文章目录
1 Author
Dong Yang, Holger Roth, Ziyue Xu, Fausto Milletari, Ling Zhang, and Daguang Xu
NVIDIA, Bethesda, USA
2 Abstract
To fully exploit the potentials of neural networks, we propose an automated searching approach for the optimal training strategy with reinforcement learning.
The proposed approach can be utilized for tuning hyper-parameters, and selecting necessary data augmentation with certain probabilities.
3 Introduction
Training models requires careful design of work-flow, and setup of data augmentation, learning rate, loss functions, optimizer and so on.
Recent works indicate that the full potentional of current state-of-the-art network models may not yet be well-explored. For instance, the winning solution of the Medical Decathlon Challange is using ensembles of 2D/3D U-Net only (nnU-Net), and elaborate engineering designs.
Therefore, although the current research trend is to develop elaborate and powerful 3D segmentation network models (within GPU memory limit), it is also very important to pay attentions to the details of model training.
4 Related Work
In machine learning, the hyper-parameter optimization has been studies for years, and several approaches have been developed such as grid search, Bayesian optimization, random search and so on.
Reinforcement learning (RL) based approaches:
In principle, a RNN-based agent/policy collects the information (reward, state) from the environment, update the weights within itself, and creates the next potential neural architectures for validation.The searching objectives are the parameters of the convolutional kernels, and how they are connected one-by-one. The validation output is utilized as the reward to update the agent/policy.
The RL related approaches fit such scenario since there is no ground truth for the neural architectures with the best validation performance.
5 Methodology
5.1 Searching Space Definition
-
Firstly, we consider the parameters for
data augmentation, which is an important component for training neural networks in 3D medical image segmentation as it increases therobustnessof the models andavoids overfitting.
Augmentationincludesimage sharpening,image smoothing,adding Gaussian noise,contrast adjustment, andrandom shift of intensity range, etc. -
Secondly, we found the
learning rateα α α is also critical for medical image segmentation.
Sometimes, large network models favor a large α for activation, and small datasets prefer small α α α.
Similar treatment can be applied to any possible hyperparameters in the training process for optimization. Moreover, unlike other approaches, we search for the optimal hyper-parameters in the high-dimensional continuous space instead of discrete space.

5.2 RL Based Searching Approach
Searching approach is shown in Algorithm 1.
For the RL setting, the reward is the validation accuracy, the action is the newly generated
C
i
{C}_{i}
Ci, environment observation/state is
C
i
−
1
{C}_{i-1}
Ci−1 from the last step, and the policy is the RNN job controller H.
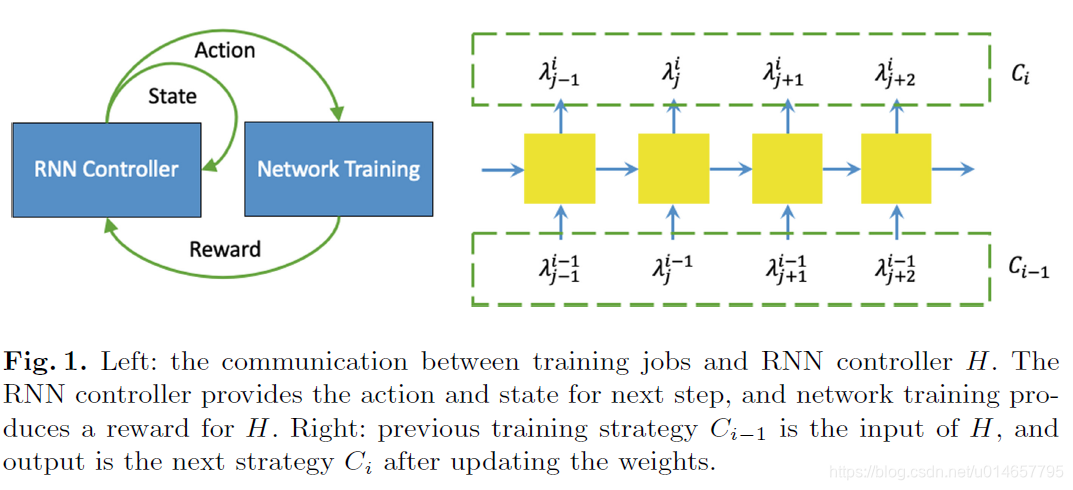
Each output node produces two-channel outputs after softmax activation.
Then the first channel of the output is fed to the next step as action after mapping back to the original searching space.
The Proximal Policy Optimization (PPO) is adopted to train the RNN cells in
H
H
H.
The loss function is as follows.
