分类,以实现更精细的理解。这项技术在自动驾驶、医学影像分析、机器人视觉等领域有着广泛的应用。
深度学习语义分割的关键特点
- 像素级分类:对于输入图像的每一个像素点,模型都需要预测其属于哪个类别。
- 全局上下文理解:为了正确地分割复杂场景,模型需要考虑整个图像的内容及其上下文信息。
- 多尺度处理:由于目标可能出现在不同的尺度上,有效的语义分割方法通常会处理多种分辨率下的特征。
主要架构和技术
-
全卷积网络 (FCN):
- FCN是最早的端到端训练的语义分割模型之一,它移除了传统CNN中的全连接层,并用卷积层替代,从而能够接受任意大小的输入并输出相同空间维度的概率图。
-
跳跃连接 (Skip Connections):
- 为了更好地保留原始图像的空间细节,一些模型引入了跳跃连接,即从编码器部分直接传递特征到解码器部分,这有助于恢复细粒度的结构信息。
-
U-Net:
- U-Net是一个专为生物医学图像分割设计的网络架构,它使用了对称的收缩路径(下采样)和扩展路径(上采样),以及丰富的跳跃连接来捕捉局部和全局信息。
-
DeepLab系列:
- DeepLab采用了空洞/膨胀卷积(Atrous Convolution)来增加感受野而不减少特征图分辨率,并通过多尺度推理和ASPP模块(Atrous Spatial Pyramid Pooling)增强了对不同尺度物体的捕捉能力。
-
PSPNet (Pyramid Scene Parsing Network):
- PSPNet利用金字塔池化机制收集不同尺度的上下文信息,然后将其融合用于最终的预测。
-
RefineNet:
- RefineNet强调了高分辨率特征的重要性,并通过一系列细化单元逐步恢复细节,确保输出高质量的分割结果。
-
HRNet (High-Resolution Network):
- HRNet在整个网络中保持了高分辨率的表示,同时通过多尺度融合策略有效地整合了低分辨率但富含语义的信息。
数据集和评价指标
常用的语义分割数据集包括PASCAL VOC、COCO、Cityscapes等。这些数据集提供了标注好的图像,用于训练和评估模型性能。
评价语义分割模型的标准通常包括:
- 像素准确率 (Pixel Accuracy):所有正确分类的像素占总像素的比例。
- 平均交并比 (Mean Intersection over Union, mIoU):这是最常用的评价指标之一,计算每个类别的IoU(交集除以并集),然后取平均值。
- 频率加权交并比 (Frequency Weighted IoU):考虑每个类别的出现频率,对mIoU进行加权。
总结
随着硬件性能的提升和算法的进步,深度学习语义分割已经取得了显著的进展。现代模型不仅能在速度上满足实时应用的需求,还能提供非常精确的分割结果。未来的研究可能会集中在提高模型效率、增强跨域泛化能力以及探索无监督或弱监督的学习方法等方面。
DeepLab
DeepLab 是一种专门为语义分割任务设计的深度学习模型,由 Google 团队提出。它在处理具有复杂结构和多尺度对象的图像时表现出色,能够精确地捕捉边界信息,并且有效地解决了传统卷积神经网络(CNN)中由于下采样操作导致的空间分辨率损失的问题。
DeepLab 的核心技术
-
空洞卷积(Atrous Convolution / Dilated Convolution)
- 空洞卷积是在标准卷积的基础上增加了一个参数——膨胀率(dilation rate)。通过调整膨胀率,可以在不改变特征图尺寸的情况下扩大感受野,从而捕获更广泛的空间上下文信息。
- 这使得 DeepLab 能够在保持较高空间分辨率的同时,利用较大的感受野来获取丰富的上下文信息,这对语义分割非常有用。
-
多尺度推理(Multi-scale Context Aggregation)
- DeepLab 采用多种方法来聚合不同尺度的信息。例如,在早期版本中使用了多尺度输入图像进行推理;而在后来的版本中,则引入了空洞空间金字塔池化(ASPP, Atrous Spatial Pyramid Pooling),即在同一层应用多个不同膨胀率的空洞卷积核,以覆盖不同的尺度。