θ
←
θ
+
γ
r
∇
θ
ln
H
(
C
i
∣
C
i
−
1
,
θ
)
\theta \leftarrow \theta+\gamma r \nabla_{\theta} \ln H\left(C_{i} | C_{i-1}, \theta\right)
θ←θ+γr∇θlnH(Ci∣Ci−1,θ)
θ
θ
θ represents the weights in RNN. During training, the reward
r
r
r is utilized to update the weights using gradient back-propagation. To train the RNN controller, we use RMSprop as the optimizer with a learning rate
γ
γ
γ of 0.1.
6 Experimental Evaluation
6.1 Datasets
The medical decathlon challenge (MSD) provides ten different tasks on 3D CT/MR image segmentation.
6.2 Implementation
Our baseline model follows the work the 2D-3D hybrid network, but without the PSP component.
Refer to:
Liu, S., et al.: 3D anisotropic hybrid network: transferring convolutional features from 2D images to 3D anisotropic volumes. In: Frangi, A.F., Schnabel, J.A., Davatzikos, C., Alberola-L´opez, C., Fichtinger, G. (eds.) MICCAI 2018. LNCS, vol. 11071, pp. 851–858. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-00934-2_94
The pre-trained ResNet-50 (on ImageNet) possesses a powerful capability for feature extraction as the encoder.
And the 3D decoder network with DenseBlock provides smooth 3D predictions.
The input of the network are
96
×
96
×
96
96 × 96 × 96
96×96×96 patches, randomly cropped from the re-sampled images during training.
Meanwhile, the validation step follows the scanning window scheme with a small overlap (one quarter of a patch).
By default, all training jobs use the Adam optimizer, and the Dice loss is used for gradient computing.
The validation accuracy is measured with the Dice’s score after scanning window.
To save searching time, we start the searching process from a pre-trained model trained after 500 epochs without any augmentation or parameter searching.
Each job fine-tunes the pre-trained model with 200 epochs with its training strategy.
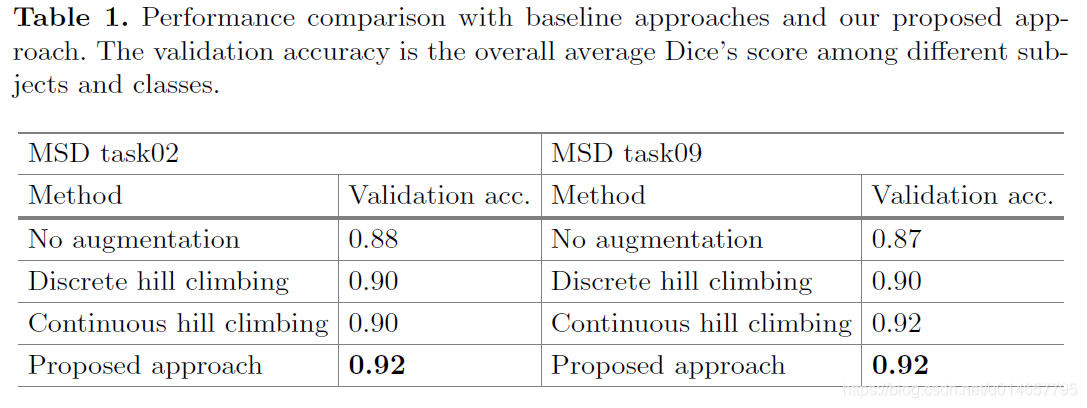
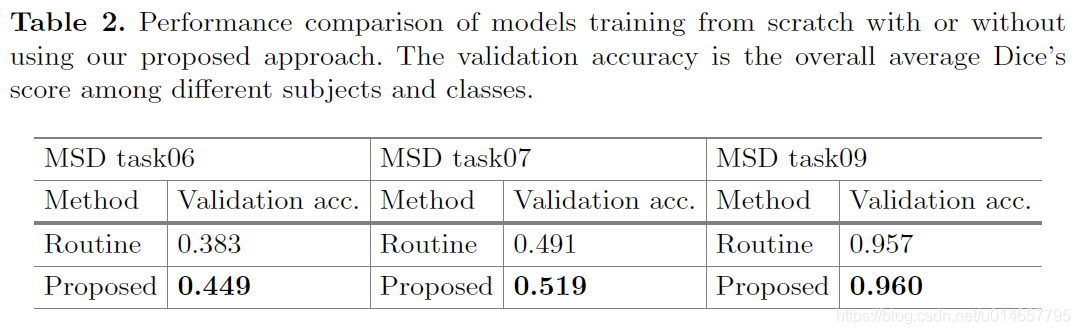
The same task, task09, is used in both, the first and second experiment. From the Tables 1 and 2, we can see training from scratch with augmentation could achieve a higher Dice’s score compared with the one fine-tuned from a “no-augmentation” model. This suggests that the found data augmentation strategy is effective when applied to training from scratch.
7 Conclusions
It possesses large potentials to be applied for general machine learning problems.
Extending the single-value reward function to a multi-dimensional reward function could be studied as the future direction.