- ASPP 可以看作是一种特殊的池化层,它通过组合来自不同尺度的感受野输出,增强了对多尺度物体的理解能力。
-
跳跃连接与解码器模块(Skip Connections and Decoder Module)
- 在某些 DeepLab 版本中,如 DeepLab v3+,加入了类似 U-Net 的跳跃连接机制,将低层次的细节信息传递给高层次的特征表示,帮助恢复精细的物体边界。
- 解码器模块则用于进一步提升分割结果的质量,特别是对于小目标或细长结构的检测更加有效。
-
批量归一化(Batch Normalization)
- 批量归一化有助于加速训练过程并提高模型泛化性能。DeepLab 模型通常会在每个卷积层之后添加 BN 层,以稳定和优化学习过程。
-
预训练权重迁移学习
- DeepLab 常常基于已有的大规模数据集(如 ImageNet)上预训练好的 CNN 模型(如 ResNet、Xception)作为骨干网络,然后针对特定的语义分割任务进行微调。这种迁移学习策略不仅提高了模型的初始表现,还减少了训练时间和计算资源需求。
DeepLab 的发展历史
- DeepLab v1:首次引入了空洞卷积的概念,用以解决卷积过程中因池化和下采样带来的分辨率降低问题。
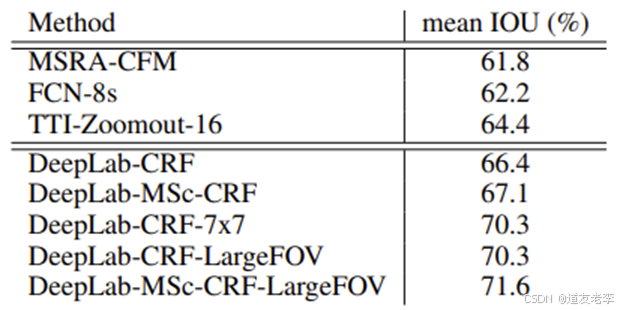
- DeepLab v2:增加了 ASPP 结构,更好地处理了多尺度物体,并引入了条件随机场(CRF)后处理步骤来改善分割边缘质量。
- DeepLab v3:改进了 ASPP 设计,移除了 CRF 后处理,转而依赖更强大的网络架构来实现更好的分割效果。
- DeepLab v3+:引入了解码器模块,结合了编码器-解码器框架的优点,进一步提升了分割精度,特别是在细粒度结构上的表现。
总之,DeepLab 系列模型通过不断创新和技术改进,成为了语义分割领域的重要研究方向之一,并为后续的工作提供了宝贵的参考和启发。

DeepLabV1
首次引入了空洞卷积的概念,用以解决卷积过程中因池化和下采样带来的分辨率降低问题
网络优势
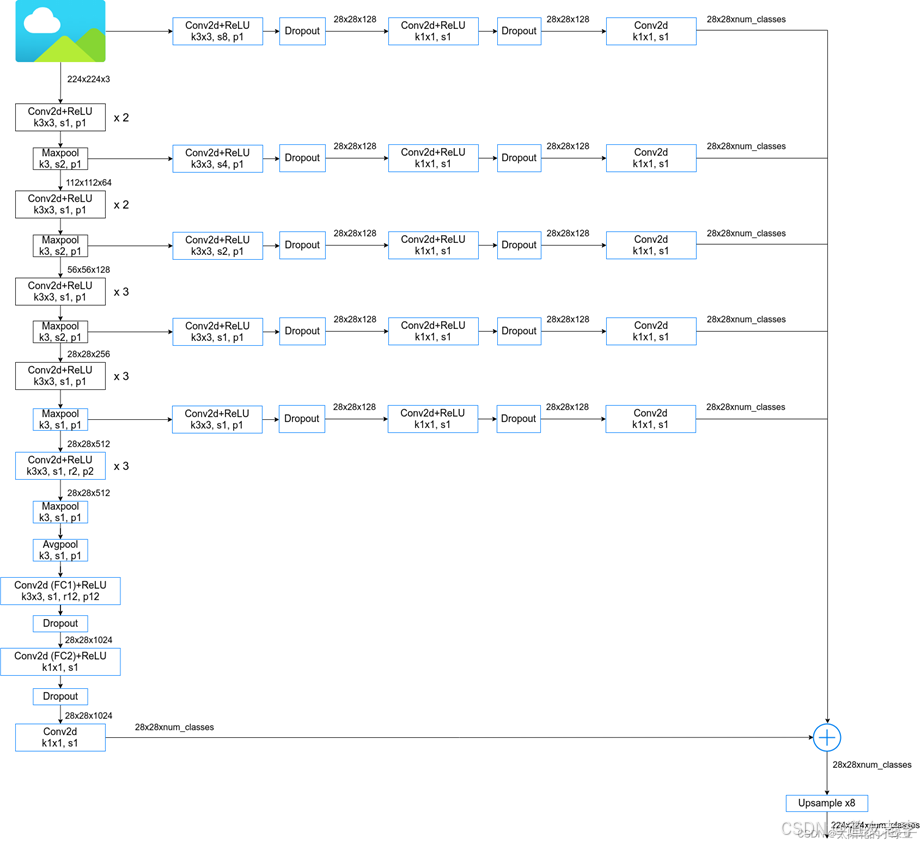
- 速度更快,论文中说是因为采用了膨胀卷积的原因,但fully-connected CRF很耗时
- 准确率更高,相比之前最好的网络提升了7.2个点
- 模型很简单,主要由DCNN和CRF联级构成

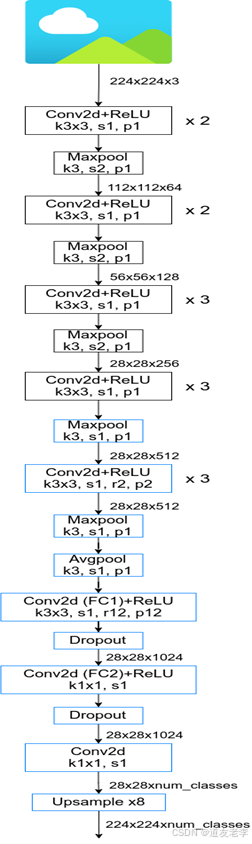
网络结构
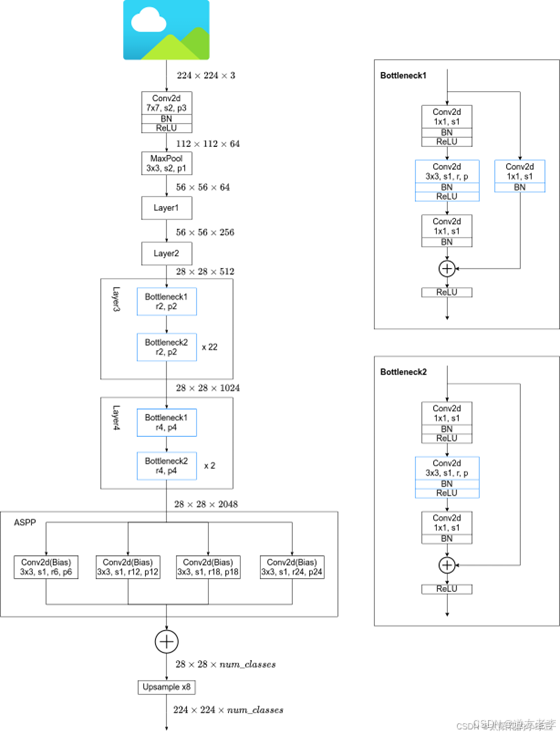
DeepLabV2
增加了 ASPP 结构,更好地处理了多尺度物体,并引入了条件随机场(CRF)后处理步骤来改善分割边缘质量
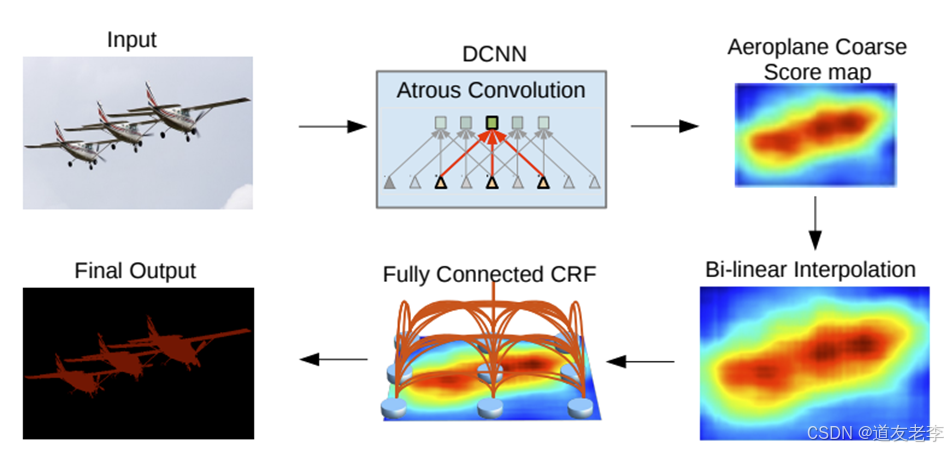
DCNNs应用在语义分割中的问题:
- 分辨率被降低(主要由于下采样stride>1的层导致)
- 目标的多尺度问题
- DCNNs的不变性会降低定位精度
对应的解决办法
- 针对分辨率被降低的问题,一般就是将最后的几个Maxpooling层的stride设置成1(如果是通过卷积下采样的,比如resnet,同样将stride设置成1即可),配合使用膨胀卷积
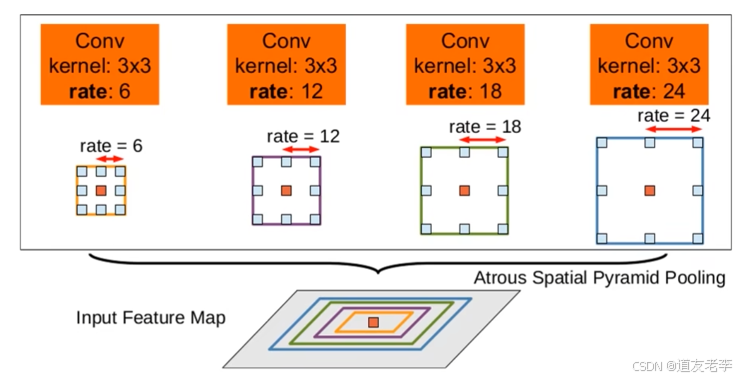
- 针对目标多尺度问题,最容易想到的就是将图像缩放到多个尺度分别通过网络进行推理,最后将多个结果进行融合即可。这样做虽然有用但是计算量太大了。为了解决这个问题,DeepLab V2中提出了ASPP模块。
- 针对DCNNs不变性导致定位精度降低的问题,和DeepLab V1差不多还是通过CRFs解决,不过这里用的是fully connected pairwise CRF,相比V1里的更高效点。
网络优势
- 速度更快
- 准确率更高(当时的state-of-art)
- 模型结构简单,还是DCNNs和CRFs联级
ASPP(atrous spatial pyramid pooling)
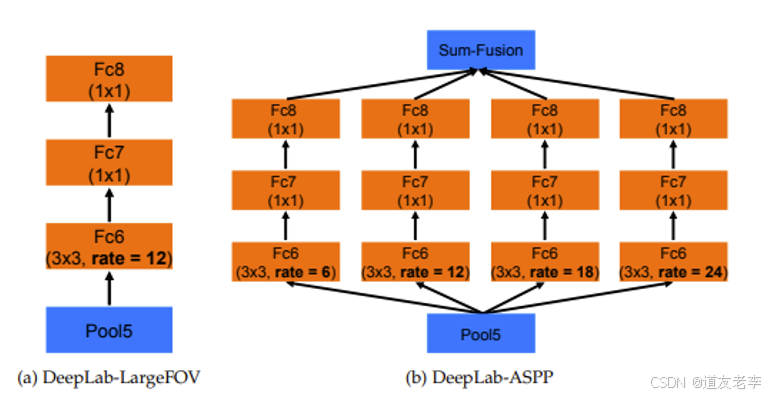
网络结构